Where is our business logic, son?
- Transfer
Thanks to heaven for raining on Saturday, and I read it (and you say thank you for translating). On Sunday, however, the sun was shining and text formatting was delayed.
Special thanks to the author for allowing a separate publication.
An extremely entertaining article on what business logic is and where it lives. The article, by the way, is already three years old. And I often come across systems where the code is not separated from the data. May lead to real holivar.
Over the years of development, we have moved from the desktop to the client-server architecture, then to the 3-link design, to the n-link, to the service oriented. During this process, many things changed, but many habits remained. Often, resistance to change comes from habits. However, in many cases it is procedural. This article describes what we are doing wrong and possible solutions.
What I will describe here is one of the methods for constructing n-link systems in terms of design and architecture. This article does not focus on code. There are many methods for constructing n-link systems; this is only one of them. If you are building a system, I hope you find good advice, a technique or a template for using this approach.
Although this article may offer several starting points from “standard methods”, everything in this article is based on Microsoft Templates and Methods and is described in Designing Data Tier Components and Passing Data through Tiers and other documents.
Even if you do not dare to apply all the methodologies proposed here, you should use at least some of them.
Ask any developer where the business logic should be, and get the answer: “Of course in the business layer.”
Ask the same developer where the business logic is in their organization, and again hear: “Of course in the business layer.”
You should not have the slightest doubt about where the business logic should be - in the business layer. Not part of business logic - all business logic should be in the business layer. After reading this article, many developers will understand that what they considered the truth about their systems is not.
These terms are often used together, but in this article I will use them as I describe here.
When I use the word link, I mean a physical link consisting of a physical server or a group of servers that perform the same function and are grouped only to increase capacity.
When I use the word layer, I mean a segment of the system that is limited to its own process or module. Many layers can be contained in one link, but any of them should be able to be easily transferred to another link.
On desktop applications, business logic is contained on the same link with all other layers. Because there is no need to separate the layers, they are often mixed and do not have clear boundaries.

There are two links in the client-server application, which leads to the creation of at least two layers. At the initial stage, the server was considered only as a remote database, and the division was as in the figure - the application on the client and the data on the server. Typically, all business logic was on the client, mixed with other layers, such as the user interface.

Quickly enough, it became clear that you can reduce the load on the network and centralize the logic to reduce fixed deployment costs by transferring most of the business logic to the server. Architecturally, the server was a well-prepared place in the client-server system, but the database as a platform provided few opportunities. Databases were designed for storage and issuance and their architecture did not include the possibility of expansion in the direction of business logic. Database stored procedure languages were developed for basic data transformations to support what SQL was missing. Stored procedure languages were developed for fast execution, and not for servicing complex business logic tasks.
But of the two evils, this was the lesser, and part of the business logic moved to stored procedures. In fact, I bet that business logic was shrunk and driven into stored procedures, exclusively from a pragmatic point of view. In the two links of the world - it was not ideal, but still much better.

When the problem of client-server architecture became apparent, the popularity of the 3-tier approach increased. The biggest and worst problem of the time was the number of connections. Now many databases can handle thousands of one-time connections; in the nineties, most databases fell somewhere around 500 connections. Servers are often licensed by the number of client connections. This all led to the fact that it was necessary to reduce the number of connections to the database.
Pooling connections has become popular, however, to implement a connection pool in a system with many separate clients, it is necessary to implement a third link between the client and the server. The middle link was called the "middle link". In most cases, the middle link existed only for managing the connection pool, but in some cases, business logic began to move to the middle link because the development languages (C ++, VB, Delphi, Java) were much better suited to implement business logic than the stored procedure languages. It soon became apparent that the middle link was the best place for business logic.
Also, the middle link provided the opportunity to connect clients with low speeds, as Direct connection to the database usually requires a wide channel and low latency.
Before I continue, let's clearly define: what is business logic. Making presentations at conferences and inside the company, I began to fear that not everyone agrees with what business logic is, and quite often they don’t even fully understand what it is and what not.
The database server is the storage tier. Databases are designed to store, retrieve and update data with the highest possible efficiency. Functionality is often a control system (Create, Delete, Get, Update). Some databases are a SUPOM, but the conversation is not about that.
Databases are designed to serve these operations very quickly. They are not designed to format phone numbers, calculate optimal usage and peak loads, determine geographic location and cargo routes, and so on. Although, I saw all of this and much more complex tasks, implemented only with help or with a large part on stored procedures.
And all this applies not only to complex things. Let's imagine a simple task and one that is often not even related to business logic. The task is to remove the buyer. In almost all systems that I saw, the removal of the buyer is handled exclusively by the stored procedure. However, in the removal of the buyer quite a few decisions must be made at the level of business logic. Can I remove a buyer? What processes should be started before and after? What precautions should be followed? From which tables should records be deleted or updated later?
The database should not care what the buyer is, it should only care about the elements used to store the buyer. The database should not be able to figure out which tables the buyer should store, and it should work with the tables without paying attention to the buyer. The task of the database is to store the rows in tables that describe the customer. In addition to basic restrictions such as cascading integrity, data types, indexes, and empty values, the database should not have functional knowledge about what a customer is in the business layer.
Stored procedures, if any, should operate on only one table; an exception is procedures that request a selection from several tables to produce data. In this case, stored procedures work as views. Views and stored procedures should be used to consolidate values, but exclusively for faster and more efficient work with data in the business layer.
But even in companies proud of the latest advances in development and technology, and in those that scream about their business logic in the business layer with foam at their mouths, a short analysis of the database quickly reveals: remove the buyer, add the buyer, block the buyer, freeze the buyer etc. etc. And not only with the buyer, but also with many other objects of business logic.
I often met stored procedures like this: Regularly part of the business logic moves to the business layer. In this case, part of the business logic was moved, but not all. Some tables are also processed in the business logic layer. The database should not have the slightest idea about which tables form the customer in the business layer. For all three operations, the business layer must issue an SQL command or call three separate stored procedures to implement the functionality in the given sp_DeleteCustomer. Having passed all the business logic to the business layer, we get:
Deleting rows can use a stored procedure if they are from the same table. However, in modern databases using query caching, this is a minor performance improvement. In addition, the SQL generated by such systems is very simple, because It works with one table, and therefore practically does not require optimization. In fact, the database does not get very well from too many loaded stored procedures, and simple SQL commands do not work on them that way.
Transferring even the modification of tables to the business layer, we will get the following advantages:
Since this method requires three successful accesses to the database instead of one, your business logic node must be connected to the database via a separate high-speed segment, such as gigabit. Sending 300 bytes instead of 100 bytes will become unprincipled. Most databases support batch transfer of SQL queries, and all three queries can be sent in one batch, reducing network load. To issue such requests, you should use the data access layer, and not include requests directly in the code.
Some database administrators and even developers may not accept this level of integration and insist on implementing such batch updates in stored procedures. This is the choice you have to make, and it is very dependent on your database and your priorities. Because almost all modern databases use query caching mechanisms, performance gains in most cases are minimal, and there are clear technological reasons for not loading the stored procedures with logic. If you choose to leave such batch updates in stored procedures, you must be very careful not to allow other business logic to slip into stored procedures, and restrict your stored procedures to LOS operations without any conditional operations or other business logic.
Let's look at another example that I discovered and sowing the seeds of war among developers - is this business logic or not. I will explain why I consider this a business logic, and not a user interface or storage. This example does not apply to easily implemented formatting. An example that I will use is telephone numbers.
Each country has its own format for displaying telephone numbers in a pleasant manner. In some countries there are even more than one. Below are a few examples:
Cyprus:
+357 (25) 66 00 34
+357 (25) 660 034
+357 25 660 034
+357 2566 0034
Germany:
+49 211 123456
+49 211 1234-0
North America (USA, Canada)
+ 1 (423) 235-2423
+ 1-423-235-2423
Russia:
+7 (812) 438-46-02
+7 (812) 438-4602
In Germany there is even a special official standard for formatting - DIN 5008.
Of course, the country code is discarded when used locally . But let's assume that you have an international system and you need to store and display the country code. For each country, we will choose one display format.
We agree to format the phones as follows:
Usually the following is done, all non-digital characters are removed and the number becomes similar to:
Phone: 35725660034
Sometimes the country code is separated and the number becomes like this:
PhoneCountry: 357
PhoneLocal: 25660034
It seems simple, but this is another task for business logic. Not all countries have the same length code. Country codes can be from 1 to 3 characters.
Often, input processing (if the country code is separated) and display logic are implemented on the client, as the client is written in a traditional language that is well suited for this. The problem is that the client needs a huge amount of data to determine the length of the country codes, and the client will need to be updated every time the display format has changed.
Sometimes formatting is done in a stored procedure. The problem with this approach is that the languages of stored procedures are not adapted for this type of logic, and it often leads to bugs and brakes in working with real logic.
More often, phone numbers are stored twice. Once in its pure form for good indexing and search, and the second in formatted for display. In addition to the problems described above, we get problems of redundant records and updates.
Particularly sophisticated extremes, which are ridiculously common, have a telephone number stored in the format in which it was received. The problem is obvious: phones cannot be quickly found, indexed or sorted.
The important thing is that although this is formatting, it does not apply to the user interface, and an attempt to total centralization can shoot down the database. This is clearly a business logic. The implementation of formatting in the business layer will not allow duplication of data and will be written in the development language, and not driven into the data processing language.
Some batch updates are many times faster when implemented using stored procedures. In most cases, simple SQL can be dispensed with, but some types of batch updates require cycles and, when implemented in the business layer, they will create thousands of SQL commands. In such rare cases, a stored procedure must be used, even if business logic needs to be implemented in it. It is necessary to pay special attention to ensuring that only the necessary minimum is implemented in it.
I will return in this article to this problem.
In client-server applications, business logic is usually available on both the client and server.
The real ratio will vary from application to company, the previous example describes client-server applications well. Most of the business logic was implemented in stored procedures and views in an attempt to centralize business logic. However, many business rules cannot be implemented simply in SQL or stored procedures, or they can be executed faster on the client, as they are based on the user interface. Due to these opposing factors, business logic is distributed between the client and server.
For many reasons, which I will describe later in a separate article, when building n-link systems, the situation only gets worse in terms of consolidating business logic. Instead of consolidation, business logic becomes even more fragmented.
Of course, each system has differences in how business logic is distributed across layers, but there is one thing in common for everyone. Business logic is now distributed in three layers instead of two. Next I will introduce some typical scenarios.
Typical distribution of business logic across an n-tier system:

In such cases, the business layer does not contain business rules. This is not a real business layer, but only an XML (or other streaming format) formatter and database dataset adapter. Although some advantages such as: connection pooling and database isolation can be achieved, this is not a real layer of business logic. It is rather a foreign physical layer without a logic layer.
Another typical scenario:

Usually, some business application rules go into the business layer, but what was in the database remains the same for the most part.
When reusing the business layer in such developments, business rules must be repeated in the client application. This negates the main goal of introducing the business layer.
Also, client applications have the opportunity not to comply with business rules without implementing them or simply ignoring them. With a real business layer, this is not possible.
Instead of all of the above, the business layer should contain all the business rules.

Such a development has the following advantages:
The above scenario is the goal. However, some duplication, especially for data verification, should be on the client. These rules must be supported by the business layer. In addition, on some systems, individual high-capacity operations, such as batch updates, can lead to exceptions and must be placed in the database. Therefore, a more realistic approach is presented below. Please note that all business logic must be implemented in the business layer, and those minimal sets that are present in other layers are just duplicates solely to improve performance or disable certain user interface components.

When switching to the central node, there is always the art of “implementing this part in a stored procedure”. Then “that” and “this one”. And soon you will find yourself in the same situation as you were, without significant changes.
Stored procedures should be used to execute SQL and retrieve datasets in databases that optimize stored procedures better than representations. But stored procedures should not be used for anything other than combining and issuing data. When updating data, it should precisely and only update, but not interpret the data in any way.
There are tasks where, in order to improve performance, some components must be placed in a stored procedure. But such tasks are actually quite rare and they should be the exception, not the rule. Each exception should be checked and approved, and not just implemented at the will of the developer or database administrator.
It sounds a little strange that buying iron can make it cheaper. But when implementing mid-level servers, virtually no additional software, except for the OS, is required. And the cost of increasing the capacity of the database server is significant for the following reasons:
When transferring logic to the middle link, you can significantly reduce the load on the database and prevent premature increase in its capacity.
In addition to cost, mid-level upgrade is usually simpler than database upgrade.
Databases have an inherent limit on how much they can be increased by simply adding iron. At some point, you need to start using other technologies like dividing, clustering, replication, etc. But none of these technologies is simple, and all require significant investments in hardware, migration, and strongly affect existing systems.
Building mid-level servers is much easier. As soon as the load balancing mechanism is launched, it all comes down to the task of adding a new server.
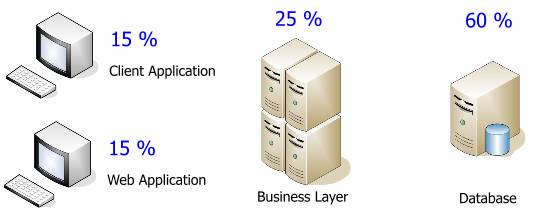
Let's look at the statements I just made using the following diagram. The fill in the segments shows the direction or importance of their name in relation to the links in the diagram. The unit price rises as we move from the client, to the middle link, to the database. I use the word unit to denote a processor or server, depending on the configuration.
(top to bottom: unit price, average bandwidth, deployment complexity, quantity)
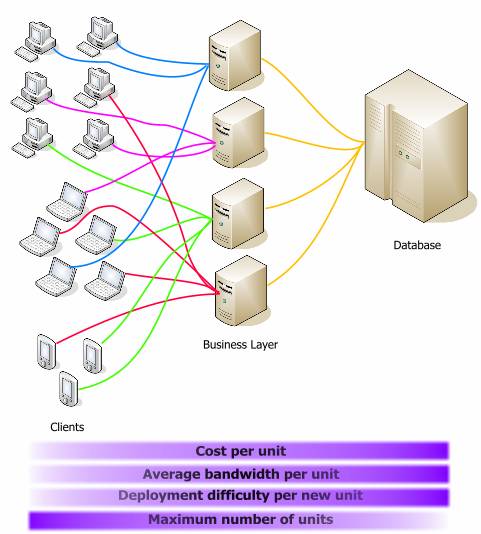
If you bring the same data in relative values, you can easily compare them:
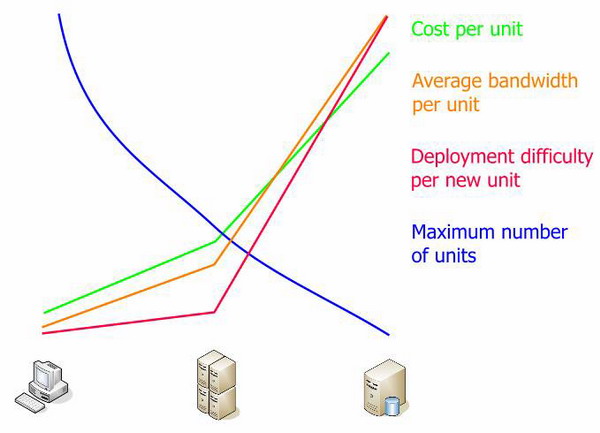
I did not cite the numbers on the graphs because they are very dependent on the network configuration, processor power, and other factors unique to each organization. Each function uses its own units. I presented only the general relationship of dimensions. It shows well that the middle link has capacity for growth and is much cheaper than the database.
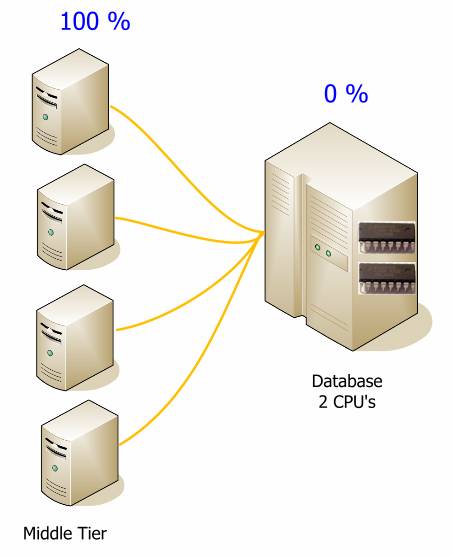
If most of the business logic is implemented in a database, you will need a more powerful database.

When transferring logic to the middle link, you can seriously reduce the load on the database. The numbers presented here are for demonstration purposes only and will vary from system to system, but they can help to catch the idea. Although there is more hardware in the following diagram, the total cost of the system will be less, and it will be easier to deploy. It is much cheaper and easier to increase the middle link.
Let's look again at one of the previous graphs:
What is the only bottleneck in the system? Which of the links has a pronounced growth limit? This is definitely a database. Everything rests against the database.

Therefore, moving calculations to the middle link, we can move away from the boundaries of the data layer.
There are several difficulties for moving to the middle link, and not all of them are that you need to program differently.
There is a saying: "it is difficult to get rid of old habits." This also applies to the team. As a team, you need to convince not only yourself, but most of the team.
Many companies have well-established security policies that require security in the database, and using stored procedures as views does not provide sufficient control. Changing corporate security policies to move to the n-tier world can be very difficult, if not impossible.
In .Net, security, like in new Microsoft technologies, is focused on mid-level corporate security as never before, but many companies still rely on databases and either do not care about changes or do not want to change.
This is a risky statement. So risky that there is something else to be said. If you are a database administrator or developer, please do not take what I want to say as a stereotype or the truth about all database administrators. However, this prevails and is common. If you are a DBA who does not fall under this description - bravo! You are the president of databases, not the lord of databases.
Database administrators with a running system often resist making any significant changes because they can break their system. Many organizations have one administrator and many assistants. The database administrator is the king in his fiefdom and has the last word in everything related to the database. And only management will try to get the better of the administrator, so immediately management incompetent in database problems surrenders to the administrator.
Many DBAs have very little knowledge about why changes are needed in the direction of n-tier architecture, or they just don't care. For them, any link is just another client, and all for them is client-server architecture. They only care about the database and go to a deal with the developers only if it does not cause them any trouble.
Database administrators do not migrate to companies as often as developers, and many of them have been managing the corporate database for the past 10 or even 20 years. The database is a very important thing for them, and they do not want to make any transactions. They built their kingdom and do not want to lose control. To force such an administrator to give back part of security and implementation is possible only in a serious battle and with the support of management.
Other administrators are not so demanding and will go to meet everything that they consider reasonable. But in many organizations, especially large ones, there are hundreds of developers and only one or a couple of database administrators, and database administrators sit at the top of the corporate command chain.
Most of the tools available today are unstable or do not provide tools for implementing business logic. Many tools focus solely on scalability, connection pooling and database isolation, and are not aimed at fulfilling the needs of business logic.
I have found great benefit in a regular audit of the system architecture, in which the incorrect placement of business logic is noted. The sooner they are discovered, the easier and cheaper it is to fix them. If you do not have a special chief architect, then the developers from the team can check each other. If something is found in the wrong place, the developer can notify the team and the team leader.
It is very useful to train database administrator assistants. Administrators have been implementing business logic for so long that it’s hard for them to determine: where is the business logic and where is the storage. Assistants usually do only what is required of them, usually following the instructions of the administrator.
Anyway, the process will affect the assistants. They write queries, optimize them, and maintain the database. They should also monitor the SQL coming from the middle link and the database performance. Assistants will also continue to design the database architecture.
Management resistance is often encountered, although this is more likely a simple obstacle than a complex one. The management doesn’t give a damn whether your work has become easier, but they care about overhead, development time, business benefits, and it would be nice to tell them about the current losses.
The main obstacle to change management will be the resistance of the database administrator. So, hand over the management with giblets and let them deal with the administrator themselves.
The basis of this article was the templates and methods that I have been using for almost ten years. Of course, they are constantly reviewed and updated in order to take advantage of new technologies and be adapted to changes in the world.
During my work, I read a lot of material written by "experts." Most of them were written by developers who are good at creating theories and teaching others how to do things, but never put their own methods into practice. Others were written by experienced developers with a narrow horizons, and this knowledge is very dependent on the specific application. When developers read such materials, they become convinced that there is only one way to solve the problem. Developers need to think more broadly and understand that the described solution to the problem is only a direction, not a doctrine.
I am talking about this only because it is very rare to find something really worthwhile and not fall into these traps. One of the best materials that I read over the years has been written in August 2002 and these are Microsoft templates and techniques. They are very well written and consistent with what I have described here and in my other articles.
Please pay attention to Designing data tier components and passing data through tiers.
Changing direction in large companies is a matter of politically and high risk. From the developer's point of view, it’s easier to go to the bottom and let others nibble each other. I doubt that many developers will say no to their proven techniques. In this article, I want to give you some ideas for reorganizing your existing processes, or at least look at some solutions that were not usually considered, more closely.
The described approach is best for building new systems, or when changing all or part of the system. On working systems, it’s better not to touch anything until some circumstance forces you to do the rebuilding.
UPD: at the prompt of maovrn moved to "Design and refactoring".
UPD1:
For those who are in the tank:
1. On Habré there are rules for processing transfers; see help
2. For those who can’t master item 1. The author of the article is Chad Z. Hower aka Kudzu
3. For those who read only the middle without beginning and end, the article is three years old . Therefore, at least it is incorrect to declare the author of an article illiterate on the basis of what he did not read at the time of publication of materials released after publication.
4. If this update touches you - these are your problems.
Special thanks to the author for allowing a separate publication.
An extremely entertaining article on what business logic is and where it lives. The article, by the way, is already three years old. And I often come across systems where the code is not separated from the data. May lead to real holivar.
Where is our business logic, son?
Introduction
Over the years of development, we have moved from the desktop to the client-server architecture, then to the 3-link design, to the n-link, to the service oriented. During this process, many things changed, but many habits remained. Often, resistance to change comes from habits. However, in many cases it is procedural. This article describes what we are doing wrong and possible solutions.
About article
What I will describe here is one of the methods for constructing n-link systems in terms of design and architecture. This article does not focus on code. There are many methods for constructing n-link systems; this is only one of them. If you are building a system, I hope you find good advice, a technique or a template for using this approach.
Although this article may offer several starting points from “standard methods”, everything in this article is based on Microsoft Templates and Methods and is described in Designing Data Tier Components and Passing Data through Tiers and other documents.
Even if you do not dare to apply all the methodologies proposed here, you should use at least some of them.
goal
Ask any developer where the business logic should be, and get the answer: “Of course in the business layer.”
Ask the same developer where the business logic is in their organization, and again hear: “Of course in the business layer.”
You should not have the slightest doubt about where the business logic should be - in the business layer. Not part of business logic - all business logic should be in the business layer. After reading this article, many developers will understand that what they considered the truth about their systems is not.
Terms
These terms are often used together, but in this article I will use them as I describe here.
Link (tier)
When I use the word link, I mean a physical link consisting of a physical server or a group of servers that perform the same function and are grouped only to increase capacity.
Layer
When I use the word layer, I mean a segment of the system that is limited to its own process or module. Many layers can be contained in one link, but any of them should be able to be easily transferred to another link.
Problem development
Desktop
On desktop applications, business logic is contained on the same link with all other layers. Because there is no need to separate the layers, they are often mixed and do not have clear boundaries.
Client server
There are two links in the client-server application, which leads to the creation of at least two layers. At the initial stage, the server was considered only as a remote database, and the division was as in the figure - the application on the client and the data on the server. Typically, all business logic was on the client, mixed with other layers, such as the user interface.
Quickly enough, it became clear that you can reduce the load on the network and centralize the logic to reduce fixed deployment costs by transferring most of the business logic to the server. Architecturally, the server was a well-prepared place in the client-server system, but the database as a platform provided few opportunities. Databases were designed for storage and issuance and their architecture did not include the possibility of expansion in the direction of business logic. Database stored procedure languages were developed for basic data transformations to support what SQL was missing. Stored procedure languages were developed for fast execution, and not for servicing complex business logic tasks.
But of the two evils, this was the lesser, and part of the business logic moved to stored procedures. In fact, I bet that business logic was shrunk and driven into stored procedures, exclusively from a pragmatic point of view. In the two links of the world - it was not ideal, but still much better.
3-link
When the problem of client-server architecture became apparent, the popularity of the 3-tier approach increased. The biggest and worst problem of the time was the number of connections. Now many databases can handle thousands of one-time connections; in the nineties, most databases fell somewhere around 500 connections. Servers are often licensed by the number of client connections. This all led to the fact that it was necessary to reduce the number of connections to the database.
Pooling connections has become popular, however, to implement a connection pool in a system with many separate clients, it is necessary to implement a third link between the client and the server. The middle link was called the "middle link". In most cases, the middle link existed only for managing the connection pool, but in some cases, business logic began to move to the middle link because the development languages (C ++, VB, Delphi, Java) were much better suited to implement business logic than the stored procedure languages. It soon became apparent that the middle link was the best place for business logic.
Also, the middle link provided the opportunity to connect clients with low speeds, as Direct connection to the database usually requires a wide channel and low latency.
What is business logic?
Before I continue, let's clearly define: what is business logic. Making presentations at conferences and inside the company, I began to fear that not everyone agrees with what business logic is, and quite often they don’t even fully understand what it is and what not.
The database server is the storage tier. Databases are designed to store, retrieve and update data with the highest possible efficiency. Functionality is often a control system (Create, Delete, Get, Update). Some databases are a SUPOM, but the conversation is not about that.
Databases are designed to serve these operations very quickly. They are not designed to format phone numbers, calculate optimal usage and peak loads, determine geographic location and cargo routes, and so on. Although, I saw all of this and much more complex tasks, implemented only with help or with a large part on stored procedures.
Remove Buyer
And all this applies not only to complex things. Let's imagine a simple task and one that is often not even related to business logic. The task is to remove the buyer. In almost all systems that I saw, the removal of the buyer is handled exclusively by the stored procedure. However, in the removal of the buyer quite a few decisions must be made at the level of business logic. Can I remove a buyer? What processes should be started before and after? What precautions should be followed? From which tables should records be deleted or updated later?
The database should not care what the buyer is, it should only care about the elements used to store the buyer. The database should not be able to figure out which tables the buyer should store, and it should work with the tables without paying attention to the buyer. The task of the database is to store the rows in tables that describe the customer. In addition to basic restrictions such as cascading integrity, data types, indexes, and empty values, the database should not have functional knowledge about what a customer is in the business layer.
Stored procedures, if any, should operate on only one table; an exception is procedures that request a selection from several tables to produce data. In this case, stored procedures work as views. Views and stored procedures should be used to consolidate values, but exclusively for faster and more efficient work with data in the business layer.
But even in companies proud of the latest advances in development and technology, and in those that scream about their business logic in the business layer with foam at their mouths, a short analysis of the database quickly reveals: remove the buyer, add the buyer, block the buyer, freeze the buyer etc. etc. And not only with the buyer, but also with many other objects of business logic.
I often met stored procedures like this: Regularly part of the business logic moves to the business layer. In this case, part of the business logic was moved, but not all. Some tables are also processed in the business logic layer. The database should not have the slightest idea about which tables form the customer in the business layer. For all three operations, the business layer must issue an SQL command or call three separate stored procedures to implement the functionality in the given sp_DeleteCustomer. Having passed all the business logic to the business layer, we get:
sp_DeleteCustomer(x)
Select row in customer table, is Locked field
If true then throw error
Sum total of customer billing table
If balance > 0 then throw error
Delete rows in customer billing table (A detail table)
if Customer table Created field older than one year then
Insert row in survey table
Delete row in customer table
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
sp_DeleteCustomer(x)
Delete rows in customer billing table (A detail table)
Delete row in customer table
Business Layer (C#, etc)
Select row in customer table, is Locked field
If true then throw error.
Sum total of customer billing table
If balance > 0 then throw error.
if Customer table Created field older than one year then
Insert row in survey table
Call sp_DeleteCustomer
Delete rows in customer billing table (A detail table)
Delete row in customer table
Deleting rows can use a stored procedure if they are from the same table. However, in modern databases using query caching, this is a minor performance improvement. In addition, the SQL generated by such systems is very simple, because It works with one table, and therefore practically does not require optimization. In fact, the database does not get very well from too many loaded stored procedures, and simple SQL commands do not work on them that way.
Transferring even the modification of tables to the business layer, we will get the following advantages:
- Migrating a database can be done with less effort, as all these stored procedures do not need to be debugged for each DBMS.
- Modification is easier because all logic is contained in one layer, and not in two.
- Debugging is easier - the logic is not spread over two layers.
- Other logic will not be able to slip into the stored procedure just because “it’s easier”.
Since this method requires three successful accesses to the database instead of one, your business logic node must be connected to the database via a separate high-speed segment, such as gigabit. Sending 300 bytes instead of 100 bytes will become unprincipled. Most databases support batch transfer of SQL queries, and all three queries can be sent in one batch, reducing network load. To issue such requests, you should use the data access layer, and not include requests directly in the code.
Some database administrators and even developers may not accept this level of integration and insist on implementing such batch updates in stored procedures. This is the choice you have to make, and it is very dependent on your database and your priorities. Because almost all modern databases use query caching mechanisms, performance gains in most cases are minimal, and there are clear technological reasons for not loading the stored procedures with logic. If you choose to leave such batch updates in stored procedures, you must be very careful not to allow other business logic to slip into stored procedures, and restrict your stored procedures to LOS operations without any conditional operations or other business logic.
Formatting
Let's look at another example that I discovered and sowing the seeds of war among developers - is this business logic or not. I will explain why I consider this a business logic, and not a user interface or storage. This example does not apply to easily implemented formatting. An example that I will use is telephone numbers.
Each country has its own format for displaying telephone numbers in a pleasant manner. In some countries there are even more than one. Below are a few examples:
Cyprus:
+357 (25) 66 00 34
+357 (25) 660 034
+357 25 660 034
+357 2566 0034
Germany:
+49 211 123456
+49 211 1234-0
North America (USA, Canada)
+ 1 (423) 235-2423
+ 1-423-235-2423
Russia:
+7 (812) 438-46-02
+7 (812) 438-4602
In Germany there is even a special official standard for formatting - DIN 5008.
Of course, the country code is discarded when used locally . But let's assume that you have an international system and you need to store and display the country code. For each country, we will choose one display format.
We agree to format the phones as follows:
- Data comes in a variety of formats.
- Each country has its own unique way to display phones.
- The formats of some countries are not simple and vary depending on the first digits.
- The first few digits (usually the country and region code) do not always have a fixed length. For example, in Russia, 812 is the city code of St. Petersburg, 495 is Moscow, but some regions have 4 characters (3952). This leads to a change in the overall length and format, depending on the regional code.
- With the advent of new laws, the emergence of new operators, the integration of the European Union, updating telephone systems and much more, the formats and lengths of phones change quite often on a global scale. Recently, Cyprus has changed its country code twice: once during a system update, a second time due to the increased number of mobile operators. With hundreds of countries around the world, changes are expected on a regular basis.
Usually the following is done, all non-digital characters are removed and the number becomes similar to:
Phone: 35725660034
Sometimes the country code is separated and the number becomes like this:
PhoneCountry: 357
PhoneLocal: 25660034
It seems simple, but this is another task for business logic. Not all countries have the same length code. Country codes can be from 1 to 3 characters.
Often, input processing (if the country code is separated) and display logic are implemented on the client, as the client is written in a traditional language that is well suited for this. The problem is that the client needs a huge amount of data to determine the length of the country codes, and the client will need to be updated every time the display format has changed.
Sometimes formatting is done in a stored procedure. The problem with this approach is that the languages of stored procedures are not adapted for this type of logic, and it often leads to bugs and brakes in working with real logic.
More often, phone numbers are stored twice. Once in its pure form for good indexing and search, and the second in formatted for display. In addition to the problems described above, we get problems of redundant records and updates.
Particularly sophisticated extremes, which are ridiculously common, have a telephone number stored in the format in which it was received. The problem is obvious: phones cannot be quickly found, indexed or sorted.
The important thing is that although this is formatting, it does not apply to the user interface, and an attempt to total centralization can shoot down the database. This is clearly a business logic. The implementation of formatting in the business layer will not allow duplication of data and will be written in the development language, and not driven into the data processing language.
Exceptions
Some batch updates are many times faster when implemented using stored procedures. In most cases, simple SQL can be dispensed with, but some types of batch updates require cycles and, when implemented in the business layer, they will create thousands of SQL commands. In such rare cases, a stored procedure must be used, even if business logic needs to be implemented in it. It is necessary to pay special attention to ensuring that only the necessary minimum is implemented in it.
I will return in this article to this problem.
Today's systems
Client server
In client-server applications, business logic is usually available on both the client and server.
The real ratio will vary from application to company, the previous example describes client-server applications well. Most of the business logic was implemented in stored procedures and views in an attempt to centralize business logic. However, many business rules cannot be implemented simply in SQL or stored procedures, or they can be executed faster on the client, as they are based on the user interface. Due to these opposing factors, business logic is distributed between the client and server.
N-link
For many reasons, which I will describe later in a separate article, when building n-link systems, the situation only gets worse in terms of consolidating business logic. Instead of consolidation, business logic becomes even more fragmented.
Of course, each system has differences in how business logic is distributed across layers, but there is one thing in common for everyone. Business logic is now distributed in three layers instead of two. Next I will introduce some typical scenarios.
Scenario 1
Typical distribution of business logic across an n-tier system:
In such cases, the business layer does not contain business rules. This is not a real business layer, but only an XML (or other streaming format) formatter and database dataset adapter. Although some advantages such as: connection pooling and database isolation can be achieved, this is not a real layer of business logic. It is rather a foreign physical layer without a logic layer.
Scenario 2
Another typical scenario:
Usually, some business application rules go into the business layer, but what was in the database remains the same for the most part.
When reusing the business layer in such developments, business rules must be repeated in the client application. This negates the main goal of introducing the business layer.
Also, client applications have the opportunity not to comply with business rules without implementing them or simply ignoring them. With a real business layer, this is not possible.
Consolidation
Instead of all of the above, the business layer should contain all the business rules.
Such a development has the following advantages:
- All business logic is in one place and can be easily verified, debugged and changed.
- Нормальный язык разработки может быть использован для реализации бизнес правил. Такие языки более гибкие и более подходят для бизнес правил, чем SQL и хранимые процедуры.
- База данных становится слоем хранения и может заниматься эффективным получением и хранением данных без ограничений относящихся к слою бизнес логики или представления.
The above scenario is the goal. However, some duplication, especially for data verification, should be on the client. These rules must be supported by the business layer. In addition, on some systems, individual high-capacity operations, such as batch updates, can lead to exceptions and must be placed in the database. Therefore, a more realistic approach is presented below. Please note that all business logic must be implemented in the business layer, and those minimal sets that are present in other layers are just duplicates solely to improve performance or disable certain user interface components.
Moving to the central hub
Slippery slope
When switching to the central node, there is always the art of “implementing this part in a stored procedure”. Then “that” and “this one”. And soon you will find yourself in the same situation as you were, without significant changes.
Stored procedures should be used to execute SQL and retrieve datasets in databases that optimize stored procedures better than representations. But stored procedures should not be used for anything other than combining and issuing data. When updating data, it should precisely and only update, but not interpret the data in any way.
There are tasks where, in order to improve performance, some components must be placed in a stored procedure. But such tasks are actually quite rare and they should be the exception, not the rule. Each exception should be checked and approved, and not just implemented at the will of the developer or database administrator.
Cheaper
It sounds a little strange that buying iron can make it cheaper. But when implementing mid-level servers, virtually no additional software, except for the OS, is required. And the cost of increasing the capacity of the database server is significant for the following reasons:
- Database servers, as a rule, are of a higher class than mid-level servers, and are more expensive.
- Databases are often licensed by the processor and adding a processor is an expensive procedure in terms of licenses. License fees can range from $ 5,000 to $ 40,000 per processor.
When transferring logic to the middle link, you can significantly reduce the load on the database and prevent premature increase in its capacity.
Easier
In addition to cost, mid-level upgrade is usually simpler than database upgrade.
Databases have an inherent limit on how much they can be increased by simply adding iron. At some point, you need to start using other technologies like dividing, clustering, replication, etc. But none of these technologies is simple, and all require significant investments in hardware, migration, and strongly affect existing systems.
Building mid-level servers is much easier. As soon as the load balancing mechanism is launched, it all comes down to the task of adding a new server.
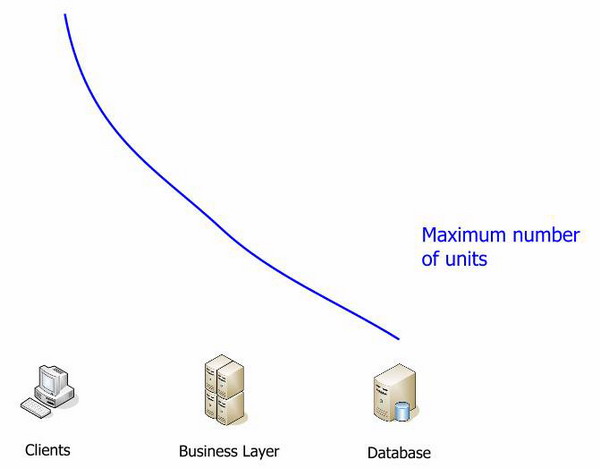
Topology
Let's look at the statements I just made using the following diagram. The fill in the segments shows the direction or importance of their name in relation to the links in the diagram. The unit price rises as we move from the client, to the middle link, to the database. I use the word unit to denote a processor or server, depending on the configuration.
(top to bottom: unit price, average bandwidth, deployment complexity, quantity)
If you bring the same data in relative values, you can easily compare them:
I did not cite the numbers on the graphs because they are very dependent on the network configuration, processor power, and other factors unique to each organization. Each function uses its own units. I presented only the general relationship of dimensions. It shows well that the middle link has capacity for growth and is much cheaper than the database.
Grow the middle
If most of the business logic is implemented in a database, you will need a more powerful database.
When transferring logic to the middle link, you can seriously reduce the load on the database. The numbers presented here are for demonstration purposes only and will vary from system to system, but they can help to catch the idea. Although there is more hardware in the following diagram, the total cost of the system will be less, and it will be easier to deploy. It is much cheaper and easier to increase the middle link.
Bottleneck
Let's look again at one of the previous graphs:
What is the only bottleneck in the system? Which of the links has a pronounced growth limit? This is definitely a database. Everything rests against the database.
Therefore, moving calculations to the middle link, we can move away from the boundaries of the data layer.
Difficulties
There are several difficulties for moving to the middle link, and not all of them are that you need to program differently.
Habits
There is a saying: "it is difficult to get rid of old habits." This also applies to the team. As a team, you need to convince not only yourself, but most of the team.
Procedures
Many companies have well-established security policies that require security in the database, and using stored procedures as views does not provide sufficient control. Changing corporate security policies to move to the n-tier world can be very difficult, if not impossible.
In .Net, security, like in new Microsoft technologies, is focused on mid-level corporate security as never before, but many companies still rely on databases and either do not care about changes or do not want to change.
Database administrators
This is a risky statement. So risky that there is something else to be said. If you are a database administrator or developer, please do not take what I want to say as a stereotype or the truth about all database administrators. However, this prevails and is common. If you are a DBA who does not fall under this description - bravo! You are the president of databases, not the lord of databases.
Database administrators with a running system often resist making any significant changes because they can break their system. Many organizations have one administrator and many assistants. The database administrator is the king in his fiefdom and has the last word in everything related to the database. And only management will try to get the better of the administrator, so immediately management incompetent in database problems surrenders to the administrator.
Many DBAs have very little knowledge about why changes are needed in the direction of n-tier architecture, or they just don't care. For them, any link is just another client, and all for them is client-server architecture. They only care about the database and go to a deal with the developers only if it does not cause them any trouble.
Database administrators do not migrate to companies as often as developers, and many of them have been managing the corporate database for the past 10 or even 20 years. The database is a very important thing for them, and they do not want to make any transactions. They built their kingdom and do not want to lose control. To force such an administrator to give back part of security and implementation is possible only in a serious battle and with the support of management.
Other administrators are not so demanding and will go to meet everything that they consider reasonable. But in many organizations, especially large ones, there are hundreds of developers and only one or a couple of database administrators, and database administrators sit at the top of the corporate command chain.
Tools
Most of the tools available today are unstable or do not provide tools for implementing business logic. Many tools focus solely on scalability, connection pooling and database isolation, and are not aimed at fulfilling the needs of business logic.
Solutions
Architecture
I have found great benefit in a regular audit of the system architecture, in which the incorrect placement of business logic is noted. The sooner they are discovered, the easier and cheaper it is to fix them. If you do not have a special chief architect, then the developers from the team can check each other. If something is found in the wrong place, the developer can notify the team and the team leader.
Assistant Training
It is very useful to train database administrator assistants. Administrators have been implementing business logic for so long that it’s hard for them to determine: where is the business logic and where is the storage. Assistants usually do only what is required of them, usually following the instructions of the administrator.
Anyway, the process will affect the assistants. They write queries, optimize them, and maintain the database. They should also monitor the SQL coming from the middle link and the database performance. Assistants will also continue to design the database architecture.
Manager training
Management resistance is often encountered, although this is more likely a simple obstacle than a complex one. The management doesn’t give a damn whether your work has become easier, but they care about overhead, development time, business benefits, and it would be nice to tell them about the current losses.
The main obstacle to change management will be the resistance of the database administrator. So, hand over the management with giblets and let them deal with the administrator themselves.
What else to read
The basis of this article was the templates and methods that I have been using for almost ten years. Of course, they are constantly reviewed and updated in order to take advantage of new technologies and be adapted to changes in the world.
During my work, I read a lot of material written by "experts." Most of them were written by developers who are good at creating theories and teaching others how to do things, but never put their own methods into practice. Others were written by experienced developers with a narrow horizons, and this knowledge is very dependent on the specific application. When developers read such materials, they become convinced that there is only one way to solve the problem. Developers need to think more broadly and understand that the described solution to the problem is only a direction, not a doctrine.
I am talking about this only because it is very rare to find something really worthwhile and not fall into these traps. One of the best materials that I read over the years has been written in August 2002 and these are Microsoft templates and techniques. They are very well written and consistent with what I have described here and in my other articles.
Please pay attention to Designing data tier components and passing data through tiers.
Conclusion
Changing direction in large companies is a matter of politically and high risk. From the developer's point of view, it’s easier to go to the bottom and let others nibble each other. I doubt that many developers will say no to their proven techniques. In this article, I want to give you some ideas for reorganizing your existing processes, or at least look at some solutions that were not usually considered, more closely.
The described approach is best for building new systems, or when changing all or part of the system. On working systems, it’s better not to touch anything until some circumstance forces you to do the rebuilding.
UPD: at the prompt of maovrn moved to "Design and refactoring".
UPD1:
For those who are in the tank:
1. On Habré there are rules for processing transfers; see help
2. For those who can’t master item 1. The author of the article is Chad Z. Hower aka Kudzu
3. For those who read only the middle without beginning and end, the article is three years old . Therefore, at least it is incorrect to declare the author of an article illiterate on the basis of what he did not read at the time of publication of materials released after publication.
4. If this update touches you - these are your problems.