Development of visual tests based on Gemini and Storybook
Hello, Habr! In this article I want to share the experience of developing visual tests in our team.
It so happened that we did not immediately think about layout testing. Well, some frame will move out for a couple of pixels, well, fix it. In the end, there are testers - the fly will not fly past them. But the human factor still cannot be fooled - to detect minor changes in the user interface is far from always physically possible even for a tester. The question arose when serious optimization of layout and transition to BEM was started. Here, it would certainly not have been lossless and we desperately needed an automated way to detect situations when, as a result of corrections, something in the UI starts to change not as intended, or not where it was intended.
Any developer knows about unit code testing. Unit tests give confidence that changes in the code did not break anything. Well, at least they did not break in the part for which there are tests. The same principle can be applied to the user interface. Just as unit tests test classes, visual tests test the visual components that make up the user interface of an application.
For visual components, you can write “classic” unit tests, which, for example, initiate rendering of components with different values of input parameters and check the expected state of the DOM tree using assert statements, comparing either individual elements or a snapshot of the DOM tree of the component with the reference generally. Visual tests are also based on snapshots, but already on snapshots of the visual display of the component (screenshots). The essence of the visual test is to compare the picture taken during the test with the reference one and, if differences are found, either accept the new picture as the reference one or fix the bug that caused these differences.
Of course, “screening” individual visual components is not very effective. The components do not live in a vacuum and their display may depend either on the top-level components or on neighboring ones. No matter how we test individual components, the picture as a whole may have defects. On the other hand, if you take pictures of the entire application window, then many of the pictures will contain the same components, which means that if you change one component, we will be forced to update all the pictures in which this component is present.
The truth, as usual, is somewhere in the middle - you can draw the entire page of the application, but take a picture of only one area under which the test is created, in the particular case this area may coincide with the area of a specific component, but this will not be a component in vacuum, but in a very real environment. And this will already be similar to a unit visual test, although it can hardly be said about modularity if the “unit” knows something about the environment. Well, okay, it’s not so important whether the category of tests includes visual tests - modular or integration. As the saying goes, "you check or go?"
To speed up the execution of tests, page rendering can be done in some headless browser that does all the work in memory without being displayed on the screen and ensures maximum performance. But in our case, it was critical to ensure that the application works in Internet Explorer (IE), which does not have a headless mode, and we needed a tool for programmatically managing browsers. Fortunately, everything has already been invented before us and there is such an instrument - it is called Selenium . As part of the Selenium project, drivers are being developed for managing various browsers, including a driver for IE. Selenium server can manage browsers not only locally, but also remotely, forming a cluster of selenium servers, the so-called selenium grid.
Selenium is a powerful tool, but the threshold for entering it is quite high. We decided to look for ready-made tools for visual testing based on Selenium and came across a wonderful product from Yandex called Gemini . Gemini can take pictures, including pictures of a certain area of the page, compare pictures with reference ones, visualizing the difference and taking into account such moments as anti-aliasing or a blinking cursor. In addition, Gemini can do reruns of fallen tests, parallelize the execution of tests, and many other goodies. In general, we decided to try.
Gemini tests are easy to write. First you need to prepare the infrastructure - install selenium-standaloneand run selenium server. Then configure gemini, specifying the address of the application under test (rootUrl), the address of the selenium server (gridUrl), the composition and configuration of browsers, as well as the necessary plugins for generating reports, optimizing image compression. Configuration Example:
The tests themselves are a collection of suites, in each of which one or more pictures (states) are taken. Before taking a snapshot (capture () method), you can set the area of the page to be shot using the setCaptureElements () method, and also perform some preparatory actions if necessary in the browser context using either the methods of the actions object or using arbitrary JavaScript code - for this in actions has an executeJS () method.
Example:
A test tool was chosen, but it was still a long way to the final solution. It was necessary to understand what to do with the data displayed in the pictures. Let me remind you that in the tests we decided not to draw individual components, but the entire page of the application, in order to test the visual components not in a vacuum, but in the real environment of other components. If you need to transfer the necessary test data to ee props (I'm talking about react components) to render an individual component, much more is needed to render the entire page of the application, and preparing the environment for such a test can be a headache.
Of course, you can leave the application itself to receive the data, so that during the test it will execute requests to the backend, which, in turn, would receive data from some kind of reference database, but what about versioning? You can’t put a database in a git repository. No, of course you can, but there are some decencies.
Alternatively, to run tests, you can replace the real backend server with a fake one, which would give the web application not data from the database, but static data stored, for example, in json format, already with the sources. However, the preparation of such data is also not too trivial. We decided to go the easier way - do not pull data from the server, but simply restore the application state before running the test (in our case, this is the state of the redux storage), which was in the application at the time of taking the reference image.
To serialize the current state of the redux store, the snapshot () method has been added to the window object:
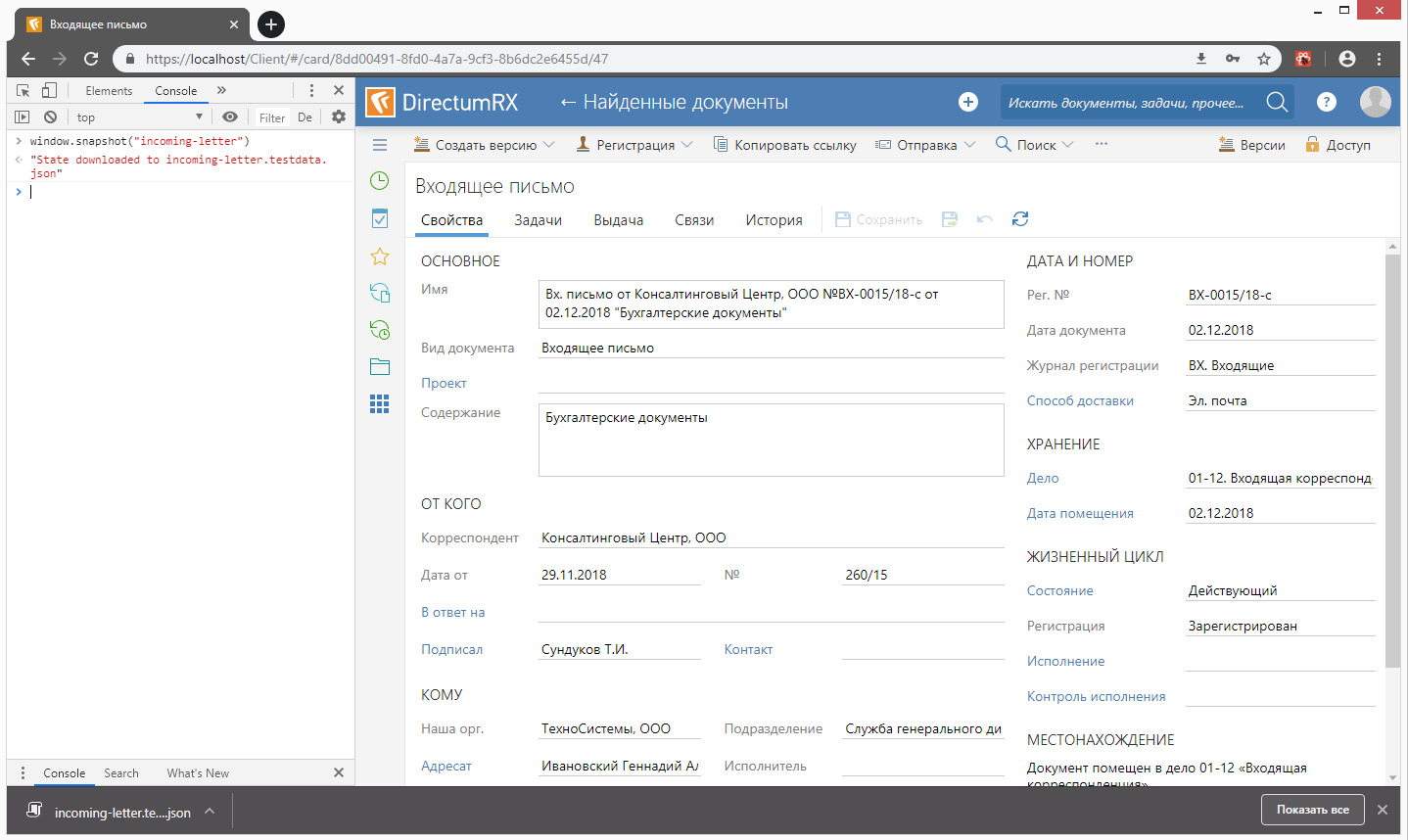
Using this method, using the command line of the browser console, you can save the current state of redux-storage to a file: Storybook
was chosen as an infrastructure for visual tests - a tool for interactive development of libraries of visual components. The main idea was that instead of the various states of the components in the stories tree, fix the various states of our application and use these states to take screenshots. In the end, there is no fundamental difference between simple and complex components, except in the preparation of the environment.
So, each visual test is a story, before rendering of which the state of the redux storage previously saved in the file is restored. This is done using the Provider component from the react-redux library, to the store property of which the deserialized state restored from the previously saved file is passed:
In the example above, ContextContainer is a component that includes the "skeleton" of the application - the navigation tree, the header and the content area. In the content area, various components can be rendered (list, card, dialog, etc.) depending on the current state of the redux storage. In order for the component not to fulfill unnecessary requests to the backend for input, corresponding stub properties are passed to it.
In the context of a Storybook, it looks something like this:
So, we figured out the data for the tests. The next task is to make friends with Gemini and Storybook. At first glance, everything is simple - in the Gemini config we specify the address of the application under test. In our case, this is the address of the Storybook server. You only need to raise the storybook server before starting the gemini tests. You can do this directly from the code using the Gemini event subscription START_RUNNER and END_RUNNER:
As the server for tests, we used http-server, which returns the contents of the folder with the statically assembled storybook (to build the static storybook, use the build-storybook command ).
So far, everything has been going smoothly, but problems have not kept themselves waiting. The fact is that the storybook displays the story inside the frame. Initially, we wanted to be able to set the selective region of the image using setCaptureElements (), but this can only be done if you specify the frame address as the address for suite, something like this:
But then it turns out that for each shot we must create our own suite, because The URL can be set for the suite as a whole, but not for a single snapshot within the suite. It should be understood that each suite runs in a separate browser session. This, in principle, is correct - the tests should not depend on each other, but opening a separate browser session and subsequent loading of the Storybook takes quite a lot of time, much more than just moving through stories within the framework of the already open Storybook. Therefore, with a large number of suites, the test execution time is very slow. Part of the problem can be solved by parallelizing the execution of tests, but parallelization consumes a lot of resources (memory, processor). Therefore, having decided to save on resources and at the same time not to lose too much in the duration of the test run, we refused to open the frame in a separate browser window. Tests are performed within a single browser session, but before each shot, the next story is loaded into the frame as if we just opened the storybook and clicked on individual nodes in the stories tree. Image area - entire frame:
Unfortunately, in this option, in addition to the ability to select the image area, we also lost the ability to use standard actions of the Gemini engine to work with elements of the DOM tree (mouseDown (), mouseMove (), focus (), etc.), etc. to. Elements within the Gemini frame do not “see.” But we still have the opportunity to use the function executeJS (), with which you can execute JavaScript code in a browser context. Based on this function, we implemented the analogues of standard actions that we need, which already work in the context of the Storybook frame. Here we had to “conjure” a little in order to transfer parameter values from the test context to the browser context - executeJS (), unfortunately, does not provide such an opportunity. Therefore, at first glance, the code looks a little strange - the function is translated into a string,
After the visual tests were written and started to work, it turned out that some of the tests were not very stable. Somewhere, the icon will not have time to draw, somewhere the selection will not be removed and we get a mismatch with the reference image. Therefore, it was decided to include retests of test execution. However, in Gemini, retries work for the entire suite, and as mentioned above, we tried to avoid situations where a suite is made for each shot - this slows down the execution of tests too much. On the other hand, the more shots are taken within the framework of one suite, the greater the likelihood that the repeated execution of the suite may fall as well as the previous one. Therefore, it was necessary to implement retries. In our scheme, repetition of the execution is not done for the entire suite, but only for those pictures that did not pass on the previous failed run.
By the way, the TEST_RESULT event was also useful for visualizing the progress of tests as they passed. Now the developer does not need to wait until all the tests are completed, he can interrupt the execution if he sees that something went wrong. If test execution is interrupted, Gemini will correctly close browser sessions opened by the selenium server.
Upon completion of the test run, if the new suite is not empty, run it until the maximum number of repetitions is exhausted:
Today we have about fifty visual tests covering the main visual states of our application. Of course, there is no need to talk about full coverage of UI tests, but we have not set such a goal yet. Tests work successfully both at the developers' workstations and at build agents. While tests are performed only in the context of Chrome and Internet Explorer, but in the future it is possible to connect other browsers. All this economy serves the Selemium grid with two nodes deployed on virtual machines.
From time to time, we are faced with the fact that after the release of the new version of Chrome it is necessary to update the reference pictures due to the fact that some elements began to be displayed a little differently (for example, scrollers), but there is nothing to be done about it. It’s rare, but it happens that when changing the structure of a redux-storage, you have to re-retrieve the saved states for the tests. To restore exactly the same state that was in the test at the time of its creation, of course, is not easy. As a rule, no one already remembers on which database these pictures were taken and you have to take a new picture on other data. This is a problem, but not a big one. To solve it, you can take pictures on a demo base, since we have scripts for its generation and are kept up to date.
It so happened that we did not immediately think about layout testing. Well, some frame will move out for a couple of pixels, well, fix it. In the end, there are testers - the fly will not fly past them. But the human factor still cannot be fooled - to detect minor changes in the user interface is far from always physically possible even for a tester. The question arose when serious optimization of layout and transition to BEM was started. Here, it would certainly not have been lossless and we desperately needed an automated way to detect situations when, as a result of corrections, something in the UI starts to change not as intended, or not where it was intended.
Any developer knows about unit code testing. Unit tests give confidence that changes in the code did not break anything. Well, at least they did not break in the part for which there are tests. The same principle can be applied to the user interface. Just as unit tests test classes, visual tests test the visual components that make up the user interface of an application.
For visual components, you can write “classic” unit tests, which, for example, initiate rendering of components with different values of input parameters and check the expected state of the DOM tree using assert statements, comparing either individual elements or a snapshot of the DOM tree of the component with the reference generally. Visual tests are also based on snapshots, but already on snapshots of the visual display of the component (screenshots). The essence of the visual test is to compare the picture taken during the test with the reference one and, if differences are found, either accept the new picture as the reference one or fix the bug that caused these differences.
Of course, “screening” individual visual components is not very effective. The components do not live in a vacuum and their display may depend either on the top-level components or on neighboring ones. No matter how we test individual components, the picture as a whole may have defects. On the other hand, if you take pictures of the entire application window, then many of the pictures will contain the same components, which means that if you change one component, we will be forced to update all the pictures in which this component is present.
The truth, as usual, is somewhere in the middle - you can draw the entire page of the application, but take a picture of only one area under which the test is created, in the particular case this area may coincide with the area of a specific component, but this will not be a component in vacuum, but in a very real environment. And this will already be similar to a unit visual test, although it can hardly be said about modularity if the “unit” knows something about the environment. Well, okay, it’s not so important whether the category of tests includes visual tests - modular or integration. As the saying goes, "you check or go?"
Tool selection
To speed up the execution of tests, page rendering can be done in some headless browser that does all the work in memory without being displayed on the screen and ensures maximum performance. But in our case, it was critical to ensure that the application works in Internet Explorer (IE), which does not have a headless mode, and we needed a tool for programmatically managing browsers. Fortunately, everything has already been invented before us and there is such an instrument - it is called Selenium . As part of the Selenium project, drivers are being developed for managing various browsers, including a driver for IE. Selenium server can manage browsers not only locally, but also remotely, forming a cluster of selenium servers, the so-called selenium grid.
Selenium is a powerful tool, but the threshold for entering it is quite high. We decided to look for ready-made tools for visual testing based on Selenium and came across a wonderful product from Yandex called Gemini . Gemini can take pictures, including pictures of a certain area of the page, compare pictures with reference ones, visualizing the difference and taking into account such moments as anti-aliasing or a blinking cursor. In addition, Gemini can do reruns of fallen tests, parallelize the execution of tests, and many other goodies. In general, we decided to try.
Gemini tests are easy to write. First you need to prepare the infrastructure - install selenium-standaloneand run selenium server. Then configure gemini, specifying the address of the application under test (rootUrl), the address of the selenium server (gridUrl), the composition and configuration of browsers, as well as the necessary plugins for generating reports, optimizing image compression. Configuration Example:
//.gemini.js
module.exports = {
rootUrl: 'http://my-app.ru',
gridUrl: 'http://127.0.0.1:4444/wd/hub',
browsers: {
chrome: {
windowSize: '1920x1080',
screenshotsDir:'gemini/screens/1920x1080'
desiredCapabilities: {
browserName: 'chrome'
}
}
},
system: {
projectRoot: '',
plugins: {
'html-reporter/gemini': {
enabled: true,
path: './report'
},
'gemini-optipng': true
},
exclude: [ '**/report/*' ],
diffColor: '#EC041E'
}
};
The tests themselves are a collection of suites, in each of which one or more pictures (states) are taken. Before taking a snapshot (capture () method), you can set the area of the page to be shot using the setCaptureElements () method, and also perform some preparatory actions if necessary in the browser context using either the methods of the actions object or using arbitrary JavaScript code - for this in actions has an executeJS () method.
Example:
gemini.suite('login-dialog', suite => {
suite.setUrl('/')
.setCaptureElements('.login__form')
.capture('default');
.capture('focused', actions => actions.focus('.login__editor'));
});Test data
A test tool was chosen, but it was still a long way to the final solution. It was necessary to understand what to do with the data displayed in the pictures. Let me remind you that in the tests we decided not to draw individual components, but the entire page of the application, in order to test the visual components not in a vacuum, but in the real environment of other components. If you need to transfer the necessary test data to ee props (I'm talking about react components) to render an individual component, much more is needed to render the entire page of the application, and preparing the environment for such a test can be a headache.
Of course, you can leave the application itself to receive the data, so that during the test it will execute requests to the backend, which, in turn, would receive data from some kind of reference database, but what about versioning? You can’t put a database in a git repository. No, of course you can, but there are some decencies.
Alternatively, to run tests, you can replace the real backend server with a fake one, which would give the web application not data from the database, but static data stored, for example, in json format, already with the sources. However, the preparation of such data is also not too trivial. We decided to go the easier way - do not pull data from the server, but simply restore the application state before running the test (in our case, this is the state of the redux storage), which was in the application at the time of taking the reference image.
To serialize the current state of the redux store, the snapshot () method has been added to the window object:
export const snapshotStore = (store: Object, fileName: string): string => {
let state = store.getState();
const file = new Blob(
[ JSON.stringify(state, null, 2) ],
{ type: 'application/json' }
);
let a = document.createElement('a');
a.href = URL.createObjectURL(file);
a.download = `${fileName}.testdata.json`;
a.click();
return `State downloaded to ${a.download}`;
};
const store = createStore(reducer);
if (process.env.NODE_ENV !== 'production') {
window.snapshot = fileName => snapshotStore(store, fileName);
};
Using this method, using the command line of the browser console, you can save the current state of redux-storage to a file: Storybook
was chosen as an infrastructure for visual tests - a tool for interactive development of libraries of visual components. The main idea was that instead of the various states of the components in the stories tree, fix the various states of our application and use these states to take screenshots. In the end, there is no fundamental difference between simple and complex components, except in the preparation of the environment.
So, each visual test is a story, before rendering of which the state of the redux storage previously saved in the file is restored. This is done using the Provider component from the react-redux library, to the store property of which the deserialized state restored from the previously saved file is passed:
import preloadedState from './incoming-letter.testdata';
const store = createStore(rootReducer, preloadedState);
storiesOf('regression/Cards', module)
.add('IncomingLetter', () => {
return (
In the example above, ContextContainer is a component that includes the "skeleton" of the application - the navigation tree, the header and the content area. In the content area, various components can be rendered (list, card, dialog, etc.) depending on the current state of the redux storage. In order for the component not to fulfill unnecessary requests to the backend for input, corresponding stub properties are passed to it.
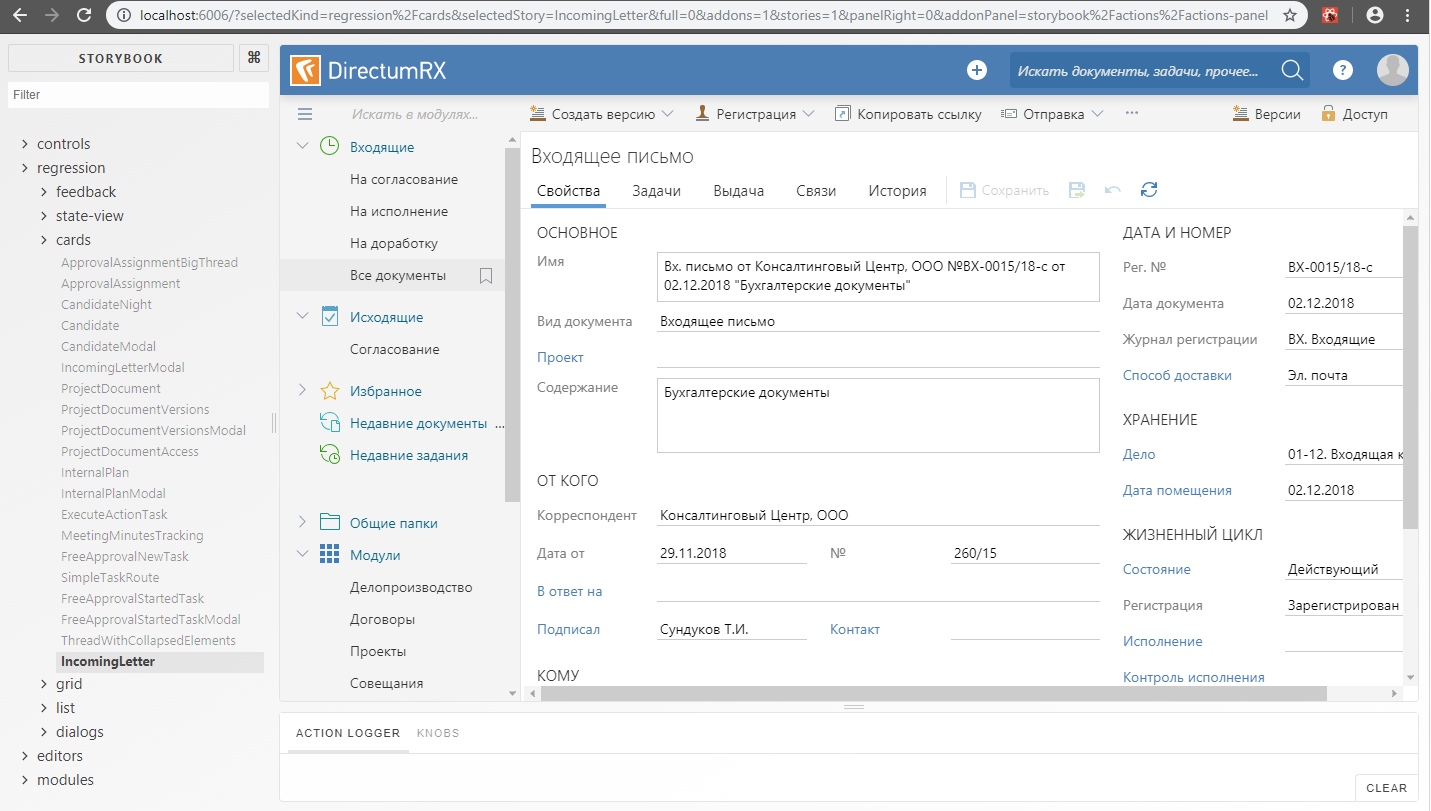
In the context of a Storybook, it looks something like this:
Gemini + storybook
So, we figured out the data for the tests. The next task is to make friends with Gemini and Storybook. At first glance, everything is simple - in the Gemini config we specify the address of the application under test. In our case, this is the address of the Storybook server. You only need to raise the storybook server before starting the gemini tests. You can do this directly from the code using the Gemini event subscription START_RUNNER and END_RUNNER:
const port = 6006;
const cofiguration = {
rootUrl:`localhost:${port}`,
gridUrl: seleniumGridHubUrl,
browsers: {
'chrome': {
screenshotsDir:'gemini/screens',
desiredCapabilities: chromeCapabilities
}
}
};
const Gemini = require('gemini');
const HttpServer = require('http-server');
const runner = new Gemini(cofiguration);
const server = HttpServer.createServer({ root: './storybook-static'});
runner.on(runner.events.START_RUNNER, () => {
console.log(`storybook server is listening on ${port}...`);
server.listen(port);
});
runner.on(runner.events.END_RUNNER, () => {
server.close();
console.log('storybook server is closed');
});
runner
.readTests(path)
.done(tests => runner.test(tests));As the server for tests, we used http-server, which returns the contents of the folder with the statically assembled storybook (to build the static storybook, use the build-storybook command ).
So far, everything has been going smoothly, but problems have not kept themselves waiting. The fact is that the storybook displays the story inside the frame. Initially, we wanted to be able to set the selective region of the image using setCaptureElements (), but this can only be done if you specify the frame address as the address for suite, something like this:
gemini.suite('VisualRegression', suite =>
suite.setUrl('http://localhost:6006/iframe.html?selectedKind=regression%2Fcards&selectedStory=IncomingLetter')
.setCaptureElements('.some-component')
.capture('IncomingLetter')
);
But then it turns out that for each shot we must create our own suite, because The URL can be set for the suite as a whole, but not for a single snapshot within the suite. It should be understood that each suite runs in a separate browser session. This, in principle, is correct - the tests should not depend on each other, but opening a separate browser session and subsequent loading of the Storybook takes quite a lot of time, much more than just moving through stories within the framework of the already open Storybook. Therefore, with a large number of suites, the test execution time is very slow. Part of the problem can be solved by parallelizing the execution of tests, but parallelization consumes a lot of resources (memory, processor). Therefore, having decided to save on resources and at the same time not to lose too much in the duration of the test run, we refused to open the frame in a separate browser window. Tests are performed within a single browser session, but before each shot, the next story is loaded into the frame as if we just opened the storybook and clicked on individual nodes in the stories tree. Image area - entire frame:
gemini.suite('VisualRegression', suite =>
suite.setUrl('/')
.setCaptureElements('#storybook-preview-iframe')
.capture('IncomingLetter', actions => openStory(actions, 'IncomingLetter'))
.capture('ProjectDocument', actions => openStory(actions, 'ProjectDocumentAccess'))
.capture('RelatedDocuments', actions => {
openStory(actions, 'RelatedDocuments');
hover(actions, '.related-documents-tree-item__title', 4);
})
);Unfortunately, in this option, in addition to the ability to select the image area, we also lost the ability to use standard actions of the Gemini engine to work with elements of the DOM tree (mouseDown (), mouseMove (), focus (), etc.), etc. to. Elements within the Gemini frame do not “see.” But we still have the opportunity to use the function executeJS (), with which you can execute JavaScript code in a browser context. Based on this function, we implemented the analogues of standard actions that we need, which already work in the context of the Storybook frame. Here we had to “conjure” a little in order to transfer parameter values from the test context to the browser context - executeJS (), unfortunately, does not provide such an opportunity. Therefore, at first glance, the code looks a little strange - the function is translated into a string,
function openStory(actions, storyName) {
const storyNameLowered = storyName.toLowerCase();
const clickTo = function(window) {
Array.from(window.document.querySelectorAll('a')).filter(
function(el) {
return el.textContent.toLowerCase() === 'storyNameLowered';
})[0].click();
};
actions.executeJS(eval(`(${clickTo.toString().replace('storyNameLowered', storyNameLowered)})`));
}
function dispatchEvents(actions, targets, index, events) {
const dispatch = function(window) {
const document = window.document.querySelector('#storybook-preview-iframe').contentWindow.document;
const target = document.querySelectorAll('targets')[index || 0];
events.forEach(function(event) {
const clickEvent = document.createEvent('MouseEvents');
clickEvent.initEvent(event, true, true);
target.dispatchEvent(clickEvent);
});
};
actions.executeJS(eval(`(${dispatch.toString()
.replace('targets', targets)
.replace('index', index)
.replace('events', `["${events.join('","')}"]`)})`
));
}
function hover(actions, selectors, index) {
dispatchEvents(actions, selectors, index, [
'mouseenter',
'mouseover'
]);
}
module.exports = {
openStory: openStory,
hover: hover
};
Repetitions of execution
After the visual tests were written and started to work, it turned out that some of the tests were not very stable. Somewhere, the icon will not have time to draw, somewhere the selection will not be removed and we get a mismatch with the reference image. Therefore, it was decided to include retests of test execution. However, in Gemini, retries work for the entire suite, and as mentioned above, we tried to avoid situations where a suite is made for each shot - this slows down the execution of tests too much. On the other hand, the more shots are taken within the framework of one suite, the greater the likelihood that the repeated execution of the suite may fall as well as the previous one. Therefore, it was necessary to implement retries. In our scheme, repetition of the execution is not done for the entire suite, but only for those pictures that did not pass on the previous failed run.
const SuiteCollection = require('gemini/lib/suite-collection');
const Suite = require('gemini/lib/suite');
let retrySuiteCollection;
let retryCount = 2;
runner.on(runner.events.BEGIN, () => {
retrySuiteCollection = new SuiteCollection();
});
runner.on(runner.events.TEST_RESULT, args => {
const testId = `${args.state.name}/${args.suite.name}/${args.browserId}`;
if (!args.equal) {
if (retryCount > 0)
console.log(chalk.yellow(`failed ${testId}`));
else
console.log(chalk.red(`failed ${testId}`));
let suite = retrySuiteCollection.topLevelSuites().find(s => s.name === args.suite.name);
if (!suite) {
suite = new Suite(args.suite.name);
suite.url = args.suite.url;
suite.file = args.suite.file;
suite.path = args.suite.path;
suite.captureSelectors = [ ...args.suite.captureSelectors ];
suite.browsers = [ ...args.suite.browsers ];
suite.skipped = [ ...args.suite.skipped ];
suite.beforeActions = [ ...args.suite.beforeActions ];
retrySuiteCollection.add(suite);
}
if (!suite.states.find(s => s.name === args.state.name)) {
suite.addState(args.state.clone());
}
}
else
console.log(chalk.green(`passed ${testId}`));
});By the way, the TEST_RESULT event was also useful for visualizing the progress of tests as they passed. Now the developer does not need to wait until all the tests are completed, he can interrupt the execution if he sees that something went wrong. If test execution is interrupted, Gemini will correctly close browser sessions opened by the selenium server.
Upon completion of the test run, if the new suite is not empty, run it until the maximum number of repetitions is exhausted:
function onComplete(result) {
if ((retryCount--) > 0 && result.failed > 0 && retrySuiteCollection.topLevelSuites().length > 0) {
runner.test(retrySuiteCollection, {}).done(onComplete);
}
}
runner.readTests(path).done(tests => runner.test(tests).done(onComplete));Summary
Today we have about fifty visual tests covering the main visual states of our application. Of course, there is no need to talk about full coverage of UI tests, but we have not set such a goal yet. Tests work successfully both at the developers' workstations and at build agents. While tests are performed only in the context of Chrome and Internet Explorer, but in the future it is possible to connect other browsers. All this economy serves the Selemium grid with two nodes deployed on virtual machines.
From time to time, we are faced with the fact that after the release of the new version of Chrome it is necessary to update the reference pictures due to the fact that some elements began to be displayed a little differently (for example, scrollers), but there is nothing to be done about it. It’s rare, but it happens that when changing the structure of a redux-storage, you have to re-retrieve the saved states for the tests. To restore exactly the same state that was in the test at the time of its creation, of course, is not easy. As a rule, no one already remembers on which database these pictures were taken and you have to take a new picture on other data. This is a problem, but not a big one. To solve it, you can take pictures on a demo base, since we have scripts for its generation and are kept up to date.