When “Zoë”! == “Zoë”, or why you need to normalize Unicode strings
- Transfer
- Tutorial
Never heard of Unicode normalization? You are not alone. But everyone should know about this. Normalization can save you from many problems. Sooner or later, something similar to what is shown in the following figure happens to any developer.
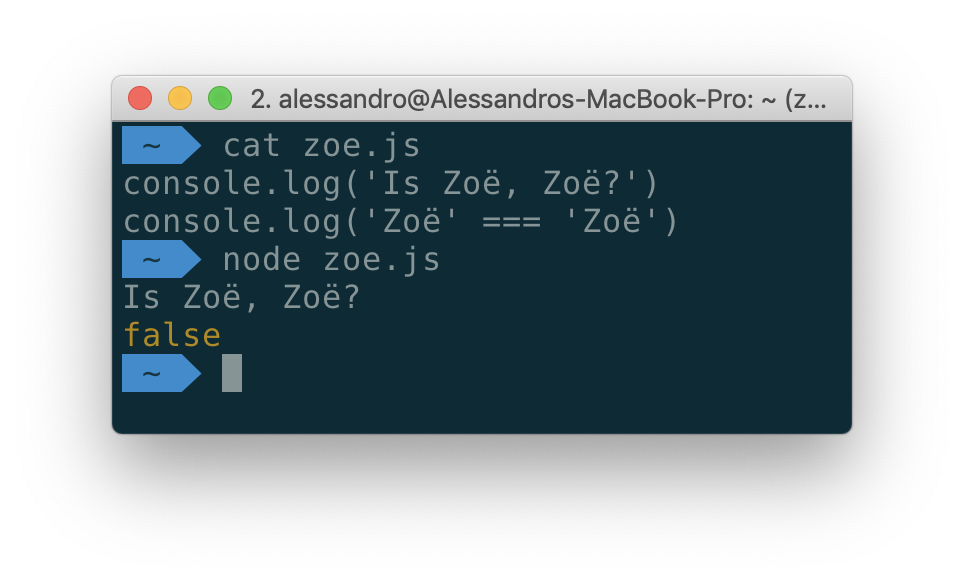 "Zoë" is not "Zoë"
"Zoë" is not "Zoë"
And this, by the way, is not an example of the next oddity of JavaScript. The author of the material, the translation of which we are publishing today, says that it can show how the same problem manifests itself when using almost every existing programming language. In particular, we are talking about Python, Go, and even shell scripts. How to deal with it?
I first encountered the Unicode problem many years ago when I wrote an application (on Objective-C) that imported a list of contacts from the user's address book and from his social networks, after which he excluded duplicates. In certain situations, it turned out that some people are on the list twice. This happened because, according to the program, their names were not identical strings.
Although in the above example, the two lines look exactly the same, the way they are represented in the system, the bytes in which they are stored on the disk are different. In the first name
Computers work with bytes, which are just numbers. In order to be able to process texts on computers, people agreed on the consistency of characters and numbers, and came to an agreement on how the visual presentation of characters should look.
The first such agreement was represented by ASCII (American Standard Code for Information Interchange) encoding. This encoding used 7 bits and could represent 128 characters, which included the Latin alphabet (uppercase and lowercase letters), numbers and basic punctuation. ASCII also included many “non-printable” characters, such as a line feed, a tab, a carriage return, and others. For example, in ASCII, the Latin letter M (uppercase m) is encoded as the number 77 (4D in hexadecimal notation).
The ASCII problem is that although 128 characters may be enough to represent all the characters that people working with English texts usually use, this number of characters is not enough to represent texts in other languages and different special characters like emoji.
The solution to this problem was the adoption of the Unicode standard, which was aimed at the possibility of representing each character used in all modern and ancient texts, including characters like emoji. For example, in the recently released Unicode 12.0 standard, there are over 137,000 characters.
The Unicode standard can be implemented using a variety of character encoding methods. The most common are UTF-8 and UTF-16. It should be noted that the UTF-8 text encoding standard is most common in web space.
The UTF-8 standard uses from 1 to 4 bytes to represent characters. UTF-8 is a superset of ASCII, so its first 128 characters are the same as the characters represented in the ASCII code table. UTF-16, on the other hand, uses 2 to 4 bytes to represent 1 character.
Why are there both standards? The fact is that texts in Western languages are usually most efficiently encoded using the UTF-8 standard (since most of the characters in such texts can be represented as 1 byte codes). If we talk about oriental languages, then we can say that the files that store texts written in these languages usually turn out less when using UTF-16.
Each character in the Unicode standard is assigned an identification number, which is called a code point. For example, the Emoji code point is U + 1F436 .
is U + 1F436 .
When encoding this icon, it can be represented as different sequences of bytes:
In the JavaScript code below, all three commands print the same character to the browser console. The internal mechanisms of most JavaScript interpreters (including Node.js and modern browsers) use UTF-16. This means that the dog icon we are examining is stored using two UTF-16 code units (16 bits each). Therefore, what the following code prints should not seem incomprehensible to you:
Now, back to what we started with, namely, let's talk about why characters that look alike to a person have a different internal concept.
Some Unicode characters are intended to modify other characters. They are called combining characters. They apply to base characters. For example:
As you can see from the previous example, combinable characters allow you to add accents to the base characters. But on this the possibilities of Unicode on the transformation of characters are not limited. For example, some sequences of characters can be represented as ligatures (so ae can turn into æ).
The problem is that special characters can be represented in various ways.
For example, the letter é can be represented in two ways:
The characters resulting from the use of any of these ways of representing the letter é will look the same, but when compared, it turns out that the characters are different. The strings containing them will have different lengths. You can verify this by running the following code in the browser console.
This can lead to unexpected errors. For example, they can be expressed in that the program, for unknown reasons, is not able to find some records in the database, that the user, by entering the correct password, cannot log in to the system.
The problems described above have a simple solution, which is to normalize strings, to bring them to a “canonical representation”.
There are four standard forms (algorithms) of normalization:
The most commonly used form is the normalization of NFC. When using this algorithm, all characters are first decomposed, after which all combining sequences undergo repeated composition in the order defined by the standard. For practical use, you can choose any form. The main thing is to apply it consistently. As a result, the arrival at the program input of the same data will always lead to the same result.
In JavaScript, starting with the ES2015 standard (ES6), there is a built-in method for normalizing strings - String.prototype.normalize ([form]) . You can use it in the Node.js environment and in almost all modern browsers. Argument
Let us return to the previously considered example, applying normalization this time:
If you are developing a web application and use what the user enters in it, always normalize the received text data. In JavaScript, you can use the standard string method normalize () to perform normalization .
Dear readers! Have you encountered problems with strings, which can be solved with the help of normalization?

And this, by the way, is not an example of the next oddity of JavaScript. The author of the material, the translation of which we are publishing today, says that it can show how the same problem manifests itself when using almost every existing programming language. In particular, we are talking about Python, Go, and even shell scripts. How to deal with it?
Prehistory
I first encountered the Unicode problem many years ago when I wrote an application (on Objective-C) that imported a list of contacts from the user's address book and from his social networks, after which he excluded duplicates. In certain situations, it turned out that some people are on the list twice. This happened because, according to the program, their names were not identical strings.
Although in the above example, the two lines look exactly the same, the way they are represented in the system, the bytes in which they are stored on the disk are different. In the first name
"Zoë"The symbol ë (e with umlaut) is a single Unicode code point. In the second case, we deal with decomposition, with an approach to the representation of characters using several symbols. If you, in your application, work with Unicode strings, you need to take into account the fact that the same characters can be represented in different ways.How we came to Emoji: in a nutshell about character encoding
Computers work with bytes, which are just numbers. In order to be able to process texts on computers, people agreed on the consistency of characters and numbers, and came to an agreement on how the visual presentation of characters should look.
The first such agreement was represented by ASCII (American Standard Code for Information Interchange) encoding. This encoding used 7 bits and could represent 128 characters, which included the Latin alphabet (uppercase and lowercase letters), numbers and basic punctuation. ASCII also included many “non-printable” characters, such as a line feed, a tab, a carriage return, and others. For example, in ASCII, the Latin letter M (uppercase m) is encoded as the number 77 (4D in hexadecimal notation).
The ASCII problem is that although 128 characters may be enough to represent all the characters that people working with English texts usually use, this number of characters is not enough to represent texts in other languages and different special characters like emoji.
The solution to this problem was the adoption of the Unicode standard, which was aimed at the possibility of representing each character used in all modern and ancient texts, including characters like emoji. For example, in the recently released Unicode 12.0 standard, there are over 137,000 characters.
The Unicode standard can be implemented using a variety of character encoding methods. The most common are UTF-8 and UTF-16. It should be noted that the UTF-8 text encoding standard is most common in web space.
The UTF-8 standard uses from 1 to 4 bytes to represent characters. UTF-8 is a superset of ASCII, so its first 128 characters are the same as the characters represented in the ASCII code table. UTF-16, on the other hand, uses 2 to 4 bytes to represent 1 character.
Why are there both standards? The fact is that texts in Western languages are usually most efficiently encoded using the UTF-8 standard (since most of the characters in such texts can be represented as 1 byte codes). If we talk about oriental languages, then we can say that the files that store texts written in these languages usually turn out less when using UTF-16.
Unicode code points and character encoding
Each character in the Unicode standard is assigned an identification number, which is called a code point. For example, the Emoji code point
is U + 1F436 . When encoding this icon, it can be represented as different sequences of bytes:
- UTF-8: 4 bytes,
0xF0 0x9F 0x90 0xB6 - UTF-16: 4 bytes,
0xD83D 0xDC36
In the JavaScript code below, all three commands print the same character to the browser console. The internal mechanisms of most JavaScript interpreters (including Node.js and modern browsers) use UTF-16. This means that the dog icon we are examining is stored using two UTF-16 code units (16 bits each). Therefore, what the following code prints should not seem incomprehensible to you:
// Так соответствующая последовательность байтов просто включается в код
console.log('') // =>
// Тут используется кодовая точка Unicode (ES2015+)
console.log('\u{1F436}') // =>
// Тут используется представление этого символа в стандарте UTF-16
// с применением двух кодовых единиц (по 2 байта каждая)
console.log('\uD83D\uDC36') // => console.log(''.length) // => 2Combining characters
Now, back to what we started with, namely, let's talk about why characters that look alike to a person have a different internal concept.
Some Unicode characters are intended to modify other characters. They are called combining characters. They apply to base characters. For example:
n + ˜ = ñu + ¨ = üe + ´ = é
As you can see from the previous example, combinable characters allow you to add accents to the base characters. But on this the possibilities of Unicode on the transformation of characters are not limited. For example, some sequences of characters can be represented as ligatures (so ae can turn into æ).
The problem is that special characters can be represented in various ways.
For example, the letter é can be represented in two ways:
- Using one code point U + 00E9 .
- Using a combination of the letter e and the acuta, that is, with the help of two code points - U + 0065 and U + 0301 .
The characters resulting from the use of any of these ways of representing the letter é will look the same, but when compared, it turns out that the characters are different. The strings containing them will have different lengths. You can verify this by running the following code in the browser console.
console.log('\u00e9') // => é
console.log('\u0065\u0301') // => é
console.log('\u00e9' == '\u0065\u0301') // => false
console.log('\u00e9'.length) // => 1
console.log('\u0065\u0301'.length) // => 2This can lead to unexpected errors. For example, they can be expressed in that the program, for unknown reasons, is not able to find some records in the database, that the user, by entering the correct password, cannot log in to the system.
Normalize strings
The problems described above have a simple solution, which is to normalize strings, to bring them to a “canonical representation”.
There are four standard forms (algorithms) of normalization:
- NFC: Normalization Form Canonical Composition.
- NFD: Normalization Form Canonical Decomposition.
- NFKC: Normalization Form Compatibility Composition.
- NFKD: Normalization Form Compatibility Decomposition.
The most commonly used form is the normalization of NFC. When using this algorithm, all characters are first decomposed, after which all combining sequences undergo repeated composition in the order defined by the standard. For practical use, you can choose any form. The main thing is to apply it consistently. As a result, the arrival at the program input of the same data will always lead to the same result.
In JavaScript, starting with the ES2015 standard (ES6), there is a built-in method for normalizing strings - String.prototype.normalize ([form]) . You can use it in the Node.js environment and in almost all modern browsers. Argument
formThis method is a string identifier of the normalization form. The default form is NFC. Let us return to the previously considered example, applying normalization this time:
const str = '\u0065\u0301'
console.log(str == '\u00e9') // => false
const normalized = str.normalize('NFC')
console.log(normalized == '\u00e9') // => true
console.log(normalized.length) // => 1Results
If you are developing a web application and use what the user enters in it, always normalize the received text data. In JavaScript, you can use the standard string method normalize () to perform normalization .
Dear readers! Have you encountered problems with strings, which can be solved with the help of normalization?