Business processes. BPMN model extraction from the document. Part 1
- Translation
 The modern projects on the optimization and the automation of many business processes, assume, as a rule, that the first step will be the analysis of the large amount of the client’s documents. The purpose of it is the modelling the business processes “as-is” in a very tight schedule. The list of the analyzed documents includes normative legal acts, industry standards, SCRUM user stories, regulations, technical specifications and other corporate documents.
The modern projects on the optimization and the automation of many business processes, assume, as a rule, that the first step will be the analysis of the large amount of the client’s documents. The purpose of it is the modelling the business processes “as-is” in a very tight schedule. The list of the analyzed documents includes normative legal acts, industry standards, SCRUM user stories, regulations, technical specifications and other corporate documents.The analyst for the project faces a rather time-consuming task which is at the same time a routine one as well. It doesn’t have many means of automation at present. According to the analysis of modern means of business process modelling, even such well-known applications on the market as Enterprise Architect, ARIS, Bizagi Modeler do not have any support mechanisms for business process model building in their text description.
This article is focused on the BPMN model extraction from the document.
It is necessary to point out that there is a technology of intellectual analysis of business processes (Process Mining) on the business process management (BPM) market now. However, the difference from the technology described below is that on the input of the Process mining is given the database with the execution results of business process modelling, but not the document set with its text description.
Problem statement
The statement of the ideal task is imagined as “the big red button”, by clicking it, all the amounts of those documents needed to be analyzed convert automatically into the client’s BPMN model business process network, that is ready to be analyzed, optimized and then automated.
To find the solution of this statement is the question that can be solved in the future. Let’s input the number of logical and technical limitations for the real pilot task.
The goal: to minimize the complexity of construction of the business process models based on the text description with the completeness and connectedness of the model.
The input has a document in the Microsoft Word format, which:
- Includes the text description of Private Business Process.
- One Participant takes part in the business process.
- The business process is described in just one level of detail (Sub-Process are absent).
The output has an xml-file in the BPMN2.0 format, which:
- Includes the business process model, corresponding BPMN Descriptive Conformance Sub-Class.
- Is open correctly for the editing in Bizagi Modeler.
As the text example is used, the text description of such a widely spread process as Incident Management from the ITIL (Information Technology Infrastructure Library) appears. The text example is taken consciously in English. The English language doesn’t have any cases and this makes it easier for the coreferences on the elements of the business process in terms of the pilot task (more details about it will be given in the second part).
At the output the model of the Incident Management should be generated “not worse” than one presented in the library ITIL. Under the criterion “not worse” is understood to mean the completeness and connectedness of the business activities, data, conditions of decision-making and participants of the business process.
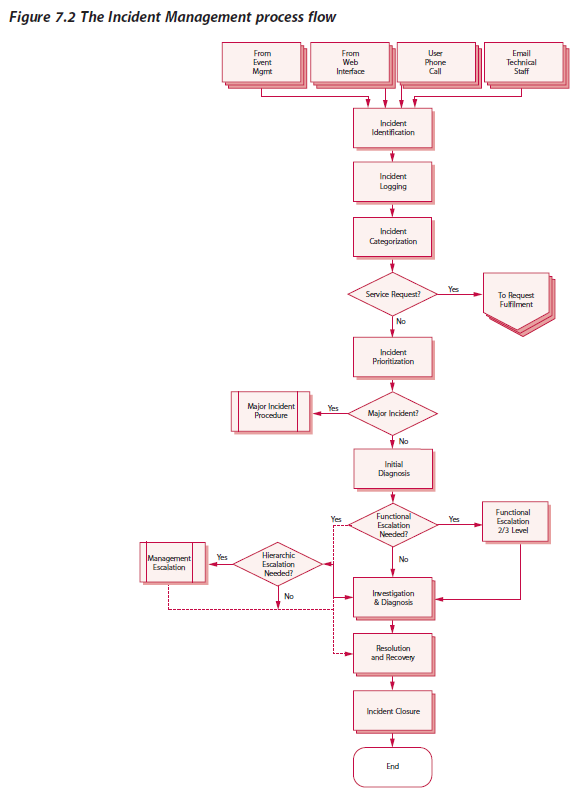
Figure 1. The Incident Management process flow (ITIL v.3 Official Introduction, p.98, Figure 7.2)
Solution concept
According to the BPMN glossary (Business Process Model and Notation, version 2.0), “a Process is depicted as a graph of Flow Elements, which are a set of Activities, Events, Gateways, and Sequence Flow that adhere to a finite execution semantics”.
Definition. Under the BPMN graph is understood the final, oriented graph with the following extensions:
- The graph vertices correspond to the BPMN elements of the Process (Flow Objects, Data, and Participant).
- The graph edges correspond to the BPMN connectors of the Process (Sequence Flows, Message Flows, and Associations).
- The vertices and edges have required attributes: ID, Name, and Documentation.
- The required types of the vertices are the elements of the category Flow Objects (Activities, Events, and Gateways).
- The required types of the edges are the connectors of the control flow (Sequence Flows).
Statement 1. The text description of the business process in the document (in their native language) contains the BPMN graph in an implicit view.
Statement 2. The extraction of the BPMN model from the document corresponds to the tasks of the extraction information from the ill-structured machine-readable documents (Information extraction). The main subtasks are the named entity recognition, the relationship extraction and the coreference resolution.
Combining the algorithms of the Graph theory and Information extraction we have the following solution steps.
- The marking of the document by the BPMN tags for identification of the Process elements.
- The compilation of the BPMN tags into the BPMN model for control flow extraction.
- The verification of the BPMN model for coreference resolution.
- The adjustment of the BPMN model, in case of the mismatch between the model and the text description.
- The export of the BPMN model into xml-file (to transform BPMN graph to the standard format).
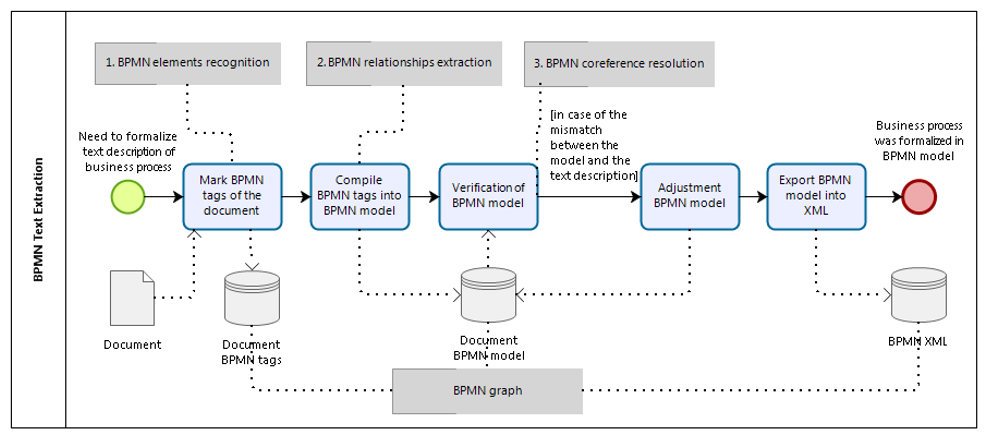
Figure 2. The BPMN model of the process “BPMN Text Extraction”
Solution step 1: The BPMN tags marking of the document
The BPMN tags are used to mark the BPMN elements of the business process in the document.
Definition. The BPMN tag is a colorful text marker with the identification that includes the type of the BPMN element. The BPMN tag name and color correspond to the certain category of the BPMN element.
Hereinafter colors, categories and types of the BPMN tags are shown. Some recommendations on the marking of the document are given as well (the search of the identification rules about the BPMN elements is the aim of the next stage of the project).
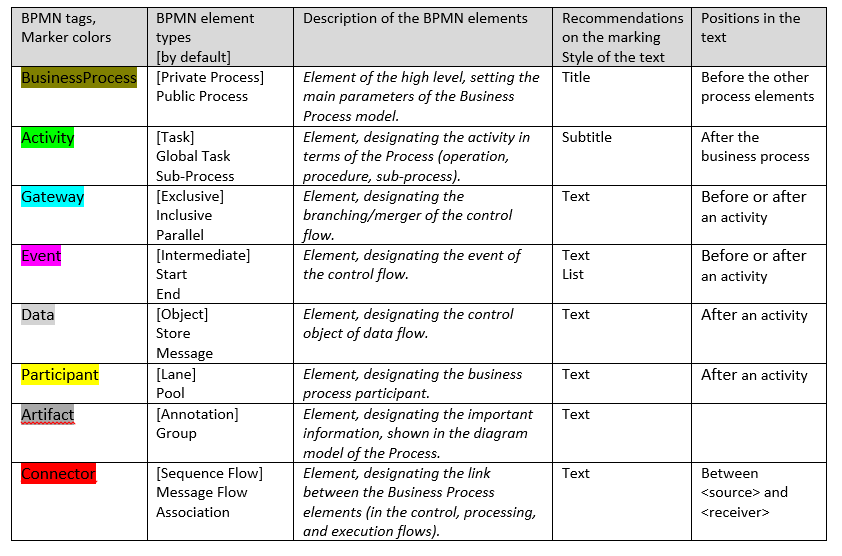
Table 1. The BPMN tags description
The common principle of the operation execution with the BPMN tags: to highlight the text fragment, containing the BPMN element and press the button corresponding to the BPMN tag; e.g. to highlight the business process you need to highlight “INCIDENT MANAGEMENT”, and then press the button . The background of the highlighted BPMN element colors into the color of the chosen BPMN tag and the bookmark with the identification of the BPMN tags will be added in the document bookmarks.

Figure 3. Microsoft Word Ribbon of BPMN Text Extractor (BPMN tags, Edit tags groups)
Hereinafter the main actions on the BPMN tags are listed:
- Add BPMN tag — adds the new BPMN tag in the document bookmarks (Word Bookmarks) and marks the highlighted text fragment by the corresponding color.
- Show tags — switches on/off the markers of the BPMN tags in the document.
- Resize — changes the area of the marked text of the BPMN tags.
- Delete — deletes the BPMN tag (the bookmark and marker) from the document.
- Details — shows the details on the BPMN tag (ID, category, type, and text of the BPMN tag).
- Report — shows the statistic report about the quantity and types of the BPMN tags in the active document.
In the result of the text document marking the following result is received.

Figure 4. The BPMN tags marking of ITIL Incident Management (figure is clickable)
Notice that there are “repeated” BPMN tags in the text, which have the same text and color (e.g. Service Desk, Problem Management, Incident Record). These are coreferences on the same element of the Process. The processing of such coreferences will be examined on the second solution step.
To be continued…