Data Warehouse Architecture: Traditional and Cloud
Hello, Habr! A lot has been written on the topic of data warehouse architecture, but it has not yet met as succinctly and succinctly as in an article that I accidentally stumbled upon.
I invite you to get acquainted with this article in my translation. Comments and additions are welcome!
(Image source)
So, the architecture of data warehouses is changing. In this article, we will compare traditional enterprise data warehouses and cloud solutions with lower initial cost, improved scalability, and performance.
A data warehouse is a system in which data is collected from various sources within a company and this data is used to support management decisions.
Companies are increasingly moving to cloud-based data warehouses instead of traditional on-premises systems. Cloud data storages have a number of differences from traditional storages:
The following concepts highlight some of the established design ideas and principles used to create traditional data warehouses.
Quite often, the traditional data warehouse architecture has a three-tier structure consisting of the following levels:

Two pioneers of data warehouses: Bill Inmon and Ralph Kimball, offer different design approaches. Ralph Kimball
's approach is based on the importance of data marts, which are data warehouses belonging to specific businesses. A data warehouse is simply a combination of various data marts that facilitate reporting and analysis. The Kimball-based data warehouse project uses a bottom-up approach. The approach of Bill Inmon is based on the fact that the data store is a central repository for all enterprise data. With this approach, the organization first creates a normalized model
data storages. Then, dimensional data marts are created based on the warehouse model. This is known as a top-down data warehouse approach.
In traditional architecture, there are three general models of data warehouses: virtual storage, data showcase, and corporate data warehouse:
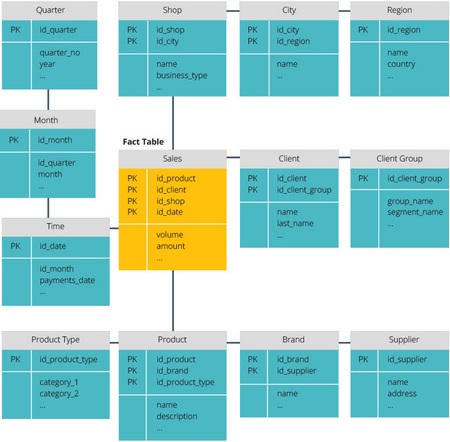
Star and snowflake schemes are two ways to structure your data warehouse.
A star schema has a centralized data warehouse, which is stored in a fact table. The chart splits the fact table into a series of denormalized dimension tables. The fact table contains the aggregated data that will be used for reporting, and the dimension table describes the stored data.
Denormalized projects are less complex because the data is grouped. The fact table uses only one link to attach to each dimension table. The simpler star-shaped design greatly simplifies the writing of complex queries.
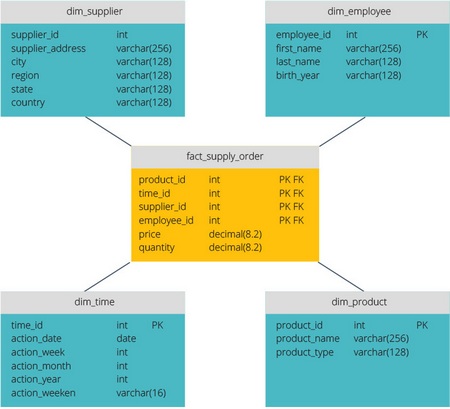
A snowflake pattern is different in that it uses normalized data. Normalization means efficient data organization so that all data dependencies are defined and each table contains a minimum of redundancy. Thus, individual measurement tables are forked into separate measurement tables.
The snowflake scheme uses less disk space and better maintains data integrity. The main disadvantage is the complexity of the queries required to access the data - each query must go through several table joins to get the corresponding data.
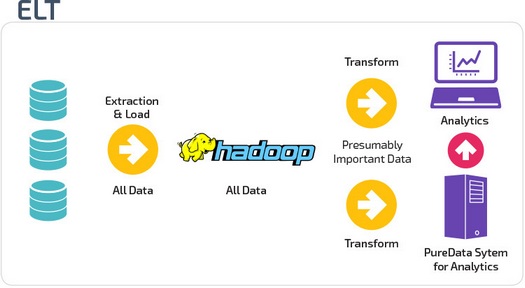
ETL and ELT are two different ways to load data into storage.
ETLs (Extract, Transform, Load) first retrieve data from a pool of data sources. Data is stored in a temporary staging database. Then, conversion operations are performed to structure and transform the data into a suitable form for the target data warehouse system. Then the structured data is loaded into the storage and ready for analysis.
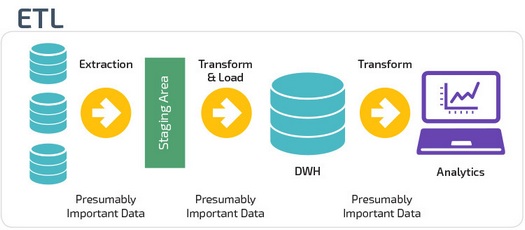
In the case of ELT (Extract, Load, Transform), data is immediately loaded after extraction from the source data pools. There is no intermediate database, which means that data is immediately uploaded to a single centralized repository.
Data is converted to a data warehouse system for use with business intelligence and analytics tools.
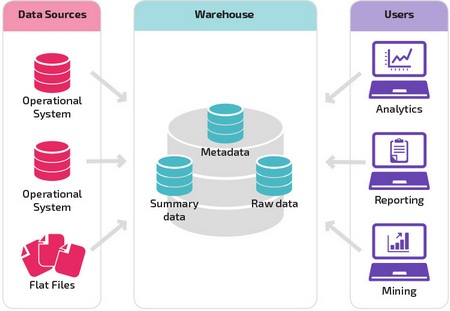
The organization’s data warehouse structure also depends on its current situation and needs.
The basic structure allows storage end users to directly access summary data from source systems, create reports and analyze this data. This structure is useful for cases where data sources come from the same types of database systems.
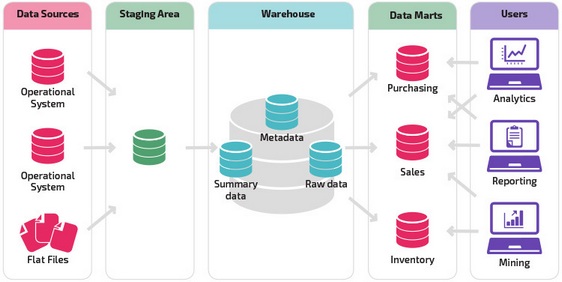
Storage with an intermediate area is the next logical step in an organization with heterogeneous data sources with many different types and formats of data. The staging area converts the data into a generic structured format that is easier to request using analysis and reporting tools.

One variation of the intermediate structure is the addition of data marts to the data warehouse. Data marts store summary data on a specific field of activity, which makes this data easily accessible for specific forms of analysis.
For example, adding data marts can enable a financial analyst to more easily perform detailed queries on sales data and predict customer behavior. Data marts facilitate analysis by tailoring data specifically to meet end-user needs.
In recent years, data warehouses are moving to the cloud. New cloud data warehouses do not adhere to traditional architecture and each of them offers its own unique architecture.
This section briefly describes the architectures used by the two most popular cloud storages: Amazon Redshift and Google BigQuery.
Amazon Redshift is a cloud-based view of a traditional data warehouse.
Redshift requires that computing resources be prepared and configured as clusters that contain a collection of one or more nodes. Each node has its own processor, memory and RAM. Leader Node compiles the requests and passes them to the compute nodes that execute the requests.
At each node, data is stored in blocks called slices . Redshift uses column storage, that is, each data block contains values from one column in several rows, and not from one row with values from several columns.
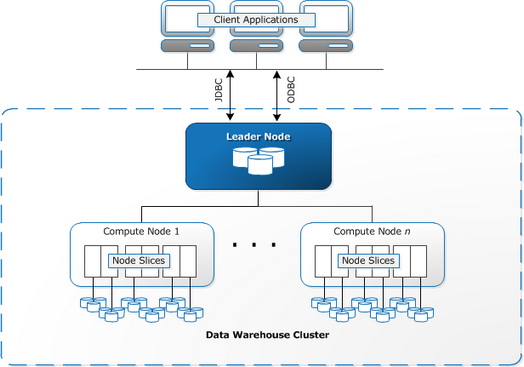
Redshift uses the MPP (Massively Parallel Processing) architecture, breaking large data sets into chunks that are assigned to slices in each node. Requests are faster because compute nodes process requests in each slice at the same time. The Leader Node node combines the results and returns them to the client application.
Client applications such as BI and analytic tools can connect directly to Redshift using the open source PostgreSQL JDBC and ODBC drivers. In this way, analysts can perform their tasks directly on Redshift data.
Redshift can only load structured data. You can load data into Redshift using pre-integrated systems, including Amazon S3 and DynamoDB, by transferring data from any local host with an SSH connection or by integrating other data sources using the Redshift API.
BigQuery architecture does not require a server, which means that Google dynamically controls the allocation of computer resources. Therefore, all resource management decisions are hidden from the user.
BigQuery allows customers to download data from Google Cloud Storage and other readable data sources. An alternative is streaming data, which allows developers to add data to the data warehouse in real time, line by line, when they become available.
BigQuery uses a query engine called Dremel, which can scan billions of rows of data in just a few seconds. Dremel uses massively parallel queries to scan data in the Colossus base file management system. Colossus distributes files into pieces of 64 megabytes among a variety of computing resources called nodes, which are grouped in clusters.
Dremel uses a column data structure similar to Redshift. Tree architecture sends requests to thousands of machines in seconds.
Simple SQL commands are used to perform data queries.

Panoply provides comprehensive data management as a service. Its unique self-optimizing architecture uses machine learning and natural language processing (NLP) to model and streamline data transfer from source to analysis, reducing time from data to values as close to zero as possible.
Panoply Intelligent Data Infrastructure includes the following features:

Cloud-based data warehousing is a big improvement over traditional architecture approaches. However, users still encounter a number of problems when configuring them:
Link to the original text: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
I invite you to get acquainted with this article in my translation. Comments and additions are welcome!
(Image source)
Introduction
So, the architecture of data warehouses is changing. In this article, we will compare traditional enterprise data warehouses and cloud solutions with lower initial cost, improved scalability, and performance.
A data warehouse is a system in which data is collected from various sources within a company and this data is used to support management decisions.
Companies are increasingly moving to cloud-based data warehouses instead of traditional on-premises systems. Cloud data storages have a number of differences from traditional storages:
- No need to buy physical equipment;
- Cloud data warehouses are faster and cheaper to configure and scale;
- Cloud data warehouses can usually perform complex analytic queries much faster because they use massive parallel processing.
Traditional data warehouse architecture
The following concepts highlight some of the established design ideas and principles used to create traditional data warehouses.
Three level architecture
Quite often, the traditional data warehouse architecture has a three-tier structure consisting of the following levels:
- Lower level : this level contains the database server used to retrieve data from many different sources, for example, from transactional databases used for front-end applications.
- Mid-tier : The mid-tier contains an OLAP server that transforms the data into a structure that is better suited for analysis and complex queries. An OLAP server can work in two ways: either as an advanced relational database management system that maps multidimensional data operations to standard relational OLAP operations, or using a multidimensional OLAP model that directly implements multidimensional data and operations.
- Top Level : The top level is the client level. This level contains the tools used for high-level data analysis, reporting, and data analysis.
Kimball vs. Inmon
Two pioneers of data warehouses: Bill Inmon and Ralph Kimball, offer different design approaches. Ralph Kimball
's approach is based on the importance of data marts, which are data warehouses belonging to specific businesses. A data warehouse is simply a combination of various data marts that facilitate reporting and analysis. The Kimball-based data warehouse project uses a bottom-up approach. The approach of Bill Inmon is based on the fact that the data store is a central repository for all enterprise data. With this approach, the organization first creates a normalized model
data storages. Then, dimensional data marts are created based on the warehouse model. This is known as a top-down data warehouse approach.
Data Warehouse Models
In traditional architecture, there are three general models of data warehouses: virtual storage, data showcase, and corporate data warehouse:
- A virtual data warehouse is a set of separate databases that can be shared so that the user can effectively access all the data as if they were stored in one data warehouse;
- A data showcase model is used to report and analyze specific business lines. In this storage model, aggregated data from a number of source systems related to a specific business area, such as sales or finance;
- The corporate data warehouse model involves storing aggregated data that spans the entire organization. This model considers the data warehouse as the heart of an enterprise information system with integrated data from all business units.
Star vs. Snowflake
Star and snowflake schemes are two ways to structure your data warehouse.
A star schema has a centralized data warehouse, which is stored in a fact table. The chart splits the fact table into a series of denormalized dimension tables. The fact table contains the aggregated data that will be used for reporting, and the dimension table describes the stored data.
Denormalized projects are less complex because the data is grouped. The fact table uses only one link to attach to each dimension table. The simpler star-shaped design greatly simplifies the writing of complex queries.
A snowflake pattern is different in that it uses normalized data. Normalization means efficient data organization so that all data dependencies are defined and each table contains a minimum of redundancy. Thus, individual measurement tables are forked into separate measurement tables.
The snowflake scheme uses less disk space and better maintains data integrity. The main disadvantage is the complexity of the queries required to access the data - each query must go through several table joins to get the corresponding data.
ETL vs. ELT
ETL and ELT are two different ways to load data into storage.
ETLs (Extract, Transform, Load) first retrieve data from a pool of data sources. Data is stored in a temporary staging database. Then, conversion operations are performed to structure and transform the data into a suitable form for the target data warehouse system. Then the structured data is loaded into the storage and ready for analysis.
In the case of ELT (Extract, Load, Transform), data is immediately loaded after extraction from the source data pools. There is no intermediate database, which means that data is immediately uploaded to a single centralized repository.
Data is converted to a data warehouse system for use with business intelligence and analytics tools.
Organizational maturity
The organization’s data warehouse structure also depends on its current situation and needs.
The basic structure allows storage end users to directly access summary data from source systems, create reports and analyze this data. This structure is useful for cases where data sources come from the same types of database systems.
Storage with an intermediate area is the next logical step in an organization with heterogeneous data sources with many different types and formats of data. The staging area converts the data into a generic structured format that is easier to request using analysis and reporting tools.
One variation of the intermediate structure is the addition of data marts to the data warehouse. Data marts store summary data on a specific field of activity, which makes this data easily accessible for specific forms of analysis.
For example, adding data marts can enable a financial analyst to more easily perform detailed queries on sales data and predict customer behavior. Data marts facilitate analysis by tailoring data specifically to meet end-user needs.
New Data Warehouse Architectures
In recent years, data warehouses are moving to the cloud. New cloud data warehouses do not adhere to traditional architecture and each of them offers its own unique architecture.
This section briefly describes the architectures used by the two most popular cloud storages: Amazon Redshift and Google BigQuery.
Amazon redshift
Amazon Redshift is a cloud-based view of a traditional data warehouse.
Redshift requires that computing resources be prepared and configured as clusters that contain a collection of one or more nodes. Each node has its own processor, memory and RAM. Leader Node compiles the requests and passes them to the compute nodes that execute the requests.
At each node, data is stored in blocks called slices . Redshift uses column storage, that is, each data block contains values from one column in several rows, and not from one row with values from several columns.
Redshift uses the MPP (Massively Parallel Processing) architecture, breaking large data sets into chunks that are assigned to slices in each node. Requests are faster because compute nodes process requests in each slice at the same time. The Leader Node node combines the results and returns them to the client application.
Client applications such as BI and analytic tools can connect directly to Redshift using the open source PostgreSQL JDBC and ODBC drivers. In this way, analysts can perform their tasks directly on Redshift data.
Redshift can only load structured data. You can load data into Redshift using pre-integrated systems, including Amazon S3 and DynamoDB, by transferring data from any local host with an SSH connection or by integrating other data sources using the Redshift API.
Google bigquery
BigQuery architecture does not require a server, which means that Google dynamically controls the allocation of computer resources. Therefore, all resource management decisions are hidden from the user.
BigQuery allows customers to download data from Google Cloud Storage and other readable data sources. An alternative is streaming data, which allows developers to add data to the data warehouse in real time, line by line, when they become available.
BigQuery uses a query engine called Dremel, which can scan billions of rows of data in just a few seconds. Dremel uses massively parallel queries to scan data in the Colossus base file management system. Colossus distributes files into pieces of 64 megabytes among a variety of computing resources called nodes, which are grouped in clusters.
Dremel uses a column data structure similar to Redshift. Tree architecture sends requests to thousands of machines in seconds.
Simple SQL commands are used to perform data queries.
Panoply
Panoply provides comprehensive data management as a service. Its unique self-optimizing architecture uses machine learning and natural language processing (NLP) to model and streamline data transfer from source to analysis, reducing time from data to values as close to zero as possible.
Panoply Intelligent Data Infrastructure includes the following features:
- Query and data analysis - determining the best configuration for each use case, adjusting it over time and creating indexes, sorting keys, disk keys, data types, evacuation and partitioning.
- Identifies queries that don’t follow best practices — for example, those that include nested loops or implicit casts — and rewrite them into an equivalent query that requires a fraction of the execution time or resources.
- Optimize server configuration over time based on query patterns and learning which server setup works best. The platform seamlessly switches server types and measures overall performance.
Beyond Cloud Storage
Cloud-based data warehousing is a big improvement over traditional architecture approaches. However, users still encounter a number of problems when configuring them:
- Uploading data to cloud-based data warehouses is not trivial, and large-scale data pipelines require configuration, testing, and support for the ETL process. This part of the process is usually performed by third-party tools;
- Updates, insertions, and deletions can be complex and must be done carefully to prevent query performance degradation;
- With the semi-structured data is difficult to deal with - they should normalize in a relational database format, which requires automation of large amounts of data;
- Nested structures are usually not supported in cloud data warehouses. You need to convert the nested tables to formats that the data warehouse understands;
- Cluster optimization . There are various options for configuring a Redshift cluster to run your workloads. Different workloads, datasets, or even different types of queries may require different configurations. To achieve optimal performance, it is necessary to constantly review and, if necessary, additionally configure the configuration;
- Query optimization - user queries may not follow best practices and therefore will take much longer to complete. You can work with users or automated client applications to optimize queries so that the data warehouse can work as expected
- Backup and recovery - although the data storage providers provide many options for backing up your data, they are non-trivial to configure and require monitoring and close attention.
Link to the original text: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud