.NET: Tools for working with multithreading and asynchrony. Part 2
I publish the original article on Habr, the translation of which is posted on the Codingsight blog .
I continue to create a text version of my talk at the multithreading meeting. The first part can be found here or here , there it was more about the basic set of tools to start a thread or Task, ways to view their status and some sweet little things like PLinq. In this article I want to focus more on the problems that may arise in a multi-threaded environment and some ways to solve them.
It is impossible to write a program that would work in multiple threads, but at the same time would not have a single shared resource: even if it works out at your level of abstraction, then going down one or more levels below it turns out that there is still a common resource. I will give a few examples:
Example # 1:
Fearing possible problems, you made the threads work with different files. By file to stream. It seems to you that the program does not have a single common resource.
Having gone down several levels below, we understand that there is only one hard drive, and its driver or operating system will have to solve the problems of ensuring access to it.
Example # 2:
After reading example #1, you decided to place the files on two different remote machines with two physically different pieces of iron and operating systems. We keep 2 different connections via FTP or NFS.
Going down several levels below, we understand that nothing has changed, and the driver of the network card or the operating system of the machine on which the program is running will have to solve the problem of competitive access.
Example # 3:
Having lost a considerable part of your hair in attempts to prove the possibility of writing a multi-threaded program, you completely refuse files and decompose the calculations into two different objects, links to each of which are available only to one thread.
I hammer the final dozen nails into the coffin of this idea: one runtime and garbage collector, thread scheduler, physically one RAM and memory, one processor are still shared resources.
So, we found out that it is impossible to write a multi-threaded program without a single shared resource at all levels of abstraction across the width of the entire technology stack. Fortunately, each of the levels of abstraction, as a rule, partially or completely solves the problems of competitive access or simply prohibits it (example: any UI framework forbids working with elements from different threads), therefore problems most often arise with shared resources on your level of abstraction. To solve them introduce the concept of synchronization.
Errors in the software can be divided into several groups:
In a multi-threaded environment, the two main problems causing errors 1 and 2 are deadlock and race condition .
Deadlock - deadlock. There are many different variations. The following can be considered the most frequent:
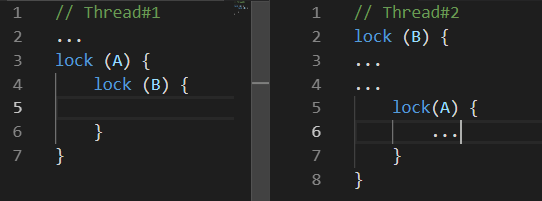
While Thread # 1 was doing something, Thread # 2 blocked resource B , a little later Thread # 1 blocked resource A and tries to lock resource B , unfortunately this will never happen, because Thread # 2 releases the resource B only after the resource block A .
Race-Condition - race condition. The situation in which the behavior and result of the calculations performed by the program depends on the work of the run-time thread scheduler.
The unpleasantness of this situation lies precisely in the fact that your program may not work only once out of a hundred or even out of a million.
The situation is aggravated by the fact that problems can go together, for example: with a certain behavior of the thread scheduler, a deadlock occurs.
In addition to these two problems leading to obvious errors in the program, there are also those that may not lead to an incorrect calculation result, but more time or processing power will be spent to get it. Two of these problems are: Busy Wait and Thread Starvation .
Busy-Wait is a problem in which the program consumes processor resources not for calculations, but for waiting.
Often such a problem in the code looks something like this:
This is an example of extremely bad code since Such code completely occupies one core of your processor while doing absolutely nothing useful. It can be justified if and only if it is critically important to process a change in some value in another thread. And speaking quickly, I’m talking about the case when you can’t wait even a few nanoseconds. In other cases, that is, in everything that can produce a healthy brain, it is more reasonable to use ResetEvent varieties and their Slim versions. About them below.
Perhaps one of the readers will propose to solve the problem of fully loading one core with a useless wait by adding constructs like Thread.Sleep (1) to the loop. This will really solve the problem, but will create another: the response time to the change will be on average half a millisecond, which may not be much, but catastrophically more than you could use the synchronization primitives of the ResetEvent family.
Thread-Starvation is a problem where the program has too many threads working simultaneously. What does it mean exactly those flows that are busy with calculations, and not just waiting for a response from any IO. With this problem, all the possible performance gain from using threads is lost, because The processor spends a lot of time switching contexts.
It is convenient to look for such problems using various profilers, below is an example of a screenshot from the dotTrace profiler launched in Timeline mode. (The picture is clickable) In the program that does not suffer from streaming hunger, there will be no pink color on the graphs reflecting streams. In addition, in the Subsystems category, it is clear that 30.6% of the program was waiting for the CPU.
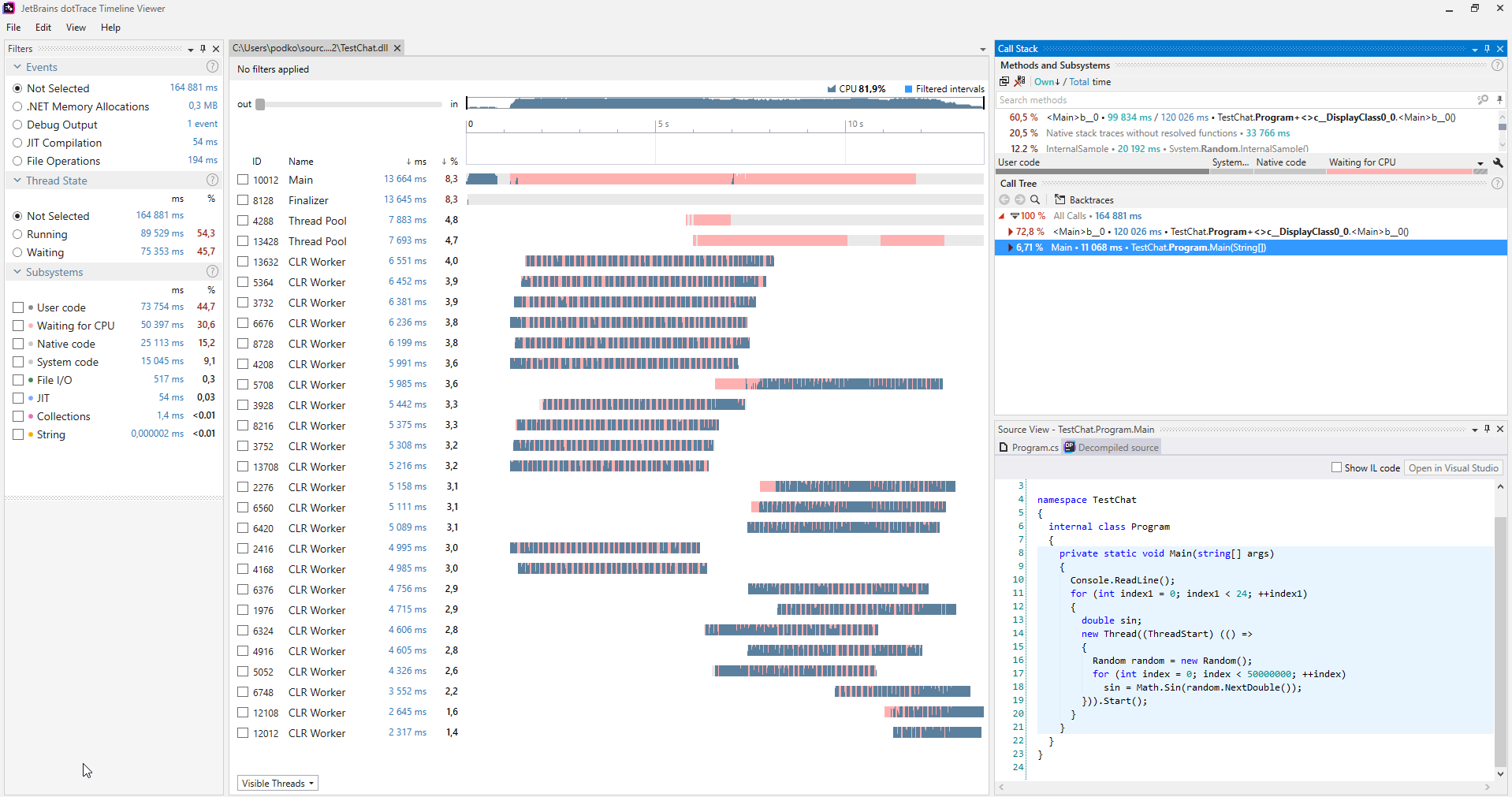
When such a problem is diagnosed, it is solved quite simply: you started too many threads at one time, start less or not all at once.
This is perhaps the most lightweight way to sync. Interlocked is a collection of simple atomic operations. An atomic operation is called an operation at the time of which nothing can happen. In .NET, Interlocked is represented by the static class of the same name with a number of methods, each of which implements one atomic operation.
To realize the horror of non-atomic operations, try writing a program that starts 10 threads, each of which makes a million increments of the same variable, and at the end of their work print the value of this variable - unfortunately it will be very different from 10 million, moreover Each time the program starts, it will be different. This happens because even such a simple operation as an increment is not atomic, but involves extracting a value from memory, calculating a new one, and writing back. Thus, two threads can simultaneously do each of these operations, in which case the increment will be lost.
The Interlocked class provides Increment / Decrement methods; it's easy to guess what they do. They are convenient to use if you are processing data in multiple threads and consider something. Such code will work much faster than the classic lock. If Interlocked is used for the situation described in the last paragraph, the program will stably give out 10 million in any situation.
The CompareExchange method performs, at first glance, a rather unobvious function, but all its presence allows you to implement many interesting algorithms, especially the lock-free family.
The method takes three values: the first is passed by reference and this is the value that will be changed to the second, if at the time of comparison location1 matches comparand, then the original value of location1 will be returned. It sounds rather confusing, because it’s easier to write code that performs the same operations as CompareExchange:
Only an implementation in the Interlocked class will be atomic. That is, if we wrote such code ourselves, a situation could have occurred when the condition location1 == comparand had already been met, but by the time the location1 = value expression was executed, another thread had changed the value of location1 and it would be lost.
We can find a good example of using this method in the code that the compiler generates for any C # event.
Let's write a simple class with one MyEvent event:
Let's build the project in the Release configuration and open the assembly using dotPeek with the Show Compiler Generated Code option turned on:
Here you can see that behind the scenes, the compiler generated a rather sophisticated algorithm. This algorithm protects against the situation of losing an event subscription when several threads subscribe to this event simultaneously. Let's write the add method in more detail, remembering what the CompareExchange method does behind the scenes
This is already a little clearer, although it probably still needs an explanation. In words, I would describe this algorithm as follows:
If MyEvent is still the same as it was at the time we started running Delegate.Combine, then write in it what Delegate.Combine returns, and if not, it doesn’t matter, let's try again and we will repeat until it comes out.
So no event subscription will be lost. You will have to solve a similar problem if you suddenly want to implement a dynamic thread-safe lock-free array. If several streams rush to add elements to it, then it is important that they all be added in the end.
These are the most commonly used constructs for thread synchronization. They implement the idea of a critical section: that is, code written between calls to Monitor.Enter, Monitor.Exit on one resource can be executed at one time in just one thread. The lock statement is syntactic sugar around Enter / Exit calls wrapped in try-finally. A nice feature of implementing a critical section in .NET is the ability to re-enter it for the same stream. This means that such code will execute without problems:
It is unlikely, of course, that someone will write this way, but if you smear this code into several methods in depth call-stack this feature can save you some ifs. In order to make such a trick possible, .NET developers had to add a restriction - only an instance of a reference type can be used as a synchronization object, and several bytes are implicitly added to each object where the stream identifier will be written.
This feature of the critical section in c # imposes one interesting limitation on the operation of the lock statement: you cannot use the await statement inside the lock statement. At first, it surprised me, because a similar try-finally Monitor.Enter / Exit construct compiles. What is the matter? Here it is necessary to carefully re-read the last paragraph once again, and then add to it some knowledge about the principle of async / await: the code after await will not necessarily be executed on the same thread as the code before await, it depends on the synchronization context and the presence or no call to ConfigureAwait. It follows that Monitor.Exit may execute on a thread other than Monitor.Enter, which will throw a SynchronizationLockException. If you do not believe it, then you can execute the following code in a console application: it will throw a SynchronizationLockException.
It is noteworthy that in WinForms or a WPF application, this code will work correctly if it is called from the main thread. there will be a synchronization context that implements a return to the UI-Thread after await. In any case, you should not play with the critical section in the context of the code containing the await operator. In these cases, it is better to use synchronization primitives, which will be discussed later.
Talking about the work of the critical section in .NET, it is worth mentioning another feature of its implementation. The critical section in .NET operates in two modes: spin-wait mode and kernel mode. The spin-wait algorithm is conveniently represented as the following pseudo-code:
This optimization is aimed at the fastest capture of the critical section in a short time, based on the assumption that if the resource is busy now, then it is about to free itself. If this does not happen in a short period of time, then the thread goes to wait in kernel mode, which, like returning from it, takes time. .NET developers have optimized the short lock scenario as much as possible, unfortunately, if many threads start tearing the critical section apart, this can lead to a high and sudden CPU load.
Since I mentioned the spin-wait algorithm, it’s worth mentioning the BCL SpinLock and SpinWait structures. They should be used if there is reason to believe that there will always be an opportunity to very quickly take a lock. On the other hand, it is hardly worth remembering about them before the results of profiling show that it is the use of other synchronization primitives that is the bottleneck of your program.
This pair of methods should be considered together. With their help, various Producer-Consumer scenarios can be implemented.
Producer-Consumer - a multi-process / multi-threaded design pattern assuming the presence of one or more threads / processes that produce data and one or more processes / threads that process this data. Usually uses a shared collection.
Both of these methods can only be called if the thread that is causing them has a lock at the moment. The Wait method releases the lock and hangs until another thread calls Pulse.
To demonstrate the work, I wrote a small example:
(I used the image, not the text, to clearly demonstrate the order of instructions)
Analysis: I set a delay of 100ms at the start of the second stream, especially to ensure that its execution starts later.
- T1: Line # 2 the stream starts
- T1: Line # 3 the stream enters the critical section
- T1: Line # 6 the stream falls asleep
- T2: Line # 3 the stream starts
- T2: Line # 4 freezes while waiting for the critical section
- T1: Line # 7 releases the critical section and freezes while waiting for Pulse
- T2: Line # 8 to enter the critical section
- T2: Line # 11 notifies T1 using the Pulse method
- T2: Line # 14 exits the critical section. Until then, T1 cannot continue execution.
- T1: Line # 15 from standby
- T1: Line # 16 comes out of the critical section
in the MSDN there is an important note regarding the use of Pulse / Wait methods, namely: Monitor does not store information about the status, which means that if the method call Pulse to Calling the Wait method can lead to deadlock. If this situation is possible, then it is better to use one of the classes of the ResetEvent family.
The previous example clearly demonstrates how the Wait / Pulse methods of the Monitor class work, but still leaves questions about when it should be used. A good example would be such an implementation of BlockingQueue, on the other hand, an implementation of BlockingCollection from System.Collections.Concurrent uses SemaphoreSlim for synchronization.
This is my beloved synchronization primitive, represented by the System.Threading namespace class of the same name. It seems to me that many programs would work better if their developers used this class instead of the usual lock.
Idea: many threads can read, only one write. As soon as the stream declares its desire to write, new readings cannot be started, but will wait for the recording to complete. There is also the concept of upgradeable-read-lock, which can be used if you understand during the reading process that you need to write something, such a lock will be converted to write-lock in one atomic operation.
There is also a ReadWriteLock class in the System.Threading namespace, but it is highly recommended for new development. Slim version will allow to avoid a number of cases leading to deadlocks, besides it allows you to quickly capture the lock, because supports synchronization in spin-wait mode before leaving for kernel mode.
If at the time of reading this article you did not yet know about this class, then I think now you have recalled quite a few examples from the code written recently, where such an approach to locks would allow the program to work efficiently.
The interface of the ReaderWriterLockSlim class is simple and straightforward, but its use can hardly be called convenient:
I like to wrap its use in a class, which makes using it much more convenient.
Idea: to make Read / WriteLock methods that return an object with the Dispose method, then this will allow them to be used in using and by the number of lines it will hardly differ from the usual lock.
Such a trick allows you to simply write further:
I include the classes ManualResetEvent, ManualResetEventSlim, AutoResetEvent to this family.
The ManualResetEvent classes, its Slim version and the AutoResetEvent class can be in two states:
- Non-signaled, in this state all threads that called WaitOne hang until the event transitions to the signaled state.
- The lowered state (signaled), in this state all flows hanging on the WaitOne call are released. All new WaitOne calls on a run-down event pass conditionally instantly.
The AutoResetEvent class differs from the ManualResetEvent class in that it automatically enters a cocked state after it releases exactly one thread. If several threads will hang waiting for AutoResetEvent, then the Set call will release only one arbitrary, unlike ManualResetEvent. ManualResetEvent will release all threads.
Let's look at an example of how AutoResetEvent works:
The example shows that the event goes into a cocked state (non-signaled) automatically only by letting go of the thread hanging on the WaitOne call.
The ManualResetEvent class, unlike ReaderWriterLock, is not marked as deprecated and not recommended for use after the appearance of its Slim version. The slim version of this class is efficiently used for short expectations, as It happens in Spin-Wait mode, the regular version is suitable for long ones.
In addition to the ManualResetEvent and AutoResetEvent classes, the CountdownEvent class also exists. This class is convenient for the implementation of algorithms, where the part that managed to be parallelized is followed by the part of bringing the results together. This approach is known as fork-join . An excellent article is devoted to the work of this class .therefore I will not analyze it here in detail.
I continue to create a text version of my talk at the multithreading meeting. The first part can be found here or here , there it was more about the basic set of tools to start a thread or Task, ways to view their status and some sweet little things like PLinq. In this article I want to focus more on the problems that may arise in a multi-threaded environment and some ways to solve them.
Content
- About Shared Resources
- Possible problems when working in a multi-threaded environment
- Sync Tools
- conclusions
About Shared Resources
It is impossible to write a program that would work in multiple threads, but at the same time would not have a single shared resource: even if it works out at your level of abstraction, then going down one or more levels below it turns out that there is still a common resource. I will give a few examples:
Example # 1:
Fearing possible problems, you made the threads work with different files. By file to stream. It seems to you that the program does not have a single common resource.
Having gone down several levels below, we understand that there is only one hard drive, and its driver or operating system will have to solve the problems of ensuring access to it.
Example # 2:
After reading example #1, you decided to place the files on two different remote machines with two physically different pieces of iron and operating systems. We keep 2 different connections via FTP or NFS.
Going down several levels below, we understand that nothing has changed, and the driver of the network card or the operating system of the machine on which the program is running will have to solve the problem of competitive access.
Example # 3:
Having lost a considerable part of your hair in attempts to prove the possibility of writing a multi-threaded program, you completely refuse files and decompose the calculations into two different objects, links to each of which are available only to one thread.
I hammer the final dozen nails into the coffin of this idea: one runtime and garbage collector, thread scheduler, physically one RAM and memory, one processor are still shared resources.
So, we found out that it is impossible to write a multi-threaded program without a single shared resource at all levels of abstraction across the width of the entire technology stack. Fortunately, each of the levels of abstraction, as a rule, partially or completely solves the problems of competitive access or simply prohibits it (example: any UI framework forbids working with elements from different threads), therefore problems most often arise with shared resources on your level of abstraction. To solve them introduce the concept of synchronization.
Possible problems when working in a multi-threaded environment
Errors in the software can be divided into several groups:
- The program does not produce a result. Crashes or freezes.
- The program returns an incorrect result.
- The program produces the correct result, but does not satisfy one or another non-functional requirement. Runs too long or consumes too many resources.
In a multi-threaded environment, the two main problems causing errors 1 and 2 are deadlock and race condition .
Deadlock
Deadlock - deadlock. There are many different variations. The following can be considered the most frequent:
While Thread # 1 was doing something, Thread # 2 blocked resource B , a little later Thread # 1 blocked resource A and tries to lock resource B , unfortunately this will never happen, because Thread # 2 releases the resource B only after the resource block A .
Race condition
Race-Condition - race condition. The situation in which the behavior and result of the calculations performed by the program depends on the work of the run-time thread scheduler.
The unpleasantness of this situation lies precisely in the fact that your program may not work only once out of a hundred or even out of a million.
The situation is aggravated by the fact that problems can go together, for example: with a certain behavior of the thread scheduler, a deadlock occurs.
In addition to these two problems leading to obvious errors in the program, there are also those that may not lead to an incorrect calculation result, but more time or processing power will be spent to get it. Two of these problems are: Busy Wait and Thread Starvation .
Busy-wait
Busy-Wait is a problem in which the program consumes processor resources not for calculations, but for waiting.
Often such a problem in the code looks something like this:
while(!hasSomethingHappened)
;
This is an example of extremely bad code since Such code completely occupies one core of your processor while doing absolutely nothing useful. It can be justified if and only if it is critically important to process a change in some value in another thread. And speaking quickly, I’m talking about the case when you can’t wait even a few nanoseconds. In other cases, that is, in everything that can produce a healthy brain, it is more reasonable to use ResetEvent varieties and their Slim versions. About them below.
Perhaps one of the readers will propose to solve the problem of fully loading one core with a useless wait by adding constructs like Thread.Sleep (1) to the loop. This will really solve the problem, but will create another: the response time to the change will be on average half a millisecond, which may not be much, but catastrophically more than you could use the synchronization primitives of the ResetEvent family.
Thread starvation
Thread-Starvation is a problem where the program has too many threads working simultaneously. What does it mean exactly those flows that are busy with calculations, and not just waiting for a response from any IO. With this problem, all the possible performance gain from using threads is lost, because The processor spends a lot of time switching contexts.
It is convenient to look for such problems using various profilers, below is an example of a screenshot from the dotTrace profiler launched in Timeline mode. (The picture is clickable) In the program that does not suffer from streaming hunger, there will be no pink color on the graphs reflecting streams. In addition, in the Subsystems category, it is clear that 30.6% of the program was waiting for the CPU.
When such a problem is diagnosed, it is solved quite simply: you started too many threads at one time, start less or not all at once.
Sync Tools
Interlocked
This is perhaps the most lightweight way to sync. Interlocked is a collection of simple atomic operations. An atomic operation is called an operation at the time of which nothing can happen. In .NET, Interlocked is represented by the static class of the same name with a number of methods, each of which implements one atomic operation.
To realize the horror of non-atomic operations, try writing a program that starts 10 threads, each of which makes a million increments of the same variable, and at the end of their work print the value of this variable - unfortunately it will be very different from 10 million, moreover Each time the program starts, it will be different. This happens because even such a simple operation as an increment is not atomic, but involves extracting a value from memory, calculating a new one, and writing back. Thus, two threads can simultaneously do each of these operations, in which case the increment will be lost.
The Interlocked class provides Increment / Decrement methods; it's easy to guess what they do. They are convenient to use if you are processing data in multiple threads and consider something. Such code will work much faster than the classic lock. If Interlocked is used for the situation described in the last paragraph, the program will stably give out 10 million in any situation.
The CompareExchange method performs, at first glance, a rather unobvious function, but all its presence allows you to implement many interesting algorithms, especially the lock-free family.
public static int CompareExchange (ref int location1, int value, int comparand);
The method takes three values: the first is passed by reference and this is the value that will be changed to the second, if at the time of comparison location1 matches comparand, then the original value of location1 will be returned. It sounds rather confusing, because it’s easier to write code that performs the same operations as CompareExchange:
var original = location1;
if (location1 == comparand)
location1 = value;
return original;
Only an implementation in the Interlocked class will be atomic. That is, if we wrote such code ourselves, a situation could have occurred when the condition location1 == comparand had already been met, but by the time the location1 = value expression was executed, another thread had changed the value of location1 and it would be lost.
We can find a good example of using this method in the code that the compiler generates for any C # event.
Let's write a simple class with one MyEvent event:
class MyClass {
public event EventHandler MyEvent;
}
Let's build the project in the Release configuration and open the assembly using dotPeek with the Show Compiler Generated Code option turned on:
[CompilerGenerated]
private EventHandler MyEvent;
public event EventHandler MyEvent
{
[CompilerGenerated] add
{
EventHandler eventHandler = this.MyEvent;
EventHandler comparand;
do
{
comparand = eventHandler;
eventHandler = Interlocked.CompareExchange(ref this.MyEvent, (EventHandler) Delegate.Combine((Delegate) comparand, (Delegate) value), comparand);
}
while (eventHandler != comparand);
}
[CompilerGenerated] remove
{
// The same algorithm but with Delegate.Remove
}
}
Here you can see that behind the scenes, the compiler generated a rather sophisticated algorithm. This algorithm protects against the situation of losing an event subscription when several threads subscribe to this event simultaneously. Let's write the add method in more detail, remembering what the CompareExchange method does behind the scenes
EventHandler eventHandler = this.MyEvent;
EventHandler comparand;
do
{
comparand = eventHandler;
// Begin Atomic Operation
if (MyEvent == comparand)
{
eventHandler = MyEvent;
MyEvent = Delegate.Combine(MyEvent, value);
}
// End Atomic Operation
}
while (eventHandler != comparand);
This is already a little clearer, although it probably still needs an explanation. In words, I would describe this algorithm as follows:
If MyEvent is still the same as it was at the time we started running Delegate.Combine, then write in it what Delegate.Combine returns, and if not, it doesn’t matter, let's try again and we will repeat until it comes out.
So no event subscription will be lost. You will have to solve a similar problem if you suddenly want to implement a dynamic thread-safe lock-free array. If several streams rush to add elements to it, then it is important that they all be added in the end.
Monitor.Enter, Monitor.Exit, lock
These are the most commonly used constructs for thread synchronization. They implement the idea of a critical section: that is, code written between calls to Monitor.Enter, Monitor.Exit on one resource can be executed at one time in just one thread. The lock statement is syntactic sugar around Enter / Exit calls wrapped in try-finally. A nice feature of implementing a critical section in .NET is the ability to re-enter it for the same stream. This means that such code will execute without problems:
lock(a) {
lock (a) {
...
}
}
It is unlikely, of course, that someone will write this way, but if you smear this code into several methods in depth call-stack this feature can save you some ifs. In order to make such a trick possible, .NET developers had to add a restriction - only an instance of a reference type can be used as a synchronization object, and several bytes are implicitly added to each object where the stream identifier will be written.
This feature of the critical section in c # imposes one interesting limitation on the operation of the lock statement: you cannot use the await statement inside the lock statement. At first, it surprised me, because a similar try-finally Monitor.Enter / Exit construct compiles. What is the matter? Here it is necessary to carefully re-read the last paragraph once again, and then add to it some knowledge about the principle of async / await: the code after await will not necessarily be executed on the same thread as the code before await, it depends on the synchronization context and the presence or no call to ConfigureAwait. It follows that Monitor.Exit may execute on a thread other than Monitor.Enter, which will throw a SynchronizationLockException. If you do not believe it, then you can execute the following code in a console application: it will throw a SynchronizationLockException.
var syncObject = new Object();
Monitor.Enter(syncObject);
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
await Task.Delay(1000);
Monitor.Exit(syncObject);
Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
It is noteworthy that in WinForms or a WPF application, this code will work correctly if it is called from the main thread. there will be a synchronization context that implements a return to the UI-Thread after await. In any case, you should not play with the critical section in the context of the code containing the await operator. In these cases, it is better to use synchronization primitives, which will be discussed later.
Talking about the work of the critical section in .NET, it is worth mentioning another feature of its implementation. The critical section in .NET operates in two modes: spin-wait mode and kernel mode. The spin-wait algorithm is conveniently represented as the following pseudo-code:
while(!TryEnter(syncObject))
;
This optimization is aimed at the fastest capture of the critical section in a short time, based on the assumption that if the resource is busy now, then it is about to free itself. If this does not happen in a short period of time, then the thread goes to wait in kernel mode, which, like returning from it, takes time. .NET developers have optimized the short lock scenario as much as possible, unfortunately, if many threads start tearing the critical section apart, this can lead to a high and sudden CPU load.
SpinLock, SpinWait
Since I mentioned the spin-wait algorithm, it’s worth mentioning the BCL SpinLock and SpinWait structures. They should be used if there is reason to believe that there will always be an opportunity to very quickly take a lock. On the other hand, it is hardly worth remembering about them before the results of profiling show that it is the use of other synchronization primitives that is the bottleneck of your program.
Monitor.Wait, Monitor.Pulse [All]
This pair of methods should be considered together. With their help, various Producer-Consumer scenarios can be implemented.
Producer-Consumer - a multi-process / multi-threaded design pattern assuming the presence of one or more threads / processes that produce data and one or more processes / threads that process this data. Usually uses a shared collection.
Both of these methods can only be called if the thread that is causing them has a lock at the moment. The Wait method releases the lock and hangs until another thread calls Pulse.
To demonstrate the work, I wrote a small example:
object syncObject = new object();
Thread t1 = new Thread(T1);
t1.Start();
Thread.Sleep(100);
Thread t2 = new Thread(T2);
t2.Start();
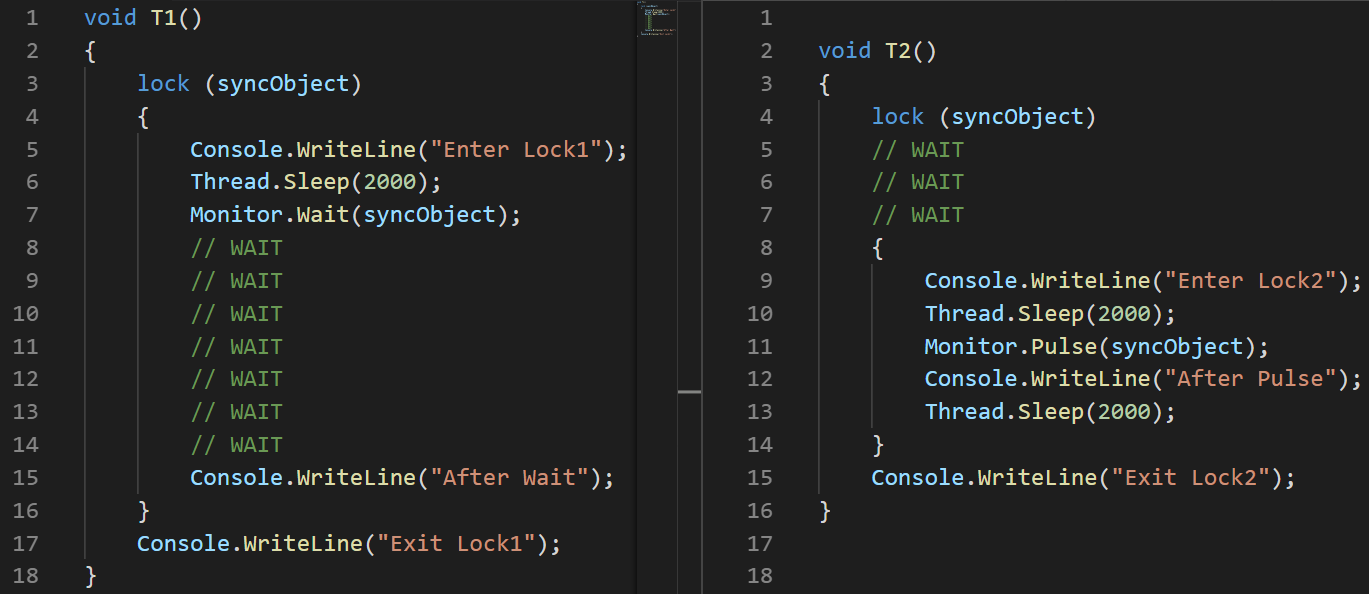
(I used the image, not the text, to clearly demonstrate the order of instructions)
Analysis: I set a delay of 100ms at the start of the second stream, especially to ensure that its execution starts later.
- T1: Line # 2 the stream starts
- T1: Line # 3 the stream enters the critical section
- T1: Line # 6 the stream falls asleep
- T2: Line # 3 the stream starts
- T2: Line # 4 freezes while waiting for the critical section
- T1: Line # 7 releases the critical section and freezes while waiting for Pulse
- T2: Line # 8 to enter the critical section
- T2: Line # 11 notifies T1 using the Pulse method
- T2: Line # 14 exits the critical section. Until then, T1 cannot continue execution.
- T1: Line # 15 from standby
- T1: Line # 16 comes out of the critical section
in the MSDN there is an important note regarding the use of Pulse / Wait methods, namely: Monitor does not store information about the status, which means that if the method call Pulse to Calling the Wait method can lead to deadlock. If this situation is possible, then it is better to use one of the classes of the ResetEvent family.
The previous example clearly demonstrates how the Wait / Pulse methods of the Monitor class work, but still leaves questions about when it should be used. A good example would be such an implementation of BlockingQueue
ReaderWriterLockSlim
This is my beloved synchronization primitive, represented by the System.Threading namespace class of the same name. It seems to me that many programs would work better if their developers used this class instead of the usual lock.
Idea: many threads can read, only one write. As soon as the stream declares its desire to write, new readings cannot be started, but will wait for the recording to complete. There is also the concept of upgradeable-read-lock, which can be used if you understand during the reading process that you need to write something, such a lock will be converted to write-lock in one atomic operation.
There is also a ReadWriteLock class in the System.Threading namespace, but it is highly recommended for new development. Slim version will allow to avoid a number of cases leading to deadlocks, besides it allows you to quickly capture the lock, because supports synchronization in spin-wait mode before leaving for kernel mode.
If at the time of reading this article you did not yet know about this class, then I think now you have recalled quite a few examples from the code written recently, where such an approach to locks would allow the program to work efficiently.
The interface of the ReaderWriterLockSlim class is simple and straightforward, but its use can hardly be called convenient:
var @lock = new ReaderWriterLockSlim();
@lock.EnterReadLock();
try
{
// ...
}
finally
{
@lock.ExitReadLock();
}
I like to wrap its use in a class, which makes using it much more convenient.
Idea: to make Read / WriteLock methods that return an object with the Dispose method, then this will allow them to be used in using and by the number of lines it will hardly differ from the usual lock.
class RWLock : IDisposable
{
public struct WriteLockToken : IDisposable
{
private readonly ReaderWriterLockSlim @lock;
public WriteLockToken(ReaderWriterLockSlim @lock)
{
this.@lock = @lock;
@lock.EnterWriteLock();
}
public void Dispose() => @lock.ExitWriteLock();
}
public struct ReadLockToken : IDisposable
{
private readonly ReaderWriterLockSlim @lock;
public ReadLockToken(ReaderWriterLockSlim @lock)
{
this.@lock = @lock;
@lock.EnterReadLock();
}
public void Dispose() => @lock.ExitReadLock();
}
private readonly ReaderWriterLockSlim @lock = new ReaderWriterLockSlim();
public ReadLockToken ReadLock() => new ReadLockToken(@lock);
public WriteLockToken WriteLock() => new WriteLockToken(@lock);
public void Dispose() => @lock.Dispose();
}
Such a trick allows you to simply write further:
var rwLock = new RWLock();
// ...
using(rwLock.ReadLock())
{
// ...
}
ResetEvent Family
I include the classes ManualResetEvent, ManualResetEventSlim, AutoResetEvent to this family.
The ManualResetEvent classes, its Slim version and the AutoResetEvent class can be in two states:
- Non-signaled, in this state all threads that called WaitOne hang until the event transitions to the signaled state.
- The lowered state (signaled), in this state all flows hanging on the WaitOne call are released. All new WaitOne calls on a run-down event pass conditionally instantly.
The AutoResetEvent class differs from the ManualResetEvent class in that it automatically enters a cocked state after it releases exactly one thread. If several threads will hang waiting for AutoResetEvent, then the Set call will release only one arbitrary, unlike ManualResetEvent. ManualResetEvent will release all threads.
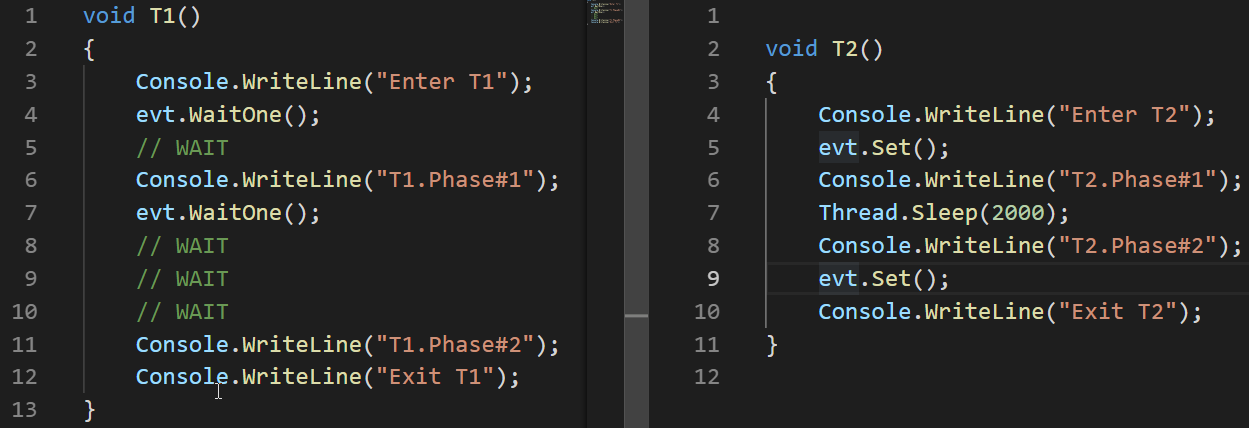
Let's look at an example of how AutoResetEvent works:
AutoResetEvent evt = new AutoResetEvent(false);
Thread t1 = new Thread(T1);
t1.Start();
Thread.Sleep(100);
Thread t2 = new Thread(T2);
t2.Start();
The example shows that the event goes into a cocked state (non-signaled) automatically only by letting go of the thread hanging on the WaitOne call.
The ManualResetEvent class, unlike ReaderWriterLock, is not marked as deprecated and not recommended for use after the appearance of its Slim version. The slim version of this class is efficiently used for short expectations, as It happens in Spin-Wait mode, the regular version is suitable for long ones.
In addition to the ManualResetEvent and AutoResetEvent classes, the CountdownEvent class also exists. This class is convenient for the implementation of algorithms, where the part that managed to be parallelized is followed by the part of bringing the results together. This approach is known as fork-join . An excellent article is devoted to the work of this class .therefore I will not analyze it here in detail.
Выводы
- При работе с потоками двумя проблемами, приводящими к неверным результатам или их отсутствию, являются race condition и deadlock
- Проблемами, что заставляют программу тратить больше времени или ресурсов — thread starvation и busy wait
- .NET богат на средства синхронизации потоков
- Существует 2 режимы ожидания блокировки — Spin Wait, Core Wait. Часть примитивов синхронизации потоков .NET использует оба
- Interlocked представляет собой набор атомарных операций, используется в lock-free алгоритмах, является самым быстрым примитивом синхронизации
- Оператор lock и Monitor.Enter/Exit реализуют идею критической секции — фрагменте кода, что может быть выполнен лишь одним потоком в один момент времени
- Методы Monitor.Pulse/Wait удобны для реализации Producer-Consumer сценариев
- ReaderWriterLockSlim may be more efficient than regular lock in scripts where parallel reading is acceptable
- The ResetEvent class family may come in handy for thread synchronization.