Seven Myths in Machine Learning Research
- Transfer
For those who are too lazy to read everything: a refutation of seven popular myths is suggested, which in the field of machine learning research is often considered true, as of February 2019. This article is available on the ArXiv website in pdf format [in English].
Myth 1: TensorFlow is a tensor library.
Myth 2: Image databases reflect real photos found in nature.
Myth 3: MO researchers do not use test kits for testing.
Myth 4: Neural network training uses all input data.
Myth 5: Batch normalization is required to train very deep residual networks.
Myth 6: Networks with attention are better than convolution.
Myth 7: Significance maps are a reliable way to interpret neural networks.
And now for the details.
In fact, this is a library for working with matrices, and this difference is very significant.
In Computing Higher Order Derivatives of Matrix and Tensor Expressions. Laue et al. NeurIPS 2018 authors demonstrate that their library of automatic differentiation, based on real tensor calculus, has much more compact expression trees. The fact is that tensor calculus uses index notation, which allows you to work equally with the direct and reverse modes.
Matrix numbering hides indices for convenience of notation, which is why automatic differentiation expression trees often become too complex.
Consider the matrix multiplication C = AB. We have for direct mode and
for direct mode and  for the opposite. To correctly perform the multiplication, you need to strictly observe the order and use of hyphenation. From the point of view of recording, this looks confusing for a person involved in MO, but from the point of view of calculations, this is an extra load for the program.
for the opposite. To correctly perform the multiplication, you need to strictly observe the order and use of hyphenation. From the point of view of recording, this looks confusing for a person involved in MO, but from the point of view of calculations, this is an extra load for the program.
Another example, less trivial: c = det (A). We have for direct mode and
for direct mode and  for the opposite. In this case, it is obviously impossible to use the expression tree for both modes, given that they consist of different operators.
for the opposite. In this case, it is obviously impossible to use the expression tree for both modes, given that they consist of different operators.
In general, the way TensorFlow and other libraries (for example, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) implemented automatic differentiation, which leads to the fact that for direct and reverse Different and ineffective expression trees are built in the mode. Tensor numbering circumvents these problems due to the commutativity of multiplication due to index notation. For details on how this works, see the scientific paper.
The authors tested their method by performing automatic differentiation of the reverse regime, also known as back propagation, in three different tasks, and measured the time it took to calculate the Hessians.

In the first problem, the quadratic function x T Ax was optimized . In the second, logistic regression was calculated, in the third - matrix factorization.
On the CPU, their method turned out to be two orders of magnitude faster than such popular libraries as TensorFlow, Theano, PyTorch, and HIPS autograd.
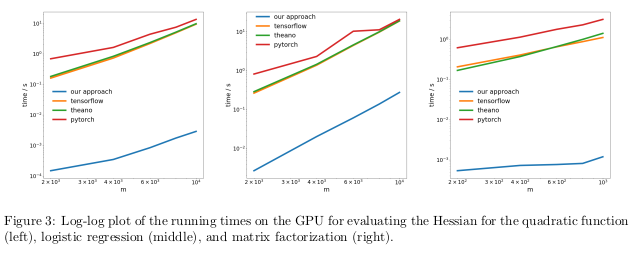
On the GPU, they observed even greater acceleration, by as much as three orders of magnitude.
The consequences:
Computing derivatives for functions of the second or higher order using current deep learning libraries is too expensive from a computational point of view. This includes the calculation of general fourth-order tensors such as Hessians (for example, in MAML and Newton’s second-order optimization). Fortunately, quadratic formulas are rare in deep learning. However, they are often found in “classical” machine learning - SVM , least squares method, LASSO, Gaussian processes, etc.
Many people like to think that neural networks have learned to recognize objects better than people. This is not true. They can be ahead of people on the bases of selected images, for example, ImageNet, but in the case of recognition of objects from real photos from ordinary life, they definitely will not be able to overtake an ordinary adult. This is because the selection of images in the current data sets does not coincide with the selection of all possible images naturally encountered in reality.
In a rather old work, Unbiased Look at Dataset Bias. Torralba and Efros. CVPR 2011. , The authors proposed to study the distortions associated with a set of images in twelve popular databases, finding out whether it is possible to train the classifier to determine the data set from which this image was taken.

The chances of accidentally guessing the correct data set are 1/12 ≈ 8%, while the scientists themselves coped with the task with a success rate of> 75%.
They trained SVM on a directional gradient histogram (HOG) and found that the classifier completed the task in 39% of cases, which significantly exceeds random hits. If we repeated this experiment today, with the most advanced neural networks, we would surely see an increase in the accuracy of the classifier.
If the image databases correctly displayed the true images of the real world, we would not have to be able to determine from which dataset a particular image comes from.

However, there are traits in the data that make each set of images different from the others. ImageNet has many race cars that are unlikely to describe the “theoretical” average car as a whole.

The authors also determined the value of each data set by measuring how well a classifier trained on one set works with images from other sets. According to this metric, the LabelMe and ImageNet databases turned out to be the least biased, having received a rating of 0.58 using the “currency basket” method. All values turned out to be less than unity, which means that training on a different data set always leads to poor performance. In an ideal world without biased sets, some numbers should have exceeded one.
The authors pessimistically concluded:
In the textbook on machine learning, we are taught to divide the data set into training, evaluation and verification. The effectiveness of the model, trained on the training set, and evaluated on the evaluation helps the person involved in the MO to fine-tune the model to maximize efficiency in its actual use. The test set does not need to be touched until the person finishes adjusting to provide an unbiased assessment of the real effectiveness of the model in the real world. If a person cheats using a test set at the training or assessment stages, the model runs the risk of becoming too adapted for a particular data set.
In the hyper-competitive world of MO research, new algorithms and models are often judged by the effectiveness of their work with verification data. Therefore, it makes no sense for researchers to write or publish papers describing methods that work poorly with test data sets. And this, in essence, means that the community of the Moscow Region as a whole uses a test set for evaluation.
What are the consequences of this scam?

Authors of Do CIFAR-10 Classifiers Generalize to CIFAR-10? Recht et al. ArXiv 2018 investigated this issue by creating a new test suite for CIFAR-10. To do this, they made a selection of images from Tiny Images.
They chose CIFAR-10 because it is one of the most commonly used datasets in the MO, the second most popular set in NeurIPS 2017 (after MNIST). The process of creating a dataset for CIFAR-10 is also well described and transparent, in the large Tiny Images database there are a lot of detailed labels, so you can reproduce a new test set, minimizing the distribution shift.

They found that a large number of different models of neural networks on the new test set showed a significant drop in accuracy (4% - 15%). However, the relative performance rank of each model remained fairly stable.
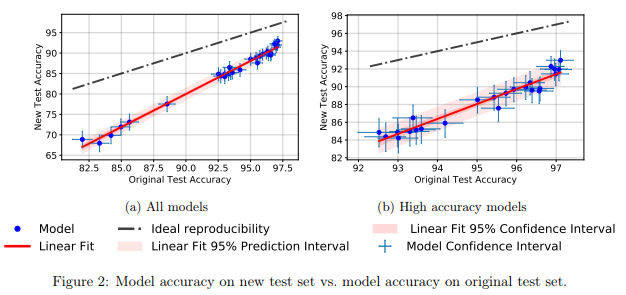
In general, better performing models showed a lower accuracy drop compared to worse performing ones. This is nice, because it follows that the loss of model generalizability due to cheating, at least in the case of CIFAR-10, decreases as the community invents improved MO methods and models.
It is generally accepted that data is a new oil , and that the more data we have, the better we can train deep learning models that are now sample-inefficient and overparametrized.
In An Empirical Study of Example Forgetting During Deep Neural Network Learning. Toneva et al. ICLR 2019 authors demonstrate significant redundancy in several common sets of small images. Surprisingly, 30% of the data from CIFAR-10 can simply be removed without changing the accuracy of the check by a significant amount.
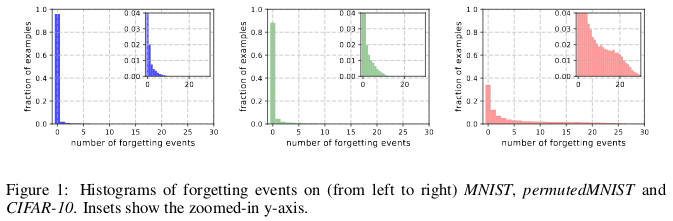
Histories of oblivion from (left to right) MNIST, permutedMNIST and CIFAR-10.
Forgetting happens when a neural network incorrectly classifies an image at time t + 1, while at time t it was able to correctly classify an image. The flow of time is measured by SGD updates. To track forgetting, the authors launched their neural network on a small data set after each SGD update, and not on all the examples available in the database. Examples that are not subject to forgetting are called unforgettable examples.
They found that 91.7% MNIST, 75.3% permutedMNIST, 31.3% CIFAR-10, and 7.62% CIFAR-100 are unforgettable examples. This is intuitively understandable, since increasing the diversity and complexity of the data set should make the neural network forget more examples.

Forgettable examples seem to exhibit more rare and strange features compared to unforgettable ones. The authors compare them with support vectors in SVM, as they seem to draw the outline of decision boundaries.
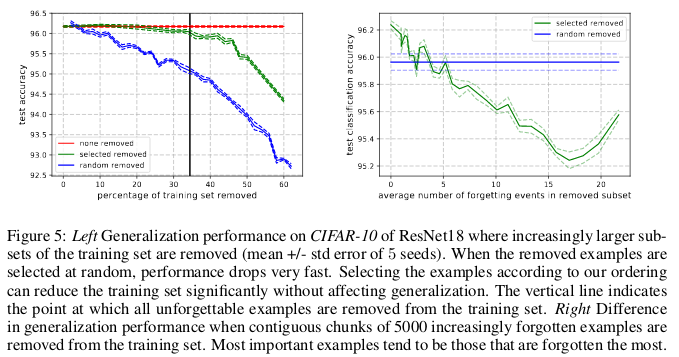
Unforgettable examples, in turn, encode mostly redundant information. If we sort the examples by the degree of unforgettableness, we can compress the data set by deleting the most unforgettable ones.
30% of the CIFAR-10 data can be deleted without affecting the accuracy of the checks, and the deletion of 35% of the data leads to a slight drop in the accuracy of the checks by 0.2%. If you select 30% of the data randomly, then deleting them will lead to a significant loss in the accuracy of the verification of 1%.
Similarly, 8% of data can be removed from the CIFAR-100 without a drop in validation accuracy.
These results show that there is significant redundancy in the data for training neural networks, similar to SVM training, where non-supporting vectors can be removed without affecting the model decision.
Consequences:
If we can determine which of the data is unforgettable before the start of training, we can save space by deleting them and time by not using them when training a neural network.
For a long time, it was believed that "training a deep neural network for direct optimization only for a controlled purpose (for example, the logarithmic probability of a correct classification) using gradient descent, starting with random parameters, does not work well."
The heap of ingenious methods of random initialization that has appeared since then, activation functions, optimization techniques, and other innovations, such as residual connections, facilitated the training of deep neural networks using the gradient descent method.
But a real breakthrough happened after the introduction of batch normalization (and other sequential normalization techniques), limiting the size of activations for each layer of the network in order to eliminate the problem of disappearing and explosive gradients.
In recent workFixup Initialization: Residual Learning Without Normalization. Zhang et al. ICLR 2019 has shown that it is possible to train a network with 10,000 layers using pure SGD without applying any normalization.

The authors compared residual neural network training for different depths on CIFAR-10 and found that while standard initialization methods did not work for 100 layers, Fixup and batch normalization methods succeeded with 10,000 layers.

They carried out a theoretical analysis and showed that “the gradient normalization of certain layers is limited by the number infinitely increasing from a deep network”, which is a problem of explosive gradients. To prevent this, Foxup is used, the key idea of which is to scale the weights in m layers for each of the residual branches L by the number of times depending on m and L.

Fixup helped train a deep residual network with 110 layers on CIFAR-10 with a high learning rate, comparable to the behavior of a network of similar architecture, trained using batch normalization.
The authors further showed similar test results using Fixup on the network without any normalization, working with the ImageNet database and with translations from English into German.
The idea that the mechanisms of “attention” are superior to convolutional neural networks is gaining popularity in the community of MO researchers. In the work of Vaswani and colleagues , it was noted that “the computational cost of detachable convolutions is equal to the combination of a self-attention layer and a point-wise feed-forward layer.”
Even advanced generative-competitive networks show the advantage of self-attention over standard convolution when modeling long-range dependencies.
Contributors Pay Less Attention with Lightweight and Dynamic Convolutions. Wu et al. ICLR 2019question the parametric efficiency and effectiveness of self-attention when modeling long-range dependencies, and offer new options for convolutions, partially inspired by self-awareness, more effective in terms of parameters.
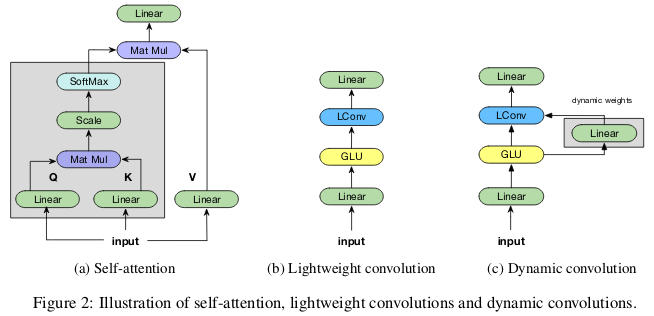
The “lightweight” convolutions are separable in depth, softmax-normalized in time dimension, separated by weight in channel dimension, and reuse the same weights at each time step (as recurrent neural networks). Dynamic convolutions are lightweight convolutions that use different weights at each time step.
Such tricks make lightweight and dynamic convolutions several orders of magnitude more effective than standard indivisible convolutions.

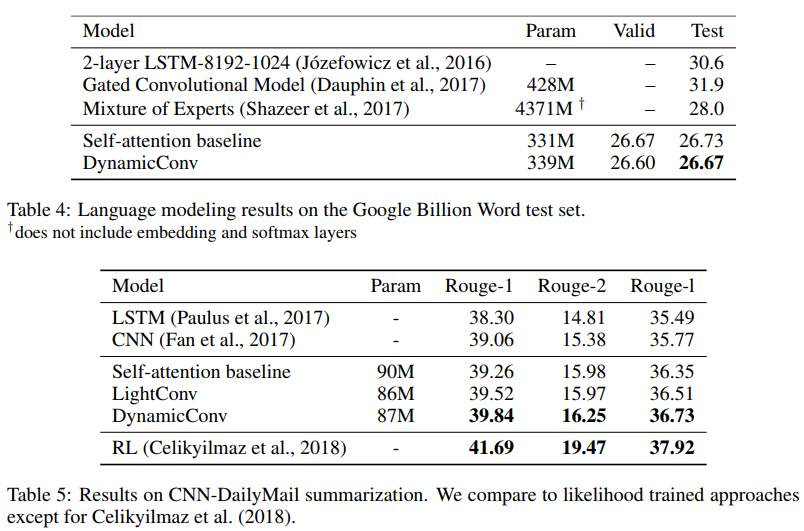
The authors show that these new convolutions correspond or exceed self-absorbing networks in machine translation, language modeling, abstract summation problems, using the same or less parameters.
Although there is an opinion that neural networks are black boxes, there have been many attempts to interpret them. The most popular of these are significance maps, or other similar methods that assign importance assessments to features or training examples.
It is tempting to be able to conclude that a given image has been classified in a certain way due to certain parts of the image that are significant to the neural network. To calculate significance maps, there are several methods that often use the activation of neural networks in a given image and the gradients passing through the network.
In Interpretation of Neural Networks is Fragile. Ghorbani et al. AAAI 2019the authors show that they can introduce an elusive change in the picture, which, however, will distort its significance map.

The neural network determines the monarch butterfly not by the pattern on its wings, but because of the presence of unimportant green leaves against the background of the photo.

Multidimensional images are often closer to decision boundaries made by deep neural networks, hence their sensitivity to adversarial attacks. And if competitive attacks move images beyond the boundaries of the solution, competitive interpretative attacks shift them along the boundary of the solution without leaving the territory of the same solution.
The basic method developed by the authors is a modification of the Goodfello method of fast gradient marking, which was one of the first successful methods of competitive attacks. It can be assumed that other, newer and more complex attacks can also be used for attacks on the interpretation of neural networks.
Consequences:
In connection with the growing spread of deep learning in such critical areas of application as medical imaging, it is important to carefully approach the interpretation of decisions made by neural networks. For example, although it would be great if the convolutional neural network could recognize the spot on the MRI image as a malignant tumor, these results should not be trusted if they are based on unreliable interpretation methods.
Myth 1: TensorFlow is a tensor library.
Myth 2: Image databases reflect real photos found in nature.
Myth 3: MO researchers do not use test kits for testing.
Myth 4: Neural network training uses all input data.
Myth 5: Batch normalization is required to train very deep residual networks.
Myth 6: Networks with attention are better than convolution.
Myth 7: Significance maps are a reliable way to interpret neural networks.
And now for the details.
Myth 1: TensorFlow is a tensor library
In fact, this is a library for working with matrices, and this difference is very significant.
In Computing Higher Order Derivatives of Matrix and Tensor Expressions. Laue et al. NeurIPS 2018 authors demonstrate that their library of automatic differentiation, based on real tensor calculus, has much more compact expression trees. The fact is that tensor calculus uses index notation, which allows you to work equally with the direct and reverse modes.
Matrix numbering hides indices for convenience of notation, which is why automatic differentiation expression trees often become too complex.
Consider the matrix multiplication C = AB. We have
for direct mode and for the opposite. To correctly perform the multiplication, you need to strictly observe the order and use of hyphenation. From the point of view of recording, this looks confusing for a person involved in MO, but from the point of view of calculations, this is an extra load for the program. Another example, less trivial: c = det (A). We have
for direct mode and for the opposite. In this case, it is obviously impossible to use the expression tree for both modes, given that they consist of different operators. In general, the way TensorFlow and other libraries (for example, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) implemented automatic differentiation, which leads to the fact that for direct and reverse Different and ineffective expression trees are built in the mode. Tensor numbering circumvents these problems due to the commutativity of multiplication due to index notation. For details on how this works, see the scientific paper.
The authors tested their method by performing automatic differentiation of the reverse regime, also known as back propagation, in three different tasks, and measured the time it took to calculate the Hessians.
In the first problem, the quadratic function x T Ax was optimized . In the second, logistic regression was calculated, in the third - matrix factorization.
On the CPU, their method turned out to be two orders of magnitude faster than such popular libraries as TensorFlow, Theano, PyTorch, and HIPS autograd.
On the GPU, they observed even greater acceleration, by as much as three orders of magnitude.
The consequences:
Computing derivatives for functions of the second or higher order using current deep learning libraries is too expensive from a computational point of view. This includes the calculation of general fourth-order tensors such as Hessians (for example, in MAML and Newton’s second-order optimization). Fortunately, quadratic formulas are rare in deep learning. However, they are often found in “classical” machine learning - SVM , least squares method, LASSO, Gaussian processes, etc.
Myth 2: Image databases reflect real-world photos
Many people like to think that neural networks have learned to recognize objects better than people. This is not true. They can be ahead of people on the bases of selected images, for example, ImageNet, but in the case of recognition of objects from real photos from ordinary life, they definitely will not be able to overtake an ordinary adult. This is because the selection of images in the current data sets does not coincide with the selection of all possible images naturally encountered in reality.
In a rather old work, Unbiased Look at Dataset Bias. Torralba and Efros. CVPR 2011. , The authors proposed to study the distortions associated with a set of images in twelve popular databases, finding out whether it is possible to train the classifier to determine the data set from which this image was taken.
The chances of accidentally guessing the correct data set are 1/12 ≈ 8%, while the scientists themselves coped with the task with a success rate of> 75%.
They trained SVM on a directional gradient histogram (HOG) and found that the classifier completed the task in 39% of cases, which significantly exceeds random hits. If we repeated this experiment today, with the most advanced neural networks, we would surely see an increase in the accuracy of the classifier.
If the image databases correctly displayed the true images of the real world, we would not have to be able to determine from which dataset a particular image comes from.
However, there are traits in the data that make each set of images different from the others. ImageNet has many race cars that are unlikely to describe the “theoretical” average car as a whole.
The authors also determined the value of each data set by measuring how well a classifier trained on one set works with images from other sets. According to this metric, the LabelMe and ImageNet databases turned out to be the least biased, having received a rating of 0.58 using the “currency basket” method. All values turned out to be less than unity, which means that training on a different data set always leads to poor performance. In an ideal world without biased sets, some numbers should have exceeded one.
The authors pessimistically concluded:
So what is the value of existing datasets for training algorithms designed for the real world? The resulting answer can be described as "better than nothing but not much."
Myth 3: MO researchers do not use test kits for testing
In the textbook on machine learning, we are taught to divide the data set into training, evaluation and verification. The effectiveness of the model, trained on the training set, and evaluated on the evaluation helps the person involved in the MO to fine-tune the model to maximize efficiency in its actual use. The test set does not need to be touched until the person finishes adjusting to provide an unbiased assessment of the real effectiveness of the model in the real world. If a person cheats using a test set at the training or assessment stages, the model runs the risk of becoming too adapted for a particular data set.
In the hyper-competitive world of MO research, new algorithms and models are often judged by the effectiveness of their work with verification data. Therefore, it makes no sense for researchers to write or publish papers describing methods that work poorly with test data sets. And this, in essence, means that the community of the Moscow Region as a whole uses a test set for evaluation.
What are the consequences of this scam?
Authors of Do CIFAR-10 Classifiers Generalize to CIFAR-10? Recht et al. ArXiv 2018 investigated this issue by creating a new test suite for CIFAR-10. To do this, they made a selection of images from Tiny Images.
They chose CIFAR-10 because it is one of the most commonly used datasets in the MO, the second most popular set in NeurIPS 2017 (after MNIST). The process of creating a dataset for CIFAR-10 is also well described and transparent, in the large Tiny Images database there are a lot of detailed labels, so you can reproduce a new test set, minimizing the distribution shift.
They found that a large number of different models of neural networks on the new test set showed a significant drop in accuracy (4% - 15%). However, the relative performance rank of each model remained fairly stable.
In general, better performing models showed a lower accuracy drop compared to worse performing ones. This is nice, because it follows that the loss of model generalizability due to cheating, at least in the case of CIFAR-10, decreases as the community invents improved MO methods and models.
Myth 4: Neural network training uses all input
It is generally accepted that data is a new oil , and that the more data we have, the better we can train deep learning models that are now sample-inefficient and overparametrized.
In An Empirical Study of Example Forgetting During Deep Neural Network Learning. Toneva et al. ICLR 2019 authors demonstrate significant redundancy in several common sets of small images. Surprisingly, 30% of the data from CIFAR-10 can simply be removed without changing the accuracy of the check by a significant amount.
Histories of oblivion from (left to right) MNIST, permutedMNIST and CIFAR-10.
Forgetting happens when a neural network incorrectly classifies an image at time t + 1, while at time t it was able to correctly classify an image. The flow of time is measured by SGD updates. To track forgetting, the authors launched their neural network on a small data set after each SGD update, and not on all the examples available in the database. Examples that are not subject to forgetting are called unforgettable examples.
They found that 91.7% MNIST, 75.3% permutedMNIST, 31.3% CIFAR-10, and 7.62% CIFAR-100 are unforgettable examples. This is intuitively understandable, since increasing the diversity and complexity of the data set should make the neural network forget more examples.
Forgettable examples seem to exhibit more rare and strange features compared to unforgettable ones. The authors compare them with support vectors in SVM, as they seem to draw the outline of decision boundaries.
Unforgettable examples, in turn, encode mostly redundant information. If we sort the examples by the degree of unforgettableness, we can compress the data set by deleting the most unforgettable ones.
30% of the CIFAR-10 data can be deleted without affecting the accuracy of the checks, and the deletion of 35% of the data leads to a slight drop in the accuracy of the checks by 0.2%. If you select 30% of the data randomly, then deleting them will lead to a significant loss in the accuracy of the verification of 1%.
Similarly, 8% of data can be removed from the CIFAR-100 without a drop in validation accuracy.
These results show that there is significant redundancy in the data for training neural networks, similar to SVM training, where non-supporting vectors can be removed without affecting the model decision.
Consequences:
If we can determine which of the data is unforgettable before the start of training, we can save space by deleting them and time by not using them when training a neural network.
Myth 5: Batch normalization is required to train very deep residual networks.
For a long time, it was believed that "training a deep neural network for direct optimization only for a controlled purpose (for example, the logarithmic probability of a correct classification) using gradient descent, starting with random parameters, does not work well."
The heap of ingenious methods of random initialization that has appeared since then, activation functions, optimization techniques, and other innovations, such as residual connections, facilitated the training of deep neural networks using the gradient descent method.
But a real breakthrough happened after the introduction of batch normalization (and other sequential normalization techniques), limiting the size of activations for each layer of the network in order to eliminate the problem of disappearing and explosive gradients.
In recent workFixup Initialization: Residual Learning Without Normalization. Zhang et al. ICLR 2019 has shown that it is possible to train a network with 10,000 layers using pure SGD without applying any normalization.
The authors compared residual neural network training for different depths on CIFAR-10 and found that while standard initialization methods did not work for 100 layers, Fixup and batch normalization methods succeeded with 10,000 layers.
They carried out a theoretical analysis and showed that “the gradient normalization of certain layers is limited by the number infinitely increasing from a deep network”, which is a problem of explosive gradients. To prevent this, Foxup is used, the key idea of which is to scale the weights in m layers for each of the residual branches L by the number of times depending on m and L.
Fixup helped train a deep residual network with 110 layers on CIFAR-10 with a high learning rate, comparable to the behavior of a network of similar architecture, trained using batch normalization.
The authors further showed similar test results using Fixup on the network without any normalization, working with the ImageNet database and with translations from English into German.
Myth 6: Networks with attention are better than convolutional ones.
The idea that the mechanisms of “attention” are superior to convolutional neural networks is gaining popularity in the community of MO researchers. In the work of Vaswani and colleagues , it was noted that “the computational cost of detachable convolutions is equal to the combination of a self-attention layer and a point-wise feed-forward layer.”
Even advanced generative-competitive networks show the advantage of self-attention over standard convolution when modeling long-range dependencies.
Contributors Pay Less Attention with Lightweight and Dynamic Convolutions. Wu et al. ICLR 2019question the parametric efficiency and effectiveness of self-attention when modeling long-range dependencies, and offer new options for convolutions, partially inspired by self-awareness, more effective in terms of parameters.
The “lightweight” convolutions are separable in depth, softmax-normalized in time dimension, separated by weight in channel dimension, and reuse the same weights at each time step (as recurrent neural networks). Dynamic convolutions are lightweight convolutions that use different weights at each time step.
Such tricks make lightweight and dynamic convolutions several orders of magnitude more effective than standard indivisible convolutions.
The authors show that these new convolutions correspond or exceed self-absorbing networks in machine translation, language modeling, abstract summation problems, using the same or less parameters.
Myth 7: Significance Cards - A Reliable Way to Interpret Neural Networks
Although there is an opinion that neural networks are black boxes, there have been many attempts to interpret them. The most popular of these are significance maps, or other similar methods that assign importance assessments to features or training examples.
It is tempting to be able to conclude that a given image has been classified in a certain way due to certain parts of the image that are significant to the neural network. To calculate significance maps, there are several methods that often use the activation of neural networks in a given image and the gradients passing through the network.
In Interpretation of Neural Networks is Fragile. Ghorbani et al. AAAI 2019the authors show that they can introduce an elusive change in the picture, which, however, will distort its significance map.
The neural network determines the monarch butterfly not by the pattern on its wings, but because of the presence of unimportant green leaves against the background of the photo.
Multidimensional images are often closer to decision boundaries made by deep neural networks, hence their sensitivity to adversarial attacks. And if competitive attacks move images beyond the boundaries of the solution, competitive interpretative attacks shift them along the boundary of the solution without leaving the territory of the same solution.
The basic method developed by the authors is a modification of the Goodfello method of fast gradient marking, which was one of the first successful methods of competitive attacks. It can be assumed that other, newer and more complex attacks can also be used for attacks on the interpretation of neural networks.
Consequences:
In connection with the growing spread of deep learning in such critical areas of application as medical imaging, it is important to carefully approach the interpretation of decisions made by neural networks. For example, although it would be great if the convolutional neural network could recognize the spot on the MRI image as a malignant tumor, these results should not be trusted if they are based on unreliable interpretation methods.