How to make friends Progress OpenEdge and Oracle DBMS
Since 1999, our bank has been using the integrated BISKVIT banking system on the Progress OpenEdge platform to service the back office, which is widely used throughout the world, including in the financial sector. The performance of this DBMS allows you to read up to a million or more records per second in one database (DB). Our Progress OpenEdge serves about 1.5 million deposits of individuals and about 22.2 million contracts for active products (car loans and mortgages), and is also responsible for all payments with the regulator (CB) and SWIFT.

Using Progress OpenEdge, we are faced with the fact that we need to make friends with Oracle DBMS. Initially, this bundle was the “bottleneck” of our infrastructure - until we installed and configured Pro2 CDC - a Progress product that allows you to send data from Progress DBMSs to Oracle DBMSs directly, online. In this post, we will explain in detail, with all the pitfalls, how to effectively make friends with OpenEdge and Oracle.
First, some facts about our infrastructure. The number of active users of the database is approximately 15 thousand. The volume of all productive databases, including replica and standby, is 600 TB, the largest database is 16.5 TB. At the same time, the databases are constantly replenished: in the last year alone, about 120 TB of productive data has been added. The system provides 150 front-end servers on the x86 platform. Databases are hosted on 21 IBM platform servers.
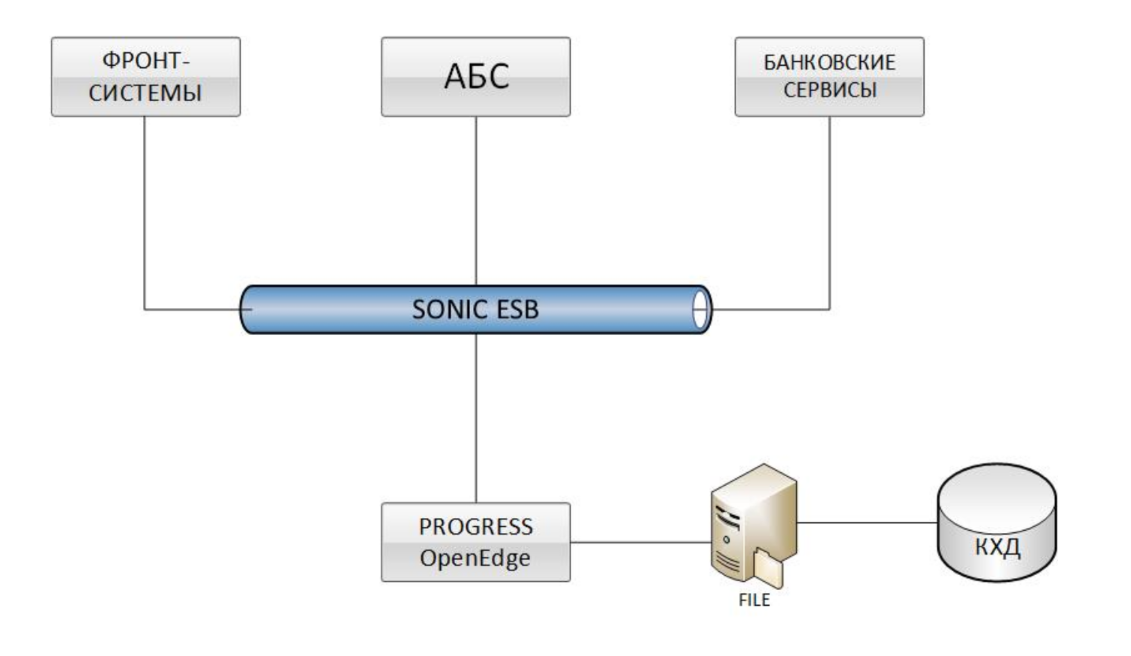
Front-systems, various ABS and banking services are integrated with OpenEdge Progress (IHD BISQUIT) via the Sonic ESB bus. Data is uploaded to QCD through file exchange. Such a solution up to a certain point in time immediately had two big problems - low productivity of uploading information to the corporate data warehouse (QCD) and the long time it takes to reconcile data (reconciliation) with other systems.
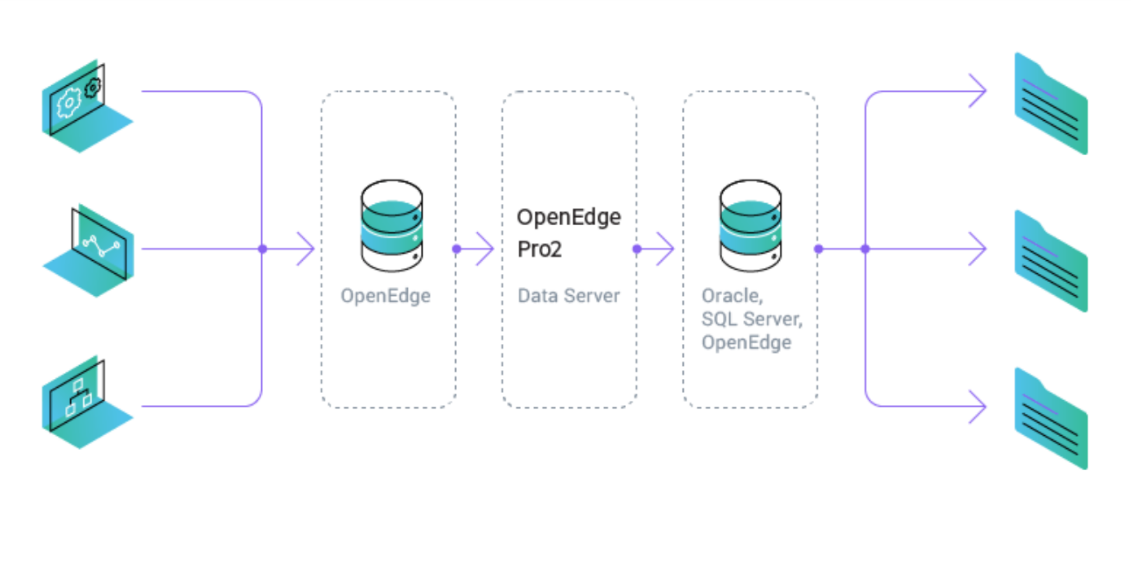
Therefore, we began to look for a tool that could accelerate these processes. The solution to both problems was precisely the new Progress OpenEdge product - Pro2 CDC (Change Data Capture). So, let's begin.
To run Pro2 Oracle on an administrator’s Windows computer, just install the Progress OpenEdge Developer Kit Classroom Edition, which can be downloaded for free. OpenEdge installation directories by default:
DLC: C: \ Progress \ OpenEdge
WRK: C: \ OpenEdge \ WRK
For ETL processes, Progress OpenEdge version 11.7+ licenses are required - namely OE DataServer for Oracle and 4GL Development System. These licenses are included with Pro2. For full operation of DataServer for Oracle with a remote Oracle database, Full Oracle Client is installed.
On the Oracle server, you need to install version of Oracle Database 12+, create an empty database and add a user (let's call it cdc ).
To install Pro2Oracle, download the latest distribution kit from the Progress Software download center . We unpack the archive into the C: \ Pro2 directory (to configure Pro2 on Unix the same distribution kit is used and the same configuration principles are applied).
The cdc (repl) replication database is used by Pro2 to store configuration information, including the replication map, the names of the replicated databases and their tables. It also contains a replication queue consisting of notes about the fact that the table row in the source database has changed. The data from the replication queue is used by ETL processes to identify the rows that need to be copied to Oracle from the source database.
Create a separate cdc database.
Now let's turn on the CDC mechanism itself, through which data will be replicated to an additional technological area. In each Progress OpenEdge source database, you must add separate storage areas to which the source data will be duplicated, and activate the mechanism itself using the proutil command .
Next, we need to create the database Schema Holder on the server where the data from the Progress DBMS to the Oracle DBMS will be replicated. DataServer Schema Holder is an empty Progress OpenEdge database without users or application data, containing a map of correspondence between source tables and external, Oracle tables.
The Schema Holder database for Progress OpenEdge DataServer for Oracle for Pro2 must be located on the ETL process server, it is created separately for each branch.
Using the Pro2 administrative panel, Pro2 settings are configured, including setting up the replication scheme and generating ETL process programs (Processor Library), primary synchronization programs (Bulk-Copy Processor), replication triggers, and OpenEdge CDC policies. There are also primary tools for monitoring and managing ETL and CDC processes. First of all, we configure the parameter files.
To configure Windows shortcuts, go to the C: \ Pro2 \ bprepl \ Scripts directory and edit the “Pro2 - Administration” shortcut. To do this, open the properties of the shortcut and in the line Start in indicate the installation directory Pro2. A similar operation needs to be done for the “Pro2 - Editor” and “RunBulkLoader” labels.
We launch the console.
Go to the “DB Map”.

To link the databases in Pro2 - Administration, go to the DB Map tab . We add mapping of source databases - Schema Holder - Oracle .

Go to the Mapping tab . In the Source Database list , the first connected source database is selected by default. To the right of the list should be All Databases Connected - the selected databases are connected. A list of Progress tables from bisquit should be visible below on the left. On the right is a list of tables from the Oracle database.
To create a replication map, you must first generate the SQL schema in Oracle. In Pro2 Administration, execute the menu item Tools -> Generate Code -> Target Schema , then in the Select Database dialog box select one or more source databases and transfer them to the right.

Click OK and select the directory to save the SQL schemas.
Next, we create the base. This can be done, for example, through Oracle SQL Developer . To do this, connect to the Oracle database and load the scheme to add tables. After changing the composition of Oracle tables, you need to update the SQL schemas in the Schema Holder.

After the download is successfully completed, exit the bisquitsh database and open the Pro2 admin panel. On the Mapping tab on the right, tables from the Oracle database should appear.
To create a replication map in the Pro2 admin panel, go to the Mapping tab, select the source database. We click on Map Tables, select on the left Select Changes tables that should be replicated to Oracle, transfer them to the right and confirm the selection. For selected tables, a map will be created automatically. Repeat the operation to create a replication map for other source databases.
The Processor Library is designed for special replication processes (ETLs) that process the Pro2 replication queue and push the changes to the Oracle database. Replication processor library programs after generation are automatically saved in the bprepl / repl_proc directory (parameter PROC_DIRECTORY) . To generate the replication processor library, go to Tools -> Generate Code -> Processor Library. After the generation is complete, the programs will appear in the bprepl / repl_proc directory .
Bulk processor programs are used to synchronize the source Progress databases with the target Oracle database based on the Progress ABL programming language (4GL). To generate them, go to the menu itemTools -> Generate Code -> Bulk-Copy Processor . In the Select Database dialog box, select the source database, transfer it to the right side of the window and click OK . After the generation is complete, the programs will appear in the bprepl \ repl_mproc directory .
Dividing the tables into sets serviced by a separate replication thread can improve the performance and efficiency of Oracle Pro2. By default, all connections created in the replication map for new replication tables are bound to stream number 1. It is recommended that tables be divided into different flows.
Information about the status of replication flows is displayed on the Pro2 Administration screen in the Monitor tab in the Replication Status section. A detailed description of the parameter values can be found in the Pro2 documentation (directory C: \ Pro2 \ Docs).
Policies are a set of rules for the OpenEdge CDC mechanism, according to which changes in tables are tracked. At the time of writing, Pro2 only supports CDC policies with level 0, that is, only the fact of a record change is tracked .
To create a CDC policy on the administrative panel, go to the Mapping tab, select the source database and click the Add / Remove Policies button. In the Select Changes window that opens, select on the left side and transfer to the right table for which you need to create or delete a CDC policy.
To activate, open the Mapping tab again, select the source database and click on the (In) Activate Policies button. Select and transfer to the right side of the table whose policies you need to activate, click OK. After that they are marked in green. Using (In) Activate Policies , you can also deactivate CDC policies. All operations are performed online.

After activating the CDC policy, notes about the changed records are saved in the “ReplCDCArea” storage area in accordance with the original database. These notes will be processed by a special CDCBatch process , which on their basis will create notes in the Pro2 replication queue in the cdc (repl) database .
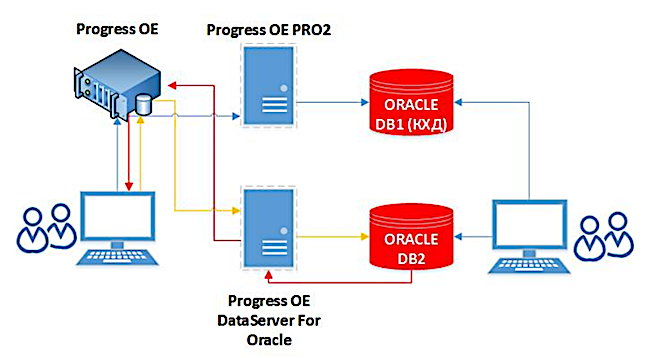
Thus, we have two queues for replication. The first stage is CDCBatch: from the source database, the data first goes to the intermediate CDC database. The second stage is when data is poured from the CDC database into Oracle. This is a feature of the current architecture and the product itself - so far, developers have not been able to establish direct replication.
After turning on the CDC mechanism and setting up the Pro2 replication server, we need to start the primary synchronization. Primary synchronization start command:
/pro2/bprepl/Script/replLoad.sh bisquit table-name
After the primary synchronization is completed, replication processes can be started.
To start replication processes, you need to run the replbatch.sh script . Before starting, make sure that there are replbatch scripts for all threads - replbatch1, replbatch2, etc. If everything is in place, open the command line (for example, proenv) , go to the / bprepl / scripts directory and start the script. In the administrative panel, we verify that the corresponding process has received the RUNNING status.

After implementation, we have greatly accelerated the upload of information to the corporate data warehouse. The data itself goes to Oracle online. No need to spend time on some long-running queries to collect data from different systems. In addition, in this solution, the replication process can compress data, which also has a positive effect on speed. Now, daily reconciliation of the BISKVIT system with other systems began to take 15-20 minutes instead of 2-2.5 hours, and full reconciliation - several hours instead of two days.
Using Progress OpenEdge, we are faced with the fact that we need to make friends with Oracle DBMS. Initially, this bundle was the “bottleneck” of our infrastructure - until we installed and configured Pro2 CDC - a Progress product that allows you to send data from Progress DBMSs to Oracle DBMSs directly, online. In this post, we will explain in detail, with all the pitfalls, how to effectively make friends with OpenEdge and Oracle.
How it was: uploading data to QCD through file sharing
First, some facts about our infrastructure. The number of active users of the database is approximately 15 thousand. The volume of all productive databases, including replica and standby, is 600 TB, the largest database is 16.5 TB. At the same time, the databases are constantly replenished: in the last year alone, about 120 TB of productive data has been added. The system provides 150 front-end servers on the x86 platform. Databases are hosted on 21 IBM platform servers.
Front-systems, various ABS and banking services are integrated with OpenEdge Progress (IHD BISQUIT) via the Sonic ESB bus. Data is uploaded to QCD through file exchange. Such a solution up to a certain point in time immediately had two big problems - low productivity of uploading information to the corporate data warehouse (QCD) and the long time it takes to reconcile data (reconciliation) with other systems.
Therefore, we began to look for a tool that could accelerate these processes. The solution to both problems was precisely the new Progress OpenEdge product - Pro2 CDC (Change Data Capture). So, let's begin.
Install Progress OpenEdge and Pro2Oracle
To run Pro2 Oracle on an administrator’s Windows computer, just install the Progress OpenEdge Developer Kit Classroom Edition, which can be downloaded for free. OpenEdge installation directories by default:
DLC: C: \ Progress \ OpenEdge
WRK: C: \ OpenEdge \ WRK
For ETL processes, Progress OpenEdge version 11.7+ licenses are required - namely OE DataServer for Oracle and 4GL Development System. These licenses are included with Pro2. For full operation of DataServer for Oracle with a remote Oracle database, Full Oracle Client is installed.
On the Oracle server, you need to install version of Oracle Database 12+, create an empty database and add a user (let's call it cdc ).
To install Pro2Oracle, download the latest distribution kit from the Progress Software download center . We unpack the archive into the C: \ Pro2 directory (to configure Pro2 on Unix the same distribution kit is used and the same configuration principles are applied).
Creating a cdc replication database
The cdc (repl) replication database is used by Pro2 to store configuration information, including the replication map, the names of the replicated databases and their tables. It also contains a replication queue consisting of notes about the fact that the table row in the source database has changed. The data from the replication queue is used by ETL processes to identify the rows that need to be copied to Oracle from the source database.
Create a separate cdc database.
Procedure for creating a database
pro2adm - for connecting from the Pro2 admin panel;
pro2etl - for connecting ETL processes (ReplBatch);
pro2cdc - for connecting CDC processes (CDCBatch);
- On the database server, create a directory for the cdc database - for example, on the / database / cdc / server .
- Create a dummy for the cdc base: procopy $ DLC / empty cdc
- Enable large file support: proutil cdc -C EnableLargeFiles
- We prepare the script to start the cdc database. Start parameters should be similar to the start parameters of the replicated database.
- We start the cdc database.
- We connect to the cdc database and load the Pro2 diagram from the cdc.df file , which is included in the Pro2 package.
- In the cdc database, create the following users:
pro2adm - for connecting from the Pro2 admin panel;
pro2etl - for connecting ETL processes (ReplBatch);
pro2cdc - for connecting CDC processes (CDCBatch);
Activating OpenEdge Change Data Capture
Now let's turn on the CDC mechanism itself, through which data will be replicated to an additional technological area. In each Progress OpenEdge source database, you must add separate storage areas to which the source data will be duplicated, and activate the mechanism itself using the proutil command .
Example procedure for the bisquit database
- Copy the cdcadd.st file from the C: \ Pro2 \ db directory to the bisquit source database directory.
- We describe in cdcadd.st fixed- extent extents for the ReplCDCArea and ReplCDCArea_IDX areas . You can add new storage areas online: prostrct addonline bisquit cdcadd.st
- Activate OpenEdge CDC:
proutil bisquit -C enablecdc area "ReplCDCArea" indexarea "ReplCDCArea_IDX" - The following users must be created in the source database to identify running processes:
a. pro2adm - for connecting from the Pro2 admin panel.
b. pro2etl - for connecting ETL processes (ReplBatch).
c. pro2cdc - for connecting CDC processes (CDCBatch).
Creating a Schema Holder for DataServer for Oracle
Next, we need to create the database Schema Holder on the server where the data from the Progress DBMS to the Oracle DBMS will be replicated. DataServer Schema Holder is an empty Progress OpenEdge database without users or application data, containing a map of correspondence between source tables and external, Oracle tables.
The Schema Holder database for Progress OpenEdge DataServer for Oracle for Pro2 must be located on the ETL process server, it is created separately for each branch.
How to create a Schema Holder
- Unpack the Pro2 distribution into the / pro2 directory
- Create and go to the / pro2 / dbsh directory
- Create the Schema Holder database using the procopy $ DLC / empty bisquitsh command
- We convert bisquitsh to the necessary encoding - for example, in UTF-8 if Oracle databases are encoded in UTF-8: proutil bisquitsh -C convchar convert UTF-8
- After creating an empty bisquitsh database, we connect to it in single-user mode: pro bisquitsh
- Go to the Data Dictionary: Tools -> Data Dictionary -> DataServer -> ORACLE Utilities -> Create DataServer Schema
- Launch Schema Holder
- Configure Oracle DataServer broker:
a. Start AdminServer.
proadsv -start
b. Start broker Oracle DataServer
oraman -name orabroker1 -start
Configure the admin panel and replication scheme
Using the Pro2 administrative panel, Pro2 settings are configured, including setting up the replication scheme and generating ETL process programs (Processor Library), primary synchronization programs (Bulk-Copy Processor), replication triggers, and OpenEdge CDC policies. There are also primary tools for monitoring and managing ETL and CDC processes. First of all, we configure the parameter files.
How to set up parameter files
- Go to the directory C: \ Pro2 \ bprepl \ Scripts
- Open the replProc.pf file for editing
- Add the parameters for connecting to the cdc replication database:
# Replication Database
-db cdc -ld repl -H <hostname of the main databases> -S <port of the database broker cdc>
-U pro2admin -P <password> - Add the parameters for connecting to the source databases and Schema Holder in the form of parameter files to replProc.pf . The name of the parameter file must match the name of the source database to be connected.
# Connect to all replicated source BISQUIT
-pf bprepl \ scripts \ bisquit.pf - Add to replProc.pf connection settings Sshema Holder.
#Target Pro DB Schema Holder
-db bisquitsh -ld bisquitsh
-H <hostname of ETL processes>
-S <broker port biskuitsh>
-db bisquitsql
-ld bisquitsql
-dt ORACLE
-S 5162 -H <hostname of the broker Oracle>
-DataService orabroker1 - Save the replProc.pf parameter file
- Next, you need to create and open for editing the parameter files for each connected source database in the C: \ Pro2 \ bprepl \ Scripts: bisquit.pf directory . Each pf-file contains parameters for connecting to the corresponding database, for example:
-db bisquit -ld bisquit -H <hostname> -S <broker port>
-U pro2admin -P <password>
To configure Windows shortcuts, go to the C: \ Pro2 \ bprepl \ Scripts directory and edit the “Pro2 - Administration” shortcut. To do this, open the properties of the shortcut and in the line Start in indicate the installation directory Pro2. A similar operation needs to be done for the “Pro2 - Editor” and “RunBulkLoader” labels.
Configuring Pro2 Administration: Downloading the Primary Configuration
We launch the console.
Go to the “DB Map”.
To link the databases in Pro2 - Administration, go to the DB Map tab . We add mapping of source databases - Schema Holder - Oracle .
Go to the Mapping tab . In the Source Database list , the first connected source database is selected by default. To the right of the list should be All Databases Connected - the selected databases are connected. A list of Progress tables from bisquit should be visible below on the left. On the right is a list of tables from the Oracle database.
Creating SQL Schemas and Databases in Oracle
To create a replication map, you must first generate the SQL schema in Oracle. In Pro2 Administration, execute the menu item Tools -> Generate Code -> Target Schema , then in the Select Database dialog box select one or more source databases and transfer them to the right.
Click OK and select the directory to save the SQL schemas.
Next, we create the base. This can be done, for example, through Oracle SQL Developer . To do this, connect to the Oracle database and load the scheme to add tables. After changing the composition of Oracle tables, you need to update the SQL schemas in the Schema Holder.
After the download is successfully completed, exit the bisquitsh database and open the Pro2 admin panel. On the Mapping tab on the right, tables from the Oracle database should appear.
Mapping tables
To create a replication map in the Pro2 admin panel, go to the Mapping tab, select the source database. We click on Map Tables, select on the left Select Changes tables that should be replicated to Oracle, transfer them to the right and confirm the selection. For selected tables, a map will be created automatically. Repeat the operation to create a replication map for other source databases.
Generation of the Pro2 Replication Processor Library and Bulk-Copy Processor Programs
The Processor Library is designed for special replication processes (ETLs) that process the Pro2 replication queue and push the changes to the Oracle database. Replication processor library programs after generation are automatically saved in the bprepl / repl_proc directory (parameter PROC_DIRECTORY) . To generate the replication processor library, go to Tools -> Generate Code -> Processor Library. After the generation is complete, the programs will appear in the bprepl / repl_proc directory .
Bulk processor programs are used to synchronize the source Progress databases with the target Oracle database based on the Progress ABL programming language (4GL). To generate them, go to the menu itemTools -> Generate Code -> Bulk-Copy Processor . In the Select Database dialog box, select the source database, transfer it to the right side of the window and click OK . After the generation is complete, the programs will appear in the bprepl \ repl_mproc directory .
Configuring replication processes in Pro2
Dividing the tables into sets serviced by a separate replication thread can improve the performance and efficiency of Oracle Pro2. By default, all connections created in the replication map for new replication tables are bound to stream number 1. It is recommended that tables be divided into different flows.
Information about the status of replication flows is displayed on the Pro2 Administration screen in the Monitor tab in the Replication Status section. A detailed description of the parameter values can be found in the Pro2 documentation (directory C: \ Pro2 \ Docs).
Create and activate CDC policies
Policies are a set of rules for the OpenEdge CDC mechanism, according to which changes in tables are tracked. At the time of writing, Pro2 only supports CDC policies with level 0, that is, only the fact of a record change is tracked .
To create a CDC policy on the administrative panel, go to the Mapping tab, select the source database and click the Add / Remove Policies button. In the Select Changes window that opens, select on the left side and transfer to the right table for which you need to create or delete a CDC policy.
To activate, open the Mapping tab again, select the source database and click on the (In) Activate Policies button. Select and transfer to the right side of the table whose policies you need to activate, click OK. After that they are marked in green. Using (In) Activate Policies , you can also deactivate CDC policies. All operations are performed online.
After activating the CDC policy, notes about the changed records are saved in the “ReplCDCArea” storage area in accordance with the original database. These notes will be processed by a special CDCBatch process , which on their basis will create notes in the Pro2 replication queue in the cdc (repl) database .
Thus, we have two queues for replication. The first stage is CDCBatch: from the source database, the data first goes to the intermediate CDC database. The second stage is when data is poured from the CDC database into Oracle. This is a feature of the current architecture and the product itself - so far, developers have not been able to establish direct replication.
Primary sync
After turning on the CDC mechanism and setting up the Pro2 replication server, we need to start the primary synchronization. Primary synchronization start command:
/pro2/bprepl/Script/replLoad.sh bisquit table-name
After the primary synchronization is completed, replication processes can be started.
Start replication processes
To start replication processes, you need to run the replbatch.sh script . Before starting, make sure that there are replbatch scripts for all threads - replbatch1, replbatch2, etc. If everything is in place, open the command line (for example, proenv) , go to the / bprepl / scripts directory and start the script. In the administrative panel, we verify that the corresponding process has received the RUNNING status.
results
After implementation, we have greatly accelerated the upload of information to the corporate data warehouse. The data itself goes to Oracle online. No need to spend time on some long-running queries to collect data from different systems. In addition, in this solution, the replication process can compress data, which also has a positive effect on speed. Now, daily reconciliation of the BISKVIT system with other systems began to take 15-20 minutes instead of 2-2.5 hours, and full reconciliation - several hours instead of two days.