Did the machine learning bubble burst, or the start of a new dawn
Recently, an article has been released that shows a good trend in machine learning in recent years. In short: the number of startups in the field of machine learning has fallen sharply in the last two years.
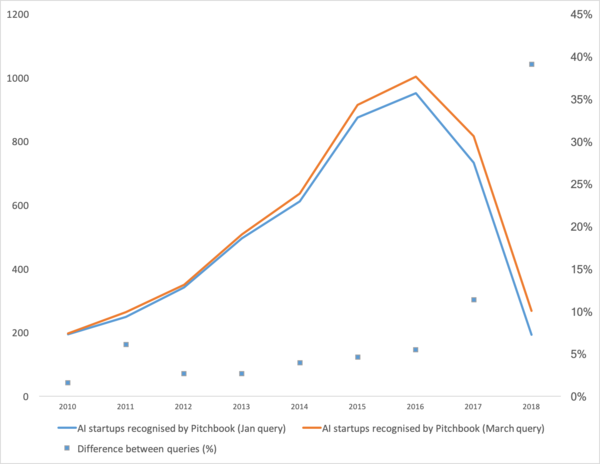
Well. Let’s analyze “whether the bubble burst”, “how to continue to live” and talk about where such a squiggle comes from.
First, let's talk about what was the booster of this curve. Where did she come from. Probably everyone will remember the victory of machine learning in 2012 at the ImageNet contest. After all, this is the first global event! But in reality this is not so. And the growth of the curve begins a little earlier. I would break it into several points.
“Did the bubble burst?” Is Hype overheating? They died like a blockchain? ”
Well then! Tomorrow Siri will stop working on your phone, and the day after tomorrow Tesla will not distinguish a turn from a kangaroo.
Neural networks are already working. They are in dozens of devices. They really allow you to earn, change the market and the world around you. Hype looks a bit different:
It’s just that neural networks have ceased to be something new. Yes, many people have high expectations. But a large number of companies have learned to use their neurons and make products based on them. Neurons give new functionality, can reduce jobs, reduce the price of services:
But the main thing, and not the most obvious: "There are no more new ideas, or they will not bring instant capital." Neural networks have solved dozens of problems. And they will decide even more. All the obvious ideas that were - spawned a lot of startups. But everything that was on the surface has already been collected. Over the past two years, I have not met a single new idea for the use of neural networks. Not a single new approach (well, ok, there are a few problems with GANs).
And every next startup is more and more complicated. It requires no longer two guys who train a neuron on open data. It requires programmers, a server, a team of scribers, complex support, etc.
As a result, there are fewer startups. But the production is more. Need to attach license plate recognition? There are hundreds of professionals with relevant experience on the market. You can hire and in a couple of months your employee will create a system. Or buy a finished one. But doing a new startup? .. Madness!
We need to make a system for tracking visitors - why pay for a bunch of licenses, when you can do your own for 3-4 months, sharpen it for your business.
Now neural networks go the same way as dozens of other technologies.
Remember how the concept of "site developer" has changed since 1995? While the market is not saturated with specialists. There are very few professionals. But I can bet that in 5-10 years there will not be much difference between a Java programmer and a neural network developer. And those and those specialists will be enough in the market.
There will simply be a class of tasks for which is solved by neurons. There was a task - hire a specialist.
"What's next? Where is the promised artificial intelligence? ”
And here there is a small but interesting misunderstanding :)
The technology stack that is today, apparently, still will not lead us to artificial intelligence. Ideas, their novelty, have largely exhausted themselves. Let's talk about what holds the current level of development.
Let's start with auto-drones. It seems to be understood that it is possible to make fully autonomous cars with today's technologies. But after how many years this will happen is not clear. Tesla believes that this will happen in a couple of years -
There are many other specialists who rate this as 5-10 years old.
Most likely, in my opinion, after 15 years, the infrastructure of the cities will itself change so that the emergence of autonomous cars will become inevitable, will be its continuation. But this can not be considered intelligence. Modern Tesla is a very complex pipeline for filtering data, searching for them and retraining. These are rules, rules, rules, data collection and filters above them ( here I wrote a little more about it, or look from this point).
And it is here that we see the first fundamental problem . Big data. This is exactly what generated the current wave of neural networks and machine learning. Now, to do something complex and automatic, you need a lot of data. Not just a lot, but a very, very much. We need automated algorithms for their collection, markup, use. We want to make the car see trucks against the sun - we must first collect a sufficient number of them. We want the car not to go crazy with a bicycle screwed to the trunk - more samples.
Moreover, one example is not enough. Hundreds? Thousands?

The second problem is the visualization of what our neural network has understood. This is a very non-trivial task. Until now, few people understand how to visualize this. These articles are very recent, these are just a few examples, even if they are distant:
Visualization of fixation on textures. It shows well on what the neuron tends to go in cycles + what she perceives as initial information.

Visualization of attenuation during translations . Really, attenuation can often be used precisely to show what caused such a network reaction. I met such things for debug and for product solutions. There are a lot of articles on this topic. But the more complex the data, the more difficult it is to understand how to achieve sustainable visualization.

Well and yes, the good old set of "look at what the grid inside is in the filters ." These pictures were popular about 3-4 years ago, but everyone quickly realized that the pictures are beautiful, but there is not much sense in them.

I did not name dozens of other lotions, methods, hacks, studies on how to display the insides of the network. Do these tools work? Do they help you quickly understand what the problem is and debug the network? .. Pull out the last percent? Well, something like this:

You can watch any contest at Kaggle. And a description of how people make final decisions. We arrived 100-500-800 mulenov model and it worked!
Of course, I exaggerate. But these approaches do not give quick and direct answers.
Having enough experience, having poked different options, you can issue a verdict on why your system made such a decision. But correcting the behavior of the system will be difficult. Put a crutch, move the threshold, add a dataset, take another backend network.
The third fundamental problem is that grids do not teach logic, but statistics. Statistically this person :

Logically - not very similar. Neural networks do not learn something complicated if they are not forced. They always learn the simplest symptoms. Have eyes, nose, head? So this face! Or give an example where the eyes will not mean the face. And again, millions of examples.
I would say that it is these three global problems that today limit the development of neural networks and machine learning. And where these problems were not limited to is already actively used.
This is the end? Neural networks got up?
Unknown But, of course, everyone hopes not.
There are many approaches and directions to solving those fundamental problems that I have covered above. But so far, none of these approaches has allowed us to do something fundamentally new, to solve something that has not yet been resolved. So far, all fundamental projects are done on the basis of stable approaches (Tesla), or remain test projects of institutes or corporations (Google Brain, OpenAI).
Roughly speaking, the main direction is the creation of some high-level representation of the input data. In a sense, “memory." The simplest example of memory is the various “Embedding” representations of images. Well, for example, all face recognition systems. The network learns to get from the face a certain stable idea that does not depend on rotation, lighting, resolution. In fact, the network minimizes the metric of “different faces - far away” and “identical - close”.

Such training requires tens and hundreds of thousands of examples. But the result brings some rudiments of “One-shot Learning”. Now we do not need hundreds of faces to remember a person. Just one face, and that's it - we will find out !
Only here is the problem ... The grid can learn only fairly simple objects. When trying to distinguish not faces, but, for example, “people by clothes” (the Re-indentification task ), quality fails by many orders of magnitude. And the network can no longer learn enough obvious angle changes.
And learning from millions of examples is also somehow so-so entertainment.
There is work to significantly reduce the election. For example, you can immediately recall one of the first OneShot Learning works from Google :
There are many such works, for example 1 or 2 or 3 .
There is one minus - usually training works well on some simple, “MNIST'ovskie examples”. And in the transition to complex tasks - you need a large base, a model of objects, or some kind of magic.
In general, work on One-Shot training is a very interesting topic. You find a lot of ideas. But for the most part, the two problems that I have listed (pre-training on a huge dataset / instability on complex data) are very hindering learning.
On the other hand, GAN - generatively competitive networks - approaches Embedding. You probably read a bunch of articles on this topic on Habré. ( 1 , 2 , 3 )
A feature of the GAN is the formation of some internal state space (essentially the same Embedding), which allows you to draw an image. It can be persons , there can be actions .
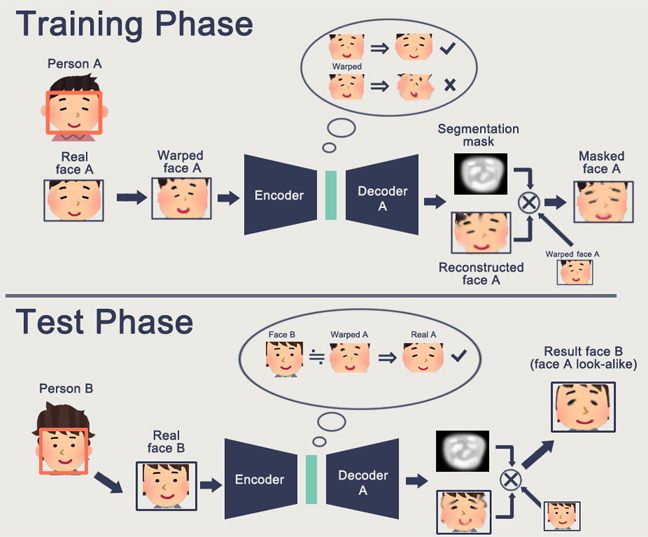
The GAN problem is that the more complex the generated object is, the more difficult it is to describe it in the “generator-discriminator” logic. As a result, from real applications of GAN, which are heard only DeepFake, which, again, manipulates the representations of individuals (for which there is a huge base).
I have encountered very few other useful applications. Usually some kind of whistle-fake with drawing pictures.
And again. No one has an understanding of how this will allow us to move towards a brighter future. Representing logic / space in a neural network is good. But we need a huge number of examples, we don’t understand how this neuron represents in itself, we don’t understand how to make the neuron remember some really complicated idea.
Reinforcement learning is a completely different approach. Surely you remember how Google beat everyone in Go. Recent victories in Starcraft and Dota. But here everything is far from being so rosy and promising. The best thing about RL and its complexity is this article .
To summarize briefly what the author wrote:
The key point is that RL does not yet work in production. Google has some kind of experiments ( 1 , 2 ). But I have not seen a single grocery system.
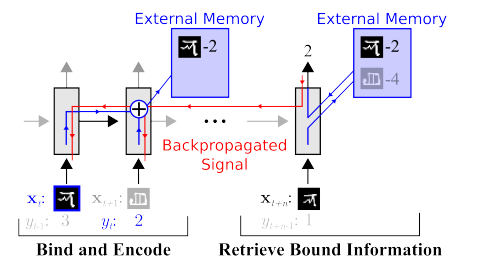
The Memory . The downside of all that is described above is unstructured. One approach to trying to tidy up all this is to provide the neural network with access to a separate memory. So that she can record and rewrite the results of her steps there. Then the neural network can be determined by the current state of memory. This is very similar to classic processors and computers.
The most famous and popular article is from DeepMind:
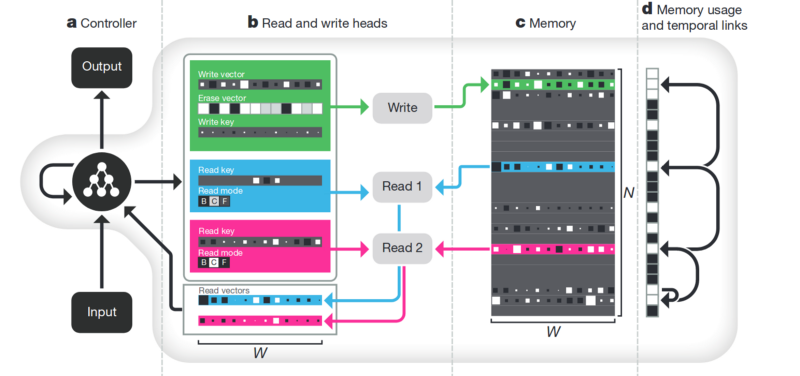
It seems that here it is, the key to understanding intelligence? But rather, no. The system still needs a huge amount of data for training. And it works mainly with structured tabular data. At the same time, when Facebook solved a similar problem, they went the way “see the memory, just make the neuron more complicated, but more examples, and it will learn itself.”
Disentanglement. Another way to create meaningful memory is to take the same embeddings, but when learning to introduce additional criteria that would allow them to highlight “meanings” in them. For example, we want to train a neural network to distinguish between the behavior of a person in a store. If we were to follow the standard path, we would have to make a dozen networks. One is looking for a person, the second determines what he is doing, the third is his age, the fourth is gender. Separate logic looks at the part of the store where he does / learns for it. The third determines its trajectory, etc.
Or, if there were infinitely a lot of data, then it would be possible to train one network for all sorts of outcomes (it is obvious that such an array of data cannot be typed).
The disenthelment approach tells us - and let us train the network so that it can itself distinguish between concepts. In order for her to form an embedding in the video, where one area would determine the action, one - the position on the floor in time, one - the height of the person, and another - his gender. At the same time, during training, I would like to almost never suggest such key concepts to the network, but so that it itself identifies and groups the areas. There are few such articles (some of them are 1 , 2 , 3 ) and in general they are quite theoretical.
But this direction, at least theoretically, should cover the problems listed at the beginning.
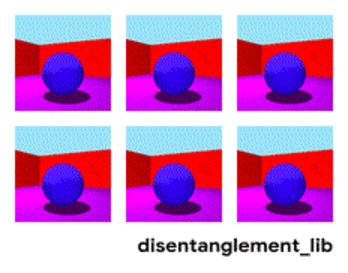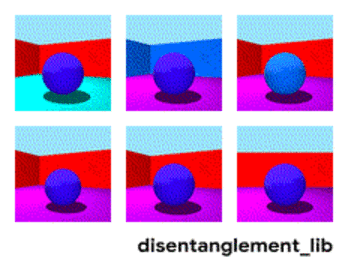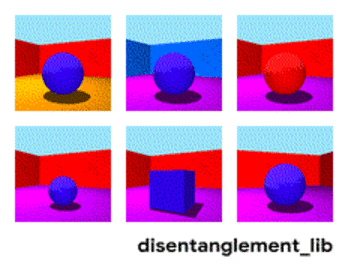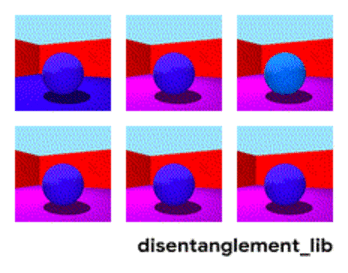
Decomposition of the image according to the parameters “wall color / floor color / object shape / object color / etc.”

Decomposition of the face according to the parameters “size, eyebrows, orientation, skin color, etc.”
There are many other not so global directions that allow us to somehow reduce the base, work with more heterogeneous data, etc.
Attention . It probably does not make sense to isolate this as a separate method. Just an approach that reinforces others. Many articles have been devoted to him ( 1 , 2 , 3 ). The meaning of Attention is to strengthen the network’s response to significant objects during training. Often by some external target designation, or a small external network.
3D simulation. If you make a good 3D engine, you can often close 90% of the training data with it (I even saw an example where almost 99% of the data was closed with a good engine). There are many ideas and hacks on how to make a network trained on a 3D engine work on real data (Fine tuning, style transfer, etc.). But often making a good engine is several orders of magnitude more difficult than collecting data. Examples when making engines:
Training robots ( google , braingarden )
Training to recognize products in the store (but in the two projects that we did - we calmly did without it).
Training at Tesla (again, the video that was above).
The whole article is in a sense conclusions. Probably the main message that I wanted to do was "the freebie is over, the neurons do not give more simple solutions." Now we have to work hard to build complex solutions. Or work hard doing complex scientific reports.
In general, the topic is debatable. Maybe readers have more interesting examples?
Well. Let’s analyze “whether the bubble burst”, “how to continue to live” and talk about where such a squiggle comes from.
First, let's talk about what was the booster of this curve. Where did she come from. Probably everyone will remember the victory of machine learning in 2012 at the ImageNet contest. After all, this is the first global event! But in reality this is not so. And the growth of the curve begins a little earlier. I would break it into several points.
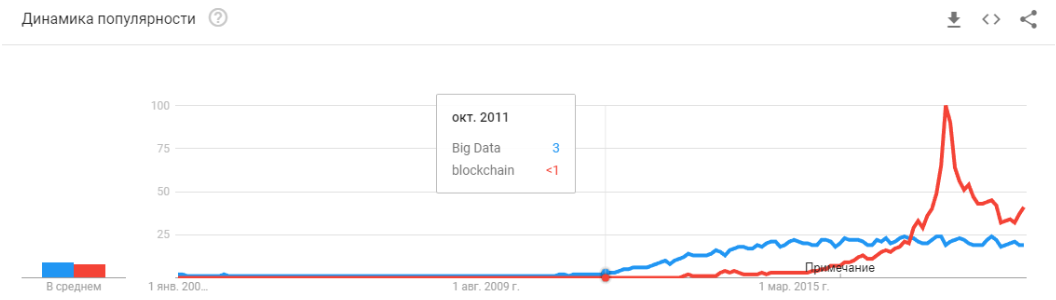
- 2008 is the emergence of the term “big data." Real products began to appear in 2010. Big data is directly related to machine learning. Without big data, the stable operation of the algorithms that existed at that time is impossible. And these are not neural networks. Until 2012, neural networks are the lot of a marginal minority. But then completely different algorithms began to work, which had existed for years, or even decades: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... Startups of those years are primarily associated with the automatic processing of structured data : ticket offices, users, advertising, much more.
The derivative of this first wave is a set of frameworks such as XGBoost, CatBoost, LightGBM, etc. - In 2011-2012, convolutional neural networks won a series of image recognition contests. Their actual use was somewhat delayed. I would say that massively meaningful startups and solutions began to appear in 2014. It took two years to digest that neurons still work, to make convenient frameworks that could be installed and run in a reasonable amount of time, to develop methods that would stabilize and accelerate the convergence time.
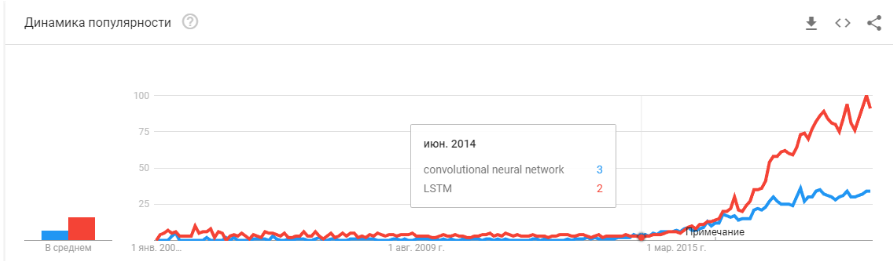
Convolutional networks made it possible to solve machine vision problems: classification of images and objects in an image, detection of objects, recognition of objects and people, image enhancement, etc., etc. - 2015-2017 years. The boom of algorithms and projects tied to recurrence networks or their analogues (LSTM, GRU, TransformerNet, etc.). Well-functioning speech-to-text algorithms and machine translation systems have appeared. In part, they are based on convolutional networks to highlight basic features. Partially on the fact that they learned to collect really big and good datasets.
“Did the bubble burst?” Is Hype overheating? They died like a blockchain? ”
Well then! Tomorrow Siri will stop working on your phone, and the day after tomorrow Tesla will not distinguish a turn from a kangaroo.
Neural networks are already working. They are in dozens of devices. They really allow you to earn, change the market and the world around you. Hype looks a bit different:
It’s just that neural networks have ceased to be something new. Yes, many people have high expectations. But a large number of companies have learned to use their neurons and make products based on them. Neurons give new functionality, can reduce jobs, reduce the price of services:
- Manufacturing companies integrate algorithms for the analysis of rejects on the conveyor.
- Livestock farms are buying systems for controlling cows.
- Automatic harvesters.
- Automated Call Centers.
- Filters in Snapchat. (
well, at least something sensible!)
But the main thing, and not the most obvious: "There are no more new ideas, or they will not bring instant capital." Neural networks have solved dozens of problems. And they will decide even more. All the obvious ideas that were - spawned a lot of startups. But everything that was on the surface has already been collected. Over the past two years, I have not met a single new idea for the use of neural networks. Not a single new approach (well, ok, there are a few problems with GANs).
And every next startup is more and more complicated. It requires no longer two guys who train a neuron on open data. It requires programmers, a server, a team of scribers, complex support, etc.
As a result, there are fewer startups. But the production is more. Need to attach license plate recognition? There are hundreds of professionals with relevant experience on the market. You can hire and in a couple of months your employee will create a system. Or buy a finished one. But doing a new startup? .. Madness!
We need to make a system for tracking visitors - why pay for a bunch of licenses, when you can do your own for 3-4 months, sharpen it for your business.
Now neural networks go the same way as dozens of other technologies.
Remember how the concept of "site developer" has changed since 1995? While the market is not saturated with specialists. There are very few professionals. But I can bet that in 5-10 years there will not be much difference between a Java programmer and a neural network developer. And those and those specialists will be enough in the market.
There will simply be a class of tasks for which is solved by neurons. There was a task - hire a specialist.
"What's next? Where is the promised artificial intelligence? ”
And here there is a small but interesting misunderstanding :)
The technology stack that is today, apparently, still will not lead us to artificial intelligence. Ideas, their novelty, have largely exhausted themselves. Let's talk about what holds the current level of development.
Limitations
Let's start with auto-drones. It seems to be understood that it is possible to make fully autonomous cars with today's technologies. But after how many years this will happen is not clear. Tesla believes that this will happen in a couple of years -
There are many other specialists who rate this as 5-10 years old.
Most likely, in my opinion, after 15 years, the infrastructure of the cities will itself change so that the emergence of autonomous cars will become inevitable, will be its continuation. But this can not be considered intelligence. Modern Tesla is a very complex pipeline for filtering data, searching for them and retraining. These are rules, rules, rules, data collection and filters above them ( here I wrote a little more about it, or look from this point).
First problem
And it is here that we see the first fundamental problem . Big data. This is exactly what generated the current wave of neural networks and machine learning. Now, to do something complex and automatic, you need a lot of data. Not just a lot, but a very, very much. We need automated algorithms for their collection, markup, use. We want to make the car see trucks against the sun - we must first collect a sufficient number of them. We want the car not to go crazy with a bicycle screwed to the trunk - more samples.
Moreover, one example is not enough. Hundreds? Thousands?
Second problem
The second problem is the visualization of what our neural network has understood. This is a very non-trivial task. Until now, few people understand how to visualize this. These articles are very recent, these are just a few examples, even if they are distant:
Visualization of fixation on textures. It shows well on what the neuron tends to go in cycles + what she perceives as initial information.
Visualization of attenuation during translations . Really, attenuation can often be used precisely to show what caused such a network reaction. I met such things for debug and for product solutions. There are a lot of articles on this topic. But the more complex the data, the more difficult it is to understand how to achieve sustainable visualization.
Well and yes, the good old set of "look at what the grid inside is in the filters ." These pictures were popular about 3-4 years ago, but everyone quickly realized that the pictures are beautiful, but there is not much sense in them.
I did not name dozens of other lotions, methods, hacks, studies on how to display the insides of the network. Do these tools work? Do they help you quickly understand what the problem is and debug the network? .. Pull out the last percent? Well, something like this:
You can watch any contest at Kaggle. And a description of how people make final decisions. We arrived 100-500-800 mulenov model and it worked!
Of course, I exaggerate. But these approaches do not give quick and direct answers.
Having enough experience, having poked different options, you can issue a verdict on why your system made such a decision. But correcting the behavior of the system will be difficult. Put a crutch, move the threshold, add a dataset, take another backend network.
Third problem
The third fundamental problem is that grids do not teach logic, but statistics. Statistically this person :
Logically - not very similar. Neural networks do not learn something complicated if they are not forced. They always learn the simplest symptoms. Have eyes, nose, head? So this face! Or give an example where the eyes will not mean the face. And again, millions of examples.
There's Plenty of Room at the Bottom
I would say that it is these three global problems that today limit the development of neural networks and machine learning. And where these problems were not limited to is already actively used.
This is the end? Neural networks got up?
Unknown But, of course, everyone hopes not.
There are many approaches and directions to solving those fundamental problems that I have covered above. But so far, none of these approaches has allowed us to do something fundamentally new, to solve something that has not yet been resolved. So far, all fundamental projects are done on the basis of stable approaches (Tesla), or remain test projects of institutes or corporations (Google Brain, OpenAI).
Roughly speaking, the main direction is the creation of some high-level representation of the input data. In a sense, “memory." The simplest example of memory is the various “Embedding” representations of images. Well, for example, all face recognition systems. The network learns to get from the face a certain stable idea that does not depend on rotation, lighting, resolution. In fact, the network minimizes the metric of “different faces - far away” and “identical - close”.
Such training requires tens and hundreds of thousands of examples. But the result brings some rudiments of “One-shot Learning”. Now we do not need hundreds of faces to remember a person. Just one face, and that's it - we will find out !
Only here is the problem ... The grid can learn only fairly simple objects. When trying to distinguish not faces, but, for example, “people by clothes” (the Re-indentification task ), quality fails by many orders of magnitude. And the network can no longer learn enough obvious angle changes.
And learning from millions of examples is also somehow so-so entertainment.
There is work to significantly reduce the election. For example, you can immediately recall one of the first OneShot Learning works from Google :
There are many such works, for example 1 or 2 or 3 .
There is one minus - usually training works well on some simple, “MNIST'ovskie examples”. And in the transition to complex tasks - you need a large base, a model of objects, or some kind of magic.
In general, work on One-Shot training is a very interesting topic. You find a lot of ideas. But for the most part, the two problems that I have listed (pre-training on a huge dataset / instability on complex data) are very hindering learning.
On the other hand, GAN - generatively competitive networks - approaches Embedding. You probably read a bunch of articles on this topic on Habré. ( 1 , 2 , 3 )
A feature of the GAN is the formation of some internal state space (essentially the same Embedding), which allows you to draw an image. It can be persons , there can be actions .
The GAN problem is that the more complex the generated object is, the more difficult it is to describe it in the “generator-discriminator” logic. As a result, from real applications of GAN, which are heard only DeepFake, which, again, manipulates the representations of individuals (for which there is a huge base).
I have encountered very few other useful applications. Usually some kind of whistle-fake with drawing pictures.
And again. No one has an understanding of how this will allow us to move towards a brighter future. Representing logic / space in a neural network is good. But we need a huge number of examples, we don’t understand how this neuron represents in itself, we don’t understand how to make the neuron remember some really complicated idea.
Reinforcement learning is a completely different approach. Surely you remember how Google beat everyone in Go. Recent victories in Starcraft and Dota. But here everything is far from being so rosy and promising. The best thing about RL and its complexity is this article .
To summarize briefly what the author wrote:
- Models out of the box do not fit / work poorly in most cases
- Practical tasks are easier to solve in other ways. Boston Dynamics does not use RL due to its complexity / unpredictability / computational complexity
- For RL to work, you need a complex function. It is often difficult to create / write.
- It’s hard to train models. We have to spend a lot of time to swing and get out of local optima
- As a result, it is difficult to repeat the model, the instability of the model at the slightest change
- It often overfills on some left patterns, up to the random number generator
The key point is that RL does not yet work in production. Google has some kind of experiments ( 1 , 2 ). But I have not seen a single grocery system.
The Memory . The downside of all that is described above is unstructured. One approach to trying to tidy up all this is to provide the neural network with access to a separate memory. So that she can record and rewrite the results of her steps there. Then the neural network can be determined by the current state of memory. This is very similar to classic processors and computers.
The most famous and popular article is from DeepMind:
It seems that here it is, the key to understanding intelligence? But rather, no. The system still needs a huge amount of data for training. And it works mainly with structured tabular data. At the same time, when Facebook solved a similar problem, they went the way “see the memory, just make the neuron more complicated, but more examples, and it will learn itself.”
Disentanglement. Another way to create meaningful memory is to take the same embeddings, but when learning to introduce additional criteria that would allow them to highlight “meanings” in them. For example, we want to train a neural network to distinguish between the behavior of a person in a store. If we were to follow the standard path, we would have to make a dozen networks. One is looking for a person, the second determines what he is doing, the third is his age, the fourth is gender. Separate logic looks at the part of the store where he does / learns for it. The third determines its trajectory, etc.
Or, if there were infinitely a lot of data, then it would be possible to train one network for all sorts of outcomes (it is obvious that such an array of data cannot be typed).
The disenthelment approach tells us - and let us train the network so that it can itself distinguish between concepts. In order for her to form an embedding in the video, where one area would determine the action, one - the position on the floor in time, one - the height of the person, and another - his gender. At the same time, during training, I would like to almost never suggest such key concepts to the network, but so that it itself identifies and groups the areas. There are few such articles (some of them are 1 , 2 , 3 ) and in general they are quite theoretical.
But this direction, at least theoretically, should cover the problems listed at the beginning.
Decomposition of the image according to the parameters “wall color / floor color / object shape / object color / etc.”
Decomposition of the face according to the parameters “size, eyebrows, orientation, skin color, etc.”
Other
There are many other not so global directions that allow us to somehow reduce the base, work with more heterogeneous data, etc.
Attention . It probably does not make sense to isolate this as a separate method. Just an approach that reinforces others. Many articles have been devoted to him ( 1 , 2 , 3 ). The meaning of Attention is to strengthen the network’s response to significant objects during training. Often by some external target designation, or a small external network.
3D simulation. If you make a good 3D engine, you can often close 90% of the training data with it (I even saw an example where almost 99% of the data was closed with a good engine). There are many ideas and hacks on how to make a network trained on a 3D engine work on real data (Fine tuning, style transfer, etc.). But often making a good engine is several orders of magnitude more difficult than collecting data. Examples when making engines:
Training robots ( google , braingarden )
Training to recognize products in the store (but in the two projects that we did - we calmly did without it).
Training at Tesla (again, the video that was above).
conclusions
The whole article is in a sense conclusions. Probably the main message that I wanted to do was "the freebie is over, the neurons do not give more simple solutions." Now we have to work hard to build complex solutions. Or work hard doing complex scientific reports.
In general, the topic is debatable. Maybe readers have more interesting examples?