Implement static analysis in the process, but do not look for bugs with it
Write this article I was inspired by a large number of materials about static analysis, more and more often caught the eye. Firstly, this is the PVS-studio blog , which actively promotes itself in Habré with the help of reviews of errors found by their tool in open source projects. Recently, PVS-studio implemented Java support , and, of course, the developers of IntelliJ IDEA, whose embedded analyzer is probably the most advanced for Java today, could not stand aside .
When reading such reviews, there is a feeling that we are talking about a magic elixir: click on the button, and here it is - a list of defects before your eyes. It seems that as the analyzers improve, bugs will automatically be found more and more, and the products scanned by these robots will get better and better, without any efforts on our part.
But magic elixirs does not happen. I would like to talk about what people usually don’t say in posts like “these are the things our robot can find”: what analyzers cannot, what is their real role and place in the software delivery process, and how to implement them correctly.
Ratchet (source: Wikipedia ).
What is, from a practical point of view, source code analysis? We feed some sources to the input, and at the output in a short time (much shorter than the test run) we get some information about our system. The principal and mathematically insurmountable limitation is that in this way we can only get a fairly narrow class of information.
The most famous example of a problem that cannot be solved using static analysis is the stopping problem : this is a theorem that proves that it is impossible to develop a general algorithm that would determine from the source code of a program whether it will loop or complete in a finite time. An extension of this theorem is the Rice theorem, asserting, for any nontrivial property of computable functions, determining whether an arbitrary program computes a function with such a property is an algorithmically unsolvable problem. For example, it is impossible to write an analyzer that, for any source code, determines whether the program being analyzed is an implementation of an algorithm that calculates, say, squaring an integer.
Thus, the functionality of static analyzers has insurmountable limitations. A static analyzer will never be able to determine such things as, for example, the occurrence of a “null pointer exception” in languages that admit the value null, or in all cases to determine the occurrence of “attribute not found” in languages with dynamic typing. All that the most advanced static analyzer can do is to single out particular cases, the number of which is, without exaggeration, a drop in the ocean among all possible problems with your source code.
From the above, the conclusion follows: static analysis is not a means of reducing the number of defects in a program. I would venture to say: being first applied to your project, it will find “amusing” places in the code, but most likely it will not find any defects that affect the quality of your program’s work.
Examples of defects automatically found by analyzers are impressive, but one should not forget that these examples were found by scanning a large set of large code bases. By the same principle, hackers who have the ability to bust a few simple passwords on a large number of accounts, eventually find those accounts that have a simple password.
Does this mean that static analysis should not be used? Of course not! And for exactly the same reason that it is worth checking every new password for hit on the stop list of “simple” passwords.
In fact, the problems practically solved by analysis are much wider. Indeed, in general, static analysis is any verification of sources, carried out before their launch. Here are some things you can do:
As you can see, the search for bugs in this list takes the least important role, and everything else is available by using free open source tools.
Which of these types of static analysis should be used in your project? Of course, everything, the more - the better! The main thing is to implement it correctly, which will be discussed further.
The classic metaphor of continuous integration is the pipeline (pipeline) through which changes occur - from changing the source code to delivery to production. The standard sequence of steps for this pipeline looks like this:
Changes rejected on the Nth stage of the pipeline are not transferred to the stage N + 1.
Why so, and not otherwise? In the part of the pipeline that concerns testing, testers will recognize the well-known testing pyramid.

Test pyramid. Source: Martin Fowler article .
At the bottom of this pyramid are tests that are easier to write, which are faster and do not have a tendency to false positives. Therefore there should be more of them, they should cover more code and be executed first. At the top of the pyramid, everything is the other way around, so the number of integration and UI tests should be reduced to the required minimum. The person in this chain is the most expensive, slow and unreliable resource, so he is at the very end and does the work only if the previous steps did not detect any defects. However, the same principles are used to build a conveyor in parts not directly related to testing!
I would like to offer an analogy in the form of a multi-stage water filtration system. Dirty water is supplied to the inlet (changes with defects), we have to get clean water at the outlet, all unwanted impurities are screened out.

Multistage filter. Source: Wikimedia Commons
As you know, cleaning filters are designed so that each subsequent cascade can filter out an ever smaller fraction of contaminants. At the same time, the cascades of coarser cleaning have a greater throughput and lower cost. In our analogy, this means that the input quality gates are more responsive, require less effort to run and are in themselves more unpretentious in their work - and it is in this sequence that they are built. The role of static analysis, which, as we now understand, is able to screen out only the roughest defects - this is the role of the “dirt trap” grid at the very beginning of the filter cascade.
Static analysis by itself does not improve the quality of the final product, as a “mud tank” does not make drinking water. Nevertheless, in common with other elements of the pipeline, its importance is obvious. Although in a multistage filter, the output stages are potentially capable of catching everything the same as the input ones - it is clear what consequences the attempt to do with fine cleaning stages alone, without input stages, will lead to.
The purpose of the "gryazevika" is to unload the subsequent cascades from trapping absolutely gross defects. For example, at a minimum, a person doing a code review should not be distracted by incorrectly formatted code and violation of established coding standards (such as extra brackets or too deeply nested branches). Bugs like NPE should be captured by unit tests, but if even before the test, the analyzer indicates that the bug should inevitably occur, this will significantly speed up its correction.
I suppose it is now clear why static analysis does not improve the quality of the product, if it is applied sporadically, and should be applied constantly to screen out changes with gross defects. The question whether the use of a static analyzer will improve the quality of your product is roughly equivalent to the question “will the drinking qualities of water taken from a dirty water reservoir improve if it is passed through a colander?”
An important practical question: how to implement static analysis in the process of continuous integration as a “quality gate”? In the case of automatic tests, everything is obvious: there is a set of tests, the fall of any one of them is sufficient reason to believe that the build did not pass the quality gate. Attempting to set the gate in the same way by the results of static analysis fails: there are too many analysis warnings on the legacy code, I don’t want to completely ignore them, but it is impossible to stop the product delivery only because it contains analyzer warnings.
Being used for the first time, on any project, the analyzer generates a huge number of warnings, the vast majority of which are not related to the correct functioning of the product. It is impossible to correct all these comments at once, and many are not necessary. In the end, we know that our product as a whole works, and before the introduction of static analysis!
As a result, many are limited to occasional use of static analysis, or use it only in the information mode, when the assembly simply produces a report analyzer. This is equivalent to the absence of any analysis, because if we already have a lot of warnings, the occurrence of one more (however serious) when changing the code remains unnoticed.
The following methods are known for introducing quality gates:
It works this way:
So little by little, but steadily (as when working with a ratchet), the number of warnings will tend to zero. Of course, the system can be deceived by making a new warning, but by correcting someone else’s. This is normal, because in the long run it gives the result: warnings are corrected, as a rule, not one by one, but immediately by a group of a certain type, and all easily eliminated warnings are quickly eliminated.
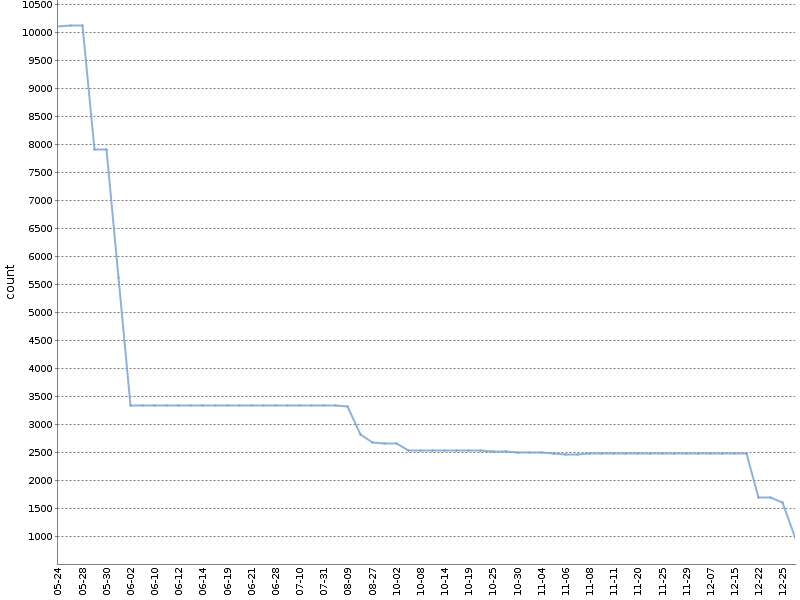
This graph shows the total number of Checkstyle warnings for the six months of work of such a "ratchet" on one of our OpenSource projects . The number of warnings has decreased by an order of magnitude, and this happened naturally, in parallel with the development of the product!
I apply a modified version of this method, separately counting warnings broken down by project modules and analysis tools, and the resulting YAML file with the metadata about the assembly looks something like this:
In any advanced CI-system "ratchet" can be implemented for any static analysis tools, without relying on plug-ins and third-party tools. Each analyzer produces its report in a simple text or XML format, which is easily amenable to analysis. It remains to register only the necessary logic in the CI script. You can see how it is implemented in our open source projects based on Jenkins and Artifactory, here or here . Both examples depend on the ratchetlib library : the method
An interesting version of the implementation of the "ratchet" is possible to analyze the spelling of comments, text literals and documentation using aspell. As you know, when checking spelling, not all unknown words to the standard dictionary are incorrect, they can be added to the user dictionary. If you make a user dictionary part of the project's source code, then the spelling quality gate can be formulated in the following way: running aspell with a standard and user dictionary should not find any spelling errors.
In conclusion, the following should be noted: no matter how you implement the analysis in your delivery pipeline, the analyzer version must be fixed. If we allow a spontaneous update of the analyzer, then when assembling the next pull request, new defects may emerge that are not related to the code change, but due to the fact that the new analyzer is just able to find more defects - and this will break your acceptance request request process. . An analyzer upgrade should be a conscious action. However, rigid fixation of the version of each component of the assembly is generally a necessary requirement and a topic for a separate conversation.
When reading such reviews, there is a feeling that we are talking about a magic elixir: click on the button, and here it is - a list of defects before your eyes. It seems that as the analyzers improve, bugs will automatically be found more and more, and the products scanned by these robots will get better and better, without any efforts on our part.
But magic elixirs does not happen. I would like to talk about what people usually don’t say in posts like “these are the things our robot can find”: what analyzers cannot, what is their real role and place in the software delivery process, and how to implement them correctly.
Ratchet (source: Wikipedia ).
{kind=link}
What static analyzers can never do
What is, from a practical point of view, source code analysis? We feed some sources to the input, and at the output in a short time (much shorter than the test run) we get some information about our system. The principal and mathematically insurmountable limitation is that in this way we can only get a fairly narrow class of information.
The most famous example of a problem that cannot be solved using static analysis is the stopping problem : this is a theorem that proves that it is impossible to develop a general algorithm that would determine from the source code of a program whether it will loop or complete in a finite time. An extension of this theorem is the Rice theorem, asserting, for any nontrivial property of computable functions, determining whether an arbitrary program computes a function with such a property is an algorithmically unsolvable problem. For example, it is impossible to write an analyzer that, for any source code, determines whether the program being analyzed is an implementation of an algorithm that calculates, say, squaring an integer.
Thus, the functionality of static analyzers has insurmountable limitations. A static analyzer will never be able to determine such things as, for example, the occurrence of a “null pointer exception” in languages that admit the value null, or in all cases to determine the occurrence of “attribute not found” in languages with dynamic typing. All that the most advanced static analyzer can do is to single out particular cases, the number of which is, without exaggeration, a drop in the ocean among all possible problems with your source code.
Static analysis is not a bug search.
From the above, the conclusion follows: static analysis is not a means of reducing the number of defects in a program. I would venture to say: being first applied to your project, it will find “amusing” places in the code, but most likely it will not find any defects that affect the quality of your program’s work.
Examples of defects automatically found by analyzers are impressive, but one should not forget that these examples were found by scanning a large set of large code bases. By the same principle, hackers who have the ability to bust a few simple passwords on a large number of accounts, eventually find those accounts that have a simple password.
Does this mean that static analysis should not be used? Of course not! And for exactly the same reason that it is worth checking every new password for hit on the stop list of “simple” passwords.
Static analysis is more than bug searching.
In fact, the problems practically solved by analysis are much wider. Indeed, in general, static analysis is any verification of sources, carried out before their launch. Here are some things you can do:
- Check coding style in the broad sense of the word. This includes checking formatting as well as searching for the use of empty / extra brackets, setting threshold values for metrics like the number of lines / cyclomatic complexity of the method, etc., all that potentially makes the code more readable and maintainable. In Java, such a tool is Checkstyle, in Python - flake8. Programs of this class are usually called "linter".
- Not only executable code can be analyzed. Resource files such as JSON, YAML, XML, .properties can (and should!) Be automatically checked for validity. After all, it is better to learn that because of any unmatched quotes, the JSON structure is broken at the early stage of the automatic Pull Request check than during the execution of tests or at Run time? Corresponding tools are available: for example, YAMLlint , JSONLint .
- Compiling (or parsing for dynamic programming languages) is also a kind of static analysis. As a rule, compilers are capable of issuing warnings that signal problems with the quality of the source code, and should not be ignored.
- Sometimes compiling is not only compiling executable code. For example, if you have documentation in the AsciiDoctor format , then at the time of turning it into HTML / PDF, the AsciiDoctor ( Maven plugin ) handler may issue warnings, for example, about broken internal links. And this is a significant reason not to accept the Pull Request with documentation changes.
- Spell checker is also a kind of static analysis. The aspell utility is able to check spelling not only in documentation, but also in source codes of programs (comments and literals) in various programming languages, including C / C ++, Java, and Python. A spelling error in the user interface or documentation is also a defect!
- Configuration tests (about what it is - see this and this report), although they are performed in the execution environment of unit tests like pytest, are in fact also a type of static analysis, since they do not execute the source codes during their execution .
As you can see, the search for bugs in this list takes the least important role, and everything else is available by using free open source tools.
Which of these types of static analysis should be used in your project? Of course, everything, the more - the better! The main thing is to implement it correctly, which will be discussed further.
Supply pipeline as a multistage filter and static analysis as its first stage
The classic metaphor of continuous integration is the pipeline (pipeline) through which changes occur - from changing the source code to delivery to production. The standard sequence of steps for this pipeline looks like this:
- static analysis
- compilation
- unit tests
- integration tests
- UI tests
- manual check
Changes rejected on the Nth stage of the pipeline are not transferred to the stage N + 1.
Why so, and not otherwise? In the part of the pipeline that concerns testing, testers will recognize the well-known testing pyramid.
Test pyramid. Source: Martin Fowler article .
At the bottom of this pyramid are tests that are easier to write, which are faster and do not have a tendency to false positives. Therefore there should be more of them, they should cover more code and be executed first. At the top of the pyramid, everything is the other way around, so the number of integration and UI tests should be reduced to the required minimum. The person in this chain is the most expensive, slow and unreliable resource, so he is at the very end and does the work only if the previous steps did not detect any defects. However, the same principles are used to build a conveyor in parts not directly related to testing!
I would like to offer an analogy in the form of a multi-stage water filtration system. Dirty water is supplied to the inlet (changes with defects), we have to get clean water at the outlet, all unwanted impurities are screened out.
Multistage filter. Source: Wikimedia Commons
{kind=link}
As you know, cleaning filters are designed so that each subsequent cascade can filter out an ever smaller fraction of contaminants. At the same time, the cascades of coarser cleaning have a greater throughput and lower cost. In our analogy, this means that the input quality gates are more responsive, require less effort to run and are in themselves more unpretentious in their work - and it is in this sequence that they are built. The role of static analysis, which, as we now understand, is able to screen out only the roughest defects - this is the role of the “dirt trap” grid at the very beginning of the filter cascade.
Static analysis by itself does not improve the quality of the final product, as a “mud tank” does not make drinking water. Nevertheless, in common with other elements of the pipeline, its importance is obvious. Although in a multistage filter, the output stages are potentially capable of catching everything the same as the input ones - it is clear what consequences the attempt to do with fine cleaning stages alone, without input stages, will lead to.
The purpose of the "gryazevika" is to unload the subsequent cascades from trapping absolutely gross defects. For example, at a minimum, a person doing a code review should not be distracted by incorrectly formatted code and violation of established coding standards (such as extra brackets or too deeply nested branches). Bugs like NPE should be captured by unit tests, but if even before the test, the analyzer indicates that the bug should inevitably occur, this will significantly speed up its correction.
I suppose it is now clear why static analysis does not improve the quality of the product, if it is applied sporadically, and should be applied constantly to screen out changes with gross defects. The question whether the use of a static analyzer will improve the quality of your product is roughly equivalent to the question “will the drinking qualities of water taken from a dirty water reservoir improve if it is passed through a colander?”
Introduction to the legacy project
An important practical question: how to implement static analysis in the process of continuous integration as a “quality gate”? In the case of automatic tests, everything is obvious: there is a set of tests, the fall of any one of them is sufficient reason to believe that the build did not pass the quality gate. Attempting to set the gate in the same way by the results of static analysis fails: there are too many analysis warnings on the legacy code, I don’t want to completely ignore them, but it is impossible to stop the product delivery only because it contains analyzer warnings.
Being used for the first time, on any project, the analyzer generates a huge number of warnings, the vast majority of which are not related to the correct functioning of the product. It is impossible to correct all these comments at once, and many are not necessary. In the end, we know that our product as a whole works, and before the introduction of static analysis!
As a result, many are limited to occasional use of static analysis, or use it only in the information mode, when the assembly simply produces a report analyzer. This is equivalent to the absence of any analysis, because if we already have a lot of warnings, the occurrence of one more (however serious) when changing the code remains unnoticed.
The following methods are known for introducing quality gates:
- Set a limit for the total number of warnings or the number of warnings divided by the number of lines of code. It works badly, since such a gate freely misses changes with new defects until their limit is exceeded.
- Fixing, at a certain point, all the old warnings in the code as ignored, and failure to build when new warnings occur. This functionality is provided by PVS-studio and some online resources, for example, Codacy. I did not have a chance to work in PVS-studio, as for my experience with Codacy, their main problem is that the definition of what is “old” and what is “new” error is a rather complicated and not always correctly working algorithm, especially if files are greatly modified or renamed. In my memory, Codacy could miss new warnings in a pull request, and at the same time not miss a pull request due to warnings not related to changes in the code of this PR.
- In my opinion, the most effective solution is the “ratcheting method” described in the book Continuous Delivery . The basic idea is that the property of each release is the number of static analysis warnings, and only changes are allowed that do not increase the total number of warnings.
Ratchet
It works this way:
- At the initial stage, an entry is made in the metadata about the release of the number of warnings in the code found by the analyzers. Thus, when building the main branch into your repository manager, not just “release 7.0.2” is recorded, but “release 7.0.2 containing 100500 Checkstyle warnings”. If you use an advanced repository manager (such as Artifactory), saving such metadata about your release is easy.
- Now each pull request compares the number of the resulting warnings to the number of warnings in the current release. If PR leads to an increase in this number, then the code does not pass the quality gate by static analysis. If the number of warnings decreases or does not change, then it passes.
- With the next release, the recalculated number of warnings will be re-recorded in the release metadata.
So little by little, but steadily (as when working with a ratchet), the number of warnings will tend to zero. Of course, the system can be deceived by making a new warning, but by correcting someone else’s. This is normal, because in the long run it gives the result: warnings are corrected, as a rule, not one by one, but immediately by a group of a certain type, and all easily eliminated warnings are quickly eliminated.
This graph shows the total number of Checkstyle warnings for the six months of work of such a "ratchet" on one of our OpenSource projects . The number of warnings has decreased by an order of magnitude, and this happened naturally, in parallel with the development of the product!
I apply a modified version of this method, separately counting warnings broken down by project modules and analysis tools, and the resulting YAML file with the metadata about the assembly looks something like this:
celesta-sql:
checkstyle: 434
spotbugs: 45
celesta-core:
checkstyle: 206
spotbugs: 13
celesta-maven-plugin:
checkstyle: 19
spotbugs: 0
celesta-unit:
checkstyle: 0
spotbugs: 0
In any advanced CI-system "ratchet" can be implemented for any static analysis tools, without relying on plug-ins and third-party tools. Each analyzer produces its report in a simple text or XML format, which is easily amenable to analysis. It remains to register only the necessary logic in the CI script. You can see how it is implemented in our open source projects based on Jenkins and Artifactory, here or here . Both examples depend on the ratchetlib library : the method
countWarnings()normally calculates xml tags in files generated by Checkstyle and Spotbugs, and compareWarningMaps()implements the same ratchet, throwing an error when the number of warnings in any of the categories rises.An interesting version of the implementation of the "ratchet" is possible to analyze the spelling of comments, text literals and documentation using aspell. As you know, when checking spelling, not all unknown words to the standard dictionary are incorrect, they can be added to the user dictionary. If you make a user dictionary part of the project's source code, then the spelling quality gate can be formulated in the following way: running aspell with a standard and user dictionary should not find any spelling errors.
On the importance of fixing the analyzer version
In conclusion, the following should be noted: no matter how you implement the analysis in your delivery pipeline, the analyzer version must be fixed. If we allow a spontaneous update of the analyzer, then when assembling the next pull request, new defects may emerge that are not related to the code change, but due to the fact that the new analyzer is just able to find more defects - and this will break your acceptance request request process. . An analyzer upgrade should be a conscious action. However, rigid fixation of the version of each component of the assembly is generally a necessary requirement and a topic for a separate conversation.
findings
- Static analysis will not find you bugs and will not improve the quality of your product as a result of a single use. The only positive effect on quality is its constant use in the delivery process.
- Search bugs in general is not the main task of the analysis, the vast majority of useful features available in the opensource tools.
- Implement quality gates based on the results of static analysis at the very first stage of the delivery pipeline, using a ratchet for legacy code.
Links
- Continuous delivery
- A. Kudryavtsev: Program Analysis: How to Understand You're a Good Programmer Report on Different Methods of Code Analysis (Not Just Static!)