What is probability and how to calculate it
Let there be some abstract experiment in the process of which a certain event may occur. This experiment was carried out five times, and in four of them the same event took place. What conclusions can be drawn from these 4/5?

There is a Bernoulli formula that gives the answer with what probability 4 out of 5 occurs with a known initial probability. But she does not give an answer, what was the initial probability if the events turned out to be 4 out of 5. Let us leave aside the Bernoulli formula.
Let's make a simple little program that simulates the probability processes for such a case, and based on the result of the calculations we construct a graph.
The code for this program can be found here , along with auxiliary functions.
The calculation was thrown into Excel and made a schedule.

This version of the graph can be called the probability density distribution of the probability value. Its area is equal to the unit that is distributed in this mound.
To complete the picture, I’ll mention that this graph corresponds to the graph according to the Bernoulli formula of the probability parameter and multiplied by N + 1 the number of experiments.
Further in the text, where I use a fraction of the form k / n in the article, this is not a division, this is k events from n experiments, so as not to write k from n each time.
Further. It is possible to increase the number of experiments, and to obtain a narrower region of the location of the main values of the probability value, but no matter how they are increased, this region will not be reduced to the zero region with a well-known probability.
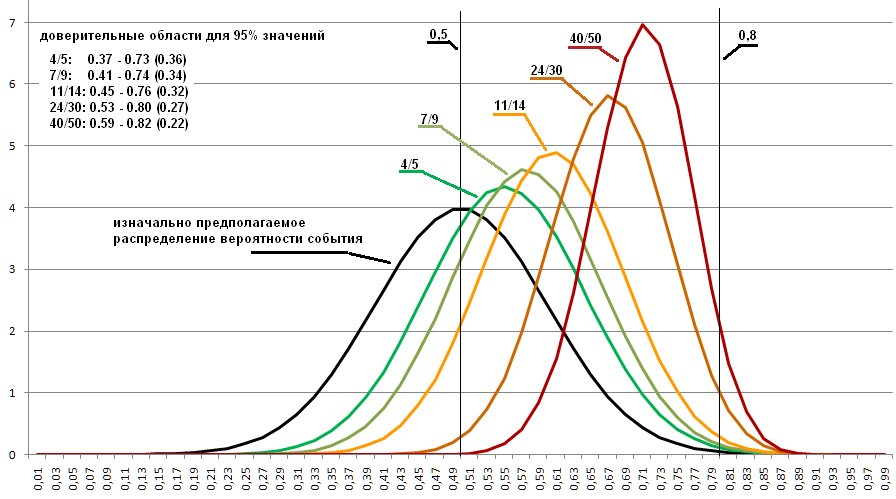
The graph below shows the distributions for 4/5, 7/9, 11/14 and 24/30. The narrower the area, the higher the mound, the area of which is a constant unit. These relations were chosen because they are all about 0.8, and not because it is precisely these that can arise at 0.8 of the initial probability. Selected to demonstrate what range of possible values remains even with 30 experiments performed.
The program code for this graph is here .

From which it follows that in reality the experimental probability cannot be exactly determined, but we can only assume the region of the possible location of such a quantity, with accuracy depending on how many measurements were taken.
No matter how many experiments are carried out, there is always the possibility that the initial probability may turn out to be both 0.0001 and 0.9999. For simplicity, extreme unlikely values are discarded. And we take, say, for example 95% of the main area of the distribution schedule.
Such a thing is called confidence intervals. I have not met any recommendations on how much and why interest should be left. For weather forecast take less, to launch more space shuttles. They also usually do not mention which confidence interval is nevertheless used for the probability of events and whether it is used at all.
In my program, the calculation of the boundaries of the confidence interval is carried out here .
It turned out that the probability of the event is determined by the probability density of the probability value, and it is still necessary to impose a percentage of the region of the main values on it so that you can at least definitely say what kind of probability the event under study is.
Let everyone be bored with a coin, toss this coin, and get 4 out of 5 drops by tails - a very real case. In fact, this is not quite the same as described a little higher. How is this different from the previous experiment?
The previous experiment was described on the assumption that the probability of the event can be equally distributed over the interval from 0 to 1. In the program, this is specified by the line double probability = get_random_real_0_1 (); . But there are no coins with a probability of falling, say, 0.1 or 0.9 are always on one side.
If you take a thousand different coins from ordinary to the most curved, and for each make a measurement of the loss by tossing them a thousand or more times, then it will show that they really fall out on one side in the range from 0.4 to 0.6 (these are random numbers, I won’t but I seek out 1000 coins and toss each 1000 times).
How does this fact change the program for simulating the probabilities of one particular coin, for which 4 out of 5 tails were received?
Suppose that the distribution of the loss on one side for coins is described as an approximation to the graph of the normal distribution taken with parameters average = 0.5, standard deviation = 0.1. (in the graph below it is shown in black).
When in the program I change the generation of the initial probability from equally distributed to distributed according to the specified rule, I get the following graphs:
The code for this option is here .
It can be seen that the distributions have shifted strongly and now determine a slightly different region in which the desired probability is highly probable. Therefore, if it is known what probabilities exist for those things, one of which we want to measure, then this can somewhat improve the result.
As a result, 4/5 does not mean anything, and even 50 of the experiments performed are not very informative. This is very little information to determine what kind of probability still underlies the experiment.
== Update ==
As jzha mentioned in the comments, a person who knows mathematics significantly, these graphs can also be constructed using exact formulas. But the purpose of this article is still to demonstrate as clearly as possible how what everyone in everyday life calls probability is formed.
In order to build it using exact formulas, it is necessary to consider the available data on the probability distribution of all coins through the approximation of the beta distribution, and by calculating the distributions, already calculate the calculations. Such a scheme is a substantial amount of explanations on how to do this, and if I describe it here, it will turn out to be an article on mathematical calculations, rather than everyday probabilities.
How to get the formulas described a special case with a coin, see comments from jzha .
There is a Bernoulli formula that gives the answer with what probability 4 out of 5 occurs with a known initial probability. But she does not give an answer, what was the initial probability if the events turned out to be 4 out of 5. Let us leave aside the Bernoulli formula.
Let's make a simple little program that simulates the probability processes for such a case, and based on the result of the calculations we construct a graph.
void test1() {
uint sz_ar_events = 50; // замеряемых точек графика
uint ar_events[sz_ar_events]; // в этом массиве сбор данных для графика
for (uint i = 0; i < sz_ar_events; ++i) ar_events[i] = 0;
uint cnt_events = 0; // сколько уже событий в точках графика
uint k = 4; // k событий из n экспериментов
uint n = 5;
// НАКОПЛЕНИЕ СТАТИСТИКИ
while (cnt_events < 1000000) {
// случайный выбор предполагаемой вероятности
// эксперимента, из диапазона 0..1
double probability = get_random_real_0_1();
uint c_true = 0;
for (uint i = 0; i < n; ++i) {
// вероятность события в эксперименте probability,
// и n-раз взяли истина или ложь с выбранной этой вероятностью
bool v = get_true_with_probability(probability);
if (v) ++c_true;
}
// если из n-раз получили k-раз истину, значит это тот самый случай
if (c_true == k) {
uint idx = lrint(floor(probability*sz_ar_events));
assert( idx < sz_ar_events ); // проверка, что с округлением не напутал
++cnt_events; // всего событий
++ar_events[idx]; // событий в этой точке графика
}
}
// ВЫВОД РЕЗУЛЬТАТА
for (uint i = 0; i < sz_ar_events; ++i) {
double p0 = DD(i)/sz_ar_events;
// плотность вероятности:
// вероятность на отрезке деленное на протяженность отрезка
double v = DD(ar_events[i])/cnt_events / (1.0/sz_ar_events);
printf("%4.2f %f\n", p0, v);
}
}The code for this program can be found here , along with auxiliary functions.
The calculation was thrown into Excel and made a schedule.
This version of the graph can be called the probability density distribution of the probability value. Its area is equal to the unit that is distributed in this mound.
To complete the picture, I’ll mention that this graph corresponds to the graph according to the Bernoulli formula of the probability parameter and multiplied by N + 1 the number of experiments.
Further in the text, where I use a fraction of the form k / n in the article, this is not a division, this is k events from n experiments, so as not to write k from n each time.
Further. It is possible to increase the number of experiments, and to obtain a narrower region of the location of the main values of the probability value, but no matter how they are increased, this region will not be reduced to the zero region with a well-known probability.
The graph below shows the distributions for 4/5, 7/9, 11/14 and 24/30. The narrower the area, the higher the mound, the area of which is a constant unit. These relations were chosen because they are all about 0.8, and not because it is precisely these that can arise at 0.8 of the initial probability. Selected to demonstrate what range of possible values remains even with 30 experiments performed.
The program code for this graph is here .
From which it follows that in reality the experimental probability cannot be exactly determined, but we can only assume the region of the possible location of such a quantity, with accuracy depending on how many measurements were taken.
No matter how many experiments are carried out, there is always the possibility that the initial probability may turn out to be both 0.0001 and 0.9999. For simplicity, extreme unlikely values are discarded. And we take, say, for example 95% of the main area of the distribution schedule.
Such a thing is called confidence intervals. I have not met any recommendations on how much and why interest should be left. For weather forecast take less, to launch more space shuttles. They also usually do not mention which confidence interval is nevertheless used for the probability of events and whether it is used at all.
In my program, the calculation of the boundaries of the confidence interval is carried out here .
It turned out that the probability of the event is determined by the probability density of the probability value, and it is still necessary to impose a percentage of the region of the main values on it so that you can at least definitely say what kind of probability the event under study is.
Now, about a more real experiment.
Let everyone be bored with a coin, toss this coin, and get 4 out of 5 drops by tails - a very real case. In fact, this is not quite the same as described a little higher. How is this different from the previous experiment?
The previous experiment was described on the assumption that the probability of the event can be equally distributed over the interval from 0 to 1. In the program, this is specified by the line double probability = get_random_real_0_1 (); . But there are no coins with a probability of falling, say, 0.1 or 0.9 are always on one side.
If you take a thousand different coins from ordinary to the most curved, and for each make a measurement of the loss by tossing them a thousand or more times, then it will show that they really fall out on one side in the range from 0.4 to 0.6 (these are random numbers, I won’t but I seek out 1000 coins and toss each 1000 times).
How does this fact change the program for simulating the probabilities of one particular coin, for which 4 out of 5 tails were received?
Suppose that the distribution of the loss on one side for coins is described as an approximation to the graph of the normal distribution taken with parameters average = 0.5, standard deviation = 0.1. (in the graph below it is shown in black).
When in the program I change the generation of the initial probability from equally distributed to distributed according to the specified rule, I get the following graphs:
The code for this option is here .
It can be seen that the distributions have shifted strongly and now determine a slightly different region in which the desired probability is highly probable. Therefore, if it is known what probabilities exist for those things, one of which we want to measure, then this can somewhat improve the result.
As a result, 4/5 does not mean anything, and even 50 of the experiments performed are not very informative. This is very little information to determine what kind of probability still underlies the experiment.
== Update ==
As jzha mentioned in the comments, a person who knows mathematics significantly, these graphs can also be constructed using exact formulas. But the purpose of this article is still to demonstrate as clearly as possible how what everyone in everyday life calls probability is formed.
In order to build it using exact formulas, it is necessary to consider the available data on the probability distribution of all coins through the approximation of the beta distribution, and by calculating the distributions, already calculate the calculations. Such a scheme is a substantial amount of explanations on how to do this, and if I describe it here, it will turn out to be an article on mathematical calculations, rather than everyday probabilities.
How to get the formulas described a special case with a coin, see comments from jzha .