Server rendering in a serverless environment
- Transfer
The author of the material, the translation of which we are publishing, is one of the founders of the Webiny project - a serverless CMS based on React, GraphQL, and Node.js. He says that supporting a multi-tenant serverless cloud platform is a business that has specific tasks. Many articles have already been written in which standard technologies for optimizing web projects are discussed. Among them are server rendering, the use of advanced web application development technologies, various ways to improve application builds, and much more. This article, on the one hand, is similar to the others, and on the other, it differs from them. The fact is that it is dedicated to optimizing projects running in a serverless environment.

In order to make measurements that will help identify the problems of the project, we will use webpagetest.org . With the help of this resource, we will fulfill requests and collect information about the execution time of various operations. This will allow us to better understand what users see and feel when working with the project.
We are particularly interested in the “First view” indicator, that is, how long does it take to load a site from a user who visits him for the first time. This is a very important indicator. The fact is that the browser cache is able to hide many bottlenecks of web projects.
Take a look at the following chart.
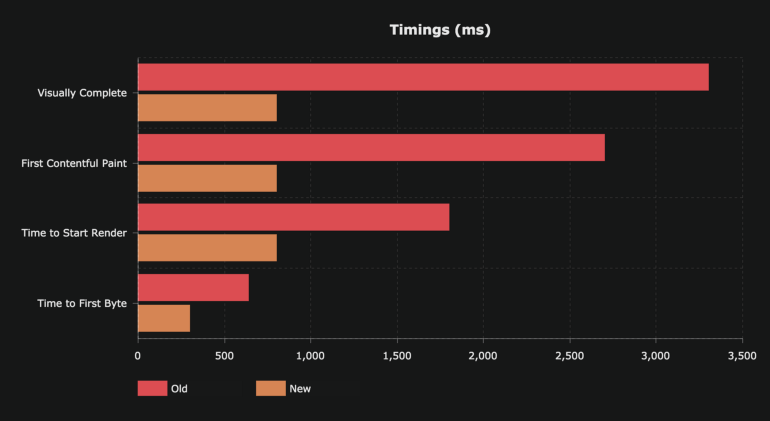
Analysis of old and new indicators of a web project
Here, the most important indicator can be recognized as “Time to Start Render” - time before the start of rendering. If you look closely at this indicator, you can see that only in order to start rendering the page, in the old version of the project, it took almost 2 seconds. The reason for this lies in the very essence of Single Page Application (SPA). In order to display the page of such an application on the screen, you first need to load the voluminous JS-bundle (this stage of page loading is marked in the following figure as 1). Then this bundle needs to be processed in the main thread (2). And only after that, something can appear in the browser window.
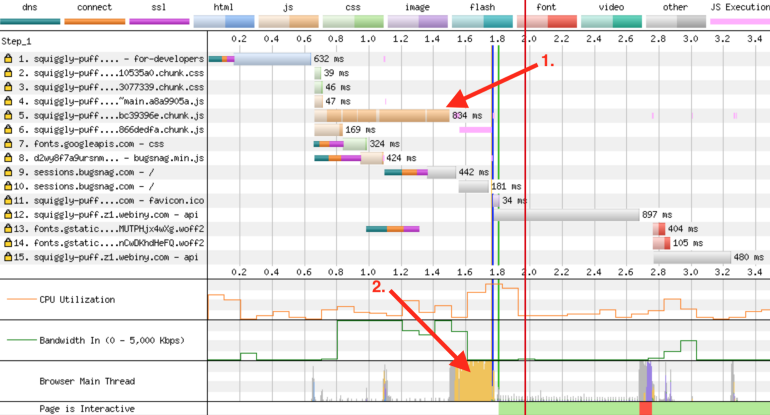
(1) Download the JS bundle. (2) Waiting for the bundle to be processed in the main thread
However, this is only part of the picture. After the main thread processes the JS bundle, it makes several requests to the Gateway API. At this stage of page processing, the user sees a rotating loading indicator. The sight is not the most pleasant. However, the user has not yet seen any page content. Here is a storyboard of the page loading process.

Loading the page
All this suggests that the user who visited such a site does not have a particularly pleasant experience working with it. Namely, he is forced to look at a blank page for 2 seconds, and then another second - at the download indicator. This second is added to the page preparation time due to the fact that after loading and processing the JS-bundle API requests are executed. These queries are necessary in order to load the data and, as a result, display the finished page.

Page loading
If the project was hosted on a regular VPS, then the time required to complete these API requests would be mostly predictable. However, projects running in a serverless environment are affected by the notorious “cold start” problem. In the case of the Webiny cloud platform, the situation is even worse. AWS Lambda features are part of VPC (Virtual Private Cloud). This means that for each new instance of such a function, you need to initialize ENI (Elastic Network Interface, elastic network interface). This significantly increases the cold start time of functions.
Here are some timelines for loading AWS Lambda features within VPCs and outside of VPCs.

Analysis of AWS Lambda function load inside VPC and outside VPC (image taken from here )
From this we can conclude that in the case when the function is launched inside VPC, this gives a 10-fold increase in cold start time.
In addition, here one more factor must be taken into account - network data transmission delays. Their duration is already included at the time it takes to execute API requests. Requests are initiated by the browser. Therefore, it turns out that by the time the API responds to these requests, the time needed to get the request from the browser to the API, and the time it takes for the response to get from the API to the browser are added. These delays occur during each request.
Based on the above analysis, we formulated several tasks that we needed to solve to optimize the project. Here they are:
Here are a few approaches to solving the problems that we considered:
In the end, we chose the third item on this list. We reasoned like this: “What if we absolutely do not need API calls? What if we can do without the JS bundle at all? This would allow us to solve all the problems of the project. ”

The first idea that we found interesting was to create an HTML snapshot of the rendered page and share the snapshot with users.
Webiny Cloud is an AWS Lambda-based serverless infrastructure that supports Webiny sites. Our system can detect bots. When it turns out that the request was completed by the bot, this request is redirected to the Puppeteer instance , which renders the page using Chrome without a user interface. The ready-made HTML code of the page is sent to the bot. This was done mainly for SEO reasons, due to the fact that many bots do not know how to execute JavaScript. We decided to use the same approach for preparing pages intended for ordinary users.
This approach works well in environments that lack JavaScript support. However, if you try to give pre-rendered pages to a client whose browser supports JS, the page is displayed, but then, after downloading the JS files, the React components simply do not know where to mount them. This results in a whole bunch of error messages in the console. As a result, such a decision did not suit us.
The strong side of Server Side Rendering (SSR) is that all API requests are executed within the local network. Since they are processed by a certain system or function that runs inside the VPC, delays that occur when executing requests from the browser to the resource backend are uncharacteristic. Although in this scenario, the problem of a “cold start” remains.
An additional advantage of using SSR is that we give the client such an HTML version of the page, when working with which, after loading the JS files, the React components do not have problems with mounting.
And finally, we don’t need a very large JS bundle. In addition, we can do without API calls to display the page. A bundle can be loaded asynchronously and this will not block the main thread.
In general, we can say that server rendering, it seems, should have solved most of our problems.
This is how site analysis looks after applying server-side rendering.
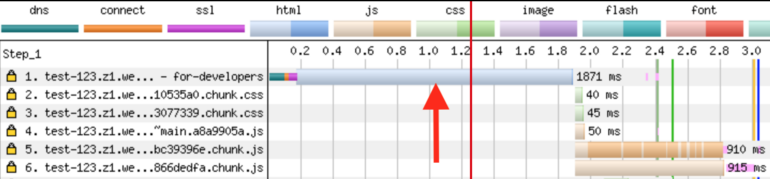
Site metrics after applying server rendering
Now API requests are not executed, and the page can be seen before the large JS bundle loads. But if you look closely at the first request, you can see that it takes almost 2 seconds to get a document from the server. Let's talk about it.
Here we discuss the TTFB metric (Time To First Byte, time to first byte). Here are the details of the first request.
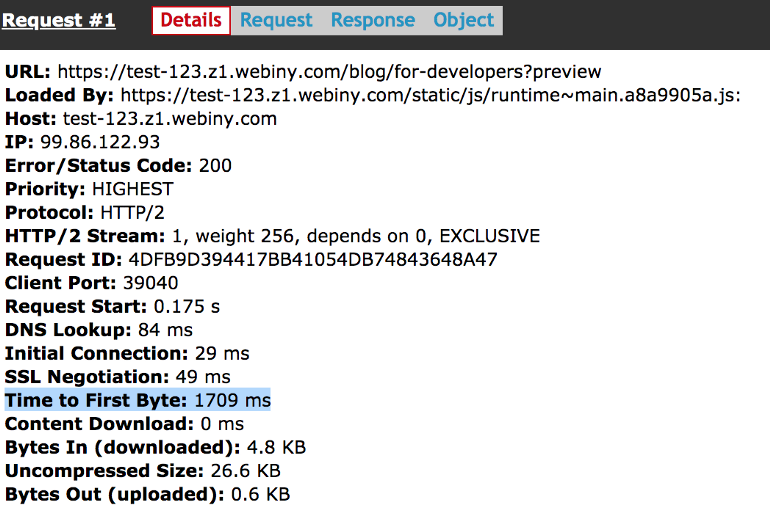
Information about the first request
To process this first request, we need to do the following: launch the Node.js server, perform server rendering, making API requests and executing JS code, and then return the final result to the client. The problem here is that all this, on average, takes 1-2 seconds.
Our server, which performs server rendering, needs to do all this work, and only after that it will be able to transmit the first byte of the response to the client. This leads to the fact that the browser has a very long time to wait for the start of the response to the request. As a result, it turns out that now for the output of the page you need to produce almost the same amount of work as before. The only difference is that this work is carried out not on the client side, but on the server, in the process of server rendering.
Here you may have a question about the word "server". We have been talking about the serverless system all this time. Where did this “server" come from? We, of course, tried to render server rendering in AWS Lambda functions. But it turned out that this is a very resource-consuming process (in particular, it was necessary to increase the amount of memory very much in order to get more processor resources). In addition, the “cold start” problem, which we have already mentioned, is also added here. As a result, then the ideal solution was to use a Node.js server that would load the site materials and engage in server-side rendering of them.
Let's go back to the consequences of using server-side rendering. Take a look at the following storyboard. It is easy to see that it is not particularly different from that which was obtained in the study of the project, which was rendered on the client.
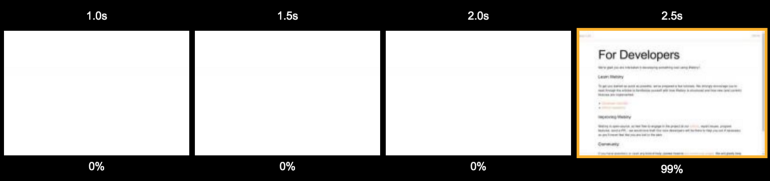
Page loading when using server rendering A
user is forced to look at a blank page for 2.5 seconds. It is sad.
Although looking at these results, one might think that we have achieved absolutely nothing, this is actually not so. We had an HTML snapshot of the page containing everything we needed. This shot was ready to work with React. In this case, during the processing of the page on the client, it was not necessary to fulfill any API requests. All the necessary data has already been embedded in HTML.
The only problem was that creating this HTML snapshot took too much time. At this point, we could either invest more time in optimizing server rendering, or simply cache its results and give clients a snapshot of the page from something like a Redis cache. We did just that.
After a user visits the Webiny website, we first of all check the centralized Redis cache to see if there is an HTML snapshot of the page. If so, we give the user a page from the cache. On average, this lowered the TTFB to 200-400 ms. It was after the introduction of the cache that we began to notice significant improvements in project performance.
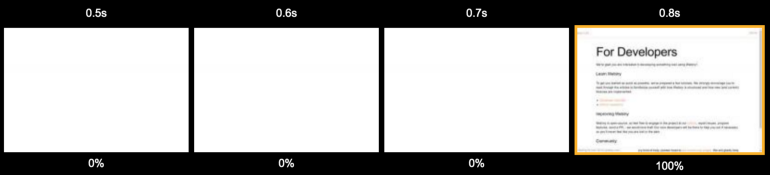
Page loading when using server-side rendering and cache
Even a user who visits a site for the first time sees the contents of the page in less than a second.
Let's look at how the waterfall diagram now looks.
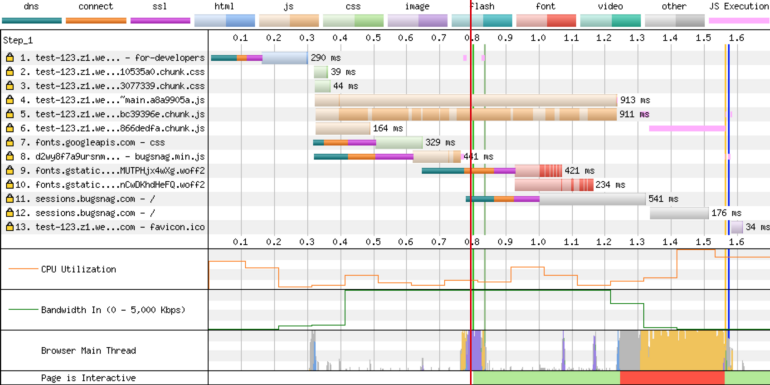
Site metrics after applying server-side rendering and caching. The
red line indicates a timestamp of 800 ms. This is where the content of the page is completely loaded. In addition, here you can see that the JS bundles are loaded at about 1.3 s. But this does not affect the time that the user needs to see the page. At the same time, you do not need to make API calls and load the main thread to display the page.
Pay attention to the fact that temporary indicators regarding loading the JS bundle, executing API requests, and performing operations in the main thread still play an important role in preparing the page for work. This investment of time and resources is required in order for the page to become “interactive”. But this does not play any role, firstly, for search engine bots, and secondly, to create the feeling of “quick page loading” among users.
Suppose a page is “dynamic”. For example, it displays a link in the header to access the user account if the user who is viewing the page is logged in. After server-side rendering, the general-purpose page will be sent to the browser. That is - one that is displayed to users who are not logged in. The title of this page will change, reflecting the fact that the user logged in, only after the JS bundle is loaded and the API calls are made. Here we are dealing with the TTI indicator (Time To Interactive, time to the first interactivity).
A few weeks later, we found that our proxy server does not close the connection with the client where it is needed, in case the server rendering was launched as a background process. Correction of literally one line of code led to the fact that the TTFB indicator was reduced to the level of 50-90 ms. As a result, the site now began to display in the browser after about 600 ms.
However, we faced another problem ...
"In computer science, there are only two complex things: cache invalidation and entity naming."
Phil Carleton
Invalidating a cache is, indeed, a very difficult task. How to solve it? Firstly, you can frequently update the cache by setting a very short storage time for cached objects (TTL, Time To Live, lifetime). This will sometimes cause pages to load more slowly than usual. Secondly, you can create a cache invalidation mechanism based on certain events.
In our case, this problem was solved using a very small TTL of 30 seconds. But we also realized the possibility of providing clients with obsolete data from the cache. At a time when clients receive such data, the cache is being updated in the background. Thanks to this, we got rid of problems, such as delays and "cold start", which are typical for AWS Lambda functions.
Here's how it works. A user visits the Webiny website. We are checking the HTML cache. If there is a screenshot of the page, we give it to the user. The age of a picture can even be a few days. By passing this old snapshot to the user in a few hundred milliseconds, we simultaneously launch the task of creating a new snapshot and updating the cache. It usually takes a few seconds to complete this task, since we created a mechanism thanks to which we always have a certain number of AWS Lambda functions that are already running and ready to work. Therefore, we do not have to, during the creation of new images, spend time on the cold start of functions.
As a result, we always return pages from the cache to clients, and when the age of cached data reaches 30 seconds, the contents of the cache are updated.
Caching is definitely an area in which we can still improve something. For example, we are considering the possibility of automatically updating the cache when the user publishes a page. However, such a cache update mechanism is not ideal either.
For example, suppose the homepage of a resource displays the three most recent blog posts. If the cache is updated when a new page is published, then, from a technical point of view, only the cache for this new page will be generated after publication. The cache for the home page will be outdated.
We are still looking for ways to improve the caching system of our project. But so far, the focus has been on sorting out existing performance issues. We believe that we have done quite a good job in terms of resolving these problems.
At first, we used client-side rendering. Then, on average, the user could see the page in 3.3 seconds. Now, this figure has dropped to about 600 ms. It is also important that we now dispense with the download indicator.
To achieve this result, we were allowed, mainly, the use of server rendering. But without a good caching system, it turns out that the calculations simply transfer from the client to the server. And this leads to the fact that the time required for the user to see the page does not change much.
The use of server rendering has another positive quality, not mentioned earlier. We are talking about the fact that it makes it easier to view pages on weak mobile devices. The speed of preparing a page for viewing on such devices depends on the modest capabilities of their processors. Server rendering allows you to remove part of the load from them. It should be noted that we did not conduct a special study of this issue, but the system that we have should help to improve the viewing of the site on phones and tablets.
In general, we can say that the implementation of server rendering is not an easy task. And the fact that we use a serverless environment only complicates this task. The solution to our problems required code changes, additional infrastructure. We needed to create a well-designed caching mechanism. But in return, we got a lot of good. The most important thing is that the pages of our site are now loading and getting ready for work much faster than before. We believe our users will like it.
Dear readers! Do you use caching and server rendering technologies to optimize your projects?

Training
In order to make measurements that will help identify the problems of the project, we will use webpagetest.org . With the help of this resource, we will fulfill requests and collect information about the execution time of various operations. This will allow us to better understand what users see and feel when working with the project.
We are particularly interested in the “First view” indicator, that is, how long does it take to load a site from a user who visits him for the first time. This is a very important indicator. The fact is that the browser cache is able to hide many bottlenecks of web projects.
Indicators reflecting the features of the site loading - identification of problems
Take a look at the following chart.
Analysis of old and new indicators of a web project
Here, the most important indicator can be recognized as “Time to Start Render” - time before the start of rendering. If you look closely at this indicator, you can see that only in order to start rendering the page, in the old version of the project, it took almost 2 seconds. The reason for this lies in the very essence of Single Page Application (SPA). In order to display the page of such an application on the screen, you first need to load the voluminous JS-bundle (this stage of page loading is marked in the following figure as 1). Then this bundle needs to be processed in the main thread (2). And only after that, something can appear in the browser window.
(1) Download the JS bundle. (2) Waiting for the bundle to be processed in the main thread
However, this is only part of the picture. After the main thread processes the JS bundle, it makes several requests to the Gateway API. At this stage of page processing, the user sees a rotating loading indicator. The sight is not the most pleasant. However, the user has not yet seen any page content. Here is a storyboard of the page loading process.
Loading the page
All this suggests that the user who visited such a site does not have a particularly pleasant experience working with it. Namely, he is forced to look at a blank page for 2 seconds, and then another second - at the download indicator. This second is added to the page preparation time due to the fact that after loading and processing the JS-bundle API requests are executed. These queries are necessary in order to load the data and, as a result, display the finished page.
Page loading
If the project was hosted on a regular VPS, then the time required to complete these API requests would be mostly predictable. However, projects running in a serverless environment are affected by the notorious “cold start” problem. In the case of the Webiny cloud platform, the situation is even worse. AWS Lambda features are part of VPC (Virtual Private Cloud). This means that for each new instance of such a function, you need to initialize ENI (Elastic Network Interface, elastic network interface). This significantly increases the cold start time of functions.
Here are some timelines for loading AWS Lambda features within VPCs and outside of VPCs.
Analysis of AWS Lambda function load inside VPC and outside VPC (image taken from here )
From this we can conclude that in the case when the function is launched inside VPC, this gives a 10-fold increase in cold start time.
In addition, here one more factor must be taken into account - network data transmission delays. Their duration is already included at the time it takes to execute API requests. Requests are initiated by the browser. Therefore, it turns out that by the time the API responds to these requests, the time needed to get the request from the browser to the API, and the time it takes for the response to get from the API to the browser are added. These delays occur during each request.
Optimization tasks
Based on the above analysis, we formulated several tasks that we needed to solve to optimize the project. Here they are:
- Improving the speed of API requests or decreasing the number of API requests that block rendering.
- Reducing the size of the JS bundle or converting this bundle to resources that are not necessary for the output of the page.
- Unlocking the main thread.
Problem Approaches
Here are a few approaches to solving the problems that we considered:
- Code optimization with a view to speeding up its execution. This approach requires a lot of effort, it has a high cost. The benefits that can be obtained as a result of such optimization are doubtful.
- Increase the amount of RAM available to AWS Lambda features. It is easy to do, the cost of such a solution is somewhere between medium and high. Only small positive effects can be expected from the application of this solution.
- The use of some other way to solve the problem. True, at that moment we did not yet know what this method was.
In the end, we chose the third item on this list. We reasoned like this: “What if we absolutely do not need API calls? What if we can do without the JS bundle at all? This would allow us to solve all the problems of the project. ”
The first idea that we found interesting was to create an HTML snapshot of the rendered page and share the snapshot with users.
Unsuccessful attempt
Webiny Cloud is an AWS Lambda-based serverless infrastructure that supports Webiny sites. Our system can detect bots. When it turns out that the request was completed by the bot, this request is redirected to the Puppeteer instance , which renders the page using Chrome without a user interface. The ready-made HTML code of the page is sent to the bot. This was done mainly for SEO reasons, due to the fact that many bots do not know how to execute JavaScript. We decided to use the same approach for preparing pages intended for ordinary users.
This approach works well in environments that lack JavaScript support. However, if you try to give pre-rendered pages to a client whose browser supports JS, the page is displayed, but then, after downloading the JS files, the React components simply do not know where to mount them. This results in a whole bunch of error messages in the console. As a result, such a decision did not suit us.
Introducing SSR
The strong side of Server Side Rendering (SSR) is that all API requests are executed within the local network. Since they are processed by a certain system or function that runs inside the VPC, delays that occur when executing requests from the browser to the resource backend are uncharacteristic. Although in this scenario, the problem of a “cold start” remains.
An additional advantage of using SSR is that we give the client such an HTML version of the page, when working with which, after loading the JS files, the React components do not have problems with mounting.
And finally, we don’t need a very large JS bundle. In addition, we can do without API calls to display the page. A bundle can be loaded asynchronously and this will not block the main thread.
In general, we can say that server rendering, it seems, should have solved most of our problems.
This is how site analysis looks after applying server-side rendering.
Site metrics after applying server rendering
Now API requests are not executed, and the page can be seen before the large JS bundle loads. But if you look closely at the first request, you can see that it takes almost 2 seconds to get a document from the server. Let's talk about it.
Problem with TTFB
Here we discuss the TTFB metric (Time To First Byte, time to first byte). Here are the details of the first request.
Information about the first request
To process this first request, we need to do the following: launch the Node.js server, perform server rendering, making API requests and executing JS code, and then return the final result to the client. The problem here is that all this, on average, takes 1-2 seconds.
Our server, which performs server rendering, needs to do all this work, and only after that it will be able to transmit the first byte of the response to the client. This leads to the fact that the browser has a very long time to wait for the start of the response to the request. As a result, it turns out that now for the output of the page you need to produce almost the same amount of work as before. The only difference is that this work is carried out not on the client side, but on the server, in the process of server rendering.
Here you may have a question about the word "server". We have been talking about the serverless system all this time. Where did this “server" come from? We, of course, tried to render server rendering in AWS Lambda functions. But it turned out that this is a very resource-consuming process (in particular, it was necessary to increase the amount of memory very much in order to get more processor resources). In addition, the “cold start” problem, which we have already mentioned, is also added here. As a result, then the ideal solution was to use a Node.js server that would load the site materials and engage in server-side rendering of them.
Let's go back to the consequences of using server-side rendering. Take a look at the following storyboard. It is easy to see that it is not particularly different from that which was obtained in the study of the project, which was rendered on the client.
Page loading when using server rendering A
user is forced to look at a blank page for 2.5 seconds. It is sad.
Although looking at these results, one might think that we have achieved absolutely nothing, this is actually not so. We had an HTML snapshot of the page containing everything we needed. This shot was ready to work with React. In this case, during the processing of the page on the client, it was not necessary to fulfill any API requests. All the necessary data has already been embedded in HTML.
The only problem was that creating this HTML snapshot took too much time. At this point, we could either invest more time in optimizing server rendering, or simply cache its results and give clients a snapshot of the page from something like a Redis cache. We did just that.
Caching server rendering results
After a user visits the Webiny website, we first of all check the centralized Redis cache to see if there is an HTML snapshot of the page. If so, we give the user a page from the cache. On average, this lowered the TTFB to 200-400 ms. It was after the introduction of the cache that we began to notice significant improvements in project performance.
Page loading when using server-side rendering and cache
Even a user who visits a site for the first time sees the contents of the page in less than a second.
Let's look at how the waterfall diagram now looks.
Site metrics after applying server-side rendering and caching. The
red line indicates a timestamp of 800 ms. This is where the content of the page is completely loaded. In addition, here you can see that the JS bundles are loaded at about 1.3 s. But this does not affect the time that the user needs to see the page. At the same time, you do not need to make API calls and load the main thread to display the page.
Pay attention to the fact that temporary indicators regarding loading the JS bundle, executing API requests, and performing operations in the main thread still play an important role in preparing the page for work. This investment of time and resources is required in order for the page to become “interactive”. But this does not play any role, firstly, for search engine bots, and secondly, to create the feeling of “quick page loading” among users.
Suppose a page is “dynamic”. For example, it displays a link in the header to access the user account if the user who is viewing the page is logged in. After server-side rendering, the general-purpose page will be sent to the browser. That is - one that is displayed to users who are not logged in. The title of this page will change, reflecting the fact that the user logged in, only after the JS bundle is loaded and the API calls are made. Here we are dealing with the TTI indicator (Time To Interactive, time to the first interactivity).
A few weeks later, we found that our proxy server does not close the connection with the client where it is needed, in case the server rendering was launched as a background process. Correction of literally one line of code led to the fact that the TTFB indicator was reduced to the level of 50-90 ms. As a result, the site now began to display in the browser after about 600 ms.
However, we faced another problem ...
Cache invalidation issue
"In computer science, there are only two complex things: cache invalidation and entity naming."
Phil Carleton
Invalidating a cache is, indeed, a very difficult task. How to solve it? Firstly, you can frequently update the cache by setting a very short storage time for cached objects (TTL, Time To Live, lifetime). This will sometimes cause pages to load more slowly than usual. Secondly, you can create a cache invalidation mechanism based on certain events.
In our case, this problem was solved using a very small TTL of 30 seconds. But we also realized the possibility of providing clients with obsolete data from the cache. At a time when clients receive such data, the cache is being updated in the background. Thanks to this, we got rid of problems, such as delays and "cold start", which are typical for AWS Lambda functions.
Here's how it works. A user visits the Webiny website. We are checking the HTML cache. If there is a screenshot of the page, we give it to the user. The age of a picture can even be a few days. By passing this old snapshot to the user in a few hundred milliseconds, we simultaneously launch the task of creating a new snapshot and updating the cache. It usually takes a few seconds to complete this task, since we created a mechanism thanks to which we always have a certain number of AWS Lambda functions that are already running and ready to work. Therefore, we do not have to, during the creation of new images, spend time on the cold start of functions.
As a result, we always return pages from the cache to clients, and when the age of cached data reaches 30 seconds, the contents of the cache are updated.
Caching is definitely an area in which we can still improve something. For example, we are considering the possibility of automatically updating the cache when the user publishes a page. However, such a cache update mechanism is not ideal either.
For example, suppose the homepage of a resource displays the three most recent blog posts. If the cache is updated when a new page is published, then, from a technical point of view, only the cache for this new page will be generated after publication. The cache for the home page will be outdated.
We are still looking for ways to improve the caching system of our project. But so far, the focus has been on sorting out existing performance issues. We believe that we have done quite a good job in terms of resolving these problems.
Summary
At first, we used client-side rendering. Then, on average, the user could see the page in 3.3 seconds. Now, this figure has dropped to about 600 ms. It is also important that we now dispense with the download indicator.
To achieve this result, we were allowed, mainly, the use of server rendering. But without a good caching system, it turns out that the calculations simply transfer from the client to the server. And this leads to the fact that the time required for the user to see the page does not change much.
The use of server rendering has another positive quality, not mentioned earlier. We are talking about the fact that it makes it easier to view pages on weak mobile devices. The speed of preparing a page for viewing on such devices depends on the modest capabilities of their processors. Server rendering allows you to remove part of the load from them. It should be noted that we did not conduct a special study of this issue, but the system that we have should help to improve the viewing of the site on phones and tablets.
In general, we can say that the implementation of server rendering is not an easy task. And the fact that we use a serverless environment only complicates this task. The solution to our problems required code changes, additional infrastructure. We needed to create a well-designed caching mechanism. But in return, we got a lot of good. The most important thing is that the pages of our site are now loading and getting ready for work much faster than before. We believe our users will like it.
Dear readers! Do you use caching and server rendering technologies to optimize your projects?