Error Handling in Go
- Transfer
Hello, Habrovsk citizens! The Golang Developer course is already starting at OTUS today , and we consider this an excellent occasion to share another useful post on the topic. Today let's talk about Go's approach to errors. Let's get started!


This post is part of the Before Getting Started series , where we explore the world of Golang, share tips and ideas you should know when writing code in Go so you don't have to fill in your own bumps.
I assume that you already have at least basic experience with Go, but if you feel that at some point you came across an unfamiliar discussion material, do not hesitate to pause, explore the topic and come back.
Now that we have cleared our way, let's go!
Go's approach to error handling is one of the most controversial and misused features. In this article, you will learn Go's approach to errors, and understand how they work “under the hood.” You will learn a few different approaches, review the Go source code and the standard library to find out how errors are handled and how to work with them. You will learn why Type Assertions play an important role in handling them, and you will see upcoming changes to error handling that you plan to introduce in Go 2.

First things first: errors in Go are no exception. Dave Cheney wrote an epic blog post about this, so I refer you to it and summarize: in other languages you cannot be sure if a function can throw an exception or not. Instead of throwing exceptions, Go functions support multiple return values , and by convention this feature is usually used to return the result of a function along with an error variable.

If for some reason your function may fail, you should probably return the previously declared

(3 // error handling
5 // continued)
These snippets are very common in Go, and some consider them as boilerplate code. The compiler treats unused variables as compilation errors, so if you are not going to check for errors, you must assign themempty identifier . But no matter how convenient it may be, errors should not be ignored.
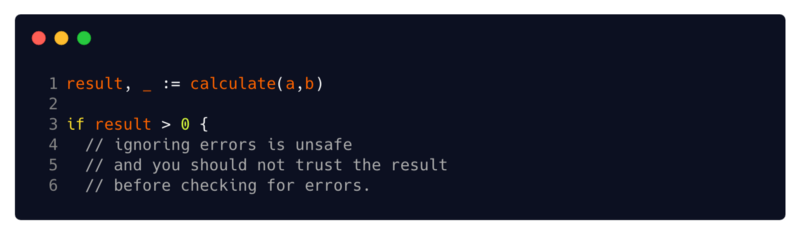
(4 // ignoring errors is unsafe, and you should not rely on the result before checking for errors) the
result cannot be trusted until checking for errors
Returning an error along with the results, along with the strict Go type system, greatly complicates the writing of the code that was tagged. You should always assume that the value of a function is corrupted, unless you have checked the error it returned, and by assigning the error to an empty identifier, you explicitly ignore that the value of your function may be corrupted.

The empty id is dark and full of horrors.
We do have Go
Error Interface
Under the hood, the error type is a simple interface with one method , and if you are not familiar with it, I highly recommend that you check out this post on the official Go blog.

the error interface from the source code
It is not difficult to implement your own errors. There are various approaches to user structures that implement a method
Let's look at a few of these approaches.
The most commonly used and widespread implementation of the error interface is the built-in structure
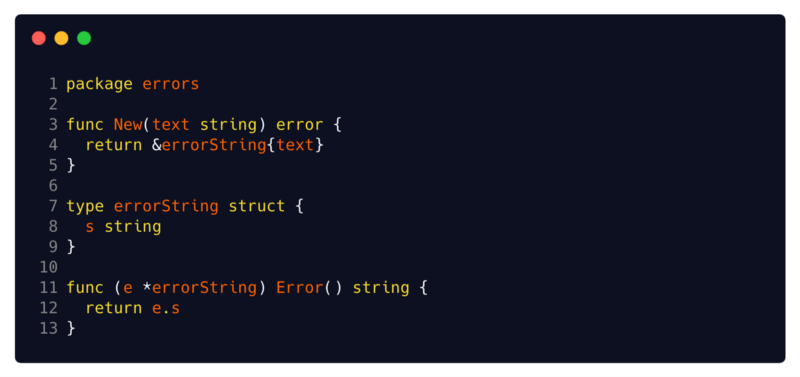
Source: Go source code.
You can see its simplified implementation here . All that she does is contain
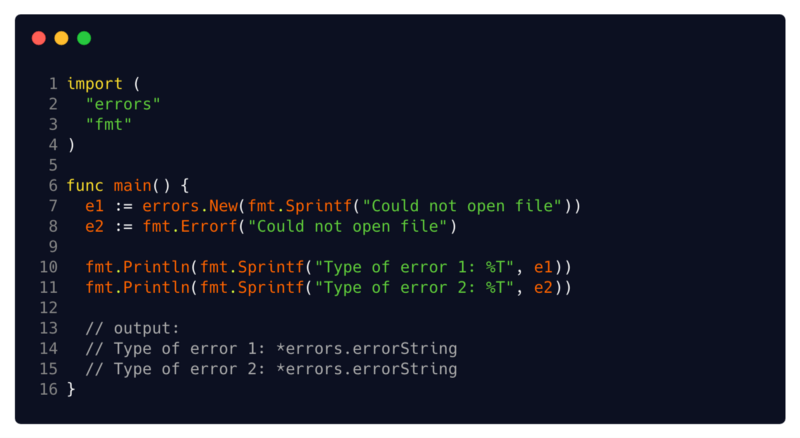
(13 // output :)
try
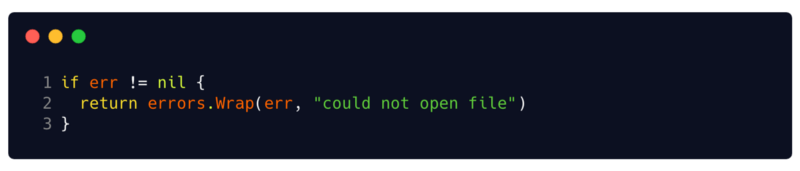
Another simple example is the pkg / errors package . Not to be confused with the built-in package

In cases where you need to attach a stack trace or necessary debugging information to your errors, using functions
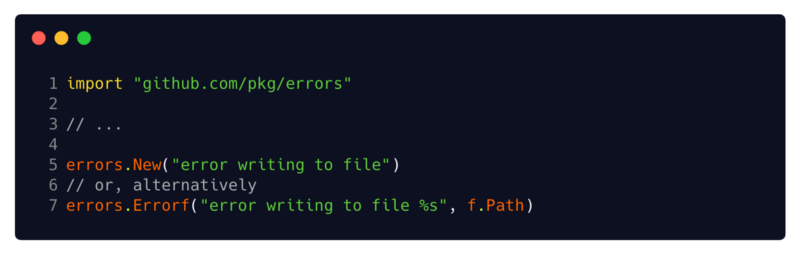
(// 6 or alternative)
This package also represents functions
Error wrappers by other errors support a
Type assertions play an important role when dealing with errors. You will use them to extract information from the interface value, and since error handling is associated with user interface
Its syntax is the same for all its purposes -
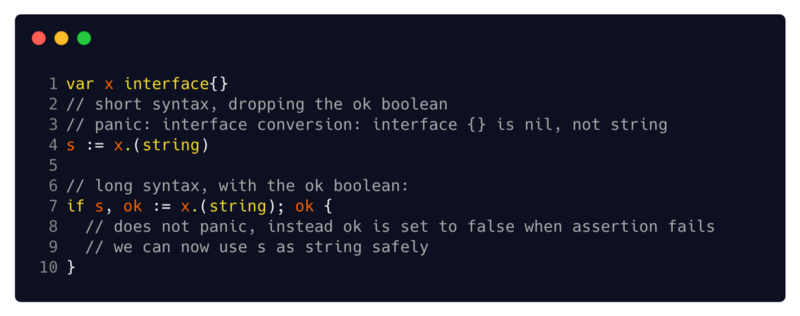
(2 // shorthand syntax skipping the boolean variable ok
3 // panic: interface conversion: interface {} is nil, not string
6 // extended syntax with the logical variable ok
8 // does not panic, instead sets ok false when the statement is false
9 // now we can safely use s as a string)
sandbox: panic with shortened syntax , safe elongated syntax
Performing a type statement

(5 ... // we claim that x implements the resolver interface
6 ... // here we can already safely use this method)
To understand how this can be used, let's take a look at
This function receives an error and extracts the innermost error that it suffers (the one that no longer serves as a wrapper for another error). This may seem primitive, but there are many wonderful things you can learn from this implementation:

source: pkg / errors
The function receives the error value, and it cannot assume that the
By creating a simple local interface containing only those methods that you need, and applying assertion on it, your code is separated from other dependencies. The argument you received does not have to be a known structure, it just has to be a mistake. Any type that implements methods
However, there is one small flaw to keep in mind: the interfaces are subject to change, so you should carefully maintain the code so that your statements are not violated. Do not forget to define your interfaces where you use them, to keep them slim and neat, and you will be fine.
Finally, if you need only one method is sometimes more convenient to make a statement on an anonymous interface containing only method to which you rely, t. E.
I preface this section by introducing two similar error handling patterns that suffer from several flaws and traps. This does not mean that they are not common. Both of them can be convenient tools in small projects, but they do not scale well.
The first is the second version of a type statement: a type statement

(2 // we can use v as mypkg.SomeErrorType) The
other is the Type Switch pattern . Type Switch combines a switch statement with a type statement using a reserved keyword

(3 // processing ...
5 // processing ...) The
big drawback of both approaches is that both of them lead to code binding with their dependencies. Both examples should be familiar with the structure
In both approaches, when handling your errors, you should be familiar with the type and import its package. The situation is aggravated when you deal with errors in wrappers, where the cause of the error may be an error arising from an internal dependency that you do not know and should not know about.

(7 // processing ...
9 // processing ...)
Type Switch distinguish between

That's all! You are now familiar with the errors and should be prepared to fix any errors that your Go application may throw (or actually return) to your path!
Both packages
When you scale simple errors, the correct use of type statements can be a great tool for handling various errors. Either using Type Switch, or by validating the behavior of the error and checking the interfaces that it implements.
Error handling in Go is now very relevant. Now that you've got the basics, you might be wondering what lies ahead for us to handle Go errors!
The next version of Go 2 pays a lot of attention to this, and you can already take a look at the draft version . In addition, during dotGo 2019, Marcel van Lojuizen had an excellent conversation on a topic that I just cannot but recommend - “GO 2 error values today” .
Obviously, there are many more approaches, tips and tricks, and I can not include them all in one post! Despite this, I hope you enjoyed it, and I will see you in the next episode of the Before You Go !
And now traditionally waiting for your comments.
Mastering the pragmatic error handling in your Go code
This post is part of the Before Getting Started series , where we explore the world of Golang, share tips and ideas you should know when writing code in Go so you don't have to fill in your own bumps.
I assume that you already have at least basic experience with Go, but if you feel that at some point you came across an unfamiliar discussion material, do not hesitate to pause, explore the topic and come back.
Now that we have cleared our way, let's go!
Go's approach to error handling is one of the most controversial and misused features. In this article, you will learn Go's approach to errors, and understand how they work “under the hood.” You will learn a few different approaches, review the Go source code and the standard library to find out how errors are handled and how to work with them. You will learn why Type Assertions play an important role in handling them, and you will see upcoming changes to error handling that you plan to introduce in Go 2.
Introduction
First things first: errors in Go are no exception. Dave Cheney wrote an epic blog post about this, so I refer you to it and summarize: in other languages you cannot be sure if a function can throw an exception or not. Instead of throwing exceptions, Go functions support multiple return values , and by convention this feature is usually used to return the result of a function along with an error variable.
If for some reason your function may fail, you should probably return the previously declared
error-a type. By convention, returning an error signals the caller about the problem, and returning nil is not considered an error. Thus, you will make the caller understand that a problem has arisen, and he needs to deal with it: whoever calls your function, he knows that he should not rely on the result before checking for an error. If the error is not nil, he is obliged to check it and process it (log, return, service, call some kind of retry / cleanup mechanism, etc.). (3 // error handling
5 // continued)
These snippets are very common in Go, and some consider them as boilerplate code. The compiler treats unused variables as compilation errors, so if you are not going to check for errors, you must assign themempty identifier . But no matter how convenient it may be, errors should not be ignored.
(4 // ignoring errors is unsafe, and you should not rely on the result before checking for errors) the
result cannot be trusted until checking for errors
Returning an error along with the results, along with the strict Go type system, greatly complicates the writing of the code that was tagged. You should always assume that the value of a function is corrupted, unless you have checked the error it returned, and by assigning the error to an empty identifier, you explicitly ignore that the value of your function may be corrupted.
The empty id is dark and full of horrors.
We do have Go
panicand recovermechanisms, which are also described inanother detailed Go blog post . But they are not intended to simulate exceptions. According to Dave, “When you panic in Go, you really panic: this is not someone else’s problem, this is already a gamer.” They are fatal and lead to a crash in your program. Rob Pike came up with the saying “Don't panic,” which speaks for itself: you should probably avoid these mechanisms and return errors instead.“Errors are the meanings.”
“Don't just check for errors, but handle them elegantly.”
“Don't panic”
all Rob Pike’s sayings
Under the hood
Error Interface
Under the hood, the error type is a simple interface with one method , and if you are not familiar with it, I highly recommend that you check out this post on the official Go blog.
the error interface from the source code
It is not difficult to implement your own errors. There are various approaches to user structures that implement a method
Error()string . Any structure that implements this single method is considered a valid error value and can be returned as such. Let's look at a few of these approaches.
Built-in errorString structure
The most commonly used and widespread implementation of the error interface is the built-in structure
errorString . This is the easiest implementation you can think of. Source: Go source code.
You can see its simplified implementation here . All that she does is contain
string, and this string is returned by the method Error. This string error can be formatted by us on the basis of some data, say, with fmt.Sprintf. But other than this, it does not contain any other features. If you applied errors.New or fmt.Errorf , then you have already used it . (13 // output :)
try
github.com/pkg/errors
Another simple example is the pkg / errors package . Not to be confused with the built-in package
errorsthat you learned about earlier, this package provides additional important features, such as error wrapping, expanding, formatting, and stack trace recording. You can install the package by running go get github.com/pkg/errors. In cases where you need to attach a stack trace or necessary debugging information to your errors, using functions
Newor Errorfthis package provides errors that are already written to your stack trace, and you can also attach simple metadata using its formatting capabilities . Errorfimplements the fmt.Formatter interface , that is, you can format it using the runes of the package fmt( %s,%v, %+v etc.). (// 6 or alternative)
This package also represents functions
errors.Wrapand errors.Wrapf. These functions add context to the error using a message and a stack trace in the place where they were called. Thus, instead of simply returning the error, you can wrap it with context and important debugging data. Error wrappers by other errors support a
Cause() errormethod that returns their internal error. In addition, they can be used by a сerrors.Cause(err error) errorfunction that retrieves the main internal error in the wrapping error.Error handling
Type approval
Type assertions play an important role when dealing with errors. You will use them to extract information from the interface value, and since error handling is associated with user interface
errorimplementations, the implementation of error statements is a very convenient tool. Its syntax is the same for all its purposes -
x.(T)if it xhas an interface type. x.(T)claims to be xnot equal niland that the value stored in xis of type T. In the next few sections, we will look at two ways to use type statements - with a specific type Tand with a type interface T. (2 // shorthand syntax skipping the boolean variable ok
3 // panic: interface conversion: interface {} is nil, not string
6 // extended syntax with the logical variable ok
8 // does not panic, instead sets ok false when the statement is false
9 // now we can safely use s as a string)
sandbox: panic with shortened syntax , safe elongated syntax
Additional syntax note: a type assertion can be used with either a shortened syntax (which panics when a statement fails) or an extended syntax (which uses the logical value OK to indicate success or failure). I always recommend taking elongated instead of shortened, since I prefer to check the OK variable, and not deal with panic.
Type T Approval
Performing a type statement
x.(T)with a type interface Tconfirms that it ximplements the interface T. Thus, you can guarantee that the interface value implements the interface, and only if so, you can use its methods. (5 ... // we claim that x implements the resolver interface
6 ... // here we can already safely use this method)
To understand how this can be used, let's take a look at
pkg/errors. You already know this error package, so let's delve into the errors.Cause(err error) errorfunction.This function receives an error and extracts the innermost error that it suffers (the one that no longer serves as a wrapper for another error). This may seem primitive, but there are many wonderful things you can learn from this implementation:
source: pkg / errors
The function receives the error value, and it cannot assume that the
errargument it receives is a wrapper error (supported Causeby the method). Therefore, before calling the method, Causeyou need to make sure that you are dealing with an error that implements this method. By executing a type statement in each iteration of the for loop, you can verify that the causevariable supports the methodCause, and can continue to extract internal errors from it until you find an error that does not Cause. By creating a simple local interface containing only those methods that you need, and applying assertion on it, your code is separated from other dependencies. The argument you received does not have to be a known structure, it just has to be a mistake. Any type that implements methods
Errorand Causeis suitable. Thus, if you implement a Causemethod in your type of error, you can use this function with it without slowdowns.However, there is one small flaw to keep in mind: the interfaces are subject to change, so you should carefully maintain the code so that your statements are not violated. Do not forget to define your interfaces where you use them, to keep them slim and neat, and you will be fine.
Finally, if you need only one method is sometimes more convenient to make a statement on an anonymous interface containing only method to which you rely, t. E.
v, ok := x.(interface{ F() (int, error) }). Using anonymous interfaces can help separate your code from possible dependencies and protect it from possible changes in the interfaces.Type T and Type Switch Approval
I preface this section by introducing two similar error handling patterns that suffer from several flaws and traps. This does not mean that they are not common. Both of them can be convenient tools in small projects, but they do not scale well.
The first is the second version of a type statement: a type statement
x.(T)with a specific type is executed T. He claims that a value xhas a type T, or it can be converted to a type T. (2 // we can use v as mypkg.SomeErrorType) The
other is the Type Switch pattern . Type Switch combines a switch statement with a type statement using a reserved keyword
type. They are especially common in error handling, where knowing the basic type of a variable error can be very useful. (3 // processing ...
5 // processing ...) The
big drawback of both approaches is that both of them lead to code binding with their dependencies. Both examples should be familiar with the structure
SomeErrorType(which obviously should be exported) and should import the package mypkg. In both approaches, when handling your errors, you should be familiar with the type and import its package. The situation is aggravated when you deal with errors in wrappers, where the cause of the error may be an error arising from an internal dependency that you do not know and should not know about.
(7 // processing ...
9 // processing ...)
Type Switch distinguish between
*MyStructand MyStruct. Therefore, if you are not sure whether you are dealing with a pointer or an actual instance of a structure, you will have to provide both options. Moreover, as in the case of regular switches, the cases in Type Switch do not fail, but unlike the usual Type Switch, use is fallthroughprohibited in Type Switch, so you have to use a comma and provide both options, which is easy to forget.To summarize
That's all! You are now familiar with the errors and should be prepared to fix any errors that your Go application may throw (or actually return) to your path!
Both packages
errorsprovide simple but important approaches to bugs in Go, and if they suit your needs, they are a great choice. You can easily implement your own error structures and take advantage of Go error handling by combining them with pkg/errors. When you scale simple errors, the correct use of type statements can be a great tool for handling various errors. Either using Type Switch, or by validating the behavior of the error and checking the interfaces that it implements.
What's next?
Error handling in Go is now very relevant. Now that you've got the basics, you might be wondering what lies ahead for us to handle Go errors!
The next version of Go 2 pays a lot of attention to this, and you can already take a look at the draft version . In addition, during dotGo 2019, Marcel van Lojuizen had an excellent conversation on a topic that I just cannot but recommend - “GO 2 error values today” .
Obviously, there are many more approaches, tips and tricks, and I can not include them all in one post! Despite this, I hope you enjoyed it, and I will see you in the next episode of the Before You Go !
And now traditionally waiting for your comments.