60 million fields and 27 crops. How we made a map of all the fields of Europe and the USA
A few months ago, we launched the world's first free interactive map , with which you can see information about any field in the United States and Europe. Dozens of publications wrote about the map, and on Product Hunt she collected an unprecedented one and a half thousand likes for a product from the agricultural sector (and as a result became AI & Machine Learning Product of the Year 2018). We developed the map for two months - that's how it was.
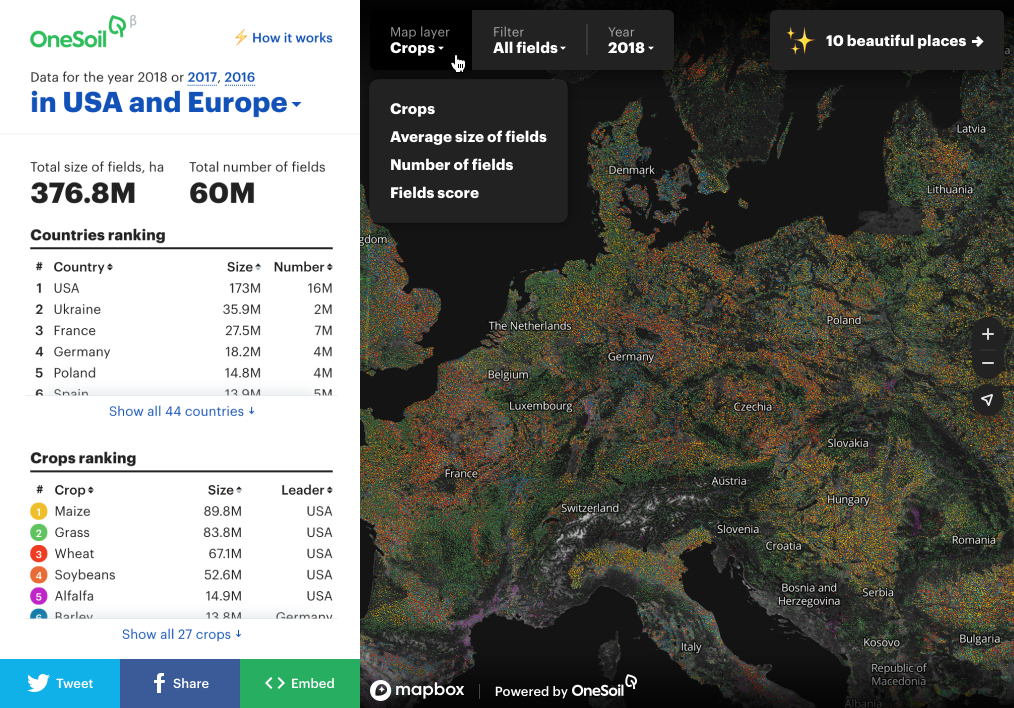
The interactive map is based on machine learning algorithms and satellite imagery. It contains information about 60 million fields and 27 cultures in 44 countries of Europe and the United States. Data - for three years. We recognized all fields using ML from satellite images. Using the map, you can both monitor trends at the level of countries and regions, and observe the development of a specific field. For example, you can find out how much land was occupied by corn in the United States in 2016 (49.1 million hectares) or which region of Belgium has the most wheat fields (Wallonia).
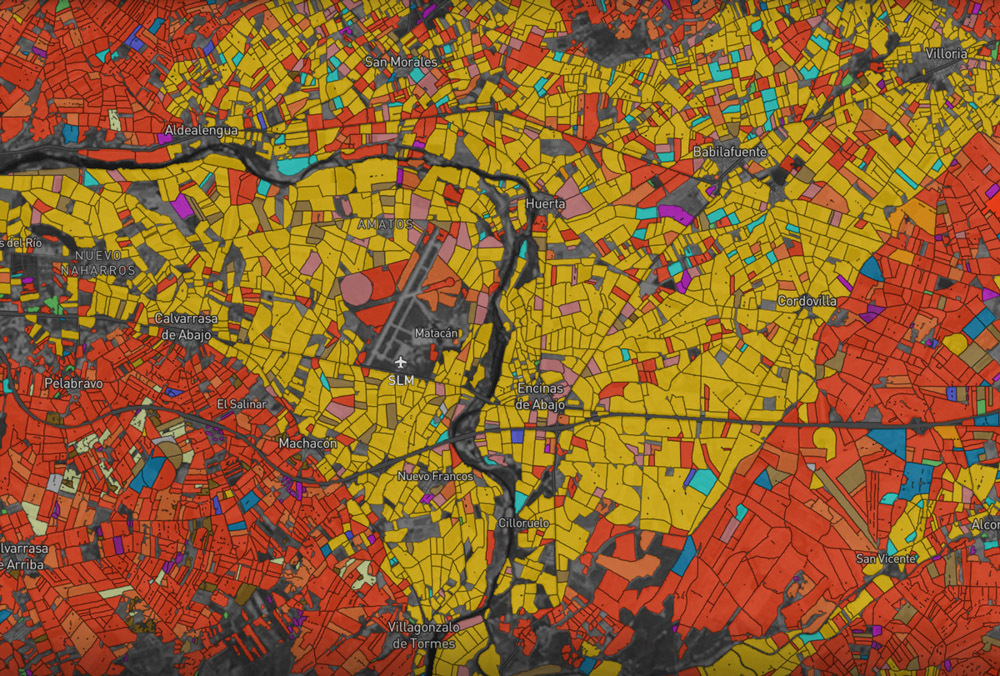
Europe at minimum zoom
Using the map, you can also find information on a separate field: its size, culture, development schedule and a comprehensive indicator Field Score. It is calculated by the NDVI index, climate indicators and relative field yields. At any time, you can see how beets are developing on your field or what area a legume allotted to a neighbor last year. Among other things, it's beautiful. We made the “random beautiful fields” button: it moves you to 35+ places around the world, each of which looks like a work of abstract art.
The idea of creating such a card appeared in July last year. We lacked a tool that would allow us to clearly demonstrate all our technological capabilities. In August, the entire team began to develop closely.
Data: collect, process, compress
When developing the map, we used images of the Sentinel-2 satellite of the Copernicus program of the European Union. In total, about 250 terabytes of information were processed for Europe and the USA. At the first stage, we did the preprocessing of the images: we cleaned the clouds, shadows, snow, and performed data compression. Then, on the resulting 50 terabytes, we launched the process of searching for field boundaries and classifying cultures on our machine learning models. At the output, we received about 250 gigabytes of vector maps containing field geometries and cultures.
To process data and calculate statistics, we used the PostgreSQL and PostGIS databases. After exporting the original vector data, we got a database in which there were about 180 million records of field geometry, as well as more than a billion records of additional attribute information about the fields themselves over three years. On this amount of data, we calculated statistics, ratings, determined the popularity of different cultures in the regions of the world - everything that is displayed on the map in the left column and interactive tips.

Fields of Croatia
We wanted to quickly calculate and display agronomic indicators for the field, as well as visualize the plant development schedule for the season. To do this, we used our own approach to caching and compression of satellite data. This allowed us to reduce the size of the data warehouse by 100-200 times, and reduce the speed of obtaining information in the field to 1 second.
Also in this version of the map, we added a comprehensive Field Score indicator, which allows you to quickly evaluate the field rating. Field Score is the first step towards yield forecasting, which our team is currently working on. The map was made in a short time, so I had to invent many original solutions on the go. But we apply all new developments in work on our main product.
Map: choose a format and prepare data
In order to visualize the data, we used Mapbox. There are two approaches to creating a map, we tried both. The first involves creating a raster map. In this case, we divide the map into squares, which we render into pictures and store on the server. The browser downloads several pictures and moves them when the user moves around the map. This approach allows you to display all the fields, you do not need to filter anything. This is beautiful, the minus is that the map is static, plus bitmaps weigh a lot.
The second approach is to create a vector map. The browser loads the vector data and animates it on the client side. This is how modern Google and Yandex maps work. Data weighs less than pictures and allows you to change the design of any element. This map can be made by the Mapbox service, in particular, their Mapbox GL library is an open source tool for displaying maps on the web. Among other things, Mapbox provides a paid map storage service. You can manually upload your data to their servers, and Mapbox will quickly distribute information, ensuring accurate map operation. This is an essential part of the work, and thanks to the fact that Mapbox takes it upon itself, the team’s task is greatly simplified.

Emilia Romagna, Italy
When working with vector data, there is a conditional limitation: the more information you want to display on the map, the slower everything will work. To solve this problem, we used a utility from Mapbox called Tippecanoe. Based on the algorithms we selected, it determined on which zoom certain fields will be visible and which are not, and removed invisible vector objects from the layer. In total, Tippecanoe has more than 20 filtering algorithms, we tried everything and selected a couple of basic ones. We compressed the data prepared in this way using the mbtiles technology from Mapbox to 50 gigabytes, and then uploaded it to the company's servers.
Using the Next JS framework, which performs server-side page rendering, allowed us to accelerate the map even more. Most applications in the modern world are rendered entirely on the client side: when a window is opened, the browser displays an empty hmtl page and a script that loads all the information. The Next JS framework renders everything on the server, and this makes loading the application quick for the client.
Map: set up the visual and come up with a “magic button” the night before the release
Mapbox was a pleasant discovery for our designer. The service simplified his task because he was able to visualize the data without involving a front-end developer. From the outside it may seem that it is easy to colorize the fields in the finished interface, but there are many nuances. We have 27 cultures, and picking colors for them was not easy. For popular cultures, contrasting colors are needed, for less popular, less contrasting colors, and they should all be clearly visible at different zoom levels. The map has a lot of nesting and interactive hints, so the most difficult thing was to think out the logic of transitions at different levels.
The night before the release, we realized that although it’s interesting to look at the map and numbers, I don’t want to share this on social networks. Therefore, we decided to add a button “random beautiful fields”, which throws users between different places on the planet. Throughout the office we searched for beautiful places, in an hour we drew a button and we made up everything. In the morning we tested it and launched it. It seems that it was this function that gave us so much coverage. Otherwise, no one would have paid attention to the fact that the fields are similar to abstract paintings. Do not underestimate the power of last-minute decisions.

Fields of France
We added another function to the map after launch. We knew that sometimes we do not recognize the fields and cultures on the map exactly, and user feedback allows us to improve our algorithms. After the release, farmers began to send messages about inaccuracies in crop recognition: "I have sunflower growing on the field, and you have corn." To resolve this issue, we added a button to the field card that sends us error notifications. We use the collected information to improve the accuracy of our crop recognition models.
Eventually
During its development, the concept of the card has become much more complicated. If at first we planned to make a simple visualization of fields and crops around the world, then the final product turned out to be much more complex. But the card was worth the effort. After the release, hundreds of investors, foundations and scientific researchers wrote to us. We will use part of technological solutions, for example, Next JS framework and Tippecanoe utility, to work on our free OneSoil precision farming web platform .
We were the first to map all the fields of the USA and Europe in three years. The data we received is unique. Already, we know more about the fields than any company or state. And the statistics that we get using machine learning algorithms are often more accurate than those that were manually collected. We have taken the first step towards automatically recognizing fields around the world - this is our plan for the near future.