Report on problems and accessibility of the Internet in 2018-2019

Hello, Habr!
This year, when writing a final document on the company's work for the year, we decided not to retell the news, and although we did not manage to completely get rid of the memories of what happened, we want to share with you what all the same happened to do - collect thoughts together and look where we will certainly find ourselves in the very near future - in the present.
Without unnecessary prefaces, key findings from last year:
- The average duration of DDoS attacks dropped to 2.5 hours;
- 2018 showed the presence of computational power capable of generating attacks with an intensity of hundreds of gigabits per second within a single country or region, leading us to the edge of the “quantum theory of relativity throughput” ;
- The intensity of DDoS attacks continues to grow;
- Together with the simultaneous increase in the proportion of attacks using HTTPS (SSL);
- Personal computers are dead - most of the current traffic is generated on mobile devices, representing a challenge for DDoS organizers and the next challenge for network security companies;
- BGP has finally become an attack vector, 2 years after the time we expected;
- DNS manipulations are still the most destructive attack vector;
- We expect new amplifiers to appear in the future, such as memcached and CoAP;
- “Safe havens” on the Internet no longer exist and all industries are equally vulnerable to cyber attacks of any kind.
Under the cut, we collected the most interesting parts of the report in one place, but you can see the full version here . Enjoy your reading.
Retrospective

The crypt ceased to be interesting to attackers.
In 2018, our company “noted” two record attacks on its own network. Memcached amplification attacks, which we described in detail at the end of February 2018, hit the Qiwi payment system with an intensity of 500 Gbit / s, but were successfully neutralized by the filtering network. At the end of October, we saw another landmark attack - DNS amplification with sources localized within a single country, but with unprecedented power.
DNS amplification has been and remains one of the most well-known vectors of data link layer DDoS attacks and still raises two pressing issues. In the case of an attack with an intensity of hundreds of gigabits per second, there is a considerable chance of overloading the connection to a higher-level provider. How to deal with it? Obviously, it is necessary to distribute such a load across as many channels as possible - which brings us to the second problem - the added network delay as a result of changing traffic paths to the points where it is processed. Fortunately, we coped with the second attack due to flexible load balancing options within the Qrator network.
In this way, balancing has shown us its highest value - since we manage anycast BGP network, our Radar models the distribution of traffic over the network after changing the balancing model. BGP is a distance vector protocol and we are well aware of states, because the distance graph remains almost static. Analyzing these distances taking into account the LCP and Equal-Cost Multipath, we can estimate the AS_path from point A to point B in advance with a high degree of accuracy.
This does not mean that amplification is the most serious threat - no, application-level attacks remain the most successful, invisible and effective, since most of them occur on a low intensity band.
This is the main reason why our company uncompromisingly improves connections with operators at points of presence, at the same time increasing their number. Such a step is logical for any network operator at present, provided that the business is growing. But we continue to believe that the majority of attackers first collect the botnet and only after that begin to choose among the widest list of available amplifiers that can be hit from all possible weapons at the maximum reload rate. Such hybrid attacks have been occurring for a long time, but only recently their intensity, both in terms of the number of packets per second and the active network band, has begun to grow.

Attacks with an intensity above 100 Gbit / s are now clearly visible in the statistics - this is no longer noise
Botnets have significantly evolved in 2018, and their owners have come up with a new occupation - clickfrod . With the improvement of machine learning technologies and getting into the hands of headless browsers that work without a GUI, the clickfrod occupation has become much simpler and cheaper - in just two years.
Today, the average web site receives from 50% to 65% of traffic from mobile devices, their browsers and applications. For some network services, this share can go up to 90% or even 100%, while only desktop websites practically no longer exist, except within corporate environments, or in the form of highly specialized cases.
Personal computers, in fact, disappeared from the peak of the network landscape by 2019, making some past successful techniques, such as mouse tracking, completely inoperative for the purpose of filtering traffic and protecting against bots. In fact, not only personal computers, but also most laptops and all-in-one boxes are rarely the source of a significant percentage of page visits, while easily becoming a weapon. At one time, a simple denial of access to anything that an incorrectly representing mobile browser had recently been quite enough to neutralize attacks from botnets almost completely, leveling the negative effect on key business metrics to zero.
The creators and managers of botnets have become accustomed to the introduction of practices that mimic the behavior of real visitors to pages in their own malicious code, just as web page owners are used to the fact that browsers on personal computers matter. Both are modified, the first is faster than the last.
We have already stated that nothing has changed in 2018, but progress and changes themselves have undergone a significant evolution. One of the most striking examples is machine learning, where improvements and progress were clearly visible, especially in the area of generative-contention networks. Slowly but surely, ML reaches the mass market. Machine learning has already become quite affordable and, as shown by the border of 2018–2019, is no longer limited to the academic branch.
And although we were expecting the appearance of the first ML-based DDoS attacks already by the beginning of 2019, this has not happened yet. Nevertheless, this does not change our expectations, but only heats them, especially considering the decreasing cost of managing neural networks and the constantly increasing accuracy of their analytics.
On the other hand, if we consider the current state of the industry of “automated human individuals”, it becomes clear that the implementation of a neural network in this design is a potentially breakthrough idea. Such a network can learn from the behavior of real people in the context of managing web pages. Such a thing will be called the “user experience of artificial intelligence” and, of course, a similar network armed with a web browser can expand the arsenal of both sides: attacking and defending.
Learning a neural network is an expensive process, but distributing and outsourcing such a system could be cheap, effective, and potentially even free if the malicious code is hidden inside cracked applications, extensions, and much more. Potentially, such a change could change the entire industry in the same way as generative-competitive networks transformed our understanding of “visual reality” and “authenticity”.
Given the ongoing race between the search engines - first of all Google and all others who are trying to carry out their reverse-engineering, the matter can go as far as absolutely fantastic things - such as a bot simulating a single, specific person. As a rule, sitting at a vulnerable computer. The Captcha and ReCaptcha versions of the project can serve as an example of how quickly and strongly the attacker develops and improves their own tools and attack techniques.
After memcached, there was a lot of talk about the likelihood (or improbability) of the emergence of a completely new weapon class for DDoS - vulnerability, bot, incorrectly configured service or something else that will endlessly send data on a specific target chosen by the attacker. One team from an attacker causes a continuous stream of traffic, such as any flood, or sending a syslog. At the moment - this is a theory. We still cannot say whether such servers or devices exist, but if the answer to this question is in the affirmative, it would be an underestimation of the situation to say that such a thing can become an incredibly dangerous weapon in evil hands.
In 2018, we also saw an increasing interest in what is called “Internet governance” and related services by governments and non-profit organizations around the world. We are neutral to such a development of events until the moment when the suppression of fundamental civil and individual freedoms begins, which we hope will not happen in developed countries.
Finally, after years of collecting and analyzing attack traffic around the world, Qrator Labs is ready to implement blocking on the first network request. The models we use to predict malicious behavior allow us to accurately determine the user's legitimacy for each specific page. We continue to insist on our own philosophy of barrier-free entry for the user and unbreakable user experience, without JavaScript checks or captchas, which from 2019 will start working even faster, ensuring the highest level of accessibility of protected services.
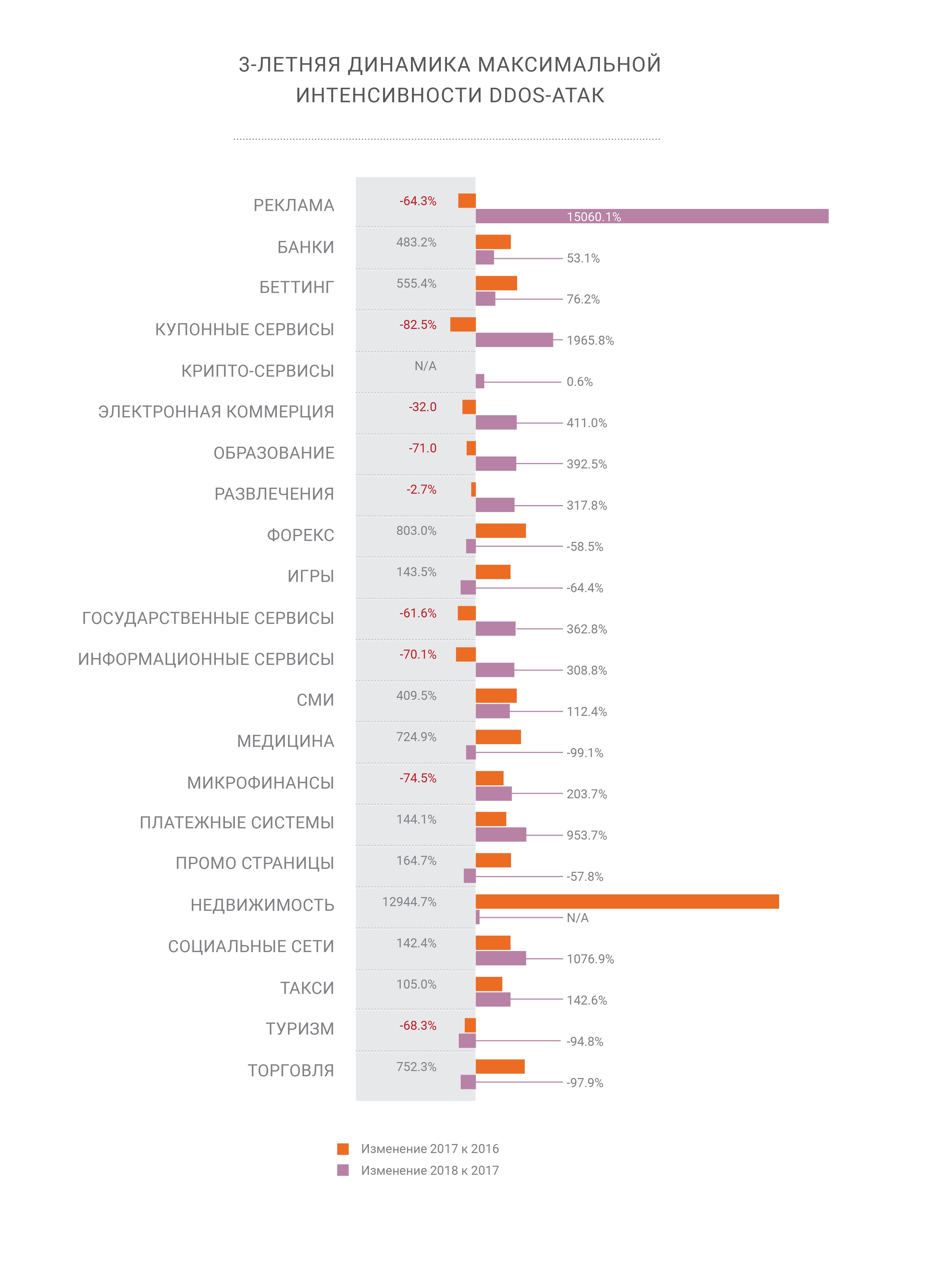
The maximum intensity of the attack strip continues to grow steadily
Mellanox
Our company chose 100G Mellanox switches as a result of internal testing over several years. We still select the equipment that best meets our rather specific requirements in certain conditions in the best possible way. For example, the switch should not dump small packets on the line rate - the maximum speed, even minimal degradation is unacceptable. In addition, the Mellanox switches have a nice price. However, this is not all - the fairness of the price is confirmed by how a particular vendor responds to your requests.
The Mellanox switches work on Switchdev, which turns their ports into simple interfaces inside Linux. Being part of the main Linux kernel, Switchdev provides a convenient way to control the device using clear and familiar interfaces, under a single API, to which any modern programmer, developer and network engineer is absolutely familiar. Any program using the standard Linux network API can be run on a switch. All network activity monitoring and management, created for servers on Linux, including possible own solutions, are easily accessible. To illustrate the changes that occurred with the active development of Switchdev, we note that the modification of the routing tables has become several times faster and more convenient with Switchdev. To the very level of the network chip, all code is visible and transparent,
The Medevanox device under control of Switchdev turned out to be a long-awaited combination, which we waited so long for, but what's even better - the manufacturing company met all expectations and requirements, not only in the issue of full support of the free operating system out of the box.
Testing the equipment before commissioning, we found that part of the redirected traffic is lost. Our investigation revealed that this was due to the fact that traffic to one of the interfaces was sent using a control processor that could not cope with its high volume. Not being able to determine the exact cause of this behavior, we, however, suggested that this is due to the processing of ICMP redirects. Mellanox confirmed the source of the problem, and therefore we asked to do something with this device behavior, to which the company responded instantly, providing a working solution in a short time.
Great job, Mellanox!
Protocols and open source
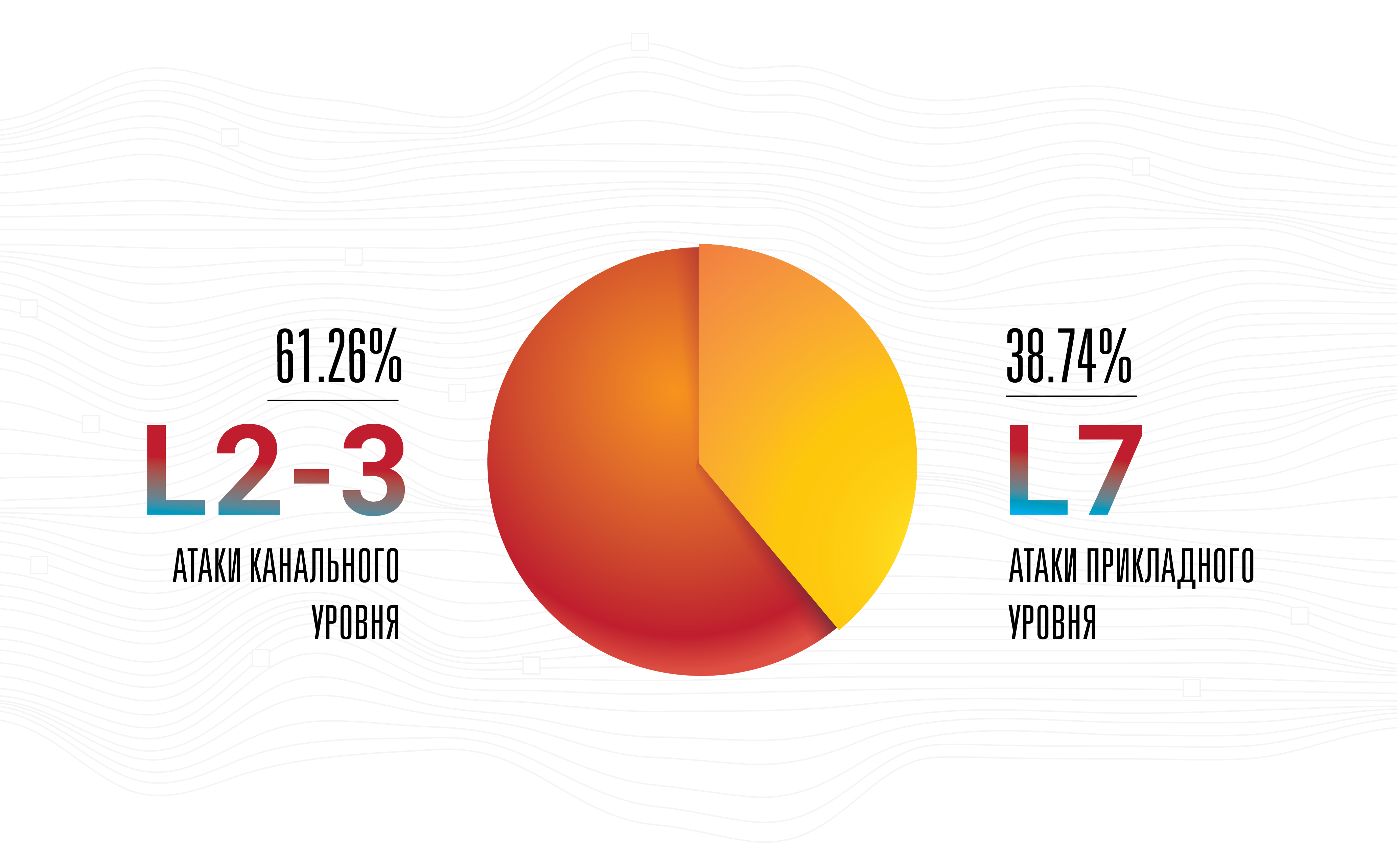
DNS-over-HTTPS is a more comprehensive technology than DNS-over-TLS. We observe how the first flourishes, while the second is slowly forgotten. This example is good because in this particular case “complexity” means “efficiency”, since DoH traffic is indistinguishable from any other HTTPS. We have already seen the same thing with the integration of RPKI data, which was initially positioned as a solution for anti-interception and, as a result, nothing good happened to it. After some time, RPKI reappeared on the scene, as a powerful tool against such anomalies as route leaks and incorrect routing settings. And now the noise was transformed into a signal, and RPKI began to be supported at the largest traffic exchange points, which is excellent news.
TLS 1.3 arrived too. Qrator Labs, like the entire information technology industry, closely followed the process of developing a new encryption standard at every stage, from the initial draft in the IETF to an understandable and manageable protocol that we are ready to support starting from 2019. The market reacted similarly, promising the speedy implementation of a trusted security protocol. It is possible that not all manufacturers of solutions to neutralize DDoS can equally quickly adapt to the changed reality, because of the technical complexity of supporting the protocol in the gland there may be explainable delays.
We are also following the ongoing development of HTTP / 2. Currently, we do not support the new version of the HTTP protocol, primarily because of the imperfection of the current code base. Bugs and vulnerabilities are still too often found in the new code; As a security solution provider, we are not yet ready to support this protocol under the SLA, which our consumers agreed to.
In 2018, we often asked ourselves the question: “Why do people want HTTP / 2 so much?” That caused a lot of fierce debate. People are still inclined to think of things with the prefix “2” as “better” versions of anything, which is especially true in the case of some aspects of the implementation of this protocol. However, DoH recommends the use of HTTP / 2 and, quite possibly, this synergy will give rise to a high degree of market acceptance of both protocols.
One of the experiences when considering the development of next-generation protocols and their planned capabilities is the fact that very often the development does not go beyond a purely academic level, not to mention such extreme cases as the creators of the protocols of cases like the neutralization of DDoS attacks. Perhaps this is the reason why cyber and info security companies make little effort to develop such standards. Section 4.4The IETF draft, called QUIC manageability, which is part of the future QUIC protocol package, is simply an ideal example of this approach: it states that "current practices in detecting and neutralizing [DDoS attacks] mostly involve passive measurement using network data level ". The latter is extremely rarely used in practice, with the exception of ISP networks and it is unlikely to be a “common case” in practice. However, in academic research paper, “general cases” are formed in this way, with the result that the final protocol standards are simply not applicable in production, after performing such simple manipulations before commissioning, such as testing under load and simulating application-level attacks on an application, using. Given the ongoing process of TLS implementation in the global Internet infrastructure, the allegation of any passive monitoring is generally seriously questioned. Building valid academic research is another challenge for security solution providers in 2019.
At the same time, Switchdev fully met the expectations that were laid in it a year ago. We hope that incessant work on Switchdev will lead the community and the common fruit of work to excellent results in the near future.
Further development and introduction of Linux XDP will help the industry achieve high efficiency of network packet processing. Shipment of some filtering patterns of illegitimate traffic from the central processor to the network processor, and in some cases even to the switch, already looks promising and our company continues its own research and development in this area.
Deep dive with bots
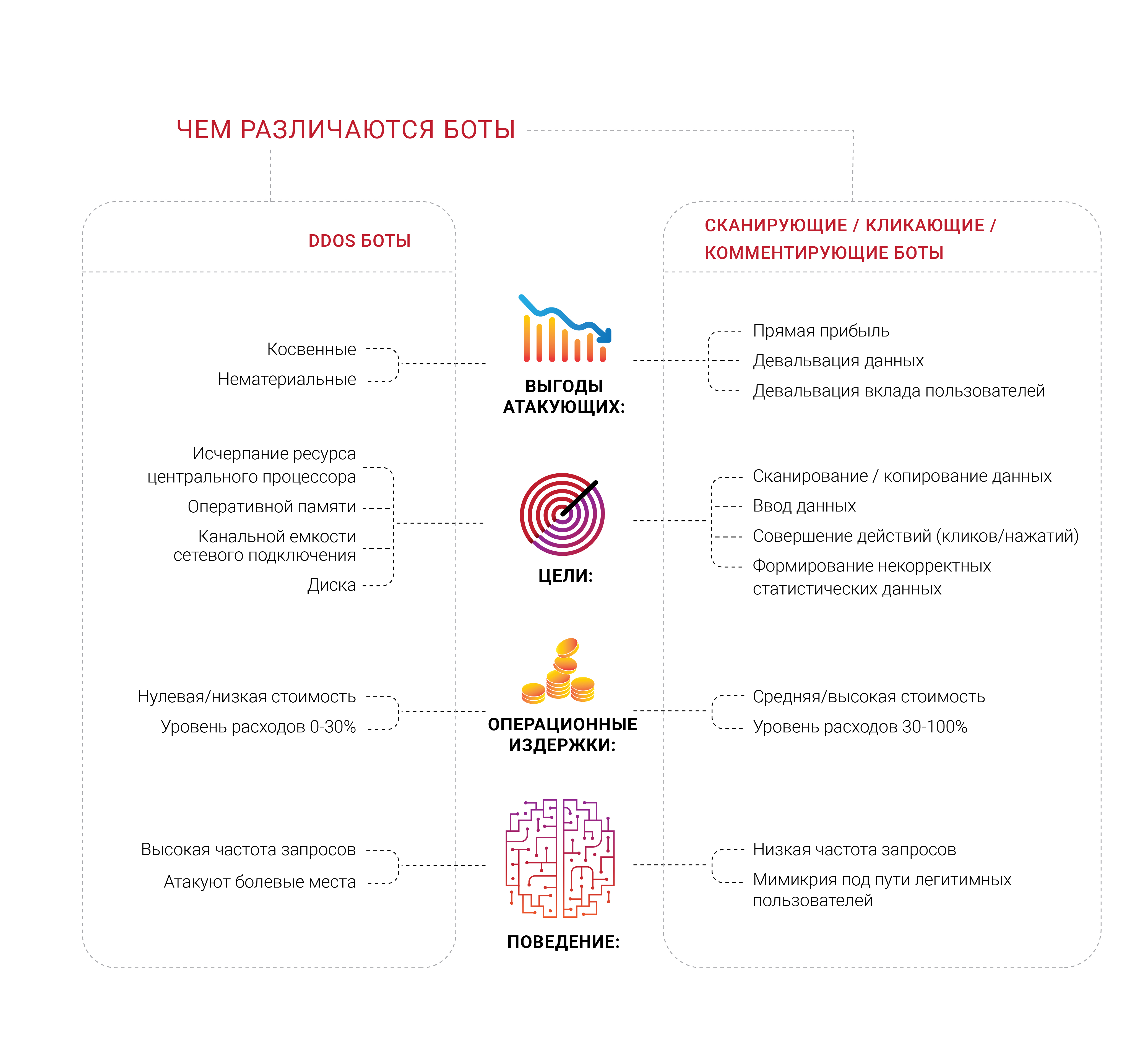
Many companies seek protection from bots and, not surprisingly, we saw a large number of diverse groups of professionals working on various areas of this problem in 2018. What seems interesting to us separately is that the majority of companies that form such demand have never experienced a targeted DDoS attack, at least typical, aimed at the exhaustion of finite resources, such as memory, processor or network connection channel. They are afraid of bots, but cannot distinguish them from legitimate users or determine what exactly they are doing. Most of the sources of such complaints want to get rid of the feeling that not real people come to their pages.
The issue of bots-scanners and many other subspecies is a very important economic component. If 30% of traffic is illegitimate and comes from unwanted sources, then 30% of the cost of supporting such traffic is thrown into the garbage, according to the logic of costs. Today we can consider this as the inevitable "Internet tax" on business. This number is almost impossible to reduce to zero, but business owners, if possible, want to see this percentage as low as possible.
Identification becomes an extremely serious problem and task in the modern Internet, since the most advanced bots do not even try to depict a person - they control it and are in the same space with it, similar to the parasites. We have been repeating for a long time that any information that is publicly available, without authentication and authorization, is and, ultimately, will end its existence in the form of public domain — no one can prevent it.
Considering this issue, we focused on the identification and management of bots. However, in our opinion, a wide range of work is much more interesting - we live in an era when it is no longer possible to know why a particular client requests something from the server. You read it right - in the end, any business wants to know that the consumer has come to buy, because this is the goal of his business, existence. Therefore, some companies want to look into the depth of who and what requests from their servers - is there a real person behind the request?
It’s not surprising, as a result, that business owners often find out that a significant proportion of their website’s traffic is generated by robots, and not by any buyers.
Automated human individuals, which we have already mentioned in a different context, can be targeted to much more specific network resources using things that are almost imperceptible, such as browser extensions. We already know that very many extensions that are so far hardly called “malicious” exist solely for the purpose of collecting and analyzing the behavior of a real user. But there are completely different things - where automation cannot pass the obstacle in front of it, people appear with browser modifications and perform all the same simple actions, perhaps only slightly more expensive for organizers. In addition, a number of tasks, such as advertising and clickfodder manipulations, are much more efficiently performed with a real person in front of the screen. Just imagine what might happen
Parsers and scanners, which are part of a broad bot problem, reached our horizon only in 2018 and, first of all, thanks to our consumers who informed us about their own experience and provided an opportunity to study and analyze more deeply what was happening on their network resources. Such bots may not even be visible at the level of standard metrics, such as the average network bandwidth used or server CPU utilization. At the moment, Qrator Labs is testing a variety of approaches, but one thing is clear - our consumers want malicious bots in their opinion to be blocked on the very first request to the server.
During the epidemic of parsing, which we observed in Russia and the CIS throughout the second half of 2018, it became obvious that bots were well advanced in encryption issues. One request per minute is quite normal intensity for a bot, which is very difficult to notice without analyzing requests and outgoing response traffic. In our humble opinion, only a consumer has the right to decide what to do with any undesirable source of requests after analyzing and marking traffic. Block, skip, or deceive is not for us to decide.

However, purely automatic solutions, or as we used to call them - “bots”, have certain difficulties in interaction. If you are sure that it was the bot that generated the unwanted and very specific request, the first thing that the majority wants to do is to block it without responding from the server. Nevertheless, we came to the conclusion that this approach is meaningless, because it gives too much feedback to both the bot and its creator and encourages them to look for a workaround. If bots do not try to take the service out of working condition, by and large we advise you not to preach such an approach - as a result of playing cat and mouse, a rather purposeful malefactor will almost always pass you in pursuit of the goal, no matter what it is.
This is also the reason why Qrator Labs has taken a malware labeling approach, as well as all traffic in general, in order to provide the application owner with maximum data and opportunities to make an informed decision, having considered the possible implications for users and business goals. One of the good examples illustrating the possible consequences are ad blockers. Most of the modern advertising on the Internet is presented in the form of scripts, blocking which you will not necessarily block advertising, and not, say, a javascript-check of the DDoS protection service. It is easy to imagine where this path can lead, ultimately resulting in a decrease in the profits of the Internet business.
When the attackers block and get the feedback they need, nothing prevents them from adapting, learning and attacking again. Our technologies are built around a simple philosophy that providing feedback to robots is not necessary - you need to either block or skip them, but simply to detect and label. After such marking has been made and we are sure of its accuracy, it’s right to ask the following question: “What do they need?” And “Why are they interested in this?” It is probably enough to slightly change the content of the web page so that no a living person does not feel the difference, but the reality of the bot is turned upside down? If these are parsers, then it is possible that a certain percentage of the data will turn out to be incorrect and fake, but this will in any case deduce the protection from the search for binary zero or one and give
Discussing this issue throughout 2018, we called attacks, such as those described, attacks on business metrics. The website, the application and the server can work just fine, and no user will complain, but you still feel something ... like the fall of the CPA from the ads you take to place on the programmatic platform, pushing advertisers towards it, not even your competitors.
Reducing an attacker's encouragement is the only way to counter. Attempting to stop bots will bring nothing but time and money spent. If anything clicks on what gives you a profit - cancel these clicks; if you are parsed, you can turn on the layer of “fake” information, through which the usual, curious, user will easily pass in search of correct and reliable information.
Clickhouse
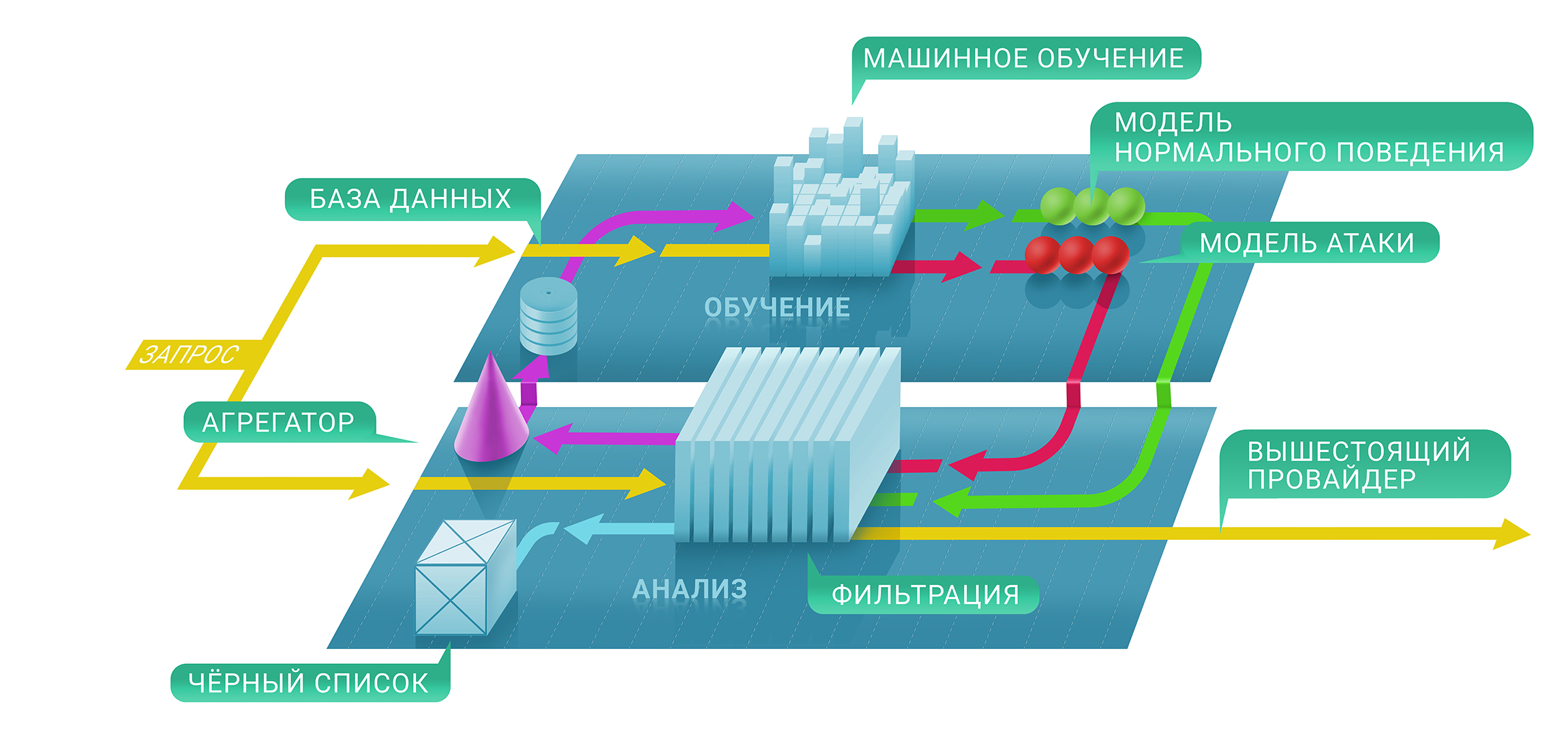
At a high level, the Qrator filtering service consists of two levels: on the first, we immediately assess if a particular request is malicious with the help of stateful and non-existent checks and, secondly, decide whether to detain the source on the black list and for how long . The resulting blacklist can be presented in the form of a unique table of IP addresses.
At the first stage of this process, we will use machine learning techniques in order to better understand the natural levels and characteristics of traffic for each resource separately, since each protection parameter of each individual service is configured individually based on the metrics we collect.
This is where Clickhouse comes into play. In order to better understand why a specific IP address was blocked from communicating with a resource, we need to trace the entire machine learning path down to the Clickhouse database. It works very fast with large chunks of data (imagine a 500 Gbit / s DDoS attack and lasting several hours of clean time out of pauses) and stores them in a convenient form for the machine learning framework used in Qrator Labs. More logs and more saved DDoS attack traffic lead to accurate results from our models, helping to fine-tune the filtering service in real time, under the most serious attacks.
We use Clickhouse DB to store all logs of illegitimate traffic of attacks and patterns of behavior of bots. This specialized solution was chosen by us because of the high potential of storing massive datasets in the style of a classic database for further processing. Analysis of this data is also used to build patterns of DDoS attacks, helping machine learning to constantly improve our traffic filtering algorithms.
A significant advantage of Clickhouse, in comparison with other databases, is that it does not need to read the whole string variable of the data - it can take a much smaller, strictly necessary segment if you store everything according to recommendations. And it works, fast!
Conclusion

For a long time, we have been living in the world of multifactor attacks, exploiting the attacking capabilities of several protocols at once to remove the target from its operational state.
Digital hygiene and current security measures should and, in fact, cover about 99% of the existing risks that an ordinary user can meet, with the exception of only, perhaps, highly specialized attacks on specific targets.
On the other hand, in the modern Internet there are sharks that can bite the availability of entire states. This does not apply to BGP, where it is possible to extinguish only certain points on any map that the attacker wants to draw.
The level of knowledge regarding network security continues to grow. However, if you look at the numbers related to the number of amplifiers in the networks or look for the possibility of forging requests - the number of vulnerable services and servers does not fall. The daily pace of young people acquiring knowledge of the skills of programming and managing computer networks does not correspond to the time needed to gain relevant experience in real life. The confidence that new vulnerabilities do not come out with new products is acquired for a long time, and most importantly - it hurts.

One of the most surprising discoveries of the past year was that most people expect much more from new technologies than they can provide. This was not always the case, but right now we are witnessing the growing tendency of people to “demand more”, regardless of the capabilities of software and, even more, hardware. This leads us into a world of quite perverted marketing campaigns. But people, nevertheless, continue to “buy promises” and companies, in turn, feel obliged to fulfill them.
Perhaps this is the essence of progress and evolution. Now many are upset because of the fact of not receiving the "guaranteed" and of what the funds were paid for. Because of the impossibility of “completely” buying a device from the manufacturer, many of the current problems are growing, but in the opposite direction, the cost of “free” services can be simply fabulous if you consider the cumulative cost of the data that a large social network does not require payment from the user.
Consumerism tells us that if we want something very strongly, then ultimately we will pay with our own lives. Do we really need such products and services that improve ourselves only in order to offer us “improved offers” based on the data that we have collected about us, do we like it or not? However, this seems to be the near future, as we have been shown with Equifax and Cambridge Analytica recently. It is not surprising if in front of us there is a “big bang” waiting for the use of personal and other data concerning each individual life.
After ten years of work, we have not changed the key principles on the architecture of the Internet. This is the reason why we continue to develop the BGP anycast filtering network with the ability to handle encrypted traffic in this form, avoiding captcha and other obstacles unexpected for the legitimate user.
Watching what continues to happen with cybersecurity experts, as well as the companies in this field, we once again want to repeat the obvious: a naive, simple and fast approach is inapplicable.
Therefore, Qrator Labs does not have hundreds or even dozens of points of presence comparable to a CDN. By managing a smaller number of filtering centers, each of which is connected to Internet providers with a class not lower than Tier-1, we are achieving true decentralization. For the same reason, we are not trying to build our own firewall, which is a task of a completely different level than the one we are working on - connectivity.
For many years, we said that in the end neither captcha nor javascript checking would work, and here we are in 2019, when neural networks became highly efficient in solving the first, and the latter never presented a problem for the attacker with the brain.
I would like to note another interesting change at the time boundary: DDoS attacks for a long time were a serious problem only for a limited number of business sectors, usually those where money jiggles on the surface: e-commerce, trading and stock exchange, banking and payment systems. But with the continued development of the Internet, we are witnessing DDoS attacks of increased intensity and frequency in absolutely all parts of the Internet. The DDoS era began at a certain threshold for the throughput of home routers and, not surprisingly, with the advent of a microchip in each physical thing around, the landscape of attacks began to change rapidly.
The one who expects the end of the development of this trend is most likely wrong. Just like we are wrong, having written so many predictions. No one can say for sure how the Internet will develop and distribute its own influence in the coming years, but looking back at what we have seen, one thing is clear - everything will increase. In 2020, the number of devices connected to the network should exceed 30 billion, not to mention the simple fact that robots have long since generated much more traffic than people. Soon we will have to decide what to do with all this “intellect”, artificial or not, since we still exist in a world where a human is responsible for its actions, correct or not.
2018 was a year of opportunity for the dark side. We also saw an increase in attacks, with their simultaneous complication and an increase in both volume in network terms and frequency. The villains got powerful tools and spent a lot of time studying them, while the good guys did nothing more than watch them progress. We sincerely hope that in the current year at least something will change, at least in the most painful places.
→ Link to the full version of the report in Russian.