Protocols of seamless reservation of PRP and HSR
In industry, LAN requirements are becoming increasingly serious as ICS take on more and more functionality, and data loss can lead to serious costs.
For example, in the energy sector, if the data from the measuring transducers does not reach the relay terminal on time, this can be fraught with the spread of a short circuit to adjacent sections of the power supply network, which will result in losses much more serious than in case of timely disconnection of the section from the short circuit. Therefore, often in energy projects you can meet the requirement "Recovery time less than 1 ms."
Network redundancy based on such industry-wide protocols as RSTP, MRP, DLR, and the like, is based on a change in topology in the event of any malfunction in data transmission. Changing the topology takes a certain time (from milliseconds to seconds, depending on the protocol), which is called the "recovery time". During this time, there is no communication with part of the network and, accordingly, data is lost. Those. conventional ring redundancy technologies do not allow recovery times of less than 1 ms.
In view of this, the so-called “seamless” redundancy technologies - PRP and HSR - are gaining popularity. Redundancy based on PRP and HSR is carried out, in contrast to the above protocols, not by rebuilding the topology, but by duplicating frames. Each frame is duplicated by the sender, and both frames are transmitted in different ways, and the receiving node processes the frame that came in first, and discards the second. This principle of operation does not require restructuring of the topology and, accordingly, this protocol operates almost “seamlessly”. Under the cut you will find details of the implementation of these protocols.
Seamless redundancy is implemented on end nodes, not network components. This is one of the main differences between PRP and HSR from other backup protocols such as RSTP or MRP. Consider the features of the network structure for PRP and HSR.
The end node has two Ethernet interfaces that connect to two networks isolated from each other, operating in parallel and having an independent topology (i.e., the topologies of these two networks can be the same or different). The networks must be isolated so that any malfunction and stop of data transmission in one network do not affect the second, i.e. even network power is supplied from different sources. There should not be any direct connections between these networks.

PRP Network Structure
These two networks are usually called LAN A and LAN B. As previously indicated, they can have different topologies as well as different performance. Delays in data transmission may also vary.
The network may contain the following elements:

RedBox's working principle
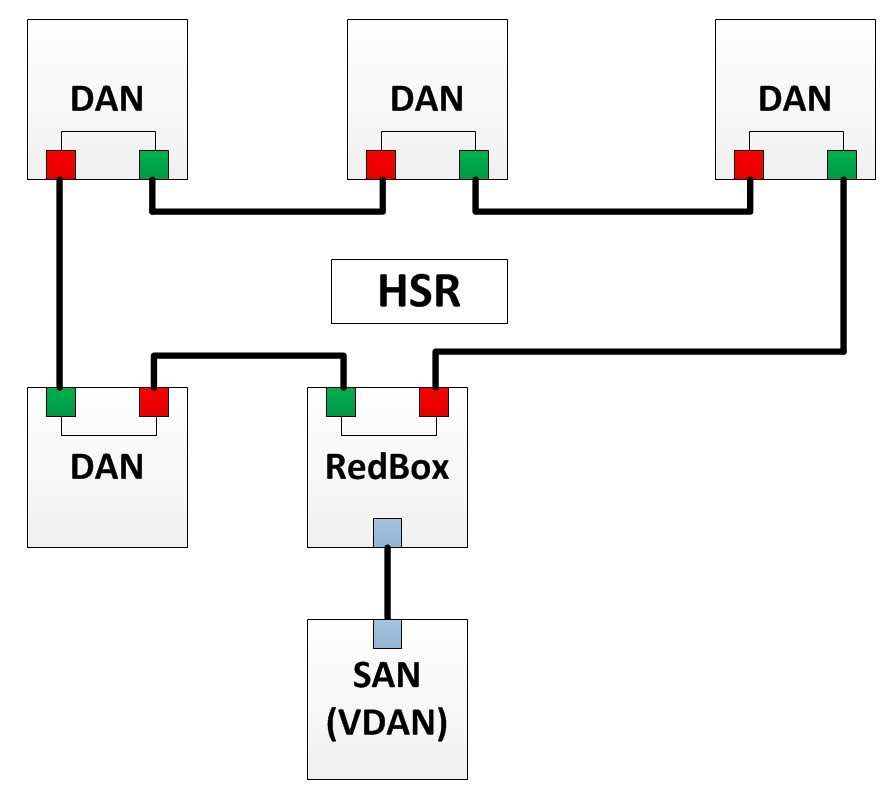
HSR network structure
The principle of operation of HSR is that all devices are combined into a ring and all messages, as well as in PRP, are duplicated. The device sends both frames through the ring: one copy clockwise, the other counterclockwise. The receiver receives both copies, but processes only the first, and deletes the second. If something happens to one of the links, and one of the duplicated frames does not come, then the other is simply accepted. All HSR devices have two Ethernet interfaces - port A and port B.
According to the HSR protocol, the following elements can exist in a network:

QuadBox example
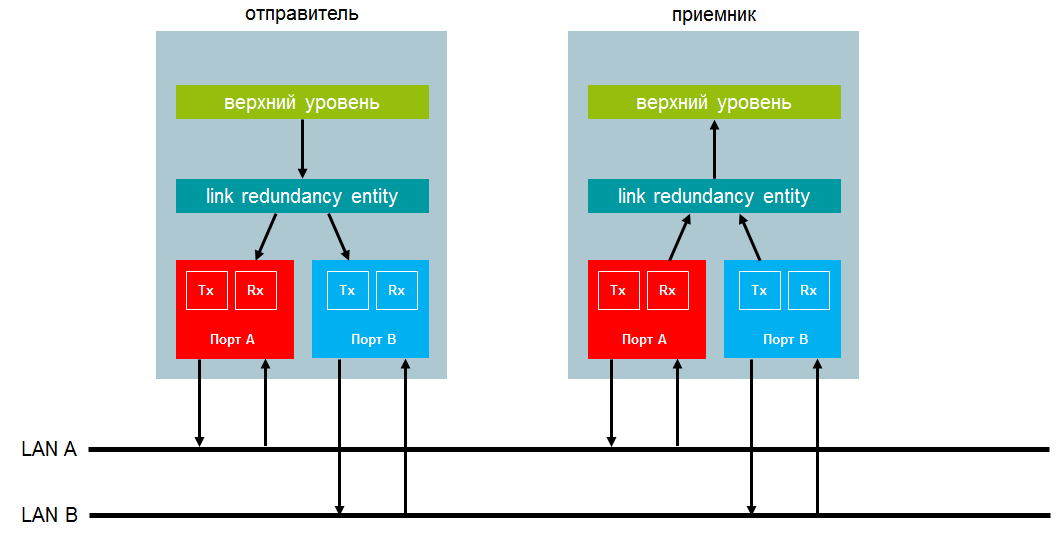
For PRP and for HSR, the DAN structure is similar. Each DAN has two interfaces operating in parallel and connected to the upper level of one communication stack through the so-called LRE layer - link redundancy entity. At this level, all backup functions are performed.
Both DAN interfaces have the same MAC address and one IP address. This allows you to make the reservation transparent to the top level. Especially important is the fact that this allows the use of ARP for DAN as well as for any non-redundant node.
However, of course, there are nuances in the DAN structure for PRP and for HSR.
When a frame is sent from the top level, the LRE duplicates it and sends both packets through the ports almost simultaneously. Both frames are transmitted in parallel through two networks with different delays. In an ideal situation, they are delivered to the destination node with a minimum time difference. Upon receipt of the LRE, the receiver sends the first received frame to the upper layer, and discards the second one.
LRE creates duplicate frames upon sending and processes them upon receipt. This level, in relation to the upper level, represents the usual interface of a non-redundant network adapter. LRE performs two tasks: handling duplicate frames and managing redundancy. To implement control, LRE adds a 32-bit redundancy control trailer (RCT) to each frame and deletes it when the frame is received.
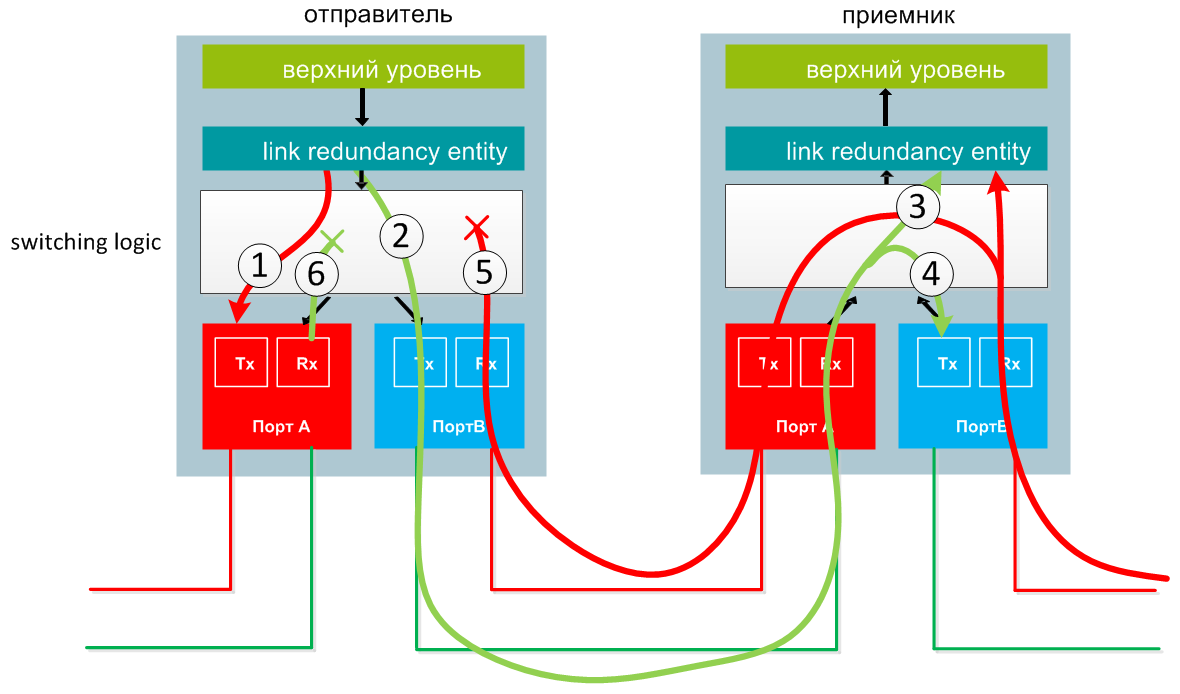
Transferring data between two DANs in PRP
A frame sent from the upper layer is duplicated by the LRE layer, and packets are sent through port A and port B almost simultaneously. (1 and 2 in the diagram).
Upon receipt of the frame, the receiver transfers it to the LRE level, and also redirects it to another port and passes it further in the ring. (3, 4).
If a frame arrives at the sender, then this frame is not transmitted further, but destroyed (5, 6).
Both frames arrive at the LRE level, but the one that was sent faster is transferred to the upper level, and the duplicated frame is discarded.
LRE adds a 48-bit HSR tag to each frame (akin to adding a VLAN tag) and deletes this tag upon receipt.
Transferring Data between Two DANs in an HSR
In PRP, a SAN can be connected to any network - LAN A or LAN B, but such a node does not support backup functions. Therefore, a SAN connected to one network cannot communicate with another similar node connected to a second network. To interact with SAN, DAN generates special frames. This need is due to the fact that the SAN in the normal frame from the redundant device must ignore the RCT, which is not possible, since the SAN cannot distinguish the RCT from the regular IEEE 802.3 data block. In turn, the DAN understands that it sends the frame to the SAN and does not add RCT to the frame. It simply forwards one frame from the top level to the interface to which the SAN is connected. In other words, if the DAN cannot determine what is exchanging data with another DAN, then it does not add RCT to the frame.
In HSR, a SAN cannot be connected directly to the network. It can be connected exclusively through RedBox.
When working with duplicate frames received on both interfaces (if they are serviceable), the DAN must accept one of the frames and discard the second one. There are two processing methods in PRP:
For HSR, consider the most popular U and X modes.
A DAN operating in this mode does not drop any of the frames when processing at the data link layer.
Frames are sent to LAN A and LAN B without RCT. The receiver’s LRE simply redirects both frames to the upper level, assuming that further transmission will destroy the duplicates (IEEE 802.1D clearly states that the upper level protocols must be able to handle duplicate frames).
For example, TCP and UDP have a high level of resilience to duplicate frames.
This method is very simple to implement, but has a serious drawback - it does not provide any network control capabilities, as the reception of both frames is not monitored in any way.
When using the second method, a field consisting of four octets is added to the frame - RCT (redundancy control trailer). A trailer is added at the LRE level when the frame is received from the top level. RCT consists of the following parameters:
Due to the addition of an RCT trailer to the frame, its size is larger than the maximum frame size defined in the IEEE 802.3-2005 standard. To transmit data within the network with PRP, the equipment must be configured to transmit data in the size of 1496 octets. Because of this, not every switch is suitable for use on LAN A or LAN B.

A frame with added RCT
Each time the link layer sends a frame to a specific address, the sender increases the sequence number for the corresponding node and sends identical frames through both interfaces .
The receiving node must determine duplicates based on information from the RCT.
The receiver assumes that frames sent from any source using the PRP protocol are sent sequentially with a constantly increasing number. The sequence number expected for the next frame is stored in the variables ExpectedSeqA and, accordingly, ExpectedSeqB.
Upon receipt, the correctness of the sequence can be checked by comparing the value of ExpectedSeqA (ExpectedSeqB) with the sequence number of the received frame, stored in the currentSeq variable in RCT. If the result is positive, the variable ExpectedSeq is set to one more than currentSeq so that it would be possible to carry out a correct check on this line.

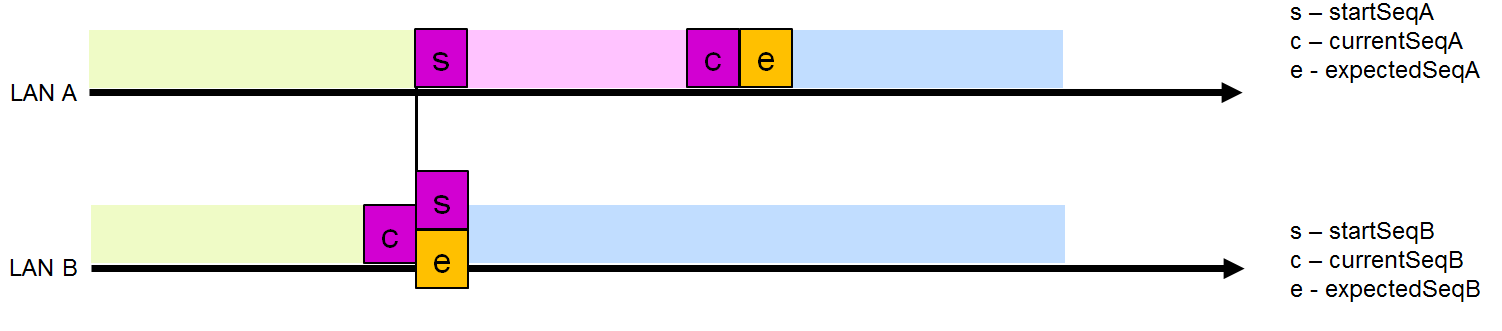
Frame Drop Interval (drop window)
For both interfaces, there is a dynamic frame drop interval for the paired sequence numbers. The upper bound of this interval is ExpectedSeq (the next expected sequence number on this interface), excluding the given value itself, and the lower bound of this interval is startSeq (the smallest sequence number at which the duplicated frame with this sequence number is discarded).
After checking the sequence number, the receiver decides to discard the frame or not. Assume that LAN A has a non-zero frame drop interval size (Fig. 5). A frame from LAN B whose number lies in this interval will be discarded. All other frames from LAN B will be accepted and sent to the upper level.
Dropping a frame from LAN B reduces the size of LAN A, because after receiving this frame, no frames with a lower number on this interface are expected. Accordingly, startSeqA is set to one more than currentSeqB. In this case, the size of the drop interval of the LAN B frame is reset to 0 (startSeqB = expectedSeqB), because Obviously, LAN B frames are “behind” LAN LAN and no frames from LAN A should be dropped.
Decrease LAN A interval after dropping frame from LAN B
In the situation in Fig. 7, when several frames from LAN A come in a row, but nothing comes from LAN B, they are accepted, because their currentSeq is outside the discard interval of the LAN B frame and the LAN A interval is increased by one position. If frames from LAN A continue to arrive, but nothing still comes from LAN B, when the maximum interval size is reached, startSeqA also starts to increase by one.
When the received frame is outside the discard interval of the frame of another LAN, then this frame is saved, and the interval size of this interface is set to 1, which means that only a frame from another LAN with the same sequence number will be discarded, while the drop window of the other interface is set to 0, which means that no frames will be dropped (Fig. 7).
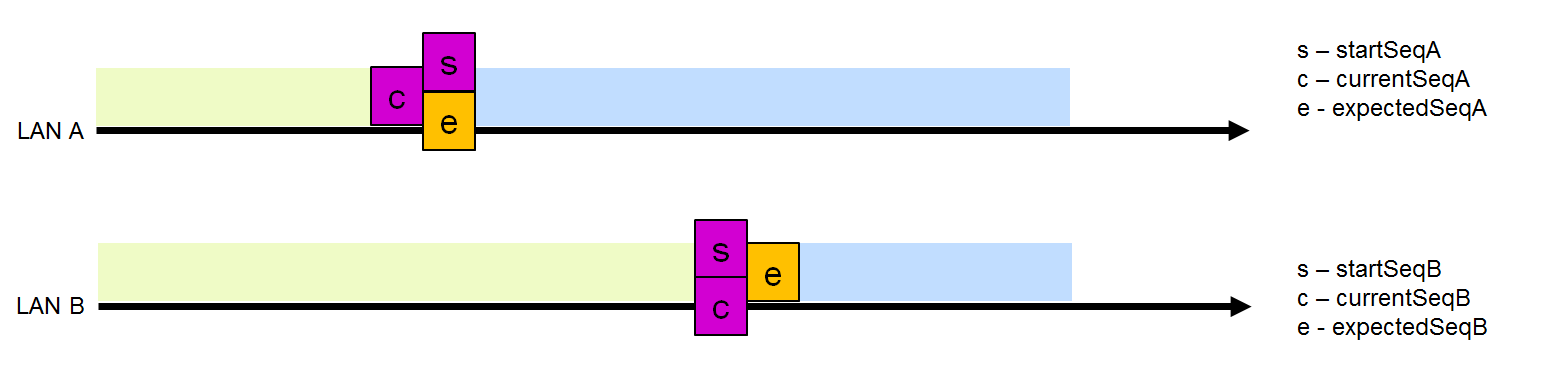
The frame from LAN B was not dropped.
The most common situation is when both interfaces are synchronized and the size of both intervals is 0 (Fig. 8), which means that the frame of the interface that comes first will be accepted and the interval of this interface will be increased to 1, which allows you to drop the frame from another interface with the same sequence number.

Synchronized LAN
Due to the presence of a LAN identifier in RCT, duplicate frames differ by one bit (and have different checksums). The receiver checks that the frame belongs to the interface (i.e., checks that the frame with LAN A identifier has arrived at interface A). The receiver will not drop this frame, as it may contain useful information in the data block, but in this case the counter cntWrongLanA or cntWrongLanB will be increased by one. Since such errors are not one-time (mixed up by LAN A and LAN B), the counter will increase constantly.
When transferring data within the HSR network, an HSR tag is added to each frame.
The HSR tag consists of the following parameters:
The sender inserts the same sequence numbers to the duplicate frames being sent, and then increments the sequence number for each message sent from this node.
The receiver monitors the sequence numbers of all frames from each source from which it receives data (it distinguishes sources by MAC address). If frames come from different lines and have the same source and sequence number, then one of them is accepted, and the second is discarded.
To control the network, each device maintains a table of all nodes in the network from which it receives data. This allows you to detect the disappearance of nodes and errors on the bus.
The node defines the frame that it sent by source and by sequence number.

Frame with added HSR tag
An HSR node never discards a frame that it has not previously received. The node defines almost all duplicated frames, but if there are few of them, it does not delete them, i.e. the frame just goes through the entire ring and is destroyed on the sender.
In the standard, the algorithm for determining duplicate frames is not defined. As possible methods, hash tables, queues, and sequence number tracking can be used.
In this mode, the node that receives the frame destroys the duplicate and does not allow it to propagate further. If the frame was nevertheless transferred further, then it is destroyed on the following nodes. This mode allows you to unload the ring from Unicast traffic.
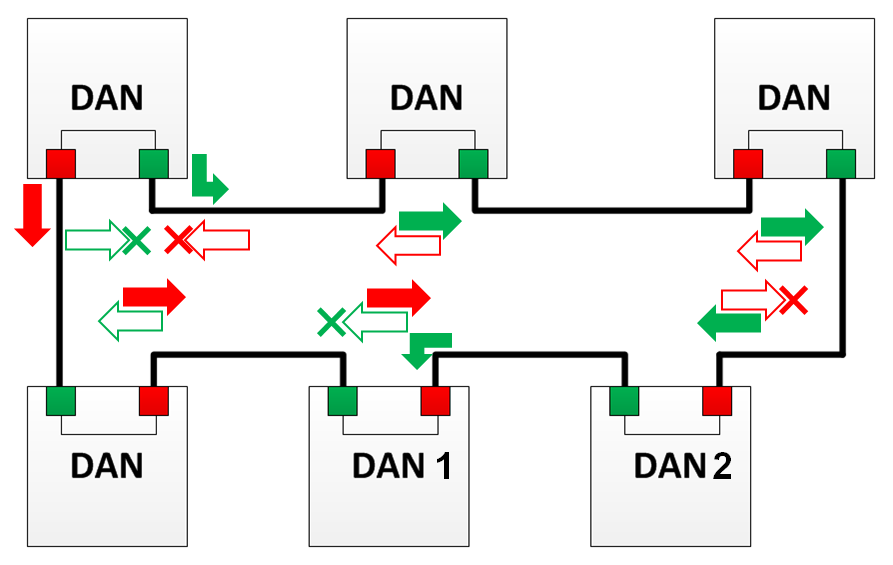
In the diagram, red arrows indicate packets with the HSR tag sent from port “A” (hereinafter - frame “A”).
Green arrows indicate packets with an HSR tag sent from port “B” (hereinafter - frame “B”).
Empty arrows indicate dropped traffic, i.e. frames that would be transmitted during normal operation, but in this mode were discarded.
The cross indicates the removal of traffic from the ring (in any case).
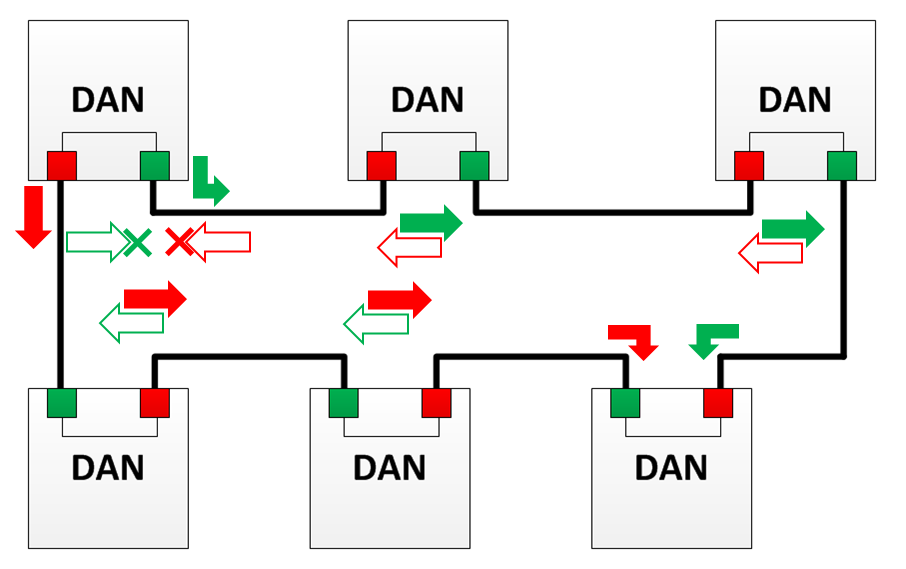
In this mode, the node does not forward the frame further and discards it if such a frame was received from another direction.
For example, DAN 1 in the image will not forward frame “B” further, because he has already received frame “A”, and DAN 2 will not transmit frame “A” further, because already received frame “B”.
In the event that an error occurred somewhere in the algorithm and the frames were transmitted further, they will be discarded on the following nodes or on the node on which they were created.
X mode is not applicable for PTP messages and for supervision frame transmission.
The receiver checks that all frames arrive sequentially and are correctly received on both channels. It supports error counters that can be read, for example, through SNMP.
All devices support node tables with which they exchange data. These tables contain information about the time when the last frame was sent or received from a particular node and other information regarding the PRP protocol.
At the same time, these tables make it possible to detect compounds in which it is necessary to synchronize sequence numbers, as well as to detect broken sequences and missing nodes.
Diagnostics is based on the fact that each DAN periodically sends a diagnostic frame (supervision frame), which allows you to check the integrity of the network and the presence of nodes. At the same time, these frames allow you to check which devices act as DANs, determine their MAC addresses and in what mode they work - duplicate accept or duplicate discard.
Each node constantly checks all links.
Each node periodically sends a diagnostic frame (to both ports) containing information about the state of the node. This frame is accepted by all nodes, including the sender. When the sender receives its own diagnostic message, a physical channel integrity check is performed.
The interval for sending a diagnostic frame is relatively large (a few seconds), because it is not required to provide redundancy, but is needed only for diagnostic purposes.
All nodes are entered into the table of all partners that were found, and the time is recorded when the node was last active, as well as all the missing frames and frames that were not sent sequentially.
All topology changes that have occurred are also logged and all information can be obtained via SNMP.
HSR and PRP: Pros and Cons
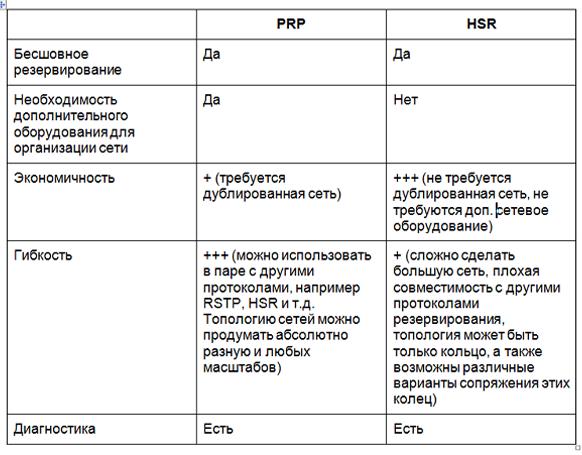
This is not to say that one protocol is better than another - they are designed a little for different applications. Both HSR and PRP allow seamless network redundancy, but HSR allows you to create more cost-effective solutions. But such profitability entails difficulties, because an HSR-based network is difficult to scale and applications are not very flexible. Low flexibility is caused by limited topology (ring, pairing of rings), as well as poor compatibility of the protocol with other technologies. Therefore, HSR is better suited for redundancy of small systems and integration into a large network. HSR-based backup of the entire network is problematic. PRP, in turn, is a more expensive solution, but allows you to organize a fairly large-scale network, which in the future can be expanded without problems, because
Find a solution
For example, in the energy sector, if the data from the measuring transducers does not reach the relay terminal on time, this can be fraught with the spread of a short circuit to adjacent sections of the power supply network, which will result in losses much more serious than in case of timely disconnection of the section from the short circuit. Therefore, often in energy projects you can meet the requirement "Recovery time less than 1 ms."
Network redundancy based on such industry-wide protocols as RSTP, MRP, DLR, and the like, is based on a change in topology in the event of any malfunction in data transmission. Changing the topology takes a certain time (from milliseconds to seconds, depending on the protocol), which is called the "recovery time". During this time, there is no communication with part of the network and, accordingly, data is lost. Those. conventional ring redundancy technologies do not allow recovery times of less than 1 ms.
In view of this, the so-called “seamless” redundancy technologies - PRP and HSR - are gaining popularity. Redundancy based on PRP and HSR is carried out, in contrast to the above protocols, not by rebuilding the topology, but by duplicating frames. Each frame is duplicated by the sender, and both frames are transmitted in different ways, and the receiving node processes the frame that came in first, and discards the second. This principle of operation does not require restructuring of the topology and, accordingly, this protocol operates almost “seamlessly”. Under the cut you will find details of the implementation of these protocols.
Network structure
Seamless redundancy is implemented on end nodes, not network components. This is one of the main differences between PRP and HSR from other backup protocols such as RSTP or MRP. Consider the features of the network structure for PRP and HSR.
PRP - network structure
The end node has two Ethernet interfaces that connect to two networks isolated from each other, operating in parallel and having an independent topology (i.e., the topologies of these two networks can be the same or different). The networks must be isolated so that any malfunction and stop of data transmission in one network do not affect the second, i.e. even network power is supplied from different sources. There should not be any direct connections between these networks.
PRP Network Structure
These two networks are usually called LAN A and LAN B. As previously indicated, they can have different topologies as well as different performance. Delays in data transmission may also vary.
The network may contain the following elements:
- DAN (Dual Attached Node) - a node that connects to both networks and sends / receives duplicate frames.
- SAN (Single Attached Node) - a node that connects to only one network (LAN A or LAN B) and sends / receives regular frames.
- In the case when it is necessary to redundantly connect a device that has one Ethernet interface and does not support PRP protocol to the RPR network, the so-called Redundancy Box (usually RedBox) is used. On RedBox, the packet from the device is duplicated and transmitted to the PRP network, as if the data were transmitted from the DAN. Moreover, the device behind RedBox is seen as a DAN for other devices. Such a node is called a virtual DAN or VDAN (Virtual DAN).
RedBox's working principle
HSR - network structure
HSR network structure
The principle of operation of HSR is that all devices are combined into a ring and all messages, as well as in PRP, are duplicated. The device sends both frames through the ring: one copy clockwise, the other counterclockwise. The receiver receives both copies, but processes only the first, and deletes the second. If something happens to one of the links, and one of the duplicated frames does not come, then the other is simply accepted. All HSR devices have two Ethernet interfaces - port A and port B.
According to the HSR protocol, the following elements can exist in a network:
- SAN is a node that has only one Ethernet interface. Such a node can be connected to the HSR network exclusively through RedBox.
- DAN - a node that can exchange data inside an HSR ring (can send / receive duplicate frames).
- RedBox - just like in PRP, RedBox allows you to connect a device that has one Ethernet interface to an HSR network. The device behind RedBox is seen as a DAN for other devices. Such a node is called a virtual DAN or VDAN (Virtual DAN).
- QuadBox - HSR also introduces one new element - QuadBox. This device has four HSR ports. It allows you to combine two HSR rings. In each ring, the QuadBox acts as a DAN and can transfer data from one ring to another.
QuadBox example
DAN structure
For PRP and for HSR, the DAN structure is similar. Each DAN has two interfaces operating in parallel and connected to the upper level of one communication stack through the so-called LRE layer - link redundancy entity. At this level, all backup functions are performed.
Both DAN interfaces have the same MAC address and one IP address. This allows you to make the reservation transparent to the top level. Especially important is the fact that this allows the use of ARP for DAN as well as for any non-redundant node.
However, of course, there are nuances in the DAN structure for PRP and for HSR.
PRP - DAN Structure
When a frame is sent from the top level, the LRE duplicates it and sends both packets through the ports almost simultaneously. Both frames are transmitted in parallel through two networks with different delays. In an ideal situation, they are delivered to the destination node with a minimum time difference. Upon receipt of the LRE, the receiver sends the first received frame to the upper layer, and discards the second one.
LRE creates duplicate frames upon sending and processes them upon receipt. This level, in relation to the upper level, represents the usual interface of a non-redundant network adapter. LRE performs two tasks: handling duplicate frames and managing redundancy. To implement control, LRE adds a 32-bit redundancy control trailer (RCT) to each frame and deletes it when the frame is received.
Transferring data between two DANs in PRP
HSR - DAN Structure
A frame sent from the upper layer is duplicated by the LRE layer, and packets are sent through port A and port B almost simultaneously. (1 and 2 in the diagram).
Upon receipt of the frame, the receiver transfers it to the LRE level, and also redirects it to another port and passes it further in the ring. (3, 4).
If a frame arrives at the sender, then this frame is not transmitted further, but destroyed (5, 6).
Both frames arrive at the LRE level, but the one that was sent faster is transferred to the upper level, and the duplicated frame is discarded.
LRE adds a 48-bit HSR tag to each frame (akin to adding a VLAN tag) and deletes this tag upon receipt.
Transferring Data between Two DANs in an HSR
Interoperability between SAN and DAN
In PRP, a SAN can be connected to any network - LAN A or LAN B, but such a node does not support backup functions. Therefore, a SAN connected to one network cannot communicate with another similar node connected to a second network. To interact with SAN, DAN generates special frames. This need is due to the fact that the SAN in the normal frame from the redundant device must ignore the RCT, which is not possible, since the SAN cannot distinguish the RCT from the regular IEEE 802.3 data block. In turn, the DAN understands that it sends the frame to the SAN and does not add RCT to the frame. It simply forwards one frame from the top level to the interface to which the SAN is connected. In other words, if the DAN cannot determine what is exchanging data with another DAN, then it does not add RCT to the frame.
In HSR, a SAN cannot be connected directly to the network. It can be connected exclusively through RedBox.
DAN Modes
When working with duplicate frames received on both interfaces (if they are serviceable), the DAN must accept one of the frames and discard the second one. There are two processing methods in PRP:
- Duplicate accept is a method in which both incoming frames are received and redirected to the upper level.
- Duplicate discard - a method in which the receiving node reads information from the RCT of the incoming frame in order to determine which frame to discard.
For HSR, consider the most popular U and X modes.
Duplicate accept
A DAN operating in this mode does not drop any of the frames when processing at the data link layer.
Frames are sent to LAN A and LAN B without RCT. The receiver’s LRE simply redirects both frames to the upper level, assuming that further transmission will destroy the duplicates (IEEE 802.1D clearly states that the upper level protocols must be able to handle duplicate frames).
For example, TCP and UDP have a high level of resilience to duplicate frames.
This method is very simple to implement, but has a serious drawback - it does not provide any network control capabilities, as the reception of both frames is not monitored in any way.
Duplicate discard at the channel level
When using the second method, a field consisting of four octets is added to the frame - RCT (redundancy control trailer). A trailer is added at the LRE level when the frame is received from the top level. RCT consists of the following parameters:
- 16-bit sequence number;
- 4-bit network identifier, 1010 (0xA) for LAN A and 1011 (0xB) for LAN B;
- 12-bit frame size.
Due to the addition of an RCT trailer to the frame, its size is larger than the maximum frame size defined in the IEEE 802.3-2005 standard. To transmit data within the network with PRP, the equipment must be configured to transmit data in the size of 1496 octets. Because of this, not every switch is suitable for use on LAN A or LAN B.
A frame with added RCT
Each time the link layer sends a frame to a specific address, the sender increases the sequence number for the corresponding node and sends identical frames through both interfaces .
The receiving node must determine duplicates based on information from the RCT.
Duplicate discard Method Algorithm
The receiver assumes that frames sent from any source using the PRP protocol are sent sequentially with a constantly increasing number. The sequence number expected for the next frame is stored in the variables ExpectedSeqA and, accordingly, ExpectedSeqB.
Upon receipt, the correctness of the sequence can be checked by comparing the value of ExpectedSeqA (ExpectedSeqB) with the sequence number of the received frame, stored in the currentSeq variable in RCT. If the result is positive, the variable ExpectedSeq is set to one more than currentSeq so that it would be possible to carry out a correct check on this line.
Frame Drop Interval (drop window)
For both interfaces, there is a dynamic frame drop interval for the paired sequence numbers. The upper bound of this interval is ExpectedSeq (the next expected sequence number on this interface), excluding the given value itself, and the lower bound of this interval is startSeq (the smallest sequence number at which the duplicated frame with this sequence number is discarded).
After checking the sequence number, the receiver decides to discard the frame or not. Assume that LAN A has a non-zero frame drop interval size (Fig. 5). A frame from LAN B whose number lies in this interval will be discarded. All other frames from LAN B will be accepted and sent to the upper level.
Dropping a frame from LAN B reduces the size of LAN A, because after receiving this frame, no frames with a lower number on this interface are expected. Accordingly, startSeqA is set to one more than currentSeqB. In this case, the size of the drop interval of the LAN B frame is reset to 0 (startSeqB = expectedSeqB), because Obviously, LAN B frames are “behind” LAN LAN and no frames from LAN A should be dropped.
Decrease LAN A interval after dropping frame from LAN B
In the situation in Fig. 7, when several frames from LAN A come in a row, but nothing comes from LAN B, they are accepted, because their currentSeq is outside the discard interval of the LAN B frame and the LAN A interval is increased by one position. If frames from LAN A continue to arrive, but nothing still comes from LAN B, when the maximum interval size is reached, startSeqA also starts to increase by one.
When the received frame is outside the discard interval of the frame of another LAN, then this frame is saved, and the interval size of this interface is set to 1, which means that only a frame from another LAN with the same sequence number will be discarded, while the drop window of the other interface is set to 0, which means that no frames will be dropped (Fig. 7).
The frame from LAN B was not dropped.
The most common situation is when both interfaces are synchronized and the size of both intervals is 0 (Fig. 8), which means that the frame of the interface that comes first will be accepted and the interval of this interface will be increased to 1, which allows you to drop the frame from another interface with the same sequence number.
Synchronized LAN
Due to the presence of a LAN identifier in RCT, duplicate frames differ by one bit (and have different checksums). The receiver checks that the frame belongs to the interface (i.e., checks that the frame with LAN A identifier has arrived at interface A). The receiver will not drop this frame, as it may contain useful information in the data block, but in this case the counter cntWrongLanA or cntWrongLanB will be increased by one. Since such errors are not one-time (mixed up by LAN A and LAN B), the counter will increase constantly.
Link HSR traffic
When transferring data within the HSR network, an HSR tag is added to each frame.
The HSR tag consists of the following parameters:
- 16-bit HSR Ethertype
- 4-bit path indicator
- 12-bit frame size
- 16 bit sequence number
The sender inserts the same sequence numbers to the duplicate frames being sent, and then increments the sequence number for each message sent from this node.
The receiver monitors the sequence numbers of all frames from each source from which it receives data (it distinguishes sources by MAC address). If frames come from different lines and have the same source and sequence number, then one of them is accepted, and the second is discarded.
To control the network, each device maintains a table of all nodes in the network from which it receives data. This allows you to detect the disappearance of nodes and errors on the bus.
The node defines the frame that it sent by source and by sequence number.
Frame with added HSR tag
An HSR node never discards a frame that it has not previously received. The node defines almost all duplicated frames, but if there are few of them, it does not delete them, i.e. the frame just goes through the entire ring and is destroyed on the sender.
In the standard, the algorithm for determining duplicate frames is not defined. As possible methods, hash tables, queues, and sequence number tracking can be used.
U mode
In this mode, the node that receives the frame destroys the duplicate and does not allow it to propagate further. If the frame was nevertheless transferred further, then it is destroyed on the following nodes. This mode allows you to unload the ring from Unicast traffic.
In the diagram, red arrows indicate packets with the HSR tag sent from port “A” (hereinafter - frame “A”).
Green arrows indicate packets with an HSR tag sent from port “B” (hereinafter - frame “B”).
Empty arrows indicate dropped traffic, i.e. frames that would be transmitted during normal operation, but in this mode were discarded.
The cross indicates the removal of traffic from the ring (in any case).
X mode
In this mode, the node does not forward the frame further and discards it if such a frame was received from another direction.
For example, DAN 1 in the image will not forward frame “B” further, because he has already received frame “A”, and DAN 2 will not transmit frame “A” further, because already received frame “B”.
In the event that an error occurred somewhere in the algorithm and the frames were transmitted further, they will be discarded on the following nodes or on the node on which they were created.
X mode is not applicable for PTP messages and for supervision frame transmission.
Network control
PRP
The receiver checks that all frames arrive sequentially and are correctly received on both channels. It supports error counters that can be read, for example, through SNMP.
All devices support node tables with which they exchange data. These tables contain information about the time when the last frame was sent or received from a particular node and other information regarding the PRP protocol.
At the same time, these tables make it possible to detect compounds in which it is necessary to synchronize sequence numbers, as well as to detect broken sequences and missing nodes.
Diagnostics is based on the fact that each DAN periodically sends a diagnostic frame (supervision frame), which allows you to check the integrity of the network and the presence of nodes. At the same time, these frames allow you to check which devices act as DANs, determine their MAC addresses and in what mode they work - duplicate accept or duplicate discard.
Hsr
Each node constantly checks all links.
Each node periodically sends a diagnostic frame (to both ports) containing information about the state of the node. This frame is accepted by all nodes, including the sender. When the sender receives its own diagnostic message, a physical channel integrity check is performed.
The interval for sending a diagnostic frame is relatively large (a few seconds), because it is not required to provide redundancy, but is needed only for diagnostic purposes.
All nodes are entered into the table of all partners that were found, and the time is recorded when the node was last active, as well as all the missing frames and frames that were not sent sequentially.
All topology changes that have occurred are also logged and all information can be obtained via SNMP.
HSR and PRP: Pros and Cons
Conclusion
This is not to say that one protocol is better than another - they are designed a little for different applications. Both HSR and PRP allow seamless network redundancy, but HSR allows you to create more cost-effective solutions. But such profitability entails difficulties, because an HSR-based network is difficult to scale and applications are not very flexible. Low flexibility is caused by limited topology (ring, pairing of rings), as well as poor compatibility of the protocol with other technologies. Therefore, HSR is better suited for redundancy of small systems and integration into a large network. HSR-based backup of the entire network is problematic. PRP, in turn, is a more expensive solution, but allows you to organize a fairly large-scale network, which in the future can be expanded without problems, because
Find a solution