How compression works in an object-oriented memory architecture
A team of engineers from MIT has developed an object-oriented memory hierarchy for more efficient work with data. The article deals with how it is arranged. / PxHere / PD
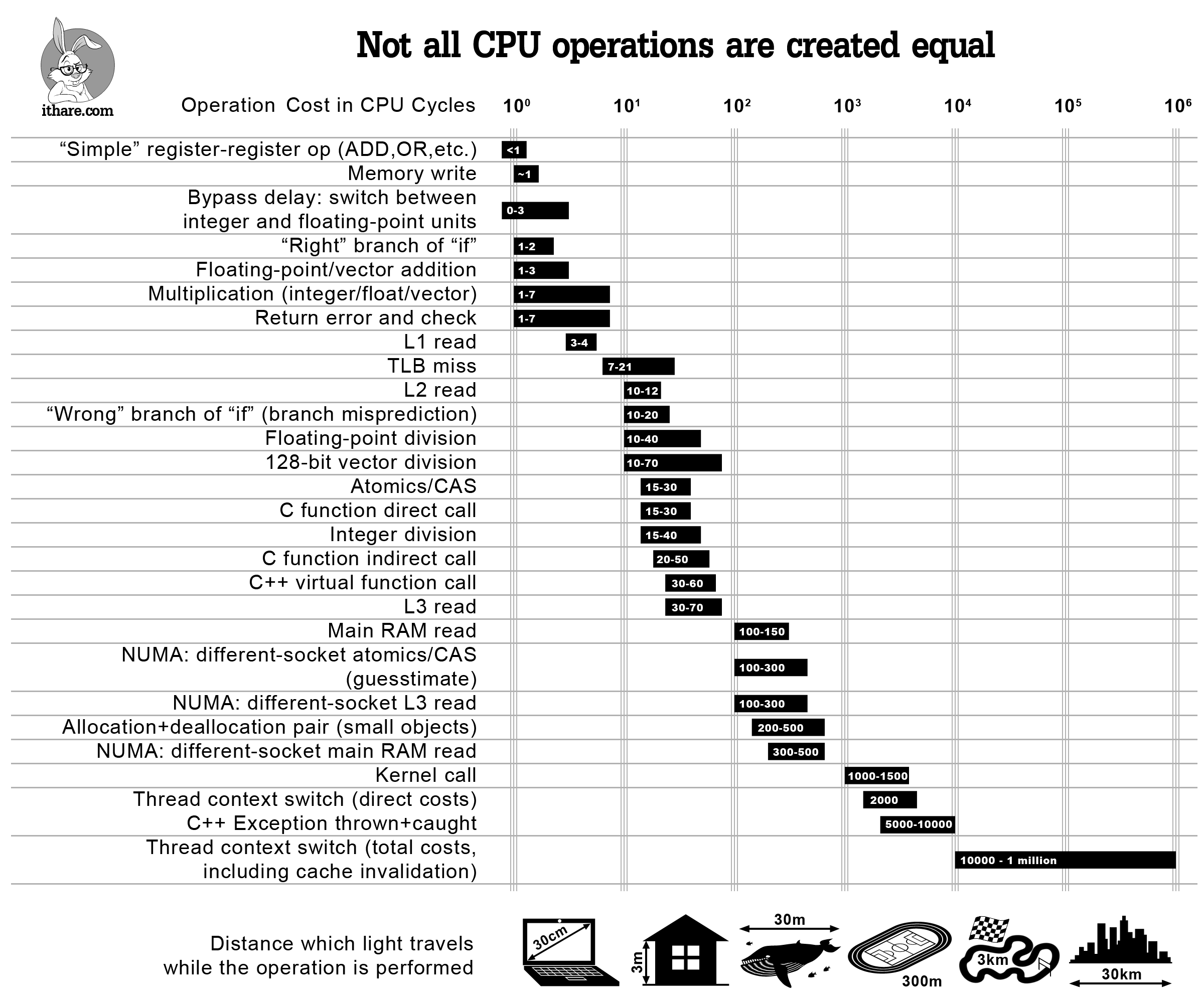
As you know, the increase in performance of modern CPUs is not accompanied by a corresponding decrease in latency when accessing memory. The difference in the change in indicators from year to year can reach up to 10 times ( PDF, p . 3 ). As a result, a bottleneck arises that prevents the full use of available resources and slows down data processing.
The so-called decompression delay causes a performance loss. In some cases, up to 64 processor cycles can take up preparatory data decompression.

For comparison: adding and multiplying floating-point numbers takes no more than ten cycles. The problem is that memory works with data blocks of a fixed size, while applications operate with objects that can contain different types of data and differ in size from each other. To solve the problem, engineers at MIT developed an object-oriented memory hierarchy that optimizes data processing.
The solution is based on three technologies: Hotpads, Zippads and the COCO compression algorithm.
Hotpads is a software-controlled hierarchy of super-operative register memory ( scratchpad ). These registers are called pads and there are three of them - from L1 to L3. They store objects of different sizes, metadata and arrays of pointers.
In essence, the architecture is a cache system, but sharpened for working with objects. The level of the pad at which the object is located depends on how often it is used. If one of the levels "overflows", the system starts a mechanism similar to the "garbage collectors" in the Java or Go languages. It analyzes which objects are used less often than others and automatically moves them between levels.

Zippads compresses objects whose volume does not exceed 128 bytes. Larger objects are divided into parts, which are then placed in different parts of the memory. According to the developers, this approach increases the coefficient of efficiently used memory.
To compress objects, the COCO (Cross-Object COmpression) algorithm is used, which we will discuss later, although the system is also able to work with Base-Delta-Immediate or FPC . COCO algorithm is a kind of differential compression ( differential compression ). It compares objects with “base” ones and removes duplicate bits - see diagram below:
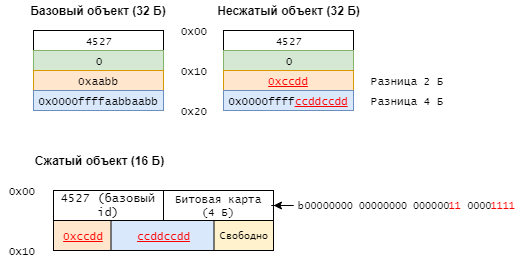
According to engineers from MIT, their object-oriented memory hierarchy is 17% more productive than classical approaches. It is much closer in its structure to the architecture of modern applications, so the new method has potential.
It is expected that in the first place the technology can begin to be used by companies that work with big data and machine learning algorithms. Another potential area is cloud platforms. IaaS providers will be able to more efficiently work with virtualization, data storage systems and computing resources.
For comparison: adding and multiplying floating-point numbers takes no more than ten cycles. The problem is that memory works with data blocks of a fixed size, while applications operate with objects that can contain different types of data and differ in size from each other. To solve the problem, engineers at MIT developed an object-oriented memory hierarchy that optimizes data processing.
{kind=link}
How the technology works
The solution is based on three technologies: Hotpads, Zippads and the COCO compression algorithm.
Hotpads is a software-controlled hierarchy of super-operative register memory ( scratchpad ). These registers are called pads and there are three of them - from L1 to L3. They store objects of different sizes, metadata and arrays of pointers.
In essence, the architecture is a cache system, but sharpened for working with objects. The level of the pad at which the object is located depends on how often it is used. If one of the levels "overflows", the system starts a mechanism similar to the "garbage collectors" in the Java or Go languages. It analyzes which objects are used less often than others and automatically moves them between levels.
Zippads works on the basis of Hotpads - it archives and unarchives data that arrives or leaves the last two levels of the hierarchy - the L3 pad and main memory. In the first and second pads, the data is stored unchanged.
Zippads compresses objects whose volume does not exceed 128 bytes. Larger objects are divided into parts, which are then placed in different parts of the memory. According to the developers, this approach increases the coefficient of efficiently used memory.
To compress objects, the COCO (Cross-Object COmpression) algorithm is used, which we will discuss later, although the system is also able to work with Base-Delta-Immediate or FPC . COCO algorithm is a kind of differential compression ( differential compression ). It compares objects with “base” ones and removes duplicate bits - see diagram below:
According to engineers from MIT, their object-oriented memory hierarchy is 17% more productive than classical approaches. It is much closer in its structure to the architecture of modern applications, so the new method has potential.
It is expected that in the first place the technology can begin to be used by companies that work with big data and machine learning algorithms. Another potential area is cloud platforms. IaaS providers will be able to more efficiently work with virtualization, data storage systems and computing resources.
Our additional resources and sources:“How we build IaaS”: 1cloud work materials
Evolution of 1cloud cloud architecture 1cloud
Potential attacks on HTTPS and ways to protect against them