Logs of the front-end developer Habr: refactor and reflex

I was always interested in how the Habr is arranged from the inside, how the workflow is built, how the communications are built, what standards are applied and how the code is written here. Fortunately, such an opportunity appeared to me, because recently I became part of the habracommand. Using the example of a small refactoring of the mobile version, I’ll try to answer the question: what is it like to work here on the front. In the program: Node, Vue, Vuex and SSR with sauce from notes on personal experience in Habré.
The first thing you need to know about the development team is that we are few. Few are three fronts, two backs and technicals of all Habr - Bucksley. Of course, there is also a tester, designer, three Vadim, a miracle broom, a marketer and other Bumburums. But there are only six direct contributors to the Habra sorts. This is quite rare - a project with a multimillion-dollar audience that looks like a gigantic enterprise from the outside is actually more like a cozy startup with the most flat organizational structure.
Like many other IT companies, Habr professes the ideas of Agile, the practice of CI, and that’s all. But according to my feelings, Habr as a product develops more undulatingly than continuously. So for several sprints in a row, we are hard at work coding, designing and redesigning, breaking something and fixing, resolving tickets and starting new ones, step on the rake and shoot ourselves in the legs to finally release the feature to the prod. And then there comes a lull, a period of redevelopment, the time to do what is in the “important-non-urgent” quadrant.
Just about such an “off-season” sprint will be discussed below. This time it got refactoring the mobile version of Habr. In general, the company has high hopes for it, and in the future it should replace the entire Habr incarnation zoo and become a universal cross-platform solution. Someday there will appear adaptive layout, and PWA, and offline mode, and user customization, and a lot of interesting things.
We set the task
Once, at an ordinary stand-up, one of the fronts talked about problems in the architecture of the comment component of the mobile version. From this presentation, we organized a micro-meeting in the format of group psychotherapy. Each in turn said where he had pain, everything was fixed on paper, sympathized, understood, except that no one clapped. The output was a list of 20 problems, which made it clear that the mobile Habr must go a long and thorny path to success.
My main concern was resource efficiency and what is called a smooth interface. Every day on the “home-work-home” route, I saw my old telephone desperately trying to display 20 headings in the stream. It looked something like this:

What is happening here? In short, the server gave the HTML page to everyone the same way, regardless of whether the user is logged in or not. Then the client JS is loaded and again requests the necessary data, but with an amendment for authorization. That is, in fact, we did the same work twice. The interface flickered, and the user downloaded a good hundred extra kilobytes. In details, everything looked even more creepy.
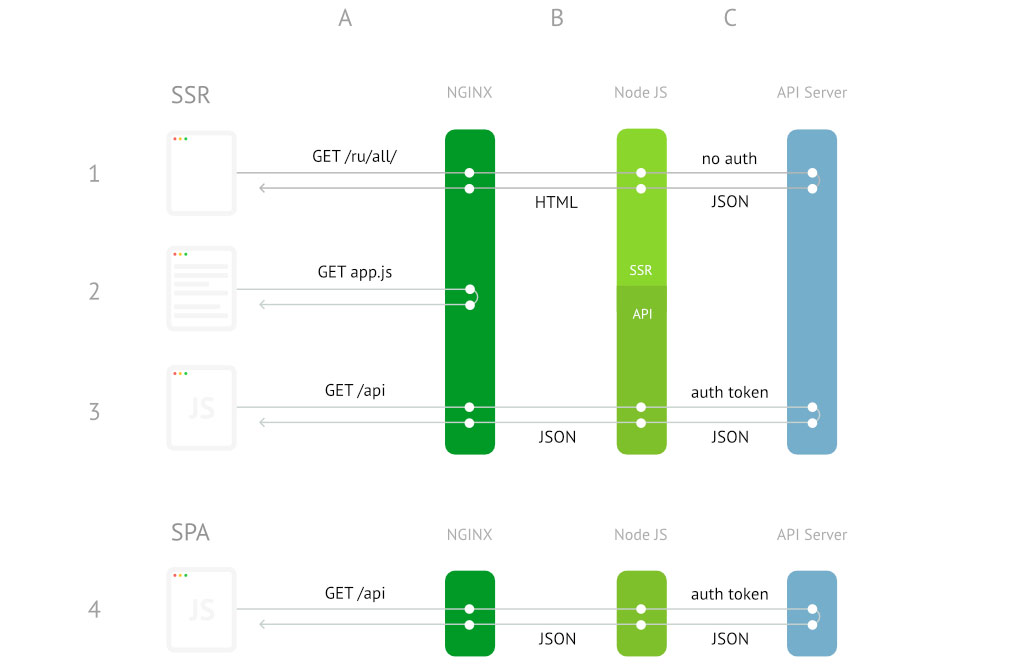
Our architecture of that time was very accurately described by one of Habr's users:
The mobile version is shit. I speak as it is. A terrible combination of SSR along with CSR.
We had to admit it, however sad it may be.
I figured out the options, set myself a ticket in the "Jira" with a description at the level of "Now it’s bad, make the rules" and with wide strokes I decomposed the task:
- reuse data
- minimize the number of redraws,
- exclude duplicate requests
- make the loading process more obvious.
Reuse data
In theory, server-side rendering is designed to solve two problems: not to suffer from the limitations of search engines regarding SPA indexing and to improve the FMP metric (inevitably worsening TTI ). In the classic scenario, which was finally formulated in Airbnb in 2013 (back at Backbone.js), SSR is the same isomorphic JS application running in the Node environment. The server simply returns the generated layout as a response to the request. Then rehydration occurs on the client side, and then everything works without page reloads. For Habr, as well as for many other text-filled resources, server rendering is a critical element in building friendly relations with search engines.
Despite the fact that more than six years have passed since the advent of the technology, and during this time, really a lot of water has flowed in the frontend world, for many developers this idea is still covered in a veil of secrecy. We did not stand aside, and rolled out a Vue application with SSR support to the prod, missing one small detail: we did not throw the initial state to the client.
Why? There is no exact answer to this question. Either they did not want to increase the size of the response from the server, or because of a bunch of other architectural problems, or simply did not take off. One way or another, throwing state and reusing everything that the server did seems to be quite appropriate and useful. The task is actually trivial - state is just injectedin the execution context, and Vue will automatically add it to the generated layout as a global variable:
window.__INITIAL_STATE__. One of the problems that arose was the inability to convert circular structures to JSON ; was solved by simply replacing such structures with their flat analogues.
In addition, when dealing with UGC content, remember that data should be converted to HTML entities so as not to break the HTML. For these purposes we use he .
Minimize redraws
As can be seen from the diagram above, in our case, one Node JS instance performs two functions: SSR and "proxy" in the API, where the user is authorized. This circumstance makes authorization impossible at the time of execution of the JS code on the server, since the node is single-threaded and the SSR function is synchronous. That is, the server simply cannot send requests to itself while the call stack is busy with something. It turned out that we skipped state, but the interface did not stop twitching, since the data on the client should be updated taking into account the user session. It was necessary to teach our application to put the correct data in the initial state, taking into account the user's login.
There were only two solutions to the problem:
- to cling authorization data to interserver requests;
- Split Node JS layers into two separate instances.
The first solution required the use of global variables on the server, and the second extended the time needed to complete the task by at least a month.
How to make a choice? Habr often moves along the path of least resistance. Informally, there is a certain general desire to minimize the cycle from idea to prototype. The model of attitude to the product is somewhat reminiscent of the postulates of booking.com, with the only difference being that Habr is much more serious about user feedback and trusts the adoption of such decisions to you as a developer.
Following this logic and my own desire to quickly solve the problem, I chose global variables. And, as this often happens, sooner or later they have to pay for them. We paid almost immediately: we worked on the weekend, raked up the consequences, wrote a post mortemand began to divide the server into two parts. The mistake was very stupid, and the bug with her participation was not easy to reproduce. And yes, for such a shame, but somehow, stumbling and grunting, my PoC with global variables still went into production and quite successfully works in anticipation of moving to a new "two-day" architecture. This was an important step, because formally the goal was achieved - the SSR learned to give a page that was completely ready for use, and the UI became much calmer.

Ultimately, the architecture of the SSR-CSR mobile version leads to this picture:

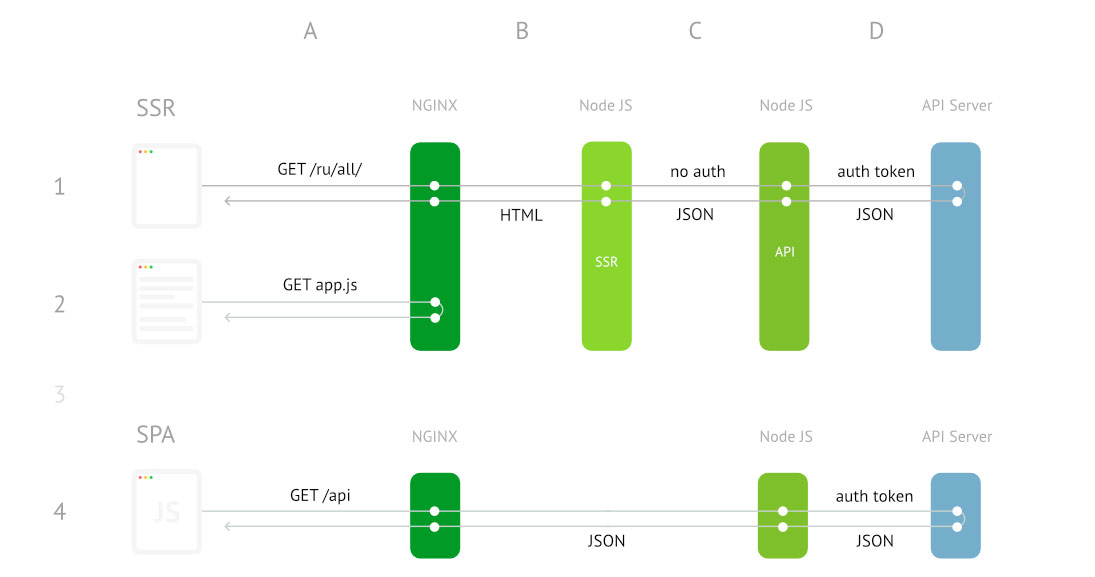
Exclude duplicate requests
After the manipulations, the initial page rendering ceased to provoke epilepsy. But the further use of Habr in the SPA mode still caused bewilderment.
Since user flow is based on transitions of the form list of articles → article → comments and vice versa, it was important to optimize the consumption of resources of this chain in the first place.
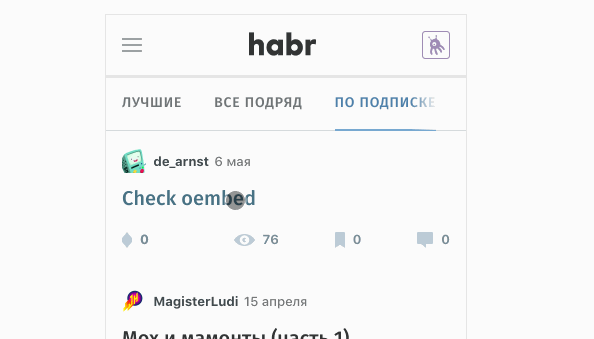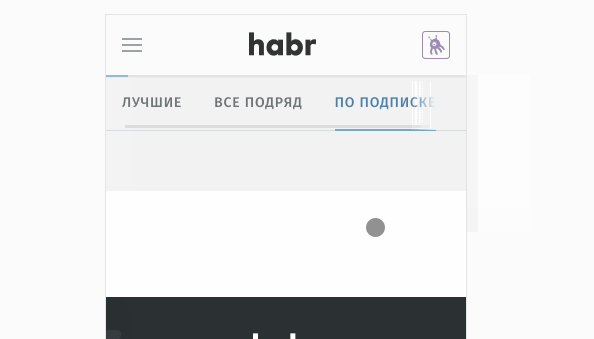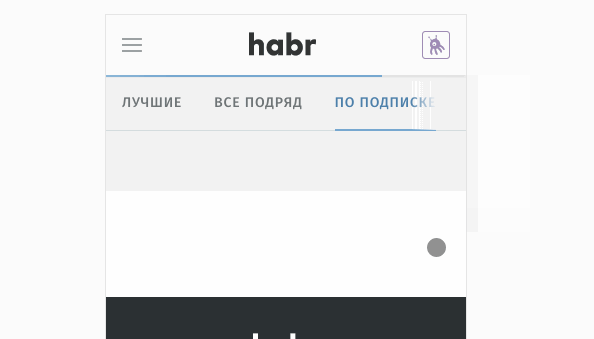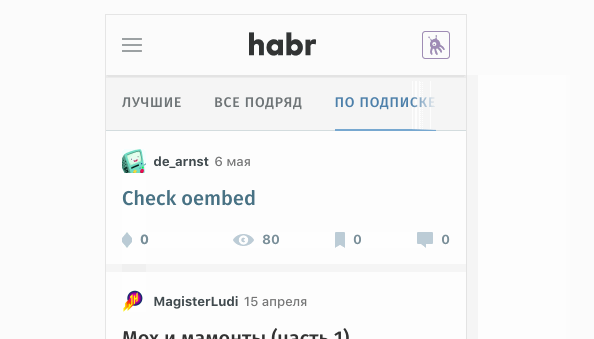
. I did not have to dig deep. On the screencast above, it can be seen that the application re-queries the list of articles when swiping back, and during the request we do not see the article, so the previous data disappears somewhere. It looks like the article list component uses a local state and loses it on destroy. In fact, the application used the global state, but the Vuex architecture was built on the forehead: the modules are tied to pages, which in turn are tied to routes. Moreover, all modules are “one-time” - each subsequent visit to the page rewrote the entire module:
ArticlesList: [
{ Article1 },
...
],
PageArticle: { ArticleFull1 },
In total, we had the ArticlesList module , which contains objects of the Article type and the PageArticle module , which was an extended version of the Article object , a kind of ArticleFull . By and large, this implementation does not carry anything terrible in itself - it is very simple, one might even say naively, but it is extremely clear. If you cut out the zeroing of the module with each change of the route, then you can even live with it. However, the transition between article feeds, for example / feed → / all , is guaranteed to throw away everything related to the personal feed, since we have only one ArticlesList in which to put new data. This again leads to duplicate queries.
Putting together everything that I managed to unearth on the topic, I formulated a new state structure and presented it to my colleagues. The discussions were lengthy, but in the end, the arguments “for” outweighed the doubts, and I started implementation.
The logic of the solution is best disclosed in two stages. First, we try to untie the Vuex module from the pages and bind directly to the routes. Yes, there will be a bit more data in the store, getters will become a little more complicated, but we will not load the articles twice. For the mobile version, this is perhaps the strongest argument. It will look something like this:
ArticlesList: {
ROUTE_FEED: [
{ Article1 },
...
],
ROUTE_ALL: [
{ Article2 },
...
],
}
But what if article lists can overlap between multiple routes, and what if we want to reuse the data of an Article object to render a post page, turning it into ArticleFull ? In this case, it would be more logical to use such a structure:
ArticlesIds: {
ROUTE_FEED: [ '1', ... ],
ROUTE_ALL: [ '1', '2', ... ],
},
ArticlesList: {
'1': { Article1 },
'2': { Article2 },
...
}
ArticlesList here is just some kind of article repository. All articles that were uploaded during the user session. We treat them as carefully as possible, because this is traffic that may have been loaded through pain somewhere in the subway between stations, and we definitely do not want to cause the user this pain again, forcing him to load the data that he has already downloaded. The ArticlesIds object is just an array of identifiers (like “links”) to Article objects . This structure allows you not to duplicate the data common to routes and reuse the Article object when rendering a post page by merging extended data into it.
The output of the article list has also become more transparent: the iterator component iterates over the array with article IDs and draws the article teaser component, passing Id as props, and the child component in turn retrieves the necessary data from the ArticlesList . When you go to the publication page, we get the existing date from the ArticlesList , make a request for the missing data, and simply add it to the existing object.
Why is this approach better? As I wrote above, this approach is more careful in relation to the downloaded data and allows you to reuse it. But besides this, it opens the way to some new opportunities that fit perfectly into such an architecture. For example, polling and uploading articles to the feed as they appear. We can simply add fresh posts to the ArticlesList “store” , save a separate list of new IDs in ArticlesIds and notify the user about this. When you click on the button “Show new publications”, we simply insert new Id at the beginning of the array of the current list of articles and everything will work almost magically.
Making the download more enjoyable
The cherry on the refactoring cake was the concept of skeletons, which makes the process of downloading content on the slow Internet a little less disgusting. There were no discussions on this subject, the journey from idea to prototype took literally two hours. The design was drawn almost by ourselves, and we taught our components how to render unpretentious, barely flickering div blocks while waiting for data. Subjectively, this approach to loading really reduces the amount of stress hormones in the user's body. Skeleton looks like this:
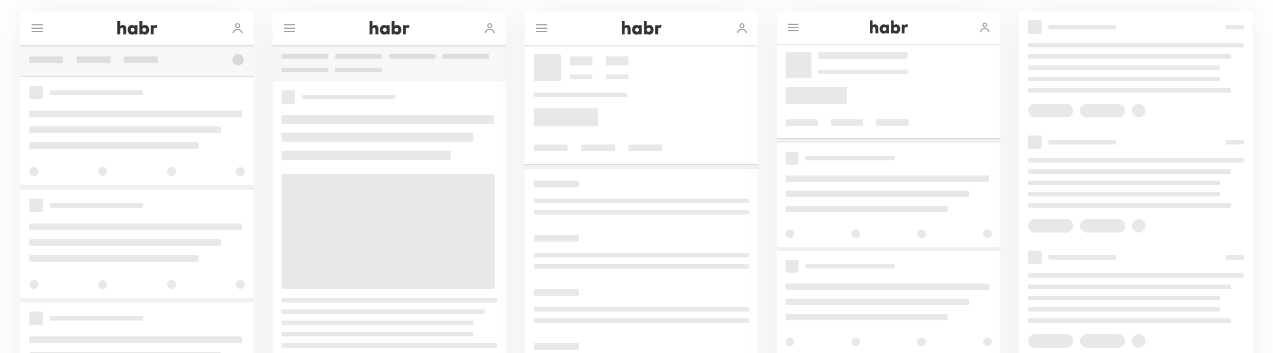
Habraloading
Reflect
I have been working in Habré for six months and friends still ask: well, how do you like it? Good, comfortable - yes. But there is something that distinguishes this work from others. I worked in teams that were completely indifferent to their product, did not know and did not understand who their users were. But here everything is different. Here you feel responsible for what you are doing. In the process of developing a feature, you partially become its owner, take part in all product meetings related to your functionality, make suggestions and make decisions yourself. Making a product that you use yourself daily is very cool, and writing code for people who may be better at it is just an incredible feeling (no sarcasm).
After the release of all these changes, we received a positive feedback, and it was very, very nice. It is inspiring. Thanks! Write more.
Let me remind you that after global variables we decided to change the architecture and separate the proxy layer into a separate instance. The "two-day" architecture has already reached the release in the form of public beta testing. Now anyone can switch to it and help us make mobile Habr better. That's all for today. I will be happy to answer all your questions in the comments.