Organization of distributed disk storage with the possibility of unlimited expansion using LVM and ATAoE technologies
Task
When the disks were small and the Internet was large, the owners of private FTP-servers faced the following problem:
A Video or Soft folder was created on each hard disk, and it turned out that adding a new hard disk made Video2, Soft2, etc.
The task of changing the hard disk to a larger disk led to the fact that the data needed to be transferred somewhere, all this happened non-trivially and with large downtimes.
The system we developed in 2005 made it possible to assemble a reliable and fast array of 3 terabytes, scalable, expandable, online, adding disks or entire servers with disks.
The price of the whole solution was 110% of the cost of the disks themselves, i.e. essentially free with little overhead.
Here is a sample device diagram of our storage:

Implementation
The idea is this: there is a supervisor and there are nodes. Supervisor is a public server that clients visit, it has several gigabit bonding interfaces outward, and several inward, to our nodes. The supervisor takes the arrays or individual disks exported using vblade via ATAoE, makes LVM on top of them and makes this section accessible via FTP. The supervisor is also a diskless download server for nodes, and it also contains the entire file system of nodes, with which they communicate via NFS after loading. Nodes are pure disks, boot via PXE, then our etherpopulate starts, and all disks are exported.
1. Setting for remote node loading
the node device is the kernel, the node directory is rootfs, the configs for pxe will all be available on the nodes config for pxe, the nfsroot dhcpd config is specified , do not forget to start it. tftpd config running tftpd? config for nfs, do not forget to run. The configuration for the remote boot is completed, all the nodes are registered.
ftp # ls /diskless/
bzImage node pxelinux.0 pxelinux.cfgftp # ls /diskless/node/
bin boot dev etc lib mnt proc root sbin sys tmp usr var
ftp # chroot /diskless/node/
ftp / # which vblade
/usr/sbin/vblade
ftp / # vblade
usage: vblade [ -m mac[,mac...] ] shelf slot netif filename
ftp / #ftp node # cat /diskless/pxelinux.cfg/default
DEFAULT /bzImage
APPEND ip=dhcp root=/dev/nfs nfsroot=172.18.0.193:/diskless/node idebus=66ftp etc # more dhcp/dhcpd.conf
option domain-name "domain.com";
default-lease-time 600;
max-lease-time 7200;
ddns-update-style none;
option space PXE;
option PXE.mtftp-ip code 1 = ip-address;
option PXE.mtftp-cport code 2 = unsigned integer 16;
option PXE.mtftp-sport code 3 = unsigned integer 16;
option PXE.mtftp-tmout code 4 = unsigned integer 8;
option PXE.mtftp-delay code 5 = unsigned integer 8;
option PXE.discovery-control code 6 = unsigned integer 8;
option PXE.discovery-mcast-addr code 7 = ip-address;
subnet 172.16.0.0 netmask 255.255.0.0 {
}
subnet 172.18.0.192 netmask 255.255.255.192 {
class "pxeclients" {
match if substring (option vendor-class-identifier, 0, 9) = "PXEClient";
option vendor-class-identifier "PXEClient";
vendor-option-space PXE;
option PXE.mtftp-ip 0.0.0.0;
filename "pxelinux.0";
next-server 172.18.0.193;
}
host node-1 {
hardware ethernet 00:13:d4:68:b2:7b;
fixed-address 172.18.0.194;
}
host node-2 {
hardware ethernet 00:11:2f:45:e9:fd;
fixed-address 172.18.0.195;
}
host node-3 {
hardware ethernet 00:07:E9:2A:A9:AC;
fixed-address 172.18.0.196;
}
}ftp etc # more /etc/conf.d/in.tftpd
# /etc/init.d/in.tftpd
# Path to server files from
INTFTPD_PATH="/diskless"
INTFTPD_USER="nobody"
# For more options, see tftpd(8)
INTFTPD_OPTS="-u ${INTFTPD_USER} -l -vvvvvv -p -c -s ${INTFTPD_PATH}"ftp etc # ps -ax |grep tft
Warning: bad ps syntax, perhaps a bogus '-'? See procps.sf.net/faq.html
5694 ? Ss 0:00 /usr/sbin/in.tftpd -l -u nobody -l -vvvvvv -p -c -s /diskless
31418 pts/0 R+ 0:00 grep tftftp etc # more exports
/diskless/node 172.18.0.192/255.255.255.192(rw,sync,no_root_squash)2. Software for automating the assembly of arrays
The software that runs on the nodes makes the md * raid arrays and exports them ataoe to supervisor. config for etherpopulate with the participation of three nodes. two more add. the disk from each node is exported for other purposes (backup on raid1)
ftp# chroot /diskless/node
ftp etc # more /usr/sbin/etherpopulate
#!/usr/bin/perl
my $action = shift();
#system('insmod /lib/modules/vb-2.6.16-rc1.ko')
# if ( -f '/lib/modules/vb-2.6.16-rc1.ko');
# Get information on node_id's of ifaces
my @ifconfig = `ifconfig`;
my $int;
my %iface;
foreach my $line (@ifconfig) {
if ($line =~ /^(\S+)/) {
$int = $1;
}
if ($line =~ /inet addr:(\d+\.\d+\.\d+\.)(\d+)/ && $1 ne '127.0.0.' && $int) {
$iface{$int} = $2;
$int = "";
}
}
my $vblade_kernel = ( -d "/sys/vblade" )?1:0;
if ( $vblade_kernel ) {
print " Using kernelspace vblade\n" if ($action eq "start");
} else {
print " Using userspace vblade\n" if ($action eq "start");
}
# Run vblade
foreach my $int (keys %iface) {
my $node_id = $iface{$int};
open(DATA, "/etc/etherpopulate.conf");
while () {
chomp;
s/#.*//;
s/^\s+//;
s/\s+$//;
next unless length;
if ($_ =~ /^node-$node_id\s+(\S+)\s+(\S+)\s+(\S.*)/) {
my $cfg_action = $1;
my $command = $2;
my $parameters = $3;
# Export disk over ATAoE
if ($action eq $cfg_action && $command eq "ataoe" && $parameters =~ /(\S+)\s+(\d+)/) {
my $disk_name = $1;
my $disk_id = $2;
if ($vblade_kernel) {
if ( $disk_name =~ /([a-z0-9]+)$/ ) {
my $disk_safe_name = $1;
system("echo 'add $disk_safe_name $disk_name' > /sys/vblade/drives");
system("echo 'add $int $node_id $disk_id' > /sys/vblade/$disk_safe_name/ports");
}
} else {
system("/sbin/start-stop-daemon --background --start --name 'vblade_$node_id_$disk_id' --exec /usr/sbin/vblade $node_id $disk_id eth0 $disk_name");
}
print " Exporting disk: $disk_name [ $node_id $disk_id ] via $int\n";
}
# Execute specified command
if ($action eq $cfg_action && $command eq "exec") {
system($parameters);
}
}
}
close(DATA);
}
ftp sbin # more /diskless/node/etc/etherpopulate.conf
# ----------------------
# Node 194 160gb
node-194 start exec /sbin/mdadm -A /dev/md0 -f /dev/hd[a-h] /dev/hdl
node-194 start ataoe /dev/md0 0 # Vblade FTP array
node-194 start ataoe /dev/hdk 1 # Vblade BACKUP disk
node-194 stop exec /usr/bin/killall vblade
node-194 stop exec /sbin/mdadm -S /dev/md0
# ----------------------
# Node 195 200 gb
node-195 start exec /sbin/mdadm -A /dev/md0 /dev/hd[a-b] /dev/hd[e-f] /dev/hd[g-h] /dev/sd[a-c]
node-195 start ataoe /dev/md0 0 # Vblade FTP array
node-195 start ataoe /dev/sdd 1 # Vblade BACKUP disk
node-195 stop exec /usr/bin/killall vblade
node-195 stop exec /sbin/mdadm -S /dev/md0
# ----------------------
# Node 196 200 gb
node-196 start exec /sbin/mdadm -A /dev/md0 /dev/hd[a-f]
node-196 start ataoe /dev/md0 0 # Vblade FTP array
node-196 stop exec /usr/bin/killall vblade
node-196 stop exec /sbin/mdadm -S /dev/md03. Final work
make the screws on the nodes work at maximum speed to the detriment of reliability.
hd*_args="-d1 -X69 -udma5 -c1 -W1 -A1 -m16 -a16 -u1"We will verify the kernel for the supervisor. On the nodes themselves, export to ATAoE occurs in userland, using vblade. on the nodes themselves immediately after loading and starting etherpopulate in accordance with the config. we collect lvm from disks on a supervisor, in the future you don’t need to do this, just by vgscan there will be a section ready for mounting from the first two nodes, 1 array and 1 disk each, from the third node only an array is exported. Before these devices can be used on the LVM supervisor, you need to make “special” markup so that LVM adds some internal identifiers to the disk. Disks are ready to use. We create Volume Group.
ftp good # grep -i OVER_ETH .config
CONFIG_ATA_OVER_ETH=ynode-195 ~ # cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid5] [raid4] [raid6] [multipath] [faulty]
md0 : active raid5 hda[0] sdc[8] sdb[7] sda[6] hdh[5] hdg[4] hdf[3] hde[2] hdb[1]
1562887168 blocks level 5, 64k chunk, algorithm 2 [9/9] [UUUUUUUUU]
unused devices: node-195 ~ # ps -ax | grep vblade | grep md
Warning: bad ps syntax, perhaps a bogus '-'? See procps.sf.net/faq.html
2182 ? Ss 2090:41 /usr/sbin/vblade 195 0 eth0 /dev/md0
node-195 ~ # mount
rootfs on / type rootfs (rw)
/dev/root on / type nfs (ro,v2,rsize=4096,wsize=4096,hard,nolock,proto=udp,addr=172.18.0.193)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
udev on /dev type tmpfs (rw,nosuid)
devpts on /dev/pts type devpts (rw)
none on /var/lib/init.d type tmpfs (rw)
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec)
ftp / # ls -la /dev/etherd/*
c-w--w---- 1 root disk 152, 3 Jun 7 2008 /dev/etherd/discover
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e194.0
brw-rw---- 1 root disk 152, 49936 Jun 7 2008 /dev/etherd/e194.1
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e195.0
brw-rw---- 1 root disk 152, 49936 Jun 7 2008 /dev/etherd/e195.1
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e196.0
cr--r----- 1 root disk 152, 2 Jun 7 2008 /dev/etherd/err
c-w--w---- 1 root disk 152, 4 Jun 7 2008 /dev/etherd/interfaces# pvcreate /dev/etherd/e194.0
...
...# vgcreate cluster /dev/etherd/e194.0 /dev/etherd/e195.0 /dev/etherd/e196.0Although the group becomes immediately active, in principle it can be turned on
# vgchange -a y clusterand off.
# vgchange -a n clusterTo add something to the volume group, use
# vgextend cluster /dev/*...Create a Logical Volume hyperspace for all available space. Each PE defaults to 4mb. So see what happened you can vgdisplay, lvdisplay, pvdisplay. You can expand everything with vgextend, lvextend, resize_reiserfs. More details here http://tldp.org/HOWTO/LVM-HOWTO/ As a result, we have / dev / cluster / hyperspace and make mkreiserfs and mount for it. All is ready. We will lower the ftp server setting. TA-dah!
# vgdisplay cluster | grep "Total PE"
Total PE 1023445
# lvcreate -l 1023445 cluster -n hyperspace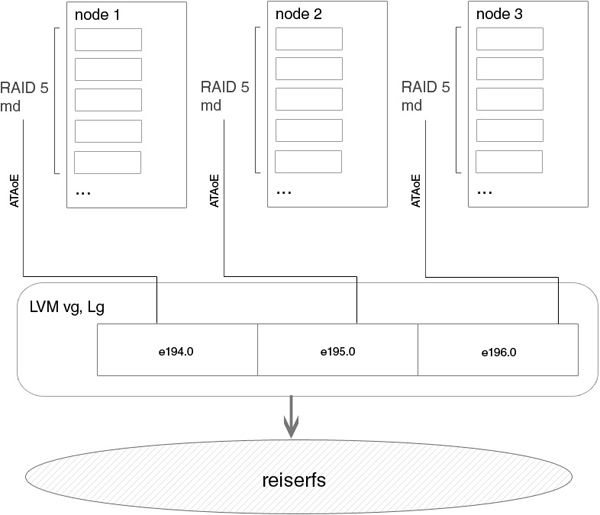
Reuse
On the supervisor itself, if it is rebooted, it is enough to execute it in order to use a previously created array.
more runme.sh
#!/bin/sh
vgscan
vgchange -a y
mount /dev/cluster/hyperspace /mnt/ftpdisadvantages
- specifically in our case, the error was with the choice of the hard drives themselves. For some reason, the choice fell on Maxtor, and almost the entire batch of 30 discs went bad in a year;
- no hot swap was used because it was still an IDE. In the case of hotplug SATA, it would be necessary at the mdadm level on the nodes themselves to configure a notification about the failure of disks;
- proftpd needs to be started only after lvm from ataoe devices is mounted in the file system of the supervisor. if proftpd started earlier, then he did not understand what happened at all;
- We experimented for a long time with the nuclear and userspace'ny vblade on the nodes, but then it was the dawn of the development of ataoe and everything worked as luck would have it. but it worked;
- either reiserfs or xfs can be used as a file system - only they supported online resize at that time if the disk under them increased;
- then only patches began to appear that allowed expanding the raid-5 array md online
- there was a limit on ataoe with 64 slots per shelf. Shelves could be made in pieces of 10, i.e., in principle, there were some restrictions, such as 640 NOD :)
- There are many nuances with performance, but they are all solved to one degree or another. in short - do not be afraid when at first the speed will not be very, there is no limit to perfection;
conclusions
The solution is certainly interesting, and I want to make it already on terabyte screws, hotplug sata and with new fresh versions of software. but who will go on such a feat is unknown. Maybe you,% username%?
Related Links
http://tldp.org/HOWTO/LVM-HOWTO/
http://sourceforge.net/search/?words=ataoe&type_of_search=soft&pmode=0&words=vblade&Search=Search
http://www.gentoo.org/doc/en/ diskless-howto.xml
Original article
PS Special thx to 029ah for writing scripts.