What is special about Cloudera and how to cook it
The market for distributed computing and big data, according to statistics , is growing at 18-19% per year. So, the question of choosing software for these purposes remains relevant. In this post, we will start with why distributed computing is needed, dwell on the choice of software, talk about using Hadoop with Cloudera, and finally, let's talk about choosing hardware and how it affects performance in different ways.

Why do we need distributed computing in a regular business? Everything is simple and complicated at the same time. Simple - because in most cases we perform relatively simple calculations per unit of information. It’s difficult because there is a lot of such information. Lots of. As a result, you have to process terabytes of data in 1000 threads . Thus, the usage scenarios are quite universal: calculations can be applied wherever it is necessary to take into account a large number of metrics on an even larger array of data.
One recent example: a pizzeria chain Dodo Pizza identifiedbased on an analysis of the customer order base, when choosing a pizza with arbitrary filling, users usually operate with only six basic sets of ingredients plus a couple of random ones. In accordance with this, the pizzeria adjusted purchases. In addition, she was able to better recommend to users additional products offered at the order stage, which helped to increase profits.
Another example: the analysis of commodity positions allowed the H&M store to reduce the range in individual stores by 40%, while maintaining the level of sales. This was achieved by eliminating poorly selling positions, and seasonality was taken into account in the calculations.
The industry standard for this kind of computing is Hadoop. Why? Because Hadoop is an excellent, well-documented framework (the same Habr issues a lot of detailed articles on this topic), which is accompanied by a whole set of utilities and libraries. You can input huge sets of both structured and unstructured data, and the system itself will distribute them between computing power. Moreover, these same capacities can be increased or disabled at any time - the same horizontal scalability in action.
In 2017, the influential consulting company Gartner concludedthat Hadoop will soon be obsolete. The reason is pretty banal: analysts believe that companies will massively migrate to the cloud, because there they can pay for the fact of using computing power. The second important factor, supposedly able to "bury" Hadoop - is the speed of work. Because options like Apache Spark or Google Cloud DataFlow are faster than the MapReduce underlying Hadoop.
Hadoop rests on several pillars, the most notable of which are MapReduce technologies (a data distribution system for computing between servers) and the HDFS file system. The latter is specifically designed to store information distributed between nodes in a cluster: each block of a fixed size can be placed on several nodes, and thanks to replication, the system is immune to individual node failures. Instead of a file table, a special server called NameNode is used.
The illustration below shows the MapReduce workflow. At the first stage, the data is divided according to a certain characteristic, at the second - they are distributed according to computing power, at the third - the calculation is performed.
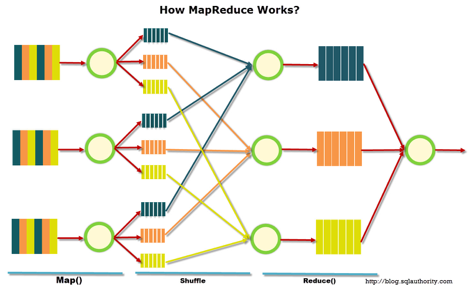
MapReduce was originally created by Google for the needs of its search. Then MapReduce went into free code, and Apache took up the project. Well, Google has gradually migrated to other solutions. An interesting nuance: at the moment Google has a project called Google Cloud Dataflow, positioned as the next step after Hadoop, as a quick replacement.
A closer look reveals that Google Cloud Dataflow is based on a variety of Apache Beam, while Apache Beam includes a well-documented Apache Spark framework, which allows us to talk about almost the same speed of decision execution. Well, Apache Spark works fine on the HDFS file system, which allows you to deploy it to Hadoop servers.
We add here the volume of documentation and turnkey solutions for Hadoop and Spark against Google Cloud Dataflow, and the choice of the tool becomes obvious. Moreover, engineers can decide for themselves which code - under Hadoop or Spark - to execute for them, focusing on the task, experience and qualifications.
The trend towards a universal transition to the cloud has even generated such an interesting term as Hadoop-as-a-service. In this scenario, the administration of the connected servers has become very important. Because, alas, in spite of its popularity, pure Hadoop is quite a difficult tool to configure, since a lot of things have to be done with your hands. For example, individually configure the servers, monitor their performance, carefully configure many parameters. In general, working for an amateur is a great chance to screw up something or to miss something.
Therefore, various distributions, which are initially equipped with convenient deployment and administration tools, gained great popularity. One of the most popular distributions that support Spark and make things easy is Cloudera. It has both a paid and a free version - and in the latter all the basic functionality is available, and without limiting the number of nodes.

During setup, Cloudera Manager will connect via SSH to your servers. An interesting point: during installation it is better to indicate that it should be carried out by the so-called parcels : special packages, each of which contains all the necessary components that are configured to work with each other. In fact, this is such an improved version of the package manager.
After installation, we get the cluster management console, where you can see telemetry by cluster, installed services, plus you can add / remove resources and edit the cluster configuration.
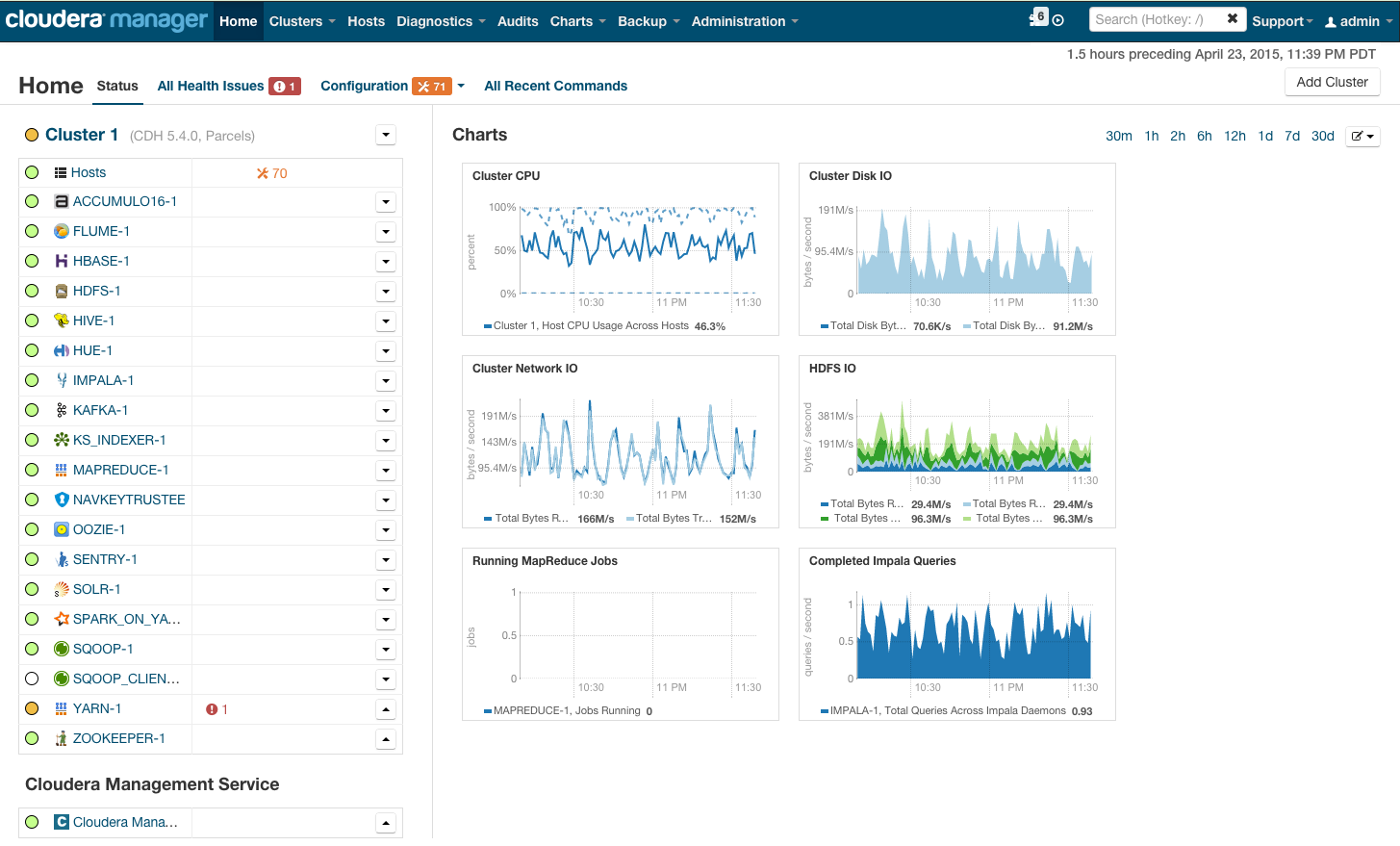
As a result, you see the cabin of the rocket that will take you to the bright future of BigData. But before you say “let's go,” let's get under the hood.
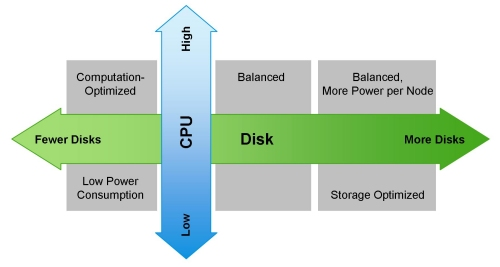
Cloudera mentions various possible configurations on its website. The general principles by which they are built are shown in the illustration:
To lubricate this optimistic picture can MapReduce. If you look again at the diagram from the previous section, it becomes obvious that in almost all cases the MapReduce job may run into a bottleneck when reading data from disk or from the network. This is also featured on the Cloudera blog. As a result, for any fast calculations, including through Spark, which is often used for real-time calculations, I / O speed is very important. Therefore, when using Hadoop, it is very important that balanced and fast machines get into the cluster, which, to put it mildly, is not always provided in the cloud infrastructure.
Balanced load balancing is achieved through the use of Openstack virtualization on servers with powerful multi-core CPUs. Data nodes are allocated their processor resources and specific disks. In our Atos Codex Data Lake Engine solution, broad virtualization is achieved, which is why we win both in performance (the influence of network infrastructure is minimized) and in TCO (unnecessary physical servers are eliminated).
In the case of using BullSequana S200 servers, we get a very uniform load, devoid of some bottlenecks. The minimum configuration includes 3 BullSequana S200 servers, each with two JBODs, plus optional additional S200s containing four data nodes are optionally connected. Here is an example of the load in the TeraGen test:
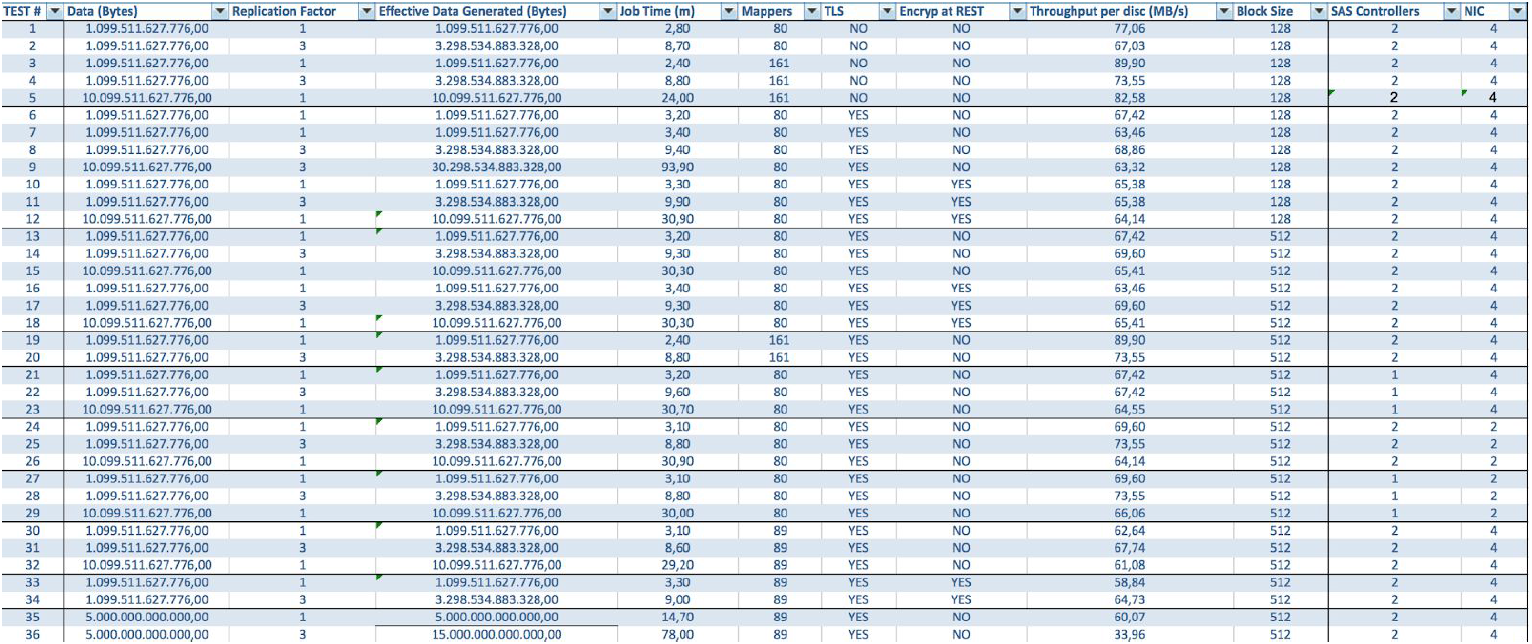
Tests with different data volumes and replication values show the same results in terms of load distribution between cluster nodes. Below is a graph of the distribution of disk access by performance tests.
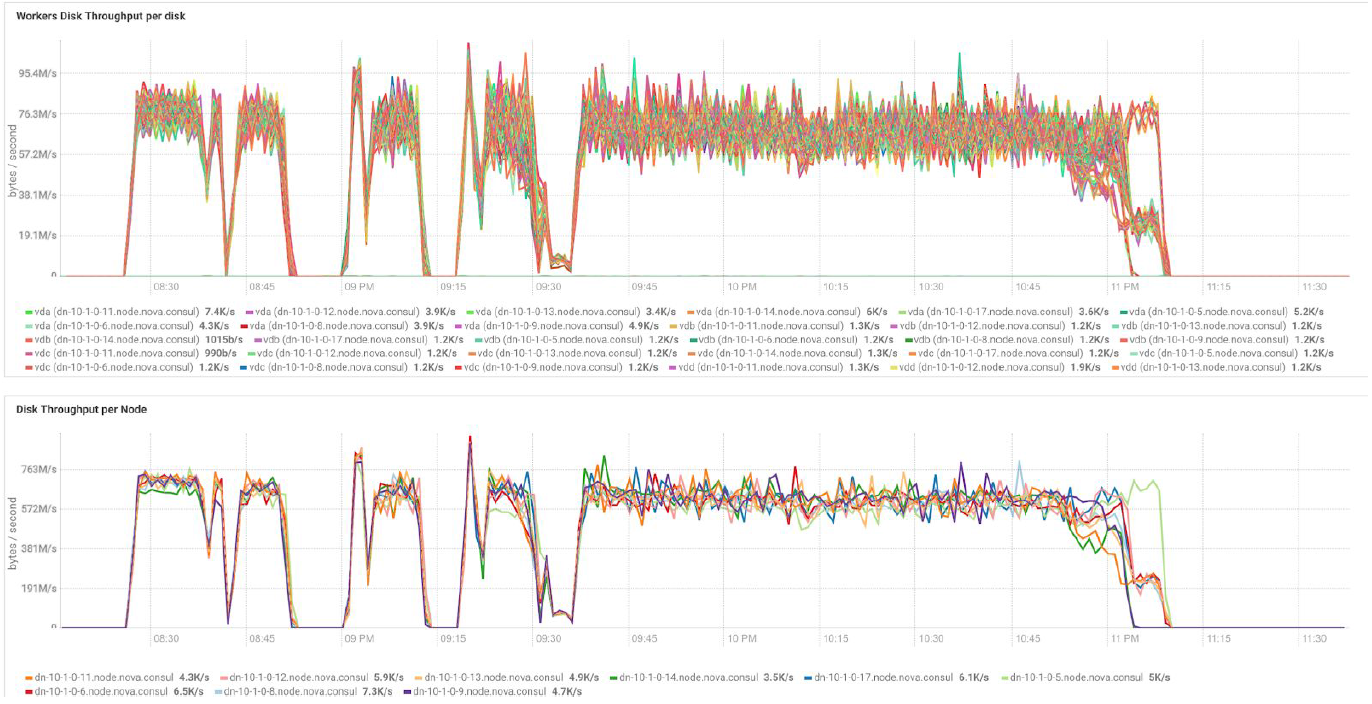
The calculations are based on the minimum configuration of 3 BullSequana S200 servers. It includes 9 data nodes and 3 main nodes, as well as reserved virtual machines in case of deployment of protection based on OpenStack Virtualization. TeraSort test result: 512 MB block size of the replication coefficient of three with encryption is 23.1 minutes.
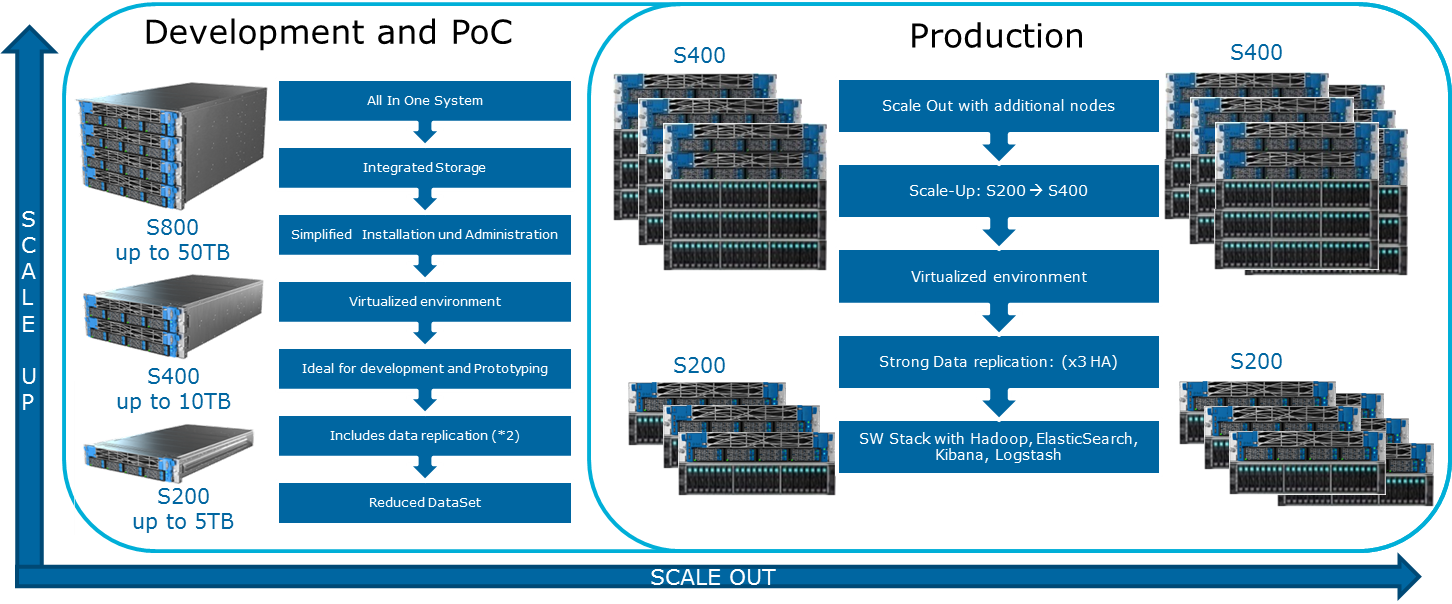
How can I expand the system? Various types of extensions are available for the Data Lake Engine:
Atos Codex Data Lake Engine includes both the servers themselves and pre-installed software, including a licensed Cloudera suite; Hadoop itself, OpenStack with virtual machines based on the RedHat Enterprise Linux kernel, a data replication system and backup (including using the backup node and Cloudera BDR - Backup and Disaster Recovery). The Atos Codex Data Lake Engine was the first virtualization solution certified by Cloudera .
If you are interested in the details, we will be happy to answer our questions in the comments.
Why do we need distributed computing in a regular business? Everything is simple and complicated at the same time. Simple - because in most cases we perform relatively simple calculations per unit of information. It’s difficult because there is a lot of such information. Lots of. As a result, you have to process terabytes of data in 1000 threads . Thus, the usage scenarios are quite universal: calculations can be applied wherever it is necessary to take into account a large number of metrics on an even larger array of data.
One recent example: a pizzeria chain Dodo Pizza identifiedbased on an analysis of the customer order base, when choosing a pizza with arbitrary filling, users usually operate with only six basic sets of ingredients plus a couple of random ones. In accordance with this, the pizzeria adjusted purchases. In addition, she was able to better recommend to users additional products offered at the order stage, which helped to increase profits.
Another example: the analysis of commodity positions allowed the H&M store to reduce the range in individual stores by 40%, while maintaining the level of sales. This was achieved by eliminating poorly selling positions, and seasonality was taken into account in the calculations.
Tool selection
The industry standard for this kind of computing is Hadoop. Why? Because Hadoop is an excellent, well-documented framework (the same Habr issues a lot of detailed articles on this topic), which is accompanied by a whole set of utilities and libraries. You can input huge sets of both structured and unstructured data, and the system itself will distribute them between computing power. Moreover, these same capacities can be increased or disabled at any time - the same horizontal scalability in action.
In 2017, the influential consulting company Gartner concludedthat Hadoop will soon be obsolete. The reason is pretty banal: analysts believe that companies will massively migrate to the cloud, because there they can pay for the fact of using computing power. The second important factor, supposedly able to "bury" Hadoop - is the speed of work. Because options like Apache Spark or Google Cloud DataFlow are faster than the MapReduce underlying Hadoop.
Hadoop rests on several pillars, the most notable of which are MapReduce technologies (a data distribution system for computing between servers) and the HDFS file system. The latter is specifically designed to store information distributed between nodes in a cluster: each block of a fixed size can be placed on several nodes, and thanks to replication, the system is immune to individual node failures. Instead of a file table, a special server called NameNode is used.
The illustration below shows the MapReduce workflow. At the first stage, the data is divided according to a certain characteristic, at the second - they are distributed according to computing power, at the third - the calculation is performed.
MapReduce was originally created by Google for the needs of its search. Then MapReduce went into free code, and Apache took up the project. Well, Google has gradually migrated to other solutions. An interesting nuance: at the moment Google has a project called Google Cloud Dataflow, positioned as the next step after Hadoop, as a quick replacement.
A closer look reveals that Google Cloud Dataflow is based on a variety of Apache Beam, while Apache Beam includes a well-documented Apache Spark framework, which allows us to talk about almost the same speed of decision execution. Well, Apache Spark works fine on the HDFS file system, which allows you to deploy it to Hadoop servers.
We add here the volume of documentation and turnkey solutions for Hadoop and Spark against Google Cloud Dataflow, and the choice of the tool becomes obvious. Moreover, engineers can decide for themselves which code - under Hadoop or Spark - to execute for them, focusing on the task, experience and qualifications.
Cloud or local server
The trend towards a universal transition to the cloud has even generated such an interesting term as Hadoop-as-a-service. In this scenario, the administration of the connected servers has become very important. Because, alas, in spite of its popularity, pure Hadoop is quite a difficult tool to configure, since a lot of things have to be done with your hands. For example, individually configure the servers, monitor their performance, carefully configure many parameters. In general, working for an amateur is a great chance to screw up something or to miss something.
Therefore, various distributions, which are initially equipped with convenient deployment and administration tools, gained great popularity. One of the most popular distributions that support Spark and make things easy is Cloudera. It has both a paid and a free version - and in the latter all the basic functionality is available, and without limiting the number of nodes.
During setup, Cloudera Manager will connect via SSH to your servers. An interesting point: during installation it is better to indicate that it should be carried out by the so-called parcels : special packages, each of which contains all the necessary components that are configured to work with each other. In fact, this is such an improved version of the package manager.
After installation, we get the cluster management console, where you can see telemetry by cluster, installed services, plus you can add / remove resources and edit the cluster configuration.
As a result, you see the cabin of the rocket that will take you to the bright future of BigData. But before you say “let's go,” let's get under the hood.
Hardware requirements
Cloudera mentions various possible configurations on its website. The general principles by which they are built are shown in the illustration:
To lubricate this optimistic picture can MapReduce. If you look again at the diagram from the previous section, it becomes obvious that in almost all cases the MapReduce job may run into a bottleneck when reading data from disk or from the network. This is also featured on the Cloudera blog. As a result, for any fast calculations, including through Spark, which is often used for real-time calculations, I / O speed is very important. Therefore, when using Hadoop, it is very important that balanced and fast machines get into the cluster, which, to put it mildly, is not always provided in the cloud infrastructure.
Balanced load balancing is achieved through the use of Openstack virtualization on servers with powerful multi-core CPUs. Data nodes are allocated their processor resources and specific disks. In our Atos Codex Data Lake Engine solution, broad virtualization is achieved, which is why we win both in performance (the influence of network infrastructure is minimized) and in TCO (unnecessary physical servers are eliminated).
In the case of using BullSequana S200 servers, we get a very uniform load, devoid of some bottlenecks. The minimum configuration includes 3 BullSequana S200 servers, each with two JBODs, plus optional additional S200s containing four data nodes are optionally connected. Here is an example of the load in the TeraGen test:
Tests with different data volumes and replication values show the same results in terms of load distribution between cluster nodes. Below is a graph of the distribution of disk access by performance tests.
The calculations are based on the minimum configuration of 3 BullSequana S200 servers. It includes 9 data nodes and 3 main nodes, as well as reserved virtual machines in case of deployment of protection based on OpenStack Virtualization. TeraSort test result: 512 MB block size of the replication coefficient of three with encryption is 23.1 minutes.
How can I expand the system? Various types of extensions are available for the Data Lake Engine:
- Data Nodes: For every 40 TB of usable space
- Analytical nodes with the ability to install a GPU
- Other options depending on the needs of the business (for example, if you need Kafka and the like)
Atos Codex Data Lake Engine includes both the servers themselves and pre-installed software, including a licensed Cloudera suite; Hadoop itself, OpenStack with virtual machines based on the RedHat Enterprise Linux kernel, a data replication system and backup (including using the backup node and Cloudera BDR - Backup and Disaster Recovery). The Atos Codex Data Lake Engine was the first virtualization solution certified by Cloudera .
If you are interested in the details, we will be happy to answer our questions in the comments.