Go Bitmap Indexes: Wild Search

introduction
I made this report in English at the GopherCon Russia 2019 conference in Moscow and in Russian at the meeting in Nizhny Novgorod. It is about a bitmap index - less common than B-tree, but no less interesting. I share the recording of the speech at the conference in English and the text transcript in Russian.
We will examine how the bitmap index works, when it is better, when it is worse than other indexes, and in which cases it is much faster than them; We will see which popular DBMSs already have bitmap indexes. try to write your own on Go. And for dessert, we will use ready-made libraries to create our own super-fast specialized database.
I really hope that my work will be useful and interesting for you. Go!
Introduction
http://bit.ly/bitmapindexes
https://github.com/mkevac/gopherconrussia2019
Hello everyone! It's six in the evening, we are all super tired. Great time to talk about the boring theory of database indexes, right? Don’t worry, I will have a couple of lines of source code here and there. :-)
If without jokes, then the report is full of information, and we do not have much time. So let's get started.

Today I will talk about the following:
- what are indexes;
- what is a bitmap index;
- where it is used and where it is NOT used and why;
- simple implementation on Go and a little struggle with the compiler;
- slightly less simple, but much more productive implementation in Go-assembler;
- “Problems” of bitmap indexes;
- existing implementations.
So what are indexes?
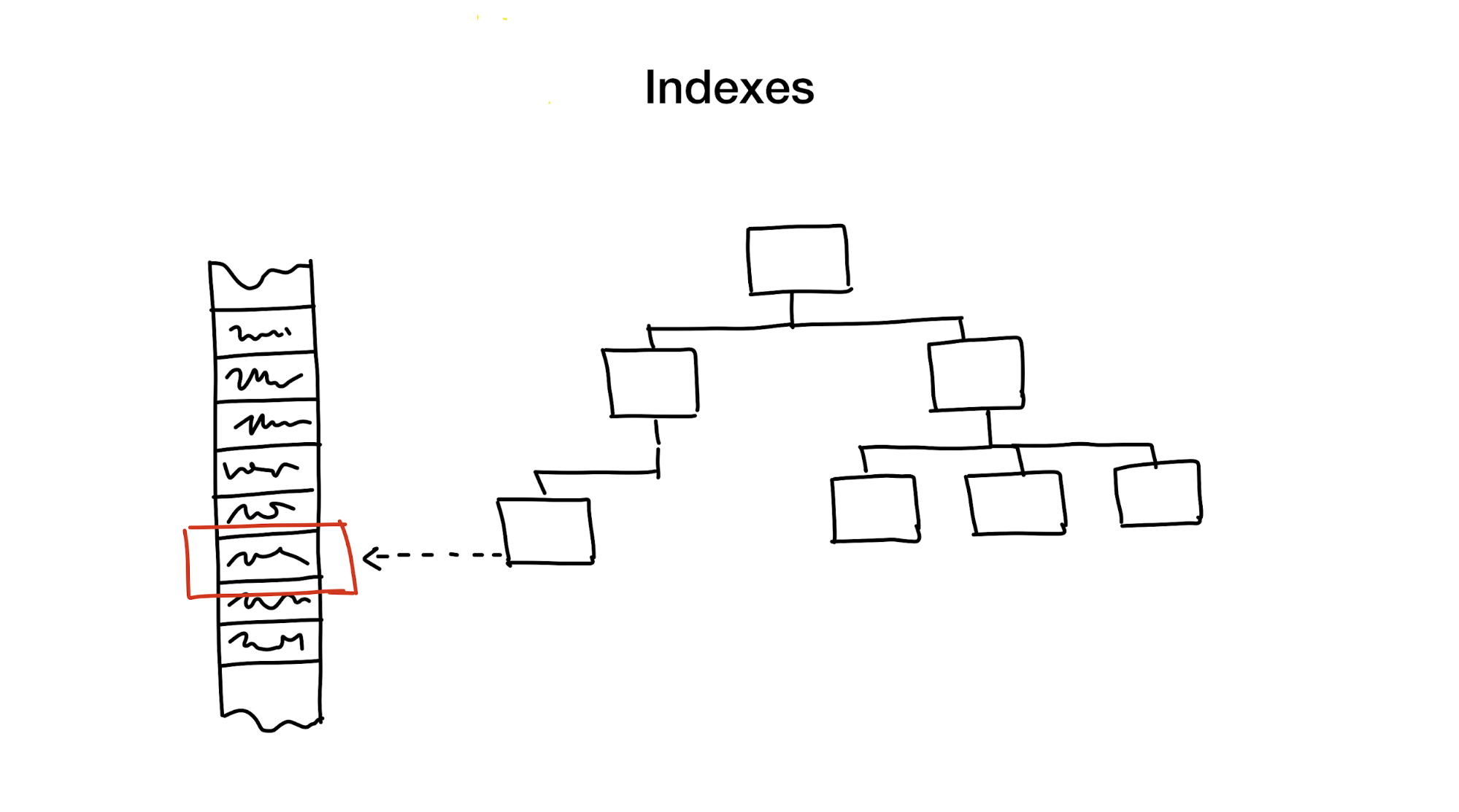
An index is a separate data structure that we hold and update in addition to the main data. It is used to speed up the search. Without indexes, a search would require a full pass through the data (a process called full scan), and this process has linear algorithmic complexity. But databases usually contain a huge amount of data and linear complexity is too slow. Ideally, we would get a logarithmic or constant.
This is a huge complex topic, overwhelmed with subtleties and compromises, but after looking at decades of development and research of various databases, I am ready to argue that there are only a few widely used approaches to creating database indexes.

The first approach is to hierarchically reduce the search area, dividing the search area into smaller parts.
Usually we do this using all sorts of trees. An example is a large box with materials in your closet, in which there are smaller boxes with materials divided by various topics. If you need materials, then you will probably look for them in a box with the words "Materials", and not in the one that says "Cookies", right?
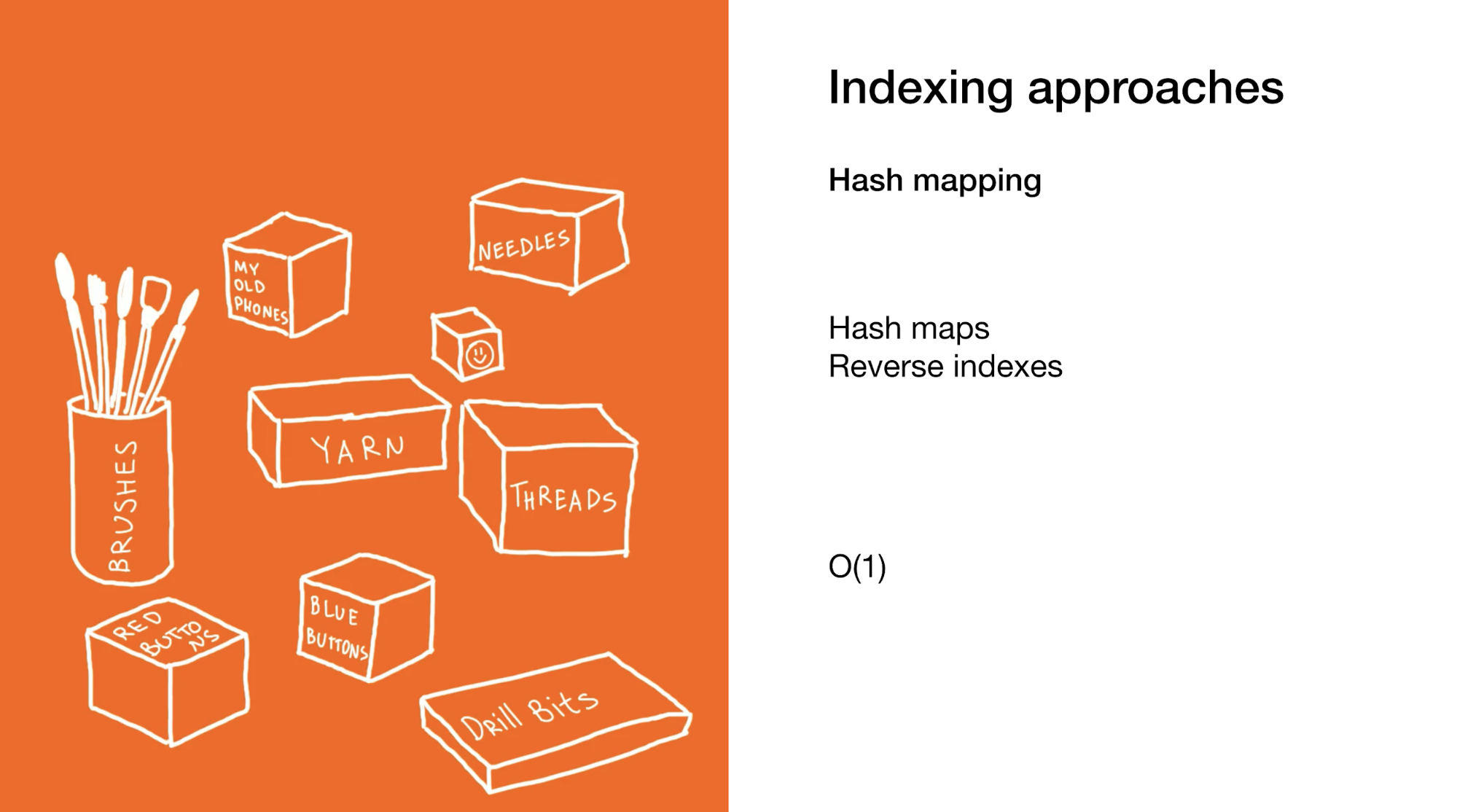
The second approach is to immediately select the desired element or group of elements. We do this in hash maps or in reverse indexes. Using hash maps is very similar to the previous example, only instead of a box with boxes in your closet there are a lot of small boxes with final items.

The third approach is to get rid of the need for a search. We do this using Bloom filters or cuckoo filters. The former provide an answer instantly, eliminating the need to search.
The last approach is to fully utilize all the capacities that modern iron gives us. This is exactly what we do in bitmap indices. Yes, when using them, we sometimes need to go through the entire index, but we do it super-efficiently.
As I said, the topic of database indexes is vast and overflowing with compromises. This means that sometimes we can use several approaches at the same time: if we need to accelerate the search even more or if it is necessary to cover all possible types of search.
Today I’ll talk about the least known approach out of these - about bitmap indexes.
Who am I to talk about this?
I work as a team lead in Badoo (perhaps you better know our other product, Bumble). We already have more than 400 million users around the world and many features that are engaged in selecting the best pair for them. We do this using custom services that use bitmap indexes as well.
So what is a bitmap index?
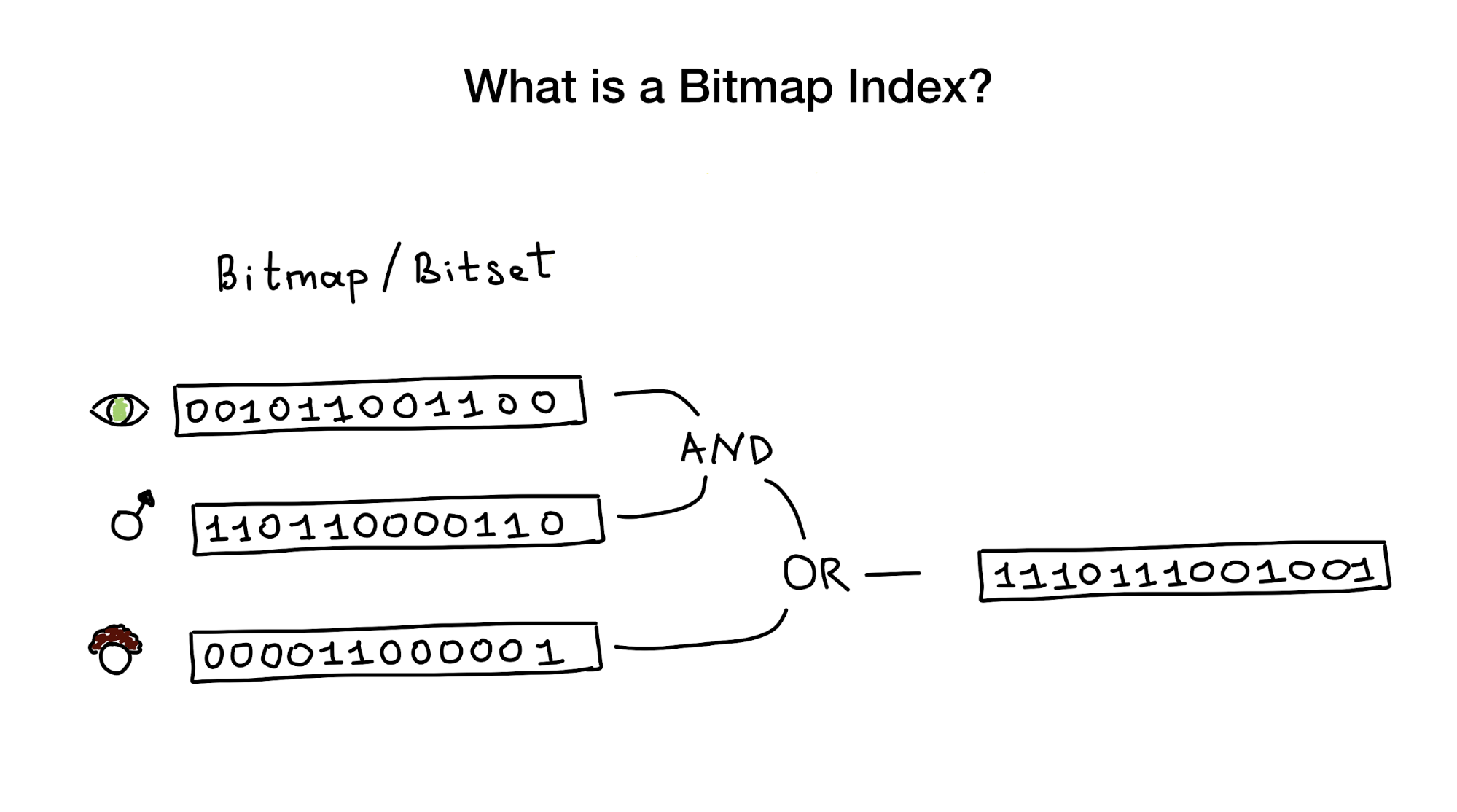
Bitmap indexes, as the name tells us, use bitmaps or bitsets to implement a search index. From a bird's eye view, this index consists of one or more such bitmaps representing any entities (such as people) and their properties or parameters (age, eye color, etc.), and from an algorithm that uses bit operations (AND, OR, NOT) to respond to a search query.

We are told that bitmap indexes are best suited and very productive for cases where there is a search that combines queries across many columns that have little cardinality (imagine “eye color” or “marital status” against something like “distance from the city center” ) But later I will show that they work perfectly in the case of columns with high cardinality.
Consider the simplest example of a bitmap index.

Imagine that we have a list of Moscow restaurants with binary properties like these:
- near the metro (near metro);
- there is a private parking (has private parking);
- there is a veranda (has terrace);
- You can reserve a table (accepts reservations);
- suitable for vegetarians (vegan friendly);
- expensive (expensive).
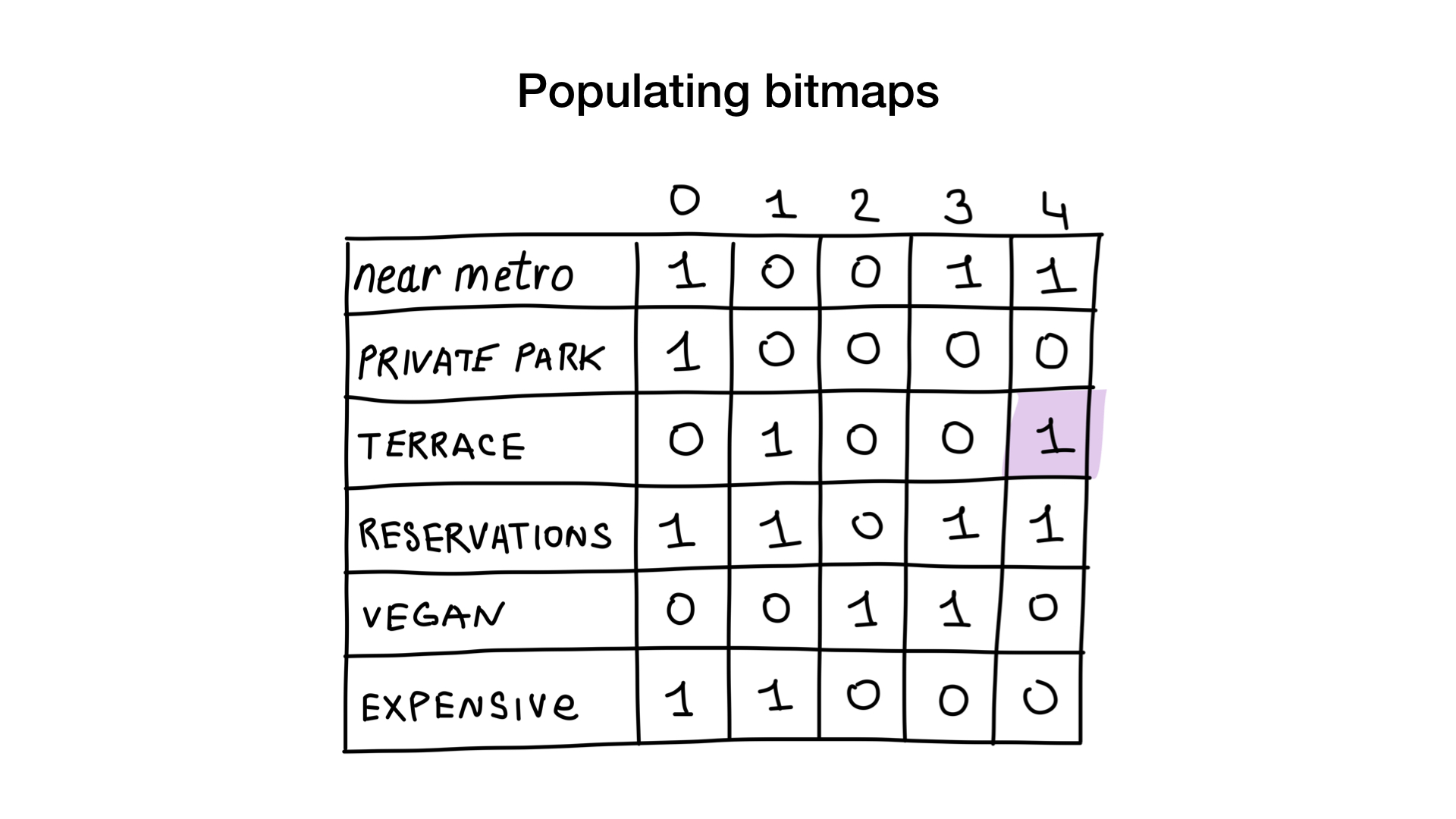
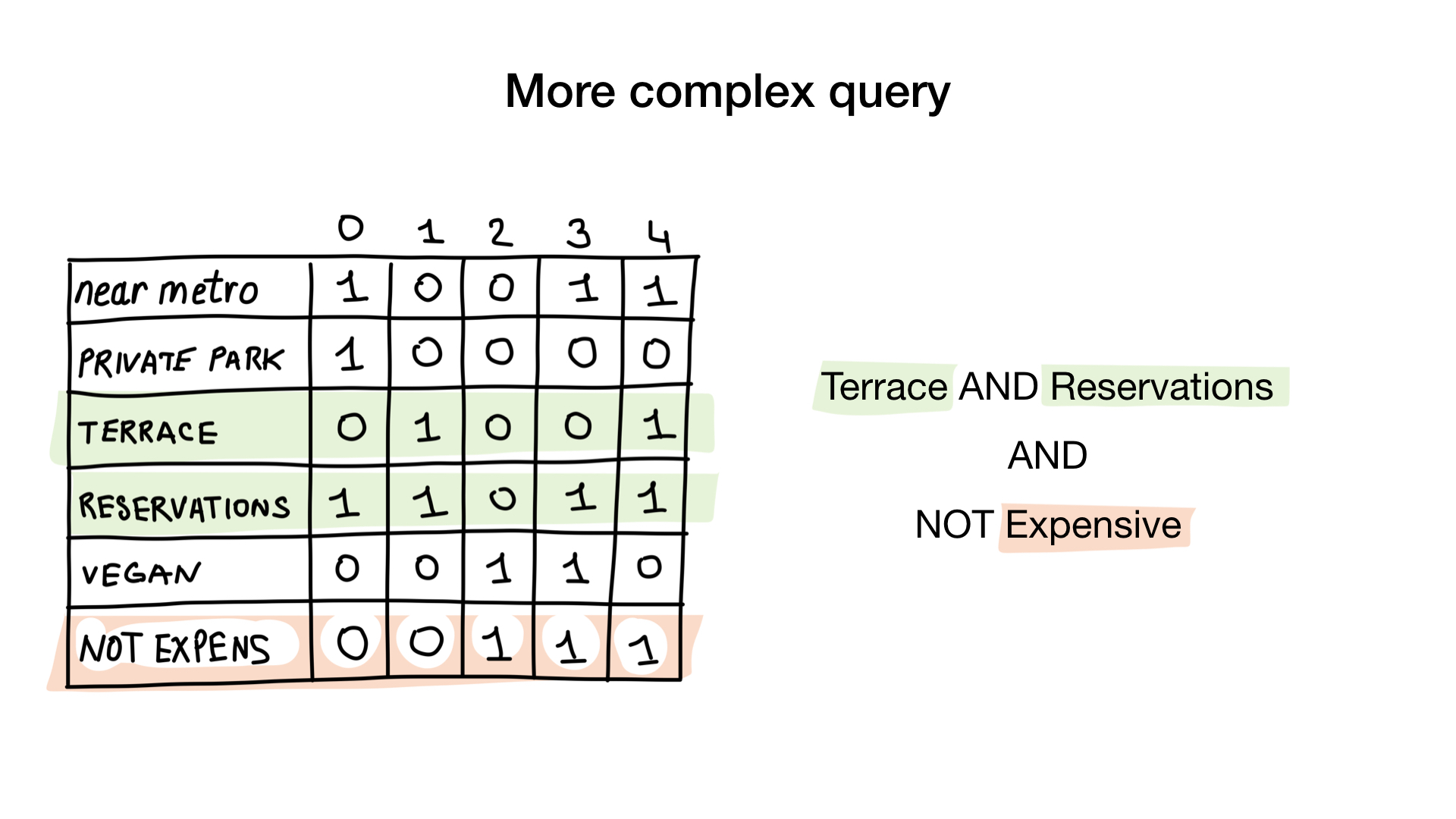
Let's give each restaurant a serial number starting at 0 and allocate memory for 6 bitmaps (one for each characteristic). Then we fill out these bitmaps, depending on whether the restaurant has this property or not. If restaurant 4 has a veranda, then bit No. 4 in the bitmap “there is a veranda” will be set to 1 (if there is no veranda, then to 0).

Now we have the simplest bitmap index possible, and we can use it to answer queries like:
- “Show me restaurants suitable for vegetarians”;
- “Show me inexpensive restaurants with a veranda where you can reserve a table.”
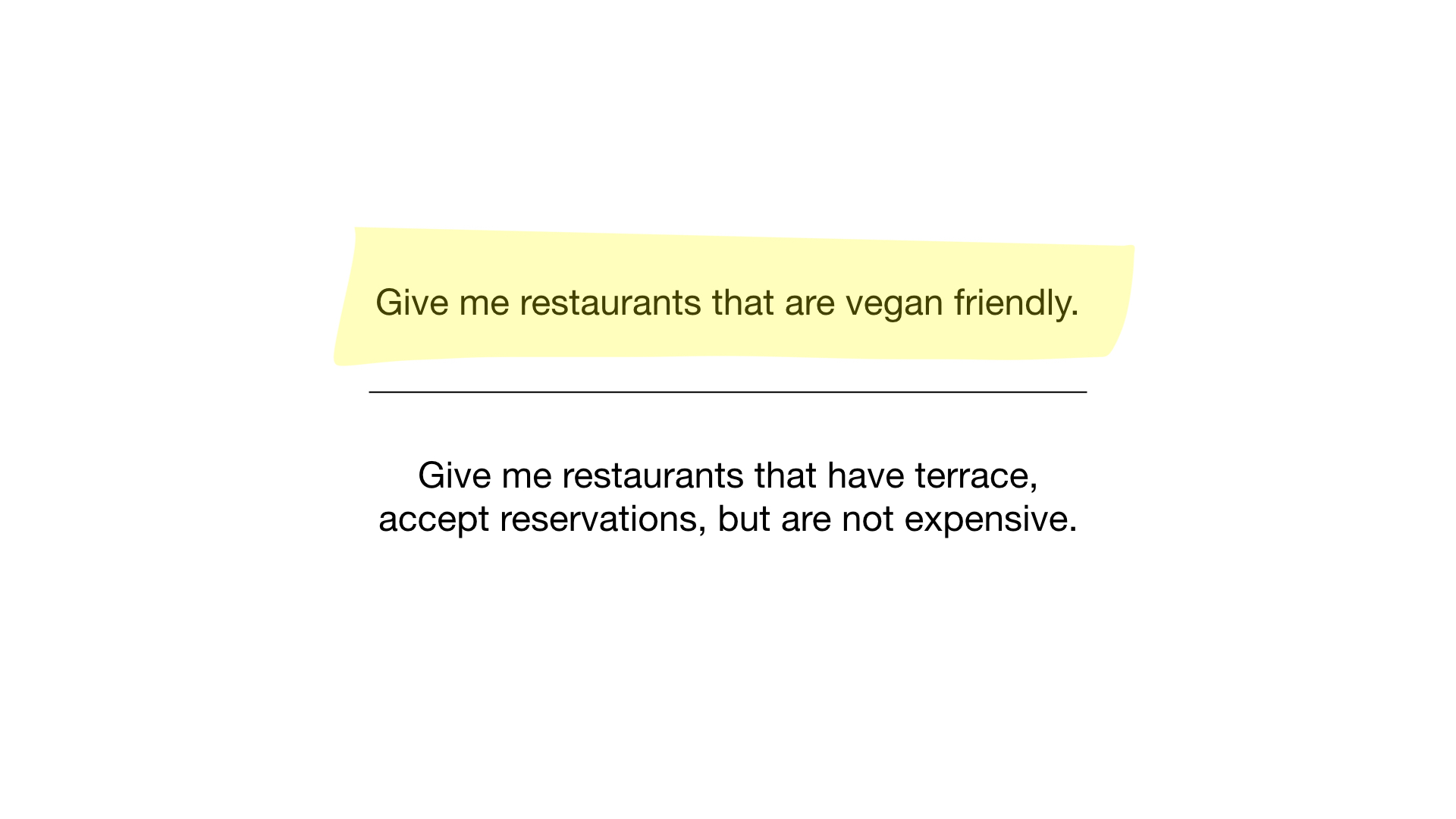
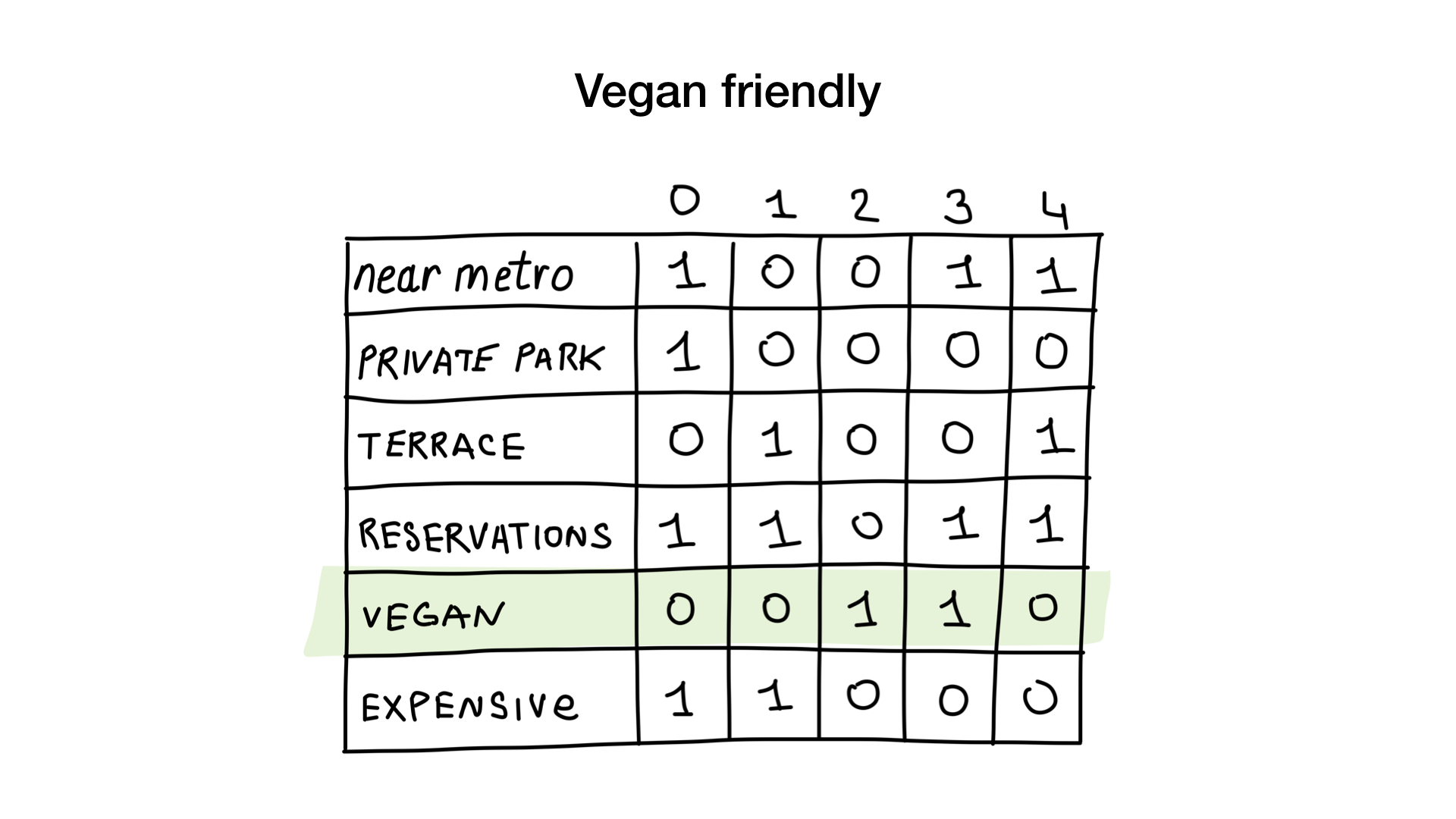
How? Let's get a look. The first request is very simple. All we need to do is take the “suitable for vegetarians” bitmap and turn it into a list of restaurants whose bits are on display.
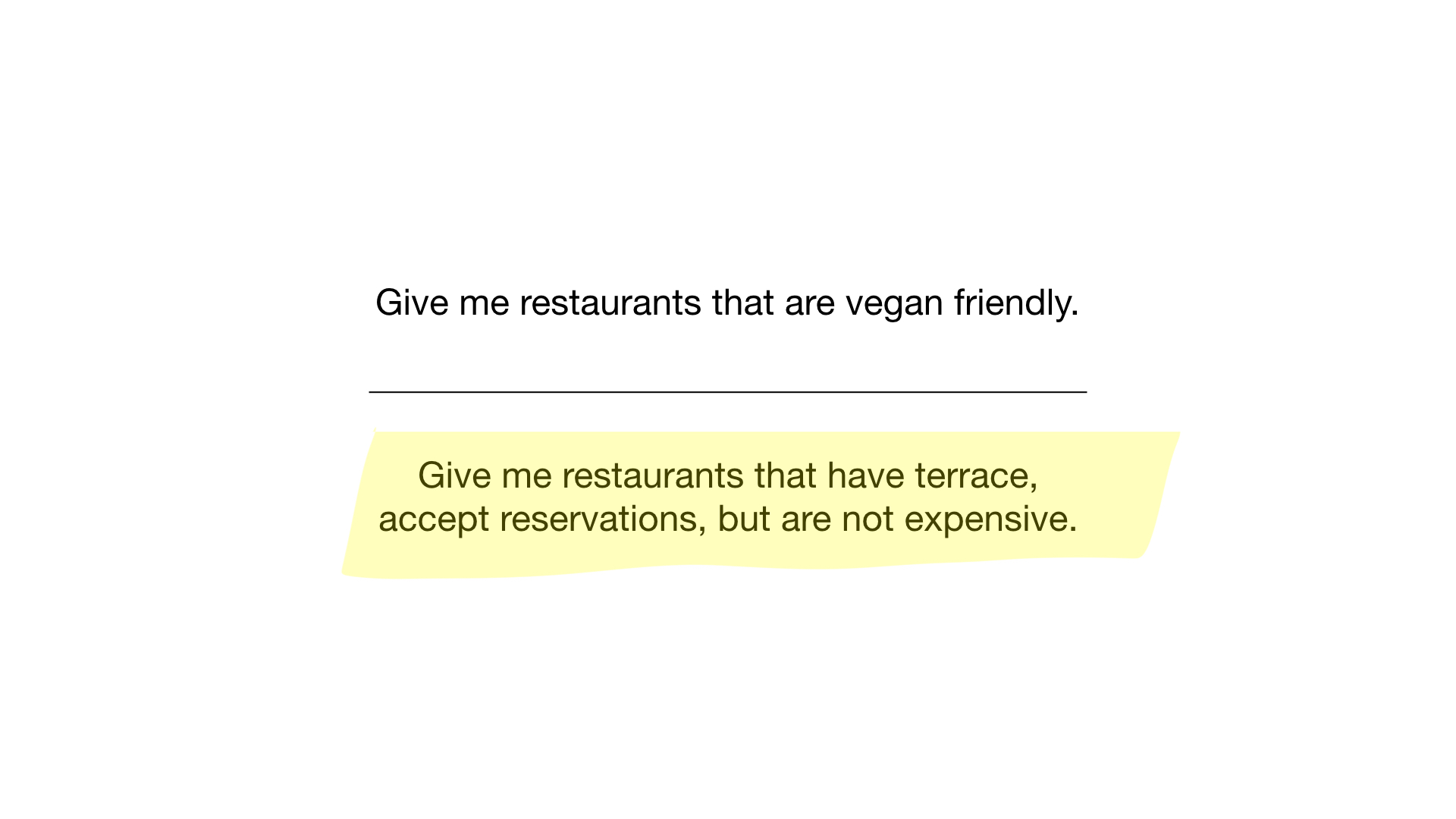

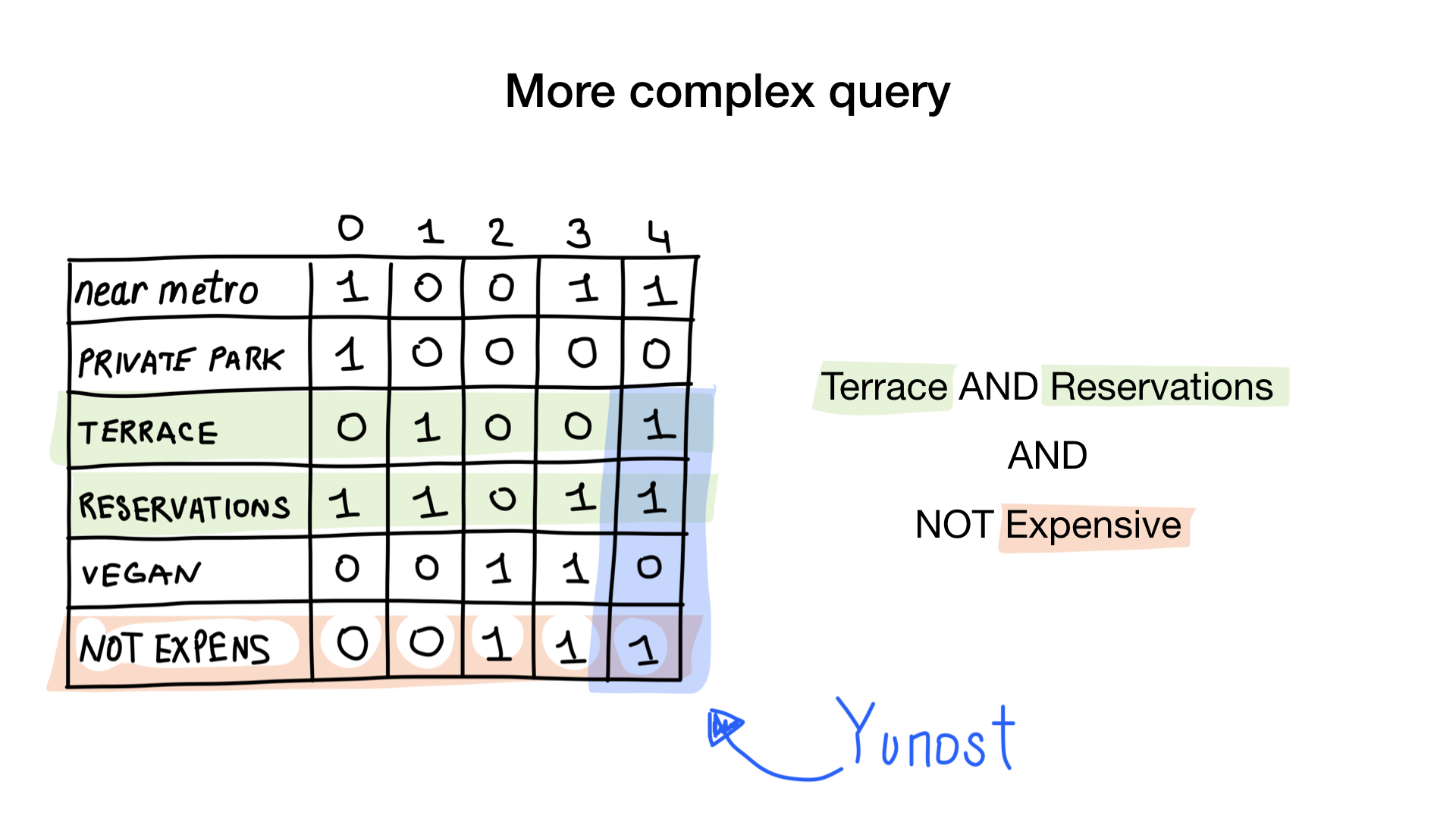
The second query is a bit more complicated. We need to use the NOT bit operation on the “expensive” bitmap to get a list of inexpensive restaurants, then set it with the bitmap “you can reserve a table” and set the result with the bitmap “there is a veranda”. The resulting bitmap will contain a list of establishments that meet all our criteria. In this example, this is only the Yunost restaurant.
There is a lot of theory, but don’t worry, we will see the code very soon.
Where are bitmap indexes used?

If you “google” bitmap indexes, 90% of the answers will somehow be related to Oracle DB. But the rest of the DBMS also probably supports such a cool thing, right? Not really.
Let's go through the list of the main suspects.

MySQL does not yet support bitmap indexes, but there is Proposal with a proposal to add this option ( https://dev.mysql.com/worklog/task/?id=1524 ).
PostgreSQL does not support bitmap indexes, but uses simple bitmaps and bit operations to combine search results across several other indexes.
Tarantool has bitset indexes, it supports a simple search on them.
Redis has simple bit fields (https://redis.io/commands/bitfield ) without the ability to search through them.
MongoDB does not yet support bitmap indexes, but there is also Proposal with a proposal to add this option https://jira.mongodb.org/browse/SERVER-1723
Elasticsearch uses bitmaps inside (https://www.elastic.co/blog/frame -of-reference-and-roaring-bitmaps ).

- But a new neighbor appeared in our house: Pilosa. This is a new non-relational database written in Go. It contains only bitmap indexes and bases everything on them. We will talk about her a little later.
Go implementation
But why are bitmap indexes so rarely used? Before answering this question, I would like to demonstrate to you the implementation of a very simple bitmap index on Go.

Bitmaps are essentially just pieces of data. In Go, let's use byte slices for this.
We have one bitmap per restaurant characteristic, and each bit in the bitmap indicates whether a particular restaurant has this property or not.

We will need two auxiliary functions. One will be used to populate our bitmaps with random data. Random, but with a certain probability that the restaurant has every property. For example, I believe that there are very few restaurants in Moscow where you cannot reserve a table, and it seems to me that approximately 20% of the establishments are suitable for vegetarians.
The second function will convert the bitmap to a list of restaurants.


To answer the request “Show me inexpensive restaurants that have a veranda and where you can reserve a table”, we need two bit operations: NOT and AND.
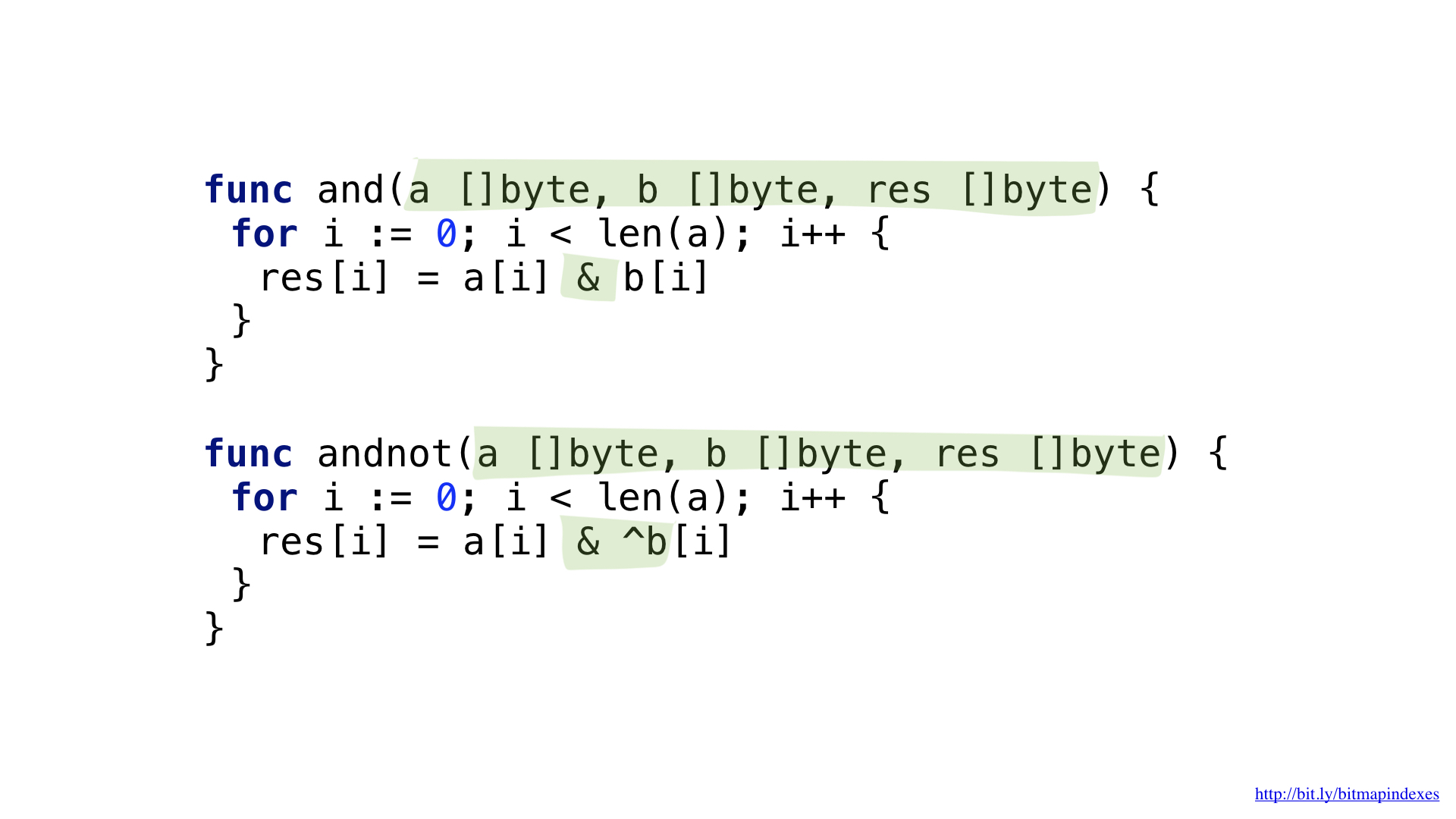
We can simplify our code a bit by using the more complex AND NOT operation.
We have functions for each of these operations. Both of them go through the slices, take the corresponding elements from each, combine them with a bit operation and put the result in the resulting slice.
And now we can use our bitmaps and functions to respond to a search query.

Performance is not so high, even despite the fact that the functions are very simple and we decently saved on the fact that we did not return a new resulting slice each time the function was called.
Having profiled a little with pprof, I noticed that the Go compiler missed one very simple, but very important optimization: function inlining.
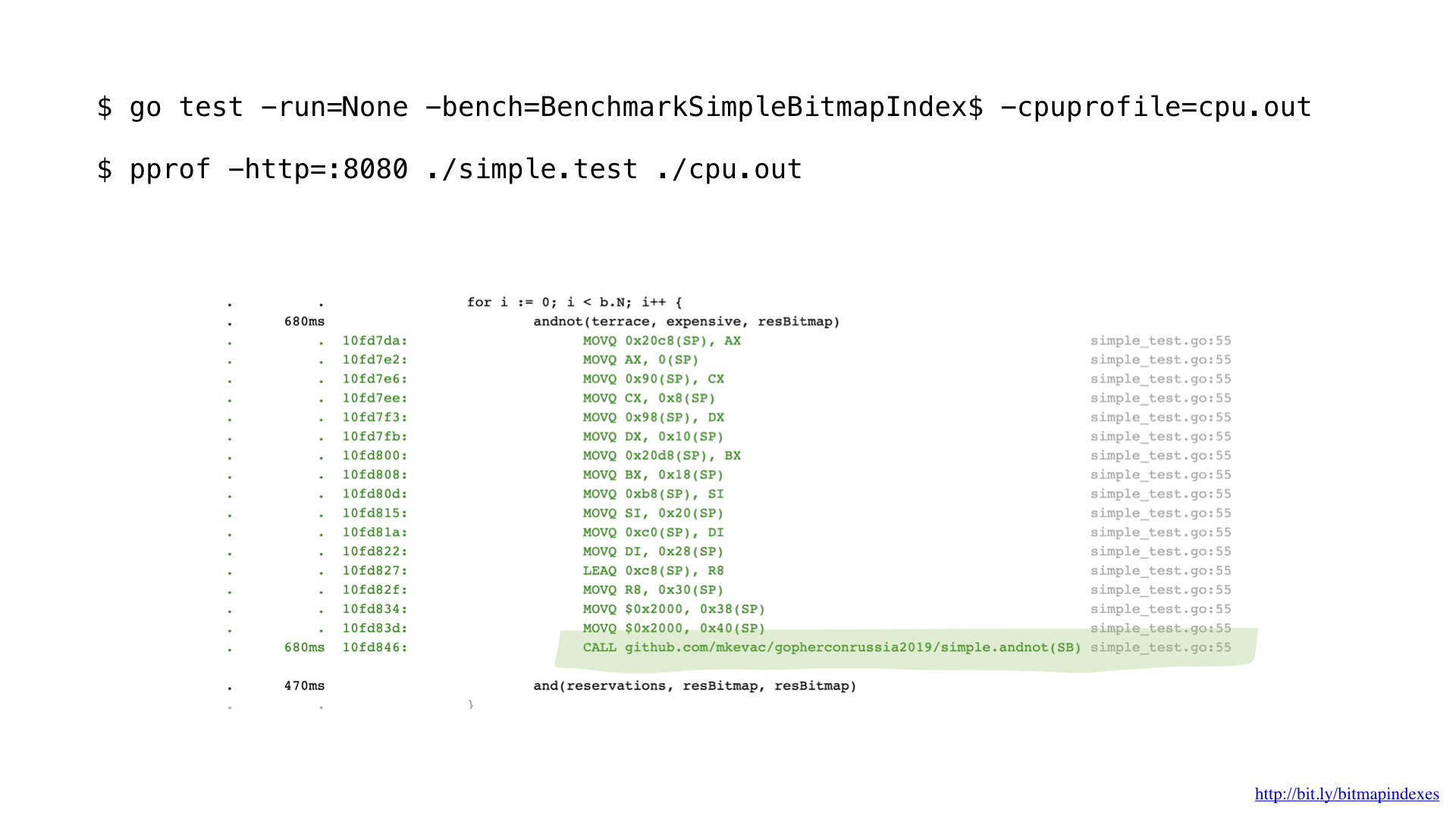
The fact is that the Go compiler is terribly afraid of loops that go through slices, and categorically refuses to inline functions that contain loops.
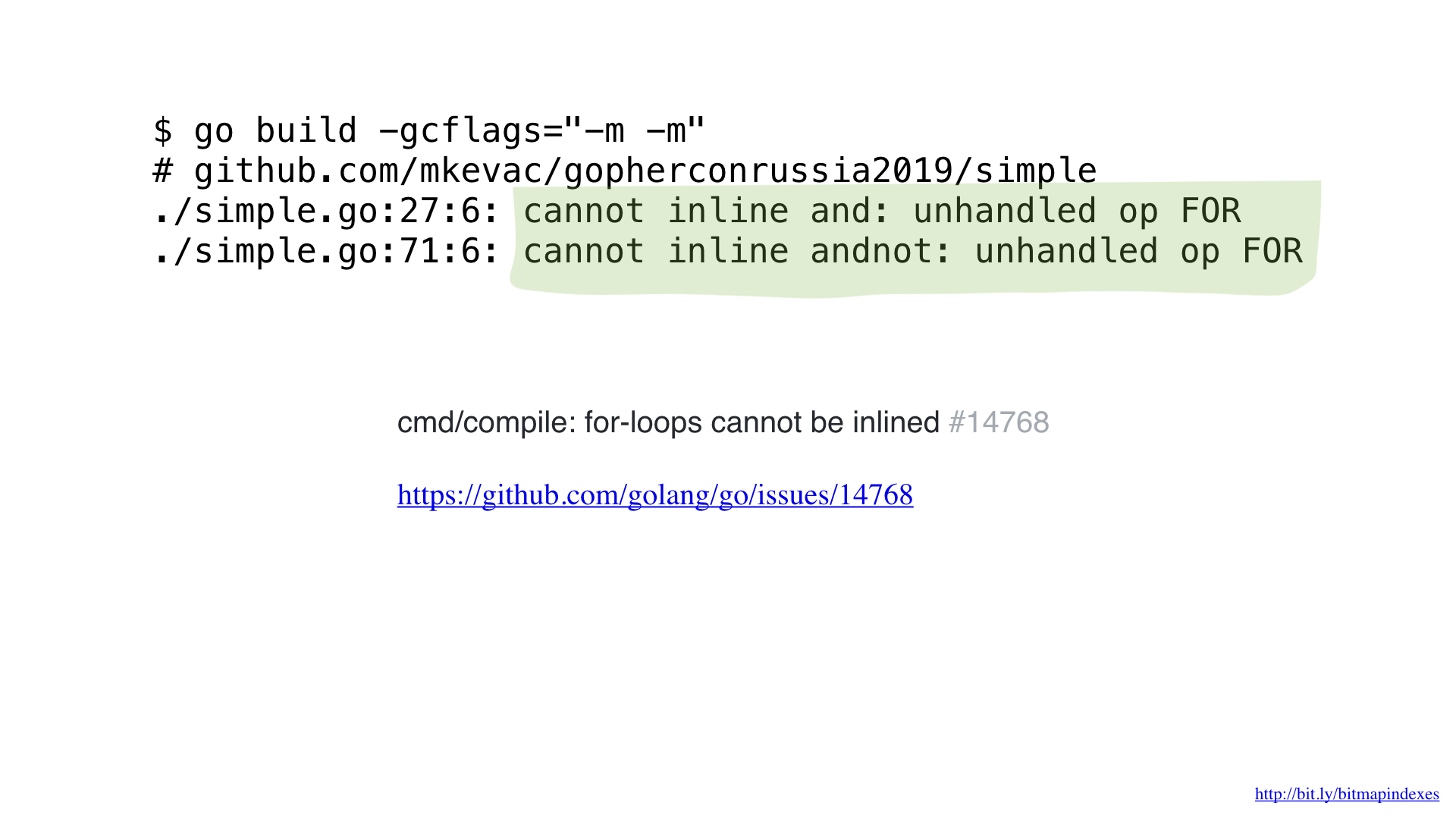
But I'm not afraid, and I can fool the compiler by using goto instead of a loop, as in the good old days.


And, as you can see, now the compiler happily inlines our function! As a result, we manage to save about 2 microseconds. Not bad!

The second bottleneck is easy to see if you carefully look at the assembler output. The compiler has added slice bound checking right inside our hottest loop. The fact is that Go is a safe language, the compiler is afraid that my three arguments (three slices) have different sizes. After all, then there will be a theoretical possibility of the appearance of the so-called buffer overflow.
Let's reassure the compiler by showing him that all slices are the same size. We can do this by adding a simple check at the beginning of our function.
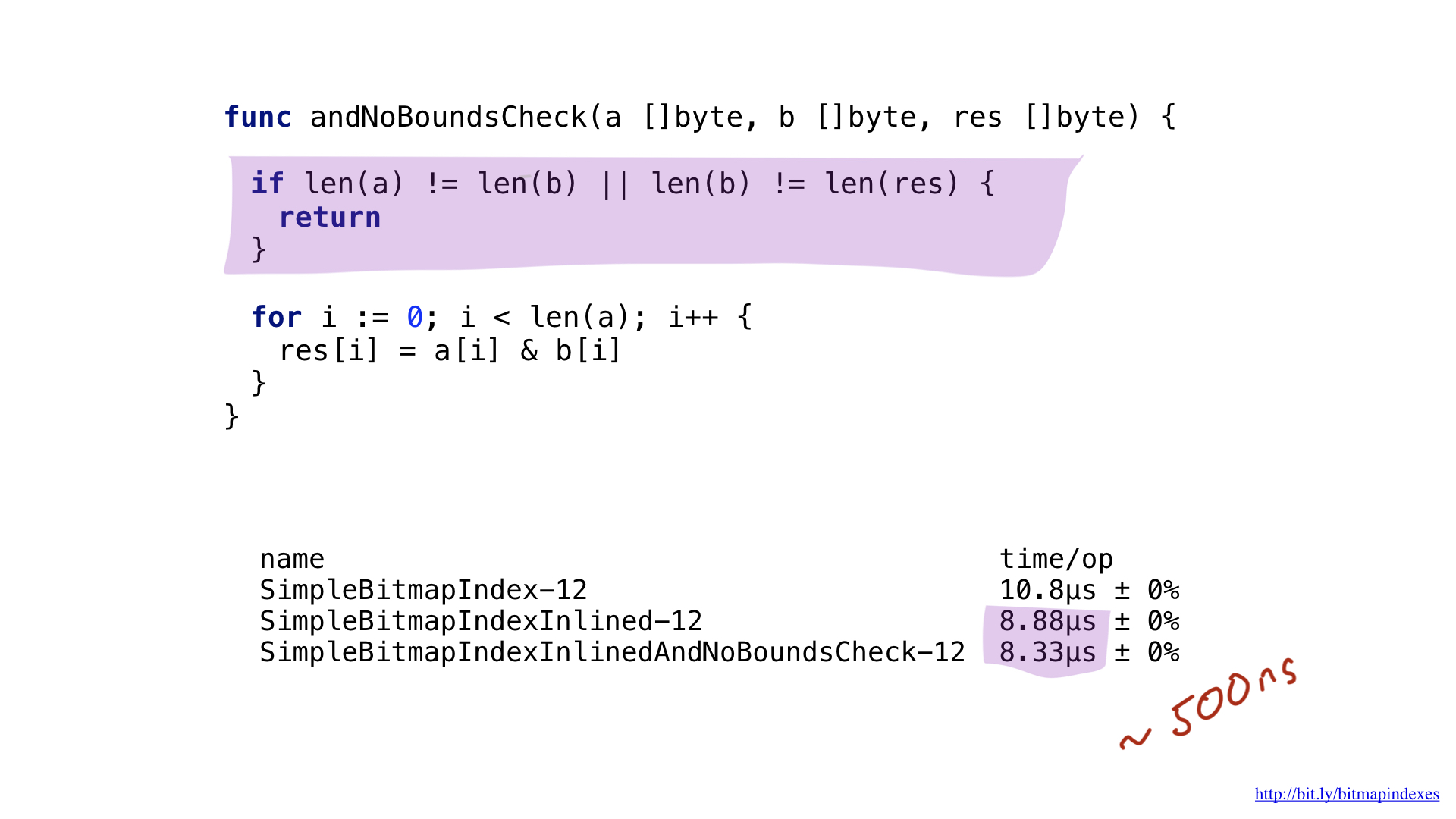
Seeing this, the compiler happily skips the test, and we end up saving another 500 nanoseconds.
Big batches
Okay, we managed to squeeze some performance out of our simple implementation, but this result, in fact, is much worse than possible with the current hardware.
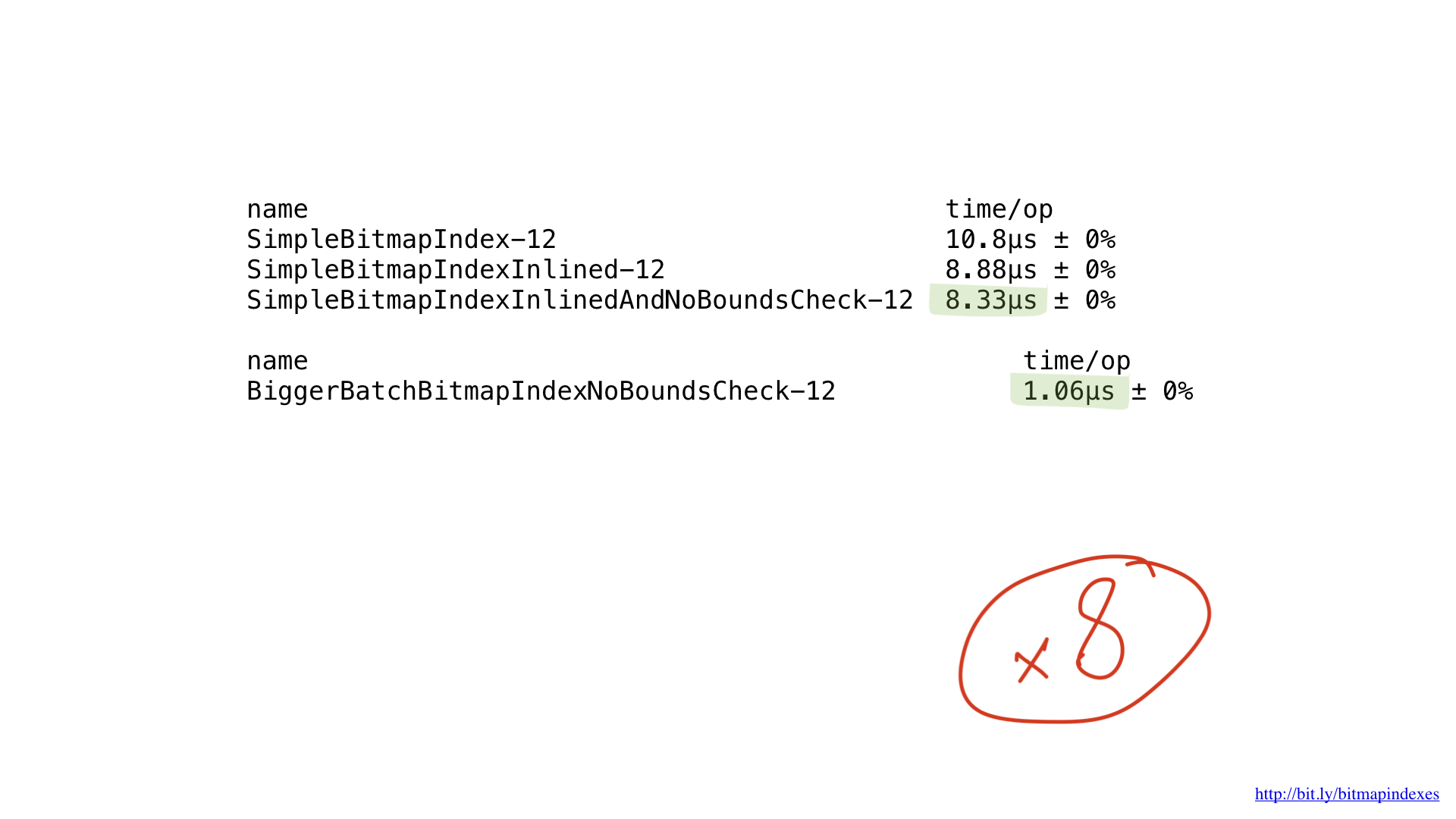
All we do is basic bit operations, and our processors perform them very efficiently. But, unfortunately, we “feed” our processor with very small pieces of work. Our functions perform operations byte by byte. We can very easily tune our code so that it works with 8-byte chunks using UInt64 slices.

As you can see, this small change has accelerated our program by eight times due to an increase in the batch by eight times. The gain can be said to be linear.
Assembler Implementation

But this is not the end. Our processors can work with pieces of 16, 32 and even 64 bytes. Such "wide" operations are called single instruction multiple data (SIMD; one instruction, a lot of data), and the process of transforming the code so that it uses such operations is called vectorization.
Unfortunately, the Go compiler is far from an excellent student in vectorization. Currently, the only way to vectorize code on Go is to take and put these operations manually using the Go assembler.

Assembler Go is a strange beast. You probably know that assembler is something that is strongly tied to the architecture of the computer you are writing for, but this is not the case with Go. The Go assembler is more like an IRL (intermediate representation language) or an intermediate language: it is practically platform independent. Rob Pike made an excellent presentation on this subject a few years ago at the GopherCon in Denver.
In addition, Go uses the unusual Plan 9 format, which differs from the generally recognized AT&T and Intel formats.

It is safe to say that writing Go assembler manually is not the most fun activity.
But, fortunately, there are already two high-level tools that help us write Go assembler: PeachPy and avo. Both utilities generate Go assemblers from higher-level code written in Python and Go, respectively.

These utilities simplify things like register allocation, writing cycles, and generally simplify the process of entering the world of assembler programming in Go.
We will use avo, so our programs will be almost normal Go programs.

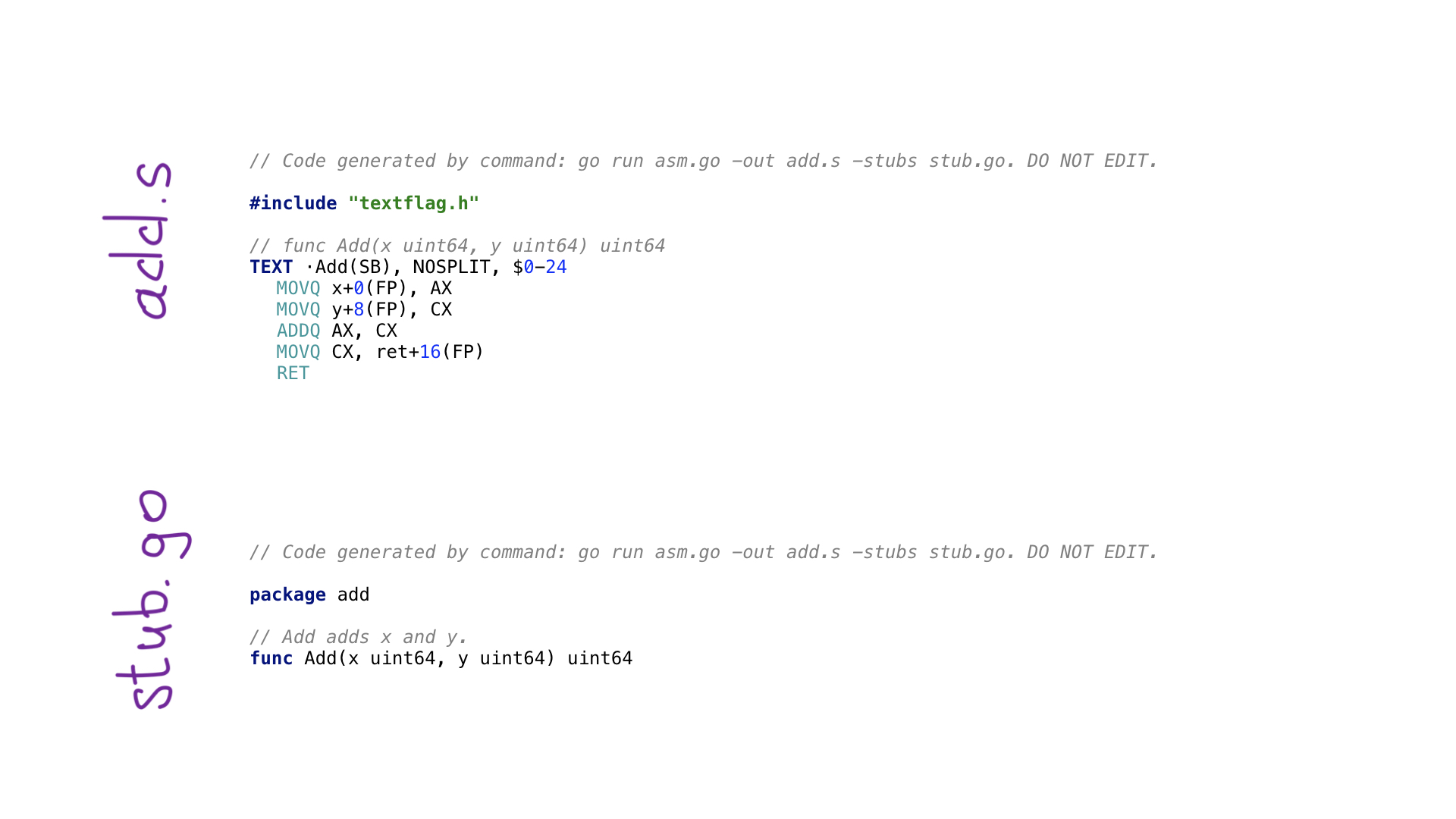
This is what the simplest example of an avo program looks like. We have a main () function that defines the Add () function inside of itself, the meaning of which is to add two numbers. There are auxiliary functions for getting parameters by name and getting one of the free and suitable processor registers. Each processor operation has a corresponding function on avo, as seen in ADDQ. Finally, we see a helper function to store the resulting value.

By calling go generate, we will execute the program on avo and in the end two files will be generated:
- add.s with the resulting Go assembler code;
- stub.go with function headers for connecting two worlds: Go and assembler.
Now that we have seen what and how avo does, let's take a look at our functions. I implemented both scalar and vector (SIMD) versions of functions.
First, look at the scalar versions.

As in the previous example, we ask you to provide us with a free and correct general-purpose register, we do not need to calculate the offsets and sizes for the arguments. All this avo does for us.

Earlier we used labels and goto (or jumps) to improve performance and to trick the Go compiler, but now we do it from the very beginning. The fact is that loops are a higher level concept. In assembler, we only have labels and jumps.

The remaining code should already be familiar and understandable. We emulate the loop with labels and jumps, take a small part of the data from our two slices, combine them with a bit operation (AND NOT in this case), and then put the result in the resulting slice. All.

This is what the final assembler code looks like. We did not need to calculate the offsets and sizes (highlighted in green) or keep track of the registers used (highlighted in red).
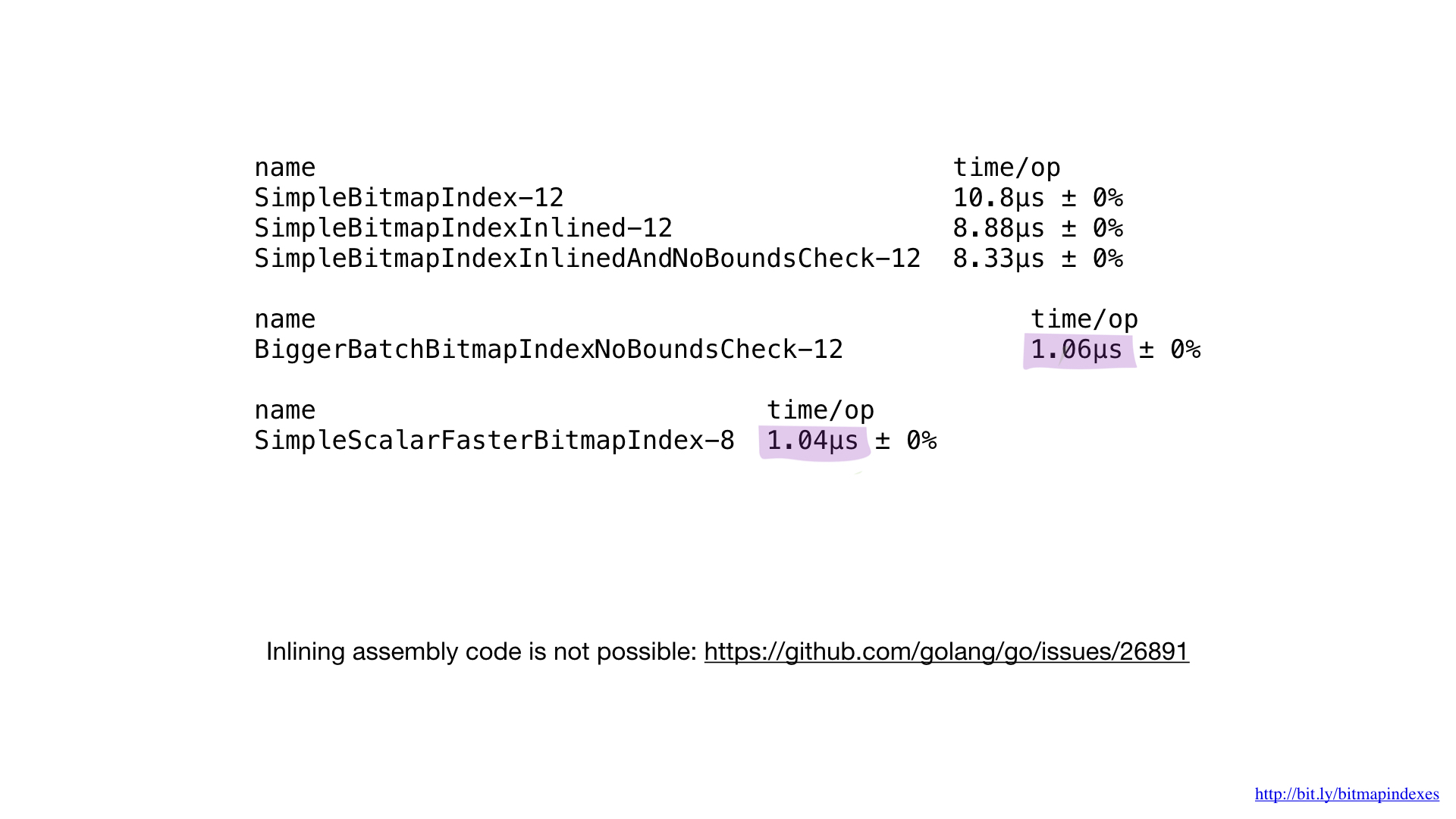
If we compare the performance of the implementation in assembler with the performance of the best implementation in Go, we will see that it is the same. And it is expected. After all, we did not do anything special - we just reproduced what the Go compiler would do.
Unfortunately, we cannot force the compiler to inline our functions written in assembler. The Go compiler does not have this feature today, although the request to add it has been around for quite some time.
That is why it is impossible to get any benefits from small functions in assembler. We need to either write large functions, or use the new math / bits package, or bypass the assembler side.
Let’s now look at the vector versions of our functions.

For this example, I decided to use AVX2, so we will use operations that work with 32-byte chunks. The code structure is very similar to the scalar option: loading parameters, please provide us with a free general register, etc.
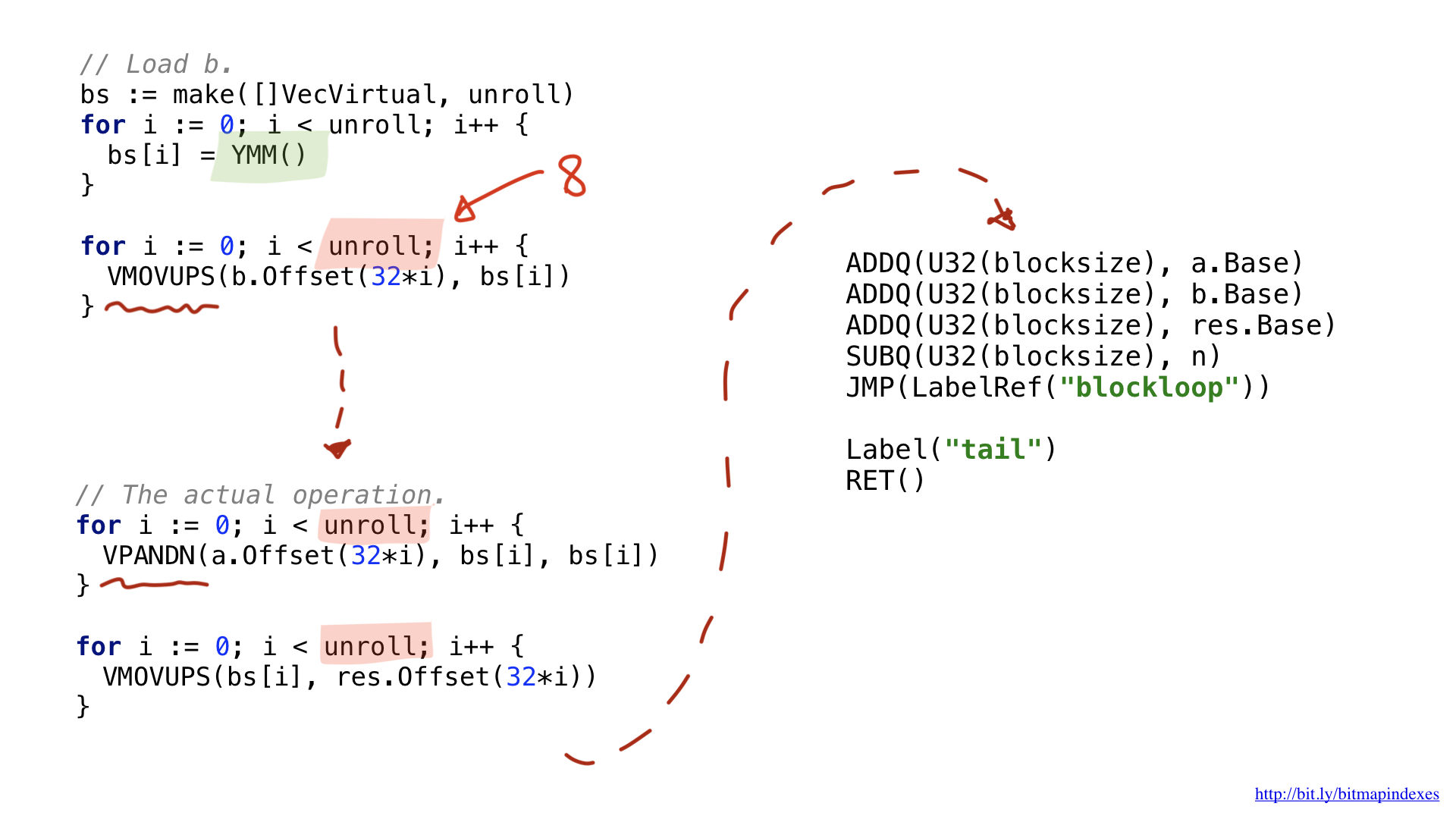
One of the innovations is that wider vector operations use special wide registers. In the case of 32-byte chunks, these are registers with the prefix Y. That is why you see the YMM () function in the code. If I used the AVX-512 with 64-bit pieces, the prefix would be Z.
The second innovation is that I decided to use an optimization called loop unrolling, that is, do eight loop operations manually before jump to the beginning of the cycle. This optimization reduces the number of brunches (branches) in the code, and it is limited by the number of free registers available.
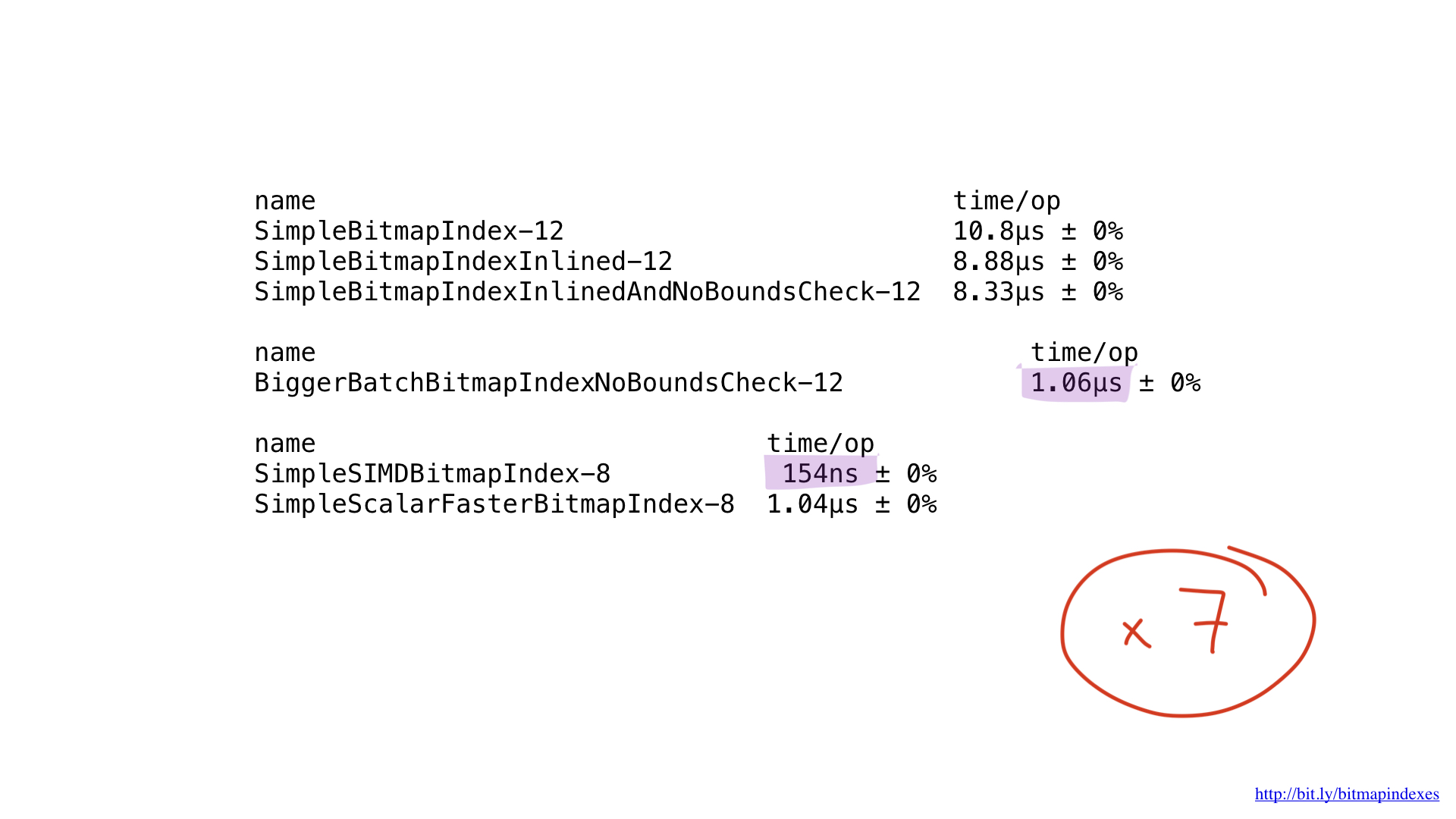
Well, what about performance? She is beautiful! We got acceleration about seven times compared with the best solution on Go. Impressive, huh?
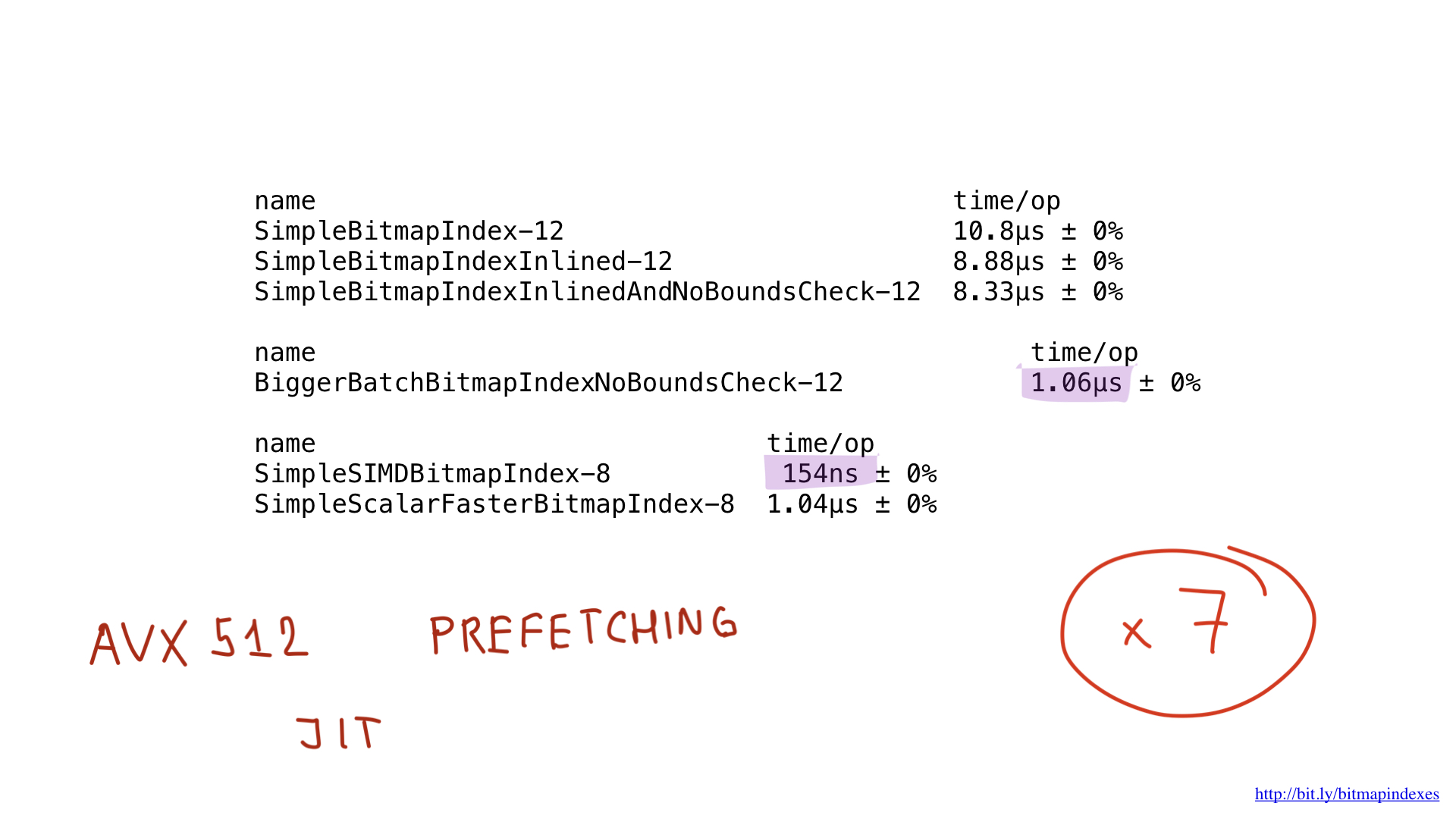
But even this implementation could potentially be accelerated by using AVX-512, prefetching or JIT (just-in-time compiler) for the query planner. But this is certainly a topic for a separate report.
Bitmap Index Issues
Now that we have already looked at a simple implementation of the Go bitmap index and much more efficient assembly language, let's finally talk about why bitmap indexes are so rarely used.

In the old scientific papers, three problems of bitmap indexes are mentioned, but newer scientific papers and I argue that they are no longer relevant. We will not delve deeply into each of these problems, but we shall consider them superficially.
The problem of great cardinality
So, we are told that bitmap indexes are suitable only for fields with low cardinality, that is, those that have few values (for example, gender or eye color), and the reason is that the usual representation of such fields (one bit per value) in case of great cardinality, it will take up too much space and, moreover, these bitmap indexes will be weakly (rarely) filled.
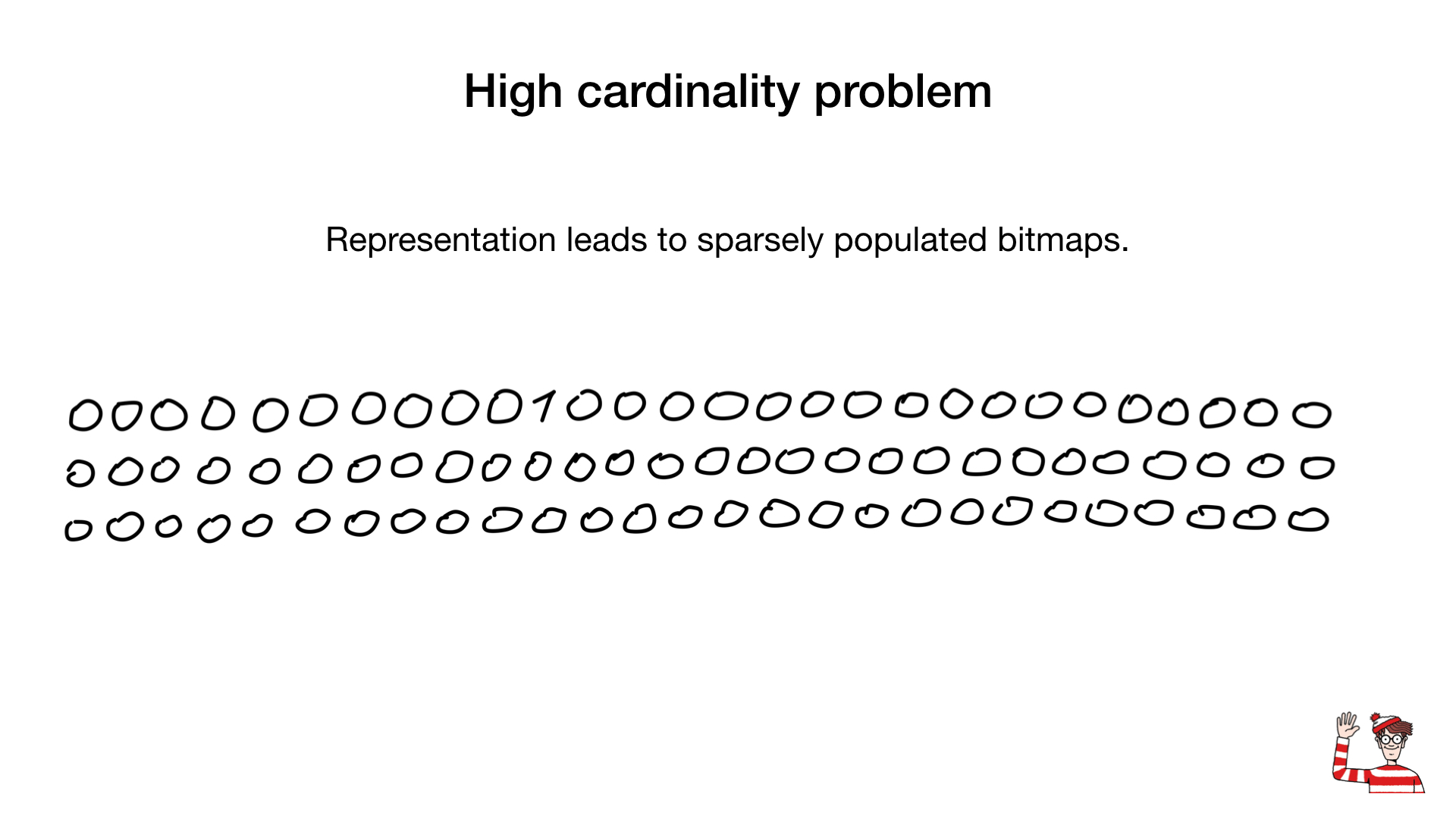
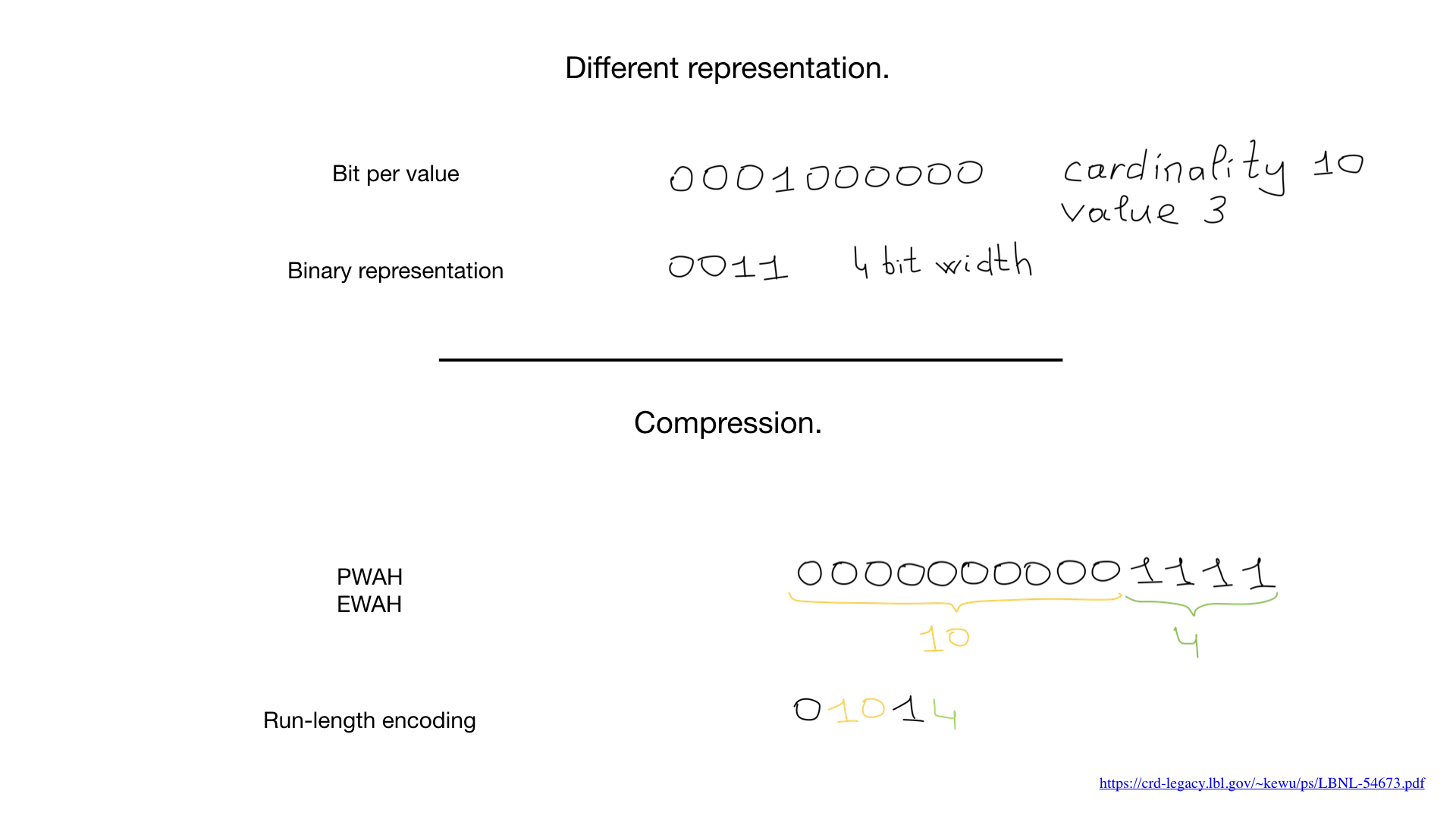
Sometimes we can use another representation, for example the standard one, which we use to represent numbers. But it was the advent of compression algorithms that changed everything. Over the past decades, scientists and researchers have come up with a large number of compression algorithms for bitmaps. Their main advantage is that you do not need to expand the bitmaps for bit operations - we can perform bit operations directly on the compressed bitmaps.

Recently, hybrid approaches have begun to appear, such as roaring bitmaps. They simultaneously use three different representations for bitmaps - actually bitmaps, arrays and the so-called bit runs - and balance between them to maximize performance and minimize memory consumption.
You can meet roaring bitmaps in the most popular applications. There are already a huge number of implementations for a wide variety of programming languages, including more than three implementations for Go.
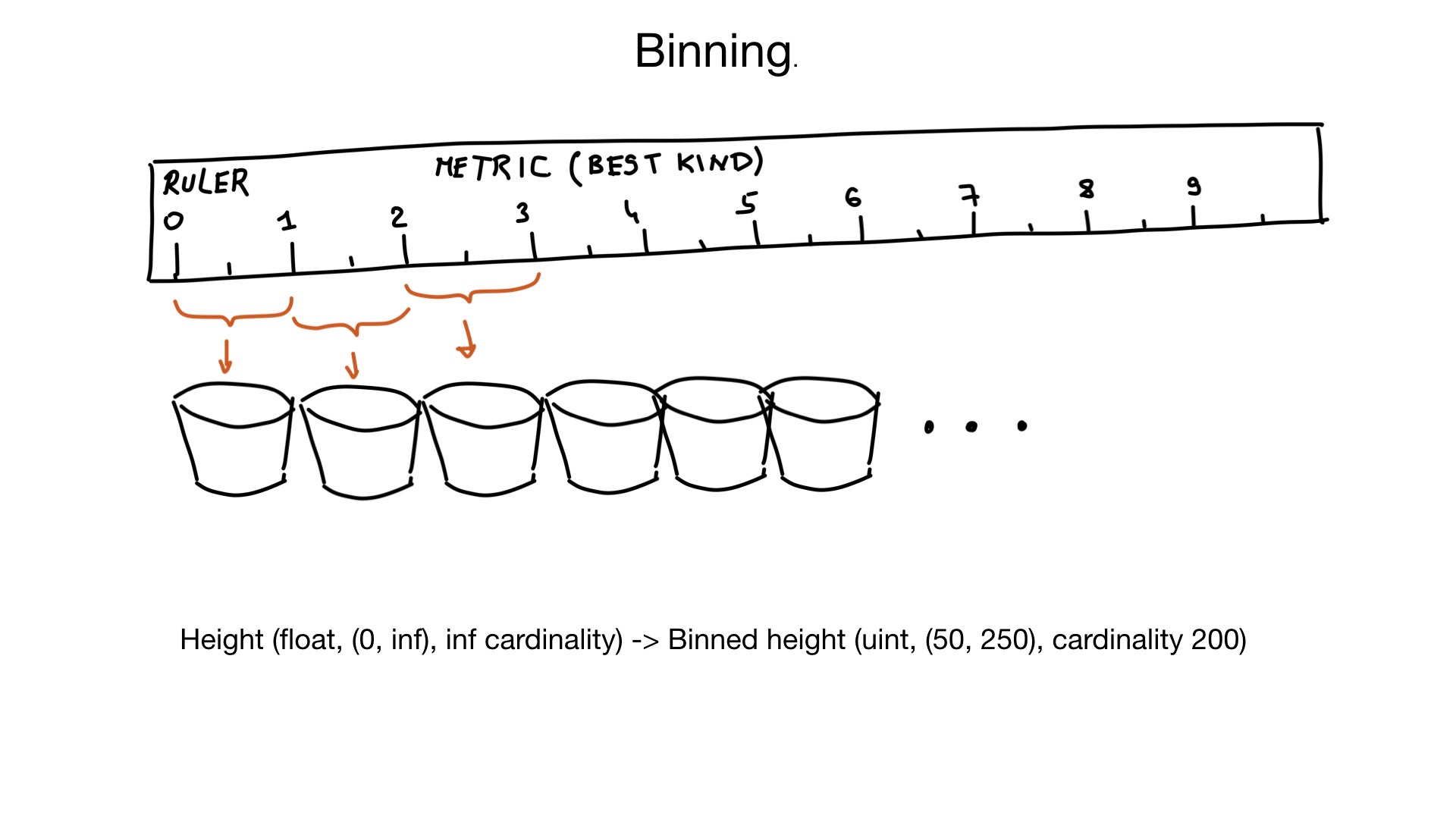
Another approach that can help us cope with great cardinality is called binning. Imagine that you have a field representing the growth of a person. Growth is a floating point number, but we humans don’t think about it in that way. For us, there is no difference between the growth of 185.2 cm and 185.3 cm.
It turns out that we can group similar values into groups within 1 cm.
And if we also know that very few people are shorter than 50 cm and more than 250 cm , then we can, in fact, turn a field with infinite cardinality into a field with cardinality of about 200 values.
Of course, if necessary, we can do additional filtering after.
High throughput problem
The next problem with bitmap indexes is that updating them can be very expensive.
Databases should make it possible to update data at a time when potentially hundreds of other queries search this data. We need locks to avoid problems with simultaneous access to data or other sharing problems. And where there is one big lock, there is a problem - lock contention, when this lock becomes a bottleneck.
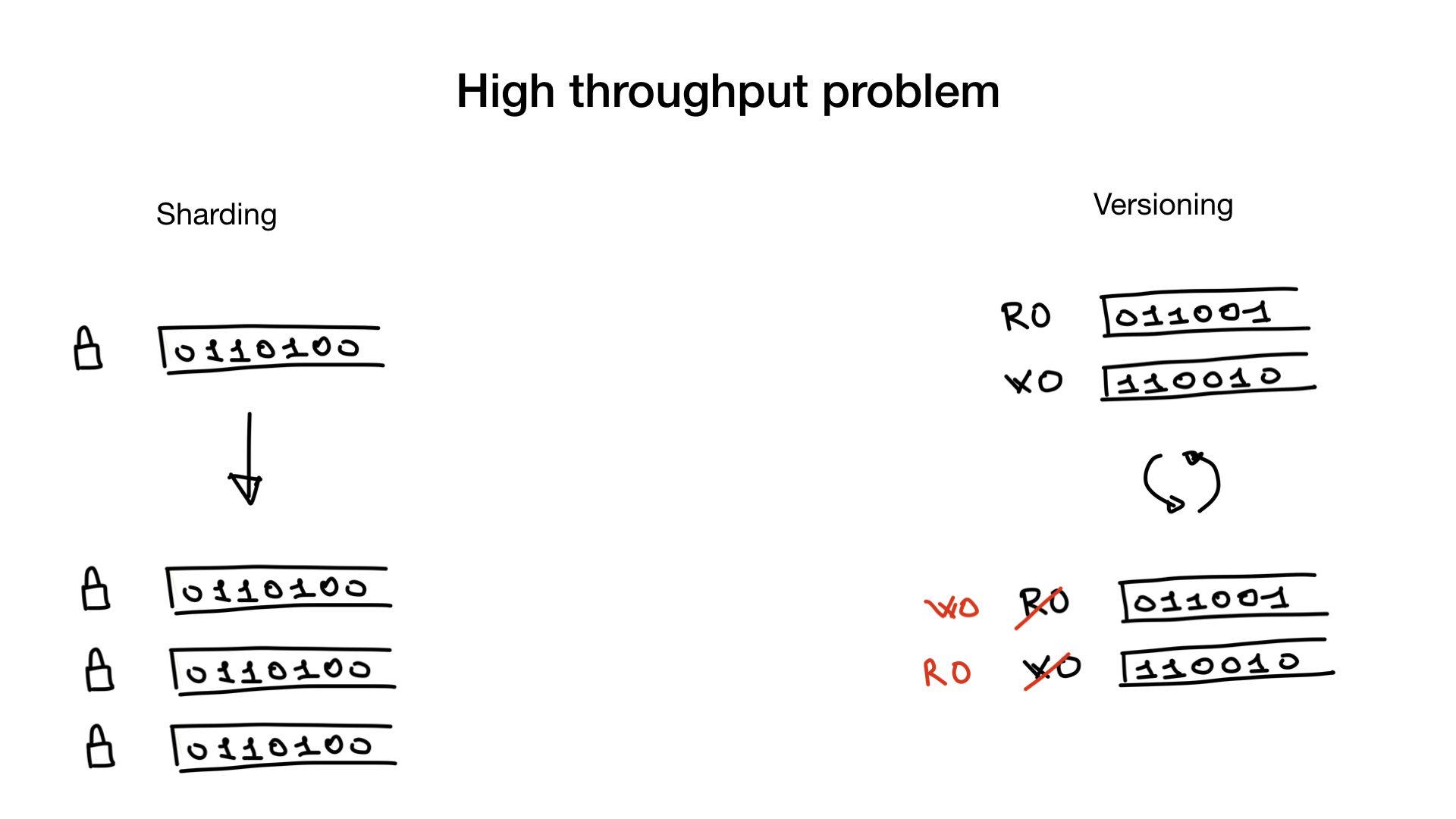
This problem can be solved or circumvented by sharding or using versioned indexes.
Sharding is a simple and well-known thing. You can shard the bitmap index as you would shard any other data. Instead of one large lock, you will get a bunch of small locks and thus get rid of lock contention.
The second way to solve the problem is to use versioned indexes. You can have one copy of the index that you use to search or read, and one to write or update. And once in a certain period of time (for example, once every 100 ms or 500 ms) you duplicate them and swap them. Of course, this approach is applicable only in cases where your application can work with a slightly lagging search index.
These two approaches can be used simultaneously: you can have a sharded versioned index.
More complex queries
The last problem with bitmap indexes is that, as we are told, they are poorly suited for more complex types of queries, such as "in-between" queries.
Indeed, if you think about it, bitwise operations like AND, OR, etc. are not very suitable for requests a la "Show me hotels with room rates from 200 to 300 dollars per night."

A naive and very unreasonable decision would be to take the results for each dollar value and combine them with the bitwise OR operation.

A slightly more correct solution would be to use grouping. For example, in groups of 50 dollars. This would speed up our process by 50 times.
But the problem is also easily solved by using a view created specifically for this type of query. In scientific papers, it is called range-encoded bitmaps.

In this representation, we do not just set one bit for any value (for example, 200), but set this value and all that is higher. 200 and above. The same goes for 300: 300 and higher. Etc.
Using this view, we can answer this kind of search query by going through the index only two times. First, we get a list of hotels where a room costs less than or $ 300, and then we throw out those where the cost of a room is less than or $ 199. Done.

You will be surprised, but even geo-queries are possible using bitmap indexes. The trick is to use the geo-view that surrounds your coordinate with a geometric shape. For example, S2 from Google. The figure should be possible to represent in the form of three or more intersecting lines that can be numbered. In this way, we can turn our geo-request into several “in-between” requests (along these numbered lines).
Ready-made solutions
I hope I'm a little interested in you and you have another useful tool in your arsenal. If you ever need to do something like this, you will know which way to look.
However, not everyone has the time, patience, and resources to create bitmap indexes from scratch. Especially more advanced using SIMD, for example.
Fortunately, there are several ready-made solutions that will help you.

Roaring Bitmaps
Firstly, there is the same roaring bitmaps-library, which I already spoke about. It contains all the necessary containers and bit operations that you will need in order to make a full bitmap index.
Unfortunately, at the moment, none of the Go implementations use SIMD, which means that Go implementations are less productive than C implementations, for example.
Pilosa
Another product that can help you is Pilosa DBMS, which, in fact, has only bitmap indexes. This is a relatively new solution, but it is winning hearts with great speed.
Pilosa uses roaring bitmaps within itself and gives you the opportunity to use them, simplifies and explains all the things that I mentioned above: grouping, range-encoded bitmaps, the concept of a field, etc.
Let's take a quick look at an example of using Pilosa to answer a question already familiar to you.

The example is very similar to what you saw before. We create a client for the Pilosa server, create an index and the necessary fields, then fill our fields with random data with probabilities and, finally, execute a familiar request.
After that, we use NOT on the “expensive” field, then intersect the result (or AND) with the “terrace” field and the “reservations” field. And finally, we get the final result.

I really hope that in the foreseeable future in DBMS like MySQL and PostgreSQL this new type of indexes will also appear - bitmap indexes.

Conclusion

If you haven’t fallen asleep yet, thanks. I had to touch on many topics in passing because of the limited amount of time, but I hope that the report was useful and, perhaps, even motivating.
It's good to know about bitmap indexes, even if you don't need them right now. Let them be another tool in your drawer.
We have covered various performance tricks for Go and the things that the Go compiler does not do very well with. But it is absolutely useful for every Go programmer to know.
That is all I wanted to tell. Thanks!