Building an automatic message moderation system
Automatic moderation systems are implemented in web services and applications where it is necessary to process a large number of user messages. Such systems can reduce the costs of manual moderation, speed it up and process all user messages in real-time. In the article, we will talk about building an automatic moderation system for processing English using machine learning algorithms. We will discuss the entire pipeline work from research tasks and the choice of ML algorithms to rolling out into production. Let's see where to look for ready-made datasets and how to collect data for the task yourself.
Prepared jointly by Ira Stepanyuk ( id_step ), Data Scientist at Poteha Labs
Task description
We work with multi-user active chats, where short messages from dozens of users can come in one chat every minute. The task is to highlight toxic messages and messages with any obscene remarks in dialogs from such chats. From the point of view of machine learning, this is a binary classification task, where each message must be assigned to one of the classes.
To solve this problem, it was first necessary to understand what toxic messages are and what exactly makes them toxic. To do this, we looked at a large number of typical user messages on the Internet. Here are a few examples that we have already divided into toxic and normal messages.
| Toxic | Normal |
|---|---|
| Your are a damn fag * ot | this book is so dummy |
| ur child is so ugly (1) | Winners win, losers make excuses |
| White people are owners of black (2) | black like my soul (2) |
It can be seen that toxic messages often contain obscene words, but still this is not a prerequisite. The message may not contain inappropriate words, but be offensive to someone (example (1)). In addition, sometimes toxic and normal messages contain the same words that are used in different contexts - offensive or not (example (2)). Such messages also need to be able to distinguish.
Having studied various messages, for our moderation system we called toxic those messages that contain statements with obscene, insulting expressions or hatred of someone.
Data
Open data
One of the most famous moderation datasets is the dataset from the Kaggle Toxic Comment Classification Challenge . Part of the markup in the dataset is incorrect: for example, messages with obscene words can be marked as normal. Because of this, you cannot just take Kernel competitions and get a well-functioning classification algorithm. You need to work more with the data, see which examples are not enough, and add additional data with such examples.
In addition to competitions, there are several scientific publications with links to suitable datasets ( example), however, not everything can be used in commercial projects. Mostly these datasets contain messages from the social network Twitter, where you can find many toxic tweets. In addition, data is collected from Twitter, as certain hashtags can be used to search and mark up toxic user messages.
Manual data
After we collected the dataset from open sources and trained on it the basic model, it became clear that open data is not enough: the quality of the model is not satisfactory. In addition to open data for solving the problem, an unallocated selection of messages from a game messenger with a large number of toxic messages was available to us.

To use this data for their task, they had to be labeled somehow. At that time, there was already a trained baseline classifier, which we decided to use for semi-automatic marking. Having run all the messages through the model, we got the toxicity probabilities of each message and sorted in descending order. At the top of this list, messages were collected with obscene and offensive words. At the end, on the contrary, there are normal user messages. Thus, most of the data (with very large and very small probability values) could not be marked out, but immediately assigned to a certain class. It remains to mark the messages that fell in the middle of the list, which was done manually.
Data Augmentation
Often in datasets you can see altered messages on which the classifier is mistaken, and the person correctly understands their meaning.
This is because users adjust and learn to cheat moderation systems so that the algorithms make mistakes on toxic messages, and the meaning remains clear to the person. What users are doing now:
- typos generate: you are stupid asswhole, fack you ,
- replace alphabetic characters with numbers similar in description: n1gga, b0ll0cks ,
- insert extra spaces: idiot ,
- remove spaces between words: dieyoustupid .
In order to train a classifier resistant to such substitutions, you need to do what users do: generate the same changes in messages and add them to the training set to the main data.
In general, this struggle is inevitable: users will always try to find vulnerabilities and hacks, and moderators will implement new algorithms.
Description of subtasks
We were faced with subtasks for analyzing messages in two different modes:
- online mode - real-time analysis of messages, with maximum response speed;
- offline mode - analysis of message logs and the allocation of toxic dialogs.
In online mode, we process each user message and run it through the model. If the message is toxic, then hide it in the chat interface, and if it’s normal, then display it. In this mode, all messages should be processed very quickly: the model should give a response so quickly as not to disrupt the structure of the dialogue between users.
In offline mode, there are no time limits for work, and therefore I wanted to implement the model with the highest quality.
Online mode. Dictionary Search
Regardless of which model is chosen next, we must find and filter messages with obscene words. To solve this subproblem, it is easiest to compile a dictionary of invalid words and expressions that cannot be skipped, and search for such words in each message. The search should be fast, so the naive substring search algorithm for that time does not fit. A suitable algorithm for finding a set of words in a string is the Aho-Korasik algorithm . Due to this approach, it is possible to quickly identify some toxic examples and block messages before they are transmitted to the main algorithm. Using the ML algorithm will allow you to "understand the meaning" of messages and improve the quality of classification.
Online mode. Basic machine learning model
For the base model, we decided to use a standard approach for text classification: TF-IDF + classical classification algorithm. Again for speed and performance reasons.
TF-IDF is a statistical measure that allows you to determine the most important words for text in the body using two parameters: the frequency of words in each document and the number of documents containing a specific word (in more detail here ). Having calculated for each word in the TF-IDF message, we get a vector representation of this message.
TF-IDF can be calculated for words in the text, as well as for n-gram words and characters. Such an extension will work better, as it will be able to handle frequently occurring phrases and words that were not in the training set (out-of-vocabulary).
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy import sparse
vect_word = TfidfVectorizer(max_features=10000, lowercase=True,
analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3))
vect_char = TfidfVectorizer(max_features=30000, lowercase=True,
analyzer='char', min_df=8, ngram_range=(3,6))
x_vec_word = vect_word.fit_transform(x_train)
x_vec_char = vect_char.fit_transform(x_train)
x_vec = sparse.hstack([x_vec_word, x_vec_char])After converting messages to vectors, you can use any classical method for classification: logistic regression, SVM , random forest, boosting .
We decided to use logistic regression in our task, since this model gives an increase in speed in comparison with other classical ML classifiers and predicts class probabilities, which allows flexible selection of the classification threshold in production.
The algorithm obtained using TF-IDF and logistic regression quickly works and well defines messages with obscene words and expressions, but does not always understand the meaning. For example, often messages with the words' black 'and'feminizm 'fell into the toxic class. I wanted to fix this problem and learn to better understand the meaning of messages using the next version of the classifier.
Offline mode
In order to better understand the meaning of messages, you can use neural network algorithms:
- Embeddings (Word2Vec, FastText)
- Neural Networks (CNN, RNN, LSTM)
- New pre-trained models (ELMo, ULMFiT, BERT)
We will discuss some of these algorithms and how they can be used in more detail.
Word2Vec and FastText
Embedding models allow you to get vector representations of words from texts. There are two types of Word2Vec : Skip-gram and CBOW (Continuous Bag of Words). In Skip-gram, the context is predicted by the word, and vice versa in CBOW: the word is predicted by the context.
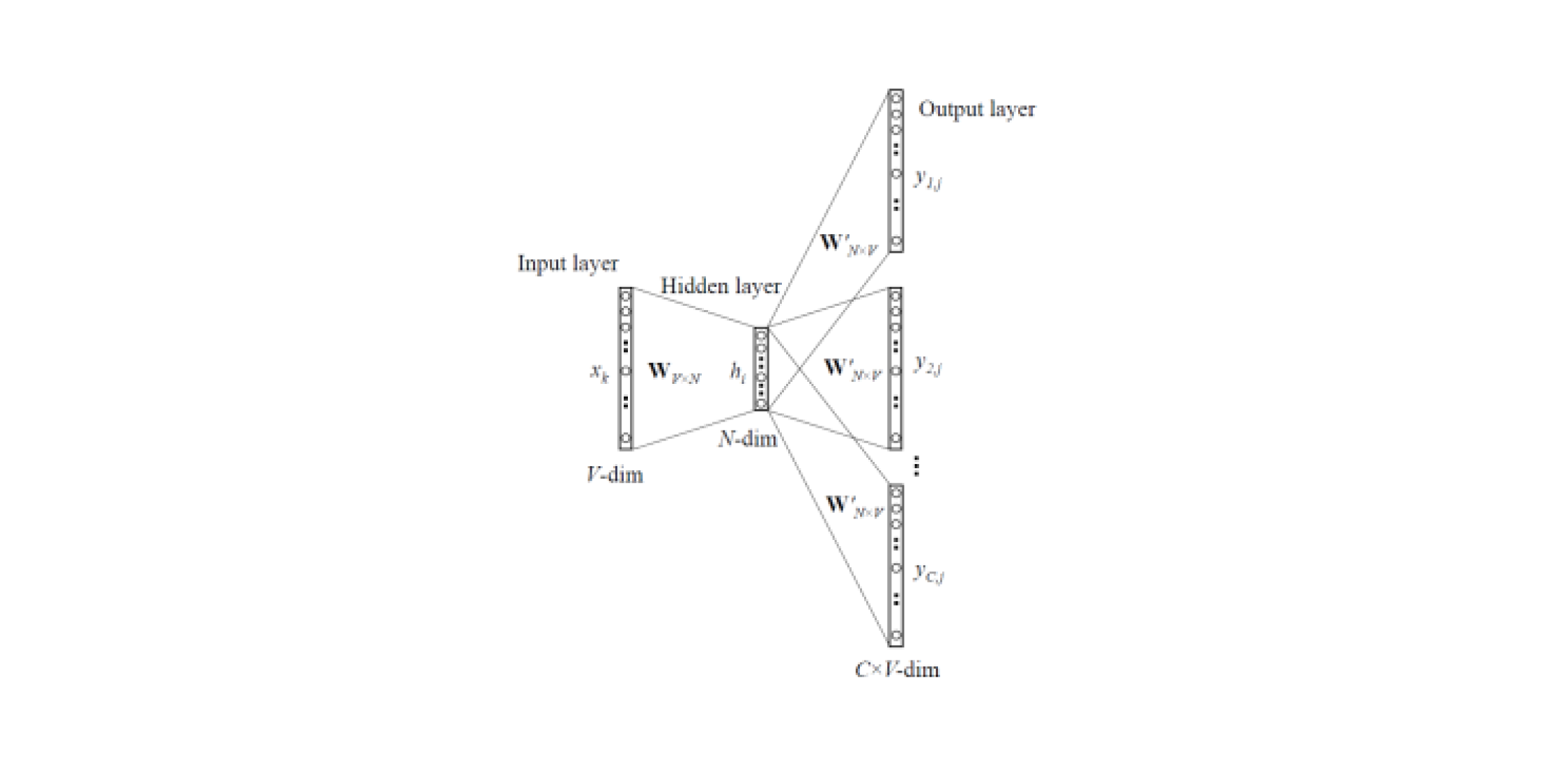
Such models are trained on large corps of texts and allow you to get vector representations of words from a hidden layer of a trained neural network. The disadvantage of this architecture is that the model learns from a limited set of words that are contained in the corpus. This means that for all words that were not in the body of texts at the training stage, there will be no embeddings. And this situation often happens when pre-trained models are used for their tasks: for some of the words there will be no embeddings, accordingly a large amount of useful information will be lost.
To solve the problem with words that are not in the dictionary (OOV, out-of-vocabulary) there is an improved embedding model - FastText. Instead of using single words to train the neural network, FastText breaks the words into n-grams (subwords) and learns from them. To obtain a vector representation of a word, you need to obtain vector representations of the n-gram of this word and add them.
Thus, pre-trained Word2Vec and FastText models can be used to obtain feature vectors from messages. The obtained characteristics can be classified using classical ML classifiers or a fully connected neural network.
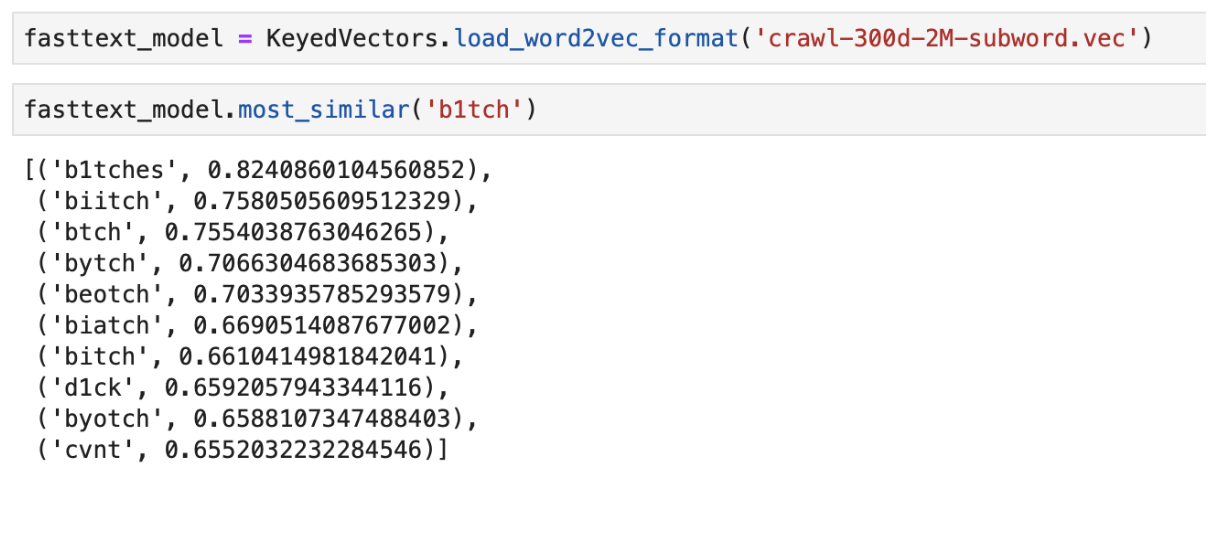
An example of the output of the words “closest” in meaning using pre- trained FastText
CNN Classifier
For processing and classification of texts from neural network algorithms, recurrent networks (LSTM, GRU) are more often used, since they work well with sequences. Convolutional networks (CNNs) are most often used for image processing, but they can also be used in the text classification task. Consider how this can be done.
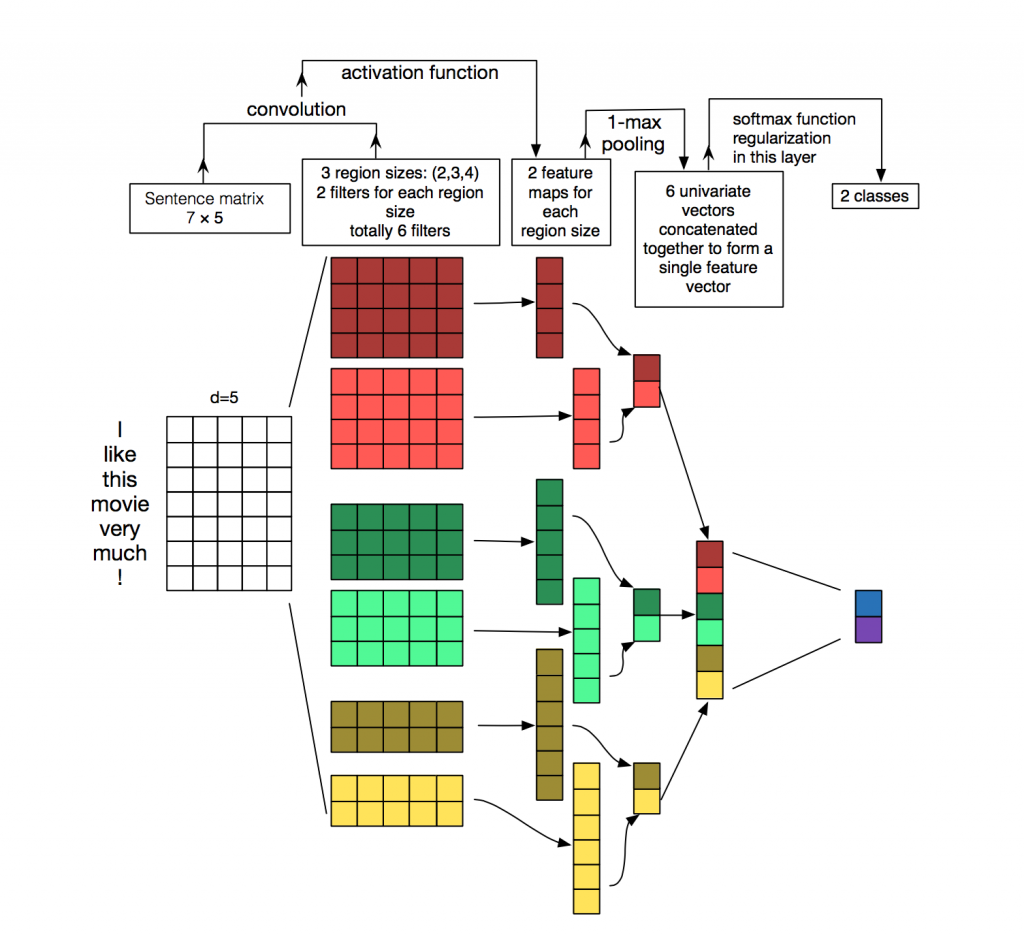
Each message is a matrix in which on each line for the token (word) its vector representation is written. Convolution is applied to such a matrix in a certain way: the convolution filter “glides” over entire rows of the matrix (word vectors), but it captures several words at a time (usually 2-5 words), thus processing the words in the context of neighboring words. Details of how this happens can be seen in the picture .
Why use convolutional networks for word processing when you can use recurrent? The fact is that convolutions work much faster. Using them for the task of classifying messages, you can greatly save time on training.
ELMo
ELMo (Embeddings from Language Models) is an embedding model based on a language model that was recently introduced . The new embedding model is different from the Word2Vec and FastText models. ELMo word vectors have certain advantages:
- The presentation of each word depends on the entire context in which it is used.
- Representation is based on symbols, which allows the formation of reliable representations for OOV (out-of-vocabulary) words.
ELMo can be used for various tasks in NLP. For example, for our task, message vectors received using ELMo can be sent to the classical ML classifier or a convolutional or fully connected network can be used.
ELMo pre-trained embeddings are quite simple to use for your task, an example of use can be found here .
Implementation Features
Flask API
The prototype API was written in Flask, as it is easy to use.
Two Docker Images
For the deployment, we used two docker images: the base one, where all the dependencies were installed, and the main one for launching the application. This greatly saves assembly time, since the first image is rarely rebuilt, and this saves time during the deployment. Quite a lot of time is spent building and downloading machine learning libraries, which is not necessary with every commit.
Testing
The peculiarity of the implementation of a fairly large number of machine learning algorithms is that even with high metrics on the validation dataset, the real quality of the algorithm in production can be low. Therefore, to test the operation of the algorithm, the whole team used the bot in Slack. This is very convenient, because any member of the team can check what response the algorithms give for a particular message. This test method allows you to immediately see how the algorithms will work on live data.
A good alternative is to launch the solution on public sites like Yandex Toloka and AWS Mechanical Turk.
Conclusion
We examined several approaches to solving the problem of automatic message moderation and described the features of our implementation.
The main observations obtained during the work:
- Dictionary search and machine learning algorithm based on TF-IDF and logistic regression allowed to classify messages quickly, but not always correctly.
- Neural network algorithms and pre-trained models of embeddings better cope with this task and can determine toxicity within the meaning of the message.
Of course, we posted the open Poteha Toxic Comment Detection demo on the Facebook bot. Help us make the bot better!
I will be glad to answer questions in the comments.