First Model: Fashion MNIST Dataset
- Tutorial
The full course in Russian can be found at this link .
The original English course is available at this link .

New lectures are scheduled every 2-3 days.
“So, we are still with you and with us, as before, Sebastian.” We just want to discuss fully connected layers, those same Dense layers. Before that, I would like to ask one question. What are the boundaries and what are the main obstacles that will stand in the way of deep learning and will have the greatest impact on it in the next 10 years? Everything changes so fast! What do you think will be the very next “big thing”?
- I would say two things. The first is general AI for more than one task. This is great! People can solve more than one problem and should never do the same thing. The second is bringing technology to market. For me, the peculiarity of machine learning is that it provides computers with the ability to observe and find patterns in data, helping people become the best in the field - at the expert level! Machine learning can be used in law, medicine, autonomous cars. Develop such applications because they can bring a huge amount of money, but most importantly, you have the opportunity to make the world a much better place.
- I really like the way you say everything into a single picture of deep learning and its application - this is just a tool that can help you solve a certain problem.
- Yes exactly! Incredible tool, right?
- Yes, yes, I completely agree with you!
“Almost like a human brain!”
- You mentioned medical applications in our first interview, in the first part of the video course. In which applications, in your opinion, the use of deep learning causes the greatest delight and surprise?
- Lots of! Highly! Medicine is on the short list of areas that actively use deep learning. I lost my sister a few months ago, she was ill with cancer, which is very sad. I think there are many diseases that could be detected earlier - in the early stages, making it possible to cure or slow down the process of their development. The idea, in fact, is to transfer some tools to the house (smart home), so that it is possible to detect such deviations in health long before the moment when the person himself sees them. I would also add - everything is repeated, any office work, where you perform the same type of actions again and again, for example, bookkeeping. Even I, as CEO, do a lot of repetitive actions. It would be great to automate them,
- I can not disagree with you! In this lesson, we will introduce students to a course with a neural network layer called a dense-layer. Could you tell us in more detail what you think about fully connected layers?
- So, let's start with the fact that each network can be connected in different ways. Some of them may have very tight connectivity, which allows you to get some benefit in scaling and “win” against large networks. Sometimes you don’t know how many connections you need, so you connect everything with everything - this is called a fully connected layer. I add that this approach has much more power and potential than something more structured.
- I completely agree with you! Thank you for helping us learn a little more about fully connected layers. I look forward to the moment when we finally begin to implement them and write code.
- Enjoy! It will be really fun!
- Welcome back! In the last lesson, you figured out how to build your first neural network using TensorFlow and Keras, how neural networks work, and how the training (training) process works. In particular, we saw how to train the model to convert degrees Celsius to degrees Fahrenheit.

- We also got acquainted with the concept of fully connected layers (dense layers), the most important layer in neural networks. But in this lesson we will do much cooler things! In this lesson, we will develop a neural network that can recognize clothing elements and images. As we mentioned earlier, machine learning uses input called “features,” and output called “labels,” by which the model learns and finds a transformation algorithm. Therefore, firstly, we will need many examples to train the neural network to recognize various elements of clothing. Let me remind you that an example for training is a pair of values - an input feature and an output label, which are fed to the input of a neural network. In our new example, the image will be the input, and the output label should be the category of clothing to which the clothing item shown in the picture belongs. Fortunately, such a dataset already exists. It is called Fashion MNIST. We will take a closer look at this dataset in the next part.
Welcome to the world of the MNIST dataset! So, our set consists of 28x28 images, each pixel of which represents a shade of gray.

The data set contains images of T-shirts, tops, sandals and even boots. Here is a complete list of what our MNIST dataset contains:
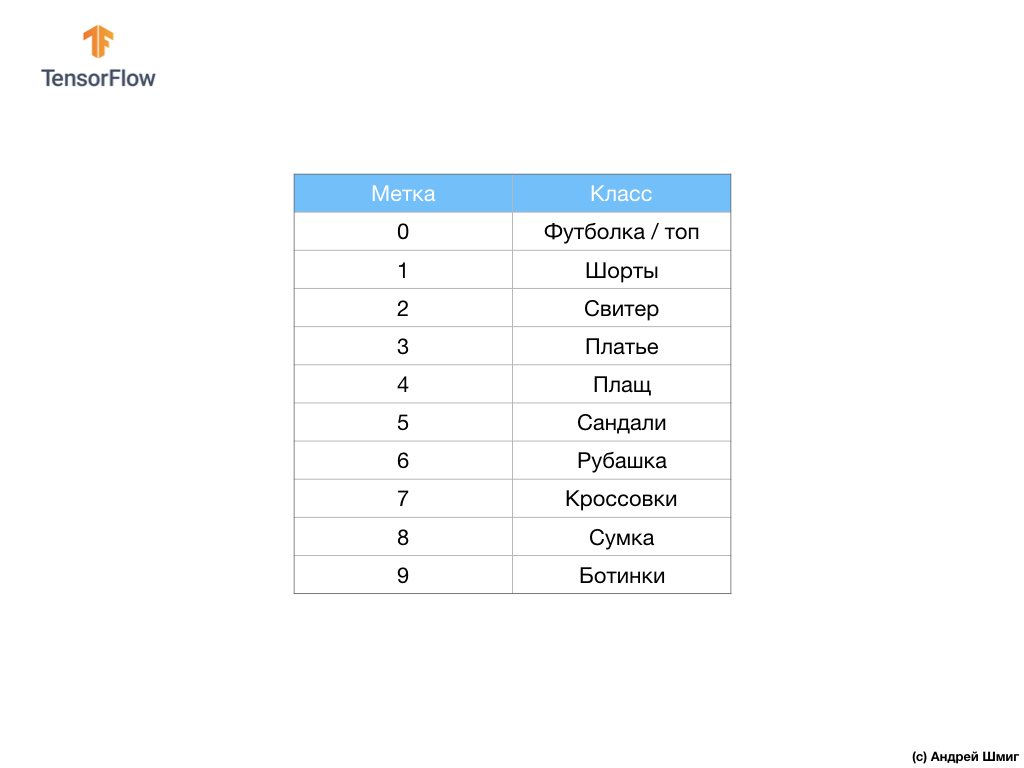
Each input image has one of the labels listed above. The Fashion MNIST dataset contains 70,000 images, so we have a place to start and work with. Of these 70,000, we will use 60,000 to train the neural network.
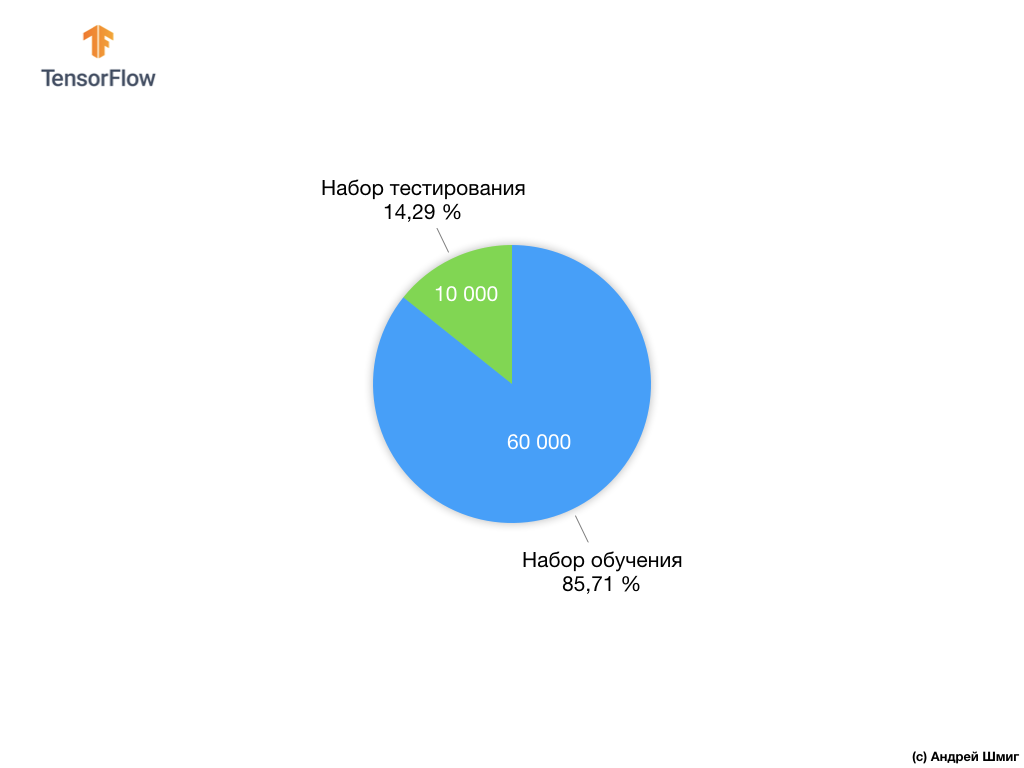
And we will use the remaining 10,000 elements to check how well our neural network has learned to recognize elements of clothing. Later we will explain why we divided the data set into a training set and a test set.
So here is our Fashion MNIST dataset.
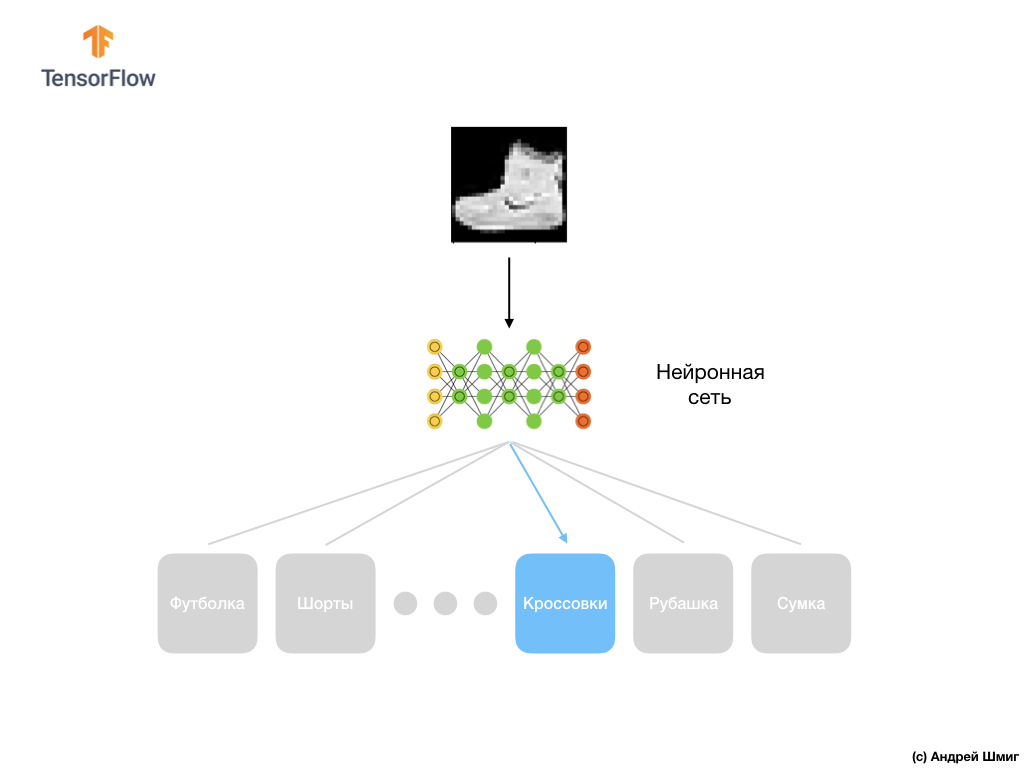
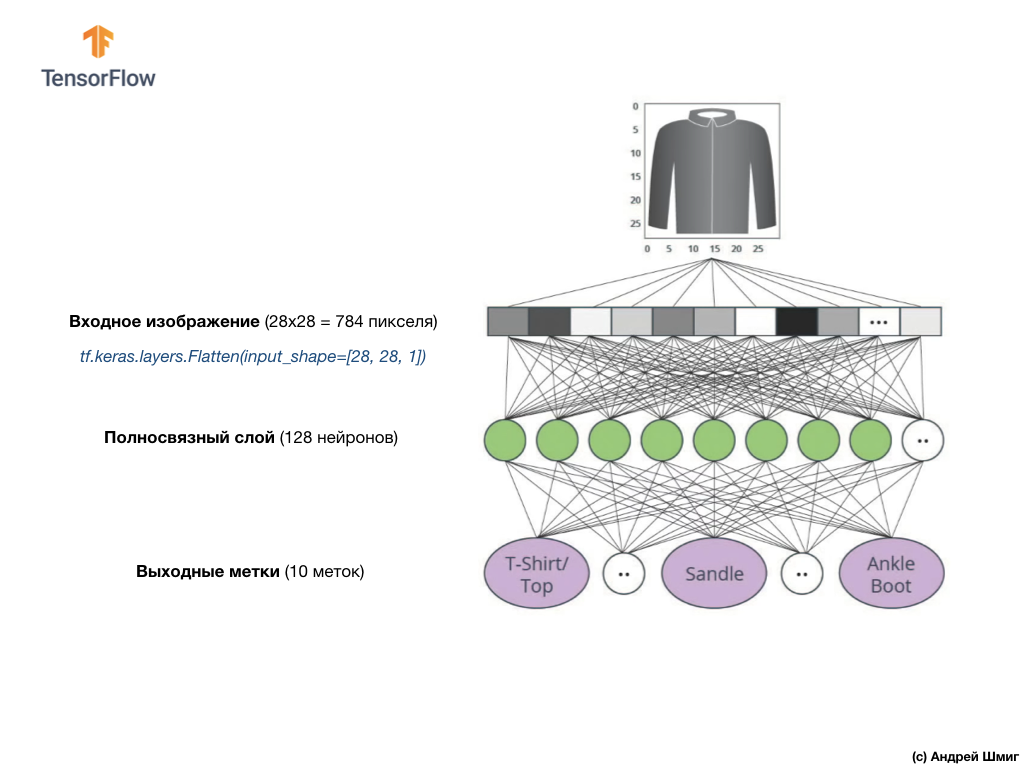
Remember, each image in the dataset is an image of size 28x28 in shades of gray, which means that each image is 784 bytes in size. Our task is to create a neural network, which receives these 784 bytes at the input, and at the output returns to which category of clothes out of 10 available, the element applied at the input belongs.
In this lesson, we will use a deep neural network that learns to classify images from the Fashion MNIST dataset.
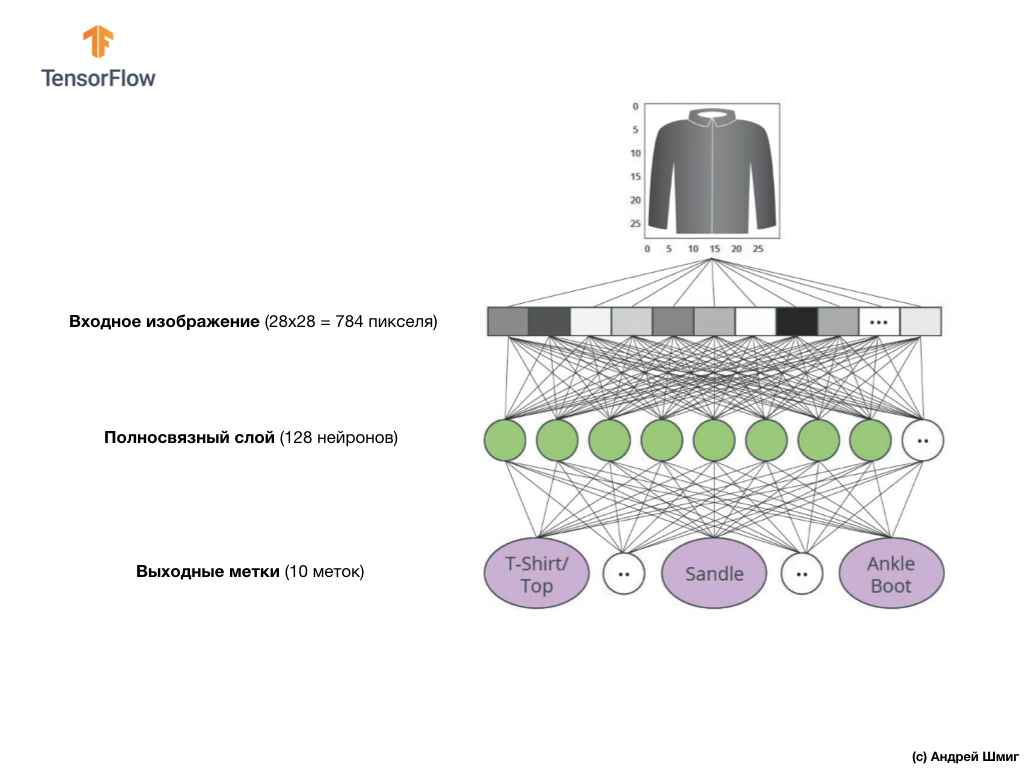
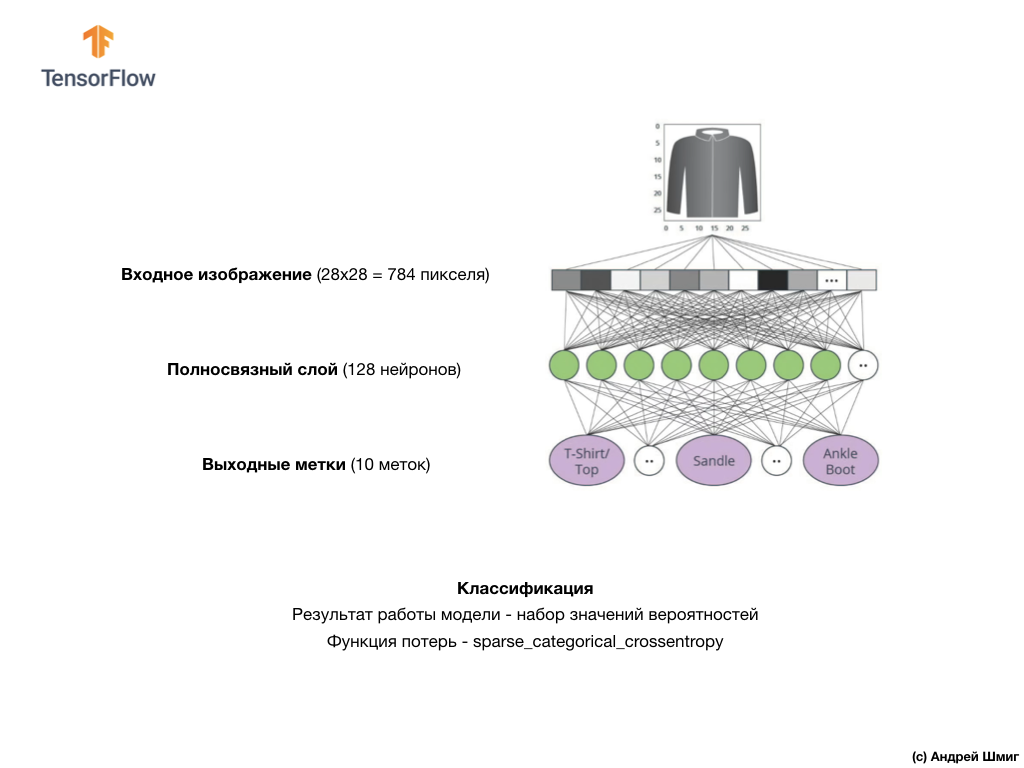
The image above shows what our neural network will look like. Let's look at it in more detail.
The input value of our neural network is a one-dimensional array with a length of 784, an array of exactly that length for the reason that each image is 28x28 pixels (= 784 pixels in total in the image), which we will convert to a one-dimensional array. The process of converting a 2D image into a vector is called flattening and is implemented through a smoothing layer — a flatten layer.
You can perform smoothing by creating the appropriate layer:
This layer converts a 28x28 pixel 2D image (1 byte for shades of gray for each pixel) into a 1D array of 784 pixels.
The input values will be fully related to our first
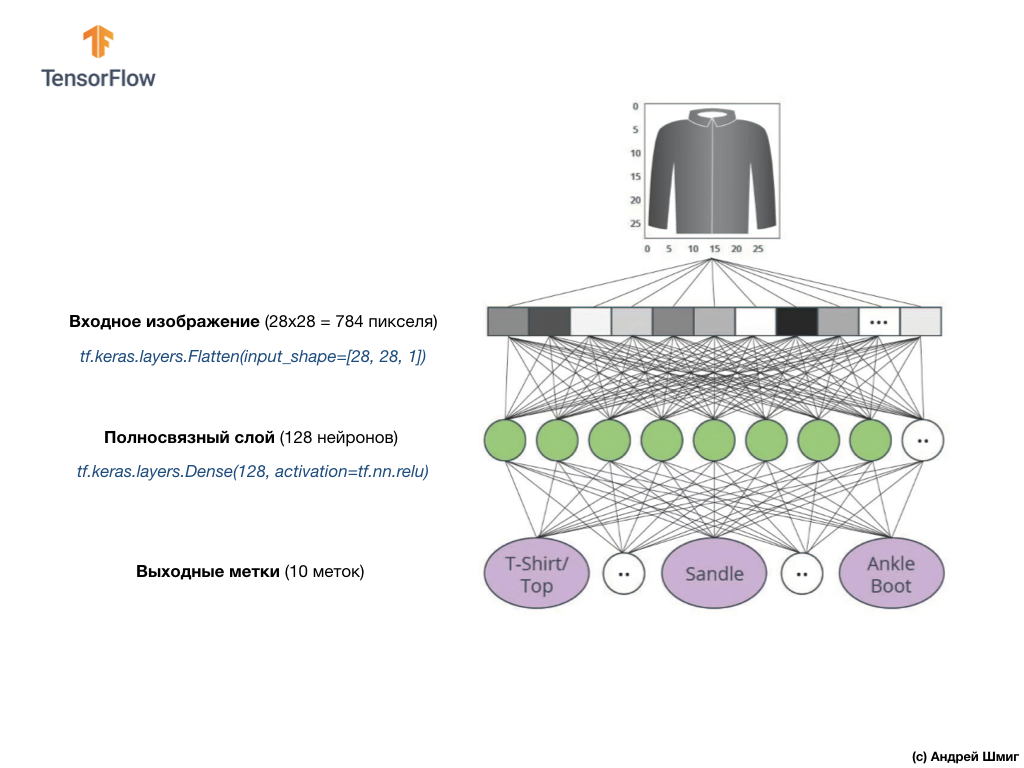
Here's what the creation of this layer in the code will look like:
Stop! What the hell is this
Finally, our last layer, also known as the output layer, consists of 10 neurons. It consists of 10 neurons because our Fashion MNIST dataset contains 10 clothing categories. Each of these 10 output values will represent the likelihood that the input image is in this clothing category. In other words, these values reflect the “confidence” of the model in the correctness of the prediction and correlation of the filed image with a specific out of 10 clothing categories at the output. For example, what is the likelihood that the image shows a dress, sneakers, shoes, etc.
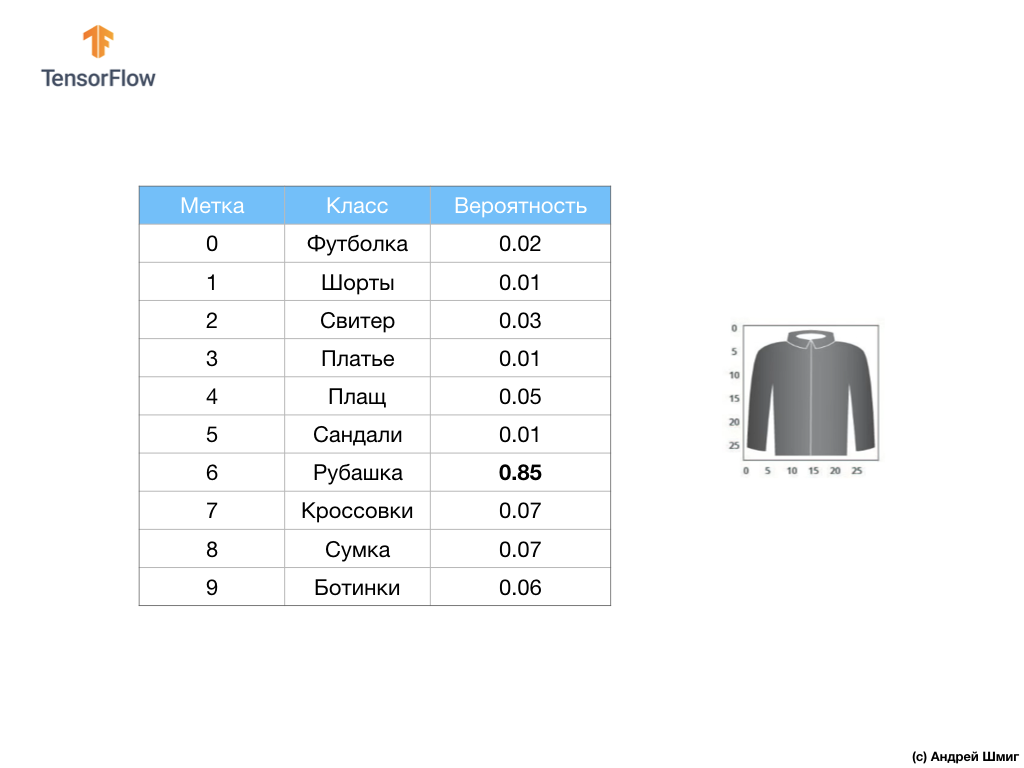
For example, if a shirt image is sent to the input of our neural network, then the model can give us results like the ones you see in the image above - the probability of the input image matching the output label.
If you pay attention, you will notice that the greatest probability - 0.85 refers to tag 6, which corresponds to the shirt. The model is 85% sure that the image on the shirt. Usually, things that look like shirts will also have a high probability rating, and things that are least similar will have a lower probability rating.
Since all 10 output values correspond to probabilities, when summing all these values we get 1. These 10 values are also called the probability distribution.
Now we need an output layer to calculate the very probabilities for each label.

And we will do this with the following command:
In fact, whenever we create neural networks that solve classification problems, we always use a fully connected layer as the last layer of a neural network. The last layer of the neural network should contain the number of neurons equal to the number of classes, the membership of which we determine and use the
In this lesson, we talked about
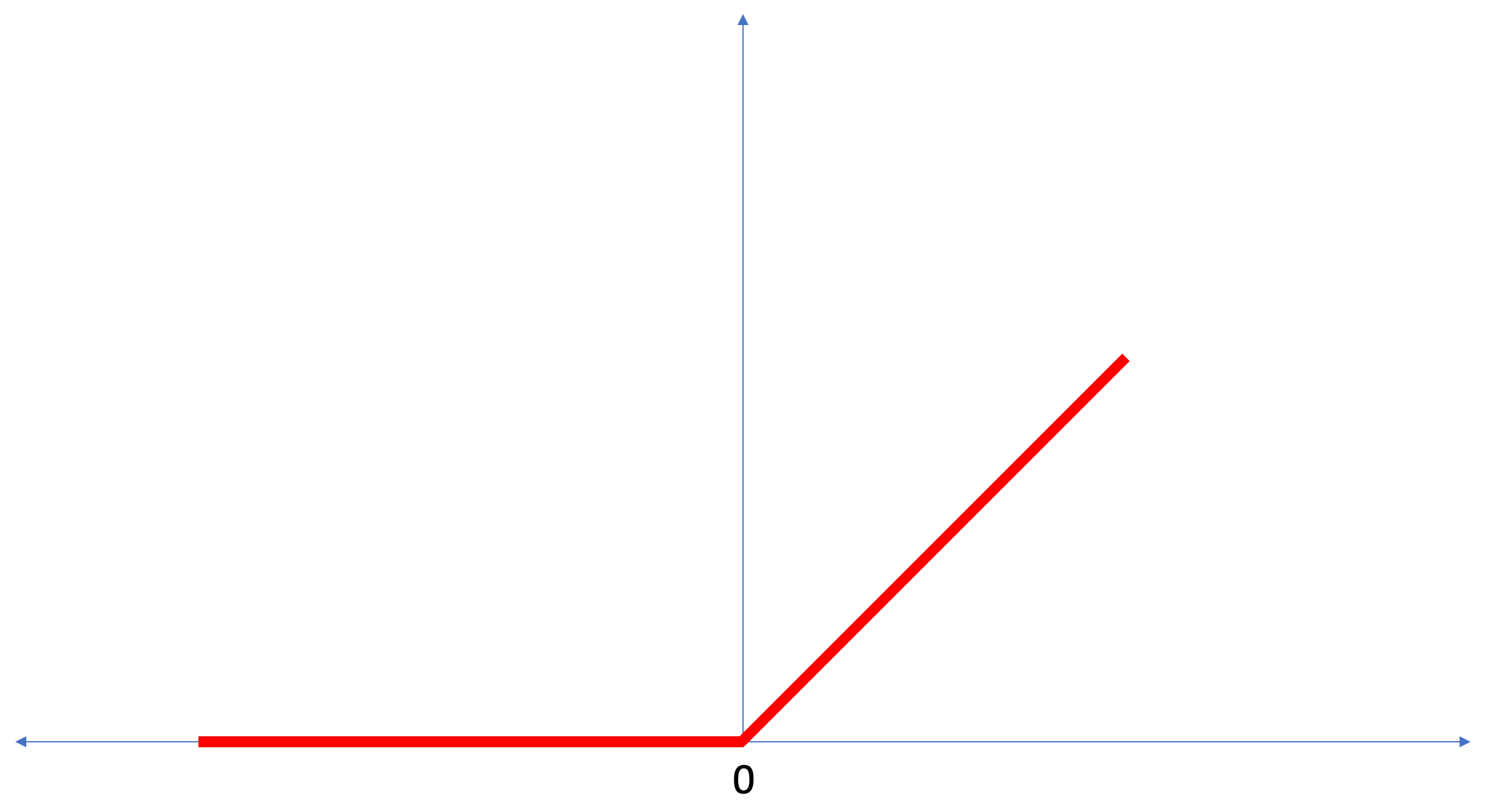
The function
Converting degrees Celsius to degrees Fahrenheit is a linear task because the expression
Let's go over the new terms introduced in this lesson:
When training a model, any model in machine learning, it is always necessary to divide the data set into at least two different sets - the data set used for training and the data set used for testing. In this part we will understand why it is worth doing this.
Let's remember how we distributed our data set from Fashion MNIST consisting of 70,000 copies.
We proposed dividing 70,000 into two parts - in the first part, leave 60,000 for training, and in the second part 10,000 for testing. The necessity of this approach is caused by the following fact: after the model has been trained on 60,000 copies, it is necessary to check the results and the effectiveness of its work on examples that were not yet in the data set on which the model was trained.
In its own way, it resembles passing an exam at school. Before you pass the exam, you are diligently engaged in solving problems of a particular class. Then, in the exam, you come across the same class of problems, but with different input data. It makes no sense to submit the same data that was during the training, otherwise the task will be reduced to remembering decisions, and not searching for a solution model. That is why at exams you are faced with tasks that were not previously in the curriculum. Only in this way can we verify whether the model has learned the general solution or not.
The same thing happens with machine learning. You show some data that represents a certain class of tasks that you want to learn how to solve. In our case, with a data set from Fashion MNIST, we want the neural network to be able to determine the category to which the clothing element in the image belongs. That is why we train our model on 60,000 examples that contain all categories of clothing items. After training, we want to check the effectiveness of the model, so we feed the remaining 10,000 items of clothing that the model has not yet “seen”. If we decided not to do this, not to test with 10,000 examples, we would not be able to say with certainty whether our model was actually trained to determine the class of the clothing item or if she remembered all the pairs of input + output values.
That is why in machine learning we always have a dataset for training and a dataset for testing.
TensorFlow is a collection of ready-to-use training data.
Data sets are usually divided into several blocks, each of which is used at a certain stage of training and testing the effectiveness of the neural network. In this part we talk about:
Consider another dataset, which I call a validation dataset. This data set is not used to train the model, only during training. So, after our model has gone through several training cycles, we feed it our test data set and look at the results. For example, if during training the value of the loss function decreases, and the accuracy deteriorates on the test data set, this means that our model simply simply remembers pairs of input-output values.
The verification data set is reused at the very end of the training to measure the final accuracy of the model predictions.
You can read more about training and test data sets at the Google Crash Course..
Link to the original CoLab in English and a link to Russian CoLab .
In this part of the lesson, we will build and train a neural network to classify images of clothing elements, such as dresses, sneakers, shirts, t-shirts, etc.
It’s all right if some moments are not clear. The purpose of this course is to introduce you to TensorFlow and at the same time explain the algorithms of its work and develop a common understanding of projects using TensorFlow, rather than delving into the implementation details.
In this part, we use
We will need a TensorFlow dataset , an API that simplifies loading and accessing datasets provided by several services. We will also need some auxiliary libraries.
This example uses the Fashion MNIST dataset, which contains 70,000 images of clothing items in 10 categories in grayscale. Images contain clothing items in low resolution (28x28 pixels), as shown below:

Fashion MNIST is used as a replacement for the classic MNIST dataset - most often used as “Hello, World!” in machine learning and computer vision. The MNIST dataset contains images of hand-written numbers (0, 1, 2, etc.) in the same format as the clothing items in our example.
In our example, we use Fashion MNIST because of the variety and because this task is more interesting from the point of view of implementation than solving a typical problem on the MNIST data set. Both data sets are small enough, therefore, they are used to check the correct operability of the algorithm. Great datasets for starting learning machine learning, testing, and debugging code.
We will use 60,000 images to train the network and 10,000 images to test the accuracy of training and image classification. You can directly access the Fashion MNIST dataset through TensorFlow using the API:
By loading a data set we get metadata, a training data set and a test data set.
Images are two-dimensional arrays
Each image belongs to one tag. Since the class names are not contained in the original data set, let's save them for future use when we draw the images:
Let's study the format and structure of the data presented in the training set before training the model. The following code will show that 60,000 images are in the training dataset, and 10,000 images are in the test dataset:
The value of each pixel in the image is in the range
Let's draw an image to take a look at it:
We display the first 25 images from the training data set and under each image we indicate which class it belongs to.
Make sure that the data is in the correct format and we are ready to start creating and training the network.

Building a neural network requires tuning layers, and then assembling a model with optimization and loss functions.
The basic element in building a neural network is the layer. The layer extracts the view from the data that came into its input. The result of the work of several layers connected, we get a view that makes sense to solve the problem.
Most of the time doing deep learning you will be creating links between simple layers. Most layers, for example, such as tf.keras.layers.Dense, have a set of parameters that can be “fitted” during the learning process.
The network consists of three layers:
Before we start training the model, it’s worth a few more settings. These settings are made during model assembly when the compile method is called:
Firstly, we determine the sequence of actions during training on a training data set:
Training takes place by calling the method
(
And here is the conclusion: During the training of the model, the value of the loss function and the accuracy metric are displayed for each training iteration. This model achieves an accuracy of about 0.88 (88%) on training data.
Let's check what accuracy the model produces on test data. We will use all the examples that we have in the test data set for checking accuracy.
Conclusion: As you can see, the accuracy on the test data set turned out to be less than the accuracy on the training data set. This is quite normal since the model was trained on train_dataset data. When a model discovers images that it has never seen before (from the train_dataset dataset), it is obvious that the classification efficiency will decrease.
We can use the trained model to obtain predictions for some images.
Conclusion: In the example above, the model predicted labels for each test input image. Let's look at the first prediction:
Conclusion:
Recall that model predictions are an array of 10 values. These values describe the “confidence” of the model that the input image belongs to a certain class (clothing item). We can see the maximum value as follows:
Conclusion:
This means that the model was most confident that this image belongs to the class labeled 6 (class_names [6]). We can check and make sure that the result is true and that it is correct:
We can display all input images and the corresponding model predictions for 10 classes:
Let's take a look at the 0th image, the result of the prediction of the model and the array of predictions.
Let's now display some images with their respective predictions. Correct predictions are blue, incorrect predictions are red. The value below the image reflects the percentage of confidence that the input image corresponds to this class. Please note that the result may be incorrect even if the value of “confidence” is high.

Use the trained model to predict the label for a single image:
Conclusion:
Models in are
Conclusion:
Now we will predict the result:
Conclusion:
The model.predict method returns a list of lists (an array of arrays), each for an image from an input block. We get the only result for our single input image:
Conclusion:
As previously, the model predicted label 6 (shirt).
Experiment with different models and see how accuracy will change. In particular, try changing the following settings:
Remember to activate the GPU so that all calculations are faster (
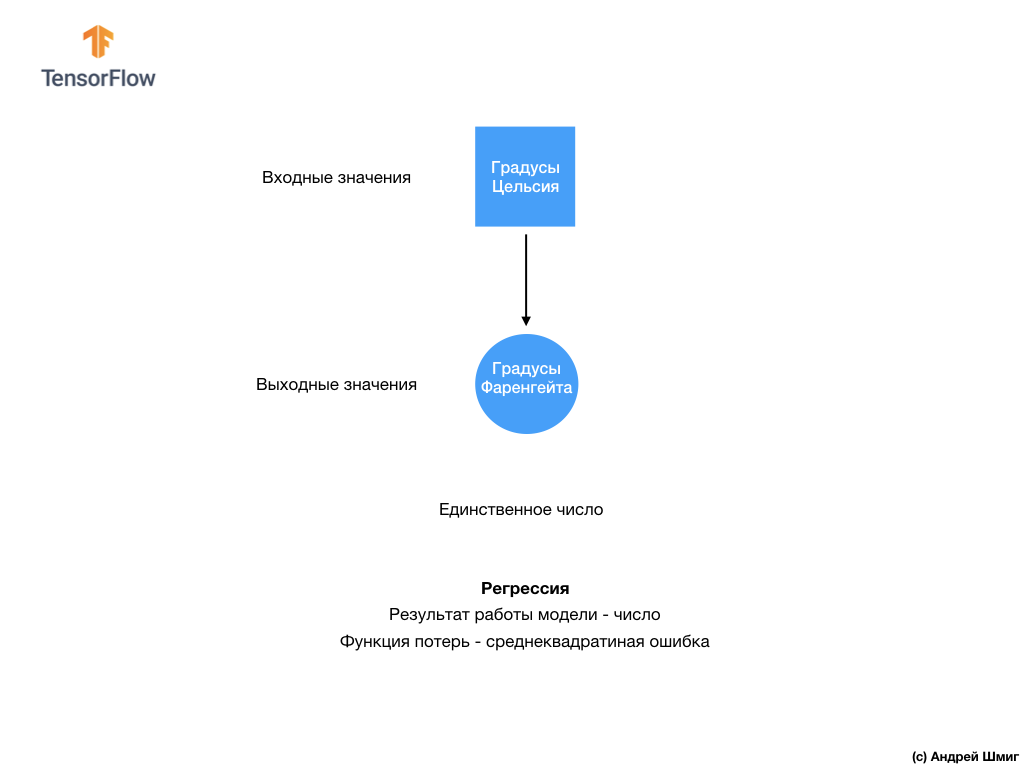
- At this stage, we have already encountered two types of neural networks. Our first neural network learned how to convert degrees Celsius to degrees Frenheit, returning a single value that can be in a wide range of numerical values.
Our second neural network returns 10 probability values that reflect the confidence of the network that the input image corresponds to a certain class.
Neural networks can be used to solve various problems.
The first class of problems that we solved with the prediction of a single value is called regression. Converting degrees Celsius to degrees Fahrenheit is one example of the task of this class. Another example of this class of tasks may be the task of determining the value of a house by the number of rooms, total area, location and other characteristics.
The second class of tasks that we examined in this lesson classifying images into available categories is called classification . According to the input data, the model will return the probability distribution (the “confidence” of the model that the input value belongs to this class). In this lesson, we developed a neural network that classified clothing elements into 10 categories, and in the next lesson, we will learn to determine who is shown in the photograph - a dog or a cat, this task also belongs to the classification task.
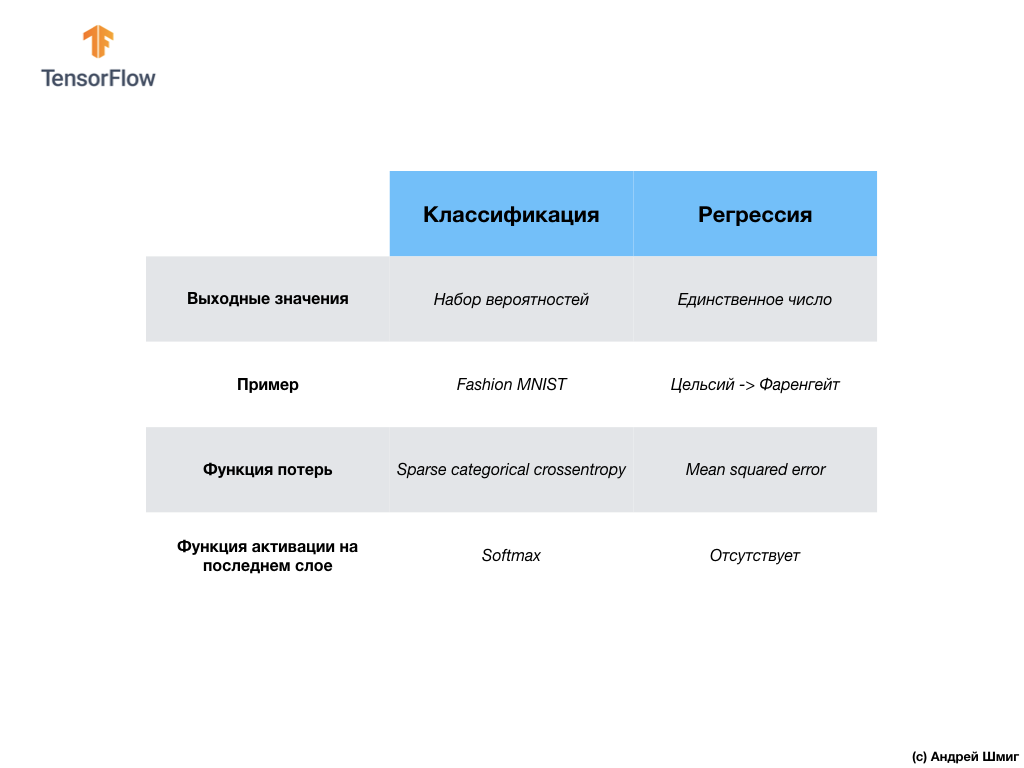
Let's summarize and note the difference between these two classes of problems - regression and classification .
Congratulations, you have studied two types of neural networks! Get ready for the next lecture, there we will study a new type of neural networks - convolutional neural networks (CNN).
In this lesson, we trained the neural network to classify images with elements of clothing. To do this, we used the Fashion MNIST dataset, which contains 70,000 images of clothing items. 60,000 of which we used to train the neural network, and the remaining 10,000 to test the effectiveness of its work. In order to submit these images to the input of our neural network, we needed to convert (smooth) them from a 28x28 2D format to a 1D format of 784 elements. Our network consisted of a fully connected layer of 128 neurons and an output layer of 10 neurons, corresponding to the number of labels (classes, categories of clothing items). These 10 output values represented the probability distribution for each class. Softmax activation functioncounted the probability distribution.
We also learned about the differences between regression and classification .
... and standard call-to-action - sign up, put plus and share :)
YouTube
Telegram
VKontakte
The original English course is available at this link .
New lectures are scheduled every 2-3 days.
Interview with Sebastian Trun, CEO Udacity
“So, we are still with you and with us, as before, Sebastian.” We just want to discuss fully connected layers, those same Dense layers. Before that, I would like to ask one question. What are the boundaries and what are the main obstacles that will stand in the way of deep learning and will have the greatest impact on it in the next 10 years? Everything changes so fast! What do you think will be the very next “big thing”?
- I would say two things. The first is general AI for more than one task. This is great! People can solve more than one problem and should never do the same thing. The second is bringing technology to market. For me, the peculiarity of machine learning is that it provides computers with the ability to observe and find patterns in data, helping people become the best in the field - at the expert level! Machine learning can be used in law, medicine, autonomous cars. Develop such applications because they can bring a huge amount of money, but most importantly, you have the opportunity to make the world a much better place.
- I really like the way you say everything into a single picture of deep learning and its application - this is just a tool that can help you solve a certain problem.
- Yes exactly! Incredible tool, right?
- Yes, yes, I completely agree with you!
“Almost like a human brain!”
- You mentioned medical applications in our first interview, in the first part of the video course. In which applications, in your opinion, the use of deep learning causes the greatest delight and surprise?
- Lots of! Highly! Medicine is on the short list of areas that actively use deep learning. I lost my sister a few months ago, she was ill with cancer, which is very sad. I think there are many diseases that could be detected earlier - in the early stages, making it possible to cure or slow down the process of their development. The idea, in fact, is to transfer some tools to the house (smart home), so that it is possible to detect such deviations in health long before the moment when the person himself sees them. I would also add - everything is repeated, any office work, where you perform the same type of actions again and again, for example, bookkeeping. Even I, as CEO, do a lot of repetitive actions. It would be great to automate them,
- I can not disagree with you! In this lesson, we will introduce students to a course with a neural network layer called a dense-layer. Could you tell us in more detail what you think about fully connected layers?
- So, let's start with the fact that each network can be connected in different ways. Some of them may have very tight connectivity, which allows you to get some benefit in scaling and “win” against large networks. Sometimes you don’t know how many connections you need, so you connect everything with everything - this is called a fully connected layer. I add that this approach has much more power and potential than something more structured.
- I completely agree with you! Thank you for helping us learn a little more about fully connected layers. I look forward to the moment when we finally begin to implement them and write code.
- Enjoy! It will be really fun!
Introduction
- Welcome back! In the last lesson, you figured out how to build your first neural network using TensorFlow and Keras, how neural networks work, and how the training (training) process works. In particular, we saw how to train the model to convert degrees Celsius to degrees Fahrenheit.
- We also got acquainted with the concept of fully connected layers (dense layers), the most important layer in neural networks. But in this lesson we will do much cooler things! In this lesson, we will develop a neural network that can recognize clothing elements and images. As we mentioned earlier, machine learning uses input called “features,” and output called “labels,” by which the model learns and finds a transformation algorithm. Therefore, firstly, we will need many examples to train the neural network to recognize various elements of clothing. Let me remind you that an example for training is a pair of values - an input feature and an output label, which are fed to the input of a neural network. In our new example, the image will be the input, and the output label should be the category of clothing to which the clothing item shown in the picture belongs. Fortunately, such a dataset already exists. It is called Fashion MNIST. We will take a closer look at this dataset in the next part.
Fashion MNIST Dataset
Welcome to the world of the MNIST dataset! So, our set consists of 28x28 images, each pixel of which represents a shade of gray.
The data set contains images of T-shirts, tops, sandals and even boots. Here is a complete list of what our MNIST dataset contains:
Each input image has one of the labels listed above. The Fashion MNIST dataset contains 70,000 images, so we have a place to start and work with. Of these 70,000, we will use 60,000 to train the neural network.
And we will use the remaining 10,000 elements to check how well our neural network has learned to recognize elements of clothing. Later we will explain why we divided the data set into a training set and a test set.
So here is our Fashion MNIST dataset.
Remember, each image in the dataset is an image of size 28x28 in shades of gray, which means that each image is 784 bytes in size. Our task is to create a neural network, which receives these 784 bytes at the input, and at the output returns to which category of clothes out of 10 available, the element applied at the input belongs.
Neural network
In this lesson, we will use a deep neural network that learns to classify images from the Fashion MNIST dataset.
The image above shows what our neural network will look like. Let's look at it in more detail.
The input value of our neural network is a one-dimensional array with a length of 784, an array of exactly that length for the reason that each image is 28x28 pixels (= 784 pixels in total in the image), which we will convert to a one-dimensional array. The process of converting a 2D image into a vector is called flattening and is implemented through a smoothing layer — a flatten layer.
You can perform smoothing by creating the appropriate layer:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
This layer converts a 28x28 pixel 2D image (1 byte for shades of gray for each pixel) into a 1D array of 784 pixels.
The input values will be fully related to our first
densenetwork layer, the size of which we have chosen equal to 128 neurons. Here's what the creation of this layer in the code will look like:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Stop! What the hell is this
tf.nn.relu? We did not use this in our previous neural network example when converting degrees Celsius to degrees Fahrenheit! The bottom line is that the current task is much more complicated than the one that was used as a fact-finding example - converting degrees Celsius to degrees Fahrenheit. ReLUIs a mathematical function that we add to our fully connected layer and which gives more power to our network. In fact, this is a small extension for our fully connected layer, which allows our neural network to solve more complex problems. We will not go into details, but a little more detailed information can be found below.Finally, our last layer, also known as the output layer, consists of 10 neurons. It consists of 10 neurons because our Fashion MNIST dataset contains 10 clothing categories. Each of these 10 output values will represent the likelihood that the input image is in this clothing category. In other words, these values reflect the “confidence” of the model in the correctness of the prediction and correlation of the filed image with a specific out of 10 clothing categories at the output. For example, what is the likelihood that the image shows a dress, sneakers, shoes, etc.
For example, if a shirt image is sent to the input of our neural network, then the model can give us results like the ones you see in the image above - the probability of the input image matching the output label.
If you pay attention, you will notice that the greatest probability - 0.85 refers to tag 6, which corresponds to the shirt. The model is 85% sure that the image on the shirt. Usually, things that look like shirts will also have a high probability rating, and things that are least similar will have a lower probability rating.
Since all 10 output values correspond to probabilities, when summing all these values we get 1. These 10 values are also called the probability distribution.
Now we need an output layer to calculate the very probabilities for each label.
And we will do this with the following command:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
In fact, whenever we create neural networks that solve classification problems, we always use a fully connected layer as the last layer of a neural network. The last layer of the neural network should contain the number of neurons equal to the number of classes, the membership of which we determine and use the
softmaxactivation function.ReLU - neuron activation function
In this lesson, we talked about
ReLUhow about something that expands the capabilities of our neural network and gives it additional power. ReLUIs a mathematical function that looks like this: The function
ReLUreturns 0 if the input value was a negative value or zero, in all other cases the function will return the original input value. ReLUmakes it possible to solve nonlinear problems. Converting degrees Celsius to degrees Fahrenheit is a linear task because the expression
f = 1.8*c + 32is an equation of the line - y = m*x + b. But most of the tasks that we want to solve are non-linear. In such cases, adding the ReLU activation function to our fully connected layer can help with this kind of task.ReLUjust one kind of activation function. There are activation functions such as sigmoid, ReLU, ELU, tanh, however it is ReLUmost often used as the default activation function. To build and use models that include ReLU, you don’t need to understand how it works internally. If you still want to understand better, then we recommend this article . Let's go over the new terms introduced in this lesson:
- Smoothing - the process of converting a 2D image into a 1D vector;
- ReLU is an activation function that allows the model to solve non-linear problems;
- Softmax - a function that calculates the probabilities for each possible output class;
- Classification - a class of machine learning tasks used to determine the differences between two or more categories (classes).
Training and testing
When training a model, any model in machine learning, it is always necessary to divide the data set into at least two different sets - the data set used for training and the data set used for testing. In this part we will understand why it is worth doing this.
Let's remember how we distributed our data set from Fashion MNIST consisting of 70,000 copies.
We proposed dividing 70,000 into two parts - in the first part, leave 60,000 for training, and in the second part 10,000 for testing. The necessity of this approach is caused by the following fact: after the model has been trained on 60,000 copies, it is necessary to check the results and the effectiveness of its work on examples that were not yet in the data set on which the model was trained.
In its own way, it resembles passing an exam at school. Before you pass the exam, you are diligently engaged in solving problems of a particular class. Then, in the exam, you come across the same class of problems, but with different input data. It makes no sense to submit the same data that was during the training, otherwise the task will be reduced to remembering decisions, and not searching for a solution model. That is why at exams you are faced with tasks that were not previously in the curriculum. Only in this way can we verify whether the model has learned the general solution or not.
The same thing happens with machine learning. You show some data that represents a certain class of tasks that you want to learn how to solve. In our case, with a data set from Fashion MNIST, we want the neural network to be able to determine the category to which the clothing element in the image belongs. That is why we train our model on 60,000 examples that contain all categories of clothing items. After training, we want to check the effectiveness of the model, so we feed the remaining 10,000 items of clothing that the model has not yet “seen”. If we decided not to do this, not to test with 10,000 examples, we would not be able to say with certainty whether our model was actually trained to determine the class of the clothing item or if she remembered all the pairs of input + output values.
That is why in machine learning we always have a dataset for training and a dataset for testing.
TensorFlow is a collection of ready-to-use training data.
Data sets are usually divided into several blocks, each of which is used at a certain stage of training and testing the effectiveness of the neural network. In this part we talk about:
- training data set : a data set intended for training a neural network;
- test data set : a data set designed to verify the efficiency of a neural network;
Consider another dataset, which I call a validation dataset. This data set is not used to train the model, only during training. So, after our model has gone through several training cycles, we feed it our test data set and look at the results. For example, if during training the value of the loss function decreases, and the accuracy deteriorates on the test data set, this means that our model simply simply remembers pairs of input-output values.
The verification data set is reused at the very end of the training to measure the final accuracy of the model predictions.
You can read more about training and test data sets at the Google Crash Course..
Practical part in CoLab
Link to the original CoLab in English and a link to Russian CoLab .
Classification of images of clothing items
In this part of the lesson, we will build and train a neural network to classify images of clothing elements, such as dresses, sneakers, shirts, t-shirts, etc.
It’s all right if some moments are not clear. The purpose of this course is to introduce you to TensorFlow and at the same time explain the algorithms of its work and develop a common understanding of projects using TensorFlow, rather than delving into the implementation details.
In this part, we use
tf.kerasa high-level API for building and training models in TensorFlow.Installing and importing dependencies
We will need a TensorFlow dataset , an API that simplifies loading and accessing datasets provided by several services. We will also need some auxiliary libraries.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
# импортируем TensorFlow и набор данных TensorFlow
import tensorflow as tf
import tensorflow_datasets as tfds
tf.logging.set_verbosity(tf.logging.ERROR)
# вспомогательные библиотеки
import math
import numpy as np
import matplotlib.pyplot as plt
# Улучшим отображение прогрессбара
import tqdm
import tqdm.auto
tqdm.tqdm = tqdm.auto.tqdm
print(tf.__version__)
tf.enable_eager_execution()
Import the Fashion MNIST dataset
This example uses the Fashion MNIST dataset, which contains 70,000 images of clothing items in 10 categories in grayscale. Images contain clothing items in low resolution (28x28 pixels), as shown below:
Fashion MNIST is used as a replacement for the classic MNIST dataset - most often used as “Hello, World!” in machine learning and computer vision. The MNIST dataset contains images of hand-written numbers (0, 1, 2, etc.) in the same format as the clothing items in our example.
In our example, we use Fashion MNIST because of the variety and because this task is more interesting from the point of view of implementation than solving a typical problem on the MNIST data set. Both data sets are small enough, therefore, they are used to check the correct operability of the algorithm. Great datasets for starting learning machine learning, testing, and debugging code.
We will use 60,000 images to train the network and 10,000 images to test the accuracy of training and image classification. You can directly access the Fashion MNIST dataset through TensorFlow using the API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
By loading a data set we get metadata, a training data set and a test data set.
- The model is trained on a dataset from `train_dataset`
- The model is tested on a dataset from `test_dataset`
Images are two-dimensional arrays
28х28where the values in each cell can be in the range [0, 255]. Labels is an array of integers where each value is in the range [0, 9]. These labels correspond to the output image class as follows:| Label | Class |
|---|---|
| 0 | T-shirt / top |
| 1 | Shorts |
| 2 | Pullover |
| 3 | Dress |
| 4 | Cloak |
| 5 | Sandals |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | A bag |
| 9 | Boot |
Each image belongs to one tag. Since the class names are not contained in the original data set, let's save them for future use when we draw the images:
class_names = ['Футболка / топ', "Шорты", "Свитер", "Платье",
"Плащ", "Сандали", "Рубашка", "Кроссовок", "Сумка",
"Ботинок"]
We research data
Let's study the format and structure of the data presented in the training set before training the model. The following code will show that 60,000 images are in the training dataset, and 10,000 images are in the test dataset:
num_train_examples = metadata.splits['train'].num_examples
num_test_examples = metadata.splits['test'].num_examples
print('Количество тренировочных экземпляров: {}'.format(num_train_examples))
print('Количество тестовых экземпляров: {}'.format(num_test_examples))
Data preprocessing
The value of each pixel in the image is in the range
[0,255]. In order for the model to work correctly, these values must be normalized - reduced to values in the interval [0,1]. Therefore, a little lower, we declare and implement the normalization function, and then apply it to each image in the training and test data sets.def normalize(images, labels):
images = tf.cast(images, tf.float32)
images /= 255
return images, labels
# метод map применяет функцию нормализации к каждому элементу в массиве
# тестовых и тренировочных наборах данных
train_dataset = train_dataset.map(normalize)
test_dataset = test_dataset.map(normalize)
We study the processed data
Let's draw an image to take a look at it:
# Берём единственное изображение и удаляем из него цветовую составляющую
# посредством метода reshape()
for image, label in test_dataset.take(1):
break;
image = image.numpy().reshape((28, 28))
# отрисовываем изображение
plt.figure()
plt.imshow(image, cmap=plt.cm.binary)
plt.colorbar()
plt.grid(False)
plt.show()
We display the first 25 images from the training data set and under each image we indicate which class it belongs to.
Make sure that the data is in the correct format and we are ready to start creating and training the network.
plt.figure(figsize=(10,10))
i = 0
for (image, label) in test_dataset.take(25):
image = image.numpy().reshape((28,28))
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(image, cmap=plt.cm.binary)
plt.xlabel(class_names[label])
i += 1
plt.show()
Building a model
Building a neural network requires tuning layers, and then assembling a model with optimization and loss functions.
Customize layers
The basic element in building a neural network is the layer. The layer extracts the view from the data that came into its input. The result of the work of several layers connected, we get a view that makes sense to solve the problem.
Most of the time doing deep learning you will be creating links between simple layers. Most layers, for example, such as tf.keras.layers.Dense, have a set of parameters that can be “fitted” during the learning process.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
The network consists of three layers:
- input
tf.keras.layers.Flatten- this layer converts images 28x28 pixels in size into a 1D-array with a size of 784 (28 * 28). On this layer, we have no parameters for training, since this layer only deals with the conversion of input data. - скрытый слой
tf.keras.layers.Dense— плотносвязный слой из 128 нейронов. Каждый нейрон (узел) принимает на вход все 784 значения с предыдущего слоя, изменяет входные значения согласно внутренним весам и смещениям во время тренировки и возвращает единственное значение на следующий слой. - выходной слой
ts.keras.layers.Dense—softmax-слой состоит из 10 нейронов, каждый из которых представляет определённый класс элемента одежды. Как и в предыдущем слое, каждый нейрон принимает на вход значения всех 128 нейронов предыдущего слоя. Веса и смещения каждого нейрона на этом слое изменяются при обучении таким образом, чтобы результатирующее значение было в интервале[0,1]и представляло собой вероятность того, что изображение относится к этому классу. Сумма всех выходных значений 10 нейронов равна 1.
Компилируем модель
Before we start training the model, it’s worth a few more settings. These settings are made during model assembly when the compile method is called:
- loss function - an algorithm for measuring how far the desired value is from the predicted.
- optimization function - an algorithm for “fitting” the internal parameters (weights and offsets) of the model to minimize the loss function;
- metrics - used to monitor the training process and testing. The example below uses metrics such as the
точностьpercentage of images that have been correctly classified.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
We train the model
Firstly, we determine the sequence of actions during training on a training data set:
- Repeat the set of input data an infinite number of times using the method
dataset.repeat()(the parameterepochsdescribed below determines the number of all training iterations to be performed) - The method
dataset.shuffle(60000)shuffles all images so that the training of our model is not affected by the order of input data input. - The method
dataset.batch(32)tells the training method tomodel.fituse blocks of 32 images and labels when updating the internal variables of the model.
Training takes place by calling the method
model.fit:- Sends
train_datasetthe model to the input. - The model learns to match the input image with the label.
- The parameter
epochs=5limits the number of training sessions to 5 complete training iterations on a data set, which ultimately gives us training on 5 * 60,000 = 300,000 examples.
(
steps_per_epochyou can ignore the parameter, soon this parameter will be excluded from the method).BATCH_SIZE = 32
train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
And here is the conclusion: During the training of the model, the value of the loss function and the accuracy metric are displayed for each training iteration. This model achieves an accuracy of about 0.88 (88%) on training data.
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
Check accuracy
Let's check what accuracy the model produces on test data. We will use all the examples that we have in the test data set for checking accuracy.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE))
print("Точность на тестовом наборе данных: ", test_accuracy)
Conclusion: As you can see, the accuracy on the test data set turned out to be less than the accuracy on the training data set. This is quite normal since the model was trained on train_dataset data. When a model discovers images that it has never seen before (from the train_dataset dataset), it is obvious that the classification efficiency will decrease.
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
Точность на тестовом наборе данных: 0.8793
Predict and explore
We can use the trained model to obtain predictions for some images.
for test_images, test_labels in test_dataset.take(1):
test_images = test_images.numpy()
test_labels = test_labels.numpy()
predictions = model.predict(test_images)
predictions.shape
Conclusion: In the example above, the model predicted labels for each test input image. Let's look at the first prediction:
(32, 10)
predictions[0]
Conclusion:
array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05,
6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09,
8.4999456e-06, 1.0296091e-09], dtype=float32)
Recall that model predictions are an array of 10 values. These values describe the “confidence” of the model that the input image belongs to a certain class (clothing item). We can see the maximum value as follows:
np.argmax(predictions[0])
Conclusion:
6
This means that the model was most confident that this image belongs to the class labeled 6 (class_names [6]). We can check and make sure that the result is true and that it is correct:
test_labels[0]
6
We can display all input images and the corresponding model predictions for 10 classes:
def plot_image(i, predictions_array, true_labels, images):
predictions_array, true_label, img = predictions_array[i], true_label[i], images[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img[...,0], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100 * np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
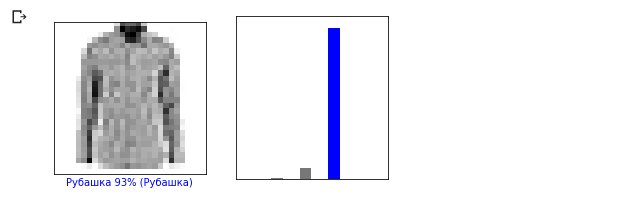
Let's take a look at the 0th image, the result of the prediction of the model and the array of predictions.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
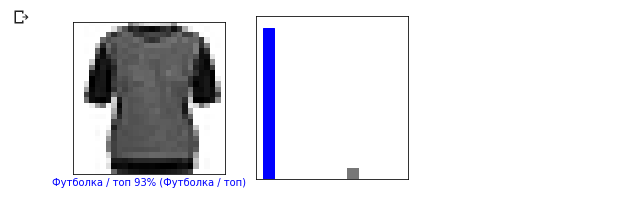
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
Let's now display some images with their respective predictions. Correct predictions are blue, incorrect predictions are red. The value below the image reflects the percentage of confidence that the input image corresponds to this class. Please note that the result may be incorrect even if the value of “confidence” is high.
num_rows = 5
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i + 1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i + 2)
plot_value_array(i, predictions, test_labels)
Use the trained model to predict the label for a single image:
img = test_images[0]
print(img.shape)
Conclusion:
(28, 28, 1)
Models in are
tf.kerasoptimized for predictions by blocks (collections). Therefore, despite the fact that we use a single element, you need to add it to the list:img = np.array([img])
print(img.shape)
Conclusion:
(1, 28, 28, 1)Now we will predict the result:
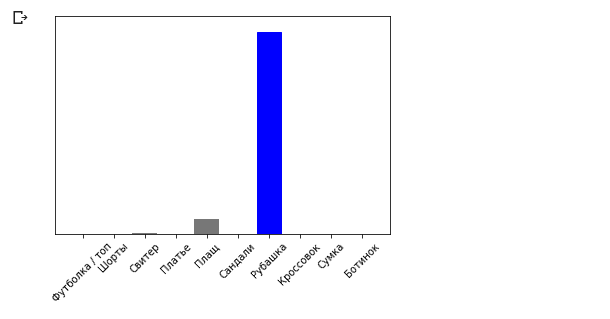
predictions_single = model.predict(img)
print(predictions_single)
Conclusion:
[[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02
1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
The model.predict method returns a list of lists (an array of arrays), each for an image from an input block. We get the only result for our single input image:
np.argmax(predictions_single[0])
Conclusion:
6
As previously, the model predicted label 6 (shirt).
Exercises
Experiment with different models and see how accuracy will change. In particular, try changing the following settings:
- set the epochs parameter to 1;
- change the number of neurons in the hidden layer, for example, from a low value of 10 to 512 and see how the accuracy of the forecast model will change;
- add additional layers between the flatten-layer (smoothing layer) and the final dense-layer, experiment with the number of neurons on this layer;
- don't normalize the pixel values and see what happens.
Remember to activate the GPU so that all calculations are faster (
Runtime -> Change runtime type -> Hardware accelertor -> GPU). Also, if you encounter problems during the operation, try resetting the global environment settings:Edit -> Clear all outputsRuntime -> Reset all runtimes
Degrees Celsius VS MNIST
- At this stage, we have already encountered two types of neural networks. Our first neural network learned how to convert degrees Celsius to degrees Frenheit, returning a single value that can be in a wide range of numerical values.
Our second neural network returns 10 probability values that reflect the confidence of the network that the input image corresponds to a certain class.
Neural networks can be used to solve various problems.
The first class of problems that we solved with the prediction of a single value is called regression. Converting degrees Celsius to degrees Fahrenheit is one example of the task of this class. Another example of this class of tasks may be the task of determining the value of a house by the number of rooms, total area, location and other characteristics.
The second class of tasks that we examined in this lesson classifying images into available categories is called classification . According to the input data, the model will return the probability distribution (the “confidence” of the model that the input value belongs to this class). In this lesson, we developed a neural network that classified clothing elements into 10 categories, and in the next lesson, we will learn to determine who is shown in the photograph - a dog or a cat, this task also belongs to the classification task.
Let's summarize and note the difference between these two classes of problems - regression and classification .
Congratulations, you have studied two types of neural networks! Get ready for the next lecture, there we will study a new type of neural networks - convolutional neural networks (CNN).
Summary
In this lesson, we trained the neural network to classify images with elements of clothing. To do this, we used the Fashion MNIST dataset, which contains 70,000 images of clothing items. 60,000 of which we used to train the neural network, and the remaining 10,000 to test the effectiveness of its work. In order to submit these images to the input of our neural network, we needed to convert (smooth) them from a 28x28 2D format to a 1D format of 784 elements. Our network consisted of a fully connected layer of 128 neurons and an output layer of 10 neurons, corresponding to the number of labels (classes, categories of clothing items). These 10 output values represented the probability distribution for each class. Softmax activation functioncounted the probability distribution.
We also learned about the differences between regression and classification .
- Regression : A model that returns a single value, such as the value of a home.
- Classification : A model that returns the probability distribution between several categories. For example, in our task with Fashion MNIST, the output values were 10 probability values, each of which was associated with a particular class (category of clothing item). I remind you that we used the softmax activation function just to get a probability distribution on the last layer.
Video version of the article
The video comes out a few days after publication and is added to the article.
... and standard call-to-action - sign up, put plus and share :)
YouTube
Telegram
VKontakte