Unicode Data Compression
In one future project, the task was to transfer and store data in VCard format, which contain Cyrillic letters. Since the size of the transmitted information is limited, it was necessary to reduce the size of the data.
There were several options:
A beautiful but useless results graph:
Business card in VCard 3.0 format (length 260 characters):
All of the results below relate to this example. For Cyrillic business cards, the results should not differ. For business cards in other languages, you probably need additional research, this was not part of the task.
Option using CP1251 dropped immediately. Despite the small size of the finished files, its use (like any other traditional encoding) greatly limits the capabilities of the service.
The Standard Compression Scheme for Unicode (SCSU) is based on the development of Reuters.
The main idea of SCSU is to define dynamic windows in the Unicode code space. Characters belonging to small alphabets (for example, Cyrillic) can be encoded with one byte, which indicates the index of the character in the current window. Windows are preinstalled to the blocks that are most often used, so the encoder does not have to set them.
For large alphabets, including Chinese, SCSU allows you to switch between single-byte and Unicode mode, which is actually UTF-16BE.
Control bytes ("tags") are inserted into the text to change windows and modes. Escape tags ("quote" tags) are used to switch to another window only for the next character. This is useful for encoding a single character outside the current window, or a character that conflicts with tags.
Before the first Cyrillic letter, the encoder uses the SC2 tag (hexadecimal 12) to switch to the dynamic window No. 2, which is preinstalled on the Cyrillic block of characters. When reusing Cyrillic characters, the tag is not used.
The Binary Ordered Compression for Unicode (BOCU) concept was developed in 2001 (by Mark Davis and Markus Scherer for the ICU project).
The basic idea of BOCU-1 is to encode each character as the difference (distance in the Unicode table) to the previous character. Small differences occupy fewer bytes than large ones. Coding differences, BOCU-1 achieves the same compression for small alphabets, no matter in which block they are.
BOCU-1 complements the concept with the following rules:
For each block change (transition from Cyrillic to Latin), the encoder needs two bytes (d3 - to switch to the Cyrillic block, 4c - for the colon).
To compare the efficiency, the gzip compression algorithm was chosen. For large texts, gzip shows a large degree of compression compared to SCSU and BOCU-1 (since the number of different characters, even in multilingual documents, is limited). On small texts, like VCard in the example, it is difficult to get an unambiguous result.
A significant drawback of universal compression algorithms is the complexity of the implementation of the compressor and decompressor.
The question of two-stage compression (for example, SCSU + gzip) remains open to me.
The results of the SCSU and BOCU-1 algorithms for the source data in comparison with CP1251 and UTF8 are shown in the first column.
The second column represents the number of bytes issued directly by the encoder (without the Marker order of bytes, BOM, which indicates the type of Unicode representation in the file).
The third column represents the compressed gzip file.
The fourth column shows the number of bytes of data in the gzip archive (without a header, 18 bytes).
All files in the archive (5 kb).
SQL Server 2008 R2 uses SCSU to store nchar (n) and nvarchar (n). Symbian OS uses SCSU to serialize strings.
You can use ICU or SC UniPad
to work with SCSU and BOCU-1 .
I was very surprised that not one of the common barcode readers recognizes SCSU or BOCU-1.
Unicode Technical Note # 14. A Survey of Unicode Compression
Unicode Technical Standard # 6. A Standard Compression Scheme for Unicode
Unicode Technical Note # 6. BOCU-1: MIME-Compatible Unicode Compression
There were several options:
- Use traditional encodings (for Cyrillic - CP1251).
- Use Unicode compression formats. Today it is SCSU and BOCU-1. I give a detailed description of these two formats below.
- Use universal compression algorithms (gzip).
A beautiful but useless results graph:
Input data
Business card in VCard 3.0 format (length 260 characters):
BEGIN: VCARD VERSION: 3.0 N: Pupkin; Vasily FN: Vasily Pupkin ORG: Horns and Hooves LLC TITLE: The Most Important TEL; TYPE = WORK, VOICE: +380 (44) 123-45-67 ADR; TYPE = WORK:; 1; Khreshchatyk; Kiev ;; 01001; UKRAINE EMAIL; TYPE = PREF, INTERNET: vasiliy.pupkin@example.com END: VCARD
All of the results below relate to this example. For Cyrillic business cards, the results should not differ. For business cards in other languages, you probably need additional research, this was not part of the task.
Option using CP1251 dropped immediately. Despite the small size of the finished files, its use (like any other traditional encoding) greatly limits the capabilities of the service.
SCSU
The Standard Compression Scheme for Unicode (SCSU) is based on the development of Reuters.
The main idea of SCSU is to define dynamic windows in the Unicode code space. Characters belonging to small alphabets (for example, Cyrillic) can be encoded with one byte, which indicates the index of the character in the current window. Windows are preinstalled to the blocks that are most often used, so the encoder does not have to set them.
For large alphabets, including Chinese, SCSU allows you to switch between single-byte and Unicode mode, which is actually UTF-16BE.
Control bytes ("tags") are inserted into the text to change windows and modes. Escape tags ("quote" tags) are used to switch to another window only for the next character. This is useful for encoding a single character outside the current window, or a character that conflicts with tags.
Example
... N: P at p to and n ... FN: In and with and l and y ... ... 4E 3A 12 9F C3 BF BA B8 BD ... 46 4E 3A 92 B0 C1 B8 BB B8 B9 ...
Before the first Cyrillic letter, the encoder uses the SC2 tag (hexadecimal 12) to switch to the dynamic window No. 2, which is preinstalled on the Cyrillic block of characters. When reusing Cyrillic characters, the tag is not used.
Benefits
- text encoded in SCSU basically takes up as much space as in traditional encoding. Tag overhead is relatively negligible.
- SCSU decoder is easy to implement, in comparison with universal compression algorithms.
disadvantages
- SCSU uses ASCII control characters, not only as tags, but also as part of regular characters. This makes SCSU an inappropriate format for protocols such as MIME, which interpret control characters without decoding them.
BOCU-1
The Binary Ordered Compression for Unicode (BOCU) concept was developed in 2001 (by Mark Davis and Markus Scherer for the ICU project).
The basic idea of BOCU-1 is to encode each character as the difference (distance in the Unicode table) to the previous character. Small differences occupy fewer bytes than large ones. Coding differences, BOCU-1 achieves the same compression for small alphabets, no matter in which block they are.
BOCU-1 complements the concept with the following rules:
- The previous or base value is aligned in the middle of the block, in order to avoid big jumps from the beginning of the block to the end.
- 32 ASCII control characters, as well as spaces, do not change during encoding, for compatibility with email and for preserving binary order
- The space does not cause a change in the base value. This means that when encoding non-Latin words separated by spaces, there is no need to make a big jump to U + 0020 and back.
- ASCII control characters reset the base value, making adjacent lines in the file independent.
Example
... N: P at p to and n; V ... FN: V a s and l and th ... ... 9e 8a d3 d3 93 8f 8a 88 8d 4c 11 d3 c6 ... 96 9e 8a d3 c6 80 91 88 8b 88 89 ...
For each block change (transition from Cyrillic to Latin), the encoder needs two bytes (d3 - to switch to the Cyrillic block, 4c - for the colon).
Benefits
- ASCII control characters remain during encoding
- Like SCSU, BOCU-1 requires little overhead compared to traditional encodings
disadvantages
- Latin letters (and all ASCII characters except control characters) change their meaning during encoding. So, for example, an XML parser should receive information about BOCU-1 encoding from a higher-level protocol.
- The BOCU-1 algorithm is not formally described anywhere, except for the program code accompanying UTN # 6.
Universal Compression Algorithms
To compare the efficiency, the gzip compression algorithm was chosen. For large texts, gzip shows a large degree of compression compared to SCSU and BOCU-1 (since the number of different characters, even in multilingual documents, is limited). On small texts, like VCard in the example, it is difficult to get an unambiguous result.
A significant drawback of universal compression algorithms is the complexity of the implementation of the compressor and decompressor.
The question of two-stage compression (for example, SCSU + gzip) remains open to me.
results
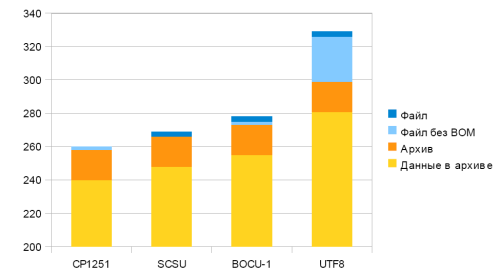
The results of the SCSU and BOCU-1 algorithms for the source data in comparison with CP1251 and UTF8 are shown in the first column.
The second column represents the number of bytes issued directly by the encoder (without the Marker order of bytes, BOM, which indicates the type of Unicode representation in the file).
The third column represents the compressed gzip file.
The fourth column shows the number of bytes of data in the gzip archive (without a header, 18 bytes).
| File | File without BOM | In the archive | Archived Data Length | |
| CP1251 | 260 | 260 | 258 | 240 |
| SCSU | 267 | 264 | 266 | 248 |
| BOCU-1 | 278 | 275 | 273 | 255 |
| Utf8 | 329 | 326 | 299 | 281 |
All files in the archive (5 kb).
Application
SQL Server 2008 R2 uses SCSU to store nchar (n) and nvarchar (n). Symbian OS uses SCSU to serialize strings.
You can use ICU or SC UniPad
to work with SCSU and BOCU-1 .
I was very surprised that not one of the common barcode readers recognizes SCSU or BOCU-1.
What else to read
Unicode Technical Note # 14. A Survey of Unicode Compression
Unicode Technical Standard # 6. A Standard Compression Scheme for Unicode
Unicode Technical Note # 6. BOCU-1: MIME-Compatible Unicode Compression