What is DevOps
Defining DevOps is very complicated, so you have to re-start the discussion about it every time. Only on Habré a thousand publications on this subject. But if you read this, you probably know what DevOps is. Because I do not. Hi, my name is Alexander Titov (@ osminog ) and we’ll just talk about DevOps and I will share my experience.

I thought for a long time how to make my story useful, so there will be many questions here - those that I ask myself and those that I ask the clients of our company. By answering these questions, understanding is getting better. I will tell you why DevOps is needed from my point of view, what it is, again, from my position, and how to understand that you are moving to DevOps again from my point of view. The last item will be through questions. By answering them yourself, you can understand if your company is moving towards DevOps or if there are problems in something.
At one time I walked along the waves of mergers and acquisitions. At first I worked in a small startup Qik, then it was bought by a slightly larger company Skype, which was then bought by a slightly larger company Microsoft. At that moment, a vision became available to me how the idea of DevOps was being transformed in different companies. After that, it became interesting to me to look at DevOps from the point of view of the market, and my colleagues and I organized the company Express 42. For 6 years we have been moving on it along the market waves.
Among other things, I am one of the organizers of the DevOps Moscow community and the organizer of DevOps -Days 2017, but I did not organize 2018. Express 42 works with many companies. We germinate DevOps there, see how this happens, draw conclusions, analyze, tell our findings to everyone, teach people DevOps practices. In general, in every way we grow experience and expertise.
The first question that haunts everyone and always - why? Many people think that DevOps is just automation or a similar thing that every company already had.
- We had Continuous Integration - that means, there was already DevOps, and why is all this tops needed? They have fun abroad, but they interfere with our work!
Over the 9 years of development of the community and methodology, it has already become clear that these are not marketing spangles, but it’s still not completely clear why it is needed. Like any tool and process, DevOps has specific goals that it ultimately solves.
All this is due to the fact that the world is changing. He moves away from the enterprise approach, when companies go straight to the dream, as our St. Petersburg classic sang, from point A to point B according to a certain strategy, with a certain structure built for this.

Automation does not change often, because when a company rolls along a rutted track - what is there to change? It works - do not touch. Now in the world, approaches are changing, and the one called the word Agile says that the endpoint B is not immediately visible.

When a company moves around the market, works with a client, it constantly researches the market and changes its end point B. Moreover, the more often the company changes direction, the more successful it is in the end, because it selects more market niches.
The strategy is demonstrated by an interesting company, about which I learned recently. One Box Shave - A delivery service for shavers and shavers by box. They know how to customize their "box" for different customers. This is done by certain software, which then sends an order to a Korean factory that produces goods.
This product was bought by Unilever for $ 1 billion. Now he is competing with Gillette and has robbed him of a significant share of consumers in the US market. One Box Shave says:
- 4 blades? Are you seriously? Why do you need this - it does not improve the quality of shaving. A specially selected cream, perfume and a high-quality razor with two blades solve much more questions than these stupid 4 blades of Gillette! So soon we will reach 10?
So the world is changing. Unilever claims to have a cool IT system that allows it. In the end, it looks like a Time-to-market concept that no one has already spoken about.

The point of the Time-to-market is not how often we deploy. You can often deploy, but release cycles will be long. If the three-month release cycles overlap each other, shifting by a week, it turns out that the company seems to be deployed once a week. And from the idea to the final implementation, 3 months pass.
In this case, software interacts with the market. This is how One Box Shave interacts with the site. They have no sellers - just a site where the visitor clicks and leaves wishes. Accordingly, the site must constantly post something new, update it in accordance with the wishes. For example, in South Korea, they shave differently than in Russia, and they like the smell of pine, but, for example, vanillacarrots in the fragrance .
Since you need to quickly change the content of the site, software development is changing greatly. Through software, we must find out what the client wants. Previously, we learned this by some workarounds, for example, through business management. Then they designed, laid the requirements in the IT system, and everything was cool. Now it’s different - the software is designed by everyone who is involved in the process, including engineers, because they learn through technical specifications how the market works, and also share their insights with the business.
For example, at Qik, we suddenly found out that people really like to upload contact lists to the server, and they put us the application. Initially, we did not think about this. In a classic company, everyone would decide that it was a bug, since the spec does not say that it should work cool and was generally implemented on the knee, they would turn off the feature and say: "This does not need anyone, the most important thing is that the main functionality works" . And the technology company sees this as an opportunity and begins to change software in accordance with this.

In 1968, the visionary guy Melvin Conway formulated the following idea.
In more detail, in order to produce systems of a different type, one must also have a communication structure within a company of another type. If your communication structure is top hierarchical, this will not allow you to create systems that can provide a very high Time-to-market indicator.
You can read about Conway’s law by following the links . It is important for understanding the culture or philosophy of DevOps, since the only thing that changes fundamentally in DevOps is the communication structure between the teams .
From the point of view of the process, before DevOps, all stages: analytics, development, testing, operation, were linear.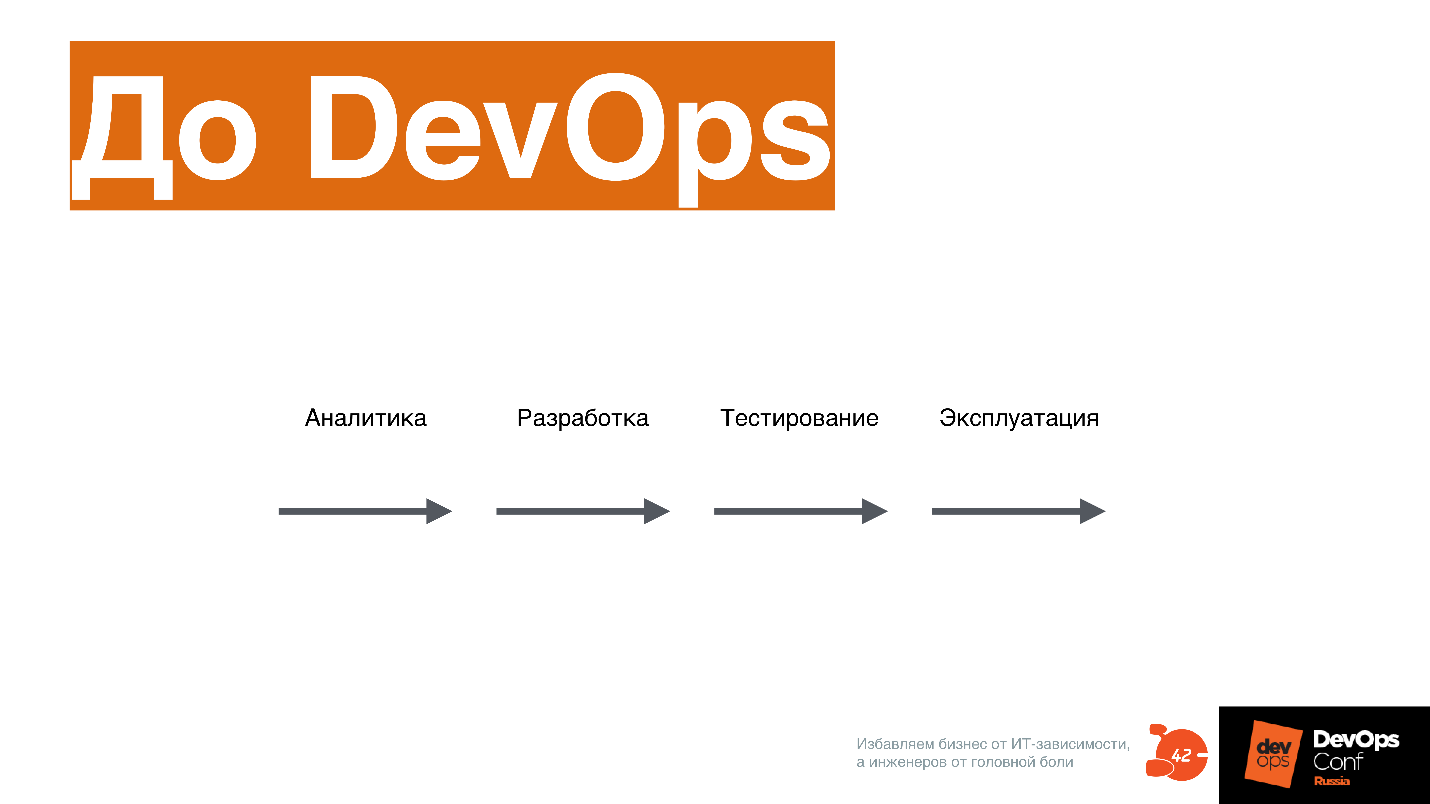
In the case of DevOps, all these processes go simultaneously.
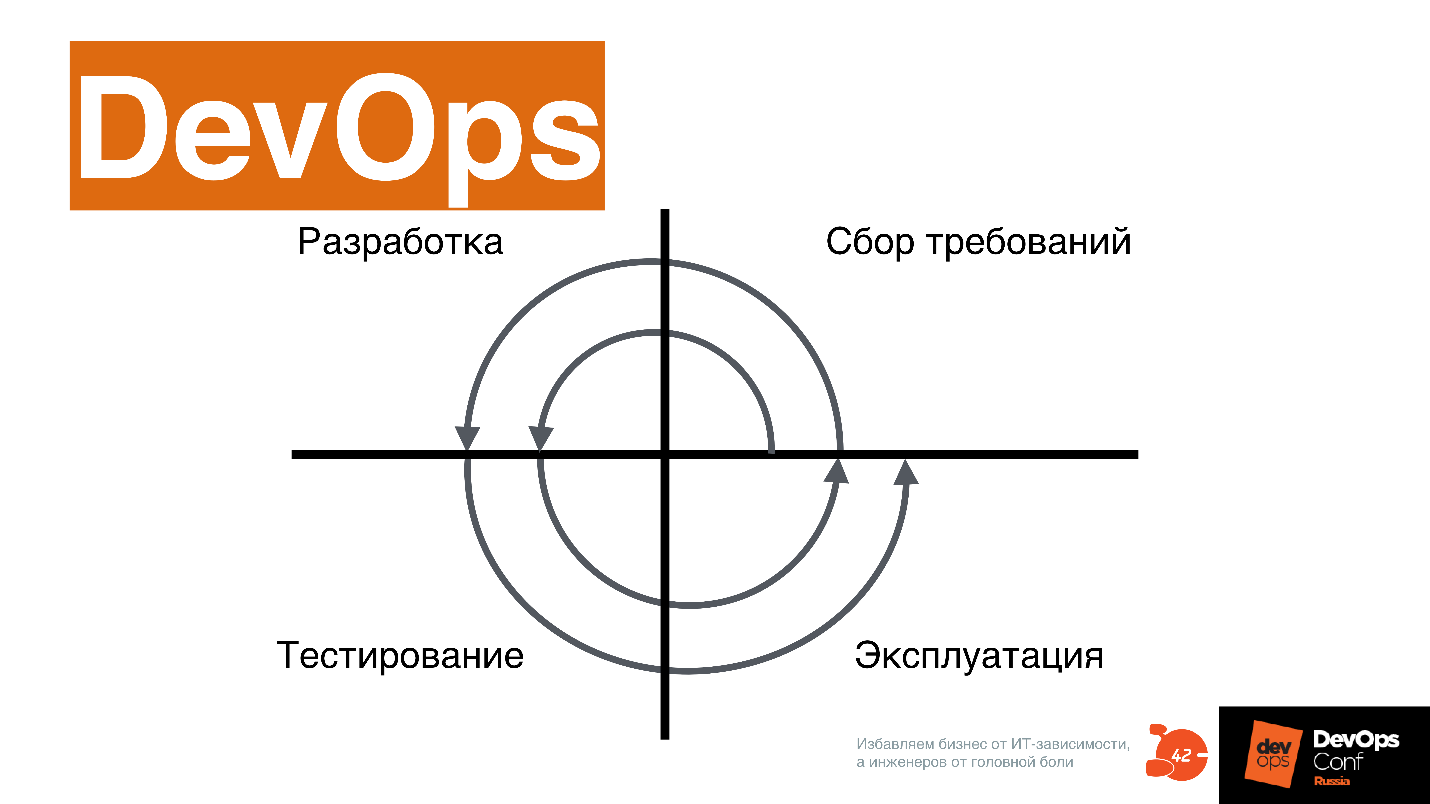
Time-to-market can only be done this way. For people who worked in the old process, it looks somewhat cosmic, and generally so-so.
For the development of digital products . If you don’t have a digital product in your company, DevOps is not needed - this is very important.
DevOps overcomes the speed limits of a consistent software production scheme . In it, all processes occur simultaneously.
Increases difficulty. When DevOps evangelists tell you that it will be easier for you to release software with it, this is nonsense.
At the conference at Avito's stand, one could see what it is to deploy a Docker container - an unrealistic task. Complexity becomes prohibitive, you have to juggle with many balls at the same time.
DevOps completely changes the process and organization in the company - more precisely, it does not change DevOps, but a digital product. To come to DevOps, you still need to completely change this process.
What about you? Questions that you can ask yourself when working in a company and developing as a specialist.
Do you have a digital product strategy? If there is, it’s already good. This means that your company is moving towards DevOps.
Is your company already creating a digital product? This means that you can go up another notch and do things more interesting - again, from the point of view of DevOps. I only speak from this point of view.
Is your company one of the market leaders in a niche with a digital product? Spotify, Yandex, Uber - companies that are at the peak of technological progress now.
Ask yourself these questions, and if all the answers are negative, then maybe you should not deal with DevOps in this company. If the DevOps theme is really interesting to you, maybe ... should you move to another company? If your company wants to go to DevOps, but you answered “No” to all the questions, then it resembles this beautiful rhino that will never change.

As I said, according to Conway’s law, an organization changes in a company. To begin with, what prevents DevOps from entering the company from the point of view of the organization.
The English word "Silo" is translated here into Russian as "well". The meaning of this problem is that between the teams there is no exchange of information . Each team digs its expertise deep into, while not building a common map in which you can navigate.
In some ways, it resembles a person who has just arrived in Moscow and still does not know how to navigate the metro map. Muscovites usually know their area very well, and throughout Moscow they are guided by the metro map. When you come to Moscow for the first time, there is no this skill, and you are simply disoriented.
Two factors interfere with this.
A consequence of the corporate management system. It is built by separate hierarchical "wells". For example, there are certain KPIs in companies that support this system. On the other hand, the brains of a person who is difficult to go beyond the limits of their expertise and navigate throughout the system interfere. It is just uncomfortable. Imagine that you got to the Bangkok airport - there you will not quickly find your bearings. DevOps is also difficult to navigate, and therefore people say that you need to find a guide to find it to get there.
But most importantly, the problem of “wells” for an engineer who was inspired by the spirit of DevOps, was read by Fowler and a bunch of other books, is expressed in the fact that “wells” do not allow you to do “obvious” things. We often get together after DevOps Moscow, talk with each other, and people complain:
- We just wanted to launch CI, but it turned out that management didn’t need it.
This is precisely due to the fact that CI and the Continuous Delivery process are on the border of many examinations. Just not overcoming the problem of “wells” at the organizational level, you will not be able to advance further, whatever you do and how sad it may be.

Each participant in the process in the company: backend and frontend developers, testing, DBA, operation, network, digs in his own direction, and no one has a common card except a manager who somehow observes and controls the divide and conquer method.
As a result, when the task appears to connect all this together and build a common pipeline, and there is no need to fight for the stars and flags, the question arises - what should I do? We must somehow agree, but nobody taught us how to do this. We have been taught from school: the eighth grade - wow! - compared to the seventh grade! It’s the same here.
To check this, you can ask yourself the following questions.
Do teams use common tools, do they contribute to changes to these common tools?
How often do teams reform? Do some specialists from one team move to another team? It is in the DevOps environment that this becomes normal, because sometimes a person simply cannot understand what another area of expertise is doing. He moves to another department, works there for two weeks to create for himself a map of orientation and interaction with this department.
Is it possible to create a committee on change and change something?Or does this require a strong hand of the highest leadership and direction? I recently wrote on Facebook how one little-known bank implements tools through orders: we wrote an order, we’ve implemented it for a year, and we’ll see what happens. This, of course, is long and sad.
How important is it for managers to receive personal achievements without taking into account the achievements of the company?
If you answer these questions for yourself, it will become clearer if you have such a problem in the company.
After this problem has been resolved, the first important practice, without which it is difficult to move further into DevOps, is infrastructure as a code .
Most often, the infrastructure as a code is perceived as follows:
- Let's automate everything on bash, cover ourselves with scripts so that the admin area has less manual work!
But this is not so.
Together with other teams, you create a map in the form of a code that everyone understands, which you can navigate and navigate. It doesn’t matter on what it is done - Chef, Ansible, Salt, or YAML files are used in Kubernetes - there is no difference.
At the conference, a colleague from 2GIS talked about how they made their own internal thing for Kubernetes, which describes the structure of individual systems. To describe 500 systems, they needed a separate tool that generates this description. When there is this description, everyone can check with each other, monitor changes, how to change and improve it, which is missing.
Agree, separate bash scripts usually do not give this understanding. In one of the companies where I worked, there was even a name “write only” - a script - when the script is written, and it is already impossible to read it. I think this is familiar to you too.
Infrastructure as a code is a code that describes the current state of the infrastructure . Many product, infrastructure, and service teams work together on this code, and most importantly, they all need to understand how this code generally works.
The code is accompanied according to the best practices of working with code : joint development, code review, XP-programming, testing, pull-quests, CI for code infrastructures - all this is suitable and can be used.
Changing the infrastructure in the code does not take much time . Yes, there may also be technical debt in infrastructure code. Usually, teams encounter it a year and a half after they started to implement "infrastructure as code" in the form of a bunch of scripts or even Ansible, which they write as spaghetti code, and even bash scripts put it in the firebox!
Important : if you haven't tried this stuff yet, remember that Ansible is not bash ! Read the documentation carefully, study what they generally write about it.
In our company, we distinguish 3 basic layers, which are very clear and simple, but there may be more. You can look at your infrastructure code and say whether you have this condition or not. If no layers are highlighted, then you need to allocate time and refactor a little.

The base layer is how the OS, backups, and other low-level things are configured, for example, how Kubernetes is deployed at a basic level.
Service level - these are the services that you give the developer: logging as a service, monitoring as a service, a database as a service, a balancer as a service, a queue as a service, Continuous Delivery as a service - a bunch of services that individual teams can provide development. All this must be described as separate modules in your configuration management system.
The layer where the applications are made and how they will be deployed on top of the previous two layers.
Do you have a common infrastructure repository in your company? Do you control technical debt in infrastructure? Do you use development practices in the infrastructure repository? Is your infrastructure sliced? You can check the Base-service-APP schema. How difficult is it to make a change?
If you are faced with the fact that the introduction of changes took a day and a half, this means that you have a technical debt and you need to work with it. You just stumbled upon a rake of technical debt in the infrastructure code. I remember many such stories when in order to change any CCTL, it is necessary to rewrite half the infrastructure code, because creativity and the desire to automate everything led to the fact that everywhere everything is shorted, all the pens are removed, and you need to refactor.
Similar debit with a loan. First, a description of the infrastructure appears, which can be quite basic. It is not necessary to describe everything in detail, but some basic description is required so that you can work with it. Otherwise, it is not clear on top of what further to do continuous delivery. All these practices unfold at the same time when you come to DevOps, but you need to start by understanding what you have and how to manage it. This is just the practice of infrastructure as code.
After it became clear that you have how to manage this, you begin to think of how to send the developer code to production as quickly as possible. I mean, together with the developer - we remember the problem of "wells", that is, not individual people come up with this, but by the team.
When we are with Vanya Evtukhovichsaw the first book of Jes Hamble and the group of authors “Continuous Delivery” , which was published in 2009, then for a long time they thought how to translate its name into Russian. They wanted to translate it as “Constantly deliver”, but, unfortunately, translated as “Continuous delivery”. It seems to me that there is something Russian in our title with pressure.
The code that lies in the grocery repository can always be downloaded in production . It may not be deflated, but it is always ready for it. Accordingly, you always write code with a difficult to explain feeling of some concern under the tailbone. It often appears when you roll out the infrastructure code. This feeling of some concern should be present - it causes brain processes that allow you to write code a little differently. This should be fixed in the rules within the development.
To deliver constantly, you need an artifact format that runs across the infrastructure platform.If you throw on the infrastructure platform of a different format "waste", then it becomes not unified for you, it is difficult to maintain, there is a problem of technical debt. The artifact format needs to be aligned - this is also a collective task: everyone needs to get together, rustle with their brains and come up with this format.
The artifact is constantly improving and changing to the production environment while passing through the supply pipeline.When the artifact moves along the pipeline, it constantly encounters some uncomfortable things for it, which are similar to what the artifact that you put in production encounters. If in the classical development the sysadmin does this, it does the rolling out, then in the DevOps process this happens all the time: here it was twisted by some tests, here - in the Kubernetes cluster they threw it, which is more or less similar to production, then load testing was suddenly launched .
This is somewhat reminiscent of a Pakman game - an artifact goes through some kind of story. At the same time, it is important to control whether the code really goes through the story and is somehow related to your production. Production stories can be dragged into the Continuous Delivery process: it happened when something fell, now let's just program this script inside the system. Each time the code will go through this script too, and you will not encounter this problem the next time. You will learn about her much earlier than she comes to your client.
Different deployment strategies. For example, you use AB testing or canary deployments to "probe" the code in different clients, get information about how the code works, and much earlier than when it rolls out to 100 million users.
“Constantly deliver” looks like this.
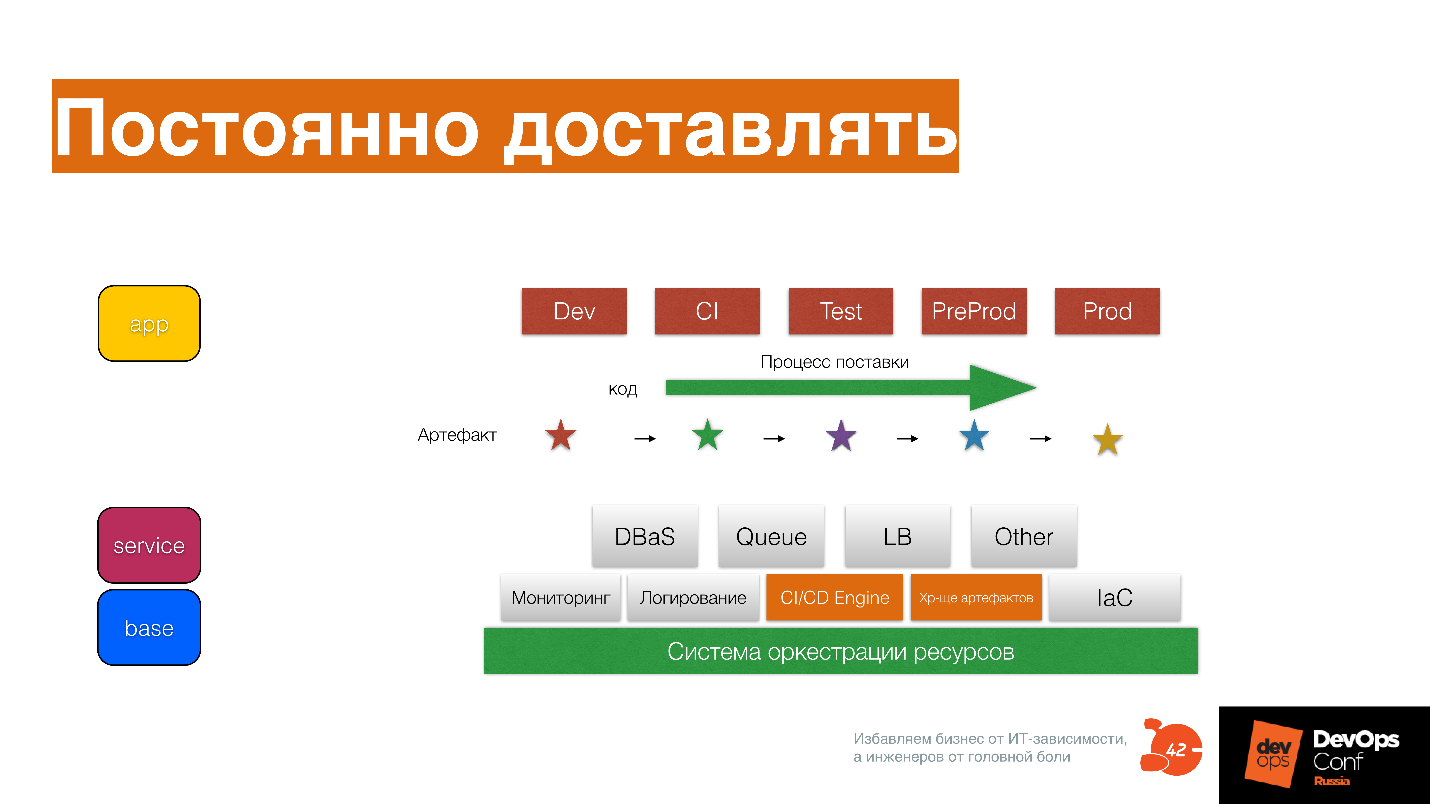
If you have the infrastructure code that is described as Base Service APP, then it helps not to forget all the scripts , and write them down as code for this artifact, promote the artifact and change it as you move.
The time from the description of features to rolling out in production in 95% of cases less than a week? Does artifact quality increase at every stage of the pipeline? Is there a story he goes through? Do you use different deployment strategies?
If all the answers are yes, then you are unrealistically cool! Write the answers in the comments - I will be happy).
This is the hardest practice of all. At the DevOpsConf conference, a colleague from Infobip, talking about her, was a little confused in words, because it is really a very difficult practice about the fact that everything needs to be monitored!

For example, a long time ago, when I worked at Qik and we realized that we needed to monitor everything. We did this, and in Zabbix we have 150,000 items that are constantly monitored. It was scary, the technical director twisted his finger at the temple:
- Guys, why are you raping the server for some reason?
But then there was a case that showed that this is really a very cool strategy.
One of the services began to fall constantly. Initially, it did not fall, which is interesting, the code was not added there, because it was a basic broker in which there was practically no business functionality - it simply drove messages between separate services. The service did not change for 4 months, and suddenly began to fall with the error "Segmentation fault".
We were shocked, opened our charts in Zabbix, and it turned out that, it turned out, one and a half weeks ago the behavior of requests in the API service that this broker uses has changed a lot. Then we saw that the frequency of sending a certain type of message has changed. After they found out that these are android clients. We asked:
- Guys, what happened to you a week and a half ago?
In response, they heard an interesting story about how they remade the UI. It is unlikely that anyone will immediately say that he changed the HTTP library. For android clients it’s like changing soap in the bathroom - they just don’t remember it. As a result, after 40 minutes of conversation, we found out that they still changed the HTTP library, and its default timings changed. This led to a change in the behavior of traffic on the API server, which led to a situation that caused a race inside the broker, and it began to fall.
It’s impossible to open it without deep monitoring.. If the organization still has a problem of "wells", when everyone throws one on top of another, this can live for years. You just restart the server because it is impossible to solve the problem. When you monitor, track, track all the events that you have, and use monitoring as testing - write the code and immediately indicate how to monitor it, also in the form of code (we already have the infrastructure as code), everything becomes clear how on the palm. Even such complex problems are easily tracked.
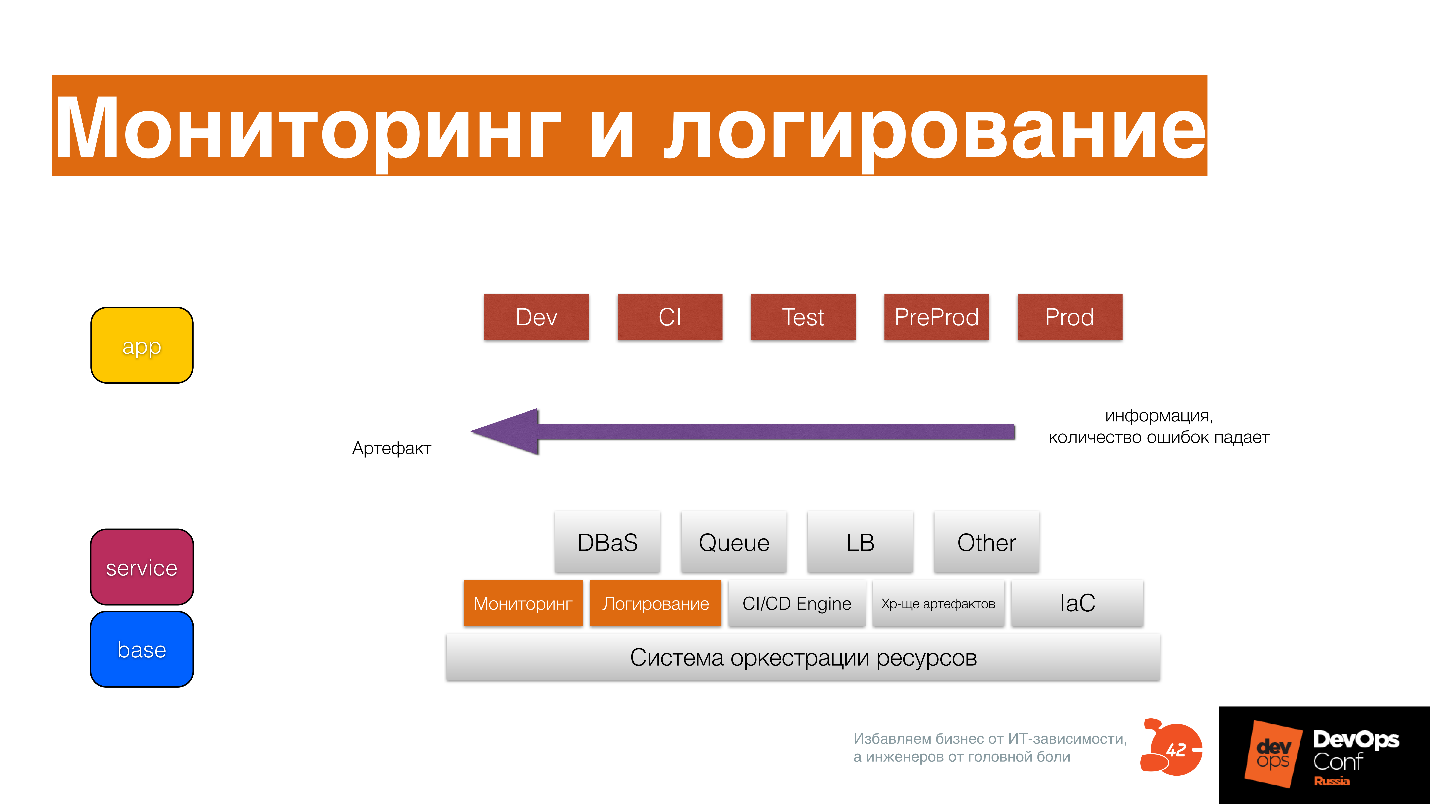
Load monitoring on CI, and there some basic things will already be visible there. Further you will see them both in Test, and in PredProd, and in load testing. Collect information at all stages, not only metrics, statistics, but also logs: how the application rolled out, anomalies - collect everything.
Otherwise, it will be difficult to figure out. I already said that DevOps is a lot of complexity. To cope with this complexity, you need to have normal analytics .
Is your monitoring and logging a development tool for you? Do your developers, including you, when writing code, think about how to monitor it?
Do you know about problems from customers? Do you understand the customer better from monitoring and logging? Do you understand the system better from monitoring and logging? Do you change the system simply because you saw that the trend in the system is growing and you understand that 3 more weeks and everything will bend?
When you have these three components, you might think about your infrastructure platform.
The point is not that this is a set of disparate tools that every company has.
It is clear that there are separate teams that are responsible for the development of individual pieces of the infrastructure platform. But at the same time, every engineer is responsible for the development, availability, and promotion of the infrastructure platform. At the domestic level, this is becoming a common tool .
All teams develop the infrastructure platform, treat it carefully as their own IDE . In your IDE, you put different plugins so that everything is beautiful and fast, you set up hot keys. When you open Sublime, Atom, or Visual Studio Code, you get code errors pouring in and you realize that it's impossible to work at all, you immediately feel sad and you run to repair your IDE.
Also apply to your infrastructure platform. If you understand that something is wrong with her, leave a request if you can not fix it yourself. If there is something simple there - edit it yourself, send a pull request - the guys consider, add. This is a slightly different approach to engineering tools in the head of the developer.
The infrastructure platform provides the transfer of artifact from development to the client with a constant improvement in quality . The programmer has programmed a set of stories that happen to the code in production. Over the years of developing these stories, there are a lot of them, some of them are unique and apply only to you - it is impossible to google them.
At this point, the infrastructure platform becomes your competitive advantage., because it is sewn into it that is not in the tool of a competitor. The deeper your IP, the greater your competitive advantage in the sense of Time-to-market. Here comes the vendor lock problem : you can take someone else’s platform for yourself, but using someone else’s experience, you won’t understand how relevant it is to you. Yes, not every company can build a platform like Amazon. This is a difficult line, where the company's experience is relevant to its market position, and vendor lock cannot be lowered there. This is also important to think about.
This is the basic framework of the infrastructure platform that will help you establish all the practices and processes in the DevOps company.
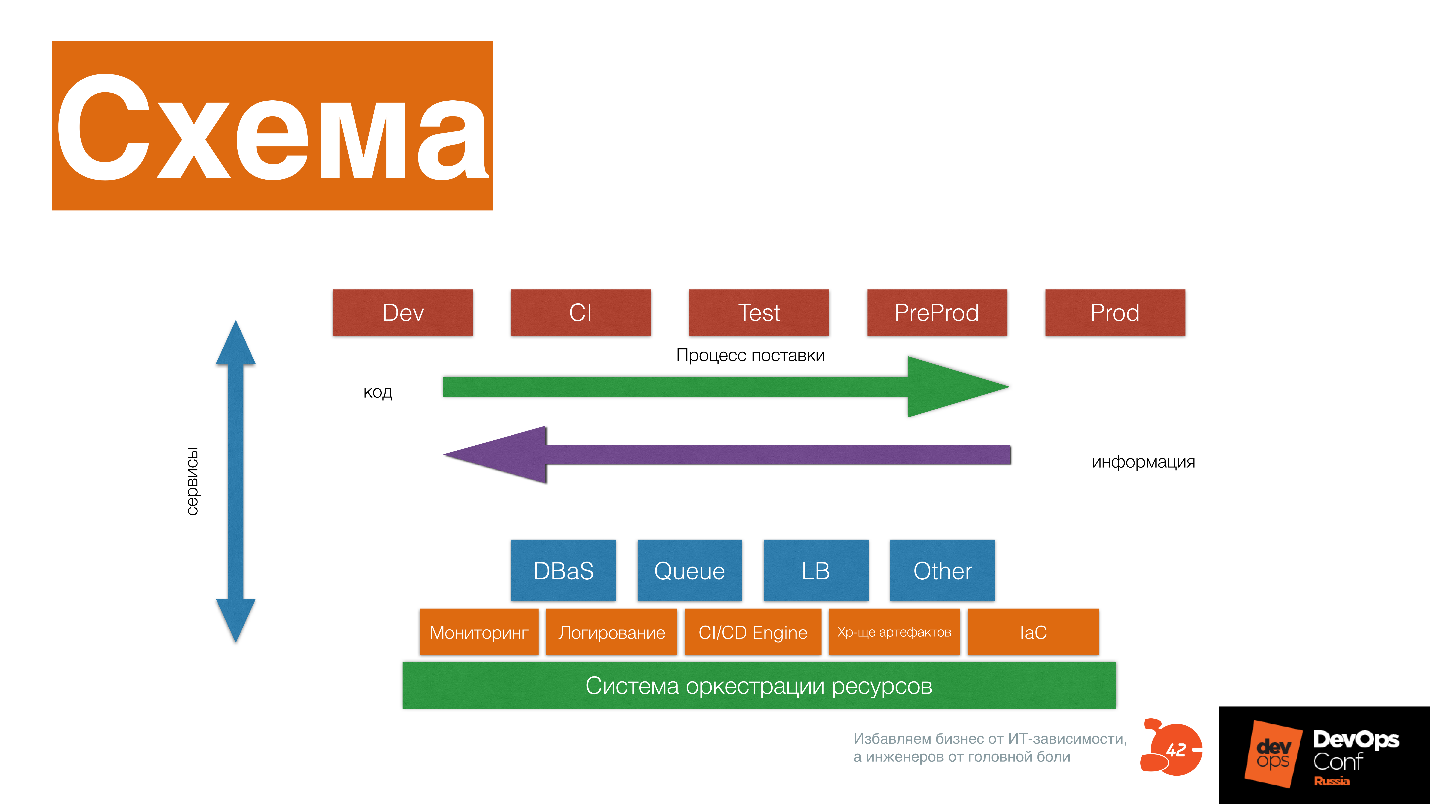
Consider what it consists of.
A resource orchestration system that provides CPU, memory, disk to applications and other services. On top of this are low-level services : monitoring, logging, CI / CD Engine, artifact storage, infrastructure as system code.
Higher level services : database as a service, queues as a service, Load Balance as a service, resizing pictures as a service, Big Data factory as a service. On top of this is a pipeline that delivers a constantly modified code to your client .
You get information about how your software works with a client, change it, deliver this code again, get information - and so constantly develop both the infrastructure platform and your software.
In the diagram, the delivery pipeline consists of many stages. But this is a circuit diagram, which is given as an example - do not repeat it one to one. Stages interact with services as with services - each brick of the platform carries its own story: how resources are allocated, how the application starts, works with resources, monitors, changes.
It is important to understand that each part of the platform carries a story, and ask yourself what story this brick carries, maybe it is worth throwing it away and replacing it with a third-party service. For example, can I put Okmeter instead of a brick? Perhaps the guys have already pumped this expertise much more than we did. But maybe not - maybe we have a unique expertise, we need to put Prometheus and develop it further.
This is a complex communication process. When you have basic practices, you start communication between different engineers and specialists who develop requirements and standards, and constantly change them to different tools and approaches. The culture that DevOps has is important here.
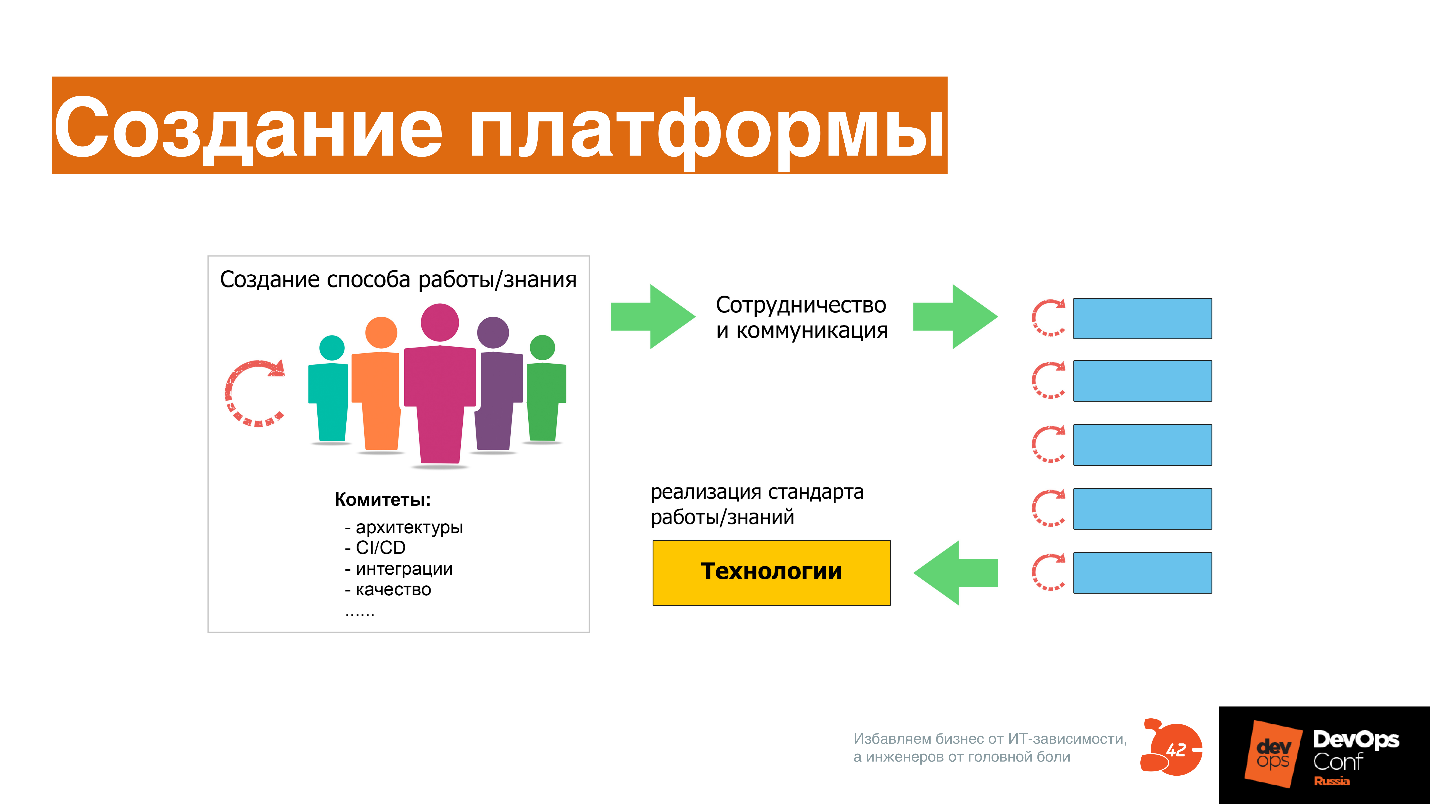
Everything is very simple with culture - this is cooperation and communication , that is, the desire to work in a common field with each other, the desire to own one tool together. There is no rocket science - everything is very simple, corny. For example, we all live in the stairwell and maintain its cleanliness - such a level of culture.
Again, questions that you can ask yourself.
Is the infrastructure platform dedicated? Who is responsible for its development? Do you understand the competitive advantages of your infrastructure platform?
These questions must be constantly asked yourself. If something can be transferred to third-party services - you need to take it out, if a third-party service begins to block your movement, then you need to build a system inside yourself.
... this is a complex system, it should include:
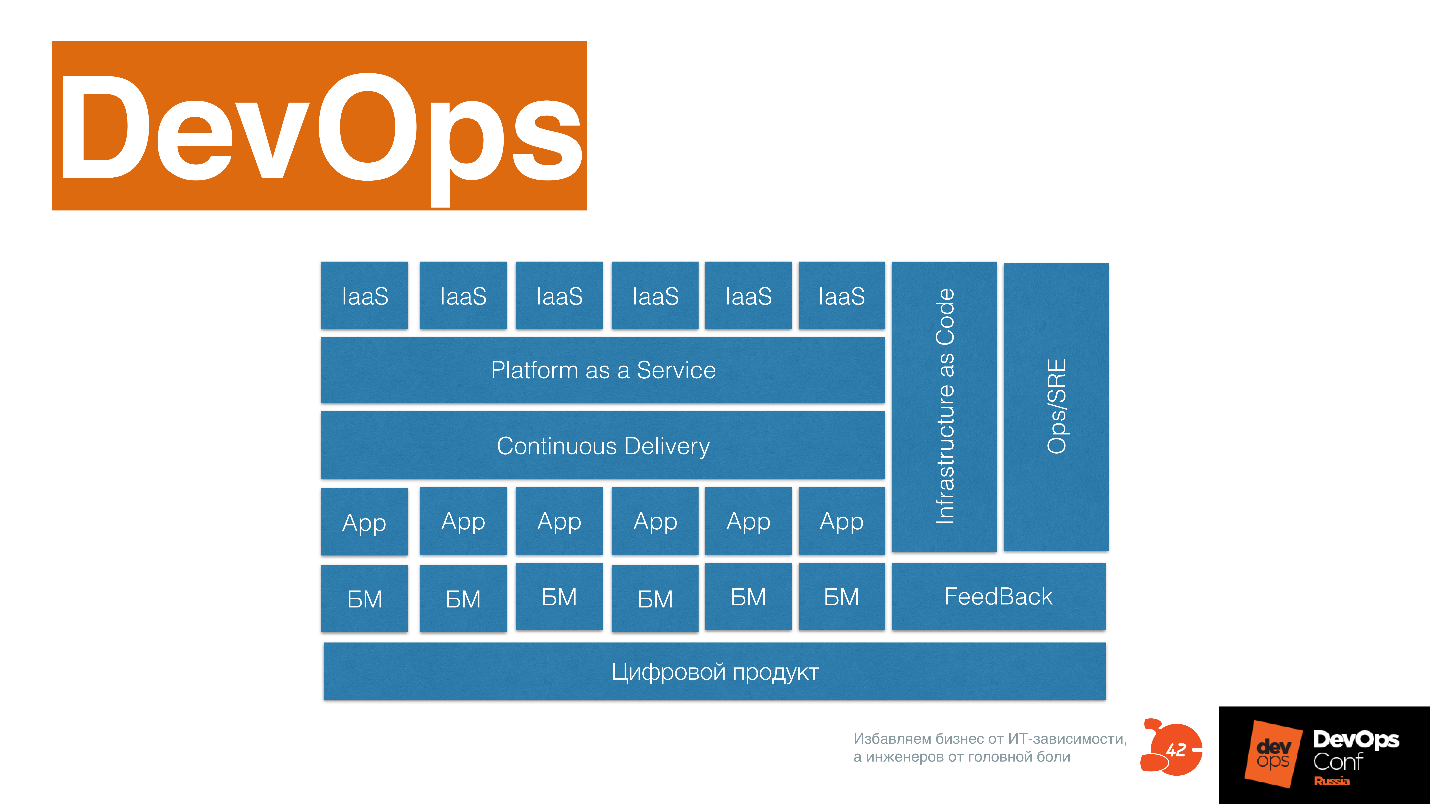
You can use this scheme by tinting in it what you already have in your company in some form: it has developed or still needs to be developed.
I thought for a long time how to make my story useful, so there will be many questions here - those that I ask myself and those that I ask the clients of our company. By answering these questions, understanding is getting better. I will tell you why DevOps is needed from my point of view, what it is, again, from my position, and how to understand that you are moving to DevOps again from my point of view. The last item will be through questions. By answering them yourself, you can understand if your company is moving towards DevOps or if there are problems in something.
At one time I walked along the waves of mergers and acquisitions. At first I worked in a small startup Qik, then it was bought by a slightly larger company Skype, which was then bought by a slightly larger company Microsoft. At that moment, a vision became available to me how the idea of DevOps was being transformed in different companies. After that, it became interesting to me to look at DevOps from the point of view of the market, and my colleagues and I organized the company Express 42. For 6 years we have been moving on it along the market waves.
Among other things, I am one of the organizers of the DevOps Moscow community and the organizer of DevOps -Days 2017, but I did not organize 2018. Express 42 works with many companies. We germinate DevOps there, see how this happens, draw conclusions, analyze, tell our findings to everyone, teach people DevOps practices. In general, in every way we grow experience and expertise.
Why DevOps
The first question that haunts everyone and always - why? Many people think that DevOps is just automation or a similar thing that every company already had.
- We had Continuous Integration - that means, there was already DevOps, and why is all this tops needed? They have fun abroad, but they interfere with our work!
Over the 9 years of development of the community and methodology, it has already become clear that these are not marketing spangles, but it’s still not completely clear why it is needed. Like any tool and process, DevOps has specific goals that it ultimately solves.
All this is due to the fact that the world is changing. He moves away from the enterprise approach, when companies go straight to the dream, as our St. Petersburg classic sang, from point A to point B according to a certain strategy, with a certain structure built for this.
In principle, in IT everything should be built for this approach. Here IT is used exclusively for process automation.
Automation does not change often, because when a company rolls along a rutted track - what is there to change? It works - do not touch. Now in the world, approaches are changing, and the one called the word Agile says that the endpoint B is not immediately visible.
When a company moves around the market, works with a client, it constantly researches the market and changes its end point B. Moreover, the more often the company changes direction, the more successful it is in the end, because it selects more market niches.
The strategy is demonstrated by an interesting company, about which I learned recently. One Box Shave - A delivery service for shavers and shavers by box. They know how to customize their "box" for different customers. This is done by certain software, which then sends an order to a Korean factory that produces goods.
This product was bought by Unilever for $ 1 billion. Now he is competing with Gillette and has robbed him of a significant share of consumers in the US market. One Box Shave says:
- 4 blades? Are you seriously? Why do you need this - it does not improve the quality of shaving. A specially selected cream, perfume and a high-quality razor with two blades solve much more questions than these stupid 4 blades of Gillette! So soon we will reach 10?
So the world is changing. Unilever claims to have a cool IT system that allows it. In the end, it looks like a Time-to-market concept that no one has already spoken about.
The point of the Time-to-market is not how often we deploy. You can often deploy, but release cycles will be long. If the three-month release cycles overlap each other, shifting by a week, it turns out that the company seems to be deployed once a week. And from the idea to the final implementation, 3 months pass.
Time-to-market is about minimizing time from an idea to the final implementation.
In this case, software interacts with the market. This is how One Box Shave interacts with the site. They have no sellers - just a site where the visitor clicks and leaves wishes. Accordingly, the site must constantly post something new, update it in accordance with the wishes. For example, in South Korea, they shave differently than in Russia, and they like the smell of pine, but, for example, vanilla
Since you need to quickly change the content of the site, software development is changing greatly. Through software, we must find out what the client wants. Previously, we learned this by some workarounds, for example, through business management. Then they designed, laid the requirements in the IT system, and everything was cool. Now it’s different - the software is designed by everyone who is involved in the process, including engineers, because they learn through technical specifications how the market works, and also share their insights with the business.
For example, at Qik, we suddenly found out that people really like to upload contact lists to the server, and they put us the application. Initially, we did not think about this. In a classic company, everyone would decide that it was a bug, since the spec does not say that it should work cool and was generally implemented on the knee, they would turn off the feature and say: "This does not need anyone, the most important thing is that the main functionality works" . And the technology company sees this as an opportunity and begins to change software in accordance with this.
In 1968, the visionary guy Melvin Conway formulated the following idea.
The organization that creates the system is limited to a design that copies the communication structure in that organization.
In more detail, in order to produce systems of a different type, one must also have a communication structure within a company of another type. If your communication structure is top hierarchical, this will not allow you to create systems that can provide a very high Time-to-market indicator.
You can read about Conway’s law by following the links . It is important for understanding the culture or philosophy of DevOps, since the only thing that changes fundamentally in DevOps is the communication structure between the teams .
From the point of view of the process, before DevOps, all stages: analytics, development, testing, operation, were linear.
In the case of DevOps, all these processes go simultaneously.
Time-to-market can only be done this way. For people who worked in the old process, it looks somewhat cosmic, and generally so-so.
So why do you need DevOps?
For the development of digital products . If you don’t have a digital product in your company, DevOps is not needed - this is very important.
DevOps overcomes the speed limits of a consistent software production scheme . In it, all processes occur simultaneously.
Increases difficulty. When DevOps evangelists tell you that it will be easier for you to release software with it, this is nonsense.
With DevOps, things will only get more complicated.
At the conference at Avito's stand, one could see what it is to deploy a Docker container - an unrealistic task. Complexity becomes prohibitive, you have to juggle with many balls at the same time.
DevOps completely changes the process and organization in the company - more precisely, it does not change DevOps, but a digital product. To come to DevOps, you still need to completely change this process.
Questions for a specialist
What about you? Questions that you can ask yourself when working in a company and developing as a specialist.
Do you have a digital product strategy? If there is, it’s already good. This means that your company is moving towards DevOps.
Is your company already creating a digital product? This means that you can go up another notch and do things more interesting - again, from the point of view of DevOps. I only speak from this point of view.
Is your company one of the market leaders in a niche with a digital product? Spotify, Yandex, Uber - companies that are at the peak of technological progress now.
Ask yourself these questions, and if all the answers are negative, then maybe you should not deal with DevOps in this company. If the DevOps theme is really interesting to you, maybe ... should you move to another company? If your company wants to go to DevOps, but you answered “No” to all the questions, then it resembles this beautiful rhino that will never change.
Organization
As I said, according to Conway’s law, an organization changes in a company. To begin with, what prevents DevOps from entering the company from the point of view of the organization.
The problem of "wells"
The English word "Silo" is translated here into Russian as "well". The meaning of this problem is that between the teams there is no exchange of information . Each team digs its expertise deep into, while not building a common map in which you can navigate.
In some ways, it resembles a person who has just arrived in Moscow and still does not know how to navigate the metro map. Muscovites usually know their area very well, and throughout Moscow they are guided by the metro map. When you come to Moscow for the first time, there is no this skill, and you are simply disoriented.
DevOps offers to pass this moment of disorientation and to all departments together to build a common map of interaction.
Two factors interfere with this.
A consequence of the corporate management system. It is built by separate hierarchical "wells". For example, there are certain KPIs in companies that support this system. On the other hand, the brains of a person who is difficult to go beyond the limits of their expertise and navigate throughout the system interfere. It is just uncomfortable. Imagine that you got to the Bangkok airport - there you will not quickly find your bearings. DevOps is also difficult to navigate, and therefore people say that you need to find a guide to find it to get there.
But most importantly, the problem of “wells” for an engineer who was inspired by the spirit of DevOps, was read by Fowler and a bunch of other books, is expressed in the fact that “wells” do not allow you to do “obvious” things. We often get together after DevOps Moscow, talk with each other, and people complain:
- We just wanted to launch CI, but it turned out that management didn’t need it.
This is precisely due to the fact that CI and the Continuous Delivery process are on the border of many examinations. Just not overcoming the problem of “wells” at the organizational level, you will not be able to advance further, whatever you do and how sad it may be.
Each participant in the process in the company: backend and frontend developers, testing, DBA, operation, network, digs in his own direction, and no one has a common card except a manager who somehow observes and controls the divide and conquer method.
People fight for some little stars or flags, each digs his own expertise.
As a result, when the task appears to connect all this together and build a common pipeline, and there is no need to fight for the stars and flags, the question arises - what should I do? We must somehow agree, but nobody taught us how to do this. We have been taught from school: the eighth grade - wow! - compared to the seventh grade! It’s the same here.
Is it the same in your company?
To check this, you can ask yourself the following questions.
Do teams use common tools, do they contribute to changes to these common tools?
How often do teams reform? Do some specialists from one team move to another team? It is in the DevOps environment that this becomes normal, because sometimes a person simply cannot understand what another area of expertise is doing. He moves to another department, works there for two weeks to create for himself a map of orientation and interaction with this department.
Is it possible to create a committee on change and change something?Or does this require a strong hand of the highest leadership and direction? I recently wrote on Facebook how one little-known bank implements tools through orders: we wrote an order, we’ve implemented it for a year, and we’ll see what happens. This, of course, is long and sad.
How important is it for managers to receive personal achievements without taking into account the achievements of the company?
If you answer these questions for yourself, it will become clearer if you have such a problem in the company.
Infrastructure as code
After this problem has been resolved, the first important practice, without which it is difficult to move further into DevOps, is infrastructure as a code .
Most often, the infrastructure as a code is perceived as follows:
- Let's automate everything on bash, cover ourselves with scripts so that the admin area has less manual work!
But this is not so.
Infrastructure as a code implies that you describe the IT system with which you work in order to constantly understand its status.
Together with other teams, you create a map in the form of a code that everyone understands, which you can navigate and navigate. It doesn’t matter on what it is done - Chef, Ansible, Salt, or YAML files are used in Kubernetes - there is no difference.
At the conference, a colleague from 2GIS talked about how they made their own internal thing for Kubernetes, which describes the structure of individual systems. To describe 500 systems, they needed a separate tool that generates this description. When there is this description, everyone can check with each other, monitor changes, how to change and improve it, which is missing.
Agree, separate bash scripts usually do not give this understanding. In one of the companies where I worked, there was even a name “write only” - a script - when the script is written, and it is already impossible to read it. I think this is familiar to you too.
Infrastructure as a code is a code that describes the current state of the infrastructure . Many product, infrastructure, and service teams work together on this code, and most importantly, they all need to understand how this code generally works.
The code is accompanied according to the best practices of working with code : joint development, code review, XP-programming, testing, pull-quests, CI for code infrastructures - all this is suitable and can be used.
Code is becoming a common language for all engineers.
Changing the infrastructure in the code does not take much time . Yes, there may also be technical debt in infrastructure code. Usually, teams encounter it a year and a half after they started to implement "infrastructure as code" in the form of a bunch of scripts or even Ansible, which they write as spaghetti code, and even bash scripts put it in the firebox!
Important : if you haven't tried this stuff yet, remember that Ansible is not bash ! Read the documentation carefully, study what they generally write about it.
Infrastructure as code is the division of infrastructure code into separate layers.
In our company, we distinguish 3 basic layers, which are very clear and simple, but there may be more. You can look at your infrastructure code and say whether you have this condition or not. If no layers are highlighted, then you need to allocate time and refactor a little.
The base layer is how the OS, backups, and other low-level things are configured, for example, how Kubernetes is deployed at a basic level.
Service level - these are the services that you give the developer: logging as a service, monitoring as a service, a database as a service, a balancer as a service, a queue as a service, Continuous Delivery as a service - a bunch of services that individual teams can provide development. All this must be described as separate modules in your configuration management system.
The layer where the applications are made and how they will be deployed on top of the previous two layers.
test questions
Do you have a common infrastructure repository in your company? Do you control technical debt in infrastructure? Do you use development practices in the infrastructure repository? Is your infrastructure sliced? You can check the Base-service-APP schema. How difficult is it to make a change?
If you are faced with the fact that the introduction of changes took a day and a half, this means that you have a technical debt and you need to work with it. You just stumbled upon a rake of technical debt in the infrastructure code. I remember many such stories when in order to change any CCTL, it is necessary to rewrite half the infrastructure code, because creativity and the desire to automate everything led to the fact that everywhere everything is shorted, all the pens are removed, and you need to refactor.
Continuous delivery
Similar debit with a loan. First, a description of the infrastructure appears, which can be quite basic. It is not necessary to describe everything in detail, but some basic description is required so that you can work with it. Otherwise, it is not clear on top of what further to do continuous delivery. All these practices unfold at the same time when you come to DevOps, but you need to start by understanding what you have and how to manage it. This is just the practice of infrastructure as code.
After it became clear that you have how to manage this, you begin to think of how to send the developer code to production as quickly as possible. I mean, together with the developer - we remember the problem of "wells", that is, not individual people come up with this, but by the team.
When we are with Vanya Evtukhovichsaw the first book of Jes Hamble and the group of authors “Continuous Delivery” , which was published in 2009, then for a long time they thought how to translate its name into Russian. They wanted to translate it as “Constantly deliver”, but, unfortunately, translated as “Continuous delivery”. It seems to me that there is something Russian in our title with pressure.
Constantly deliver - that means
The code that lies in the grocery repository can always be downloaded in production . It may not be deflated, but it is always ready for it. Accordingly, you always write code with a difficult to explain feeling of some concern under the tailbone. It often appears when you roll out the infrastructure code. This feeling of some concern should be present - it causes brain processes that allow you to write code a little differently. This should be fixed in the rules within the development.
To deliver constantly, you need an artifact format that runs across the infrastructure platform.If you throw on the infrastructure platform of a different format "waste", then it becomes not unified for you, it is difficult to maintain, there is a problem of technical debt. The artifact format needs to be aligned - this is also a collective task: everyone needs to get together, rustle with their brains and come up with this format.
The artifact is constantly improving and changing to the production environment while passing through the supply pipeline.When the artifact moves along the pipeline, it constantly encounters some uncomfortable things for it, which are similar to what the artifact that you put in production encounters. If in the classical development the sysadmin does this, it does the rolling out, then in the DevOps process this happens all the time: here it was twisted by some tests, here - in the Kubernetes cluster they threw it, which is more or less similar to production, then load testing was suddenly launched .
This is somewhat reminiscent of a Pakman game - an artifact goes through some kind of story. At the same time, it is important to control whether the code really goes through the story and is somehow related to your production. Production stories can be dragged into the Continuous Delivery process: it happened when something fell, now let's just program this script inside the system. Each time the code will go through this script too, and you will not encounter this problem the next time. You will learn about her much earlier than she comes to your client.
Different deployment strategies. For example, you use AB testing or canary deployments to "probe" the code in different clients, get information about how the code works, and much earlier than when it rolls out to 100 million users.
“Constantly deliver” looks like this.
The delivery process Dev, CI, Test, PreProd, Prod is not a separate environment, it is stages or stations with fireproof amounts through which your artifact passes.
If you have the infrastructure code that is described as Base Service APP, then it helps not to forget all the scripts , and write them down as code for this artifact, promote the artifact and change it as you move.
Self Test Questions
The time from the description of features to rolling out in production in 95% of cases less than a week? Does artifact quality increase at every stage of the pipeline? Is there a story he goes through? Do you use different deployment strategies?
If all the answers are yes, then you are unrealistically cool! Write the answers in the comments - I will be happy).
Feedback
This is the hardest practice of all. At the DevOpsConf conference, a colleague from Infobip, talking about her, was a little confused in words, because it is really a very difficult practice about the fact that everything needs to be monitored!
For example, a long time ago, when I worked at Qik and we realized that we needed to monitor everything. We did this, and in Zabbix we have 150,000 items that are constantly monitored. It was scary, the technical director twisted his finger at the temple:
- Guys, why are you raping the server for some reason?
But then there was a case that showed that this is really a very cool strategy.
One of the services began to fall constantly. Initially, it did not fall, which is interesting, the code was not added there, because it was a basic broker in which there was practically no business functionality - it simply drove messages between separate services. The service did not change for 4 months, and suddenly began to fall with the error "Segmentation fault".
We were shocked, opened our charts in Zabbix, and it turned out that, it turned out, one and a half weeks ago the behavior of requests in the API service that this broker uses has changed a lot. Then we saw that the frequency of sending a certain type of message has changed. After they found out that these are android clients. We asked:
- Guys, what happened to you a week and a half ago?
In response, they heard an interesting story about how they remade the UI. It is unlikely that anyone will immediately say that he changed the HTTP library. For android clients it’s like changing soap in the bathroom - they just don’t remember it. As a result, after 40 minutes of conversation, we found out that they still changed the HTTP library, and its default timings changed. This led to a change in the behavior of traffic on the API server, which led to a situation that caused a race inside the broker, and it began to fall.
It’s impossible to open it without deep monitoring.. If the organization still has a problem of "wells", when everyone throws one on top of another, this can live for years. You just restart the server because it is impossible to solve the problem. When you monitor, track, track all the events that you have, and use monitoring as testing - write the code and immediately indicate how to monitor it, also in the form of code (we already have the infrastructure as code), everything becomes clear how on the palm. Even such complex problems are easily tracked.
Collect all the information about what happens with the artifact at every stage of the delivery process - not in production.
Load monitoring on CI, and there some basic things will already be visible there. Further you will see them both in Test, and in PredProd, and in load testing. Collect information at all stages, not only metrics, statistics, but also logs: how the application rolled out, anomalies - collect everything.
Otherwise, it will be difficult to figure out. I already said that DevOps is a lot of complexity. To cope with this complexity, you need to have normal analytics .
Questions for self-control
Is your monitoring and logging a development tool for you? Do your developers, including you, when writing code, think about how to monitor it?
Do you know about problems from customers? Do you understand the customer better from monitoring and logging? Do you understand the system better from monitoring and logging? Do you change the system simply because you saw that the trend in the system is growing and you understand that 3 more weeks and everything will bend?
When you have these three components, you might think about your infrastructure platform.
Infrastructure platform
The point is not that this is a set of disparate tools that every company has.
The meaning of the infrastructure platform is that all teams use these tools and develop them together.
It is clear that there are separate teams that are responsible for the development of individual pieces of the infrastructure platform. But at the same time, every engineer is responsible for the development, availability, and promotion of the infrastructure platform. At the domestic level, this is becoming a common tool .
All teams develop the infrastructure platform, treat it carefully as their own IDE . In your IDE, you put different plugins so that everything is beautiful and fast, you set up hot keys. When you open Sublime, Atom, or Visual Studio Code, you get code errors pouring in and you realize that it's impossible to work at all, you immediately feel sad and you run to repair your IDE.
Also apply to your infrastructure platform. If you understand that something is wrong with her, leave a request if you can not fix it yourself. If there is something simple there - edit it yourself, send a pull request - the guys consider, add. This is a slightly different approach to engineering tools in the head of the developer.
The infrastructure platform provides the transfer of artifact from development to the client with a constant improvement in quality . The programmer has programmed a set of stories that happen to the code in production. Over the years of developing these stories, there are a lot of them, some of them are unique and apply only to you - it is impossible to google them.
At this point, the infrastructure platform becomes your competitive advantage., because it is sewn into it that is not in the tool of a competitor. The deeper your IP, the greater your competitive advantage in the sense of Time-to-market. Here comes the vendor lock problem : you can take someone else’s platform for yourself, but using someone else’s experience, you won’t understand how relevant it is to you. Yes, not every company can build a platform like Amazon. This is a difficult line, where the company's experience is relevant to its market position, and vendor lock cannot be lowered there. This is also important to think about.
Scheme
This is the basic framework of the infrastructure platform that will help you establish all the practices and processes in the DevOps company.
Consider what it consists of.
A resource orchestration system that provides CPU, memory, disk to applications and other services. On top of this are low-level services : monitoring, logging, CI / CD Engine, artifact storage, infrastructure as system code.
Higher level services : database as a service, queues as a service, Load Balance as a service, resizing pictures as a service, Big Data factory as a service. On top of this is a pipeline that delivers a constantly modified code to your client .
You get information about how your software works with a client, change it, deliver this code again, get information - and so constantly develop both the infrastructure platform and your software.
In the diagram, the delivery pipeline consists of many stages. But this is a circuit diagram, which is given as an example - do not repeat it one to one. Stages interact with services as with services - each brick of the platform carries its own story: how resources are allocated, how the application starts, works with resources, monitors, changes.
It is important to understand that each part of the platform carries a story, and ask yourself what story this brick carries, maybe it is worth throwing it away and replacing it with a third-party service. For example, can I put Okmeter instead of a brick? Perhaps the guys have already pumped this expertise much more than we did. But maybe not - maybe we have a unique expertise, we need to put Prometheus and develop it further.
Platform creation
This is a complex communication process. When you have basic practices, you start communication between different engineers and specialists who develop requirements and standards, and constantly change them to different tools and approaches. The culture that DevOps has is important here.
Everything is very simple with culture - this is cooperation and communication , that is, the desire to work in a common field with each other, the desire to own one tool together. There is no rocket science - everything is very simple, corny. For example, we all live in the stairwell and maintain its cleanliness - such a level of culture.
What about you?
Again, questions that you can ask yourself.
Is the infrastructure platform dedicated? Who is responsible for its development? Do you understand the competitive advantages of your infrastructure platform?
These questions must be constantly asked yourself. If something can be transferred to third-party services - you need to take it out, if a third-party service begins to block your movement, then you need to build a system inside yourself.
So DevOps ...
... this is a complex system, it should include:
- Digital product.
- The business modules that this digital product is developing.
- Product teams that write code.
- Continuous Delivery practices.
- Platforms as a service.
- Infrastructure as a service.
- Infrastructure as a code.
- Separate reliability practices wired inside DevOps.
- Feedback practice that describes all this.
You can use this scheme by tinting in it what you already have in your company in some form: it has developed or still needs to be developed.
In a couple of weeks, DevOpsConf 2019 will be held . as part of RIT ++. Come to the conference, where you will find many cool reports on continuous delivery, infrastructure as a code and DevOps transformation. Book your tickets , last deadline for prices is May 20