How we build UI for ad systems

Instead of joining
Earlier in our blog we wrote what IPONWEB does- we automate the display of advertising on the Internet. Our systems make decisions not only on the basis of historical data, but also actively use information obtained in real time. In the case of DSP (Demand Side Platform - an advertising platform for advertisers), the advertiser (or his representative) must create and upload an advertising banner (creative) in one of the formats (picture, video, interactive banner, picture + text, etc.) , select the audience of users to whom this banner will be displayed, determine how many times it is possible to show advertising to one user, in which countries, on which sites, on which devices, and reflect this (and much more) in the targeting settings of the advertising campaign, as well as distribute advertising budget s. For SSP (Supply Side Platform - an advertising platform for owners of advertising platforms), the site owner (mobile application, billboard, television channel) must determine the advertising spots on his site and indicate, for example, which categories of advertising he is ready to display on them. All these settings are made manually in advance (not at the time of displaying ads) using the user interface. In this article I will talk about our approach to building such interfaces, provided that there are many, they are similar to each other and at the same time have individual characteristics. All these settings are made manually in advance (not at the time of displaying ads) using the user interface. In this article I will talk about our approach to building such interfaces, provided that there are many, they are similar to each other and at the same time have individual characteristics. All these settings are made manually in advance (not at the time of displaying ads) using the user interface. In this article I will talk about our approach to building such interfaces, provided that there are many, they are similar to each other and at the same time have individual characteristics.
How it all began
We started advertising business back in 2007, but we didn’t do interfaces immediately, but only in 2014. We are traditionally engaged in the development of custom platforms that are completely designed in accordance with the specifics of the business of each individual client - among the dozens of platforms that we built, there are no two identical. And since our advertising platforms were designed without restrictions on the possibilities of customization, the user interface had to meet the same requirements.
When we received the first request for an advertising interface for DSP five years ago, our choice fell on the popular and convenient technology stack: JavaScript and AngularJS on the front end, and the backend on Python, Django and Django Rest Framework (DRF). From this, the most ordinary project was made, the main task of which was to provide CRUD functionality. The result of his work was a settings file for the advertising system in XML format. Now, such an interaction protocol may seem strange, but, as we already discussed, the first advertising systems (even without a UI) we started building in the “zero” ones, and this format has been preserved to this day.
After the successful launch of the first project, the following did not take long. These were also the UI for the DSP and the requirements for them were the same as for the first project. Nearly. Despite the fact that everything was very similar, the devil was hiding in the details - there is a slightly different hierarchy of objects, a couple of fields are added there ... The most obvious way to get the second project, very similar to the first, but with improvements, was the replication method, which we used . And it entailed problems familiar to many - along with the “good” code, bugs were copied too, patches for which had to be distributed by hand. The same thing happened with all the new features that rolled out on all active projects.
In this mode, it was possible to work while there were few projects, but when their number exceeded 20, the familiar approach ceased to scale. Therefore, we decided to transfer the common parts of the projects to the library, from which the project will connect the components it needs. If a bug is detected, it is repaired once in the library and is automatically distributed to projects when the version of the library is updated, and the same thing happens with the reuse of new features.
Configuration and terminology
We had several iterations in the implementation of this approach, and they all flowed into each other evolutionarily, starting with our usual project on pure DRF. In the latest implementation, our project is described using JSON-based DSL (see picture). This JSON describes both the structure of the project components and their interconnections, and both the frontend and backend can read it.
After initializing the Angular application, the frontend requests a JSON config from the backend. The backend does not just give away a static configuration file, but additionally processes it, adding various metadata or deleting parts of the config that are responsible for parts of the system inaccessible to the user. This allows you to show different users the interface in different ways, including interactive forms, CSS styles of the entire application and specific design elements. The latter is especially true for user interfaces of platforms that are used by different types of clients with different roles and access levels.

The backend, unlike the frontend, reads the configuration once at the initialization stage of the Django application. Thus, the full amount of functionality is recorded on the backend, and access to various parts of the system is checked on the fly.
Before moving on to the most interesting part - database structure - I want to introduce several concepts that we use when we talk about the structure of our projects in order to be on the same wavelength with the reader.
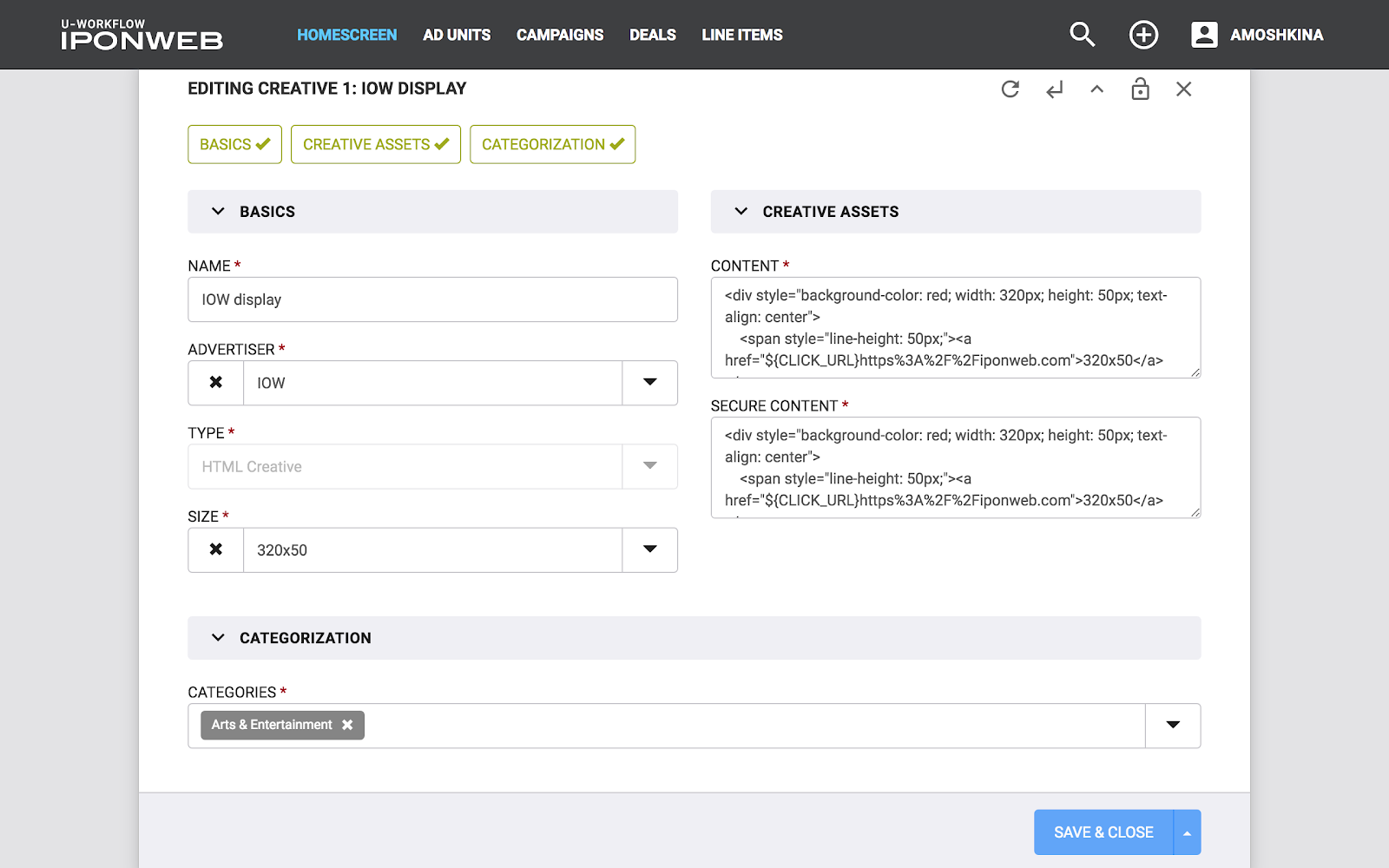
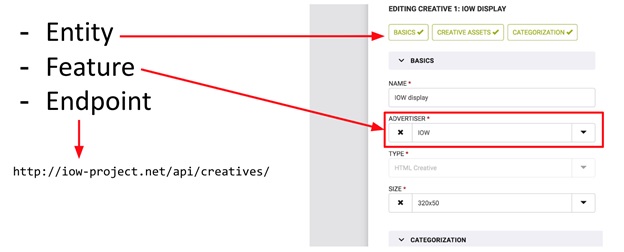
These concepts - Entity and Feature - are well illustrated on the data entry form (see picture). The whole form is Entity, and the individual fields on it are Feature. The picture also shows Endpoint (just in case). So, Entity is an independent object in the system on which CRUD operations can be performed, while Feature is only part of “something more”, part of Entity. With Feature, you cannot perform CRUD operations without being tied to any Entity. For example: the budget of an advertising campaign without reference to the campaign itself is simply a number that cannot be used without information about the parent campaign.
The same concepts can be found in the JSON configuration of the project (see the picture).

Database structure
The most interesting part of our projects is the database structure and the mechanics that support it. Having started using PostgreSQL for the very first versions of our projects, we remain with this technology today. Along with this, we are actively using Django ORM. In early implementations, we used the standard model of relationships between objects (entities) on the Foreign Key, however, this approach caused difficulties when it was necessary to change the hierarchy of relationships. So, for example, in the standard hierarchy of DSP Business Unit -> Advertiser -> Campaign, some clients needed to enter the Agency level (Business Unit -> Agency -> Advertiser -> ...). Therefore, we gradually abandoned the use of Foreign Key and organize links between objects using Many To Many links through a separate table, we call it `LinkRegistry`.
In addition, we gradually abandoned the hardcode for filling entities and began to store most of the fields in separate tables, linking them also through `LinkRegistry` (see picture). Why was this needed? For each client, the content of the entity may vary - some fields will be added or deleted. It turns out that we will have to store in each entity a superset of fields for all our customers. At the same time, they will all have to be made optional, so that the “alien” mandatory fields do not interfere with the work.

Consider the example in the picture: here the database structure for the creative with one additional field is described - `image_url`. Only its id is stored in the creative table, and image_url is stored in a separate table, their relationship is described by another entry in the table LinkRegistry. Thus, this creative will be described by three entries, one in each of the tables. Accordingly, in order to save such a creative, you need to make an entry in each of them, and to read it in the same way, visit 3 tables. It would be very inconvenient to write such processing every time from scratch, so our library abstracts all these details from the programmer. To work with data, Django and DRF use models and serializers described by code. In our projects, the set of fields in models and serializers is determined in runtime by JSON configuration, model classes are created dynamically (using the type function) and stored in a special register, from where they are available during application operation. We also use special base classes for these models and serializers, which help in working with non-standard base structure.
When saving a new object (or updating an existing one), the data received from the front-end gets into the serializer, where they are validated - there’s nothing unusual, standard DRF mechanisms work. But saving and updating are redefined here. The serializer always knows which model it works with, and according to the internal representation of our dynamic model, it can understand which table the data of the next field should be put into. We encode this information in custom model fields (remember how the `ForeignKey` is described in Django - a related model is passed inside the field, we do the same). In these special fields, we also abstract the need to add a third link entry in LinkRegistry using the descriptor mechanism - in the code you write `creative.image_url = 'http: // foo.bar' ',
This applies to writing to the database. And now let's deal with reading. How is a tuple pulled out of a database converted to a Django model instance? In the base Django model there is a `from_db` method, which is called for each tuple received when executing a query in` queryset`. At the input, it receives a tuple and returns the instance of the Django model. We redefined this method in our base model, where according to the tuple of the main model (where only `id` comes in), we get data from other related tables and, having this complete set, we instantiate the model. Of course, we also worked to optimize the Django prefetching mechanism for our non-standard use case.
Testing
Our framework is quite complex, so we write a lot of tests. We have tests for both the frontend and the backend. I will dwell on backend tests in detail.
To run the tests, we use pytest. On the backend, we have two large classes of tests: tests of our framework (we also call it the “core”) and project tests.
In the kernel, we write both isolated unit tests and functional ones for testing endpoints using the pytest-django plugin. In general, all work with the database is mainly tested through requests to the API - as it happens in production.
Functional tests can specify a JSON configuration. In order not to become attached to design terminology, we use “dummy” names for entities with which we test our Features in the kernel (“Emma”, “Alla”, “Karl”, “Maria” and so on). Since, by writing the image_url feature, we don’t want to limit the consciousness of the developer to the fact that it can be used only with the Creative entity - the features and entities are universal, and they can be connected to each other in any combinations that are relevant for a particular client.
As for testing projects, in them all test cases are run with the production configuration, no dummy entities, since it is important for us to check exactly what the client will work with. In the project, you can write any tests that will cover the features of the business logic of the project. At the same time, basic CRUD tests can be connected to the project from the kernel. They are written in a general way, and they can be connected to any project: a feature test can read the JSON configuration of a project, determine which entities this feature is connected to, and run checks only for the necessary entities. For the convenience of preparing test data, we have developed a system of helpers who are also able to prepare test data sets based on the JSON configuration. A special place in project testing is occupied by E2E tests on Protractor, which test all the basic functions of the project.
Afterword
In this article, we examined the modular design approach developed by IPONWEB in the UI department. This solution has been successfully operating in production for three years. However, this solution still has a number of limitations that do not allow us to rest on our laurels. Firstly, our code base is still quite complex. Secondly, the basic code that supports dynamic models is associated with such critical components as search, bulk loading of objects, access rights, and others. Because of this, changes in one of the components can significantly affect the others. In an effort to get rid of these restrictions, we continue to actively process our library, breaking it into many independent parts and reducing the complexity of the code. We will tell you about the results in the following articles.
This article is an extended transcript of my presentation at MoscowPythonConf ++ 2019, so I also share links to videos and slides .