MyTarget dynamic remarketing: non-personal product recommendations

Dynamic remarketing (dynrem) in myTarget is a targeted advertising technology that uses information about user actions on websites and in mobile applications of advertisers. For example, in an online store, a user viewed the pages of goods or added them to the basket, and myTarget uses these events to display advertisements for precisely those goods and services to which a person has already shown interest. Today I’ll talk in more detail about the mechanism for generating non-personal, that is, item2item-recommendations, which allow us to diversify and complement the advertising output.
The customers for dynrem myTarget are mainly online stores, which can have one or more lists of products. When building recommendations, the pair “store - list of goods” should be considered as a separate unit. But for simplicity, we will simply use the "store" next. If we talk about the dimension of the input task, then recommendations should be built for about a thousand stores, and the number of goods can vary from several thousand to millions.
The recommendation system for dynrem must meet the following requirements:
- The banner contains products that maximize its CTR.
- Recommendations are built offline for a given time.
- The system architecture must be flexible, scalable, stable and work in a cold start environment.
Note that from the requirement to build recommendations for a fixed time and the described initial conditions (we will optimistically assume that the number of stores is increasing), a requirement naturally arises for the economical use of machine resources.
Section 2 contains the theoretical foundations for constructing recommender systems, sections 3 and 4 discuss the practical side of the issue, and section 5 summarizes the overall result.
Basic concepts
Consider the task of building a recommendation system for one store and list the basic mathematical approaches.
Singular Value Decomposition (SVD)
A popular approach to building recommender systems is the singular decomposition (SVD) approach. Rating Matrix
 represent as a product of two matrices
represent as a product of two matrices  and
and  so that
so that  then rating user rating
then rating user rating  for goods
for goods  represented as
represented as  [1], where the elements of the scalar product are dimension vectors
[1], where the elements of the scalar product are dimension vectors  (main parameter of the model). This formula serves as the basis for other SVD models. The task of finding and reduces to optimizing the functional:
(main parameter of the model). This formula serves as the basis for other SVD models. The task of finding and reduces to optimizing the functional: (2.1)

Where
 - error function (for example, RMSE as in Netflix competition ),
- error function (for example, RMSE as in Netflix competition ), - regularization, and the summation is over pairs for which the rating is known. We rewrite expression (2.1) in an explicit form:
- regularization, and the summation is over pairs for which the rating is known. We rewrite expression (2.1) in an explicit form: (2.2)

Here
 ,
,  - L2-regularization coefficients for user representations
- L2-regularization coefficients for user representations  and goods
and goods  respectively. The basic model for the Netflix competition was:
respectively. The basic model for the Netflix competition was: (2.3)

(2.4)

Where
,  and
and  - biases for rating, user and product, respectively. Model (2.3) - (2.4) can be improved by adding an implicit user preference to it. In the Netflix competition example, the explicit response is the score set by the user to the film “at our request”, and other information about the “user interaction with the product” (viewing the movie, its description, reviews on it; that is, the implicit response does not give an implicit response) direct information about the rating of the film, but at the same time indicates interest). Implicit response accounting is implemented in the SVD ++ model:
- biases for rating, user and product, respectively. Model (2.3) - (2.4) can be improved by adding an implicit user preference to it. In the Netflix competition example, the explicit response is the score set by the user to the film “at our request”, and other information about the “user interaction with the product” (viewing the movie, its description, reviews on it; that is, the implicit response does not give an implicit response) direct information about the rating of the film, but at the same time indicates interest). Implicit response accounting is implemented in the SVD ++ model: (2.5)

Where
 - a set of objects with which the user implicitly interacted,
- a set of objects with which the user implicitly interacted,  - dimension representation for an object from .
- dimension representation for an object from .Factorization Machines (FM)
As can be seen in the examples with different SVD models, one model differs from the other in the set of terms included in the evaluation formula. Moreover, the expansion of the model each time represents a new task. We want such changes (for example, adding a new kind of implicit response, taking into account time parameters) to be easily implemented without changing the model implementation code. Models (2.1) - (2.5) can be represented in a convenient universal form using the following parameterization. We represent the user and the product in the form of a set of features:
(2.6)

(2.7)

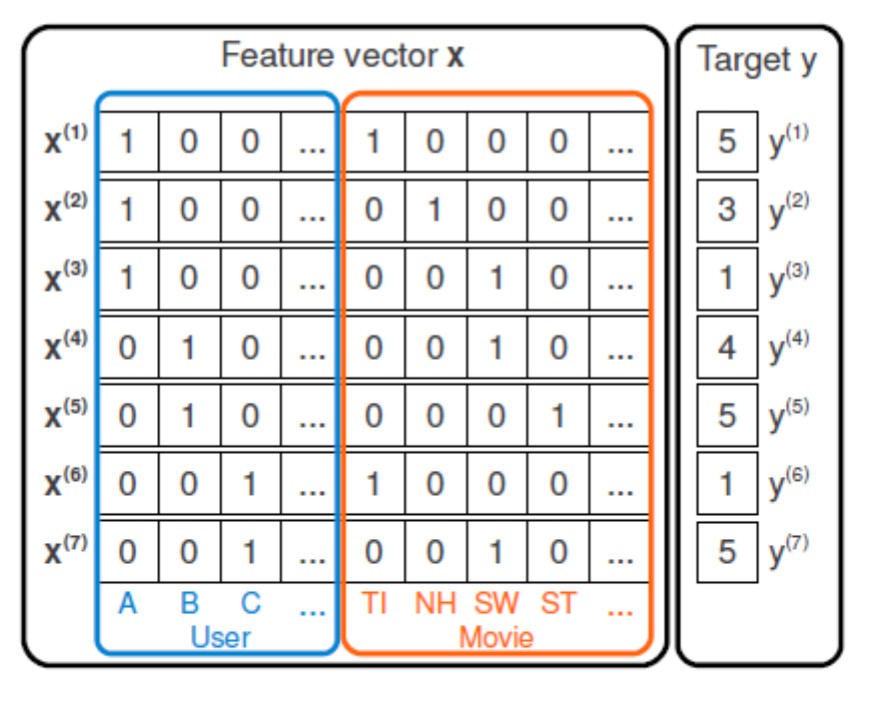
Fig. 1: An example of a feature matrix in the case of CF.
For example, in the case of collaborative filtering (CF), when only data on the interaction of users and products are used, the feature vectors look like one-hot-code (Fig. 1). Introduce vector
 , then the recommendation task is reduced to regression problems with the target variable
, then the recommendation task is reduced to regression problems with the target variable  :
:- Linear Model:
(2.8)
- Poly2:
(2.9)
- FM:
(2.10)
Where
 - model parameters,
- model parameters,  Are dimension vectors representing the sign in latent space
Are dimension vectors representing the sign in latent space  and
and  - the number of signs of the user and product, respectively. In addition to one-hot-codes, content-based features (Content-based, CB) can serve as signs (Fig. 2), for example, vectorized descriptions of products and user profiles.
- the number of signs of the user and product, respectively. In addition to one-hot-codes, content-based features (Content-based, CB) can serve as signs (Fig. 2), for example, vectorized descriptions of products and user profiles. 
Fig. 2: An example of an expanded feature matrix.
The FM model introduced in [2] is a generalization for (2.1) - (2.5), (2.8), (2.10). The essence of FM is that it takes into account the pairwise interaction of features using a scalar product
 , not using the parameter
, not using the parameter  . The advantage of FM over Poly2 is a significant reduction in the number of parameters: for vectors we will need
. The advantage of FM over Poly2 is a significant reduction in the number of parameters: for vectors we will need  parameters, and for required
parameters, and for required  parameters. At and of large orders, the first approach uses significantly fewer parameters.
parameters. At and of large orders, the first approach uses significantly fewer parameters. Please note: if there is no specific pair in the training set
 , then the corresponding term with in Poly2 it does not affect the training of the model, and the rating score is formed only on the linear part. However, the approach (2.10) allows us to establish relationships through other features. In other words, the data on one interaction help to evaluate the parameters of attributes that are not included in this example.
, then the corresponding term with in Poly2 it does not affect the training of the model, and the rating score is formed only on the linear part. However, the approach (2.10) allows us to establish relationships through other features. In other words, the data on one interaction help to evaluate the parameters of attributes that are not included in this example. On the basis of FM, a so-called hybrid model is implemented in which CB attributes are added to CF attributes. It allows you to solve the problem of a cold start, and also takes into account user preferences and allows you to make personalized recommendations.
Lightfm
In the popular implementation of FM , the emphasis is on the separation between the characteristics of the user and the product. Matrices act as model parameters
 and
and  Representation of user and product features:
Representation of user and product features: (2.11)

as well as offsets
 . Using user and product views:
. Using user and product views: (2.12)

(2.13)

get the pair rating
 :
: (2.14)

Loss functions
In our case, it is necessary to rank products for a specific user so that a more relevant product has a higher rating than a less relevant one. LightFM has several loss functions:
- Logistic is an implementation that requires a negative that is not explicitly presented in most tasks.
- BPR [3] is to maximize the difference in ratings between positive and negative examples for a particular user. Negative is obtained using bootstrap sampling. The quality functional used in the algorithm is similar to ROC-AUC.
- WARP [4] differs from BPR in the method of sampling negative examples and the loss function, which is also ranking, but at the same time optimizes the top recommendations for the user.
Practical implementation
To build recommendations for a given time, a parallel implementation on Spark is used. An independent task is launched for each store, the execution of which is controlled by luigi.
Data preprocessing
Data preprocessing is performed by automatically scalable Spark SQL tools. The features selected in the final model are textual descriptions of goods and catalogs with standard conversions.
What helped us when interacting with Spark:
- Партицирование подготовленных данных (матрицы взаимодействий пользователей и товаров, признаки для них) по магазинам. Это позволяет на этапе обучения экономить время на чтении данных из HDFS. В противном случае каждой задаче приходится считывать данные в память Spark и фильтровать их по ID магазина.
- Сохранение/получение данных в/из Spark мы делаем частями. Это связано с тем, что в процессе любого из этих действий данные загружаются в память JVM. Почему просто не увеличить память для JVM? Во-первых, тогда уменьшается доступная для обучения модели память, а во-вторых, не нужно хранить что-либо в JVM, она выступает в данном случае как временное хранилище.
Обучение модели
The model for each store is trained in its own Spark container, so that you can simultaneously run an arbitrary number of tasks for stores, limited only by cluster resources.
LightFM lacks early stop mechanisms, therefore, we spend extra resources on additional iterations of training when there is no increase in the target metric. We chose AUC as a metric, the relationship of which with CTR is confirmed experimentally.
Denote:
 - all known interactions between users and products, that is, pairs ,
- all known interactions between users and products, that is, pairs , - a lot of all goods ,
- a lot of all goods , - a lot of all users .
- a lot of all users . For a specific user
also introduce  - A lot of products with which the user interacted. AUC can be calculated as follows [ref]:
- A lot of products with which the user interacted. AUC can be calculated as follows [ref]: (3.1)

(3.2)

In formula (3.1) we need to calculate the rating for all possible pairs
( fixed), as well as compare ratings for items from  with ratings from
with ratings from  . Given that the user interacts with the scanty part of the assortment, the complexity of the calculation is
. Given that the user interacts with the scanty part of the assortment, the complexity of the calculation is . At the same time, one era of FM training costs us
. At the same time, one era of FM training costs us .
. Therefore, we modified the calculation of AUC. First, you should break the sample into a training
 and validation
and validation  , and
, and  . Next, we use sampling to create many users for validation
. Next, we use sampling to create many users for validation . For the user of
. For the user of  elements of a positive class we will consider
elements of a positive class we will consider  similar . As elements of a negative class, we take a subsample
similar . As elements of a negative class, we take a subsample so that no elements from . The subsample size can be taken proportional to the size.
so that no elements from . The subsample size can be taken proportional to the size. , i.e
, i.e  . Then formulas (3.1), (3.2) for calculating AUC will change:
. Then formulas (3.1), (3.2) for calculating AUC will change: (3.3)

(3.4)

As a result, we obtain a constant time for calculating AUC, since we take only a fixed part of users, and the sets
and  have a small size. The learning process for the store stops after the AUC (3.4) ceases to improve.
have a small size. The learning process for the store stops after the AUC (3.4) ceases to improve.Search for similar objects
As part of the item2item task, you must select for each item
 (or products as similar as possible) to those that maximize the clickability of the banner. Our assumption: candidates for the banner must be considered from top-closest in space embeddings. We tested the following methods for calculating “nearest neighbors”: Scala + Spark, ANNOY, SCANNs, HNSW.
(or products as similar as possible) to those that maximize the clickability of the banner. Our assumption: candidates for the banner must be considered from top-closest in space embeddings. We tested the following methods for calculating “nearest neighbors”: Scala + Spark, ANNOY, SCANNs, HNSW. For Scala + Spark for a store with 500 thousand objects, it took 15 minutes to calculate an honest cosine metric and a significant amount of cluster resources, so we tested approximate methods for finding nearest neighbors. When the method of the study ranged SCANNs following parameters:
bucketLimit, shouldSampleBuckets, NumHashesand setSignatureLength, but the results were poor in comparison with other methods (got very different objects in the buckets). The ANNOY and HNSW algorithms showed results comparable to an honest cosine, but worked much faster.| 200k products | 500k goods | 2.2m products | ||||
| Algorithm | ANNOY | Hnsw | ANNOY | Hnsw | ANNOY | Hnsw |
index build time (sec) | 59.45 | 8.64 | 258.02 | 25.44 | 1190.81 | 90.45 |
| total time (sec) | 141.23 | 01/14 | 527.76 | 43.38 | 2081.57 | 150.92 |
Due to the fact that HNSW worked faster than all algorithms, we decided to stop on it.
We also search for the nearest neighbors in the Spark container and write the result in Hive with the appropriate partitioning.
Conclusion
Recall: we use WARP to train the model, AUC for the early stop, and the final quality assessment is carried out using the A / B test on live traffic.
We believe that in this place - in organizing the experiment and selecting the optimal composition of the banner - data ends and science begins. Here we learn to determine whether it makes sense to show recommendations for products for which retargeting worked; exactly how many recommendations to show; how many products viewed, etc. We will talk about this in the following articles.
Further improvements to the algorithm - the search for universal embeddings that will allow the products of all stores to be placed in one space - are carried out within the framework of the paradigm described at the beginning of the article.
Thanks for attention!
Literature
[1] Ricci F., Rokach L., Shapira B. Introduction to recommender systems handbook
// Recommender systems handbook. - Springer, Boston, MA, 2011. - S. 147160.
[2] Rendle S. Factorization machines // 2010 IEEE International Conference on Data Mining. - IEEE, 2010 .-- S. 995-1000.
[3] Rendle S. et al. BPR: Bayesian personalized ranking from implicit feedback
// Proceedings of the twenty-fifth conference on uncertainty in artificial intelligence.
- AUAI Press, 2009 .-- S. 452-461.
[4] Weston J., Bengio S., Usunier N. Wsabie: Scaling up to large vocabulary image annotation // Twenty-Second International Joint Conference on Artificial Intelligence. - 2011.