NLP Notes (Part 3)
(Beginning: 1 , 2 ) Well, we come to the most interesting part - the analysis of proposals. This topic is multifaceted and multilevel, so approaching it is not very simple. But difficulties only harden :) Yes and output, the text is written easy ...
Let's start with this concept as a syntactic analysis of sentences (in English parsing ). The essence of this process is to build a graph that “somehow” reflects the structure of the proposal.
I say “in any way” because today there is no single accepted system of principles on which the graph is built. Even within the framework of one concept, the views of individual scientists on the relationship between words can differ (this resembles the disagreement in the interpretation of morphological phenomena, which was discussed in the previous part).
Probably, first of all, it is necessary to divide the methods of constructing a graph (usually a tree) of dependencies into phrase structure-based parsing and dependency parsing.
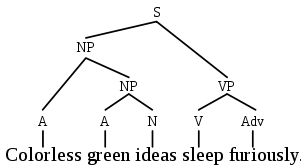
Representatives of the first school divide the sentence into "components", then each component is divided into its components - and so on, until we get to the words. This idea is well illustrated by a picture from Wikipedia:
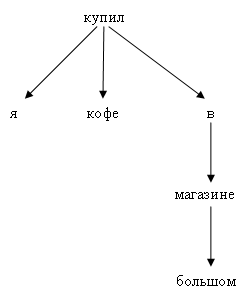
Representatives of the second school connect the words depending on each other directly, without any auxiliary nodes:
I must say that my sympathies are on the side of the second approach (dependency parsing), but both of them deserve a more detailed discussion.
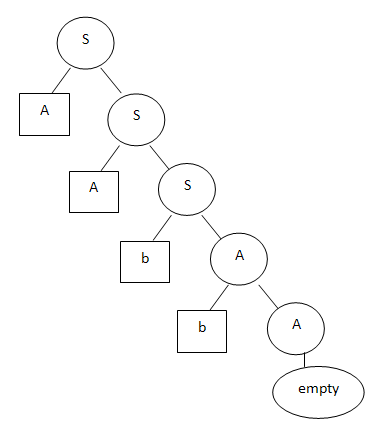
Let's say the following tree corresponds to the aabb line:
An obvious plus of this method is that Chomsky’s grammar is a long-known formalism. There are long-developed parsing algorithms; the "formal properties" of grammars are known, i.e. their expressive abilities, processing complexity, etc. In addition, Chomsky grammars are successfully used in compiling programming languages.
Chomsky himself is primarily a linguist, and he tried on his works in natural language, English, first of all. Therefore, in English-language computer linguistics, the influence of his works is quite large. Although “on the forehead” Chomsky’s formalisms are, as far as I know, not used in natural language processing (they are not sufficiently developed for this), the spirit of his school lives on.
A good example of a parser building such trees is Stanford parser (there is an online demo).
In general, this approach is also difficult to call particularly fresh. Everyone refers to the work of Lucien Tesniere of the fifties as the source. Mention is made of earlier thoughts (but from the same opera as what is called the father of the PLO Plato, because he coined the concept of the “world of ideas,” that is, abstract classes). However, in computer linguistics, dependency parsing was for a long time in the background, while Chomsky's grammars were actively used. Probably, the limitations of Chomsky’s approach hit the languages with a freer (than in English) word order, which is why the most interesting work in the field of dependency parsing is still carried out “outside” the English-speaking world.
The main idea of dependency parsing is to interconnect dependent words. The center of almost any phrase is the verb (explicit or implied). Further from the verb (action) you can ask questions: who does what does, where does and so on. For attached entities, you can also ask questions (first of all, the question “what”). For example, for the tree “I bought coffee in a large store” above, you can reproduce this chain of questions. Root - bought (phrase action). Who bought? - I. What did you buy? - Coffee. Where did you buy it? - In the shop. In which shop? - In the Big.
Here, too, there are many technical subtleties and ambiguities. The lack of a verb can be treated differently. Usually, the verb "to be" is still implied: "I [am] a student." In predicative sentences, the situation is more complicated: It's damp on the street. You can’t say that it’s damp on the street :) It’s not always clear what depends on what and how to interpret it. For example, “I won’t go to work today.” How does the “not” particle relate to other words? As an option, we can assume that the verb “non-action” is used here: “I will not go” (even though this is not in Russian, but it’s meaningful). It is not entirely clear how to sculpt homogeneous members joined by a union. "I bought coffee and a bun." For example, you can sculpt the word “and” to “bought”, and attach “coffee” and “bun” to “and”. But there are other approaches. A rather subtle point arises from the interaction of words, forming a kind of unity: "I will go to work." It is clear that “I will walk” is essentially the only verb (that is, action) of the future tense, it was simply created in two words.
If you want to look at such an analyzer in action, I can recommend the Connexor website .
Why is dependency parsing attractive? Give different arguments. For example, it is said that combining words with each other, we do not create additional entities, and, therefore, simplify further analysis. In the end, parsing is just the next step in text processing, and then you need to imagine what to do with the resulting tree. In a sense, the dependency tree is “cleaner” because it shows explicit semantic relationships between elements of a sentence. Further, it is often claimed that dependency parsing is more suitable for languages with a free word order. In Chomsky, all dependent blocks somehow really turn out to be next to each other. Here, in theory, you can have connections between words at different ends of the sentence (although technically it’s not so simple here, but more on that later). In principle, these arguments are enough for me,
I must say that there is formal evidence of the proximity of the resulting trees. Somewhere slipped a theorem that a tree of one kind can be converted into a tree of another kind and vice versa. But in practice, this does not work. At least in my memory no one tried to get a dependency tree by converting the output of Stanford parser. Apparently, not everything is so simple, and the errors multiply ... first the Stanford parser will make a mistake, then the conversion algorithm will make a mistake ... and what happens in the end? Error on error.
(UPD: the mentioned Stanford guys still tested the method of converting the output of their parser into dependency structures. However, I should note that with this conversion only the projective trees we are talking aboutin the fifth part ).
Probably enough for today. We continue in the next part.
Let's start with this concept as a syntactic analysis of sentences (in English parsing ). The essence of this process is to build a graph that “somehow” reflects the structure of the proposal.
I say “in any way” because today there is no single accepted system of principles on which the graph is built. Even within the framework of one concept, the views of individual scientists on the relationship between words can differ (this resembles the disagreement in the interpretation of morphological phenomena, which was discussed in the previous part).
Probably, first of all, it is necessary to divide the methods of constructing a graph (usually a tree) of dependencies into phrase structure-based parsing and dependency parsing.
Representatives of the first school divide the sentence into "components", then each component is divided into its components - and so on, until we get to the words. This idea is well illustrated by a picture from Wikipedia:
Representatives of the second school connect the words depending on each other directly, without any auxiliary nodes:
I must say that my sympathies are on the side of the second approach (dependency parsing), but both of them deserve a more detailed discussion.
Chomsky School
The analysis of “components” clearly grew out of Chomsky’s grammar. If anyone does not know, Chomsky’s grammar is a way of defining rules that describe language sentences. Using this grammar, you can both generate phrases and analyze them. For example, the following grammar describes a “language” consisting of an arbitrary number of letters a, followed by an arbitrary number of letters b: Starting with the character S, any line of the form a ... ab ... b can be generated. There is also a universal algorithm for parsing such a grammar. By feeding him an input string and a set of grammar rules, you can get the answer - whether the string is a valid string within the given language or not. You can also get a parsing tree showing how the string is derived from the initial character S.S -> aS | bA | 'empty'
A -> bA | 'empty'
Let's say the following tree corresponds to the aabb line:
An obvious plus of this method is that Chomsky’s grammar is a long-known formalism. There are long-developed parsing algorithms; the "formal properties" of grammars are known, i.e. their expressive abilities, processing complexity, etc. In addition, Chomsky grammars are successfully used in compiling programming languages.
Chomsky himself is primarily a linguist, and he tried on his works in natural language, English, first of all. Therefore, in English-language computer linguistics, the influence of his works is quite large. Although “on the forehead” Chomsky’s formalisms are, as far as I know, not used in natural language processing (they are not sufficiently developed for this), the spirit of his school lives on.
A good example of a parser building such trees is Stanford parser (there is an online demo).
Word Relationship Model
In general, this approach is also difficult to call particularly fresh. Everyone refers to the work of Lucien Tesniere of the fifties as the source. Mention is made of earlier thoughts (but from the same opera as what is called the father of the PLO Plato, because he coined the concept of the “world of ideas,” that is, abstract classes). However, in computer linguistics, dependency parsing was for a long time in the background, while Chomsky's grammars were actively used. Probably, the limitations of Chomsky’s approach hit the languages with a freer (than in English) word order, which is why the most interesting work in the field of dependency parsing is still carried out “outside” the English-speaking world.
The main idea of dependency parsing is to interconnect dependent words. The center of almost any phrase is the verb (explicit or implied). Further from the verb (action) you can ask questions: who does what does, where does and so on. For attached entities, you can also ask questions (first of all, the question “what”). For example, for the tree “I bought coffee in a large store” above, you can reproduce this chain of questions. Root - bought (phrase action). Who bought? - I. What did you buy? - Coffee. Where did you buy it? - In the shop. In which shop? - In the Big.
Here, too, there are many technical subtleties and ambiguities. The lack of a verb can be treated differently. Usually, the verb "to be" is still implied: "I [am] a student." In predicative sentences, the situation is more complicated: It's damp on the street. You can’t say that it’s damp on the street :) It’s not always clear what depends on what and how to interpret it. For example, “I won’t go to work today.” How does the “not” particle relate to other words? As an option, we can assume that the verb “non-action” is used here: “I will not go” (even though this is not in Russian, but it’s meaningful). It is not entirely clear how to sculpt homogeneous members joined by a union. "I bought coffee and a bun." For example, you can sculpt the word “and” to “bought”, and attach “coffee” and “bun” to “and”. But there are other approaches. A rather subtle point arises from the interaction of words, forming a kind of unity: "I will go to work." It is clear that “I will walk” is essentially the only verb (that is, action) of the future tense, it was simply created in two words.
If you want to look at such an analyzer in action, I can recommend the Connexor website .
Why is dependency parsing attractive? Give different arguments. For example, it is said that combining words with each other, we do not create additional entities, and, therefore, simplify further analysis. In the end, parsing is just the next step in text processing, and then you need to imagine what to do with the resulting tree. In a sense, the dependency tree is “cleaner” because it shows explicit semantic relationships between elements of a sentence. Further, it is often claimed that dependency parsing is more suitable for languages with a free word order. In Chomsky, all dependent blocks somehow really turn out to be next to each other. Here, in theory, you can have connections between words at different ends of the sentence (although technically it’s not so simple here, but more on that later). In principle, these arguments are enough for me,
I must say that there is formal evidence of the proximity of the resulting trees. Somewhere slipped a theorem that a tree of one kind can be converted into a tree of another kind and vice versa. But in practice, this does not work. At least in my memory no one tried to get a dependency tree by converting the output of Stanford parser. Apparently, not everything is so simple, and the errors multiply ... first the Stanford parser will make a mistake, then the conversion algorithm will make a mistake ... and what happens in the end? Error on error.
(UPD: the mentioned Stanford guys still tested the method of converting the output of their parser into dependency structures. However, I should note that with this conversion only the projective trees we are talking aboutin the fifth part ).
Probably enough for today. We continue in the next part.