How to start DevOps transformation
If you do not understand what DevOps is, then here is a short cheat sheet. DevOps is a set of practices that reduce the fears of engineers and reduce the number of failures in software production. As a rule, they also reduce the time to market - the period from the idea to the delivery of the final product to customers, which allows you to quickly conduct business experiments .
How to start DevOps transformation? In short: we select the service from which we will start the process, identify those who are related to the service, build the Value Stream Map, create a temporary team that will deal with the transformation for the first time and set it a task. We repeat the cycle as many times as necessary.

A detailed DevOps transformation plan with examples and instructions under the cut is in the decoding of the report of Andrei Alexandrov , an engineer at Express42, which advises on germinating DevOps, accelerating this process, because it has already built a rake map. If you think that you don’t need the transformation, or if you have such a specificity that DevOps practices are not suitable, use the report as an instruction for finding and eliminating restrictions.
If you are concerned about the issue of DevOps transformation, then you have a big company, and you need to gradually scale this process to the entire structure. As long as there is a need to transform the team or remove some kind of restriction, the algorithm below can be repeated.
We have outlined a plan, start with the first step - choosing a service. The first criterion is the lifetime : there are old services - legacy, and new ones. You can start with those and others.
It’s logical to choose a young service . It is fresh, there is no well-established process of working in a team that deals with it. Around him there is no mountain of technical debt, no need to repair it all the time. We can do whatever we want with him.
In the case of the old service, there are problems associated with the fact that it is always difficult to change . There already is a set of some serious restrictions, but perhaps people who are already ready to shovel it all deal with it - they are tired and want to do something differently, because it hurts.
Working with the old service sets a powerful precedentin your company - you can change something. If you changed a new service, it rolls to prod 100 times per hour, and everything is fine, then people in your company can say:
- This is a new service! Everything was simple there, try to do something with our pimped things.
It makes sense to take a Legacy service into a transformation when you do it with someone, for example, if you invited an external consultant. Let's be honest, the transformation will stagger everything that is possible . You are experimenting and do not know where you will come, what technologies and why you will use, where and what pitfalls will arise in the processes. Therefore, a new change is easier.
There are services that are just an interface for users, for example, a simple website or a mobile application. But there are serious things in the spirit of billing. If something goes wrong with billing, it will be difficult to understand. Here we also have a choice.
We work either with a critical service , but already suffer because of it, it creates restrictions, or we work with the interface . This is the second selection criterion. Similarly, it is possible to attract an experienced consultant - we work with a difficult option.
But even in this case, I would not advise doing so, because while there is no understanding what to work with and how to transform, taking a critical thing and shaking it is not a good idea. Therefore, in this case, we prefer to work with an interface whose failure is not critical.
Next, consider the service command . With those who are engaged in this service, we will have to constantly work and interact in very close contact.
People in the team are conditionally divided into two categories: conservatives - they live in the old world, or simply don’t know anything about DevOps, and innovators who carry all the fashionable practices. The latter do not always understand the topic, but at least they are ready for it.
On the one hand, conservatives are experienced people: they have been with the company for a long time, they understand it completely, but they don’t know just about practices. On the other hand, there are innovators who have heard something, but most likely they have been working for the company not so long ago. Which of them is better to work with?
In any case, you will have to interact with conservatives, as this is their service. We’ll have to communicate with them, find out the specifics of the service, what can be done this way and what’s different. We depend on their advice. Surely they will have to entrust something, because they know their service better. Therefore, it is important which team we will eventually have contact with.
In practice, it often happens that conservative people have significant experience, but there is no understanding of how to live on. They are simply afraid that after the transformation and alteration of the service, they will be dismissed as unnecessary. Sometimes, simply because of a lack of understanding of what is happening, they sabotage the work.
I had a case when a guy from a team repaired anything, because it is supposedly more critical than what we are doing now. We set the task: to realize this piece today - no, there is a fire on the other side of the world, we are going to repair it. It is difficult to work with such people.
People from the conservative team often clog on tasks, or put them off until the last. And if, John Willis save you, you made a mistake and hung them with KPI for the number of tasks completed, and for some reason some of them were not included in KPI, then they won’t do anything at all. In general, they will be right, because then they lose the bonus.
It’s easier with innovators - they are more loyal . They already heard something, they want to go somewhere, so they will help. We need people who are ready to suffer the first time: if the service changes, then all the cones and rakes will be caught by innovators as pioneers. Innovators want the newest and the most fashionable, and suffer.
Conservatives can later be converted. When you show that you have changed a piece and everything works well, most likely they will also want to try and adopt the new DevOps religion.
If it is possible to call an external consultant, instead of a new one, we take the old service, because of which we are already suffering. People who have been engaged in transformation for quite some time in different companies have seen different cases and already understand how to do it right and which way to go.
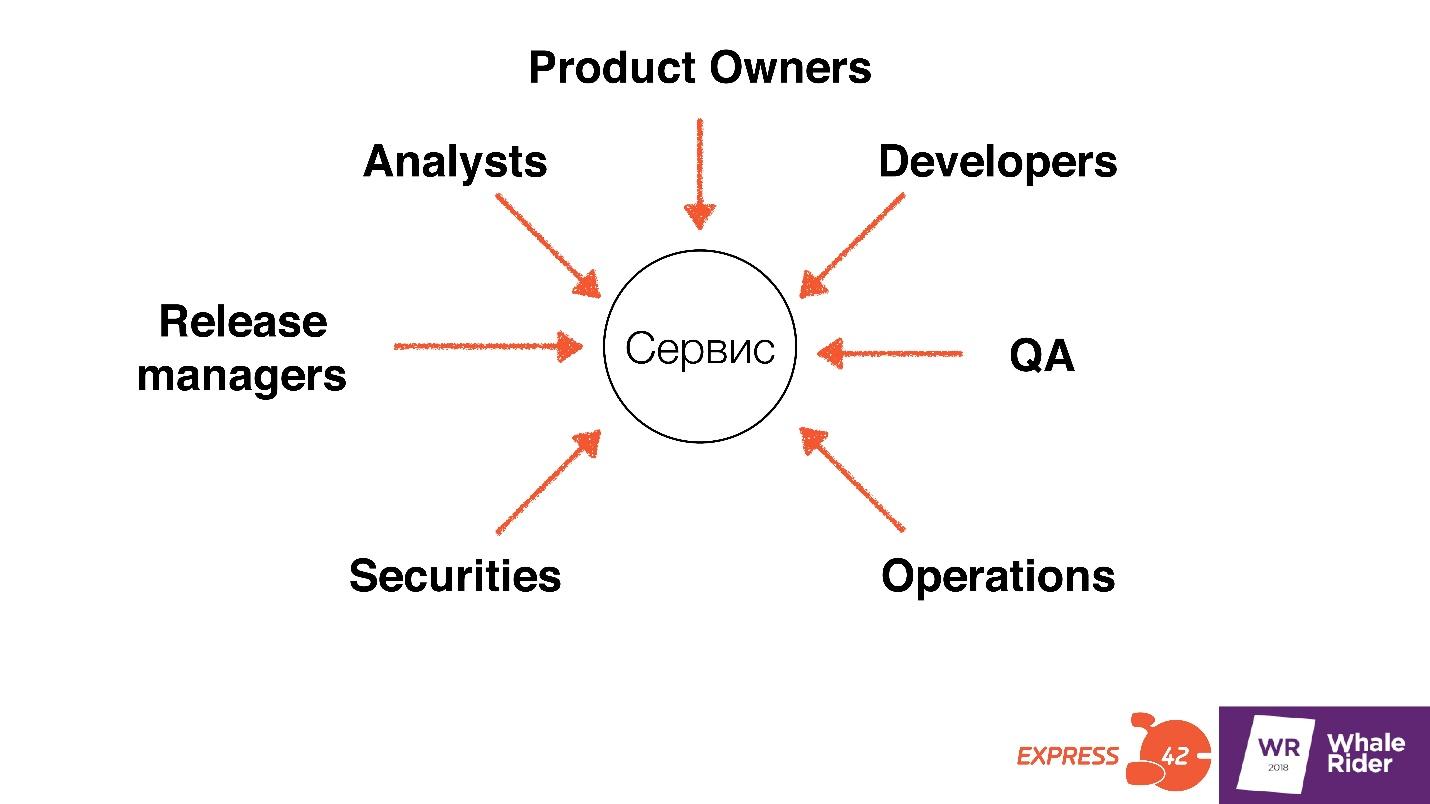
We need to find in general everyone who has at least something to do with the service: developers, testers, admins, security guards, managers, and possibly Product Owners. Despite the fact that Product Owners are not techies, they are related to the service: make a decision, set a task.
What are they for us? To know who to negotiate with . During the transformation, when the usual principle of working with the service changes, it will shake anyway. There will be glitches for a while while we test new approaches. People should be prepared for this and agree with it.
Then you have to build a Value Stream Map and without these people you can’t build it, because only they all together know the full picture of what is happening. One person never knows everything that happens with the service.
They will advise people on the team. Later we will discuss why a separate team is needed. It will have to take people from existing departments. Those who are related to the service will be able to recommend colleagues who think in our direction, who can help us and have the competence in what we need.
Then we collect all these people from different departments into one room and begin to build a Value Stream Map.
Value Stream Map is a diagram or map that shows the flow of values to the client . This is the whole process from inventing an idea to its implementation, including all the intermediate stages and how the value ultimately reaches our customers.
The Value Stream Map is needed to visualize all stages of development , to localize problems through measurements that are in the current process, and to begin to eliminate these problems and set an initial goal . This is the place where we will start to really do something.
There are many different metrics described in the Value Stream Map literature, but for starters, we only need three.
Lead Time - delay / wait - the time when we wait for something. For example, the tester waits until the test stand is freed up and cannot do anything at this time.
Value Added Time - the time of useful work - the one that we spent at such and such a stage to create the ultimate value for the user. For example, a tester ran his test and began to test something. This is the time of useful work when we really do something for the product. This is what customers pay for - for quality software.
% C / A - percentage of accepted work. We have one stage - development, the second stage - testing. How many features testers took from developers, and there is this percentage.
This is what our map looks like.
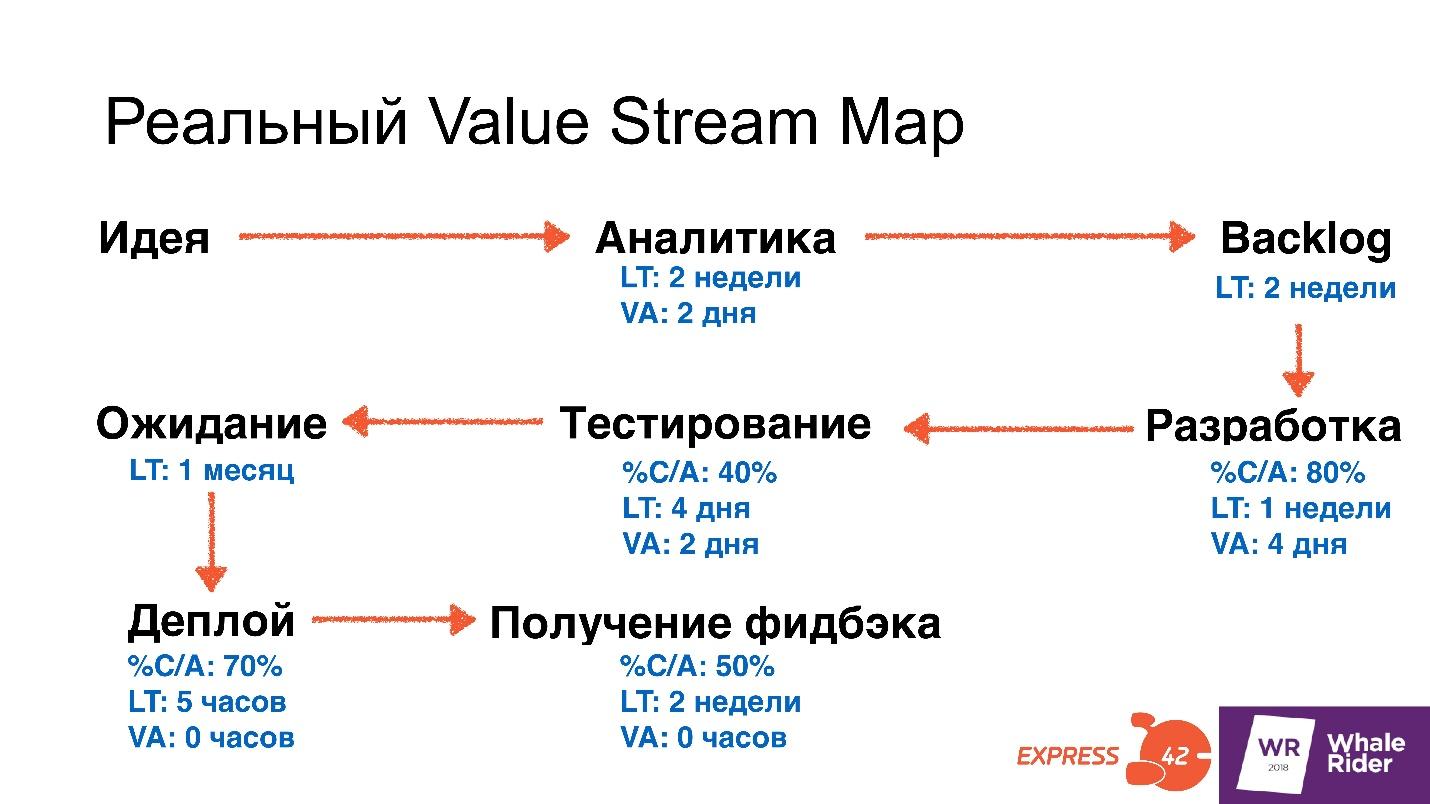
It may look different depending on the structure of the organization, the number of departments and what you do. But in the general case, the map will have two stages: an idea and analytics . At this point, data is expected, for example, Lead Time 2 weeks and Value Added Time 2 days.
Backlog - how many tasks lay after the analysts came up with them.
Development - how many weeks developers have been waiting for clarifications on tasks, stands or equipment - it doesn’t matter, but they are waiting for something. For example, they implement a feature for 4 days. The% C / A metric appears here. Developers took only 80% of the tasks from Backlog. They believe that the remaining 20% do not have clear TK, and sent them for revision.
Testing . On the LT scheme, 4 days are set. For example, testers were waiting for the test bench to be released, VA for 2 days they really are testing something, and% C / A = 40%. - only 40% of the code or features that the developers sent were considered by testers to be adequate. They did not like the rest for some reason.
I will not dwell on how to carry out these measurements, at the end of the article I will recommend literature from which you can learn about them.
The only thing I advise is do not believe the people who will be composing the Value Stream Map with you. They represent how much time the different processes take, but these estimates are not always correct, therefore it is better to measure yourself.
We had a case when we came to the Operations department and asked how long it takes to deliver a new feature to production. They answered that 10 minutes, and we thought, why did we come to this company? It turned out that 10 minutes is the running time of the script, which takes the code and delivers it to the server. But before this, the release lies three days on the server and just gathers dust - in Backlog lies the task that needs to be deployed. It turns out that before the deployment stage there is a waiting stage when the project simply lies. If we had not gone with a notebook, had not caught our eyes on a task in Jira, and had not begun to track it in stages, we would have thought that everything was wonderful and there was no problem.
Therefore, measurements will still have to be done by yourself, preferably more than once, in order to have a representation close to reality. Depending on the Value Stream Map, you will decide on where to start and what to fix first.
Many companies that have decided to introduce DevOps create a team, not just temporary, but existing for several years. If you go to the DevOps apologize service, which describes the different patterns for building an organizational structure in DevOps, then you will understand that this is an antipattern.
If a team exists between departments, only to do something else separate, and exists for a long time, then it creates an extra barrier. Now, instead of going directly to the administrator, the programmer needs to first contact the DevOps department, and he will go further.
Therefore, to start, you need to create a temporary team. It will exist for a suspended period of six months, maximum a year, depending on the task, only to eliminate one limitation that we have chosen. Then she will die. If we choose the next point where it hurts a lot and understand that we also need a separate team for it, then we will create it again. But such teams should not exist on a “permanent basis” - then they only interrupt communication and take on separate tasks in general, only to do something. These tasks may not be related to DevOps or transformation at all. Why don't we give this task to the existing departments?
Conflict with current processes . DevOps transformation is a change not only of the technologies and tools that we use, but a change in the process of work, thinking and values. If the team works the way she’s used to, she won’t be able to try other approaches.
These people should live by different rules: ignore all KPIs in the company, because they try to work differently. Temporary teams will not fill out applications to get a server, but will go directly to the department that manages them, demanding that they be the very first to give what they need, because this is a priority task and because they try to live differently. The team has a complete conflict with all current processes. So that the existing working methods do not interfere with them now, and they do not interfere with others, we isolate these people by singling them out as a separate team.
Avoiding bureaucracy in experiments. There is no bureaucracy in temporary teams; they do not fill out reports on working hours; they do not report to managers. This is a completely separate world in which people live and think differently, and do completely different things. Do not bother them once again.
Non-stop work on the service . In the first paragraph, we have chosen something to experiment with. Experimenting and finding ways to work better is good, but we also want to do features. If the whole team engages in transformation instead of features, then we will begin to lose revenue, bugs will hang for a long time - we do not need this. Creating a temporary team allows you to experiment without stopping work on the product.
Do not waste time on work tasks. This is again about the product. It takes a lot of time for the team to try other tools and stuff. In order for people to master the tools, begin to implement them and use them normally, it will take at least six months. If they will also deal with the product - six months stretch cosmically. If people are engaged in a product, they again work with old processes - we do not need this.
Therefore, we separate people from different departments into a separate team that will deal with the transformation of the service. As a result, the service works, continues to develop, and at the same time, we put some experiments on it.
The team consists of universal people . This means that we took not only developers. We did not come to the service and didn’t take a half-team from there - no, we took people from different departments . A few points ago, we found different departments and different employees that are related to the transforming service. Of these, we are recruiting a team, because it must be universal - we will change the testing process, the development process, and the process of servicing the service. Different competencies are needed.
Usually, we conditionally take a developer, tester and engineer - each one at a time, and together with them we come up with a solution that allows you to live differently.
It is desirable that these people have authority in the organization. You may have to take one conservative, although you do not want to. If we have a large company, not everyone will believe in our venture, and someone can put sticks in the wheels, for example, not highlight a stand. Here you will need "authority" - a respected person with extensive experience, who deserves a good attitude from colleagues. The authority of the employee in the team will simplify the task and work of the temporary team. People will think:
- Yeah, this cool dude that we all know and love, blended in there - apparently there is something worth looking into DevOps!
We gathered people, chose a service, looked at the restrictions, determined which people we will influence. Now you need to set a goal and it should be right on SMART - that's all we love.
Specific - specific .
Measurable - measurable . This is a very important point of SMART. If you cannot measure something, then you cannot change it and understand what and how you have done better or worse.
Achievable is achievable . Adjust for your specifics. If you are an enterprise company with a long history and a large burden of responsibilities, which releases a product version once a year, you will not be able to achieve the release of new product versions every hour in six months. It won’t work out that way. Therefore, set a real goal that is achievable in an acceptable period.
Relevant - Relevant.We only eliminate the limitation that really pursues our current goals.
Time Limited - time limited . If there is no deadline, the team will do anything: try 15 technologies instead of 3, write huge reports, conduct useless research, lick its implementation to a shine when the goal is already achieved.
We take the goal with the help of the Value Stream Map - again we collect all the people and draw. But only now, based on the previous Value Stream Map, we draw what we want to get.
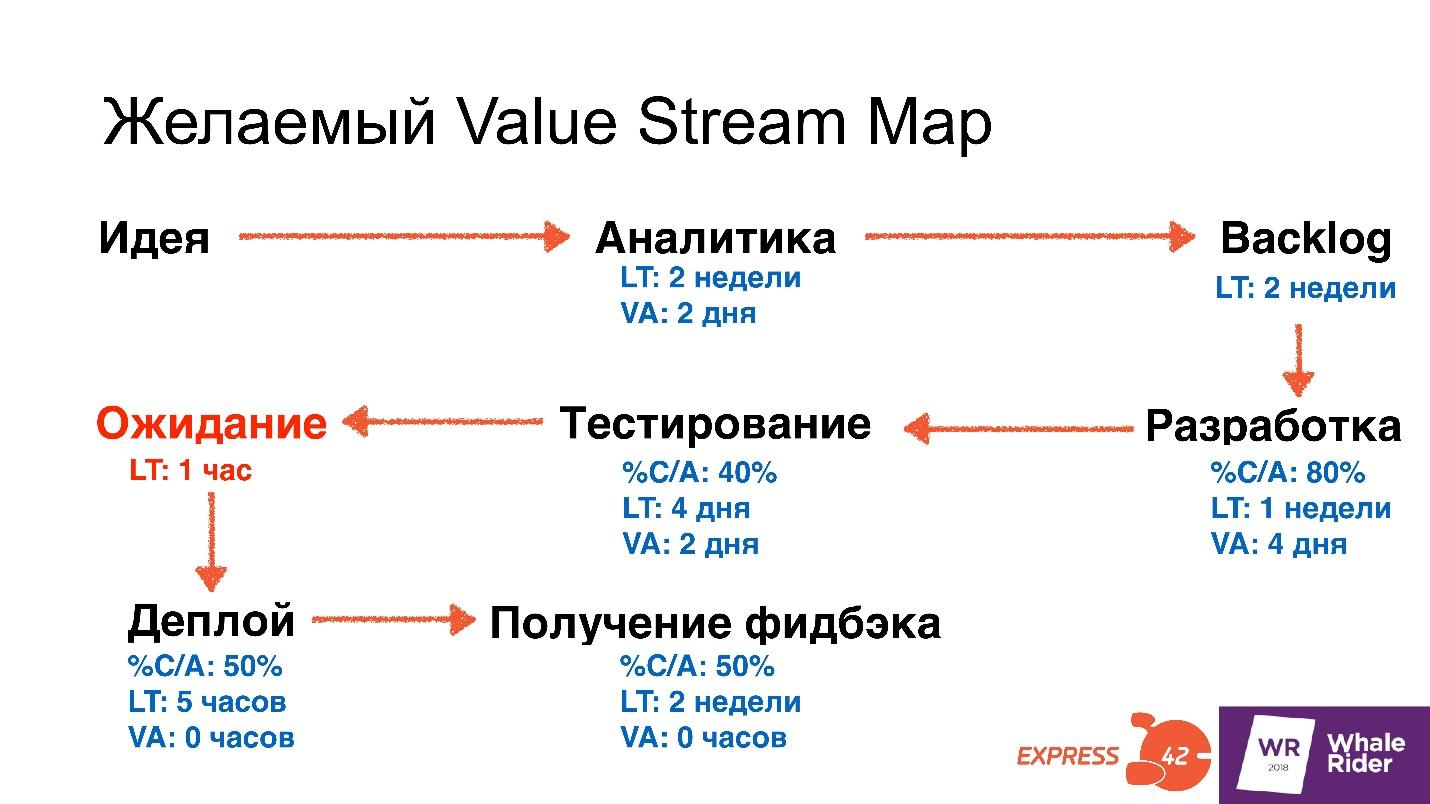
We single out one limitation that we will eliminate right now - this is what the team will do. As an example, I took the expectation from a finished release to its deployment in production - this is the most common limitation that people turn to consultants.
Based on this, we set the task: we want the wait between a ready release and going into action to be a maximum of an hour.
Examples of tasks.
Examples of tasks are not taken from the head - they are based on the measurements that we did when developing the Value Stream Map.
We set a similar task to our team and a time limit. Depending on how well your company is doing, you set different deadlines. On average, it takes half a year to eliminate the restriction, if people do this for the first time and still don’t know with what technologies and how they will solve the problem.
So, our team is created, it has a goal, people begin to work. An important point is a short work planning: sprints of one to two weeks and, no more, measurable improvements every week and course correction .
For example, we often use the moving-moving approach , when the whole team gathers at the beginning of each week, throws into a file what everyone will do. A week later, we note: what has been done and what is not, if not, then why, and we think what to do next.
They tried something for a week or two: technologies, approaches, ways of working, after that you measure again and look - has this approach become better or worse? If it’s worse, then we are going the wrong way, we need to adjust the course: to set a different task, take a different technology or do something else. Short sprints for 1-2 weeks allow you to maneuver and get away from bad decisions in time.
The team achieves some success, small or large - it doesn’t matter, there is always some result. Everyone should know about this result: both those involved in DevOps and the neighboring departments. In an ideal world, it is desirable that this reaches generally all the people in the company .
What for? If we want to transform not a part of the company, eliminate not one restriction, but generally everything, so that the company becomes flexible, the code quickly flies to the client, and nothing breaks, we need everyone to be loyal to the idea of DevOps. You will not be able to take an approach to services and teams that are categorically against.
For loyalty to appear, we must tell everyone that we tried this - we have a result, try it too! This will increase interest and loyalty to what we do, people will start trying to do something right now. As practice shows, when we tell what we tried and what we achieved, other teams begin to ask how and what they did. They look at implementations, code, documentation, come up with questions and try to change something at home.
We choose the service as a starting point - that is the place where we start the changes in the company. We identify everyone who has anything to do with the service and build a Value Stream Map with them , measure and see where and what are the limitations.
We create a new temporary team that will solve the task. Based on the measurements and the Value Stream Map, we draw a new map, where we highlight the limitation that we will solve . Based on this limitation, we set the task that the team will be engaged in. The task must necessarily be SMART - specific, measurable, relevant to current tasks and limited in time.
Repeat the processuntil we transform absolutely all our services to the required form and eliminate all restrictions.
For those who decide to do DevOps on their own.
The original title is “The Phoenix Project: A Novel about It, Devops, and Helping Your Business Win”. This is a novel about DevOps - the story of how an employee was made the head of the department, who was constantly on fire. The new boss was given the task:
- You have several years to fix everything so that we can finally quickly and efficiently deliver our product to our customers.
“The Phoenix Project. A novel about how DevOps is changing life for the better ”is a book for all managers, because these people make decisions about what is happening in the company. If you are an engineer or programmer and you want your company to start moving and transforming, buy a book and give it to management. This novel explains everything, and is read quickly and easily.
The book is more complicated. It was released several years ago in English under the title “The DevOps Handbook How to create world-class agility, reliability, and security in Technology organizations”, but now it is already in Russian. This is a real handbook - a practical guide : how to take measurements, what is Value Stream Map and why is it needed, where is it worth moving, in what order. The book is just for those who want to do everything on their own. Most importantly, it contains examples of the experience of other companies.
For example, it tells how one company built a Value Stream Map and realized that its limitation was not in the product, but in the fact that the cashier goes from the store to the neighboring office to use this product. Instead of solving the problem with the program, they just bought tablets for their sellers, and now no one is going anywhere, and all actions are performed at the workplace. Conclusion: Value Stream Map can be extended not only to software, but also to all processes in the organization.
Full name: "Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations." This is the next level - hardcore. The book was published last year, so far only in English and it is about research. Authors Nicole Forsgren, Jez Humble, and Gene Kim have used different practices in different companies for many years and explored which practices, how and what they affect.
The second chapter on measurements refers to the Value Stream Map, the metrics that I called, and many others, and the measurement process is described in detail. Authors measure using questionnaires and self-tracking tasks. It is described in detail which metrics are correct to measure, which are not worth it, human errors in measurements. If you have difficulty measuring, refer to the second chapter of Accelerate. If your team just has a lot of practices, but it’s not clear which practices to apply now, which then, which really work, and which don’t, read the book.
How to start DevOps transformation? In short: we select the service from which we will start the process, identify those who are related to the service, build the Value Stream Map, create a temporary team that will deal with the transformation for the first time and set it a task. We repeat the cycle as many times as necessary.
A detailed DevOps transformation plan with examples and instructions under the cut is in the decoding of the report of Andrei Alexandrov , an engineer at Express42, which advises on germinating DevOps, accelerating this process, because it has already built a rake map. If you think that you don’t need the transformation, or if you have such a specificity that DevOps practices are not suitable, use the report as an instruction for finding and eliminating restrictions.
If you are concerned about the issue of DevOps transformation, then you have a big company, and you need to gradually scale this process to the entire structure. As long as there is a need to transform the team or remove some kind of restriction, the algorithm below can be repeated.
Service selection
We have outlined a plan, start with the first step - choosing a service. The first criterion is the lifetime : there are old services - legacy, and new ones. You can start with those and others.
It’s logical to choose a young service . It is fresh, there is no well-established process of working in a team that deals with it. Around him there is no mountain of technical debt, no need to repair it all the time. We can do whatever we want with him.
In the case of the old service, there are problems associated with the fact that it is always difficult to change . There already is a set of some serious restrictions, but perhaps people who are already ready to shovel it all deal with it - they are tired and want to do something differently, because it hurts.
Working with the old service sets a powerful precedentin your company - you can change something. If you changed a new service, it rolls to prod 100 times per hour, and everything is fine, then people in your company can say:
- This is a new service! Everything was simple there, try to do something with our pimped things.
It makes sense to take a Legacy service into a transformation when you do it with someone, for example, if you invited an external consultant. Let's be honest, the transformation will stagger everything that is possible . You are experimenting and do not know where you will come, what technologies and why you will use, where and what pitfalls will arise in the processes. Therefore, a new change is easier.
If you do everything yourself, but the company does not have serious competence, we take a new service. If you know an external consultant and there are funds - choose the old one.
There are services that are just an interface for users, for example, a simple website or a mobile application. But there are serious things in the spirit of billing. If something goes wrong with billing, it will be difficult to understand. Here we also have a choice.
We work either with a critical service , but already suffer because of it, it creates restrictions, or we work with the interface . This is the second selection criterion. Similarly, it is possible to attract an experienced consultant - we work with a difficult option.
But even in this case, I would not advise doing so, because while there is no understanding what to work with and how to transform, taking a critical thing and shaking it is not a good idea. Therefore, in this case, we prefer to work with an interface whose failure is not critical.
Next, consider the service command . With those who are engaged in this service, we will have to constantly work and interact in very close contact.
People in the team are conditionally divided into two categories: conservatives - they live in the old world, or simply don’t know anything about DevOps, and innovators who carry all the fashionable practices. The latter do not always understand the topic, but at least they are ready for it.
On the one hand, conservatives are experienced people: they have been with the company for a long time, they understand it completely, but they don’t know just about practices. On the other hand, there are innovators who have heard something, but most likely they have been working for the company not so long ago. Which of them is better to work with?
In any case, you will have to interact with conservatives, as this is their service. We’ll have to communicate with them, find out the specifics of the service, what can be done this way and what’s different. We depend on their advice. Surely they will have to entrust something, because they know their service better. Therefore, it is important which team we will eventually have contact with.
It’s logical to choose an innovator team, because conservatives can put a pig.
In practice, it often happens that conservative people have significant experience, but there is no understanding of how to live on. They are simply afraid that after the transformation and alteration of the service, they will be dismissed as unnecessary. Sometimes, simply because of a lack of understanding of what is happening, they sabotage the work.
I had a case when a guy from a team repaired anything, because it is supposedly more critical than what we are doing now. We set the task: to realize this piece today - no, there is a fire on the other side of the world, we are going to repair it. It is difficult to work with such people.
People from the conservative team often clog on tasks, or put them off until the last. And if, John Willis save you, you made a mistake and hung them with KPI for the number of tasks completed, and for some reason some of them were not included in KPI, then they won’t do anything at all. In general, they will be right, because then they lose the bonus.
It’s easier with innovators - they are more loyal . They already heard something, they want to go somewhere, so they will help. We need people who are ready to suffer the first time: if the service changes, then all the cones and rakes will be caught by innovators as pioneers. Innovators want the newest and the most fashionable, and suffer.
Conservatives can later be converted. When you show that you have changed a piece and everything works well, most likely they will also want to try and adopt the new DevOps religion.
To summarize. If we do all the transformation in our company ourselves, then we choose: a new service, preferably a simple interface, so as not to suffer much from its breakdown, and a team of innovators.
If it is possible to call an external consultant, instead of a new one, we take the old service, because of which we are already suffering. People who have been engaged in transformation for quite some time in different companies have seen different cases and already understand how to do it right and which way to go.
Who is involved?
We need to find in general everyone who has at least something to do with the service: developers, testers, admins, security guards, managers, and possibly Product Owners. Despite the fact that Product Owners are not techies, they are related to the service: make a decision, set a task.
Everyone who makes at least some decisions and influences what is happening with the service needs to find, meet and chat.
What are they for us? To know who to negotiate with . During the transformation, when the usual principle of working with the service changes, it will shake anyway. There will be glitches for a while while we test new approaches. People should be prepared for this and agree with it.
Then you have to build a Value Stream Map and without these people you can’t build it, because only they all together know the full picture of what is happening. One person never knows everything that happens with the service.
They will advise people on the team. Later we will discuss why a separate team is needed. It will have to take people from existing departments. Those who are related to the service will be able to recommend colleagues who think in our direction, who can help us and have the competence in what we need.
Then we collect all these people from different departments into one room and begin to build a Value Stream Map.
Building a Value Stream Map
Value Stream Map is a diagram or map that shows the flow of values to the client . This is the whole process from inventing an idea to its implementation, including all the intermediate stages and how the value ultimately reaches our customers.
The Value Stream Map is needed to visualize all stages of development , to localize problems through measurements that are in the current process, and to begin to eliminate these problems and set an initial goal . This is the place where we will start to really do something.
Metrics
There are many different metrics described in the Value Stream Map literature, but for starters, we only need three.
Lead Time - delay / wait - the time when we wait for something. For example, the tester waits until the test stand is freed up and cannot do anything at this time.
Value Added Time - the time of useful work - the one that we spent at such and such a stage to create the ultimate value for the user. For example, a tester ran his test and began to test something. This is the time of useful work when we really do something for the product. This is what customers pay for - for quality software.
% C / A - percentage of accepted work. We have one stage - development, the second stage - testing. How many features testers took from developers, and there is this percentage.
This is what our map looks like.
It may look different depending on the structure of the organization, the number of departments and what you do. But in the general case, the map will have two stages: an idea and analytics . At this point, data is expected, for example, Lead Time 2 weeks and Value Added Time 2 days.
Metrics cover absolutely all stages.
Backlog - how many tasks lay after the analysts came up with them.
Development - how many weeks developers have been waiting for clarifications on tasks, stands or equipment - it doesn’t matter, but they are waiting for something. For example, they implement a feature for 4 days. The% C / A metric appears here. Developers took only 80% of the tasks from Backlog. They believe that the remaining 20% do not have clear TK, and sent them for revision.
Testing . On the LT scheme, 4 days are set. For example, testers were waiting for the test bench to be released, VA for 2 days they really are testing something, and% C / A = 40%. - only 40% of the code or features that the developers sent were considered by testers to be adequate. They did not like the rest for some reason.
I will not dwell on how to carry out these measurements, at the end of the article I will recommend literature from which you can learn about them.
The only thing I advise is do not believe the people who will be composing the Value Stream Map with you. They represent how much time the different processes take, but these estimates are not always correct, therefore it is better to measure yourself.
We had a case when we came to the Operations department and asked how long it takes to deliver a new feature to production. They answered that 10 minutes, and we thought, why did we come to this company? It turned out that 10 minutes is the running time of the script, which takes the code and delivers it to the server. But before this, the release lies three days on the server and just gathers dust - in Backlog lies the task that needs to be deployed. It turns out that before the deployment stage there is a waiting stage when the project simply lies. If we had not gone with a notebook, had not caught our eyes on a task in Jira, and had not begun to track it in stages, we would have thought that everything was wonderful and there was no problem.
Therefore, measurements will still have to be done by yourself, preferably more than once, in order to have a representation close to reality. Depending on the Value Stream Map, you will decide on where to start and what to fix first.
Temporary team
Many companies that have decided to introduce DevOps create a team, not just temporary, but existing for several years. If you go to the DevOps apologize service, which describes the different patterns for building an organizational structure in DevOps, then you will understand that this is an antipattern.
When the DevOps team has existed continuously for several years, this is a big mistake, because DevOps is about communication between departments, about speed and efficiency.
If a team exists between departments, only to do something else separate, and exists for a long time, then it creates an extra barrier. Now, instead of going directly to the administrator, the programmer needs to first contact the DevOps department, and he will go further.
Therefore, to start, you need to create a temporary team. It will exist for a suspended period of six months, maximum a year, depending on the task, only to eliminate one limitation that we have chosen. Then she will die. If we choose the next point where it hurts a lot and understand that we also need a separate team for it, then we will create it again. But such teams should not exist on a “permanent basis” - then they only interrupt communication and take on separate tasks in general, only to do something. These tasks may not be related to DevOps or transformation at all. Why don't we give this task to the existing departments?
Why you need a temporary team
Conflict with current processes . DevOps transformation is a change not only of the technologies and tools that we use, but a change in the process of work, thinking and values. If the team works the way she’s used to, she won’t be able to try other approaches.
These people should live by different rules: ignore all KPIs in the company, because they try to work differently. Temporary teams will not fill out applications to get a server, but will go directly to the department that manages them, demanding that they be the very first to give what they need, because this is a priority task and because they try to live differently. The team has a complete conflict with all current processes. So that the existing working methods do not interfere with them now, and they do not interfere with others, we isolate these people by singling them out as a separate team.
Avoiding bureaucracy in experiments. There is no bureaucracy in temporary teams; they do not fill out reports on working hours; they do not report to managers. This is a completely separate world in which people live and think differently, and do completely different things. Do not bother them once again.
Non-stop work on the service . In the first paragraph, we have chosen something to experiment with. Experimenting and finding ways to work better is good, but we also want to do features. If the whole team engages in transformation instead of features, then we will begin to lose revenue, bugs will hang for a long time - we do not need this. Creating a temporary team allows you to experiment without stopping work on the product.
Do not waste time on work tasks. This is again about the product. It takes a lot of time for the team to try other tools and stuff. In order for people to master the tools, begin to implement them and use them normally, it will take at least six months. If they will also deal with the product - six months stretch cosmically. If people are engaged in a product, they again work with old processes - we do not need this.
Therefore, we separate people from different departments into a separate team that will deal with the transformation of the service. As a result, the service works, continues to develop, and at the same time, we put some experiments on it.
The temporary team is only involved in the DevOps transformation - eliminating the restriction that we found, and nothing more.
The team consists of universal people . This means that we took not only developers. We did not come to the service and didn’t take a half-team from there - no, we took people from different departments . A few points ago, we found different departments and different employees that are related to the transforming service. Of these, we are recruiting a team, because it must be universal - we will change the testing process, the development process, and the process of servicing the service. Different competencies are needed.
Usually, we conditionally take a developer, tester and engineer - each one at a time, and together with them we come up with a solution that allows you to live differently.
It is desirable that these people have authority in the organization. You may have to take one conservative, although you do not want to. If we have a large company, not everyone will believe in our venture, and someone can put sticks in the wheels, for example, not highlight a stand. Here you will need "authority" - a respected person with extensive experience, who deserves a good attitude from colleagues. The authority of the employee in the team will simplify the task and work of the temporary team. People will think:
- Yeah, this cool dude that we all know and love, blended in there - apparently there is something worth looking into DevOps!
We set a goal
We gathered people, chose a service, looked at the restrictions, determined which people we will influence. Now you need to set a goal and it should be right on SMART - that's all we love.
Specific - specific .
Measurable - measurable . This is a very important point of SMART. If you cannot measure something, then you cannot change it and understand what and how you have done better or worse.
Achievable is achievable . Adjust for your specifics. If you are an enterprise company with a long history and a large burden of responsibilities, which releases a product version once a year, you will not be able to achieve the release of new product versions every hour in six months. It won’t work out that way. Therefore, set a real goal that is achievable in an acceptable period.
Relevant - Relevant.We only eliminate the limitation that really pursues our current goals.
Time Limited - time limited . If there is no deadline, the team will do anything: try 15 technologies instead of 3, write huge reports, conduct useless research, lick its implementation to a shine when the goal is already achieved.
We take the goal with the help of the Value Stream Map - again we collect all the people and draw. But only now, based on the previous Value Stream Map, we draw what we want to get.
We single out one limitation that we will eliminate right now - this is what the team will do. As an example, I took the expectation from a finished release to its deployment in production - this is the most common limitation that people turn to consultants.
Based on this, we set the task: we want the wait between a ready release and going into action to be a maximum of an hour.
Examples of tasks.
- Reduce Lead Time testing from 4 days to 1 hour.
- Reduce Value Added Time for testing from 2 days to 3 hours.
- Reduce the Lead Time deployment from 5 hours to 10 minutes.
- Increase C / A from 50% to 95%, that is, increase the number of features that testers accept, in other words, improve the quality of the developers.
Examples of tasks are not taken from the head - they are based on the measurements that we did when developing the Value Stream Map.
We set a similar task to our team and a time limit. Depending on how well your company is doing, you set different deadlines. On average, it takes half a year to eliminate the restriction, if people do this for the first time and still don’t know with what technologies and how they will solve the problem.
Short planning
So, our team is created, it has a goal, people begin to work. An important point is a short work planning: sprints of one to two weeks and, no more, measurable improvements every week and course correction .
For example, we often use the moving-moving approach , when the whole team gathers at the beginning of each week, throws into a file what everyone will do. A week later, we note: what has been done and what is not, if not, then why, and we think what to do next.
Sprints allow you to adjust the course on time.
They tried something for a week or two: technologies, approaches, ways of working, after that you measure again and look - has this approach become better or worse? If it’s worse, then we are going the wrong way, we need to adjust the course: to set a different task, take a different technology or do something else. Short sprints for 1-2 weeks allow you to maneuver and get away from bad decisions in time.
Share success
The team achieves some success, small or large - it doesn’t matter, there is always some result. Everyone should know about this result: both those involved in DevOps and the neighboring departments. In an ideal world, it is desirable that this reaches generally all the people in the company .
What for? If we want to transform not a part of the company, eliminate not one restriction, but generally everything, so that the company becomes flexible, the code quickly flies to the client, and nothing breaks, we need everyone to be loyal to the idea of DevOps. You will not be able to take an approach to services and teams that are categorically against.
For loyalty to appear, we must tell everyone that we tried this - we have a result, try it too! This will increase interest and loyalty to what we do, people will start trying to do something right now. As practice shows, when we tell what we tried and what we achieved, other teams begin to ask how and what they did. They look at implementations, code, documentation, come up with questions and try to change something at home.
Talking about what you did is important. So you convince conservatives who want to do everything the old way and transform them into innovators to go to your camp.
Total
We choose the service as a starting point - that is the place where we start the changes in the company. We identify everyone who has anything to do with the service and build a Value Stream Map with them , measure and see where and what are the limitations.
We create a new temporary team that will solve the task. Based on the measurements and the Value Stream Map, we draw a new map, where we highlight the limitation that we will solve . Based on this limitation, we set the task that the team will be engaged in. The task must necessarily be SMART - specific, measurable, relevant to current tasks and limited in time.
Repeat the processuntil we transform absolutely all our services to the required form and eliminate all restrictions.
Bonus Useful materials
For those who decide to do DevOps on their own.
Phoenix Project
The original title is “The Phoenix Project: A Novel about It, Devops, and Helping Your Business Win”. This is a novel about DevOps - the story of how an employee was made the head of the department, who was constantly on fire. The new boss was given the task:
- You have several years to fix everything so that we can finally quickly and efficiently deliver our product to our customers.
“The Phoenix Project. A novel about how DevOps is changing life for the better ”is a book for all managers, because these people make decisions about what is happening in the company. If you are an engineer or programmer and you want your company to start moving and transforming, buy a book and give it to management. This novel explains everything, and is read quickly and easily.
DevOps Guide
The book is more complicated. It was released several years ago in English under the title “The DevOps Handbook How to create world-class agility, reliability, and security in Technology organizations”, but now it is already in Russian. This is a real handbook - a practical guide : how to take measurements, what is Value Stream Map and why is it needed, where is it worth moving, in what order. The book is just for those who want to do everything on their own. Most importantly, it contains examples of the experience of other companies.
For example, it tells how one company built a Value Stream Map and realized that its limitation was not in the product, but in the fact that the cashier goes from the store to the neighboring office to use this product. Instead of solving the problem with the program, they just bought tablets for their sellers, and now no one is going anywhere, and all actions are performed at the workplace. Conclusion: Value Stream Map can be extended not only to software, but also to all processes in the organization.
Accelerate
Full name: "Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations." This is the next level - hardcore. The book was published last year, so far only in English and it is about research. Authors Nicole Forsgren, Jez Humble, and Gene Kim have used different practices in different companies for many years and explored which practices, how and what they affect.
The second chapter on measurements refers to the Value Stream Map, the metrics that I called, and many others, and the measurement process is described in detail. Authors measure using questionnaires and self-tracking tasks. It is described in detail which metrics are correct to measure, which are not worth it, human errors in measurements. If you have difficulty measuring, refer to the second chapter of Accelerate. If your team just has a lot of practices, but it’s not clear which practices to apply now, which then, which really work, and which don’t, read the book.
Transformation is a crossroads between DevOps and management. Somewhere in the same area of intersection of development, operation and testing are topics that we are trying to discuss at DevOpsConf , the same integration is needed to create a quality product - the main theme of QaulityConf . Management at the RIT ++ festival is presented by Whale Rider - that means ideas for the transformation of everything there. Join on May 27 and 28, we will integrate and transform.