How to recognize text from a photo: new features of the Vision framework
- Transfer
Now the Vision framework is able to recognize text for real, and not as before. We look forward to when we can apply this to Dodo IS. In the meantime, a translation of an article on recognizing cards from the board game Magic The Gathering and extracting textual information from them.
The Vision framework was first introduced to the general public at WWDC in 2017, along with iOS 11.
Vision was created to help developers classify and identify objects, horizontal planes, barcodes, facial expressions, and text.
However, there was a problem with text recognition: Vision could find the place where the text is, but the actual text recognition did not occur. Of course, it was nice to see the bounding box around individual text fragments, but then they had to be pulled out and recognized independently.
This problem was solved in the Vision update, which was included in iOS 13. Now the Vision framework provides true text recognition.
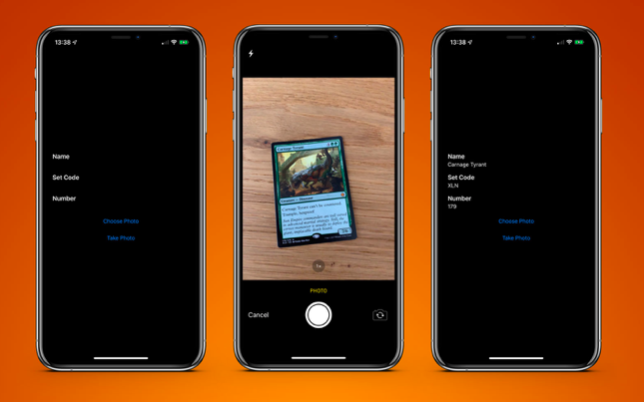
To test this, I created a very simple application that can recognize a card from the Magic The Gathering board game and extract text information from it:
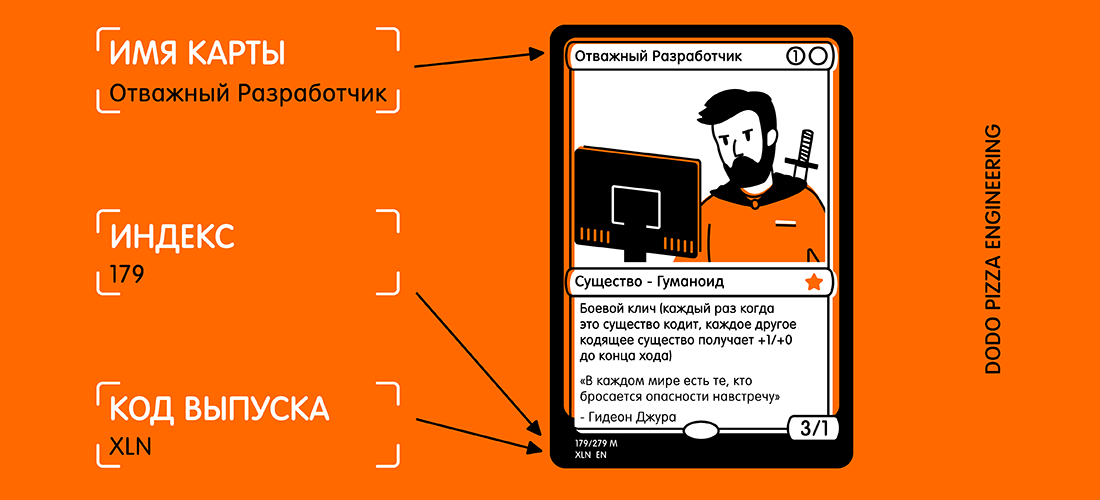
Here is an example of a map and selected text that I would like to receive.

Looking at the card, you might think: “This text is rather small, plus there are a lot of other text on the card that can interfere.” But for Vision, this is not a problem.
First we need to create
The completion block has the form
Two levels of recognition accuracy are available:
I limited recognition to British English, since all my cards are in it. You can specify several languages, but you need to understand that scanning and recognition may take a little longer for each additional language.
There are two more properties worth mentioning:
Now that we have our request, we must pass it along with the picture to the request handler:
I use the image directly from the camera, converting it from
As part of this demo, I use the phone only in portrait orientation. So naturally, I add orientation
It turns out that the orientation of the camera on your device is completely separate from the rotation of the device and is always considered to the left (as was default in 2009, that to take photos you need to keep the phone in landscape orientation). Of course, times have changed, and we basically shoot photos and videos in portrait format, but the camera is still aligned to the left.
As soon as our handler is configured, we go to the priority thread
Our handler returns our query, which now has the results property. Each result is
You can get up to 10 candidates for each unit of recognized text, and they are sorted in descending order of confidence. This can be useful if you have certain terminology that the parser incorrectly recognizes on the first try. But determines correctly later, even if he is less confident in the correctness of the result.
In this example, we only need the first result, so we loop through
That’s almost all you need. If I run a photo of the card through this, I get the following result in less than 0.5 seconds on the iPhone XS Max:
Even a very small copyright is mostly correct. All this was done on a 3024x4032 image weighing 3.1 MB. The process would be even faster if I first reduced the image. It is also worth noting that this process is much faster on the new A12 bionic chips, which have a special neural engine.
When the text is recognized, the last thing to do is pull out the information I need. I will not put all the code here, but the key logic is to iterate over each to
PS In fact, I only need a release code and a collection number (it's an index). Then they can be used in the Scryfall service API to get all the possible information about this map, including the rules of the game and the cost.
A sample application is available on GitHub .
The Vision framework was first introduced to the general public at WWDC in 2017, along with iOS 11.
Vision was created to help developers classify and identify objects, horizontal planes, barcodes, facial expressions, and text.
However, there was a problem with text recognition: Vision could find the place where the text is, but the actual text recognition did not occur. Of course, it was nice to see the bounding box around individual text fragments, but then they had to be pulled out and recognized independently.
This problem was solved in the Vision update, which was included in iOS 13. Now the Vision framework provides true text recognition.
To test this, I created a very simple application that can recognize a card from the Magic The Gathering board game and extract text information from it:
- card name;
- release code;
- collection number (aka index).
Here is an example of a map and selected text that I would like to receive.
Looking at the card, you might think: “This text is rather small, plus there are a lot of other text on the card that can interfere.” But for Vision, this is not a problem.
First we need to create
VNRecognizeTextRequest. In essence, this is a description of what we hope to recognize, plus a recognition language setting and level of accuracy:let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText)
request.recognitionLevel = .accurate
request.recognitionLanguages = ["en_GB"]The completion block has the form
handleDetectedText(request: VNRequest?, error: Error?). We pass it to the constructor VNRecognizeTextRequestand then set the remaining properties. Two levels of recognition accuracy are available:
.fastand .accurate. Since our card has a rather small text at the bottom, I chose a higher accuracy. The quicker option is probably better suited for large volumes of text. I limited recognition to British English, since all my cards are in it. You can specify several languages, but you need to understand that scanning and recognition may take a little longer for each additional language.
There are two more properties worth mentioning:
customWords: you can add an array of strings to be used on top of the built-in lexicon. This is useful if there are any unusual words in your text. I did not use the option for this project. But if I were to make the commercial Magic The Gathering card recognition application, I would add some of the most complex cards (for example, Fblthp, the Lost ) to avoid problems.minimumTextHeight: This is a float value. It indicates the size relative to the height of the image at which the text should no longer be recognized. If I created this scanner just to get the name of the map, it would be useful to delete all other text that is not needed. But I need the smallest pieces of text, so for now I have ignored this property. Obviously, if you ignore small texts, the recognition speed will be higher.
Now that we have our request, we must pass it along with the picture to the request handler:
let requests = [textDetectionRequest]
let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try imageRequestHandler.perform(requests)
} catchlet error {
print("Error: \(error)")
}
}I use the image directly from the camera, converting it from
UIImageto CGImage. This is used in VNImageRequestHandlerconjunction with the orientation flag to help the handler understand what text it should recognize. As part of this demo, I use the phone only in portrait orientation. So naturally, I add orientation
.right. So padaji! It turns out that the orientation of the camera on your device is completely separate from the rotation of the device and is always considered to the left (as was default in 2009, that to take photos you need to keep the phone in landscape orientation). Of course, times have changed, and we basically shoot photos and videos in portrait format, but the camera is still aligned to the left.
As soon as our handler is configured, we go to the priority thread
.userInitiatedand try to fulfill our requests. You may notice that this is an array of queries. This happens because you can try to pull out several pieces of data in one pass (i.e., identify faces and text from the same image). If there are no errors, the callback created using our request will be called after the text is detected:funchandleDetectedText(request: VNRequest?, error: Error?) {
iflet error = error {
print("ERROR: \(error)")
return
}
guardlet results = request?.results, results.count > 0else {
print("No text found")
return
}
for result in results {
iflet observation = result as? VNRecognizedTextObservation {
for text in observation.topCandidates(1) {
print(text.string)
print(text.confidence)
print(observation.boundingBox)
print("\n")
}
}
}
}Our handler returns our query, which now has the results property. Each result is
VNRecognizedTextObservationone for which we have several options for the result (hereinafter - the candidates). You can get up to 10 candidates for each unit of recognized text, and they are sorted in descending order of confidence. This can be useful if you have certain terminology that the parser incorrectly recognizes on the first try. But determines correctly later, even if he is less confident in the correctness of the result.
In this example, we only need the first result, so we loop through
observation.topCandidates(1)and extract both text and confidence. While the candidate himself has a different text and confidence, .boundingBoxremains the same..boundingBoxuses a normalized coordinate system with the origin in the lower left corner, therefore, if it will be used further in UIKit, for your convenience it needs to be transformed. That’s almost all you need. If I run a photo of the card through this, I get the following result in less than 0.5 seconds on the iPhone XS Max:
{kind=link}
Carnage Tyrant
1.0
(0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786)
Creature
1.0
(0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635)
Dinosaur
1.0
(0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364)
Carnage Tyrant can't be countered.
1.0
(0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906)
Trample, hexproof
0.5
(0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653)
Sun Empire commanders are well versed
1.0
(0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302)
in advanced martial strategy. Still, the
1.0
(0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136)
correct maneuver is usually to deploy the
1.0
(0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009)
giant, implacable death lizard.
1.0
(0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258)
7/6
0.5
(0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593)
179/279 M
1.0
(0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193)
XLN: EN N YEONG-HAO HAN
0.5
(0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319)
TN & 0 2017 Wizards of the Coast
1.0
(0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)This is unbelievable! Each piece of text was recognized, placed in its own bounding box, and returned as a result with a confidence rating of 1.0.
Even a very small copyright is mostly correct. All this was done on a 3024x4032 image weighing 3.1 MB. The process would be even faster if I first reduced the image. It is also worth noting that this process is much faster on the new A12 bionic chips, which have a special neural engine.
When the text is recognized, the last thing to do is pull out the information I need. I will not put all the code here, but the key logic is to iterate over each to
.boundingBoxdetermine the location, so that I can select the text in the lower left corner and in the upper left corner, ignoring anything further to the right.The end result is an application that scans a card and returns me the result in less than one second.
PS In fact, I only need a release code and a collection number (it's an index). Then they can be used in the Scryfall service API to get all the possible information about this map, including the rules of the game and the cost.
A sample application is available on GitHub .