Top development mistakes when working with PostgreSQL
HighLoad ++ has been around for a long time, and we talk about working with PostgreSQL regularly. But developers still have the same problems from month to month, from year to year. When in small companies without a DBA in the state there are errors in working with databases, this is not surprising. Large companies also need databases, and even with debugged processes, errors still occur and the databases fall. It doesn’t matter what size the company is - errors still occur, databases periodically crash, crash.

Of course, this will never happen to you, but checking the checklist is not difficult, and it can be very decent to save future nerves. Under the cat, we’ll list the top typical mistakes that developers make when working with PostgreSQL, see why we don’t need to do this, and find out how.
About the speaker: Aleksei Lesovsky ( lesovsky ) started Linux system administrator. From tasks of virtualization and monitoring systems gradually came to PostgreSQL. Now PostgreSQL DBA in Data Egret , a consulting company that works with a lot of different projects and sees many examples of recurring problems. This is a link to the presentation of the report at HighLoad ++ 2018.
To warm up, a few stories about how errors occur.
One of the problems is what features the company uses when working with PostgreSQL. It all starts simple: PostgreSQL, datasets, simple queries with JOIN. We take the data, do SELECT - everything is simple.
Then we begin to use the additional functionality of PostgreSQL, add new functions, extensions. The feature is getting bigger. We connect streaming replication, sharding. Various utilities and body kits appear around - pgbouncer, pgpool, patroni. Like that.

The way we store data is also a source of errors.
When the project first appeared, there were quite a few data and tables in it. Simple queries are enough to receive and record data. But then there are more and more tables. Data is selected from different places, JOINs appear. Queries are complicated and include CTE constructs, SUBQUERY, IN lists, LATERAL. Making a mistake and writing a curve query becomes much easier.
And this is just the tip of the iceberg - somewhere on the side there can be another 400 tables, partitions, from which data is also occasionally read.
The story of how the product is followed. Data always needs to be stored somewhere, so there is always a database. How does a database develop when a product develops?
On the one hand, there are developers who are busy with programming languages. They write their applications and develop skills in the field of software development, not paying attention to services. Often they are not interested in how Kafka or PostgreSQL works - they develop new features in their application, and they do not care about the rest. Admins, on the

other hand . They raise new Amazon instances on Bare-metal and are busy with automation: they set up deployments to make the layout work well, and configs so that the services interact well with each other.

There is a situation when there is no time or desire for thin tuning of components, and the database as well. The databases work with default configs, and then they completely forget about them - “it works, don’t touch it”.
As a result, rakes are scattered in various places, which now and then fly into the forehead of the developers. In this article, we will try to collect all these rakes in one shed so that you know about them and do not step on them when working with PostgreSQL.
First, imagine that we have a new project - it is always an active development, hypothesis testing and implementation of new features. At the moment when the application has just appeared and is developing, it has little traffic, users and customers, and they all generate small amounts of data. The database has simple queries that are quickly processed. No need to drag large amounts of data, there are no problems.
But there are more users, traffic comes: new data appears, databases grow and old queries stop working. It is necessary to complete indexes, rewrite and optimize queries. There are performance issues. All this leads to alerts at 4 a.m., stress for admins and discontent of the management.
The first example . We open the schedule for monitoring disk utilization, and we see that the free space on the disk is running out .
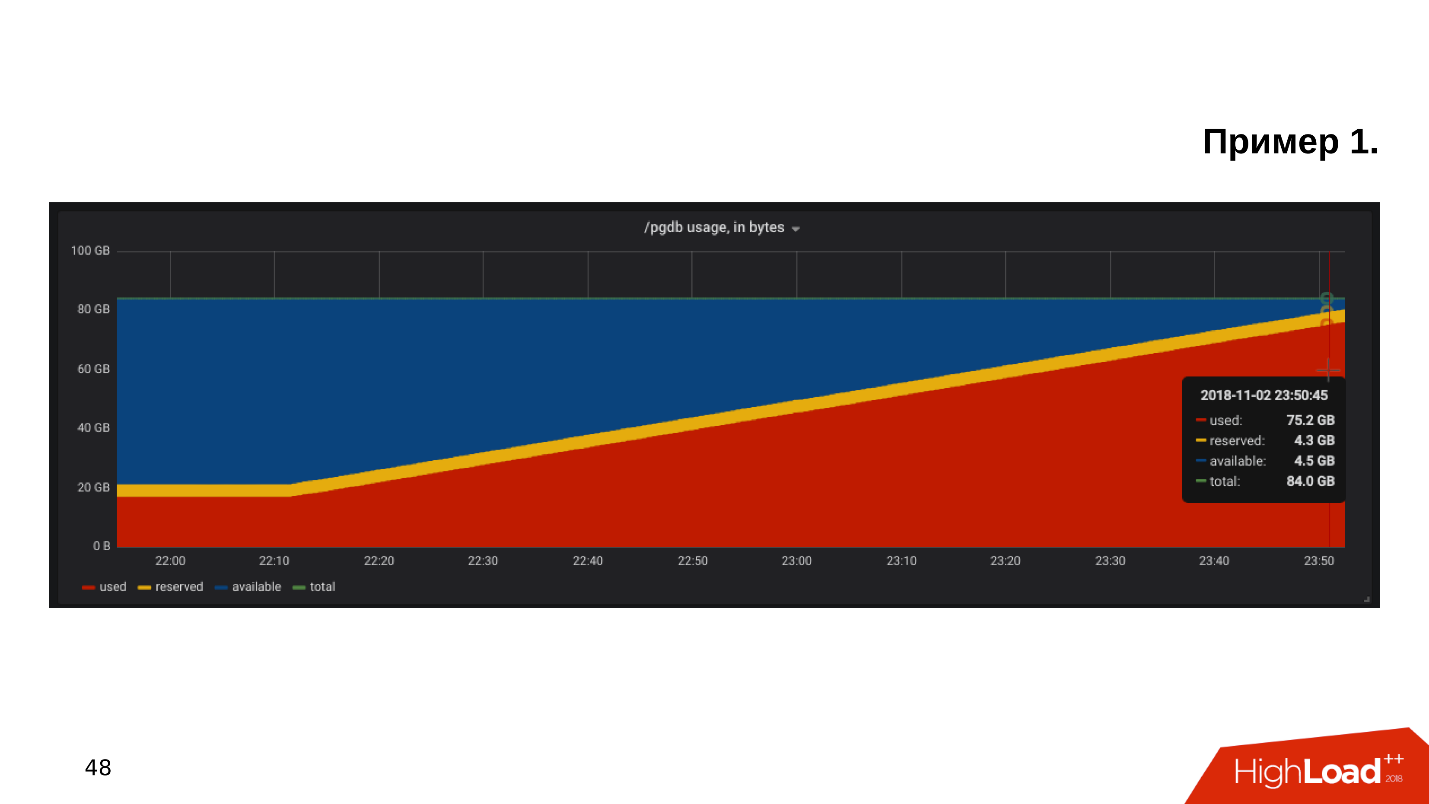
We look at how much space and what is eaten up - it turns out there is a pg_xlog directory:
Database admins usually know what this directory is, and they don’t touch it - it exists and exists. But the developer, especially if he looks at staging, scratches his head and thinks:
- Some kind of logs ... Let's delete pg_xlog!
Deletes the directory, the database stops working . Immediately you have to google how to raise the database after you deleted the transaction logs.

Second example . Again, we open monitoring and see that there is not enough space. This time the place is occupied by some kind of base.
We are looking for which database takes up the most space, which tables and indexes.

It turns out that this is a table with historical logs. We never needed historical logs. They are written just in case, and if it were not for the problem with the place, no one would have looked at them until the second coming:
- Come on, we’ll clean everything that is ... older than October!
Make an update request, run it, it will work out and delete some of the lines.
The query runs for 10 minutes, but the table still takes up the same amount of space.
PostgreSQL removes rows from the table - everything is correct, but it does not return the place to the operating system. This behavior of PostgreSQL is unknown to most developers and can be very surprising.
The third example . For example, ORM made an interesting request. Usually everyone blames ORM for making “bad” queries that read out a few tables.
Suppose there are several JOIN operations that read tables in parallel in multiple threads. PostgreSQL can parallelize data operations and can read tables in multiple threads. But, given that we have several application servers, this query reads all the tables several thousand times per second. It turns out that the database server is overloaded, the disks cannot cope, and all this leads to a 502 Bad Gateway error from the backend - the database is unavailable.
But that is not all. You can recall other features of PostgerSQL.
How to be Need monitoring and planning! It would seem obvious, but for some reason, in most cases, no one plans a base, and monitoring does not cover all that needs to be monitored during the operation of PostgreSQL. There is a set of clear rules, with which everything will work well, and not "at random".
Host the database on an SSD without hesitation . SSDs have long become reliable, stable and productive. Enterprise SSD models have been around for years.
Always plan a data schema . Do not write to the database that you doubt what is needed - guaranteed not to be needed. A simple example is a slightly modified table of one of our customers.

This is a log table in which there is a data column of type json. Relatively speaking, you can write anything in this column. From the last record of this table it can be seen that the logs occupy 8 MB. PostgreSQL has no problem storing records of this length. PostgreSQL has very good storage that chews on such records.
But the problem is that when application servers read data from this table, they will easily clog the entire network bandwidth, and other requests will suffer. This is the problem of planning a data schema.
Use partitioning for any hint of a story that needs to be stored for more than two years . Partitioning sometimes seems complicated - you need to bother with triggers, with functions that will create partitions. In new versions of PostgreSQL, the situation is better and now setting up partitioning is much simpler - once done, and works.
In the considered example of deleting data in 10 minutes,
When the data is sorted by partition, the partition is deleted literally in a few milliseconds, and the OS takes over immediately. Managing historical data is easier, easier, and safer.
Monitoring is a separate big topic, but from the point of view of the database there are recommendations that can fit into one section of the article.
By default, many monitoring systems provide monitoring of processors, memory, network, disk space, but, as a rule, there is no disposal of disk devices . Information about how loaded the disks are, what bandwidth is currently on the disks and the latency value should always be added to the monitoring. This will help you quickly evaluate how drives are loaded.
There are a lot of PostgreSQL monitoring options, there are for every taste. Here are some points that must be present.
For more information, see the “PostgreSQL Monitoring Basics” report with HighLoad ++ Siberia and the Monitoring page in the PostgreSQL Wiki.
When we planned everything and “covered ourselves” with monitoring, we can still encounter some problems.
Typically, the developer sees the database line in the config. He is not particularly interested in how it is arranged internally - how checkpoint, replication, scheduler works. The developer already has something to do - in todo there are a lot of interesting things that he wants to try.
Ignorance of the subject leads to quite interesting consequences when the developer begins to write queries that work in this database. Fantasies when writing queries sometimes give stunning effects.
There are two types of transactions. OLTP transactions are fast, short, lightweight that take fractions of a millisecond. They work out very quickly, and there are a lot of them. OLAP - analytical queries - slow, long, heavy, read large arrays of tables and read statistics.
The last 2-3 years often abbreviated as HTAP - Hybrid Transaction / Analytical Processing or hybrid transactional-analytical processing. If you have no time to think about scaling and diversity of OLAP and OLTP requests, you can say: “We have HTAP!” But the experience and the pain of errors show that, after all, different types of requests must live separately from each other, because long OLAP requests block light OLTP requests.
So we come to the question of how to scale PostgreSQL so as to spread the load, and everyone was satisfied.
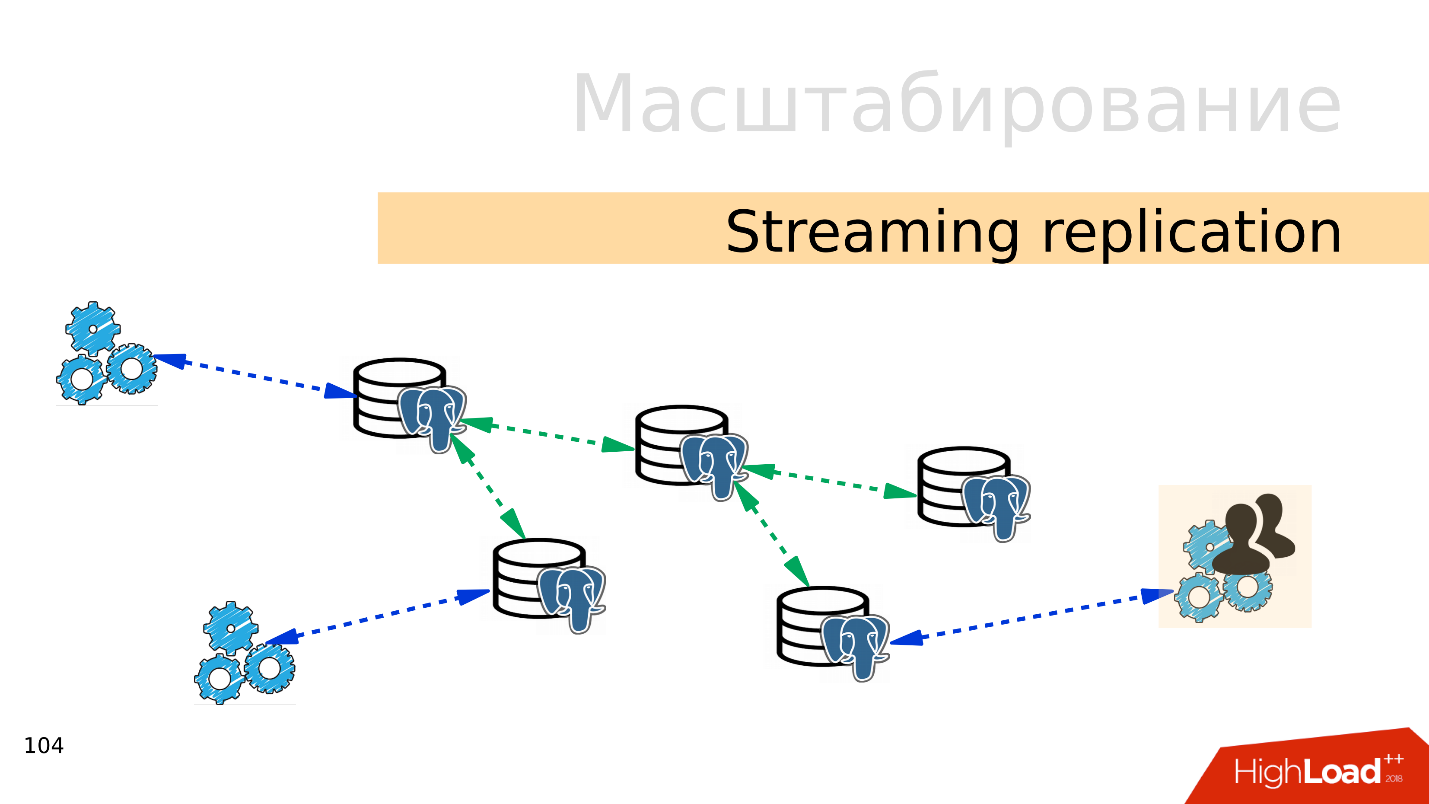
Streaming replication . The easiest option is streaming replication . When the application works with the database, we connect several replicas to this database and distribute the load. Recording still goes to the master base, and reading to replicas. This method allows you to scale very widely.
Plus, you can connect more replicas to individual replicas and getcascading replication . Separate user groups or applications that, for example, read analytics, can be moved to a separate replica.
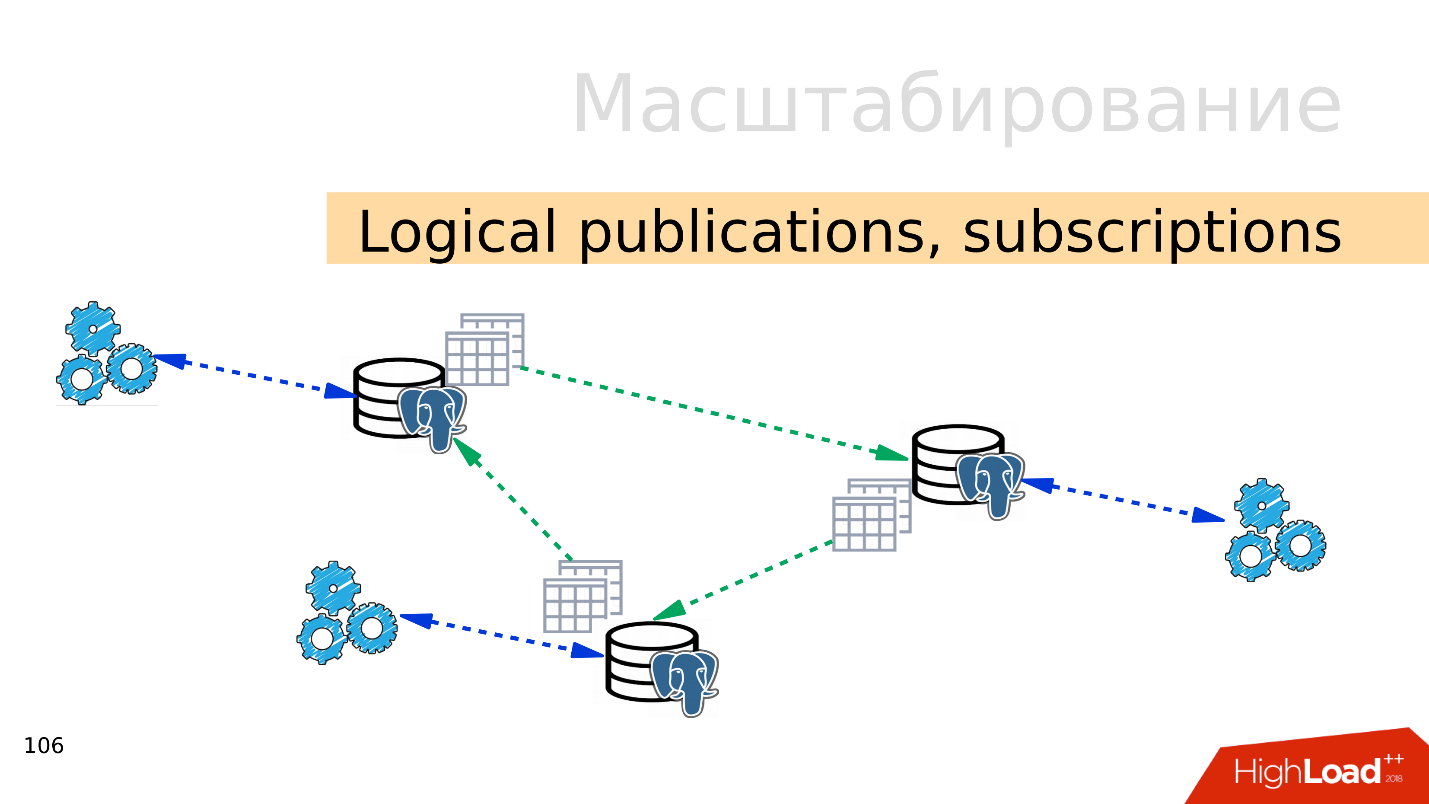
Logical publications, subscriptions - the mechanism of logical publications and subscriptions implies the presence of several independent PostgreSQL-servers with separate databases and sets of tables. These sets of tables can be connected to neighboring databases, they will be visible to applications that can use them normally. That is, all changes that occur in the source are replicated to the destination base and are visible there. Works great with PostgreSQL 10.
Foreign tables, Declarative Partitioning - declarative partitioning and external tables. You can take several PostgreSQL and create several sets of tables there that will store the desired data ranges. This can be data for a specific year or data collected over any range.
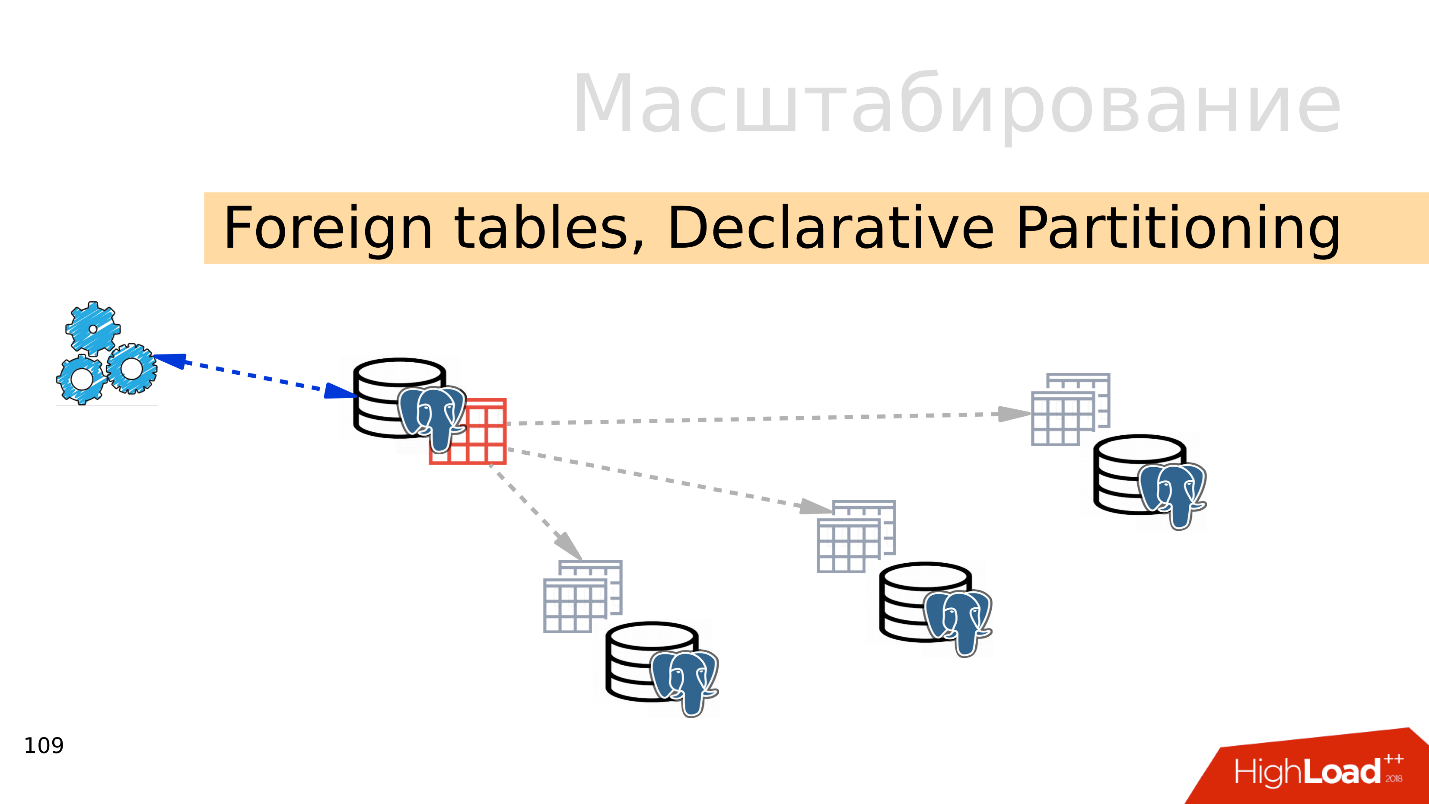
Using the mechanism of external tables, you can combine all these databases in the form of a partitioned table in a separate PostgreSQL. An application may already work with this partitioned table, but in fact it will read data from remote partitions. When data volumes are more than the capabilities of a single server, then this is sharding.

All this can be combined into spreading configurations, to come up with different PostgreSQL replication topologies, but how it all works and how to manage it is the topic of a separate report.
The easiest option is with replication . The first step is to spread the load on reading and writing. That is, write to the master, and read from replicas. So we scale the load and carry out the reading from the wizard. In addition, do not forget about the analysts. Analytical queries work for a long time, they need a separate replica with separate settings so that long analytical queries can not interfere with the rest.
The next step is balancing . We still have the same line in the config that the developer operates on. He needs a place where he will write and read. There are several options here.
Ideal - implement application-level balancingwhen the application itself knows where to read the data from, and knows how to choose a replica. Suppose an account balance is always needed up-to-date and needs to be read from the master, and the product picture or information about it can be read with some delay and done from a replica.
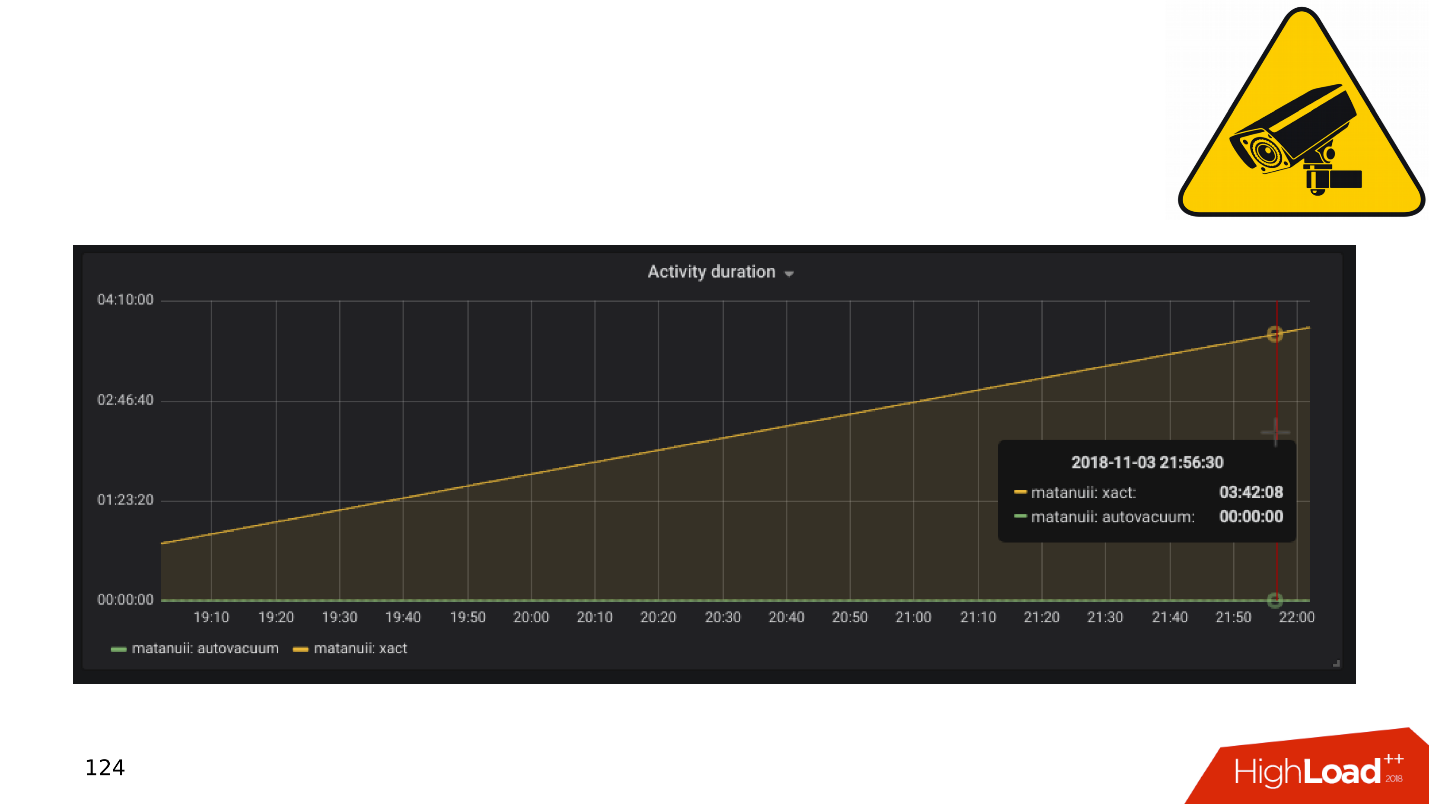
And there are nuances with replication, the most common of which is the replication lag . You can do it like GitLab, and when the lag accumulates, just drop the base. But we have comprehensive monitoring - we look at it and see long transactions.
In general, slow and idle transactions result in:
Let's look at a little theory about how these problems arise, and why the mechanism of long and idle transactions is harmful.
PostgreSQL has MVCC - relatively speaking, a database engine. It allows customers to work competitively with data without interfering with each other: readers do not interfere with readers, and writers do not interfere with writers. Of course, there are some exceptions, but in this case they are not important.
It turns out that in the database for one row there can be several versions for different transactions. Clients connect, the database gives them snapshots of data, and within these snapshots different versions of the same line may exist. Accordingly, in the life cycle of the database, transactions are shifted, replace each other, and versions of rows appear that no one needs.
So arisesthe need for a garbage collector is auto vacuum . Long transactions exist and prevent auto vacuum from cleaning out unnecessary row versions. This junk data begins to wander from memory to disk, from disk to memory. To store this garbage, CPU and memory resources are wasted.
From the point of view of “Who is to blame?”, The app is to blame for the appearance of long transactions. If the database will exist on its own, long, do-nothing transactions will not be taken from anywhere. In practice, there are the following options for the appearance of idle transactions.
"Let's go to an external source . " The application opens a transaction, does something in the database, then decides to turn to an external source, for example, Memcached or Redis, in the hope that it will then return to the database, continue working and close the transaction. But if an error occurs in the external source, the application crashes and the transaction remains closed until someone notices it and kills it.
No error handling. On the other hand, there may be a problem handling errors. When, again, the application opened a transaction, solved some problem in the database, returned to code execution, performed some functions and calculations, in order to continue working in the transaction and close it. When on these calculations the application operation was interrupted with an error, the code returned to the beginning of the cycle, and the transaction again remained unclosed.
The human factor . For example, an administrator, developer, analyst, works in some pgAdmin or in DBeaver - opened a transaction, does something in it. Then the person was distracted, he switched to another task, then to the third, forgot about the transaction, left for the weekend, and the transaction continues to hang. Base performance suffers.
Let's see what to do in these cases.
Everything becomes even more interesting when pending tasks appear, for example, you need to carefully calculate the units. And we come to the issue of bicycle construction.
Sensitive subject. Business on the application side needs to perform background processing of events. For example, to calculate aggregates: minimum, maximum, average value, send notifications to users, issue invoices to customers, set up a user’s account after registration or register in neighboring services - do delayed processing.
The essence of such tasks is the same - they are postponed for later. Tables appear in the database that just execute the queues.

Here is the identifier of the task, the time when the task was created, when updated, the handler that took it, the number of attempts to complete. If you have a table that even remotely resembles this one, then you have self-written queues .
All this works fine until long transactions appear. After that, tables that work with queues swell in size . New jobs are added all the time, old ones are deleted, updates happen - a table with intensive recording is obtained. It should be cleaned regularly from outdated versions of strings so that performance does not suffer.
Processing time is growing - a long transaction holds a lock on outdated versions of rows or prevents vacuum from cleaning it. When the table grows in size, the processing time also increases, since you need to read many pages with garbage. Time increases, and the queue at some point ceases to work at all .
Below is an example of the top of one of our customers, who had a queue. All requests are just related to the queue.

Pay attention to the execution time of these requests - all but one of them work for more than twenty seconds.
To solve these problems, Skytools PgQ , a queue manager for PostgreSQL, was invented long ago . Do not reinvent your bike - take PgQ, set it up once and forget about the lines.
True, he also has features. Skytools PgQ has little documentation . After reading the official page, one gets the feeling that he did not understand anything. The feeling grows when you try to do something. Everything works, but how it works is not clear . Some kind of Jedi magic. But you can get a lot of information atMailing-lists . This is not a very convenient format, but a lot of interesting things are there, and you will have to read these sheets.
Despite the cons, Skytools PgQ works on the principle of "set up and forget." A trigger function is created that is hung on the table with which we want to receive changes, and everything works reliably. Almost remember about PgQ when you need to add another table to the queue. Using PgQ is cheaper than supporting and setting up individual brokers.
In our practice, we saw a lot of self-written bursts and replaced them with PgQ. Of course, there are large installations of PostgreSQL, for example, in Avito, where PgQ features are not enough. But these are single cases that are decided separately.
Admins from automation want to be able to roll out instances so that the deploy works without their intervention and configs roll out instantly. And the developers want the deployment to work in such a way that as soon as they commit some changes, they will continue to pull themselves up, test, spill and everything would be fine. Of course, they want to roll migrations without manual intervention, so that they do not need to log in to the server, perform alter with their hands.
Together they want an auto-failover - if suddenly during the operation of the PostgreSQL cluster some kind of failure occurs, the role of the wizard will automatically be transferred to another server, and we did not even know anything about it. But there are some very serious problems that prevent the use of auto-failover.
Split brain. In a normal PostgreSQL cluster with a master and several replicas, writing goes to one server, reading from replicas. If a failure occurs, the server shuts down. But in PostgreSQL, there is no fencing mechanism out of the box, and often even in Kubernets you have to configure it separately. If the application crashes, it can still write to the old master, and the new switching application starts writing to the new master. There is a situation of Split-brain.

Trying to restore consistency can be very difficult and will require a lot of nerves. When GitHub collided with a split-brain, they had to restore their base from backup.
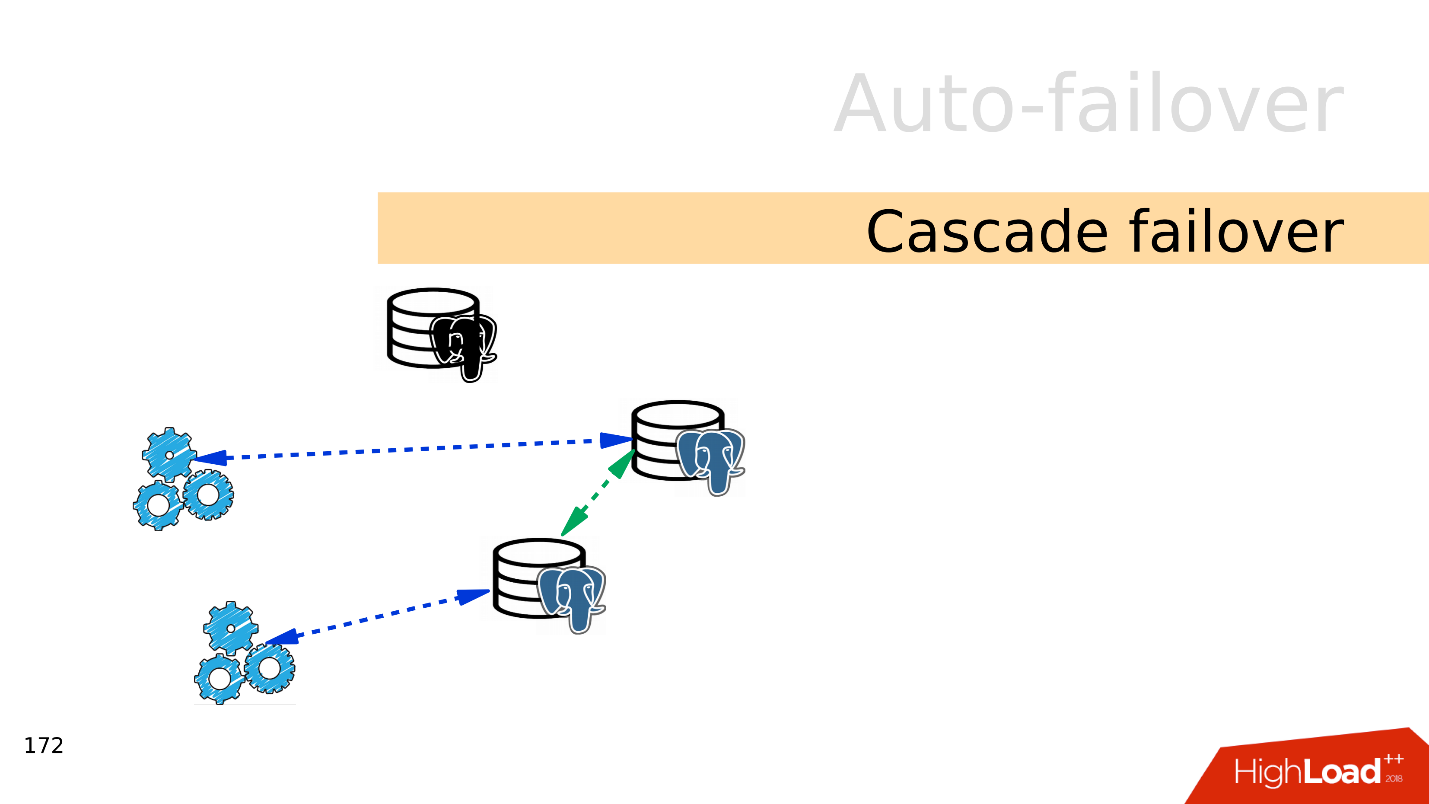
Cascade failover . Let's say there is a master and several replicas. The master drops and the load switches to the new master and the remaining replicas.
The old master did not have time to reinitialize and become a replica, and at that moment another master falls. It takes seconds, and all the load falls on a single server.
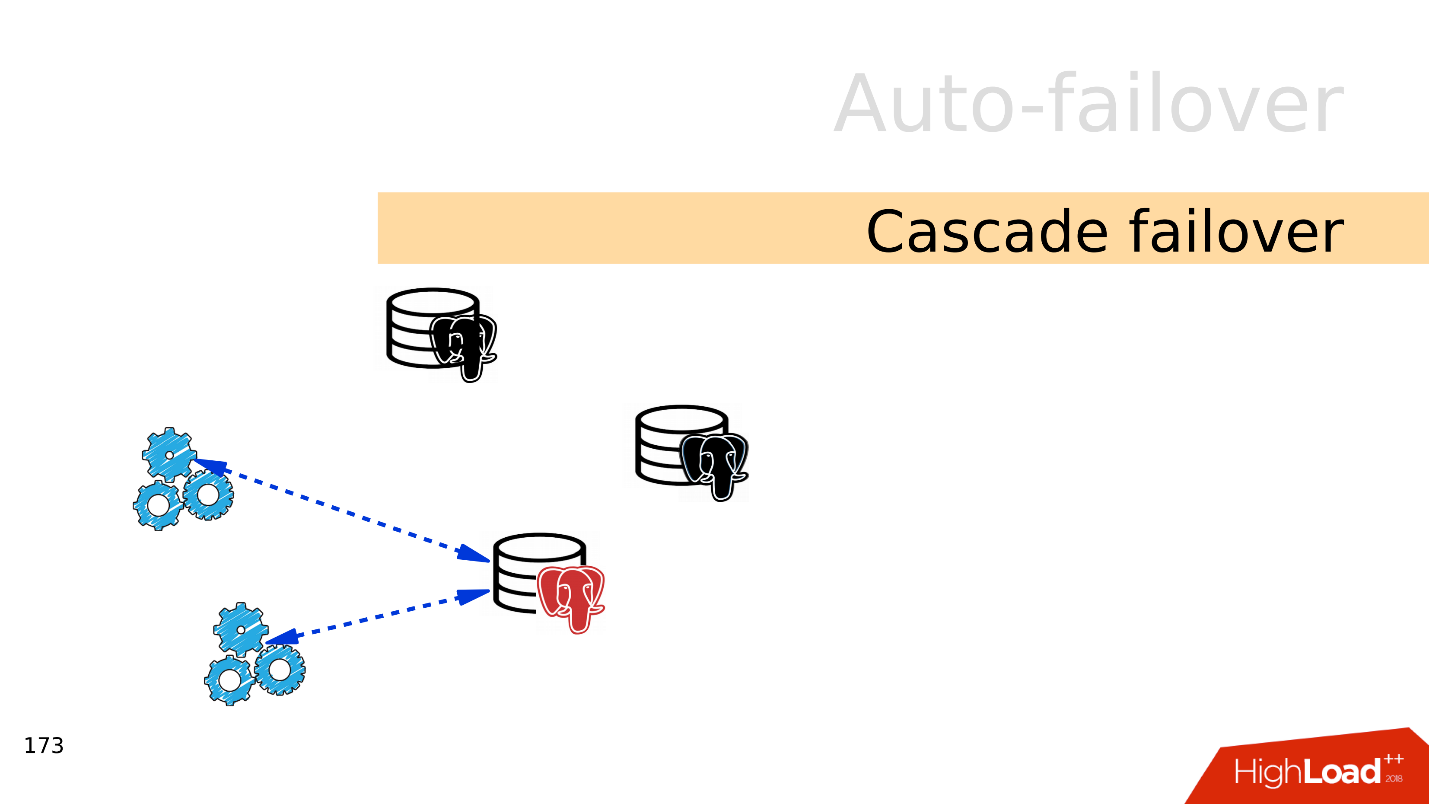
It does not cope with the load and also fails - it turns out a cascading failover.
If you still take on auto-failover, then there are the following ways.
Bash scripts are a fragile solution that needs to be constantly tested and debugged. One admin has left, another has come and does not know how to use it. If suddenly something breaks, it is very difficult to find where what happened. This solution requires constant refinement.
Ansible playbooks - bash scripts on steroids. Also, you need to constantly check that everything works, run on test clusters.
Patroni - in my opinion, one of the best products, because it has auto-failover, monitoring the status of the cluster, plus the function of returning the cluster topology to service discovery.
PAF - Based on Pacemaker . Also an interesting tool for auto-failover in PostgreSQL, but it is already more complicated and requires knowledge of Pacemaker.
Stolon is more for cloud computing . For Kubernetes, for example. Stolon is more complex than Patroni, but they are interchangeable and you can choose between them.
In recent years, Docker and Kubernetes have been growing. These are dynamically developing technologies in which a lot of new things appear.
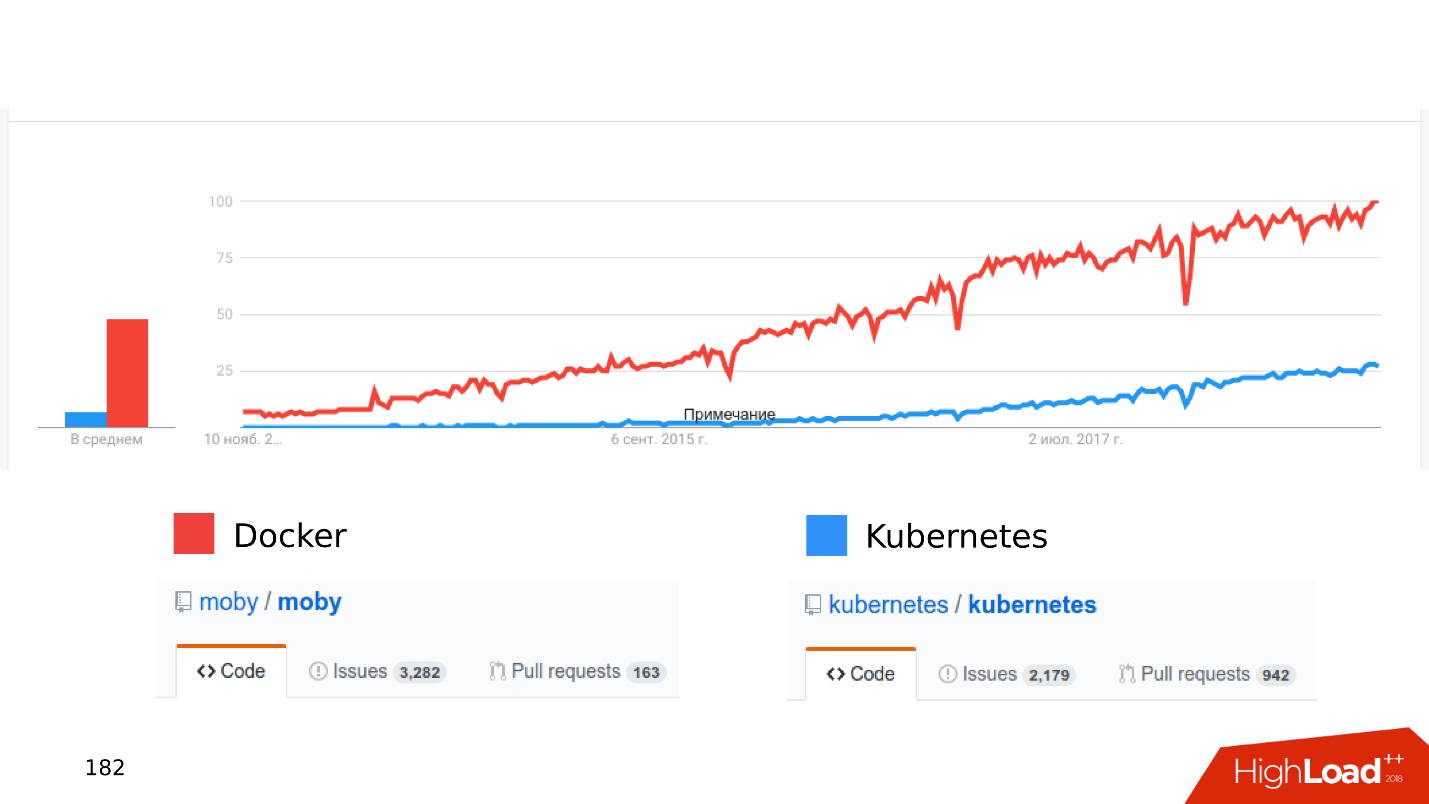
Each new version adds a lot of interesting functionality, though the old one may stop working. With “What if you deploy the base in Kubernetes ...” various amazing stories begin.
The base is always stateful , it needs to be stored somewhere. Where? Fault-tolerant network storage comes to mind. Solutions from Open Source: CEPH, GlusterFS, LinStor DRBD. The fundamental problem is that it all works very slowly and probably will never work fast.
As a bonus, you get an additional headache - the need to support a clustered file system. For example, if you are only familiar with Kubernetes, you will have to study CEPH in depth. This is a complex system with a lot of problems - you will have to increase your expertise. Speaking generally about network attached storage and databases in them, then this works while three requirements are met.
This brings us to the fact that it’s good to use Kubernetes and Docker for the database on staging or dev-servers or at the stage of hypothesis testing. But for high loads, in my opinion, Kubernetes and shared storage are not very good.
But if you really want to, then the best option would be local volumes - local storage without the use of shared file systems, streaming replication - native streaming replication through which data is synchronized and PostgreSQL-operators that provide us with something like a button - clicked, and it worked. There are currently two such operators: Zalando and Crunchy .
Of course, it is worth remembering that all this is developing dynamically. Look at the number of issues and pull requests. New features appear, errors may be hidden in them, so implement containerization without fanaticism.
When you are planning and monitoring, do not save on SSDs - they are relatively cheap and will delay performance problems for a year or even more.
Do not write everything to the database . The practice of writing 8 MB JSON is bad, you can't do that.
Monitoring is needed , and do not leave it in the default state. Monitor PostgreSQL, expand your monitoring.
Spread the load - Postgres is ready . Try not to read or write data from one place. PostgreSQL scales very well, and there are options for scaling it for every taste. To scale the load, use: streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
Avoid doing nothing . They reduce performance and very slowly but surely kill the base.
If you are doing something that other people might already need, look around - maybe everything is already there . This directly relates to queues. Do not invent self-written lines, use Skytools PgQ!
If you really want a base in Kubernetes, use local volumes, streaming replication and PostgreSQL operators . You can somehow work with this, but without fanaticism, because everything is changing very quickly.
Of course, this will never happen to you, but checking the checklist is not difficult, and it can be very decent to save future nerves. Under the cat, we’ll list the top typical mistakes that developers make when working with PostgreSQL, see why we don’t need to do this, and find out how.
About the speaker: Aleksei Lesovsky ( lesovsky ) started Linux system administrator. From tasks of virtualization and monitoring systems gradually came to PostgreSQL. Now PostgreSQL DBA in Data Egret , a consulting company that works with a lot of different projects and sees many examples of recurring problems. This is a link to the presentation of the report at HighLoad ++ 2018.
Where do the problems come from
To warm up, a few stories about how errors occur.
History 1. Features
One of the problems is what features the company uses when working with PostgreSQL. It all starts simple: PostgreSQL, datasets, simple queries with JOIN. We take the data, do SELECT - everything is simple.
Then we begin to use the additional functionality of PostgreSQL, add new functions, extensions. The feature is getting bigger. We connect streaming replication, sharding. Various utilities and body kits appear around - pgbouncer, pgpool, patroni. Like that.
Each keyword is a reason for an error to appear.
History 2. Data Storage
The way we store data is also a source of errors.
When the project first appeared, there were quite a few data and tables in it. Simple queries are enough to receive and record data. But then there are more and more tables. Data is selected from different places, JOINs appear. Queries are complicated and include CTE constructs, SUBQUERY, IN lists, LATERAL. Making a mistake and writing a curve query becomes much easier.
And this is just the tip of the iceberg - somewhere on the side there can be another 400 tables, partitions, from which data is also occasionally read.
History 3. Life Cycle
The story of how the product is followed. Data always needs to be stored somewhere, so there is always a database. How does a database develop when a product develops?
On the one hand, there are developers who are busy with programming languages. They write their applications and develop skills in the field of software development, not paying attention to services. Often they are not interested in how Kafka or PostgreSQL works - they develop new features in their application, and they do not care about the rest. Admins, on the
other hand . They raise new Amazon instances on Bare-metal and are busy with automation: they set up deployments to make the layout work well, and configs so that the services interact well with each other.
There is a situation when there is no time or desire for thin tuning of components, and the database as well. The databases work with default configs, and then they completely forget about them - “it works, don’t touch it”.
As a result, rakes are scattered in various places, which now and then fly into the forehead of the developers. In this article, we will try to collect all these rakes in one shed so that you know about them and do not step on them when working with PostgreSQL.
Planning and monitoring
First, imagine that we have a new project - it is always an active development, hypothesis testing and implementation of new features. At the moment when the application has just appeared and is developing, it has little traffic, users and customers, and they all generate small amounts of data. The database has simple queries that are quickly processed. No need to drag large amounts of data, there are no problems.
But there are more users, traffic comes: new data appears, databases grow and old queries stop working. It is necessary to complete indexes, rewrite and optimize queries. There are performance issues. All this leads to alerts at 4 a.m., stress for admins and discontent of the management.
What's wrong?
In my experience, most often there are not enough disks.
The first example . We open the schedule for monitoring disk utilization, and we see that the free space on the disk is running out .
We look at how much space and what is eaten up - it turns out there is a pg_xlog directory:
$ du -csh -t 100M /pgdb/9.6/main/*
15G /pgdb/9.6/main/base
58G /pgdb/9.6/main/pg_xlog
72G итогоDatabase admins usually know what this directory is, and they don’t touch it - it exists and exists. But the developer, especially if he looks at staging, scratches his head and thinks:
- Some kind of logs ... Let's delete pg_xlog!
Deletes the directory, the database stops working . Immediately you have to google how to raise the database after you deleted the transaction logs.
Second example . Again, we open monitoring and see that there is not enough space. This time the place is occupied by some kind of base.
$ du -csh -t 100M /pgdb/9.6/main/*
70G /pgdb/9.6/main/base
2G /pgdb/9.6/main/pg_xlog
72G итогоWe are looking for which database takes up the most space, which tables and indexes.
It turns out that this is a table with historical logs. We never needed historical logs. They are written just in case, and if it were not for the problem with the place, no one would have looked at them until the second coming:
- Come on, we’ll clean everything that is ... older than October!
Make an update request, run it, it will work out and delete some of the lines.
=# DELETE FROM history_log
-# WHERE created_at < «2018-10-01»;
DELETE 165517399
Time: 585478.451 msThe query runs for 10 minutes, but the table still takes up the same amount of space.
PostgreSQL removes rows from the table - everything is correct, but it does not return the place to the operating system. This behavior of PostgreSQL is unknown to most developers and can be very surprising.
The third example . For example, ORM made an interesting request. Usually everyone blames ORM for making “bad” queries that read out a few tables.
Suppose there are several JOIN operations that read tables in parallel in multiple threads. PostgreSQL can parallelize data operations and can read tables in multiple threads. But, given that we have several application servers, this query reads all the tables several thousand times per second. It turns out that the database server is overloaded, the disks cannot cope, and all this leads to a 502 Bad Gateway error from the backend - the database is unavailable.
But that is not all. You can recall other features of PostgerSQL.
- Brakes of DBMS background processes - PostgreSQL has all kinds of checkpoints, vacuumes, and replication.
- Virtualization overhead . When the database is running on a virtual machine, on the same piece of iron there are also virtual machines on the side, and they can conflict over resources.
- The storage is from the Chinese manufacturer NoName , the performance of which depends on the moon in Capricorn or the position of Saturn, and there is no way to figure out why it works this way. The base is suffering.
- The default configuration . This is my favorite topic: the customer says that his database is slowing down - you look, and he has a default config. The fact is that the default PostgreSQL config is designed to run on the weakest teapot . The base is launched, it works, but when it already works on mid-level hardware, then this config is not enough, it needs to be tuned.
Most often, PostgreSQL lacks either disk space or disk performance. Fortunately, with processors, memory, and a network, as a rule, everything is more or less in order.
How to be Need monitoring and planning! It would seem obvious, but for some reason, in most cases, no one plans a base, and monitoring does not cover all that needs to be monitored during the operation of PostgreSQL. There is a set of clear rules, with which everything will work well, and not "at random".
Planning
Host the database on an SSD without hesitation . SSDs have long become reliable, stable and productive. Enterprise SSD models have been around for years.
Always plan a data schema . Do not write to the database that you doubt what is needed - guaranteed not to be needed. A simple example is a slightly modified table of one of our customers.
This is a log table in which there is a data column of type json. Relatively speaking, you can write anything in this column. From the last record of this table it can be seen that the logs occupy 8 MB. PostgreSQL has no problem storing records of this length. PostgreSQL has very good storage that chews on such records.
But the problem is that when application servers read data from this table, they will easily clog the entire network bandwidth, and other requests will suffer. This is the problem of planning a data schema.
Use partitioning for any hint of a story that needs to be stored for more than two years . Partitioning sometimes seems complicated - you need to bother with triggers, with functions that will create partitions. In new versions of PostgreSQL, the situation is better and now setting up partitioning is much simpler - once done, and works.
In the considered example of deleting data in 10 minutes,
DELETEyou can replace it with DROP TABLE- such an operation in similar circumstances will take only a few milliseconds.When the data is sorted by partition, the partition is deleted literally in a few milliseconds, and the OS takes over immediately. Managing historical data is easier, easier, and safer.
Monitoring
Monitoring is a separate big topic, but from the point of view of the database there are recommendations that can fit into one section of the article.
By default, many monitoring systems provide monitoring of processors, memory, network, disk space, but, as a rule, there is no disposal of disk devices . Information about how loaded the disks are, what bandwidth is currently on the disks and the latency value should always be added to the monitoring. This will help you quickly evaluate how drives are loaded.
There are a lot of PostgreSQL monitoring options, there are for every taste. Here are some points that must be present.
- Connected Clients . It is necessary to monitor what statuses they work with, quickly find the "harmful" customers that harm the database, and turn them off.
- Error . It is necessary to monitor errors in order to monitor how well the database works: no errors - great, errors have appeared - a reason to look at the logs and start to understand what is going wrong.
- Requests (statements) . We monitor the quantitative and qualitative characteristics of requests in order to roughly assess whether we have slow, long or resource-intensive requests.
For more information, see the “PostgreSQL Monitoring Basics” report with HighLoad ++ Siberia and the Monitoring page in the PostgreSQL Wiki.
When we planned everything and “covered ourselves” with monitoring, we can still encounter some problems.
Scaling
Typically, the developer sees the database line in the config. He is not particularly interested in how it is arranged internally - how checkpoint, replication, scheduler works. The developer already has something to do - in todo there are a lot of interesting things that he wants to try.
"Give me the address of the base, then I myself." © Anonymous developer.
Ignorance of the subject leads to quite interesting consequences when the developer begins to write queries that work in this database. Fantasies when writing queries sometimes give stunning effects.
There are two types of transactions. OLTP transactions are fast, short, lightweight that take fractions of a millisecond. They work out very quickly, and there are a lot of them. OLAP - analytical queries - slow, long, heavy, read large arrays of tables and read statistics.
The last 2-3 years often abbreviated as HTAP - Hybrid Transaction / Analytical Processing or hybrid transactional-analytical processing. If you have no time to think about scaling and diversity of OLAP and OLTP requests, you can say: “We have HTAP!” But the experience and the pain of errors show that, after all, different types of requests must live separately from each other, because long OLAP requests block light OLTP requests.
So we come to the question of how to scale PostgreSQL so as to spread the load, and everyone was satisfied.
Streaming replication . The easiest option is streaming replication . When the application works with the database, we connect several replicas to this database and distribute the load. Recording still goes to the master base, and reading to replicas. This method allows you to scale very widely.
Plus, you can connect more replicas to individual replicas and getcascading replication . Separate user groups or applications that, for example, read analytics, can be moved to a separate replica.
Logical publications, subscriptions - the mechanism of logical publications and subscriptions implies the presence of several independent PostgreSQL-servers with separate databases and sets of tables. These sets of tables can be connected to neighboring databases, they will be visible to applications that can use them normally. That is, all changes that occur in the source are replicated to the destination base and are visible there. Works great with PostgreSQL 10.
Foreign tables, Declarative Partitioning - declarative partitioning and external tables. You can take several PostgreSQL and create several sets of tables there that will store the desired data ranges. This can be data for a specific year or data collected over any range.
Using the mechanism of external tables, you can combine all these databases in the form of a partitioned table in a separate PostgreSQL. An application may already work with this partitioned table, but in fact it will read data from remote partitions. When data volumes are more than the capabilities of a single server, then this is sharding.
All this can be combined into spreading configurations, to come up with different PostgreSQL replication topologies, but how it all works and how to manage it is the topic of a separate report.
Where to begin?
The easiest option is with replication . The first step is to spread the load on reading and writing. That is, write to the master, and read from replicas. So we scale the load and carry out the reading from the wizard. In addition, do not forget about the analysts. Analytical queries work for a long time, they need a separate replica with separate settings so that long analytical queries can not interfere with the rest.
The next step is balancing . We still have the same line in the config that the developer operates on. He needs a place where he will write and read. There are several options here.
Ideal - implement application-level balancingwhen the application itself knows where to read the data from, and knows how to choose a replica. Suppose an account balance is always needed up-to-date and needs to be read from the master, and the product picture or information about it can be read with some delay and done from a replica.
- DNS Round Robin , in my opinion, is not a very convenient implementation, because sometimes it works for a long time and does not give the necessary time when switching wizard roles between servers in cases of failover.
- A more interesting option is to use Keepalived and HAProxy . Virtual addresses for the master and set of replicas are thrown between HAProxy servers, and HAProxy is already balancing traffic.
- Patroni, DCS in conjunction with something like ZooKeeper, etcd, Consul - the most interesting option, in my opinion. That is, service discovery is responsible for the information who is the master now and who is the replica. Patroni manages a cluster of PostgreSQL's, performs switching - if the topology has changed, this information will appear in service discovery, and applications can quickly find out the current topology.
And there are nuances with replication, the most common of which is the replication lag . You can do it like GitLab, and when the lag accumulates, just drop the base. But we have comprehensive monitoring - we look at it and see long transactions.
Applications and DBMS Transactions
In general, slow and idle transactions result in:
- decrease in productivity - not to a sharp spasmodic, but smooth;
- locks and deadlocks , because long transactions hold locks on rows and prevent other transactions from working;
- 50 * HTTP errors on the backend , interface errors, or somewhere else.
Let's look at a little theory about how these problems arise, and why the mechanism of long and idle transactions is harmful.
PostgreSQL has MVCC - relatively speaking, a database engine. It allows customers to work competitively with data without interfering with each other: readers do not interfere with readers, and writers do not interfere with writers. Of course, there are some exceptions, but in this case they are not important.
It turns out that in the database for one row there can be several versions for different transactions. Clients connect, the database gives them snapshots of data, and within these snapshots different versions of the same line may exist. Accordingly, in the life cycle of the database, transactions are shifted, replace each other, and versions of rows appear that no one needs.
So arisesthe need for a garbage collector is auto vacuum . Long transactions exist and prevent auto vacuum from cleaning out unnecessary row versions. This junk data begins to wander from memory to disk, from disk to memory. To store this garbage, CPU and memory resources are wasted.
The longer the transaction, the more junk and lower performance.
From the point of view of “Who is to blame?”, The app is to blame for the appearance of long transactions. If the database will exist on its own, long, do-nothing transactions will not be taken from anywhere. In practice, there are the following options for the appearance of idle transactions.
"Let's go to an external source . " The application opens a transaction, does something in the database, then decides to turn to an external source, for example, Memcached or Redis, in the hope that it will then return to the database, continue working and close the transaction. But if an error occurs in the external source, the application crashes and the transaction remains closed until someone notices it and kills it.
No error handling. On the other hand, there may be a problem handling errors. When, again, the application opened a transaction, solved some problem in the database, returned to code execution, performed some functions and calculations, in order to continue working in the transaction and close it. When on these calculations the application operation was interrupted with an error, the code returned to the beginning of the cycle, and the transaction again remained unclosed.
The human factor . For example, an administrator, developer, analyst, works in some pgAdmin or in DBeaver - opened a transaction, does something in it. Then the person was distracted, he switched to another task, then to the third, forgot about the transaction, left for the weekend, and the transaction continues to hang. Base performance suffers.
Let's see what to do in these cases.
- We have monitoring; accordingly, we need alerts in monitoring . Any transaction that hangs for more than an hour and does nothing is an occasion to see where it came from and understand what is wrong.
- The next step is to shoot such transactions through the task in the crown (pg_terminate_backend (pid)) or configure in the PostgreSQL config. Thresholds of 10-30 minutes are needed, after which transactions are automatically completed.
- Application refactoring . Of course, you need to find out where the idle transactions come from, why they occur and eliminate such places.
Avoid long transactions at all costs, because they greatly affect database performance.
Everything becomes even more interesting when pending tasks appear, for example, you need to carefully calculate the units. And we come to the issue of bicycle construction.
Bicycle construction
Sensitive subject. Business on the application side needs to perform background processing of events. For example, to calculate aggregates: minimum, maximum, average value, send notifications to users, issue invoices to customers, set up a user’s account after registration or register in neighboring services - do delayed processing.
The essence of such tasks is the same - they are postponed for later. Tables appear in the database that just execute the queues.
Here is the identifier of the task, the time when the task was created, when updated, the handler that took it, the number of attempts to complete. If you have a table that even remotely resembles this one, then you have self-written queues .
All this works fine until long transactions appear. After that, tables that work with queues swell in size . New jobs are added all the time, old ones are deleted, updates happen - a table with intensive recording is obtained. It should be cleaned regularly from outdated versions of strings so that performance does not suffer.
Processing time is growing - a long transaction holds a lock on outdated versions of rows or prevents vacuum from cleaning it. When the table grows in size, the processing time also increases, since you need to read many pages with garbage. Time increases, and the queue at some point ceases to work at all .
Below is an example of the top of one of our customers, who had a queue. All requests are just related to the queue.
Pay attention to the execution time of these requests - all but one of them work for more than twenty seconds.
To solve these problems, Skytools PgQ , a queue manager for PostgreSQL, was invented long ago . Do not reinvent your bike - take PgQ, set it up once and forget about the lines.
True, he also has features. Skytools PgQ has little documentation . After reading the official page, one gets the feeling that he did not understand anything. The feeling grows when you try to do something. Everything works, but how it works is not clear . Some kind of Jedi magic. But you can get a lot of information atMailing-lists . This is not a very convenient format, but a lot of interesting things are there, and you will have to read these sheets.
Despite the cons, Skytools PgQ works on the principle of "set up and forget." A trigger function is created that is hung on the table with which we want to receive changes, and everything works reliably. Almost remember about PgQ when you need to add another table to the queue. Using PgQ is cheaper than supporting and setting up individual brokers.
If you are faced with a task that someone has most likely encountered, look for tools that have already been invented. This is especially true for queues.
In our practice, we saw a lot of self-written bursts and replaced them with PgQ. Of course, there are large installations of PostgreSQL, for example, in Avito, where PgQ features are not enough. But these are single cases that are decided separately.
Automation
Admins from automation want to be able to roll out instances so that the deploy works without their intervention and configs roll out instantly. And the developers want the deployment to work in such a way that as soon as they commit some changes, they will continue to pull themselves up, test, spill and everything would be fine. Of course, they want to roll migrations without manual intervention, so that they do not need to log in to the server, perform alter with their hands.
Together they want an auto-failover - if suddenly during the operation of the PostgreSQL cluster some kind of failure occurs, the role of the wizard will automatically be transferred to another server, and we did not even know anything about it. But there are some very serious problems that prevent the use of auto-failover.
Split brain. In a normal PostgreSQL cluster with a master and several replicas, writing goes to one server, reading from replicas. If a failure occurs, the server shuts down. But in PostgreSQL, there is no fencing mechanism out of the box, and often even in Kubernets you have to configure it separately. If the application crashes, it can still write to the old master, and the new switching application starts writing to the new master. There is a situation of Split-brain.
Trying to restore consistency can be very difficult and will require a lot of nerves. When GitHub collided with a split-brain, they had to restore their base from backup.
Cascade failover . Let's say there is a master and several replicas. The master drops and the load switches to the new master and the remaining replicas.
The old master did not have time to reinitialize and become a replica, and at that moment another master falls. It takes seconds, and all the load falls on a single server.
It does not cope with the load and also fails - it turns out a cascading failover.
If you still take on auto-failover, then there are the following ways.
Bash scripts are a fragile solution that needs to be constantly tested and debugged. One admin has left, another has come and does not know how to use it. If suddenly something breaks, it is very difficult to find where what happened. This solution requires constant refinement.
Ansible playbooks - bash scripts on steroids. Also, you need to constantly check that everything works, run on test clusters.
Patroni - in my opinion, one of the best products, because it has auto-failover, monitoring the status of the cluster, plus the function of returning the cluster topology to service discovery.
PAF - Based on Pacemaker . Also an interesting tool for auto-failover in PostgreSQL, but it is already more complicated and requires knowledge of Pacemaker.
Stolon is more for cloud computing . For Kubernetes, for example. Stolon is more complex than Patroni, but they are interchangeable and you can choose between them.
Containers and Orchestration
In recent years, Docker and Kubernetes have been growing. These are dynamically developing technologies in which a lot of new things appear.
Each new version adds a lot of interesting functionality, though the old one may stop working. With “What if you deploy the base in Kubernetes ...” various amazing stories begin.
The base is always stateful , it needs to be stored somewhere. Where? Fault-tolerant network storage comes to mind. Solutions from Open Source: CEPH, GlusterFS, LinStor DRBD. The fundamental problem is that it all works very slowly and probably will never work fast.
As a bonus, you get an additional headache - the need to support a clustered file system. For example, if you are only familiar with Kubernetes, you will have to study CEPH in depth. This is a complex system with a lot of problems - you will have to increase your expertise. Speaking generally about network attached storage and databases in them, then this works while three requirements are met.
- The size of the database is small , and you do not need to transfer GB and dozens of GB of data between nodes.
- No performance or latency requirements . If latency increases to tens or even hundreds of milliseconds, this is a completely inoperative solution.
- It's not scary to lose data . Kubernetes is developing, it finds some bugs. The engines that allow shared storage for Kubernetes are also developing and they also find bugs there. At some point, you can just run into a bug and lose everything.
This brings us to the fact that it’s good to use Kubernetes and Docker for the database on staging or dev-servers or at the stage of hypothesis testing. But for high loads, in my opinion, Kubernetes and shared storage are not very good.
But if you really want to, then the best option would be local volumes - local storage without the use of shared file systems, streaming replication - native streaming replication through which data is synchronized and PostgreSQL-operators that provide us with something like a button - clicked, and it worked. There are currently two such operators: Zalando and Crunchy .
Of course, it is worth remembering that all this is developing dynamically. Look at the number of issues and pull requests. New features appear, errors may be hidden in them, so implement containerization without fanaticism.
Summary
When you are planning and monitoring, do not save on SSDs - they are relatively cheap and will delay performance problems for a year or even more.
Do not write everything to the database . The practice of writing 8 MB JSON is bad, you can't do that.
Monitoring is needed , and do not leave it in the default state. Monitor PostgreSQL, expand your monitoring.
Spread the load - Postgres is ready . Try not to read or write data from one place. PostgreSQL scales very well, and there are options for scaling it for every taste. To scale the load, use: streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
Avoid doing nothing . They reduce performance and very slowly but surely kill the base.
If you are doing something that other people might already need, look around - maybe everything is already there . This directly relates to queues. Do not invent self-written lines, use Skytools PgQ!
If you really want a base in Kubernetes, use local volumes, streaming replication and PostgreSQL operators . You can somehow work with this, but without fanaticism, because everything is changing very quickly.
Do not miss the new opportunity to discuss high loads and hear among other things about database administration. This time in Novosibirsk, where on June 24 and 25 at HighLoad ++ Siberia Alexei colleague Andrei Salnikov will talk about how to build a workflow when you have several hundred databases with completely different workloads. And 38 more class reports in the schedule - a great reason to come to the conference!