About the strange method of saving hard disk space
Another user wants to write a new piece of data to the hard disk, but he does not have enough free space for this. I don’t want to delete anything either, since "everything is very important and necessary." And what shall we do with it?
He has no such problem. Terabytes of information rest on our hard drives, and this amount does not tend to decrease. But how unique is it? In the end, after all, all files are just sets of bits of a certain length and, most likely, the new one is not much different from the one that is already stored.
It is clear that to search for already stored pieces of information on the hard drive is a task, if not a failure, then at least not an effective one. On the other hand, because if the difference is small, then you can fit a little ...

TL; DR - the second attempt to talk about a strange method of optimizing data using JPEG files, now in a more understandable form.
About bits and difference
If we take two completely random pieces of data, then on average half of the contained bits coincides in them. Indeed, among the possible layouts for each pair ('00, 01, 10, 11 '), exactly half have the same values, everything is simple here.
But of course, if we just take two files and fit one under the second, then we will lose one of them. If we keep the changes, then we simply reinvent the delta coding , which even without us perfectly exists, although it is not usually used for the same purpose. You can try to embed a smaller sequence into a larger one, but even so, we risk losing critical data segments when used rashly with everything.
Between what and what then can the difference be eliminated? Well, that is, a new file recorded by the user is just a sequence of bits with which we cannot do anything by itself. Then you just need to find such bits on the hard drive so that they can be changed without having to store the difference, so that you can survive their loss without serious consequences. Yes, and it makes sense to change not just the file itself on the FS, but some less sensitive information inside it. But which one and how?
Fit Methods
Lossy compressed files come to the rescue. All these jpeg, mp3 and others, although they are lossy compression, contain a bunch of bits available for safe change. You can use advanced techniques, discreetly modifying their components in various areas of coding. Wait. Advanced techniques ... inconspicuous modification ... some bits to others ... yes it's almost steganography !
Indeed, embedding one information in another resembles its methods. It also impresses the invisibility of the changes made to the human senses. That’s where the paths diverge - it’s in secrecy: our task is to add additional information to the user’s hard drive, it will only hurt him. Forget more.
Therefore, although we can use them, we need to make some modifications. And then I will tell and show them on the example of one of the existing methods and the common file format.
About the jackals
If you compress, then the most compressible in the world. We are, of course, talking about JPEG files. Not only is there a ton of tools and existing methods for embedding data in it, it is the most popular graphic format on this planet.

Nevertheless, in order not to engage in dog breeding, you need to limit your field of activity in files of this format. Nobody likes monochrome squares that arise due to excessive compression, so you need to limit yourself to working with an already compressed file, avoiding transcoding . More specifically, with integer coefficients that remain after the operations responsible for data loss - DCT and quantization, which is perfectly displayed on the encoding scheme (thanks to the wiki of the Bauman National Library):
There are many possible methods for optimizing jpeg files. There is lossless optimization (jpegtran), there is a lossless optimization , which actually still contribute, but they do not bother us. Indeed, if a user is ready to embed one information in another for the sake of increasing free disk space, then he either optimized his images for a long time or does not want to do this at all because of fear of loss of quality.
F5
Under such conditions, a whole family of algorithms is suitable, which can be found in this good presentation . The most advanced of them is the F5 algorithm, authored by Andreas Westfeld, working with the coefficients of the brightness component, since the human eye is the least sensitive to its changes. Moreover, he uses an embedding technique based on matrix coding, which allows one to make the less of their changes when embedding the same amount of information, the larger the size of the container used.
The changes themselves come down to a decrease in the absolute value of the coefficients per unit under certain conditions (that is, not always), which allows F5 to be used to optimize data storage on the hard drive. The fact is that the coefficient after such a change is likely to occupy a smaller number of bits after Huffman coding due to the statistical distribution of values in JPEG, and new zeros will benefit from encoding them using RLE.
The necessary modifications come down to eliminating the part responsible for secrecy (password permutation), which allows saving resources and execution time, and adding a mechanism for working with many files instead of one at a time. In more detail, the process of changing the reader is unlikely to be interesting, so we turn to the description of the implementation.
High tech
To demonstrate the work of this approach, I implemented the method in pure C and carried out a number of optimizations both in terms of speed and memory (you can’t imagine how much these pictures weigh without compression even before DCT). Cross-platform performance is achieved using a combination of the libjpeg , pcre, and tinydir libraries , for which I thank them. All this is going to be done by make, so Windows users want to install some kind of Cygwin for evaluation, or deal with Visual Studio and libraries on their own.
The implementation is available in the form of a console utility and a library. More information about using the latter can be found in the readme in the repository on the github, a link to which I will attach at the end of the post.
How to use?
Carefully. Images used for packaging are selected by regular expression search in the specified root directory. At the end of the file, you can move, rename and copy as desired within it, change the file and operating systems, etc. However, you should be extremely careful and not change the immediate contents. Loss of the value of even one bit can lead to the inability to restore information.
Upon completion of the work, the utility leaves a special archive file containing all the information necessary for unpacking, including data on the images used. By itself, it weighs on the order of a couple of kilobytes and does not have any significant impact on the occupied disk space.
You can analyze the possible capacity using the '-a' flag: './f5ar -a [search folder] [Perl-compatible regular expression]'. Packing is done with the command './f5ar -p [search folder] [Perl-compatible regular expression] [packed file] [archive name]', and unpacking with './f5ar -u [archive file] [name of the restored file]' .
Work demonstration
To show the effectiveness of the method, I downloaded a collection of 225 absolutely free photos of dogs from the Unsplash service and dug up a large pdf for 45 meters in the documents of the second volume of the Knut Programming Art .
The sequence is pretty simple:
$ du -sh knuth.pdf dogs/
44M knuth.pdf
633M dogs/
$ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar
Reading compressing file... ok
Initializing the archive... ok
Analysing library capacity... done in 17.0s
Detected somewhat guaranteed capacity of 48439359 bytes
Detected possible capacity of upto 102618787 bytes
Compressing... done in 39.4s
Saving the archive... ok
$ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf
Initializing the archive... ok
Reading the archive file... ok
Filling the archive with files... done in 1.4s
Decompressing... done in 21.0s
Writing extracted data... ok
$ sha1sum knuth.pdf knuth_unpacked.pdf
5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf
5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf
$ du -sh dogs/
551M dogs/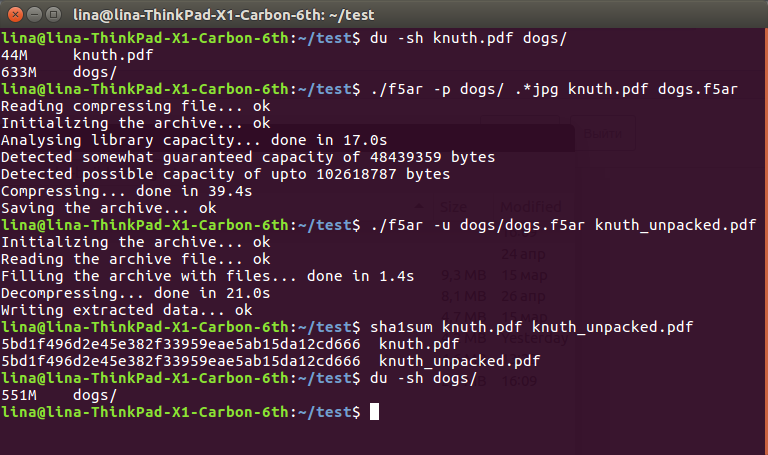
The unpacked file is still possible and should be read:

As you can see, from the original 633 + 36 == 669 megabytes of data on the hard drive, we came to a more pleasant 551. This radical difference is explained by the decrease in the coefficient values, which affect their subsequent compression without loss: a decrease of only one by one can calmly " cut "a couple of bytes from the resulting file. However, this is still data loss, albeit extremely small, that you have to put up with.
Fortunately, they are not completely visible to the eye. Under the spoiler (because habrastorage cannot handle large files), the reader can evaluate the difference both by eye and their intensity, obtained by subtracting the values of the changed component from the original: the original , with the information inside , the difference (the dimmer the color, the smaller the difference in the block )
Instead of a conclusion
Looking at all these difficulties, buying a hard drive or uploading everything to the cloud may seem like a much simpler solution to the problem. But even though we now live in such a wonderful time, there are no guarantees that tomorrow it will still be possible to go online and upload somewhere all your extra data. Or come to the store and buy yourself another hard drive for a thousand terabytes. But you can always use already lying houses.
-> github