How we automated a large online store and began to match products automatically

The article is more technical than about business, but we will also draw some conclusions from the point of view of business. Most attention will be paid to the automatic comparison of goods from different sources.
The work of the online store consists of a fairly large number of components. And no matter what the plan is, to make a profit right now, or to grow and look for investors, or, for example, to develop related areas, at least you will have to close these questions:
- Work with providers. To sell something unnecessary, you must first buy something unnecessary.
- Directory Management. Someone has a narrow specialization, while someone sells hundreds of thousands of different goods.
- Retail price management. Here you will have to take into account the prices of suppliers, and the prices of competitors, and affordable financial instruments.
- Work with the warehouse. In principle, it is possible not to have your own warehouse, but to take the goods from the warehouses of partners, but one way or another the question is.
- Marketing. Here is filling the site with content, placing on sites, advertising (online and offline), promotions and much more.
- Reception and processing of orders. Call center, basket on the site, orders through instant messengers, orders through platforms and marketplaces.
- Delivery.
- Accounting and other internal systems.
The store, which we will talk about, does not have a narrow specialization, but offers a bunch of everything from cosmetics to a mini-tractor. I will tell you how we work with suppliers, monitoring competitors, catalog management and pricing (wholesale and retail), working with wholesale customers. A little touch on the topic of the warehouse.
In order to better understand some technical solutions, it will not be superfluous to know that at
some point we decided that we would do technological things, if possible, not for ourselves, but universal. And, perhaps, after several attempts, it will come out to develop a new business. It turns out, conditionally, a startup within the company.
So we are considering a separate system, more or less universal, with which the rest of the company's infrastructure is integrated.
What is the problem of working with suppliers?
And there are a lot of them, in fact. Just to give some:
- There are many suppliers per se. We have about 400. Everyone needs to take some time.
- There is no single way to get offers from suppliers. Someone sends to the mail on schedule, someone on request, someone uploads to file hosting, someone places on the site. There are many ways, up to sending the file via skype.
- There is no single data format. I even drew a picture on this subject (it is lower, tables symbolize different formats).
- There is the concept of minimum retail and minimum wholesale prices that must be observed in order to continue working with the supplier. Often they are provided in their own format.
- The nomenclature of each supplier is different. As a result, the same product is called differently, and there is no unique key by which they can be easily compared. Therefore, we compare it difficult.
- The system of placing an order with the supplier is not automated. We order from someone on Skype, from someone in your personal account, to someone we send an exel file every evening with a list of orders.

We have learned to cope with these problems. In addition to the latter, work on the latter is in progress. Now there will be technical details, and then consider the following list.
Collecting data
As it was
Supplier files were manually collected from various sources and prepared. Preparation included renaming according to a specific template and editing the content. Depending on the file, it was necessary to remove non-standard goods, goods that are not in stock, rename columns or convert currency, collect data from different tabs on one.
How did
First of all, we learned to check mail and pick up letters with attachments from there. Then they automated the work with direct links and links to Yandex and Google drives. This resolved the issue of receiving offers from approximately 75% of our suppliers. We also noticed that it is through these channels that offers are more often updated, so that the real percentage of automation is more. We still get some prices in messengers.
Secondly, we no longer process files manually. To do this, we have entered supplier profiles, where you can specify which column and tab to use, how to determine the currency and availability, delivery time, and the supplier’s work schedule.
It turned out flexibly. Naturally, we didn’t take everything into account the first time, but now there is enough flexibility to configure the processing of all 400 providers, given that everyone has different file formats.
As for file formats, we understand xls, xlsx, csv, xml (yml). In our case, this was enough.
They also figured out how to filter records. We made a list of stop words, and if the offer of the supplier contains it, then we do not process it. Technical details are as follows: on a small list you can and even better “head-on”, on large lists faster Bloom filter. We experimented with him and left everything as it is, because the gain is felt on the list an order of magnitude larger than ours.
Another important thing is the supplier’s work schedule. Our suppliers work on different schedules, in addition, they are located in different countries, on which weekends do not coincide. And delivery time is usually indicated as a number or a range of numbers in business days. When we form the retail and wholesale prices, we will have to somehow evaluate the time when we can deliver the goods to the client. To do this, we have created configurable calendars, and in the settings of each provider you can specify which of the calendars it works on.
I had to make a configuration of discounts and margins depending on the category and manufacturer. It happens that the supplier has a common file for all partners, but there are discount agreements with some partners. Thanks to this, it was still possible to add or subtract VAT if necessary.
By the way, the configuration of the rules of discounts and margins leads us to the next topic. After all, before using them, you need to find out what kind of product it is.
How mapping works
A small example of how the same product can be called from different suppliers to understand what you will have to work with:
Monitor LG LCD 22MP48D-P
21.5 "LG 22MP48D-P Black (16: 9, 1920x1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Computer Peripherals - Monitors LG 22MP48D-P
up to 22" inclusive LG Monitor LG 22MP48D-P (21.5 ", black, IPS LED 5ms 16: 9 DVI matte 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Monitors LG 22" LG 22MP48D-P Glossy-Black (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) Monitor
LCD monitors LG LCD monitor 22 "IPS 22MP48D-P LG 22MP48D-P
LG Monitor 21.5" LG 22MP48D-P gl.Black IPS, 1920x1080, 5ms , 250 cd / m2, 1000: 1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
LG Monitor LG 22MP48D-P Black 22MP48D-P.ARUZ
Monitor LG 22MP48D-P 22MP48D- P
Monitors LG 22MP48D-P Glossy-Black 22MP48D-P
Monitor 21.5 "LG Flatron 22MP48D-P gl.Black (IPS, 1920x1080, 16: 9, 178/178, 250cd / m2, 1000: 1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Monitor 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5" 22MP48D-P IPS LED, 1920x1080, 5ms, 250cd / m2, 5Mln: 1, 178 ° / 178 °, D-Sub, DVI, Tilt, VESA , Glossy Black 22MP48D-P
LG 21.5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Monitor 21.5`` LG 22MP48D-P Black
LG MONITOR 21.5" LG 22MP48D-P Glossy-Black (IPS, LED , 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) 22MP48D-P
LG Monitor 21.5 '' LCD [16: 9] 1920x1080 (FHD) IPS, nonGLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P
LCD LG 21.5 "22MP48D-P black {IPS LED 1920x1080 5ms 16: 9 250cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitors LG LG 22" LCD 22MP48D 22MP48D-P
21.5 "16x9 LG Monitor LG 21.5" 22MP48D-P black IPS LED 5ms 16: 9 DVI matte 250cd 1920x1080 D-Sub FHD 2.7kg 22MP48D-P.ARUZ
Monitor 21.5 "LG 22MP48D-P [Black]; 5ms; 1920x1080, DVI, IPS
As it was
Comparison involved 1C (third-party paid module). As for convenience / speed / accuracy, such a system made it possible to maintain a catalog with 60 thousand products available at this level by 6 people. That is, every day, outdated and disappeared from the suppliers' offers, as many matched goods as new ones were created. Very approximately - 0.5% of the catalog size, i.e. 300 products.
How it became: a general description of the approach
A little higher, I gave an example of what we need to match. Exploring the topic of matching, I was a little surprised that ElasticSearch is popular for the task of matching, in my opinion, it has conceptual limitations. As for our technology stack, we use MS SQL Server for data storage, but the comparison works on our own infrastructure, and since there is a lot of data and we need to process it quickly, we use data structures optimized for a specific task and try not to access the disk or database without the need and other slow systems.
Obviously, the comparison problem can be solved in many ways and obviously, none of them will give absolute accuracy. Therefore, the main idea is to try to combine these methods, rank them by accuracy and speed and apply them in descending order of accuracy, taking into account speed.
The execution plan for each of our algorithms (with a reservation about degenerate cases) can be briefly represented by the following general sequence:
Tokenization. We break the source line into something meaningful independent parts. It can be done once and further used in all algorithms.
Normalization of tokens. In a good way, you need to bring the words of the natural language to the general number and declension, and identifiers like “ABC15MX” (this is Cyrillic, if that) should be converted to Latin. And bring everything to the same register.
Token categorization. Trying to understand what each part means. For example, you can select a category, manufacturer, color, and so on.
Search for the best candidate for a match.
An estimate of the likelihood that the original line and the best candidate do indicate the same product.
The first two points we have in common for all the algorithms that are at the moment, and then improvisations begin.
Tokenization Here we did just that, we break the line into parts according to special characters such as space, slash, and so on. The character set over time turned out to be significant, but we did not use anything complicated in the algorithm itself.
Then we need to normalize the tokens. Convert them to lowercase. Instead of leading everything to the nominative case, we simply cut off the endings. We also have a small dictionary, and we translate our tokens into English. Among other things, the translation saves us from synonyms, similar in meaning Russian words are translated into English in the same way. Where we failed to translate, we change the Cyrillic characters similar in writing to the Latin alphabet. (It’s not at all superfluous, as it turned out. Even where you do not expect a dirty trick, for example, in the line “Samsung UЕ43NU7100U” the Cyrillic E can quite meet).

Token categorization. We can highlight the category, manufacturer, model, article, EAN, color. We have a directory where the data is structured. We have data on competitors that trading platforms provide to us. When processing them, where possible, we structure the data. We can correct errors or typos, for example, the manufacturer or color, which occur only once in all our sources, not to consider the manufacturer and color, respectively. As a result, we have a large dictionary of possible manufacturers, models, articles, colors, and token categorization is just a dictionary search for O (1). Theoretically, you can have an open list of categories and some kind of smart classification algorithm, but our basic approach works well, and categorization is not a bottleneck.
It should be noted that sometimes the supplier provides already structured data, for example, the article is in a separate cell in the table, or the supplier makes a discount on retail at wholesale sales, and retail prices can be obtained in yml (xml) format. Then we save the data structure, and heuristically divide the tokens into categories only from unstructured data.
And now about what algorithms and in what order we use.
Exact and almost exact matches
The simplest case. The lines were divided into tokens, they led them to one form. Then they came up with a hash function that is not sensitive to the order of tokens. In addition, by matching by hash, we can keep all the data in memory, we can afford 16 megabytes per dictionary with a million keys. In practice, the algorithm performed better than simple string comparisons.
As for hashing, the use of "exclusive or" suggests itself, and a function like this:
public static long GetLongHashCode(IEnumerable tokens)
{
long hash = 0;
foreach (var token in tokens.Distinct())
{
hash ^= GetLongHashCode(token);
}
return hash;
} The most interesting thing at this stage is getting the hash of a single line. In practice, it turned out that 32 bits are small, a lot of collisions are obtained. And also - that you can’t just take the source code of the function from the framework and change the type of the return value, there are less collisions for individual lines, but after the “exclusive or” they still occur, so we wrote our own. In fact, they simply added to the function from the nonlinearity framework from the input data. It was definitely better, with the new function with a collision, we met only once on our millions of records, recorded and postponed until better times.
Thus, we are looking for matches without taking into account the word order and their form. Such a search works for O (1).
Unfortunately, rarely, but it happens like this: “ABC 42 Type 16” and “ABC 16 Type 42”, and these are two different products. We also learned to deal with such things, but more on that later.
Matching Human Confirmed Products
We have products that are manually matched (most often these are products that are matched automatically, but that have been manually checked). In fact, we are doing the same thing in this case, only now we have added a dictionary of matching hashes, the search for which did not change the time complexity of the algorithm.
Manually matched lines simply lie in the database, just in case, such raw data will allow you to change the hashing algorithm in the future, recalculate everything and lose nothing.
Attribute Mapping
The first two algorithms are fast and accurate, but not enough. Next we apply attribute matching.
Previously, we already presented data in the form of normalized tokens and even sorted them into categories. In this chapter, I call token categories attributes.
The most reliable attribute is EAN (https://ru.wikipedia.org/wiki/European_Article_Number). EAN matches give you almost a 100% guarantee that they are the same product. EAN mismatch, however, does not say anything, because one product may have different EANs. Everything would be fine, but in our data EAN is rare, therefore its influence on the comparison at the level of error.
The article is less reliable. Something strange often comes directly from the structured data of the supplier, but in any case, at this stage we use it.
As at the last stage, here we use dictionaries (search for O (1)), and the hash from (manufacturer + model + article) is used as the key. Hashing allows you to perform all operations in memory. In this case, we also take into account the color, if it matches or does not exist, then we believe that the goods coincided.
Search for the best match
The previous steps were simple, fast, and fairly reliable, but unfortunately they cover less than half of the comparisons.
In the search for the best match, there is a simple idea: the coincidence of rare tokens has a large weight, the coincidence of frequent tokens is small. Tokens containing numbers are valued more than letter tokens. Tokens that match in the same order are valued more than tokens that are rearranged. Long matches are better than short ones.
Now it remains to come up with a fast data structure that can take all this into account at the same time and fits into the memory of a directory of a couple of million records.
We came up with the idea of presenting our catalog in the form of a dictionary of dictionaries; on the first level, the key will be a hash from the manufacturer (the data in the catalog are structured, we know the manufacturer), the value is the dictionary. Now the second level. The key at the second level will be the hash from the token, the value is the list of id items from the catalog where this token is found. And in this case, we use including combinations of tokens in the order in which they appear in our catalog. We decide what to use as a combination, and what is not, depending on the number of tokens, their length and so on, this is a compromise between speed, accuracy and the required memory. In the figure, I simplified this structure, without hashes and without normalization.
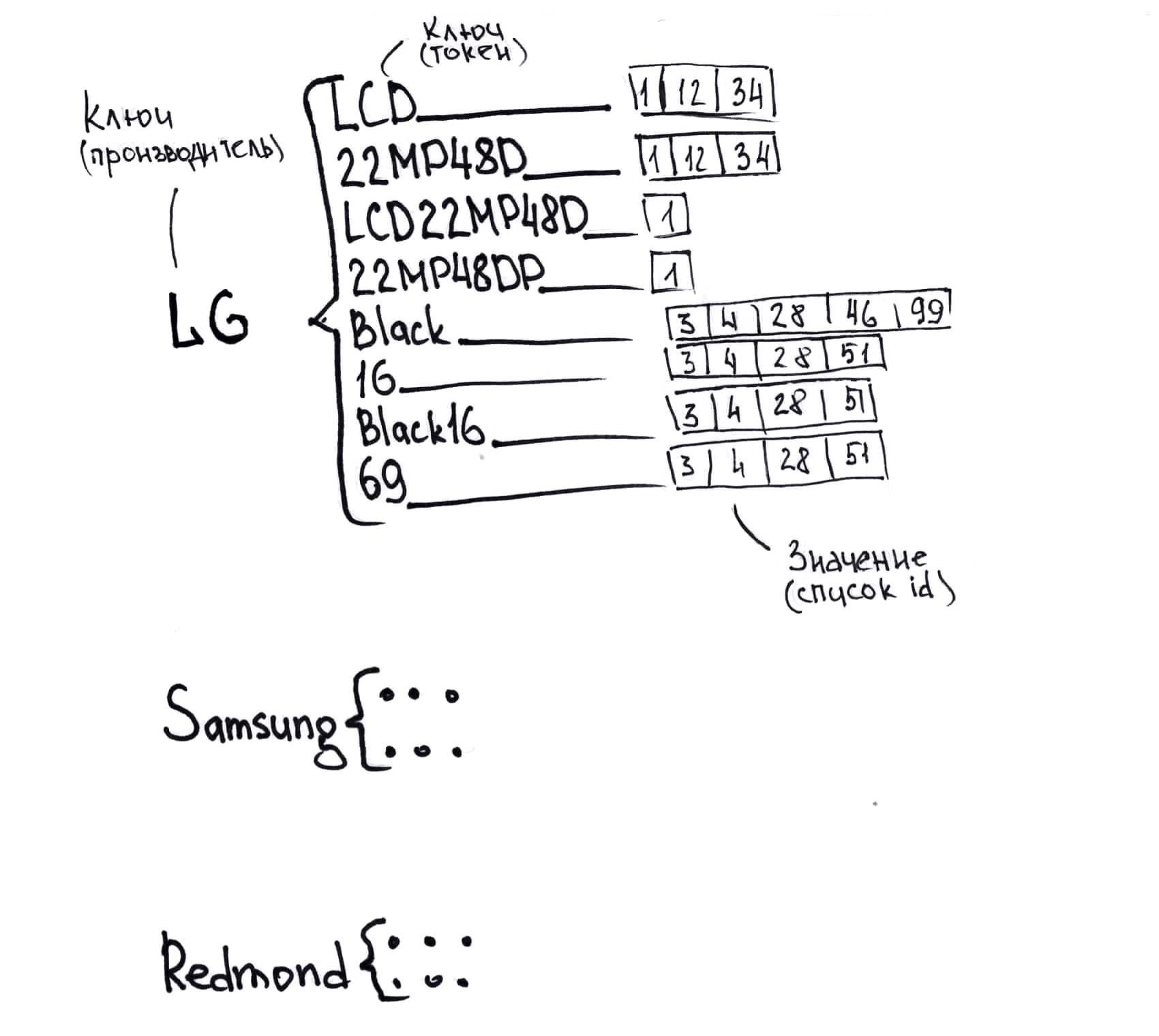
If on average 20 tokens are used for each product, then in our lists that contain the values of the enclosed dictionary, a link to the product will occur on average 20 times. There will be no more than 20 times different tokens than there are goods in the catalog. Approximately, you can calculate the memory required for a catalog of a million records: 20 million keys, 4 bytes each, 20 million product id, 4 bytes each, overhead for organizing dictionaries and lists (the order is the same, but since the size of lists and dictionaries we do not know in advance, but increase on the go, multiply by two). Total - 480 megabytes. In reality, it turned out a little more tokens for goods, and we need up to 800 megabytes per catalog of a million goods. Which is acceptable, the capabilities of modern iron allow you to simultaneously store in memory more than a hundred directories of this size.
Back to the algorithm. Having a string that we need to match, we can determine the manufacturer (we have a categorization algorithm), and then get tokens using the same algorithm as for goods from the catalog. Here I mean including combinations of tokens.
Then everything is relatively simple. For each token, we can quickly find all the products in which it is found, estimate the weight of each match, taking into account all that we talked about earlier - length, frequency, the presence of numbers or special characters, and evaluate the “similarity” of all the candidates found. In reality, there are also optimizations here, we do not consider all candidates, first we form a small list of matches of tokens with a large weight, and we do not apply matches of tokens with a low weight to all products, but only to this list.
We select the best match, look at the coincidence of the tokens that turned out to be categorized and consider the comparison score. Further, we have two threshold values P1 and P2, P1 <P2. If the assessment turned out to be more than the threshold value P2 - human participation is not required, everything happens automatically. If between two values - we offer to see the comparison manually, before that it will not participate in pricing. If less than P1 - most likely, such a product is not in the catalog, we do not return anything.
Back to the lines “ABC 42 Type 16” and “ABC 16 Type 42”. The solution is surprisingly simple - if several products have the same hashes, then we do not match them by hash. And the last algorithm will take into account the order of tokens. Theoretically, such lines in the supplier’s price list cannot be matched with anything arbitrary, where the numbers 16 and 42 do not occur at all. In fact, we did not encounter such a need.
Speed and accuracy
Now for the speed of it all. The time required to prepare the dictionaries linearly depends on the size of the catalog. The time required directly for comparison, linearly depends on the number of goods being compared. All data structures involved in the search are not changed after creation. This gives us the opportunity to use multithreading at the matching stage. The preparatory work for the catalog of a million records takes about 40-80 seconds. The comparison works at a speed of 20-40 thousand records per second and does not depend on the size of the directory. Then, however, you need to save the results. The approach chosen is generally beneficial for large volumes, but a file with a dozen records will be disproportionately long. Therefore, we use the cache and recount our search structures once every 15 minutes.
True, the data for comparison needs to be read somewhere (most often this is an excel file), and the matching sentences need to be saved somewhere, and this also takes time. So the total number is 2-4 thousand records per second.
In order to evaluate the accuracy, we prepared a test suite of approximately 20,000 manually verified comparisons of different suppliers from different categories. After each change, the algorithm was tested on this data. The results are as follows:
- the goods are in the catalog and were compared correctly - 84%
- the product is in the catalog, but has not been matched, manual matching is required - 16%
- the goods are in the catalog and were compared incorrectly - 0.2%
- the product is not in the catalog, and the program correctly identified it - 98.5%
- the product is not in the catalog, but the program matched it to one of the products - 1.5%
In 80% of cases when the product was matched, manual confirmation is not required (we automatically confirm the comparison), among such automatically confirmed offers are 0.1% of errors.
By the way, 0.1% of errors is a lot, it turns out. For a million records matched, this is a thousand records matched incorrectly. And this is a lot because buyers find exactly such records best. Well, how not to order a tractor for the price of the headlights from this tractor. However, this thousand errors is at the start of work on a million proposals, they were gradually corrected. Quarantine for suspicious prices, which closes this issue, appeared later, the first couple of months we worked without it.
There is another category of errors that is not related to comparison; these are incorrect prices of our suppliers. This is partly why we do not take price into account in comparison. We decided that since we have additional information in the form of a price, we will use it to try to determine not only our own mistakes, but also those of others.
Search for the wrong prices
This is the part that we are actively experimenting on. The basic version is, and it does not allow you to sell the phone at the price of a case, but I have a feeling that it is better.
For each product we find the boundaries of acceptable supplier prices. Depending on what data is available, we take into account the prices of suppliers for this product, prices of competitors, prices of suppliers of goods of this manufacturer in this category. Those prices that do not fall within the borders are quarantined and ignored in all our algorithms. Manually, you can mark such a suspicious price as normal, then we remember this for this product and recount the boundaries of acceptable prices.
The direct algorithm for calculating the maximum and minimum acceptable prices is now constantly changing, we are looking for a compromise between the number of false positives and the number of detected incorrect prices.
We use median values in the calculations (averages give the worst result) and do not yet analyze the distribution form. The analysis of the distribution form is just the place where, it seems to me, the algorithm can be improved.
Work with the database
From all the above, we can conclude that we update the data on suppliers and competitors often and in many ways, and working with the database can become a bottleneck. In principle, we initially drew attention to this and tried to achieve maximum performance. When working with a large number of records, we do the following:
- we delete indexes from the table with which we work
- disable full text indexing on this table
- delete all records with a certain condition (for example, all offers of specific suppliers that we are currently processing)
- insert new records with BULK COPY
- re-create indexes
- enable full text indexing
Bulk copy operates at a speed of 10-40 thousand records per second, why such a large spread remains to be seen, but it is so acceptable.
Deleting records takes about the same time as inserting. Still some time is required to recreate the indices.
By the way, for each directory we have a separate database. We create them on the fly. And now I’ll tell you why we have more than one catalog.
What is the problem of cataloging
And there are a lot of them too. Now we will list:
- The catalog contains about 400 thousand products from completely different categories. It is impossible to professionally understand each of the categories.
- You need to follow a certain style, follow the general rules for the name of the catalog, naming subcategories, and so on. Thus we are trying to achieve a coherent and logical directory structure.
- You can create the same product several times, and this is a problem. Without a tool that analyzes similar names, duplicates are constantly being created.
- It is reasonable to add to the catalog those goods that suppliers have in stock. In this case, you need to have priorities for product categories.
- We need several directories. One of our own, we conduct it ourselves, the other - the aggregator catalog, we update it by api. The meaning of the second catalog is that the aggregator platform only works with its own catalog, and, accordingly, accepts offers in its nomenclature. This is another place where it turned out to need a comparison.
We thought it logical and correct to maintain a directory in the same place where comparisons are made. So we can tell the users who administer the directory what the supplier has, but not in the directory.
How we catalog
It will be about the catalog without detailed characteristics, the characteristics are a separate big story, about it some other time.
As the basic properties, we chose the following:
- manufacturer
- category
- model
- vendor code
- Colour
- Ean
First, we made api to get the catalog from an external source, and then we worked on the convenience of creating, editing and deleting entries.
How search works
The convenience of managing a catalog, first of all, is the ability to quickly find a product in a catalog or a supplier’s offer, and there are nuances. For example, you need to be able to search for the line “LG 21.5” 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P ”for“ 2MP48. ”A
full-text sql server search out of the box is not suitable, because it doesn’t know how, and the search with LIKE '% 2MP48%' is too slow.
Our solution is fairly standard, we use N-grams. Trigrams, to be more precise. We already build a full-text index and perform a full-text search using trigrams. I’m not sure that we use it very rationally place in this case, but the speed of such a solution came up, depending on the request, it works from 50 to 500 milliseconds , sometimes up to a second on an array of three million records.
Let me explain, the line “LG 21.5” 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P ”is converted to the line“ lg2 g21 215 152 522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22 ”, which is stored in a separate field, which participates in the full-text index.
By the way, trigrams are still useful to us.
Create a new product
For the most part, products in the catalog are created at the suggestion of the supplier. That is, we already have information that the supplier offers “LG LCD Monitor 21.5 '' [16: 9] 1920x1080 (FHD) IPS, nonGLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5ms, VGA, DVI, Tilt, 2Y, Black OK 22MP48D-P ”at a price of $ 120, and he has 5 to 10 units in stock.
When creating a product, first of all, we need to make sure that such a product has not yet been created in the catalog. We solve this problem in four stages.
Firstly, if we have a product in the catalog, it is very likely that the supplier’s proposal will be matched to this product automatically.
Secondly, before showing the user the form for creating a new product, we will perform a search by trigrams and show the most relevant results. (technically this is done using CONTAINSTABLE).
Thirdly, as we fill out the fields for a new product, we will show similar existing products. This solves two problems: it helps to avoid duplicates and maintain the style in the names, similar products can be used as a model.
And fourth, remember, we broke the lines into tokens, normalized them, counted hashes? We will do the same and just will not let create goods with the same hashes.
At this stage, we try to help the user. By the line that is in the price list, we will try to determine the manufacturer, category, article, EAN and color of the goods. First, by tokens (we can divide them into categories), then, if it doesn’t work out, we will find the most similar product by trigrams. And, if it is similar enough, fill in the manufacturer and category.
Product editing works almost the same, just not everything is applicable.
How we set our prices
The task is this: to maintain a balance between the quantity and margin of sales, in fact - to achieve maximum profit. All other aspects of the store’s work are also about this, but exactly what happens at the stage of pricing has the greatest impact.
At a minimum, we need information on offers from suppliers and competitors. It is also worth considering the minimum retail and wholesale prices and delivery costs, as well as financial instruments - loans and installments.
We collect competitor prices
To begin with, we have many profiles of our own prices. There is a profile for retail, there are several for wholesale customers. All of them are created and configured in our system.
Accordingly, the competitors for each profile are different. In retail - other retail stores, in wholesale sales - our same suppliers.
Everything is clear with suppliers, but for retail we collect competitor data in several ways. Firstly, some aggregators provide information on all prices for all goods that are on the site. In our own nomenclature, but we can match products, so it works automatically. And this is almost enough for now. Secondly, we have competitors parsers. Since they are not yet automated and exist in the form of console applications (which sometimes crash), we rarely use them.
Customize your profile
In the profile, we have the opportunity to configure different ranges of margins depending on the price of the goods from the supplier, category, manufacturer, supplier. It is still possible to indicate with which suppliers in which category or manufacturer we are working, and with which - not, which of the competitors we take into account.
Then we set up financial instruments, indicate which installments are available and how much the bank will take for itself.
And already within the margins of margins, we form our own prices, trying to maintain the same balance in the first place, and to make our warehouse goods sell better in the second place. This is so in a nutshell, but in fact I do not presume to explain in simple words what is happening there.
I can tell you what is not happening. Unfortunately, we do not yet know how to forecast demand and take into account the cost of storing goods in a warehouse.
Integration with third-party systems
An important part from a business point of view, but uninteresting from a technical point of view. In a nutshell, I’ll say that we can send data to third-party systems (including incremental ones, that is, we understand what has changed since the last exchange) and we can do mailing lists.
The newsletters are customizable, so (and not only that) we deliver our offers to wholesale customers.
Another way to work with wholesale customers is the b2b portal. It is still in active development, it will work literally in a month.
Accounts, change logging
Another question that is not interesting from a technical point of view. Each user has an account.
In short, the following can be said: if ORM is used, then it has a built-in change tracking mechanism. If you get into it (and in our case it is EF Core and there is even an API there), then you can get logging in almost two lines.
For the change history, we made an interface, and now we can trace who changed what in the system settings, who edited or compared certain products, and so on.
According to the logs, statistics can be considered, which we do. We know who created or edited how many products, how many comparisons were manually confirmed and how many were rejected, you can see each change.
A little bit about the general structure of the system
We have one database for accounts and catalog-independent things, one database for logs, and a database for each directory. This makes directory queries easier, and it’s easier to analyze the data, and the code is more understandable.
By the way, the logging system is self-written, we really need to group logs related to one request or one heavy task, in addition, we need basic functionality for analyzing them. With ready-made solutions, this turned out to be difficult, plus this is another dependency that needs to be supported.
The web interface is made on ASP.NET Core and bootstrap, and heavy operations are performed by the Windows service.
Another feature that has benefited the project, in my opinion, is different models for reading and writing data. We did not implement full-fledged СQRS, but we took one of the concepts from there. We write to the database through the repositories, but the objects that are used for recording never leave the update / create / delete methods. Mass update is done through BULK COPY. A separate model and a separate layer of data access were made for reading, so we only read what we need at a particular moment. It turned out that you can use ORM, and at the same time avoid heavy queries, access to the database at uncertain times (like with lazy loading), N + 1 problems. And we also use the model for reading as DTO.
Of the major dependencies, we have ASP.NET Core, several third-party nuget packages, and MS SQL Server. While it is possible, we try not to depend on many third-party systems. In order to fully deploy the project locally, just install SQL Server, grab the source code from the version control system and build the project. The necessary databases will be created automatically, but nothing else is needed. You may have to change one or two lines in the configuration.
What did not
We have not yet made a project knowledge system. We want to do wikis and tips in place. They did not make a simple intuitive interface, the one that is not bad, but for an unprepared person is a bit confusing. CI / CD so far only in the plans.
Did not handle the detailed characteristics of the goods. We also plan, but there is no specific deadline yet.
Business Summary
From the beginning of active development until launch in production, two people worked on the project for 7 months. At the start, we had a prototype made in our free time. The most difficult integration was given to existing systems.
For the three months we are in production, the number of goods available for wholesale customers has grown from 70 thousand to 230 thousand, the number of goods on the site - from 60 thousand to 140 thousand. The site is always late because it needs features, pictures, product descriptions. We unload 106 thousand offers on the aggregator instead of 40 thousand three months ago. The number of people working with the catalog has not changed.
We work with 425 suppliers, this number has almost doubled in three months. We track prices of more than a thousand competitors. Well, as we track it - we have a system for parsing, but in most cases we take ready-made data from those who regularly provide it.
Unfortunately, I can’t tell you about sales, I myself do not have reliable data. The demand is seasonal, and it is impossible to directly compare the month to the previous month. And in a year too much has happened to highlight the influence of our system from all factors. Very, very conditional, plus or minus a kilometer, catalog growth, more flexible and competitive prices and the associated sales growth have already paid for the development and implementation.
Another result - we got a project that is essentially not related to the infrastructure of a particular store, and you can make a public service out of it. It was conceived from the very beginning, and this plan almost worked. Unfortunately, the boxed solution has failed. To offer a project as a service where you can register, check the box “I agree”, and which works “as is”, without adapting to the client, you need to redesign the interface, add flexibility and create a wiki. And to make the infrastructure easily scalable and eliminate a single point of failure. Now, from the means of ensuring reliability, we have only regular backups. As an enterprise solution, I think we are ready to solve business problems. Small business is to find a business.
By the way, we have already attracted one third-party client, having the most basic functionality. The guys needed a tool for comparing goods, and the inconvenience associated with active development did not frighten them.
