What is wrong with reinforcement learning (Reinforcement Learning)?
- Tutorial

Back in the beginning of 2018, the Deep Reinforcement Learning Doesn't Work Yet article was published (" Reinforcement Training Doesn't Work Yet "). The main complaint of which was reduced to the fact that modern learning algorithms with reinforcements require approximately the same amount of time to solve a problem as a normal random search.
Has anything changed since that time? Not.
Reinforcement training is considered one of the three main ways to build a strong AI. But the difficulties faced by this area of machine learning, and the methods by which scientists are trying to deal with these difficulties, suggest that perhaps this very approach has fundamental problems.
Wait, what does one of the three mean? And the other two are what?
Given the success of neural networks in recent years and an analysis of how they work with high-level cognitive abilities, previously considered characteristic only of humans and higher animals, today the scientific community has the opinion that there are three main approaches to creating a strong AI on based on neural networks that can be considered less realistic:
1. Text processing
The world has accumulated a huge number of books and text on the Internet, including textbooks and reference books. The text is convenient and fast for processing on a computer. Theoretically, this array of texts should be enough to teach a strong conversational AI.
In this case, it is assumed that these text arrays reflect the complete structure of the world (at a minimum, it is described in textbooks and reference books). But this is absolutely not a fact. Texts as a type of representation of information are strongly detached from the real three-dimensional world and the flow of time in which we live.
Good examples of AI trained on textual arrays are chat bots and automatic translators. Since the translation of the text you need to understand the meaning of the phrase and retell it with new words (in another language). There is a common misconception that the rules of grammar and syntax, including the description of all possible exceptions, completely describe a specific language. This is not true. Language is only an auxiliary tool in life, it changes easily and adapts to new situations.
The problem of word processing (even with expert systems, even with neural networks) is that there is no set of rules, which phrases should be used in which situations. Pay attention - not the rules for constructing the phrases themselves (what the grammar and syntax do), but exactly which phrases in which life situations. In the same situation, people pronounce phrases in different languages that are generally not related to each other in terms of the structure of the language. Compare phrases with extreme astonishment: "oh my God!" and "o, holy shit!". Well, and how between them to carry out the correspondence, knowing the language model? Yes, nothing. It so happened historically. You need to know the situation and what is usually spoken in a particular language. Because of this, automatic translators are so imperfect.
Whether it is possible to isolate this knowledge purely from an array of texts is unknown. But if automatic translators start to translate perfectly, without making silly and ridiculous mistakes, then this will be proof that creating a strong AI based only on text is possible.
2. Image recognition
Look at this image

Looking at this photo, we understand that the shooting was done at night. Judging by the flags, the wind blows from right to left. And judging by the right-hand traffic, it does not happen in England or Australia. None of this information is explicitly indicated in the pixels of the picture, it is external knowledge. In the photo there are only signs on which we can use the knowledge obtained from other sources.
О том и речь… И найдите себе девушку, наконец
Therefore, it is believed that if you train a neural network to recognize objects in the picture, then it will form an internal idea of how the real world works. And this view, obtained from photographs, will surely correspond to our real and real world. Unlike text arrays, where this is not guaranteed.
The value of neural networks trained on the ImageNet photo array (and now OpenImages V4 , COCO , KITTI , BDD100K, and others) is not at all in the fact of recognition of the cat in the photo. And that is stored in the penultimate layer. It is there that is a set of high-level features that describe our world. A vector of 1024 numbers is enough to get a description of 1000 different categories of objects with 80% accuracy (and in 95% of cases the correct answer will be in the 5 closest variants). Just think about it.
That is why these features from the penultimate layer are so successfully used in completely different tasks in computer vision. Through Transfer Learning and Fine Tuning. From this vector in 1024 numbers you can get, for example, a depth map for the picture
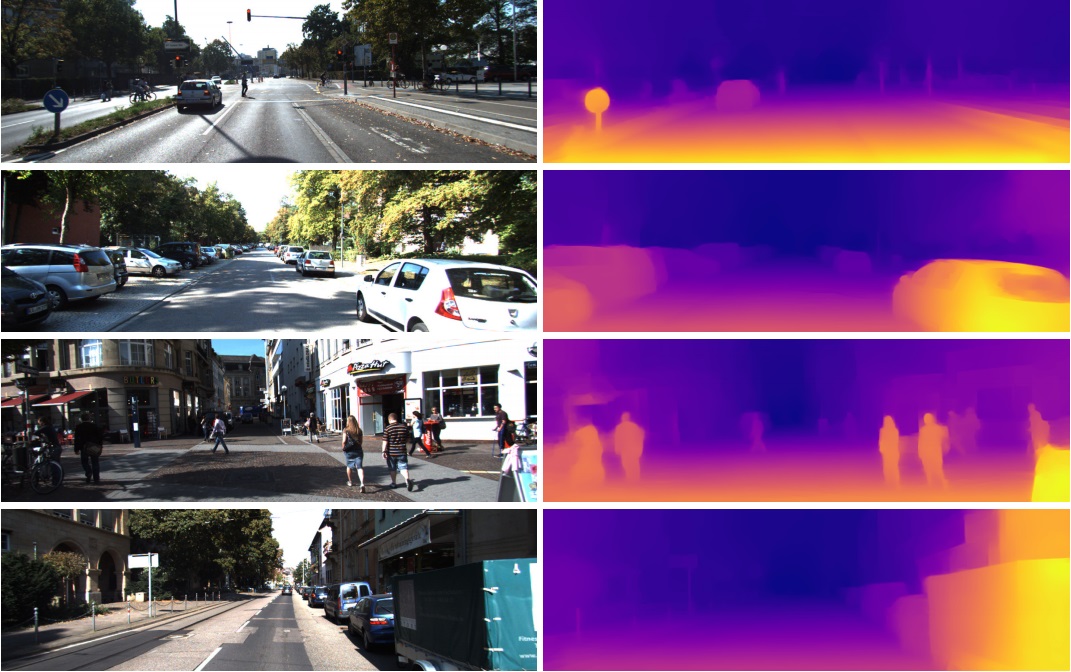
(an example from work where practically unchanged pre-trained network Densenet-169 is used)
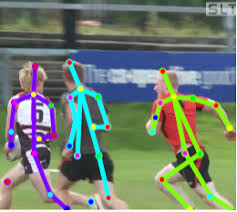
Or determine the pose of a person. There are many applications.
As a consequence, image recognition can potentially be used to create a strong AI, as it truly reflects the model of our real world. From photography to video is one step, and video is our life, since we receive about 99% of the information visually.
But the photograph is completely incomprehensible how to motivate the neural network to think and draw conclusions. She can be trained to answer questions like "how many pencils are on the table?" (this class of tasks is called Visual Question Answering, an example of such a dataset: https://visualqa.org ). Or give a text description of what is happening in the photo. This is the Image Captioning class of tasks .

But is this an intelligence? Having developed this approach, in the near future neural networks will be able to answer video questions like "Two sparrows sat on wires, one of them flew away, how many sparrows left?". This is already real mathematics, in slightly more complicated cases inaccessible to animals and located at the level of human school education. Especially if, apart from the sparrows, there will be titmouses sitting next to them, but they should not be taken into account, since the question was only about the sparrows. Yes, it will definitely be intelligence.
3. Reinforcement Learning
The idea is very simple: to encourage actions that lead to reward, and to avoid leading to failure. This is a universal way of learning and, obviously, it can definitely lead to the creation of a strong AI. Therefore, there is such a great interest in Reinforcement Learning in recent years.
Конечно, лучше всего сильный ИИ создавать комбинируя все три подхода. На картинках и с обучением с подкреплением можно получить ИИ уровня животных. А добавив к картинкам текстовые названия объектов (шутка, конечно же — заставив ИИ просматривать видео, где люди взаимодействуют и разговаривают, как при обучении младенца), и дообучив на текстовом массиве для получения знаний (аналог нашей школы и университета), в теории можно получить ИИ человеческого уровня. Способный разговаривать.
Reinforcement training has one big plus. In the simulator, you can create a simplified model of the world. So, for a human figure, only 17 degrees of freedom are sufficient, instead of 700 in a living person (approximate number of muscles). Therefore, in the simulator you can solve the problem in a very small dimension.
Looking ahead, modern Reinforcement Learning algorithms are not capable of arbitrarily controlling a person’s model even with 17 degrees of freedom. That is, they cannot solve the optimization problem, where the input is 44 numbers and the output 17. It can only be done in very simple cases, with fine manual adjustment of the initial conditions and hyperparameters. And even in this case, for example, to teach a humanoid model with 17 degrees of freedom to run, and starting from a standing position (which is much simpler), it takes several days of calculations on a powerful GPU. A little more complicated cases, such as learning how to get up from an arbitrary pose, may never learn at all. This is a failure.
In addition, all Reinforcement Learning algorithms work with disappointingly small neural networks, and with large learning can not cope. Large convolutional networks are used only to reduce the dimension of the picture to several features, which are fed to the input of learning algorithms with reinforcement. The same running humanoid is controlled by a Feed Forward network with two or three layers of 128 neurons each. Seriously? And based on this, are we trying to build a strong AI?
To try to understand why this is happening and what is wrong with reinforcement learning, you must first familiarize yourself with the main architectures in modern Reinforcement Learning.
The physical structure of the brain and nervous system is tuned by evolution to a specific type of animal and its habitat conditions. Thus, a fly developed such a nervous system and such work of neurotransmitters in the ganglia (analogous to the brain in insects) in order to quickly dodge the fly swatter. Well, not from a fly swatter, but from birds that caught them 400 million years (joke, the birds themselves appeared 150 million years ago, rather from frogs 360 million years). And the rhinoceros has enough of such a nervous system and brain to slowly turn toward the goal and start running. And there, as they say, the rhino has poor eyesight, but these are not his problems.
But besides evolution, it is the usual mechanism of reinforcement learning that works for each individual individual, starting at birth and throughout life. In the case of mammals and insects, too , this work is done by the dopamine system. Her work is full of secrets and nuances, but it all comes down to the fact that, in the case of receiving a reward, the dopamine system, through memory mechanisms, somehow fixes the connections between neurons that were active just before. This is how the associative memory is formed.
Which, by virtue of its associativity, is then used in decision making. Simply put, if the current situation (the current active neurons in this situation) activate the neurons of the memory of pleasure by associative memory, then the individual chooses the actions that she did in a similar situation and which she remembered. "Choosing actions" is a bad definition. No choice. Simply activated neurons of the memory of pleasure, fixed by the dopamine system for this situation, automatically activate the motor neurons, leading to muscle contraction. This is if immediate action is needed.
Artificial learning with reinforcement, as a field of knowledge, needs to solve both of these tasks:
1. Choose the neural network architecture (which evolution has already done for us)
The good news is that the higher cognitive functions performed in the neocortex in mammals (and in the corpus striatum of corvids ) are performed in an approximately homogeneous structure. Apparently, this does not need some kind of rigidly defined "architecture".
The diversity of brain areas is probably due to purely historical reasons. When, as evolution progressed, new parts of the brain grew on top of the base ones left over from the very first animals. By the principle works - do not touch. On the other hand, in different people, the same parts of the brain react to the same situations. This can be explained both by associativity (features and "grandmother's neurons" naturally formed in these places in the learning process) and by physiology. That the signal paths encoded in the genes lead precisely to these areas. There is no consensus here, but you can read, for example, this recent article: "Biological and artificial intelligence" .
2. Learn to teach neural networks on the principles of learning with reinforcement
This is precisely what modern Reinforcement Learning is doing. And what progress? Not really.
Naive approach
It would seem that it is very simple to train a neural network with reinforcement: we do random actions, and if we receive an award, then we consider the actions that we have taken as “reference”. We put them on the output of the neural network as standard labels and train the neural network using the method of back propagation of an error, so that it would give just such an output. Well, the most common learning neural network. And if the actions lead to failure, then either we ignore this case, or we suppress these actions (we put some others as a reference at the output, for example, any other random action). In general, this idea repeats the dopamine system.
But if you try to train any neural network like that, no matter how complex the architecture is, recurrent, convolutional, or regular direct propagation, then ... Nothing will work!
Why? Unknown.
It is believed that the useful signal is so small that it is lost against the background of noise. Therefore, the network does not learn the standard backpropagation method. The reward happens very rarely, maybe once out of hundreds or even thousands of steps. And even LSTM remembers a maximum of 100-500 points of history, and then only in very simple tasks. And on more complex ones, if there are 10-20 points of history, then this is already good.
But the root of the problem is in very rare rewards (at least in tasks of practical value). At the moment, we are not able to train neural networks that would memorize isolated cases. What the brain copes with shine. You can remember something just once, remember for a lifetime. And, by the way, most of the training and work of the intellect is based on such cases.
This is something like a terrible imbalance of classes from the field of image recognition. There is simply no way to deal with this. The best that we could come up with so far is simply to submit to the input of the network along with new situations, successful situations from the past saved in an artificial special buffer. That is, to constantly teach not only new cases, but also successful old ones. Naturally, you can not infinitely increase such a buffer, and it is not clear what exactly to store in it. They are still trying to fix the paths within the neural network for some time, which were active during the successful event so that the subsequent training would not overwrite them. A rather close analogy to what is happening in the brain, in my opinion, although we have not yet achieved much success in this direction either. Since new trained tasks in their calculation use the results of the output of neurons from frozen paths, then, as a result, the signal only for these frozen interferes with new ones, and old tasks stop working. There is another interesting approach: to teach the network new examples / tasks only in the orthogonal direction to the previous tasks (https://arxiv.org/abs/1810.01256 ). This does not overwrite previous experience, but drastically limits network capacity.
A separate class of algorithms designed to deal with this disaster (and at the same time giving hope to achieve a strong AI), are being developed in Meta-Learning. These are attempts to teach a neural network several tasks at once. Not in the sense of recognizing different pictures in one task, namely, different tasks in different domains (each with its own distribution and landscape of solutions). Say, recognize pictures and ride a bike at the same time. Successes are not very good either, as it usually all comes down to preparing a neural network with common universal weights in advance, and then quickly, in just a few steps of a gradient descent, to adapt them to a specific task. Examples of meta-learning algorithms are MAML and Reptile .
In general, only this problem (the inability to learn from single successful examples) puts an end to modern training with reinforcement. All the power of neural networks before this sad fact is powerless.
This fact that the easiest and most obvious way does not work, forced the researchers to return to the classic tabular Reinforcement Learning. Which as a science appeared in antiquity, when neural networks were not even in the project. But now, instead of manually counting the values in the tables and in the formulas, let's use such a powerful approximator as neural networks as target functions! This is the essence of modern Reinforcement Learning. And its main difference from the usual learning neural networks.
Q-learning and DQN
Reinforcement Learning (even before neural networks) was born as a fairly simple and original idea: let's do, again, random actions, and then for each cell in the table and each direction of movement, we calculate using a special formula (called the Bellman equation, you will meet in virtually every reinforcement training job) how good this cell and the chosen direction are. The higher this number is, the more likely this path leads to victory.
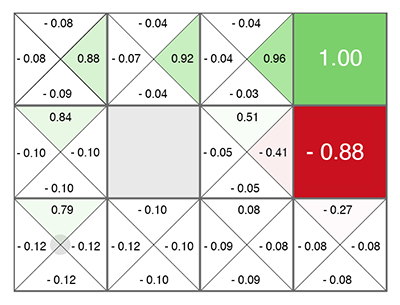
Whatever cell you are in, move upwards in green! (towards the maximum number on the sides of the current cell).
This number is called Q (from the word quality is the quality of choice, obviously), and the method is Q-learning. Replacing the formula for calculating this number on a neural network, or rather, teaching the neural network using this formula (plus a couple of tricks related purely to the math of learning neural networks), Deepmind received the DQN method . This is which in 2015 won the Atari pile of games and marked the beginning of a revolution in Deep Reinforcement Learning.
Unfortunately, this method in its architecture only works with discrete discrete actions. In DQN, the current state (current situation) is fed to the input of the neural network, and the neural network predicts the Q number at the output. And since all the possible actions are listed at the output of the network (each with its predicted Q), it turns out that the neural network in DQN implements the classic Q function (s, a) from Q-learning. Returns Q for state and action (therefore Q (s, a) as a function of s and a). We are simply looking for the usual argmax array among the network outputs of the cell with the maximum number Q and do the action that corresponds to the index of this cell.
And you can always choose an action with a maximum Q, then this policy will be called deterministic. And you can choose an action as random from the available ones, but in proportion to their Q-values (that is, actions with high Q will be chosen more often than with low). This policy is called stochastic. In the stochastic choice, plus the fact that the search and exploration of the world is automatically realized (Exploration), since each time different actions are chosen, sometimes not seemingly the most optimal, but which can lead to a great reward in the future. And then we will learn and increase the probability of these actions, so that now they are more often chosen according to their probability.
But what if the options are endless? If this is not the 5 buttons on the joystick in Atari, but the continuous torque control of the robot engine? Of course, the moment in the range -1..1 can be divided into subranges of 0.1, and at each moment of time you can choose one of these subranges, like pressing a joystick in Atari. But not always the right number can be discretized at intervals. Imagine that you are riding a bike through a mountain peak. And you can only turn the steering wheel 10 degrees left or right. At some point, the peak may become so narrow that turning 10 degrees in both directions will result in a fall. This is the fundamental problem of discrete actions. Moreover, DQN does not work with large dimensions, and even with 17 degrees of freedom it simply does not converge on a robot. Everything is good, but there is a small nuance, as they say.
Later, many original and sometimes ingenious algorithms based on DQN were developed, which allowed, among other things, to work with continuous actions (due to tricks and the introduction of additional neural networks): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. Perhaps, here can also be attributed Direct Future Prediction (DFP)which is related to the DQN network architecture and discrete actions. Instead of predicting the Q number for all actions, DFP directly predicts how much health or ammo will be in the next step if you choose this action. And one step forward and several steps forward. We can only go through all the network outputs and find the maximum value of the parameter of interest to us and choose the appropriate action for this element of the array, depending on current priorities. For example, if we are injured, we can look for the action among the exits of the network, leading to the maximum increase in health.
But more importantly, in the subsequent time new architectures were developed specifically for Reinforcement Learning.
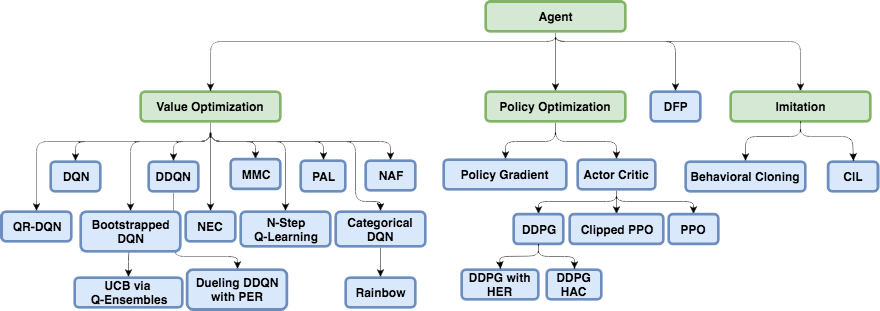
Policy gradient
Let's input the current state to the network input, and immediately predict the actions at the output (either the actions themselves or the probability distribution for them in the stochastic policy). We simply act using actions predicted by the neural network. And then we look, what reward R has typed for an episode. This award can be either higher than the initial (when won in the game) or lower (lost in the game). You can also compare the reward with a certain average reward. Above it is average or lower.
Actually, the dynamics of the received award R as a result of actions that the neural network prompted can be used to calculate the gradient using a special formula. And apply this gradient to the weights of the neural network! And then use the usual reverse error propagation. Simply, instead of "reference" actions at the exit of the network as labels (we do not know what they should be), we use the change of the reward to calculate the gradient. According to this gradient, the network will learn to predict actions that lead to an increase in the R award.
This is a classic policy gradient. But he has a drawback - you have to wait until the end of the episode to calculate the cumulative reward R before changing the weights of the network according to its change. And of the advantages - a flexible system of rewards and punishments, which not only works in both directions, but also depends on the size of the reward. A big reward more strongly encourages the actions that led to it.
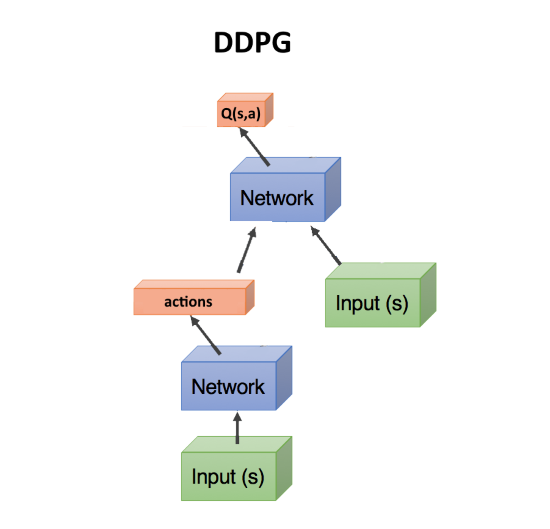
Actor-critic, DDPG
Now imagine that we have two networks - one predicts what actions to take, and the second assesses how good these actions are. That is, it gives a Q-number for these actions, as in the DQN algorithm. The state is fed to the input of the first network, and it predicts action (s). The second network also receives state at the input, but also the action actions predicted by the first network, and the output gives the number Q as a function of both of them: Q (s, a).
Actually, this number Q (s, a), issued by the second network (it is called a critic, critic), can also be used to calculate the gradient, which updates the weights of the first network (which is called an actor), as we did above with the award R Well, the second network is updated in the usual way, according to the actual passage of the episode. This method was called actor-critic. Its plus in comparison with the classical Policy Gradient, that the weights of the network can be updated at each step, without waiting for the end of the episode. What speeds up learning.
As such, it is a DDPG network. Since it predicts actions directly, it works great with continuous actions. DDPG is a direct continuous competitor of DQN with its discrete actions.
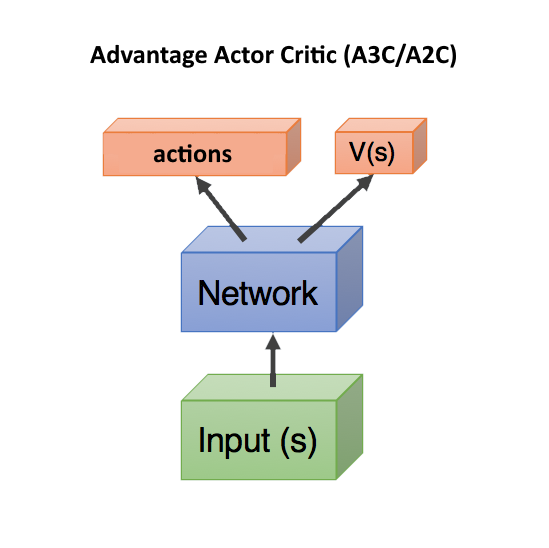
Advantage Actor Critic (A3C / A2C)
The next step was to use the number Q (s, a) for teaching the first network not just the critic's predictions — how good the actions predicted by the actor actor, as it was in the DDPG. And how much these predicted actions turned out to be better or worse than we expected.
This is very close to what happens in the biological brain. It is known from experiments that the maximum release of dopamine does not occur during the actual enjoyment, but during the waiting period , which we will soon enjoy. However, if expectations were not met, then terrible consequences would occur, greater than in the usual case (there is a special punishment system in the body, the opposite of the reward system).
To do this, to calculate the gradients, they began to use not the number Q (s, a), but the so-called Advantage: A (s, a) = Q (s, a) - V (s). The number A (s, a) shows not the absolute quality Q (s, a) of the selected actions, but the relative advantage — how much better after the actions taken will be better than the current situation V (s). If A (s, a)> 0, then the gradient will change the weights of the neural network, encouraging the actions predicted by the network. If A (s, a) <0, then the gradient will change the weights so that the predicted actions will be suppressed, because they turned out to be bad.
In this formula, V (s) shows how good the current state is by itself, without reference to actions (therefore it depends only on s, without a). If we are standing a step away from the summit of Everest, this is a very good situation of the state, with a large V (s). And if we have already broken and are falling, then this is a bad state, with a low V (s).
Fortunately, with this approach, Q (s, a) can be replaced by the reward r, which we get after performing the action, and then the formula of the advantage for calculating gradients is A = r - V (s).
In this case, it is enough to predict only V (s) (and we will see the reward by the fact of what happens in reality), and the two networks, actor and critic, can be combined into one! Which receives on an input state, and on an output it is divided into two heads: one predicts actions actions, and another predicts V (s). Such a combination helps to reuse weights, because both networks should receive state at the entrance. However, you can use two separate networks.
Taking into account and predicting by the network the quality of the current situation V (s) in any case helps to accelerate learning. Since in case of a bad V (s), where nothing can be corrected under any action actions (we are flying upside down from Everest), one can find no further solution. This is used in Dueling Q-Network (DuDQN), where Q (s, a) inside the network is specially decomposed into Q (s, a) = V (s) + A (a), and then it is going back.
Asynchronous Advantage Actor Critic (A3C) means only that there is a server collecting results from the actor set. And the update weights as soon as the batch batch of the right size is dialed. Therefore asynchronous, that does not wait for each actor. It seems to dilute examples, removing unnecessary correlation from them, which improves learning. On the other hand, then A2C appeared - a synchronous version of A3C, in which the server waits for the end of episodes for all actor and only after that updates the weights (therefore synchronous). A2C also shows good results, so both versions are applied, depending on the taste of the developer.
TRPO, PPO, SAC
Actually, this progress is over.
Despite the beautiful and logical description, it doesn’t work very well. Even the best Reinforcement Learning algorithms require tens of millions of examples, are comparable in efficiency with random search, and the saddest thing is that it does not allow using them to create a strong AI - they work only on extremely low dimensions, measured in units. Not even dozens.
Further improvements - TRPO and PPO, which are now state-of-the-art, are a variety of Actor-Critic. PPOs currently train the majority of agents in the RL world. For example, they were taught OpenAI Five to play Dota 2.
You will laugh, but all that was invented in the TRPO and PPO methods is to limit the change in the neural network with each update so that the weights do not change dramatically. The fact is that in A3C / A2C there are dramatic changes that spoil previous experience. If you make the new policy not too different from the previous one, you can avoid such emissions. Something like gradient clipping in recurrent networks to protect against exploding gradients, only on a different math apparatus. The fact that it is necessary to cut off so roughly and worsen the training (the large gradients didn’t just appear there, they are necessary for the example that caused them), and that it has a positive effect suggests that we turned somewhere not there.
Recently, the Soft-Actor-Critic (SAC) algorithm has been growing in popularity. It is not much different from PPO, only the goal of learning to increase the entropy in policy has been added. Make agent behavior more casual. No not like this. That the agent was able to act in more random situations. This automatically increases the reliability of the policy, since the agent is ready for any random situations. In addition, SAC requires slightly less training examples than PPO, and is less sensitive to setting up hyper parameters, which is also a plus. However, even with the SAC, in order to train to run a humanoid with 17 degrees of freedom, from a standing position, you need about 20 million frames and about a day of calculation on a single GPU. More complex initial conditions, say, to teach a humanoid to get up from an arbitrary position, may not learn at all.
Total, general recommendation in modern Reinforcement Learning: use SAC, PPO, DDPG, DQN (in this order, in descending order).
Model-Based
There is another interesting approach, indirectly related to reinforcement training. This is to build a model of the environment, and use it to predict what will happen if we take some action.
Its disadvantage is that it does not say what actions need to be taken. Only about their result. But on the other hand, such a neural network is easy to train - we simply train on any statistics. It turns out something like a simulator of the world based on a neural network.
After that, we generate a huge number of random actions, and each run through this simulator (via a neural network). And look, which of them will bring the maximum reward. There is a small optimization - to generate not just random actions, but deviating according to the normal law from the current trajectory. And indeed, if we raise our hand, then we most likely need to continue raising it. Therefore, first of all, you need to check the minimum deviations from the current path.
Here the trick is that even a primitive physical simulator like MuJoCo or pyBullet yields about 200 FPS. And if you train a neural network to predict at least a few steps ahead, then for simple environments you can easily get batch of 2000-5000 predictions at a time. Depending on the power of the GPU, per second, you can get a forecast for tens of thousands of random actions due to parallelization in the GPU and the compactness of the calculations in the neural network. The neural network here simply plays the role of a very fast reality simulator.
In addition, since the neural network can predict the real world (this is the model-based approach, in a general sense), it is possible to conduct training entirely in the imagination, so to speak. This concept in Reinforcement Learning is called Dream Worlds, or World Models. It works well, a good description is here: https://worldmodels.github.io . In addition, it has a natural counterpart - ordinary dreams. And multiple scrolling of recent or planned events in the head.
Imitation learning
From the powerlessness that the Reinforcement Learning algorithms do not work on large dimensions and complex tasks, the people set out to at least repeat the actions for experts in the form of people. It managed to achieve good results (unattainable conventional Reinforcement Learning). So, OpenAI got to go through the game Montezuma's Revenge . The focus turned out to be simple - to place the agent immediately at the end of the game (at the end of the trajectory shown by the man). There, using the PPO, thanks to the proximity of the final award, the agent quickly learns to walk along the path. After that we place him back a bit, where he quickly learns to reach the place that he has already learned. And so gradually moving the spawn point along the trajectory to the very beginning of the game, the agent learns to go through / imitate the trajectory of the expert throughout the game.
Another impressive result is the repetition of movements for people, shot on Motion Capture: DeepMimic . The recipe is similar to the OpenAI method: we start each episode not from the beginning of the trajectory, but from a random point along the trajectory. Then PPO successfully studies the neighborhood of this point.
It must be said that the sensational Uber Go-Explore algorithm , which passed Montezuma's Revenge with record points, is not Reinforcement Learning algorithm at all. This is a common random search, but starting from a randomly visited cell (a coarsened cell in which several states fall). And only when such a random search finds the trajectory until the end of the game, the neural network is already trained by it with the help of Imitation Learning. In a way similar to OpenAI, i.e. starting at the end of the trajectory.
Curiosity (curiosity)
A very important concept in Reinforcement Learning is curiosity (Curiosity). In nature, it is an engine for environmental research.
The problem is that as a curiosity assessment, you cannot use the simple error of network prediction, what will happen next. Otherwise, such a network will hang before the first tree with swinging foliage. Or in front of a TV with random channel switching. Since the result due to the complexity will be impossible to predict and the error will always be big. However, this is precisely the reason why we (people) so love to look at the leaves, water and fire. And the way other people work =). But we have protective mechanisms in order not to hang forever.
One of these mechanisms was invented as the Inverse Model in the work of Curiosity-driven Exploration by
Self-supervised Prediction . In short, the agent (neural network), in addition to predicting what actions are best performed in this situation, additionally tries to predict what will happen to the world after the actions performed. And it uses its own prediction of the world for the next step, so that according to it and the current step back, you can predict your own actions taken earlier (yes, it is difficult, you cannot understand without half a liter).
This leads to a curious effect: the agent becomes curious only to what he can influence with his actions. He can not affect the swinging branches of a tree, so they become uninteresting to him. But he can walk around the district, so he is curious to walk and explore the world.
However, if the agent has a TV remote that switches random channels, it can affect him! And he will be curious to click the channels to infinity (since he cannot predict what the next channel will be, because it is random). An attempt to circumvent this problem was undertaken by Google in Episodic Curiosity through Reachability .
But, perhaps, the best state-of-the-art result of curiosity, at the moment belongs to OpenAI with the idea of Random Network Distillation (RND) . Its essence is that a second, completely randomly initialized network is taken, and the current state is supplied to it. And our main working neural network is trying to guess the output of this neural network. The second network is not trained, it remains fixed all the time as it was initialized.
What's the point? The point is that if a state has already been visited and studied by our work network, then it will be more or less successful in predicting the output of that second network. And if this is a new state where we have never been, then our neural network will not be able to predict the output of that RND network. This error in predicting the release of that randomly initialized network is used as an indicator of curiosity (it gives high rewards if in this situation we cannot predict its output).
Why this works is not entirely clear. But they write that this fixes the problem when the goal of the prediction is stochastic and when there is not enough data to predict what will happen next (which gives a big prediction error in the usual curiosity algorithms). One way or another, the RND actually showed excellent research results based on curiosity in games. And copes with the problem of random TV.
With RND curiosity in OpenAI for the first time honestly (and not through a preliminary random search, as in Uber) passed the first level of Montezuma's Revenge. Not every time and unreliable, but from time to time it turns out.

What is the result?
As you can see, in just a few years, Reinforcement Learning has come a long way. Not just a few successful solutions, like in convolutional networks, where resudal and skip connections allowed us to train networks with depths of hundreds of layers, instead of a dozen layers with the Relu activation function alone, which overcomes the problem of fading gradients in sigmoid and tanh. In reinforcement training, there was progress in the concepts and understanding of the reasons why one or another naive implementation variant did not work. Keyword "not earned."
But from the technical side, everything still rests on the predictions of the same Q, V or A values. Neither temporal dependencies at different scales, as in the brain (Hierarchical Reinforcement Learning does not count, it is too primitive hierarchy in comparison with associativity in the living brain). No attempt to come up with a network architecture, sharpened specifically for training with reinforcements, as happened with LSTM and other recurrent networks for temporary sequences. Reinforcement Learning is either marking time, rejoicing at small successes, or moving in some very wrong direction.
I want to believe that one day in the training with reinforcement there will be a breakthrough in the architecture of neural networks, similar to what happened in convolutional networks. And we will see really working reinforcement training. Studying on single examples, with a working associative memory and working on different time scales.