Who reads whom in LJ - analysis of the intersection of the audiences of top bloggers
Start
 The topic of the study of connections in social networks is becoming increasingly relevant for various reasons: an attempt to answer the question about the degree of connectedness of network participants; speed and ways of disseminating information; about the effectiveness of targeted advertising, after all. Yes, and the process of research and the search for implicit links is addictive!
The topic of the study of connections in social networks is becoming increasingly relevant for various reasons: an attempt to answer the question about the degree of connectedness of network participants; speed and ways of disseminating information; about the effectiveness of targeted advertising, after all. Yes, and the process of research and the search for implicit links is addictive! For my research in this direction, I chose the most “boiling” piece of Runet, namely, the Russian segment of LiveJournal . The foggy-worded question sounded something like this: is it possible to distinguish blogging “groups” based on the structure of relations between users of the LiveJournal service, i.e. with only information about friends .
Putting as a working hypothesis the idea that such information can be extracted from an analysis of the audiences of popular magazines, I was faced with the task of obtaining reliable data about these audiences. The basic tools of the livejournal service do not provide an opportunity to get a complete list of readers of the multi-thousand-plus blog. Therefore, the first step was to assemble the structure of the Russian LJ links on the home computer.
Looking ahead, I’ll say: the social graph of Russian LJ in my study has 2.08 million vertices and 58.05 million arcs. Interesting? Then, under the cut, there are a lot of letters, numbers and pictures.
Collection of information
According to the Yandex.Blogs service, the Russian segment of LiveJournal has a little more than 2 million blogs. Taking this list as a basis, I did some automated work on filling out a database of “friendly” relations between blogs, which allows me to answer at least one question: who reads a particular blog.
Few numbers
Connections were collected 2.08 million users . Those. the graph with 2.08 million vertices received another 58.05 million arcs (directed friendship between users) on 03/13/2011 . Moreover, only half - 1.08 million users are reading someone else (has an outgoing arc) and 1.26 million have readers. As an illustration, we can cite some statistics on the number of friends (readers):

The database did not include connections that were sent outside the “Russian segment” (this is somewhere a little more than 6 million arcs to 0.9 million peaks) that are not were investigated additionally and classified as “foreign”, although live Russian blogs also get there.
Error estimation
To assess the completeness of the collected graph, we compare the “official” number of readers from the livejournal.com top with the number for the same bloggers, but obtained by summing the incoming arcs on the graph. For greater accuracy, two TOP-50 fragments were taken:
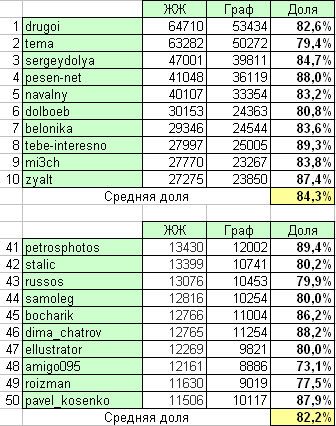
As we can see from the table, the generated graph of readers corresponds to the real one by a little more than 80%. The error may be due to the initial isolation of the “Russian segment” (that is, the exclusion of foreign friends) and the incompleteness of the list of Russian magazines. In the future, some slight refinement of the structure of the local graph is possible.
Analysis of the intersection of the TOP-10 audiences
The analysis itself is simple and flat - we take the lists of readers of each blog from the TOP-10 and look for their intersection, putting the results in a tablet. More precisely, in two tablets - in absolute, with quantitative values and relative - indicating the percentage of audience overlap.
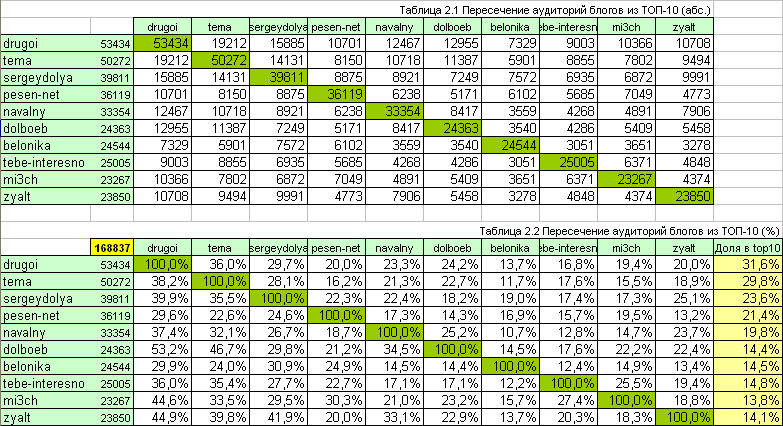
Firstly , the second table shows that the total audience of magazines from the TOP-10 (i.e. people who have subscribed to at least one top blog): 168837 people (we remember about the error).
Secondly , we can say that a third (34.5%) of the audience of Anton Nosik ( dolboeb ) also reads Navalny ( navalny ), but from the readers of Nika Belotserkovskaya ( belonika) of the same Navalny reads only 14.5%. But 30.9% of its readers are also eagerly awaiting new reports by Sergey Doly ( sergeydolya ) and as much as a quarter (24.9%) - stories from the life of Slava Se ( pesen_net ). And by the way, almost half (46.7%) of the readers of the same Anton Nosik follow movements on the tundra of Artemy Lebedev ( tema ), and 20% of the audience of top leader Rustem Adagamov ( drugoi ) likes to receive hot photo reports of our political movement from the source - Ilya Varlamova ( zyalt ).
Thirdly, you can build and intersection of audiences of higher orders. For example, the analysis of the intersections of the audiences of three bloggers is a cube. So a slice of a similar cube according to Alexei Navalny will give the following picture:

The matrix is obtained symmetric with respect to the main diagonal. The numbers indicate the proportion of the total audience of two magazines (the intersection of the row and column), which also read Alexei Navalny ( navalny ).
From the table you can see that only a third (34.4%) of the total audience of tema and drugoi blogs also read navalny , but from the audience zyalt and dolboebit is read by almost two thirds - 64.2%. The minimal interest in the fight against corruption online is shown to the audience of belonika-sergeydolya (26.6%) and belonika-pesen_net (25.5%).
Well, and fourthly , if you are engaged in the placement of advertising posts on the blogs of thousands of people and do not have such layouts in the TOP-50 - fire the marketer :)
How to embrace the immense?
On the one hand, numerical data are sufficient for various applied research. On the other hand, for some researchers, it is simply necessary to visually evaluate the working field. Let's try to twist the data before our eyes. How?
Here, methods of visual presentation of multidimensional data with a decrease in dimension will be useful to us: try to “squeeze” our 10-dimensional data set (bloggers reading magazines from TOP-10) into a two-dimensional image on a plane. In this case, ideally, it would be nice to get some grouping of readers on readable blogs. Not very confused?
The first grouping option is to cluster using the g-means (clustering with automatic determination of the number of clusters) or k-means algorithms (clustering by a given number of clusters). In principle, the idea is sound, but this approach does not solve the problem of displaying the results and has its drawbacks given the structure of our data.
Therefore, I tried to use my favorite clustering tool - Kohnen self-organizing maps in the implementation of the Deductor analytical system (Academic version) from BaseGroup Labs. The details of the algorithm can be read in the relevant publications, I can only say that in this problem, its ability to project a multidimensional data relief onto the display plane is important. What results and how to interpret it depends heavily on the processing parameters and understanding of the nature of the data being processed. Therefore, further analysis is a special case, not claiming absolute truth.
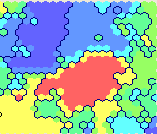
So, after feeding a sample of the neural network, which is the Kohonen map, we get this picture. The number of clusters (multi-colored zones in the lower right window) is slightly manually adjusted - set 7 pieces (numbering 0..6) - for a better visual breakdown of the result.
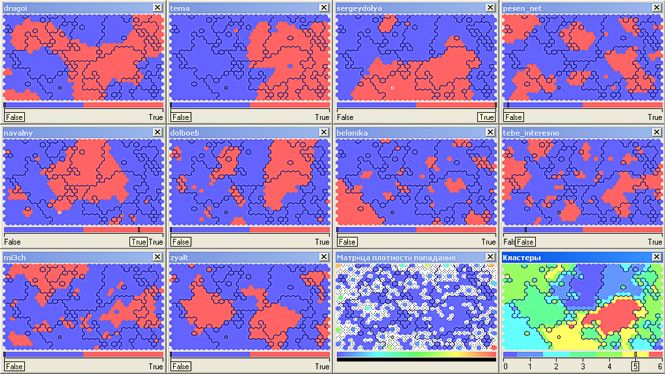
After a little meditation on a beautiful and incomprehensible picture, we can proceed to some superficial analysis.
So, the apolitical cluster (number 2, almost 19 thousand participants) of fans of Nika Belotserkovskaya ( belonika ), mainly has intersections with readers of the magazines drugoi , sergeydolya , pesen_net , mi3ch (the selected cluster has a fill in the net):
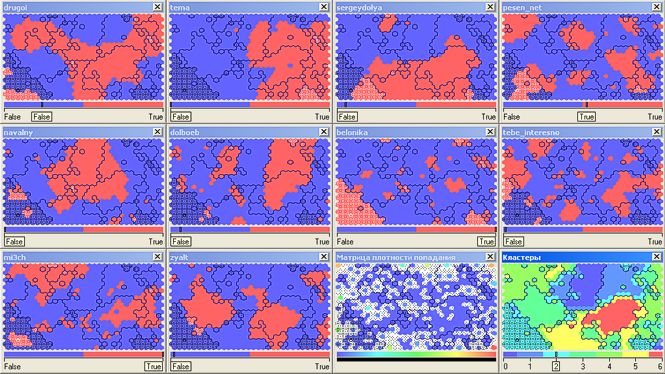
Creative intelligentsia reading Slava Se ( pesen_net ), Dmitry Chernyshev ( mi3ch ), admiring beautiful pictures from the drugoi and tebe_interesno magazines and also discussing design findings by Artemy Lebedev ( tema ) are grouped in cluster number 4 (54.5 thousand):
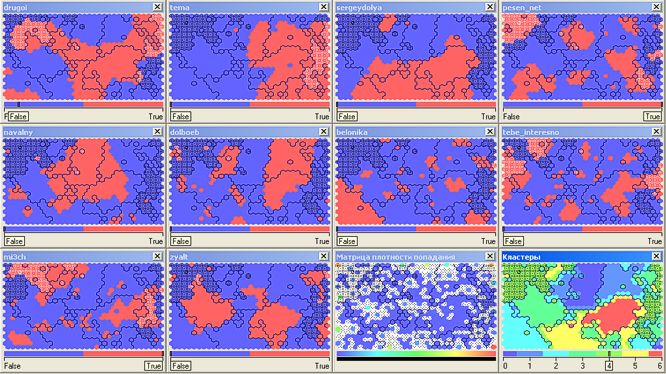
Cluster No. 6 incorporates readers (8 ths.) Without a pronounced bias reading of almost all top bloggers simultaneously:
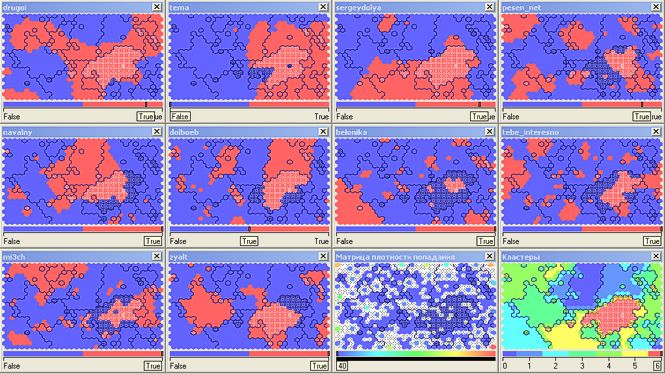
Well, where do today without Alexei Navalny ( navalny ) !? Fearing the invasion of bots, I write these lines ... Cluster number 0 (oh, just don’t beat me for associations - in the Tarot card decks the zero card is called "Jester") covers 33 thousand readers (there should be a remark, but it will go to end). It would be correct to combine it with cluster number 1 (another 16.5 thousand), also covering politically active top bloggers ( drugoi , dolboeb , zyalt ):
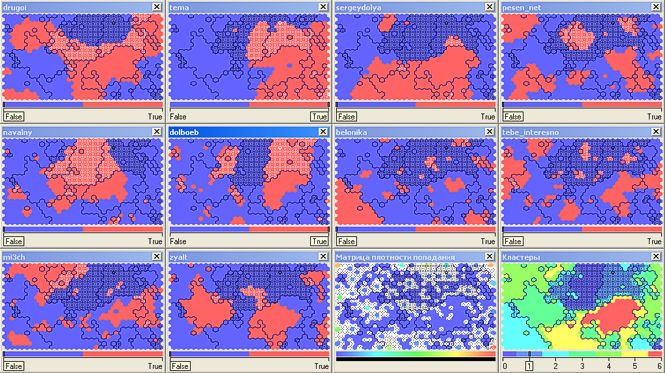
Technical Note
As I already said, in this case, the content and structure of the displayed clusters depends on their number, which can be configured. For example, for this model the number of “physical” clusters into which many readers crashed as a result of processing is 19, but for clarity, I made a rougher model with 7 “visual” clusters. The accuracy of such a partition (and the method of clustering through neural networks itself) is not absolute, so it may happen that a user who does not read it gets into the Navalny cluster. But this error, in principle, is not critical for a superficial evaluation analysis.
Instead of a conclusion
This concludes the demonstration of the work done, and on its applied value (for example, analysis of the TOP-30 or TOP-50 or a specially formed list) I suggest that advertisers using LJ to promote their goods and services think about it.
PS
LJ users who are not registered on Habré, can ask questions in my blog infist-xxi.livejournal.com