Operating Systems: Three Easy Pieces. Part 4: Introduction to the Scheduler (translation)
Introduction to Operating Systems
Hello, Habr! I want to bring to your attention a series of articles-translations of one interesting literature in my opinion - OSTEP. This article discusses rather deeply the work of unix-like operating systems, namely, work with processes, various schedulers, memory and other similar components that make up the modern OS. The original of all materials you can see here . Please note that the translation was done unprofessionally (quite freely), but I hope I retained the general meaning.
Laboratory work on this subject can be found here:
Other parts:
- Part 1: Intro
- Part 2: Abstraction: the process
- Part 3: Introduction to the Process API
- Part 4: Introduction to the Scheduler
- Part 5: MLFQ Scheduler
And you can look at my channel in telegram =)
Introduction to the Scheduler
The essence of the problem: How to develop a scheduler policy.
How should the basic scheduler policy frameworks be developed? What should be the key assumptions? What metrics are important? What basic techniques were used in early computing?
Workload Assumptions
Before discussing possible policies, for a start we will make a few simplifying digressions about the processes running in the system, which are collectively called the workload . By defining a workload as a critical part of building policies and the more you know about the workload, the better policy you can write.
We make the following assumptions about the processes running in the system, sometimes also called jobs (tasks). Almost all of these assumptions are not realistic, but necessary for the development of thought.
- Each task runs the same amount of time,
- All tasks are set at the same time,
- The task at hand until its completion,
- All tasks use only the CPU,
- The running time of each task is known.
Scheduler Metrics
In addition to some assumptions about the load, there is still a need for some tool for comparing various planning policies: scheduler metrics. A metric is just a measure of something. There are a number of metrics that can be used to compare planners.
For example, we will use the metric, which is called turn-around time (turnaround time). The turnaround time of a task is defined as the difference between the time it takes to complete the task and the time the task enters the system.
Tturnaround = Tcompletion − Tarrival
Since we assumed that all the tasks arrived at the same time, then Ta = 0 and thus Tt = Tc. This value will naturally change when we change the above assumptions.
Another metric is fairness(justice, honesty). Productivity and honesty are often opposing characteristics in planning. For example, a scheduler may optimize performance, but at the cost of waiting for other tasks to run, thus reducing integrity.
FIRST IN FIRST OUT (FIFO)
The most basic algorithm that we can implement is called FIFO or first come (in), first served (out) . This algorithm has several advantages: it is very simple to implement and it fits all our assumptions, doing the job pretty well.
Consider a simple example. Suppose 3 tasks were set at the same time. But suppose task A came a little earlier than everyone else, so it will be on the execution list earlier than the others, just like B relative to C. Assume that each of them takes 10 seconds to complete. What will be the average time to complete these tasks?
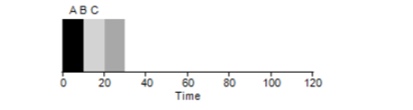
Counting the values - 10 + 20 + 30 and dividing by 3, we get the average execution time of the program equal to 20 seconds.
Now let's try to change our assumptions. In particular, assumption 1, and thus we will no longer assume that each task takes the same amount of time. How will FIFO show itself this time?
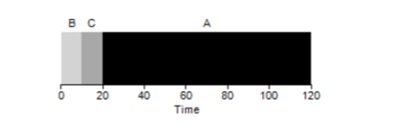
As it turns out, different execution times of tasks have an extremely negative impact on the productivity of the FIFO algorithm. Assume that task A will be executed for 100 seconds, while B and C will still be 10 each.

As can be seen from the figure, the average time for the system is (100 + 110 + 120) / 3 = 110. This effect is called the convoy effect.when some short-term consumers of a resource will stand in line after a heavy consumer. It looks like a grocery store line when a customer with a full trolley is in front of you. The best solution to the problem is to try to change the cashier or relax and breathe deeply.
Shortest job first
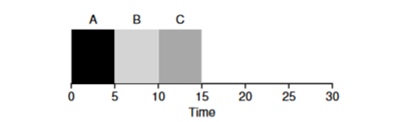
Is it possible to somehow solve a similar situation with heavy processes? Of course. Another type of scheduling is called Shortest Job First (SJF). Its algorithm is also quite primitive - as the name implies, the shortest tasks will be launched first one after another.
In this example, the result of starting the same processes will be an improvement in the average turnaround time of the programs and it will be 50 instead of 110 , which is almost 2 times better.
Thus, for the given assumption that all tasks arrive at the same time, the SJF algorithm seems to be the most optimal algorithm. However, our assumptions still do not seem realistic. This time, we change assumption 2 and this time imagine that tasks can remain at any time, and not all at the same time. What problems can this lead to?

Imagine that task A (100s) arrives very first and begins to be executed. At time t = 10, tasks B, C arrive, each of which will take 10 seconds. Thus, the average execution time is (100+ (110-10) + (120-10)) \ 3 = 103. What could the planner do to improve the situation?
Shortest Time-to-Completion First (STCF)
In order to improve the situation, we omit assumption 3 that the program is up and running until completion. In addition, we will need hardware support, and as you might have guessed, we will use a timer to interrupt a working task and switch contexts . Thus, the scheduler can do something at the time tasks B and C arrive - stop the execution of task A and put tasks B and C in processing and, after they finish, continue the process A. This scheduler is called STCF or Preemptive Job First .
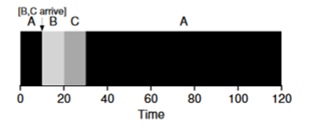
The result of this scheduler will be this result: ((120-0) + (20-10) + (30-10)) / 3 = 50. Thus, such a scheduler becomes even more optimal for our tasks.
Metric Response Time
Thus, if we know the run time of the tasks and that these tasks use only the CPU, STCF will be the best solution. And once in the early days, these algorithms worked and pretty well. However, now the user spends most of the time at the terminal and expects productive interactive interaction from it. So a new metric was born - response time (response).
The response time is
calculated as follows: Tresponse = Tfirstrun − Tarrival
Thus, for the previous example, the response time will be: A = 0, B = 0, B = 10 (abg = 3.33).
And it turns out that the STCF algorithm is not so good in a situation when 3 tasks arrive at the same time - it will have to wait until the small tasks are completely completed. Thus, the algorithm is good for the turnaround time metric, but bad for the interactivity metric. Imagine sitting at the terminal in an attempt to type characters in the editor, you would have to wait more than 10 seconds, because some other task is occupied by the processor. This is not very pleasant.
So we are faced with another problem - how can we build a scheduler that is sensitive to response time?
Round robin
To solve this problem, the Round Robin (RR) algorithm was developed . The basic idea is quite simple: instead of starting tasks to completion, we will start the task for a certain period of time (called a time quantum) and then switch to another task from the queue. The algorithm repeats its work until all tasks are completed. In this case, the program run time must be a multiple of the time after which the timer interrupts the process. For example, if the timer interrupts the process every x = 10ms, then the size of the process execution window should be a multiple of 10 and be 10.20 or x * 10.
Let's look at an example: Tasks of ABV arrive simultaneously in the system and each of them wants to work for 5 seconds. The SJF algorithm will complete each task to the end before starting another. In contrast, the RR algorithm with the launch window = 1s will go through the tasks as follows (Fig. 4.3):
(SJF Again (Bad for Response Time)
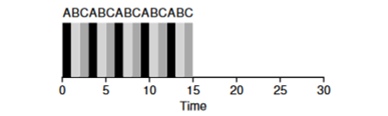
(Round Robin (Good For Response Time) The
average response time for the RR algorithm (0 + 1 + 2 ) / 3 = 1, while for SJF (0 + 5 + 10) / 3 = 5.
It is logical to assume that the time window is a very important parameter for RR, the smaller it is, the higher the response time. However, you cannot make it too small, because the time to switch context will also play a role in overall performance. Thus, the timing of the execution window is set by the OS architect and depends on the tasks that are planned to be executed in it. Switching the context is not the only service operation that spends time - the running program operates with a lot more, for example, various caches, and each time it is necessary to save and restore this environment, which can also take a lot of time.
RR is a great planner if it was only a response time metric. But how will the metric of the turnaround time of the task behave with this algorithm? Consider the example above, when the operating time A, B, C = 5s and arrive at the same time. Task A will end at 13, B at 14, C at 15s and the average turnaround time will be 14s. Thus, RR is the worst algorithm for turnover metrics.
More generally, any algorithm such as RR is honest, it divides the time spent on the CPU equally among all processes. And thus, these metrics constantly conflict with each other.
Thus, we have several opposed algorithms and at the same time several assumptions remain - that the task time is known and that the task only uses the CPU.
Mixing with I / O
First of all, we remove assumption 4 that the process only uses the CPU, of course this is not so, and the processes can turn to other equipment.
The moment a process requests an I / O operation, the process goes into a blocked state, waiting for I / O to complete. If I / O is sent to the hard disk, then such an operation can take up to several ms or longer, and the processor will be idle at that moment. At this time, the scheduler may take over the processor by any other process. The next decision that the scheduler will have to make is when the process completes its I / O. When this happens, an interrupt will occur and the OS will put the I / O-calling process in the ready state.
Consider an example of several tasks. Each of them needs 50ms of processor time. However, the first one will access I / O every 10ms (which will also be executed for 10ms). And process B simply uses a 50ms processor without I / O.
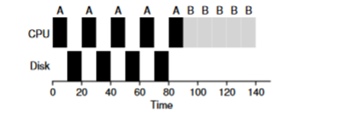
In this example, we will use the STCF scheduler. How does the scheduler behave if you run a process like A on it? He will proceed as follows - first fully process A, and then process B.

The traditional approach to solving this problem is to interpret each 10-ms sub-task of process A as a separate task. Thus, when starting with the STJF algorithm, the choice between a 50 ms task and a 10 ms task is obvious. Then, when subtask A is completed, process B and I / O will be started. After I / O is completed, it will be customary to start the 10-ms process A again instead of process B. Thus, it is possible to realize overlap when the CPU is used by another process while the first one is waiting for I / O. And as a result, the system is better utilized - at the moment when interactive processes are waiting for I / O, other processes can be executed on the processor.
Oracle is no more
Now let's try to get rid of the assumption that the time of the task is known. This is generally the worst and most unrealistic assumption from the whole list. In fact, in average standard OSs, the OS itself usually knows very little about the time it takes to complete tasks, so how can you build a scheduler without knowing how long the task will take? Perhaps we could use some of the principles of RR to solve this problem?
Total
We examined the basic ideas of task planning and reviewed 2 families of planners. The first one starts the shortest task at the beginning and thus increases the turnaround time, the second one is torn between all tasks equally, increasing the response time. Both algorithms are bad where other family algorithms are good. We also looked at how parallel use of the CPU and I / O can improve performance, but did not solve the problem with clairvoyance of the OS. And in the next lesson, we will consider a planner who looks into the near past and tries to predict the future. And it is called multi-level feedback queue.