What you need to know before moving to Akka toolkit to implement Event Sourcing and CQRS
Hello, dear readers of Habr. My name is Rustem and I am the main developer at the Kazakhstani IT company DAR. In this article I will tell you what you need to know before moving on to Event Sourcing and CQRS templates using the Akka toolkit.
Around 2015, we began to design our ecosystem. After analysis and based on experience with Scala and Akka, we decided to stop at the Akka toolkit. We had successful implementations of Event Sourcing templates with CQRS and not so. The accumulation of expertise in this area, which I want to share with readers. We will look at how Akka implements these patterns, as well as what tools are available and talk about Akka pitfalls. I hope that after reading this article, you will have more understanding of the risks of switching to Akka toolkit.
On subjects of CQRS and Event Sourcing many articles on Habré and on other resources were written. This article is intended for readers who already understand what CQRS and Event Sourcing are. In the article I want to concentrate on Akka.
Domain driven design
A lot of material has been written about Domain-Driven Design (DDD). There are both opponents and supporters of this approach. I want to add on my own that if you decide to switch to Event Sourcing and CQRS, then it will not be superfluous to study DDD. In addition, the DDD philosophy is felt in all Akka tools.
In fact, Event Sourcing and CQRS are just a small part of the big picture called Domain-Driven Design. When designing and developing, you may have many questions about how to properly implement these templates and integrate into the ecosystem, and knowing DDD will make your life easier.
In this article, the term entity (entity by DDD) will mean a Persistence Actor that has a unique identifier.
Why Scala?
We are often asked why Scala, and not Java. One reason is Akka. The framework itself, written in the Scala language with support for the Java language. Here I must say that there is also an implementation on .NET , but this is another topic. In order not to cause a discussion, I will not write why Scala is better or worse than Java. I will just tell you a couple of examples that, in my opinion, Scala has an advantage over Java when working with Akka:
- Immutable objects. In Java, you need to write immutable objects yourself. Believe me, it’s not easy and not very convenient to constantly write the final parameters. Scala is
case classalready immutable with a built-in functioncopy - Coding style. When implemented in Java, you will still write in the Scala style, that is, functionally.
Here is an example implementation of actor in Scala and Java:
Scala:
object DemoActor {
def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber))
}
class DemoActor(magicNumber: Int) extends Actor {
def receive = {
case x: Int => sender() ! (x + magicNumber)
}
}
class SomeOtherActor extends Actor {
context.actorOf(DemoActor.props(42), "demo")
// ...
}Java:
static class DemoActor extends AbstractActor {
static Props props(Integer magicNumber) {
return Props.create(DemoActor.class, () -> new DemoActor(magicNumber));
}
private final Integer magicNumber;
public DemoActor(Integer magicNumber) {
this.magicNumber = magicNumber;
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(
Integer.class,
i -> {
getSender().tell(i + magicNumber, getSelf());
})
.build();
}
}
static class SomeOtherActor extends AbstractActor {
ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
// ...
}(Example taken from here )
Pay attention to the implementation of the method createReceive()using the Java language as an example. Inside, through the factory ReceiveBuilder, pattern-matching is implemented. receiveBuilder()- a method from Akka to support lambda expressions, namely pattern-matching in Java. In Scala, this is implemented natively. Agree, the code in Scala is shorter and easier to read.
- Documentation and examples. Despite the fact that in the official documentation there are examples in Java, on the Internet, almost all examples are in Scala. Also, it will be easier for you to navigate in the sources of the Akka library.
In terms of performance, there will be no difference between Scala and Java, as everything revolves in the JVM.
Storage
Prior to implementing Event Sourcing with Akka Persistence, I recommend that you pre-select a database for permanent data storage. The choice of base depends on the requirements for the system, on your desires and preferences. Data can be stored both in NoSQL and RDBMS, and in a file system, for example LevelDB from Google .
It is important to note that Akka Persistence is not responsible for writing and reading data from the database, but does it through a plug-in that should implement the Akka Persistence API.
After choosing a tool for storing data, you need to select a plugin from the list, or write it yourself. The second option, I do not recommend why reinvent the wheel.
For permanent data storage, we decided to stay at Cassandra. The fact is that we needed a reliable, fast and distributed base. In addition, Typesafe themselves accompany the plugin , which fully implements the Akka Persistence API . It is constantly updated and in comparison with others, the Cassandra plugin has written more complete documentation.
It is worth mentioning that the plugin also has several problems. For example, there is still no stable version (at the time of this writing, the latest version is 0.97). For us, the biggest nuisance we encountered while using this plugin was the loss of events when reading Persistent Query for some entities. For a complete picture, below is the CQRS chart:
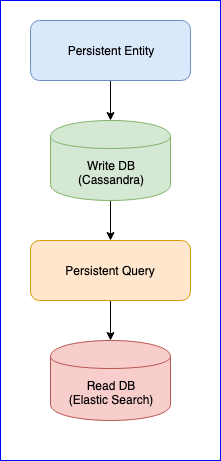
Persistent Entity distributes entity events into tags using the consistent hash algorithm (for example, 10 shards):
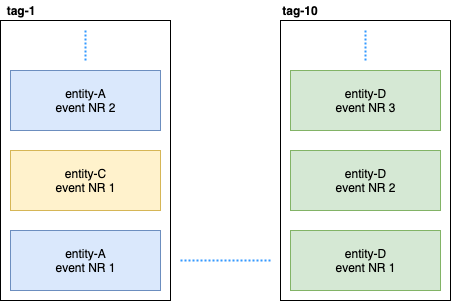
Then, Persistent Query subscribes to these tags and launches a stream that adds data to Elastic Search. Since Cassandra is in a cluster, events will be scattered across nodes. Some nodes can sag and will respond more slowly than others. There is no guarantee that you will receive events in strict order. To solve this problem, the plugin is implemented so that if it receives an unordered event, for example entity-A event NR 2, then it waits for a certain time for the initial event and if it does not receive it, it simply ignores all events of this entity. Even about this, there were discussions on Gitter. If anyone is interested, you can read the correspondence between @kotdv and the developers of the plugin: Gitter
How can this misunderstanding be resolved:
- You need to update the plugin to the latest version. In recent versions, Typesafe developers have solved many problems related to Eventual Consistency. But, we are still waiting for a stable version
- More precise settings have been added for the component that is responsible for receiving events. You can try to increase the latency of unordered events for more reliable operation of the plugin: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Configure Cassandra as recommended by DataStax. Put garbage collector G1 and allocate as much memory as possible for Cassandra .
In the end, we solved the problem with the missing events, but now there is a stable data delay on the Persistence Query side (from five to ten seconds). It was decided to leave the approach for data that is used for analytics, and where speed is important, we manually publish events on the bus. The main thing is to choose the appropriate mechanism for processing or publishing data: at-least-once or at-most-once. A good description from Akka can be found here . It was important for us to maintain the consistency of data, and therefore, after successfully writing data to the database, we introduced a transition state that controls the successful publication of data on the bus. The following is sample code:
object SomeEntity {
sealed trait Event {
def uuid: String
}
/**
* Событие, которое отправляется на сохранение.
*/
case class DidSomething(uuid: String) extends Event
/**
* Индикатор, который указывает что последнее событие было опубликовано.
*/
case class LastEventPublished(uuid: String) extends Event
/**
* Контейнер, который хранит текущее состояние сущности.
* @param unpublishedEvents – хранит события, которые не опубликовались.
*/
case class State(unpublishedEvents: Seq[Event])
object State {
def updated(event: Event): State = event match {
case evt: DidSomething =>
copy(
unpublishedEvents = unpublishedEvents :+ evt
)
case evt: LastEventPublished =>
copy(
unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid)
)
}
}
}
class SomeEntity extends PersistentActor {
…
persist(newEvent) { evt =>
updateState(evt)
publishToEventBus(evt)
}
…
}If for some reason it was not possible to publish the event, then at the next start SomeEntity, it will know that the event DidSomethingdid not reach the bus and will try again to republish the data.
Serializer
Serialization is an equally important point in using Akka. He has an internal module - Akka Serialization . This module is used to serialize messages when exchanging them between actors and when storing them through the Persistence API. By default, Java serializer is used, but it is recommended to use another one. The problem is that the Java Serializer is slow and takes up a lot of space. There are two popular solutions - these are JSON and Protobuf. JSON, although slow, is easier to implement and maintain. If you need to minimize the cost of serialization and data storage, you can stop at Protobuf, but then the development process will go slower. In addition to the Domain Model, you will have to write another Data Model. Do not forget about data versioning. Be prepared to constantly write mapping between the Domain Model and the Data Model.
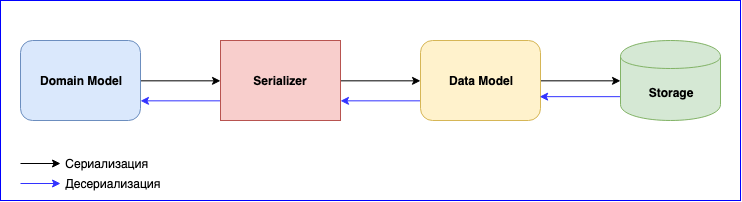
Added a new event - write mapping. Changed the data structure - write a new version of the Data Model and change the mapping function. Do not forget about tests for serializers. In general, there will be a lot of work, but in the end you will get loosely coupled components.
conclusions
- Carefully study and choose a suitable base and plugin for yourself. I recommend choosing a plugin that is well-maintained and will not stop developing. The area is relatively new, there are still a bunch of flaws that have yet to be resolved
- If you select distributed storage, you will have to solve the problem with a delay of up to 10 seconds yourself, or put up with it
- The complexity of serialization. You can sacrifice speed and stop on JSON, or choose Protobuf and write a lot of adapters and support them.
- There are pluses to this template, these are loosely coupled components and independent development teams that build one large system.