Hash tables in Go. Implementation details

We will discuss the implementation of map in a language without generics, consider what a hash table is, how it is arranged in Go, what are the pros and cons of this implementation, and what you should pay attention to when using this structure.
Details under the cut.
Attention! If you are already familiar with hash tables in Go, I advise you to skip the basics and go here , otherwise there is a risk of getting tired of the most interesting moment.
What is a hash table
To begin with, I’ll remind you what a hash table is. This is a data structure that allows you to store key-value pairs, and, as a rule, possessing functions:
- Mapping:
map(key) → value - Inserts:
insert(map, key, value) - Removal:
delete(map, key) - Search:
lookup(key) → value
Hash table in go language
A hash table in the go language is represented by the map keyword and can be declared in one of the ways below (more about them later):
m := make(map[key_type]value_type)
m := new(map[key_type]value_type)
var m map[key_type]value_type
m := map[key_type]value_type{key1: val1, key2: val2}
The main operations are performed as follows:
- Insert:
m[key] = value - Removal:
delete(m, key) - Search:
value = m[key]
orvalue, ok = m[key]
Go around a table in go
Consider the following program:
package main
import "fmt"
func main() {
m := map[int]bool{}
for i := 0; i < 5; i++ {
m[i] = ((i % 2) == 0)
}
for k, v := range m {
fmt.Printf("key: %d, value: %t\n", k, v)
}
}
Launch 1:
key: 3, value: false
key: 4, value: true
key: 0, value: true
key: 1, value: false
key: 2, value: true
Run 2:
key: 4, value: true
key: 0, value: true
key: 1, value: false
key: 2, value: true
key: 3, value: false
As you can see, the output varies from run to run. And all because the map in Go is unordered, that is, not ordered. This means that you do not need to rely on order when going around. The reason can be found in the source code of the language runtime:
// mapiterinit initializes the hiter struct used for ranging over maps.
func mapiterinit(t *maptype, h *hmap, it *hiter) {...
// decide where to start
r := uintptr(fastrand())
...
it.startBucket = r & bucketMask(h.B)...}
The search location is determined randomly , remember this! Rumor has it that runtime developers are forcing users not to rely on order.
Go table search
Let's look at a piece of code again. Suppose we want to create pairs "number" - "number times 10":
package main
import (
"fmt"
)
func main() {
m := map[int]int{0: 0, 1: 10}
fmt.Println(m, m[0], m[1], m[2])
}
We launch:
map[0:0 1:10] 0 10 0
And we see that when we tried to get the value of two (which we forgot to put) we got 0. We find lines in the documentation explaining this behavior: “An attempt to fetch a map value with a key that is not present in the map will return the zero value for the type of the entries in the map. ”, but translated into Russian, this means that when we try to get the value from the map, but it’s not there, we get a“ zero type value ”, which in the case of the number 0. What to do, if we want to distinguish between cases 0 and absence 2? To do this, we came up with a special form of “multiple assignment” - a form where instead of the usual one map value returns a pair: the value itself and another boolean that answers the question whether the requested key is present in the map or not. ”
Correctly the previous piece of code will look like this:
package main
import (
"fmt"
)
func main() {
m := map[int]int{0: 0, 1: 10}
m2, ok := m[2]
if !ok {
// somehow process this case
m2 = 20
}
fmt.Println(m, m[0], m[1], m2)
}
And at startup we get:
map[0:0 1:10] 0 10 20
Create a table in Go.
Suppose we want to count the number of occurrences of each word in a string, start a dictionary for this and go through it.
package main
func main() {
var m map[string]int
for _, word := range []string{"hello", "world", "from", "the",
"best", "language", "in", "the", "world"} {
m[word]++
}
for k, v := range m {
println(k, v)
}
}
Do you see a

When we try to start such a program, we get a panic and the message "assignment to entry in nil map". And all because mapa is a reference type and it is not enough to declare a variable, you need to initialize it:
m := make(map[string]int)
A little lower it will be clear why this works this way. In the beginning, there were already presented 4 ways to create a map, two of them we examined - this declaration as a variable and creation through make. You can also create using the " Composite literals " design
map[key_type]value_type{}and if you wish, even immediately initialize with values, this method is also valid. As for the creation using new - in my opinion, it does not make sense, because this function allocates memory for a variable and returns a pointer to it filled with a zero value of the type, which in the case of map will be nil (we get the same result as in var, more precisely a pointer to it).
How is map passed to a function?
Suppose we have a function that tries to change the number that was passed to it. Let's see what happens before and after the call:
package main
func foo(n int) {
n = 10
}
func main() {
n := 15
println("n before foo =", n)
foo(n)
println("n after foo =", n)
}
An example, I think, is quite obvious, but still include the conclusion:
n before foo = 15
n after foo = 15
As you probably guessed, the n function came by value, not by reference, so the original variable has not changed.
Let's do a similar mapa trick:
package main
func foo(m map[int]int) {
m[10] = 10
}
func main() {
m := make(map[int]int)
m[10] = 15
println("m[10] before foo =", m[10])
foo(m)
println("m[10] after foo =", m[10])
}
And lo and behold:
m[10] before foo = 15
m[10] after foo = 10
The value has changed. “Well, Mapa is passed by reference?”, You ask. Not. There are no links in Go. It is impossible to create 2 variables with 1 address, as in C ++ for example. But then you can create 2 variables pointing to the same address (but these are pointers, and they are in Go).
Suppose we have a function fn that initializes map m. In the main function, we simply declare a variable, send it to initialize and look what happened after.
package main
import "fmt"
func fn(m map[int]int) {
m = make(map[int]int)
fmt.Println("m == nil in fn?:", m == nil)
}
func main() {
var m map[int]int
fn(m)
fmt.Println("m == nil in main?:", m == nil)
}
Conclusion: So, the variable m was passed by value , therefore, as in the case of passing a regular int to the function, it did not change (the local copy of the value in fn changed). Then why does the value lying in m itself change? To answer this question, consider the code from the language runtime:
m == nil in fn?: false
m == nil in main?: true
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
Map in Go is just a pointer to the hmap structure. This is the answer to the question why, despite the fact that the map is passed to the function by value, the values themselves in it change - it's all about the pointer. The hmap structure also contains the following: the number of elements, the number of buckets (presented as a logarithm to speed up calculations), seed for randomizing hashes (to make it harder to add - try to pick up keys so that there are continuous collisions), all sorts of service fields and most importantly, a pointer to buckets where the values are stored. Let's look at the picture:
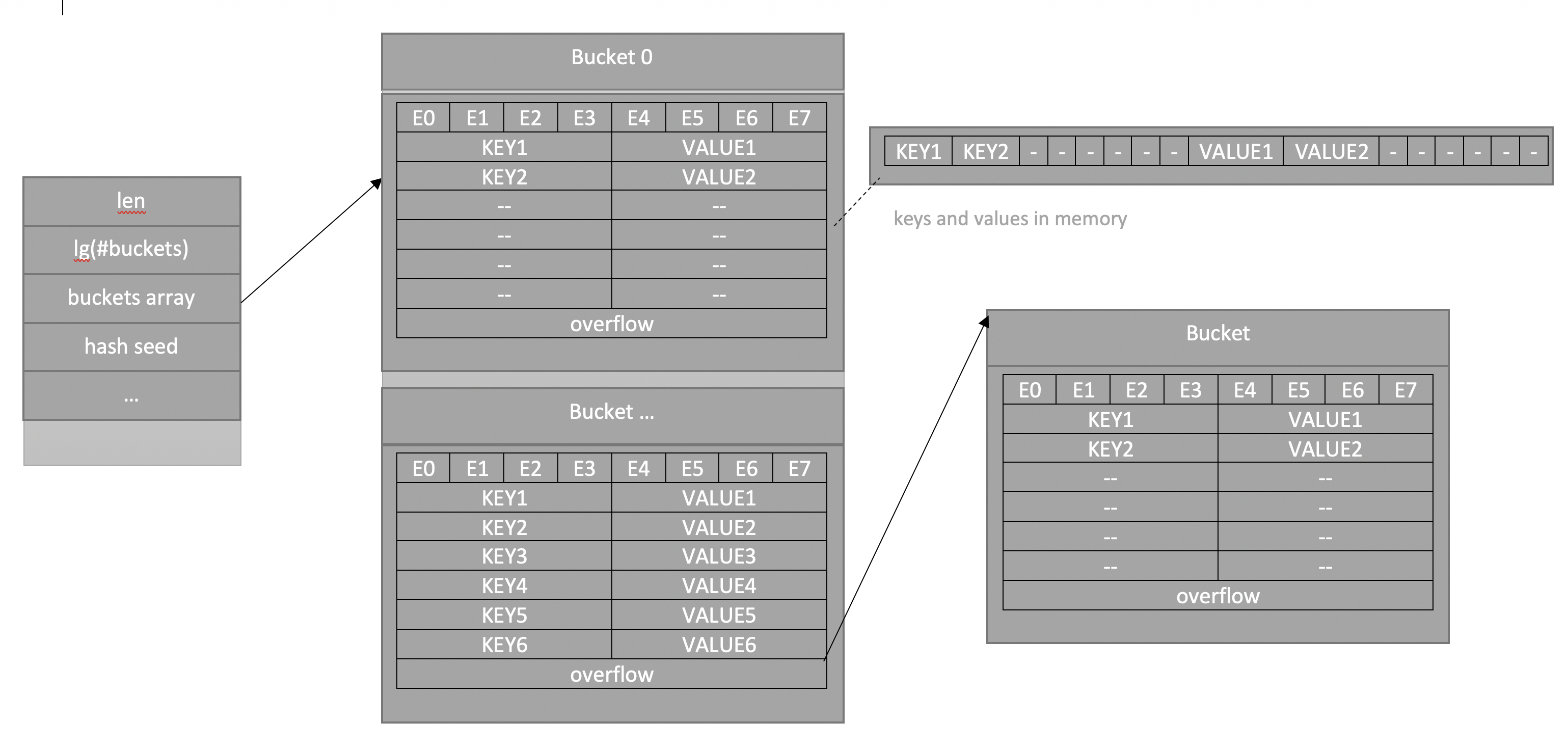
The picture shows a schematic image of the structure in memory - there is a hmap header, the pointer to which is a map in Go (it is created when declared with var, but it is not initialized, which causes the program to crash when trying to insert it). The buckets field is a repository of key-value pairs, there are several such buckets, each contains 8 pairs. First in the “bucket” are slots for additional hash bits (e0..e7 is called e - because extra hash bits). Next are the keys and values as a list of all keys first, then a list of all values.
According to the hash of the function, it is determined in which “bucket” we put the value, inside each “bucket” there can be up to 8 collisions, at the end of each “bucket” there is a pointer to an additional one, if the previous one overflows.
How does the map grow?
In the source code you can find the line:
// Maximum average load of a bucket that triggers growth is 6.5.that is, if there is an average of more than 6.5 elements in each bucket, an increase in the buckets array occurs. At the same time, the array is allocated 2 times more, and the old data is copied into it in small portions every insertion or deletion, so as not to create very large delays. Therefore, all operations will be slightly slower in the process of evacuating data (when searching, too, we have to search in two places). After a successful evacuation, new data begins to be used.

Taking the address of the map element.
Another interesting point - at the very beginning of using the language I wanted to do like this:
package main
import (
"fmt"
)
func main() {
m := make(map[int]int)
m[1] = 10
a := &m[1]
fmt.Println(m[1], *a)
}
But Go says: “cannot take the address of m [1]”. The explanation of why it is impossible to take the address of the value lies in the data evacuation procedure. Imagine that we took the address of the value, and then the mapa grew, new memory was allocated, the data was evacuated, the old ones were deleted, the pointer became incorrect, so such operations are prohibited.
How is map implemented without generics?
Neither an empty interface, nor code generation has anything to do with it; the whole thing is to replace it at compile time. Consider what the familiar functions from Go turn into:
v := m["k"] → func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
v, ok := m["k"] → func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
m["k"] = 9001 → func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
delete(m, "k") → func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
We see that there are mapaccess functions for accesses, for writing and deleting mapassign and mapdelete, respectively. All operations use unsafe.Pointer, which does not care what type it points to, and information about each value is described by a type descriptor .
type mapType struct {
key *_type
elem *_type ...}
type _type struct {
size uintptr
alg *typeAlg ...}
type typeAlg struct {
hash func(unsafe.Pointer, uintptr) uintptr
equal func(unsafe.Pointer, unsafe.Pointer) bool...}
MapType stores the descriptors (_type) of the key and value. For a type descriptor, operations (typeAlg) of comparison, taking a hash, size, and so on are defined, so we always know how to produce them.
A bit more about how it works. When we write v = m [k] (trying to get the value of v from the key k), the compiler generates something like the following:
kPointer := unsafe.Pointer(&k)
vPointer := mapaccess1(typeOf(m), m, kPointer)
v = *(*typeOfvalue)vPointer
That is, we take a pointer to a key, the mapType structure, from which we find out which descriptors of the key and value, the pointer to hmap itself (that is, map) and pass it all to mapaccess1, which will return a pointer to the value. We cast the pointer to the desired type, dereference and get the value.
Now let's look at the search code from runtime (which is slightly adapted for reading):
func lookup(t *mapType, m *mapHeader, key unsafe.Pointer) unsafe.Pointer {
The function searches for the key in the map and returns a pointer to the corresponding value, the arguments are already familiar to us - this is mapType, which stores descriptors of the key types and values, map itself (mapHeader) and a pointer to the memory that stores the key. We return a pointer to the memory that stores the value.
if m == nil || m.count == 0 {
return zero
}
Next, we check if the pointer to the map header is not null, if there are 0 elements there and return a null value, if so.
hash := t.key.hash(key, m.seed) // hash := hashfn(key)
bucket := hash & (1<> 56) // extra := top 8 bits of hash
b := (*bucket)(add(m.buckets, bucket*t.bucketsize)) // b := &m.buckets[bucket]
We calculate the key hash (we know how to calculate for a given key from a type descriptor). Then we try to understand which “bucket” you need to go and see (the remainder of dividing by the number of “buckets”, the calculations are just slightly accelerated). Then we calculate the additional hash (we take the 8 most significant bits of the hash) and determine the position of the “bucket” in memory (address arithmetic).
for {
for i := 0; i < 8; i++ {
if b.extra[i] != extra { // check 8 extra hash bits
continue
}
k := add(b, dataOffset+i*t.key.size) // pointer to ki in bucket
if t.key.equal(key, k) {
// return pointer to vi
return add(b, dataOffset+8*t.key.size+i*t.value.size)
}
}
b = b.overflow
if b == nil {
return zero
}
}
Search, if you look, is not so complicated: we go through the chains of "buckets", moving on to the next one, if you did not find it. The search in the “bucket” begins with a quick comparison of the additional hash (that’s why these e0 ... e7 at the beginning of each are a “mini” hash of the pair for quick comparison). If it doesn’t match, go further, if it does, then we check more carefully - we determine where the key suspected of being searched for lies in the memory, compare whether it is equal to what was requested. If equal, determine the position of the value in memory and return. As you can see, nothing supernatural.
Conclusion
Use maps, but know and understand how they work! You can avoid a rake by understanding some of the subtleties - why it is impossible to take the address of the value, why everything falls during the declaration without initialization, why it is better to allocate memory in advance, if the number of elements is known (we will avoid evacuations) and much more.
References:
“Go maps in action”, Andrew Gerrand
“How the go runtime implements maps efficiently”, Dave Cheney
“Understanding type in go”, William Kennedy
Inside map implementation, Keith Randall
map source code, Go Runtime
golang spec
effective go
pictures with gophers