Understanding Machine Learning in Elastic Stack (aka Elasticsearch, aka ELK)
Recall that the Elastic Stack is based on the non-relational Elasticsearch database, the Kibana web interface and data collectors (the most famous Logstash, various Beats, APM and others). One of the nice additions to the entire listed product stack is data analysis using machine learning algorithms. In the article, we understand what these algorithms are. We ask for cat.
Machine learning is a paid feature of the shareware Elastic Stack and is part of the X-Pack. To start using it, it is enough after activation to activate the 30-day trial. After the trial period expires, you can request support for its extension or buy a subscription. The subscription cost is calculated not from the amount of data, but from the number of nodes used. No, the amount of data affects, of course, the number of nodes required, but still this approach to licensing is more humane in relation to the company's budget. If there is no need for high performance - you can save.
ML in Elastic Stack is written in C ++ and works outside the JVM, which runs Elasticsearch itself. That is, the process (which, by the way, is called autodetect) consumes everything that the JVM does not swallow. At the demo stand, this is not so critical, but in a productive environment it is important to highlight separate nodes for ML tasks.
Machine learning algorithms are divided into two categories - with and without a teacher . In Elastic Stack, the algorithm is from the “no teacher” category. According to this link , you can see the mathematical formalism of machine learning algorithms.
To perform the analysis, the machine learning algorithm uses the data stored in the Elasticsearch indexes. You can create tasks for analysis both from the Kibana interface and through the API. If you do this through Kibana, then some things are not necessary to know. For example, additional indexes that the algorithm uses in the process.
Additional indexes used in the analysis process
.ml-state - information about statistical models (analysis settings);
.ml-anomalies- * - results of the work of ML algorithms;
.ml-notifications - notification settings based on analysis results.
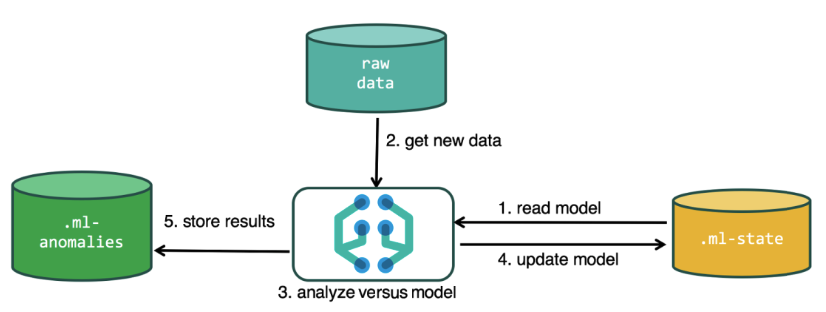
.ml-anomalies- * - results of the work of ML algorithms;
.ml-notifications - notification settings based on analysis results.
The data structure in the Elasticsearch database consists of indexes and documents stored in them. If compared with a relational database, then the index can be compared with the database schema, and a document with an entry in the table. This comparison is conditional and provided to simplify the understanding of further material for those who have only heard about Elasticsearch.
The same functionality is available through the API as through the web interface, so for clarity and understanding of the concepts, we will show how to configure through Kibana. There is a Machine Learning section in the menu on the left where you can create a new job. In the Kibana interface, it looks like the image below. Now we will analyze each type of task and show the types of analysis that can be constructed here.
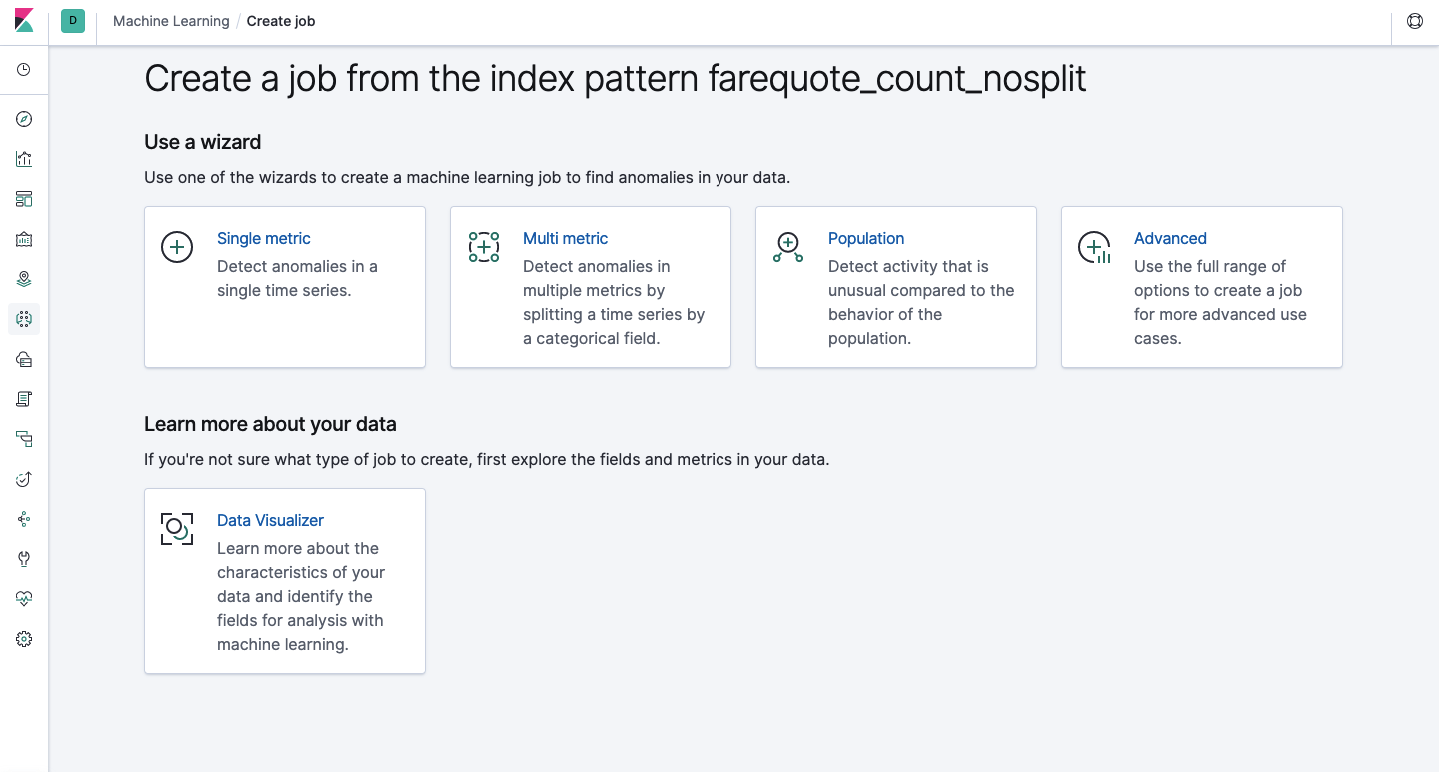
Single Metric - analysis of one metric, Multi Metric - analysis of two or more metrics. In both cases, each metric is analyzed in an isolated environment, i.e. the algorithm does not take into account the behavior of the metrics analyzed in parallel as it might seem in the case of Multi Metric. To carry out the calculation taking into account the correlation of various metrics, you can apply Population analysis. And Advanced is a fine-tuning of algorithms with additional options for certain tasks.
Single metric
Analysis of changes in one single metric is the simplest thing you can do here. After clicking on Create Job, the algorithm will look for anomalies.
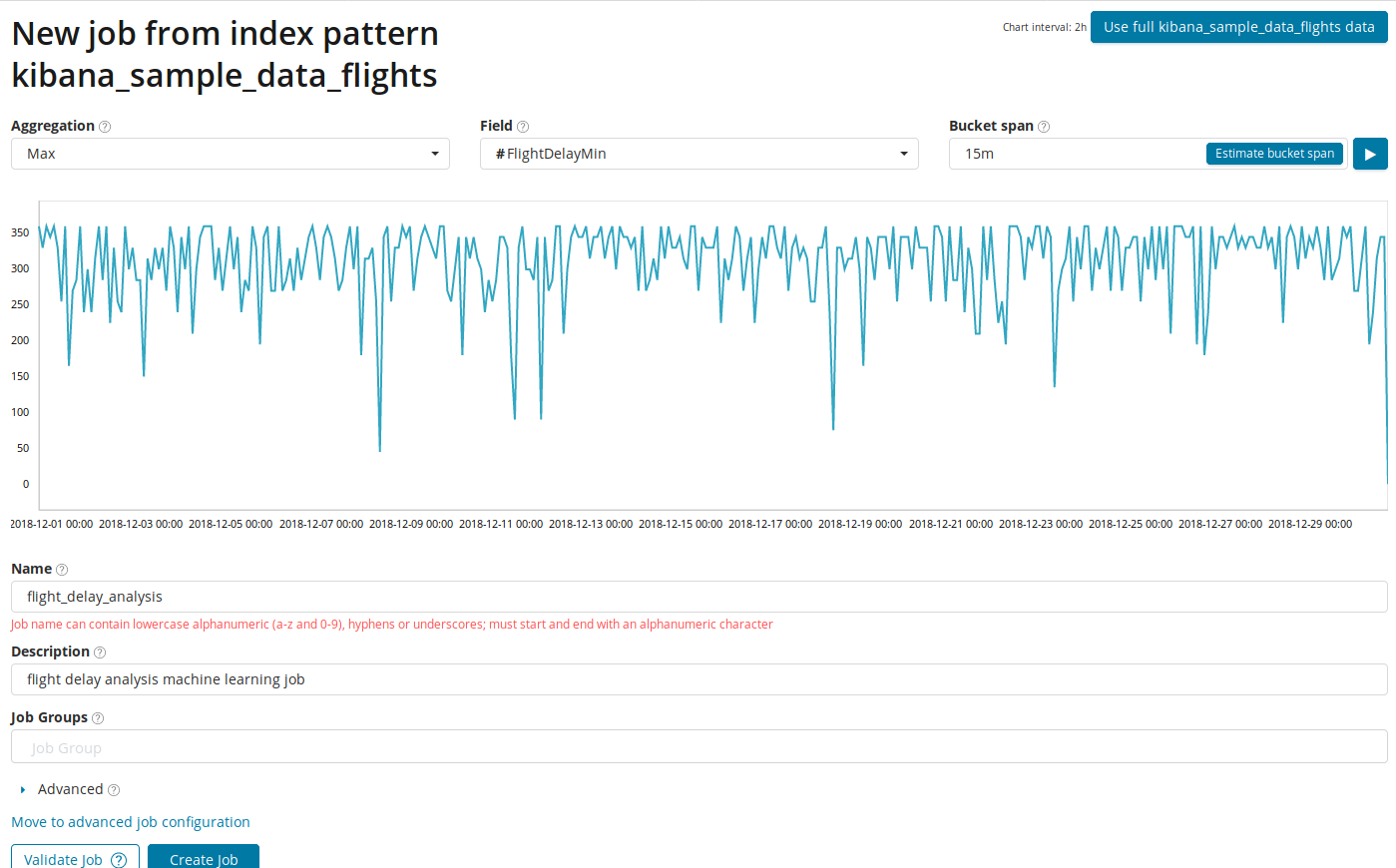
In the Aggregation field, you can choose an approach to search for anomalies. For example, with Min abnormal values will be considered lower than typical. There are Max, Hign Mean, Low, Mean, Distinct and others. Description of all functions can be found here .
In the Field specifies a numeric field in the document on which we will analyze.
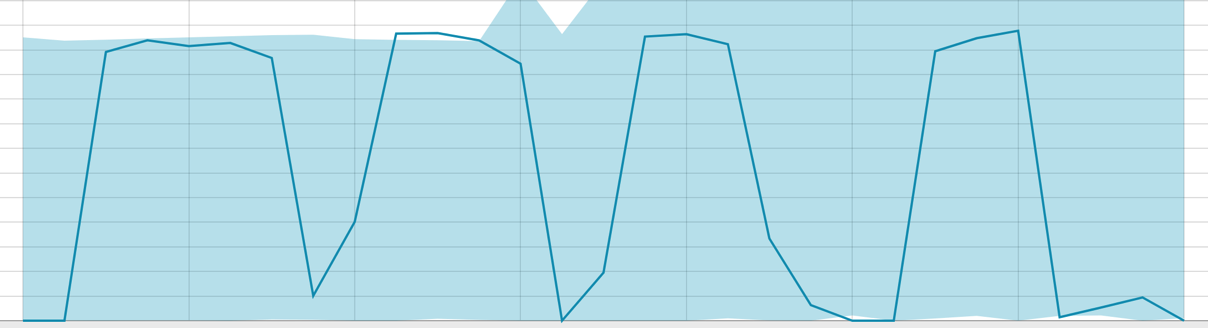
In the Bucket span field- granularity of the intervals on the timeline over which the analysis will be conducted. You can trust the automation or choose manually. The image below shows an example of granularity too low - you can skip the anomaly. Using this setting, you can change the sensitivity of the algorithm to anomalies.

The duration of the data collected is a key thing that affects the effectiveness of the analysis. In the analysis, the algorithm determines the repeating intervals, calculates the confidence interval (baselines) and identifies anomalies - atypical deviations from the usual behavior of the metric. Just for an example:
Baselines with a small piece of data:
When the algorithm has something to learn, baselines look like this:
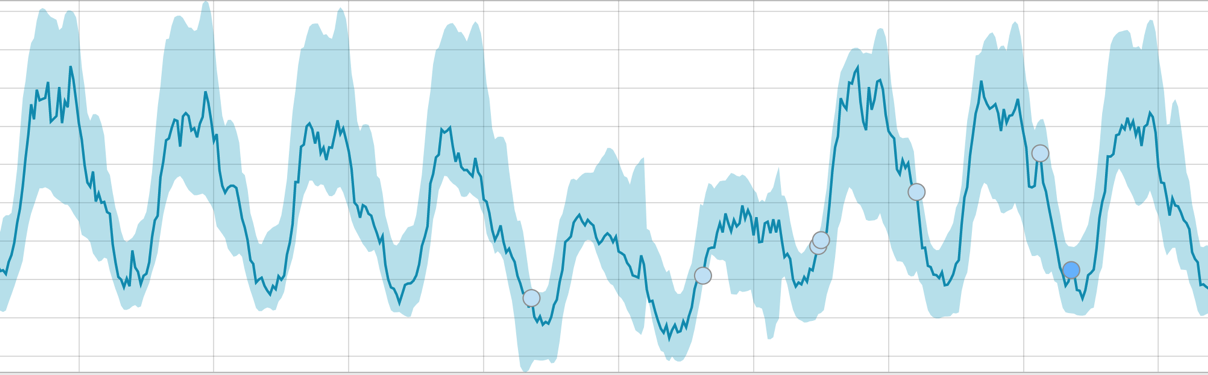
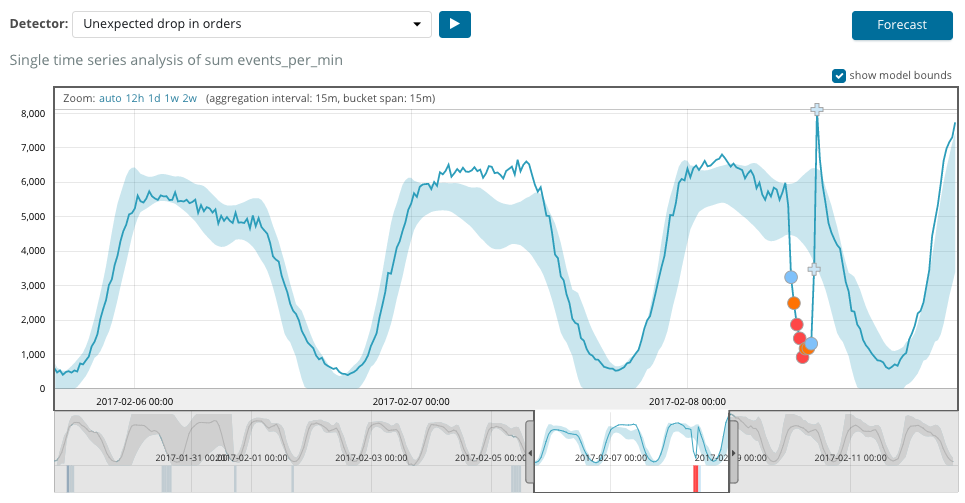
After starting the task, the algorithm determines the abnormal deviations from the norm and ranks them by the probability of the anomaly (the color of the corresponding label is indicated in brackets):
Warning (blue): less than 25
Minor (yellow): 25-50
Major (orange): 50-75
Critical ( red): 75-100
The example below shows anomalies found.
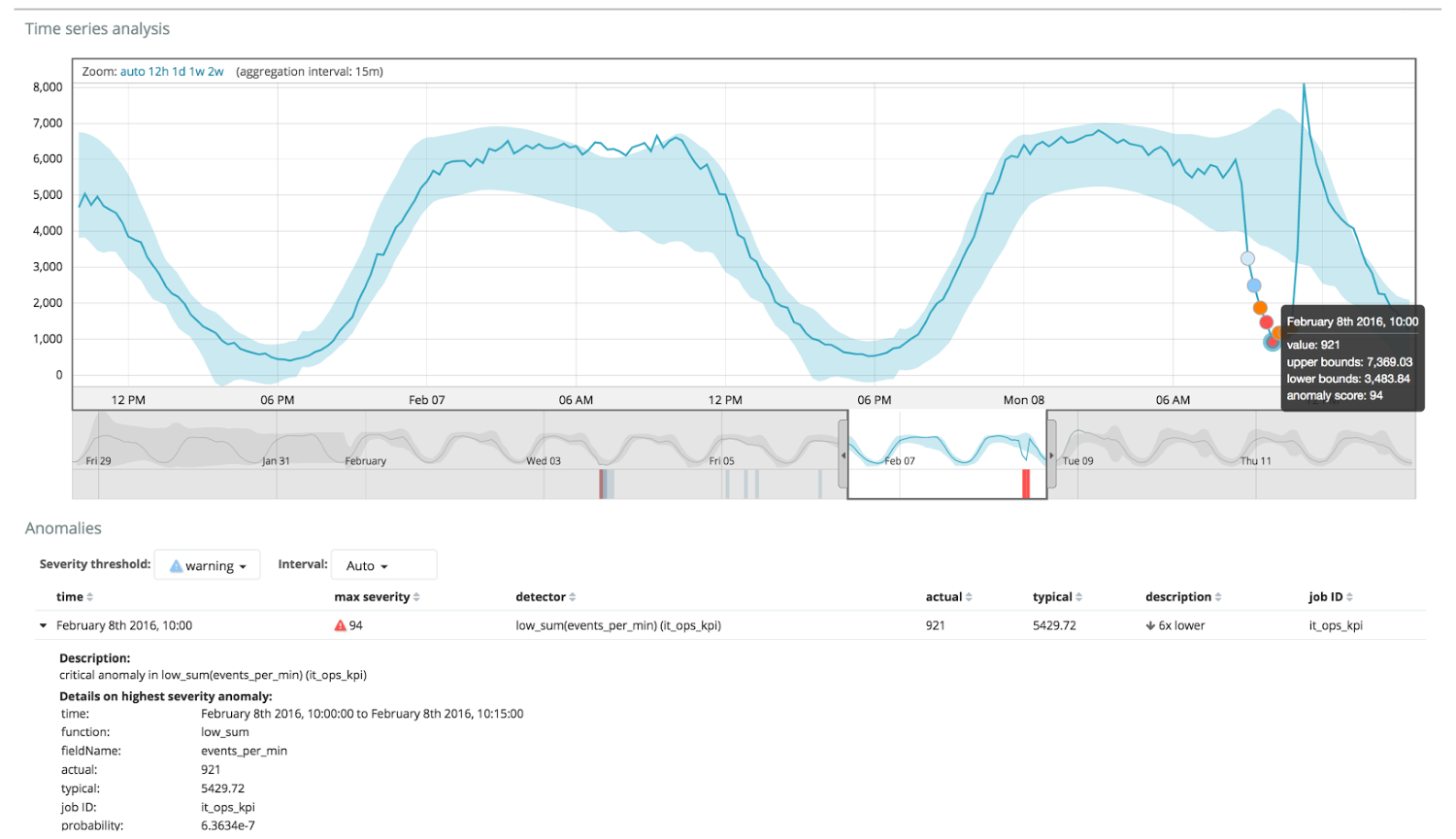
Here you can see the number 94, which indicates the probability of an anomaly. It is clear that since the value is close to 100, it means an anomaly. The column under the graph shows a derogatory probability of 0.000063634% of the appearance of the metric value there.
In addition to searching for anomalies in Kibana, you can run forecasting. This is done in an elementary way and from the same view with anomalies - the Forecast button in the upper right corner.

The forecast is based on a maximum of 8 weeks in advance. Even if you really want to, you can no longer by design.
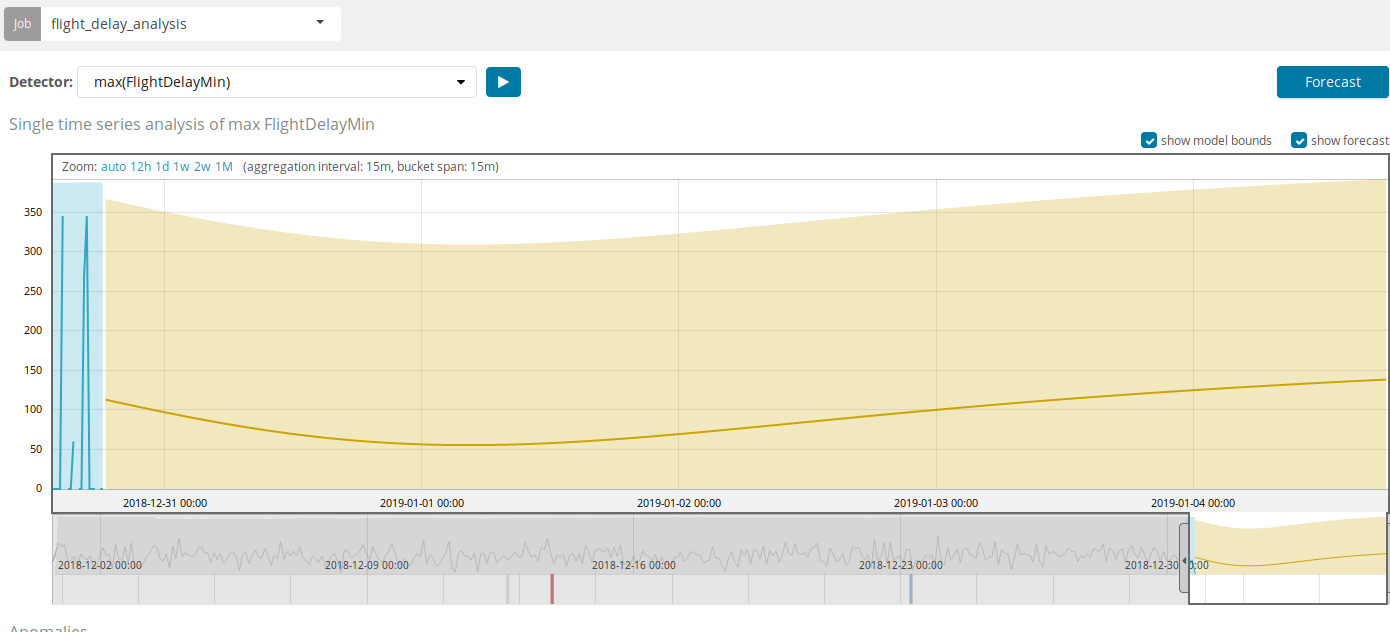
In some situations, the forecast will be very useful, for example, when the user load on the infrastructure is monitored.
Multi metric
We move on to the next ML feature in Elastic Stack - analysis of several metrics in one bundle. But this does not mean that the dependence of one metric on another will be analyzed. This is the same as Single Metric with only a lot of metrics on one screen for easy comparison of the effects of one on the other. We will talk about the analysis of the dependence of one metric on another in the part of Population.
After clicking on the square with Multi Metric, a settings window will appear. We will dwell on them in more detail.
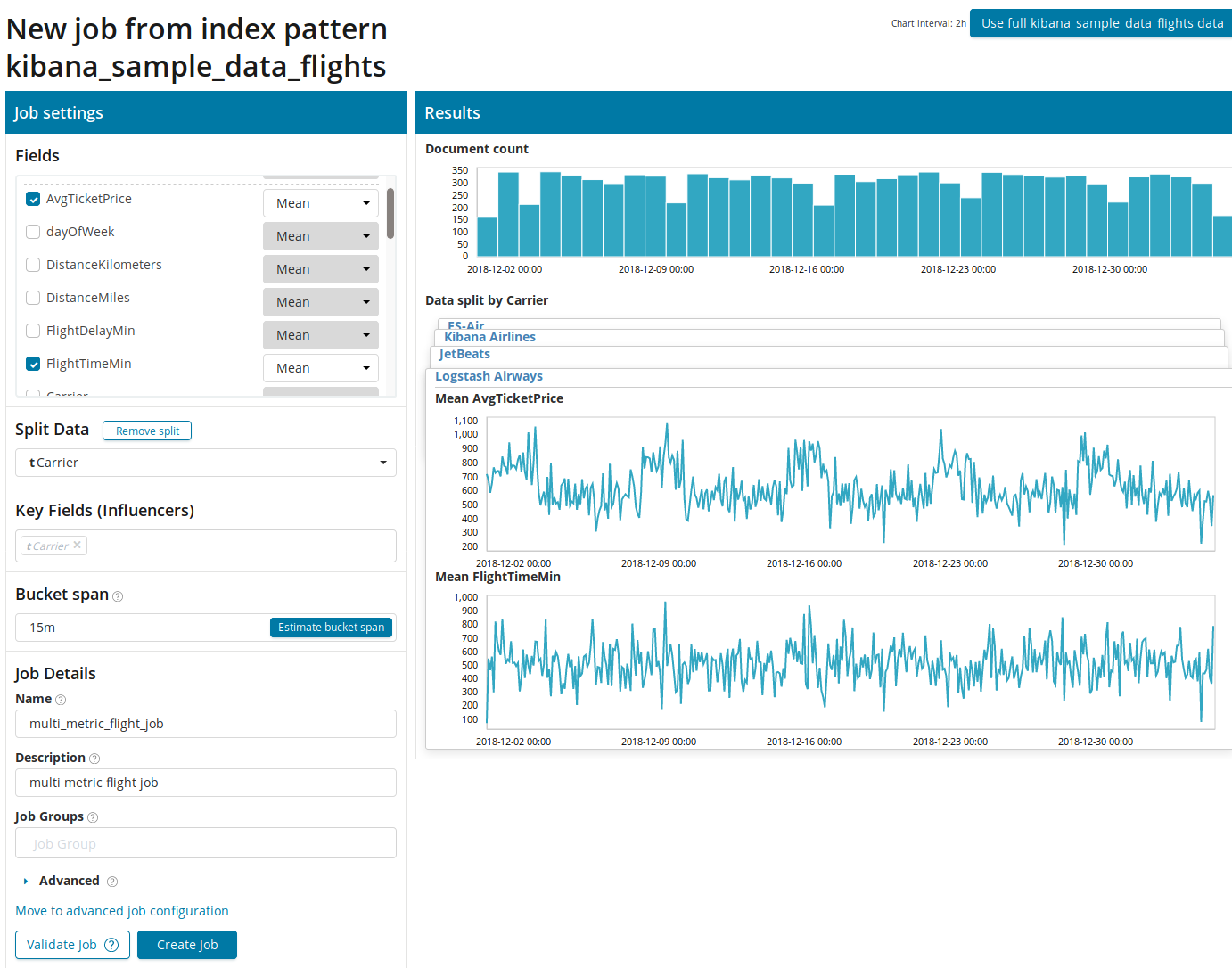
First you need to select the fields for analysis and aggregation of data on them. The aggregation options here are the same as for Single Metric ( Max, Hign Mean, Low, Mean, Distinct, and others). Further, the data is optionally divided into one of the fields (field Split Data ). In the example, we did this by fieldOriginAirportID . Note that the metrics graph on the right is now presented as multiple graphs.
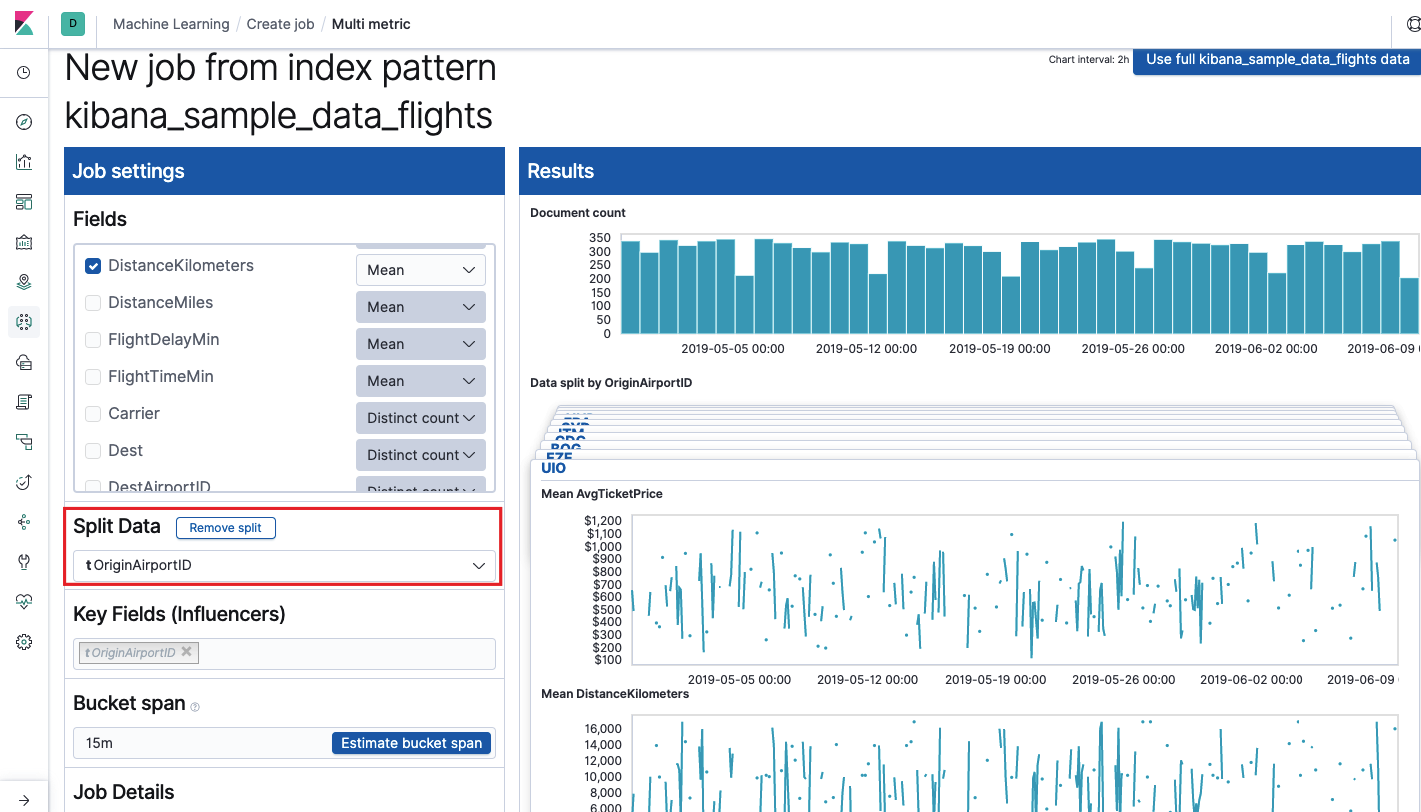
The Key Fields (Influencers) field directly affects the anomalies found. By default, there will always be at least one value, and you can add additional ones. The algorithm will take into account the influence of these fields in the analysis and show the most “influential” values.
After launching, the following picture will appear in the Kibana interface.
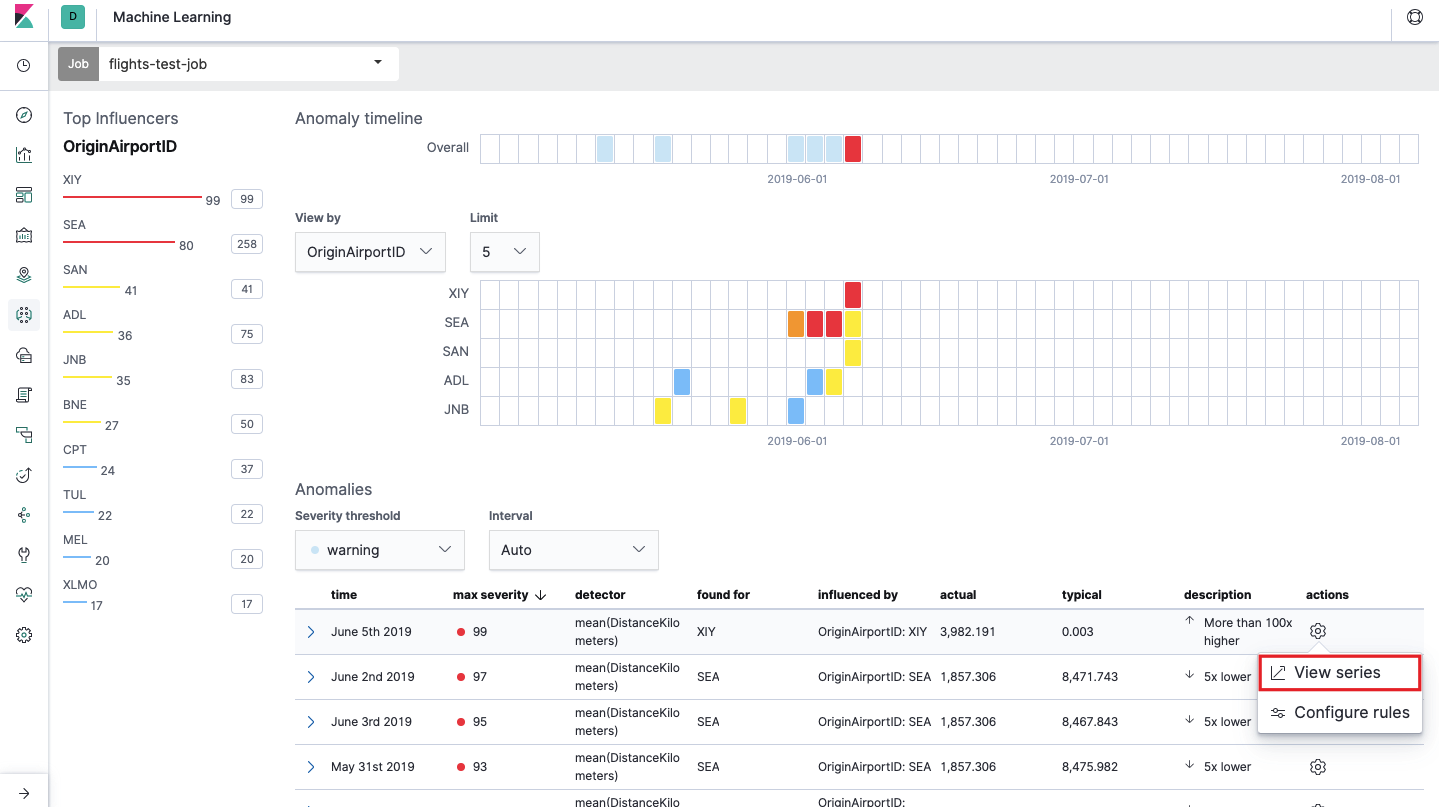
This is the so-called heat map of anomalies for each value of the OriginAirportID field that we specified in Split Data. As with Single Metric, color indicates the level of abnormal deviation. It is convenient to do a similar analysis, for example, on workstations to track those where there are suspiciously a lot of authorizations, etc. We already wrote about suspicious events in EventLog Windows , which can also be collected and analyzed here.
Below the heatmap is a list of anomalies, from each one you can go to the Single Metric view for detailed analysis.
Population
To search for anomalies among the correlations between different metrics, Elastic Stack has a specialized Population analysis. It is with the help of it that you can search for anomalous values in the performance of a server compared to others with, for example, an increase in the number of requests to the target system.
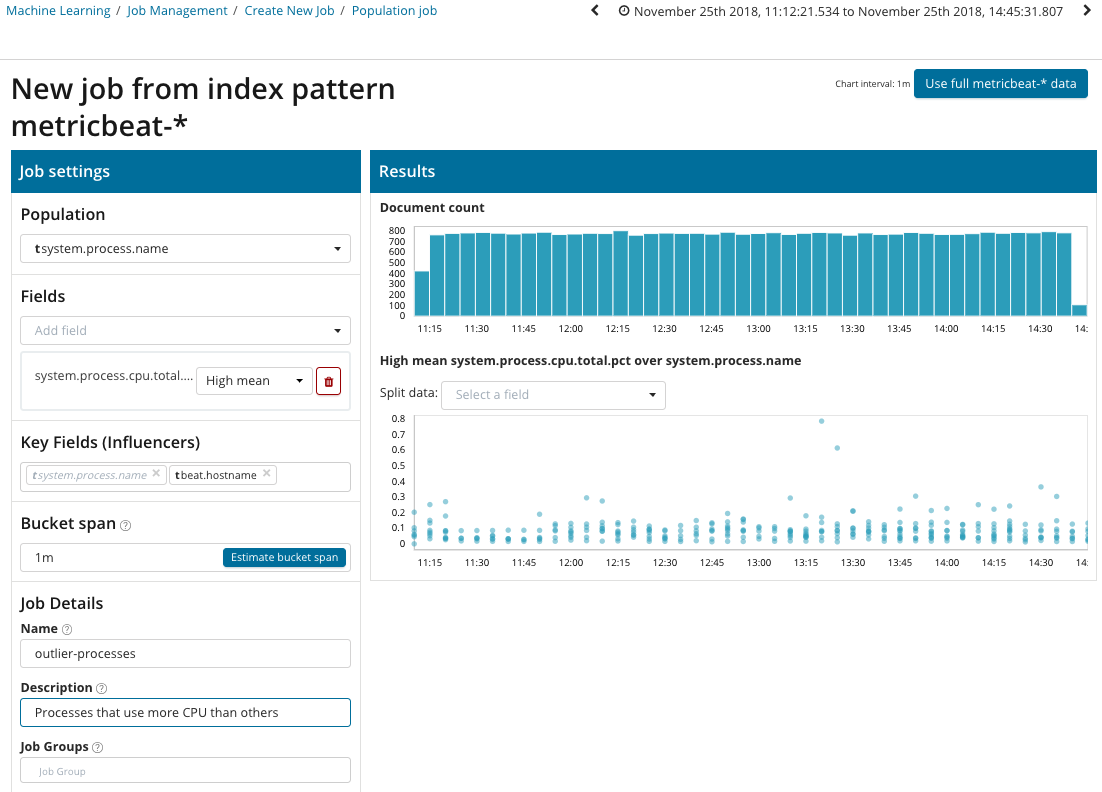
In this illustration, the Population field indicates the value to which the analyzed metrics will relate. This is the name of the process. As a result, we will see how processor loading by each of the processes influenced each other.
Please note that the graph of the analyzed data is different from the cases with Single Metric and Multi Metric. This is done in Kibana by design for an improved perception of the distribution of values of the analyzed data.

The graph shows that the process abnormally behavedstress (by the way, generated by a special utility) on the poipu server , which affected (or turned out to be an influencer) the occurrence of this anomaly.
Advanced
Fine-tuned analytics. With Advanced Analysis, additional settings appear in Kibana. After clicking on the create menu on the Advanced tile, such a tabbed window appears. The Job Details tab was deliberately skipped, there the basic settings are not directly related to the analysis settings.
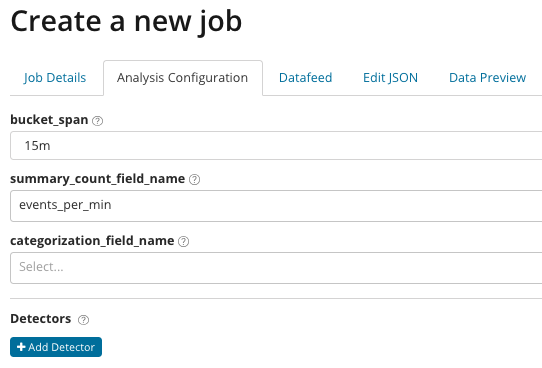
In summary_count_field_name, you can optionally specify the name of the field from documents containing aggregated values. In this example, the number of events per minute. In categorization_field_name it indicated the name of the field value from a document that contains some variables. By mask on this field, you can break the analyzed data into subsets. Pay attention to the Add detector buttonin the previous illustration. Below is the result of clicking on this button.

Here is an additional settings block for setting up the anomaly detector for a specific task. We plan to analyze specific use cases (especially for security) in the following articles. For an example, look at one of the disassembled cases. It is associated with the search for rarely appearing values and is implemented by the rare function .
In the function field, you can select a specific function to search for anomalies. In addition to rare , there are a couple of interesting functions - time_of_day and time_of_week . They identify anomalies in the behavior of metrics throughout the day or week, respectively. Other analysis functionsis in the documentation .
The field_name indicates the field of the document that will be analyzed. By_field_name can be used to separate analysis results for each individual value of the document field specified here. If you fill in over_field_name you get the population analysis, which we examined above. If you specify a value in partition_field_name , then on this document field individual baselines for each value will be calculated (for example, the name of the server or the process on the server can play the role of the value). In exclude_frequent, you can select all or none, which will mean the exclusion (or inclusion) of frequently occurring document field values.
In the article we tried to give the most concise idea about the possibilities of machine learning in Elastic Stack, there are still a lot of details behind the scenes. Tell us in the comments which cases you managed to solve with the help of Elastic Stack and for what tasks you use it. To contact us, you can use personal messages on Habré or the feedback form on the site .