Crouching in the shadows or searching for the next world

Assembler is my favorite language ... but life is so short.
I continue the cycle of research on the issue of suitable shadows for some bagels. After the publication, I cooled down once and twice for this topic, but the effect of incomplete action prompts me to return to the debris of pixels, and to complete the gestalt .
Knowing myself, I’m sure that the game will hardly get its embodiment, but maybe some of the public will be interested in my achievements on this thorny path. And so let's get started.
Already at the end of the last cycle, I came to the understanding that calculating graphics on a CPU was already the last century, but natural obstinacy insisted: not all the possibilities were used, there were still options for interesting solutions.
The ray tracing remained unimplemented. More precisely, its kind, where for each pixel of the image (block of pixels) a ray is scattered and the level of illumination of the current point is determined. The algorithm itself is described in a previous article and there is no point in returning to it. For reverse ray tracing, the code was even more simplified, all trigonometry was completely removed, which in the future could give an acceptable result.
Pascal
const tile_size = 32; // размер тайла
tile_size1 : single = 0.03125; // 1/32 - обратный размер тайла
block_size = 4; // Ширина/высота блока в пикселях
Size_X:Byte = 32; // Количесво тайлов по X
Size_Y:Byte = 24; // Количесво тайлов по Y
//---------------------------------
function is_no_empty(x,y:Integer):Integer;
begin
if (x>=0) AND (x=0) AND (y0 then
inc(transp_key);
if (xi=i0) and (yj=j0) then
begin
crossing := min(255,transp_key*64+ l * r_view);
exit;
end;
dx0 := (temp_x-x)/l+0.0000001;
dy0 := (temp_y-y)/l+0.0000001;
key := False;
last_k :=0;
// Инициализация направления
if dx0<0 then
begin di :=-1; ddi:= 0; end
else
begin di := 1; ddi:= 1; end;
if dy0<0 then
begin dj :=-1; ddj:= 0; end
else
begin dj := 1; ddj:= 1; end;
sum_lenX := 0;
sum_lenY := 0;
sec1 := 1/dx0;
cosec1 := 1/dy0;
// Длина начального плеча по Х и Y
temp_x := x-(xi+ddi) * tile_size ;
temp_y := y-(yj+ddj) * tile_size ;
Dx := sqrt(sqr(temp_x) + sqr(temp_x * sec1 * dy0));
DY := sqrt(sqr(temp_y) + sqr(temp_y * cosec1 * dx0));
// Длина плеча по Х и Y
Dx1 := abs(tile_size * sec1);
Dy1 := abs(tile_size * cosec1);
repeat
if sum_lenX+DX < sum_lenY+DY then
begin
xi += di;
k := is_no_empty(xi,yj);
sum_lenX += DX;
if DX<>Dx1 then DX := Dx1;
end
else
begin
yj += dj;
k := is_no_empty(xi,yj);
sum_lenY += DY;
if DY<>Dy1 then DY := Dy1;
end;
if key Then
begin
if (xi<>i2) Or (yj<>j2) then
begin
// стена (дальше не расчитываем)
if last_k=1 then
begin
crossing := 255;
exit;
end;
// множество препятствий (дальше не расчитываем)
if transp_key>2 then
begin
crossing := 255;
exit;
end;
inc(transp_key);
key:= false;
end;
end;
if k>0 then
begin
i2:=xi;
j2:=yj;
key:=true;
last_k:=k;
end;
// Обнаружили искомый тайл
if (xi=i0) and (yj=j0) then
begin
crossing := min(255, transp_key*64+ l * r_view);
exit;
end;
until k=-1; // Вышли за границу карты
end;
//---------------------------------
..................
x0:= mouse_x;
y0:= mouse_y;
// Деление выносим за функцию для оптимизиции
x1 := x0 div tile_size;
y1 := y0 div tile_size;
koef := tile_size div block_size;
// Для каджого пикселя вызываем трасировку (в данном случае для блока пикселей)
for j:=0 to Size_Y * koef do
for i:=0 to Size_X * koef do
picture_mask.SetPixel(i, j, BGRA(0,0,0,crossing(x0, y0, x1, y1, i, j)));
..................
Alas, the result was much worse than expected, it was worth deploying the picture to full screen, FPS sought to units.

Grouping pixels into macroblocks to reduce calculations and applying subsequent smoothing did not much improve performance. The effect frankly did not like the word at all.

The algorithm was perfectly parallel, but it didn’t make sense to use a lot of streams, the effect seemed much worse than in the previous article, even with better picture quality.
It turned out to be a dead end. I had to admit, the CPU in the calculation of graphics in my eyes has exhausted itself. A curtain.
Digression 1
Over the past decade, there has been virtually no progress in the development of general-purpose processors. If approached by the user, then the maximum noticeable performance increase is no more than 30% per core. Progress, to put it mildly, is insignificant. If we omit the extension of the length of vector instructions, and some acceleration of conveyor blocks, this is an increase in the number of working cores. Safe work with threads is still a pleasure, and not all tasks can be successfully parallelized. I would like to have a working core, albeit one, but if so, it’s 5-10 faster, but alas and oh, as they say.
Here on Habré there is an excellent cycle of articles "Life in an era of" dark "silicon", which explains some of the prerequisites for the current state of affairs, but also returns from heaven to earth. In the next decade, you can not expect any significant increase in computing per core. But we can expect further development of the number of GPU cores and their overall acceleration. Even on my old laptop, the estimated total GPU performance is 20 times higher than a single CPU thread. Even if you effectively load all 4 processor cores, it is much less than we would like.
I pay tribute to the developers of the graphics of the past, who made their masterpieces without hardware accelerators, real masters.
Here on Habré there is an excellent cycle of articles "Life in an era of" dark "silicon", which explains some of the prerequisites for the current state of affairs, but also returns from heaven to earth. In the next decade, you can not expect any significant increase in computing per core. But we can expect further development of the number of GPU cores and their overall acceleration. Even on my old laptop, the estimated total GPU performance is 20 times higher than a single CPU thread. Even if you effectively load all 4 processor cores, it is much less than we would like.
I pay tribute to the developers of the graphics of the past, who made their masterpieces without hardware accelerators, real masters.
So, we deal with the GPU. It turned out to be somewhat unexpected for me that in real practice, few people simply scatter polygons in shape. All interesting things are created using shaders . Having discarded the finished 3D engines, I tried to study the offal of technology as it is at a deep level. The same processors are the same assembler, only a few truncated set of instructions and their own specifics of work. For the test, I stopped at GLSL , a C-like syntax, simplicity, a lot of training lessons and examples, including the Habr.
Since I was mostly used to writing in Pascal , the challenge was how to connect OpenGL
to the project. I managed to find two ways to connect: the GLFW library and the header filedglOpenGL . The only thing in the first I could not connect the shaders, but apparently this is from the curvature of my hands.
Digression 2
Many friends ask me why I write in Pascal? Obviously, this is an endangered language, its community is steadily falling, there is almost no development. Low-level system engineers prefer C, and Java, Python, Ruby, or whatever is at their peak right now.
For me, Pascal is akin to first love. Two decades ago, back in the days of Turbo Pascal 5.5 , it sunk into my soul and has been walking with me ever since, be it Delphi or in recent years Lazarus . I like the predictability of the language, the relative low level (assembler inserts and viewing the processor instruction), compatibility with C. The main thing is that the code is assembled and executed without problems, but the fact that it is not fashionable is outdated, and there are no some features, this is nonsense. They say there are people who are still on LISP they write, but he generally for half a century.
For me, Pascal is akin to first love. Two decades ago, back in the days of Turbo Pascal 5.5 , it sunk into my soul and has been walking with me ever since, be it Delphi or in recent years Lazarus . I like the predictability of the language, the relative low level (assembler inserts and viewing the processor instruction), compatibility with C. The main thing is that the code is assembled and executed without problems, but the fact that it is not fashionable is outdated, and there are no some features, this is nonsense. They say there are people who are still on LISP they write, but he generally for half a century.
So, let's dive into the development. For a test step, we will not take accurate realistic models of shading, but try to implement what we have already tried before, but with GPU performance, so to speak for a clear comparison.
Initially, I thought of getting a shadow of approximately this shape, using triangles for an object.
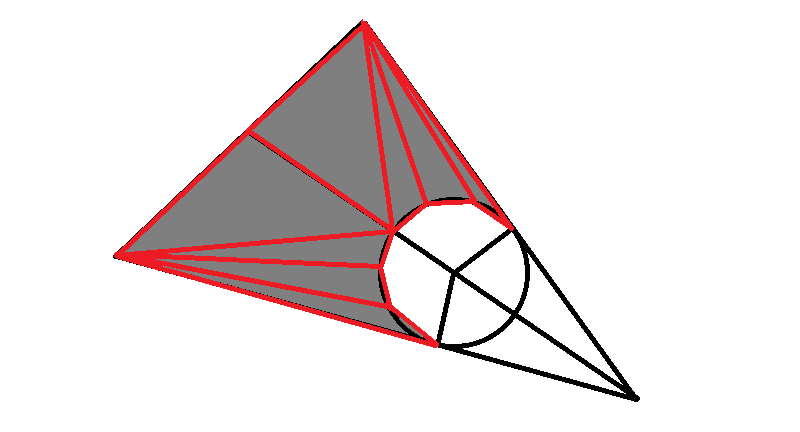
To create the effect of a smooth circle, you need a lot of polygons. But what if you use triangles to a minimum, using a pixel shader to create a hole in the shape. The idea came to me after reading an article by a respected master, in which the opportunity was opened to create a sphere with a shader.
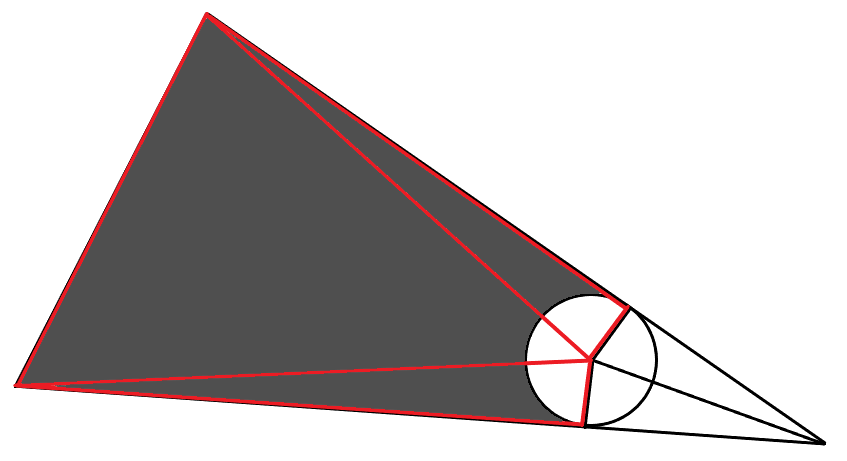
If you extend the triangle beyond the boundaries of the screen, then the result is this:

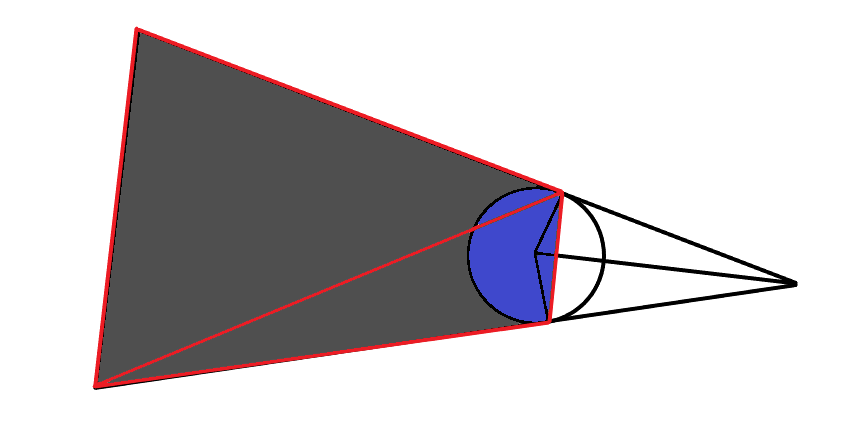
The borders of the shadow turned out to be very rigid and also stepped. But there is a way how to get an acceptable result without using supersampling , this is using smoothed borders. To do this, slightly change the scheme. The corners of the polygons at the intersection of the tangent to the circle will make transparent.
The result is better, but it still looks unnatural.

Add a little smoothing of the circle to give softness, and also change the form of the gradient from linear to power.

It is an acceptable result.
And in the end we will add objects imitating obstacles to the form.

Shader code
// Вершинный шейдер
#version 330 core
layout (location = 0) in vec2 aVertexPosition;
void main(void) {
gl_Position = vec4(aVertexPosition.xy, 0, 1.0);
}
// Шейдер геометрии
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
uniform mat4 uModelViewMatrix;
uniform float uRadius;
uniform vec2 uHeroPoint;
out float fTransparency;
out vec2 vCenter;
void main(){
vCenter = gl_in[0].gl_Position.xy;
vec2 d = uHeroPoint - vCenter;
float l = length(d);
float i = uRadius / l;
float ii = i*i;
float ij = i * sqrt(1 - ii);
vec2 p1 = vec2(vCenter.x + d.x*ii - d.y*ij , vCenter.y + d.x*ij + d.y*ii);
vec2 p2 = vec2(vCenter.x + d.x*ii + d.y*ij , vCenter.y - d.x*ij + d.y*ii);
d = uHeroPoint - p1;
vec2 p3 = vec2(p1 - d/length(d)*1000000);
d = uHeroPoint - p2;
vec2 p4 = vec2(p2 - d/length(d)*1000000);
fTransparency = 0;
gl_Position = uModelViewMatrix * vec4(p1, 0, 1);
EmitVertex();
fTransparency = 1;
gl_Position = uModelViewMatrix * vec4(p3, 0, 1);
EmitVertex();
gl_Position = uModelViewMatrix * vec4(vCenter, 0, 1);
EmitVertex();
gl_Position = uModelViewMatrix * vec4(p4, 0, 1);
EmitVertex();
fTransparency = 0;
gl_Position = uModelViewMatrix * vec4(p2, 0, 1);
EmitVertex();
EndPrimitive();
}
// Фрагментный шейдер
#version 330 core
precision mediump float;
varying float fTransparency;
varying vec2 vCenter;
uniform float uRadius;
uniform vec2 uScreenHalfSize;
uniform float uShadowTransparency;
uniform float uShadowSmoothness;
out vec4 FragColor;
void main(){
float l = distance(vec2((gl_FragCoord.xy - uScreenHalfSize.xy)/uScreenHalfSize.y), vCenter.xy);
if (l
else {FragColor = vec4(0, 0, 0, min(pow(fTransparency, uShadowSmoothness), (l-uRadius)/uRadius*10)*uShadowTransparency);}
}
I hope it was informative,
your humble servant, tormentor of pixels, Rebuilder.
I am enclosing a small demo . (EXE Windows)
PS The title of the article contains an easter egg , a reference to the Siala Chronicles trilogy . An excellent work in the styles of fantasy, about the misfortunes of the horns, from Alexei Pekhov.