OOP is dead, long live OOP
- Transfer
sources of inspiration
This post came about as a result of a recent publication by Aras Prantskevichus about a report intended for junior programmers. It talks about how to adapt to new ECS architectures. Aras follows the usual pattern ( explanation below ): shows examples of the terrible OOP code, and then demonstrates that the relational model is an excellent alternative solution ( but calls it “ECS” rather than relational) By no means do I criticize Aras - I am a big fan of his work and praise him for his excellent presentation! I chose his presentation instead of hundreds of other posts about ECS from the Internet because he made extra efforts and published a git repository for study in parallel with the presentation. It contains a small simple “game”, used as an example of the selection of different architectural solutions. This small project allowed me to demonstrate my comments on a specific material, so thanks, Aras!
Aras slides are available here: http://aras-p.info/texts/files/2018Academy - ECS-DoD.pdf , and the code is on github: https://github.com/aras-p/dod-playground .
I will not (yet?) Analyze the resulting ECS architecture from this report, but focus on the “bad OOP” code (similar to the stuffed trick) from its beginning. I will show how it really would look if all violations of the principles of OOD (object-oriented design, object-oriented design) were correctly corrected.
Spoiler: eliminating all OOD violations leads to performance improvements similar to Aras to ECS conversions, also uses less RAM and requires fewer lines of code than the ECS version!
TL; DR: Before concluding that OOP sucks and ECS steers, pause and examine OOD (to know how to use OOP correctly), and also understand the relational model (to know how to use ECS correctly).
I have been taking part in a lot of discussions about ECS on the forum for a long time, partly because I don’t think that this model deserves to exist as a separate term ( spoiler: this is just an ad-hoc version of the relational model ), but also because almost every post, presentation, or article promoting an ECS pattern follows the following structure:
- Show an example of terrible OOP code, the implementation of which has terrible flaws due to excessive use of inheritance (which means that this implementation violates many principles of OOD).
- To show that composition is a better solution than inheritance (and not to mention that OOD actually gives us the same lesson).
- Show that the relational model is great for games (but call it “ECS”).
Such a structure infuriates me because: (A) this is a trick "stuffed" ... comparing soft to warm (bad code and good code) ... and this is unfair, even if done unintentionally and is not required to demonstrate that the new architecture is good; and, more importantly: (B) it has a side effect - such an approach suppresses knowledge and inadvertently demotivates readers from acquaintance with studies conducted for half a century. The relational model was first written in the 1960s. Throughout the 70s and 80s, this model has improved significantly. Beginners often have questions like " what class do you want to put this data in? ", And in response they are often told something vague, like "you just need to gain experience and then you just learn to understand in-depth "... but in the 70s this question was actively studied and a formal answer was generally given to it; this is called normalization of databases . Discarding existing studies and calling ECS completely new and With a modern solution, you hide this knowledge from beginners.The
foundations of object-oriented programming were laid just as long ago, if not earlier ( this style began to be explored in the work of the 1950s )! However, it was in the 1990s that object-oriented It became fashionable, viral, and very quickly turned into the dominant programming paradigm, and many new OO languages, including Java and the ( standardized version), exploded in popularity.) C ++. However, since this was due to hype, everyone needed to know this high-profile concept in order to write in their resume, but only a few really went into it. These new languages created the keywords — class , virtual , extends , implements — out of many features of OO , and I think that is why at that moment OO was divided into two separate entities, living their own lives.
I will call the use of these OO-inspired language features “ OOP ”, and the use of OO-inspired design / architecture techniques “ OOD ”"Everyone quickly picked up OOP. Educational institutions have OO courses that bake new OOP programmers ... however, OOD knowledge lags behind.
I believe that code that uses the language features of OOP but does not follow OOD design principles is not an OO code Most criticisms against OOP use an eviscerated code as an example, which is not really an OO code. The
OOP code has a very bad reputation, and in particular because most of the OOP code does not follow OOD principles, but therefore is not "true m "object-oriented code.
Background
As stated above, the 1990s became the peak of the “fashion for OO”, and it was at that time that the “bad OOP” was probably the worst. If you studied OOP at that time, you most likely learned about the “four pillars of OOP”:
- Abstraction
- Encapsulation
- Polymorphism
- Inheritance
I prefer to call them not four pillars, but “four OOP tools”. These are tools that you can use to solve problems. However, it’s not enough just to find out how the tool works, you need to know when to use it ... On the part of teachers, it is irresponsible to teach people a new tool, not telling them when each of them is worth using. In the early 2000s, there was resistance to the active misuse of these tools, a kind of “second wave” of OOD thinking. The result was the emergence of SOLID mnemonicswhich provided a quick way to evaluate architectural strengths. It should be noted that this wisdom was actually widespread in the 90s, but has not yet received a cool acronym, which allowed them to be fixed as five basic principles ...
- The principle of sole responsibility ( S ingle responsibility principle). Each class should have only one reason for the change. If class “A” has two responsibilities, then you need to create class “B” and “C” to process each of them individually, and then create “A” from “B” and “C”.
- The principle of openness / closure ( O pen / closed principle). Software changes over time ( i.e. its support is important ). Strive to put the pieces that will likely change in the implementation (implementations) ( ie, concrete classes ) and create interfaces (interfaces) on the basis of those parts that are likely to remain unchanged ( eg, abstract base classes ).
- The substitution principle of Barbara Liskov ( L iskov substitution principle). Each implementation of an interface must 100% meet the requirements of this interface, i.e. any algorithm working with an interface should work with any implementation.
- The principle of separation of the interface ( I nterface segregation principle). Make the interfaces as small as possible so that each part of the code “knows” about the smallest amount of code base, for example, avoids unnecessary dependencies. This tip is good for C ++ too, where compilation times become huge if you don't follow it.
- The principle of dependency inversion ( D ependency inversion principle). Instead of two specific implementations that communicate directly (and depend on each other), they can usually be separated by formalizing their communication interface as a third class, used as the interface between them. It can be an abstract base class that defines the calls of the methods used between them, or even just a POD structurethat defines the data transferred between them.
- Another principle is not included in the acronym SOLID, but I'm sure it is very important: “Prefer composition over inheritance” (Composite reuse principle). Composition is the right choice by default . Inheritance should be left for cases when it is absolutely necessary.
So we get SOLID-C (++)
Below I will refer to these principles, calling them acronyms - SRP, OCP, LSP, ISP, DIP, CRP ...
A few more comments:
- In OOD, the concepts of interfaces and implementations cannot be tied to any specific OOP keywords. In C ++, we often create interfaces with abstract base classes and virtual functions , and then implementations inherit from these base classes ... but this is only one specific way to implement the principle of the interface. In C ++, we can also use PIMPL , opaque pointers , duck typing , typedef, etc. ... You can create an OOD structure and then implement it in C, in which there are no OOP language keywords at all! So when I talk about interfaces , I don't necessarily mean virtualfunctions - I'm talking about the principle of hiding implementation . Interfaces can be polymorphic , but more often than not they are! Polymorphism is very rarely used correctly, but interfaces are a fundamental concept for all software.
- As I made clear above, if you create a POD structure that simply stores some data for transmission from one class to another, then this structure is used as an interface - this is a formal description of the data .
- Even if you just create one separate class with the public and private parts, then everything that is in the common part is an interface , and everything in the private part is an implementation .
- As I made clear above, if you create a POD structure that simply stores some data for transmission from one class to another, then this structure is used as an interface - this is a formal description of the data .
- Inheritance actually has (at least) two types — interface inheritance and implementation inheritance.
- In C ++, interface inheritance includes abstract base classes with pure virtual functions, PIMPL, conditional typedef. In Java, interface inheritance is expressed through the implements keyword .
- In C ++, inheritance of implementations occurs every time the base classes contain something other than pure virtual functions. In Java, inheritance of implementations is expressed using the extends keyword .
- OOD has many rules for inheriting interfaces, but inheritance of implementations is usually worth considering as "code with a bite" !
And finally, I should show some examples of the terrible OOP training and how it leads to bad code in real life (and OOP's bad reputation).
- When you were taught hierarchies / inheritance, you might have been given a similar task: Suppose you have a university application that contains a directory of students and staff. You can create the base class Person, and then the class Student and the class Staff, inherited from Person.
No no no. Here I will stop you. The unspoken implication of the LSP principle is that class hierarchies and the algorithms that process them are symbiotic. These are two halves of the whole program. OOP is an extension of procedural programming, and it is still mainly associated with these procedures. If we do not know what types of algorithms will work with Students and Staff (and which algorithms will be simplified due to polymorphism ), it will be completely irresponsible to start creating the structure of class hierarchies. First you need to know the algorithms and data. - When you were taught hierarchies / inheritance, you were probably given a similar task: Suppose you have a class of shapes. We also have squares and rectangles as subclasses. Should a square be a rectangle, or a rectangle a square?
This is actually a good example to demonstrate the difference between inheritance of implementations and inheritance of interfaces.- If you use the implementation inheritance approach, then you completely disregard the LSP and, from a practical point of view, think about the possibility of reusing the code, using inheritance as a tool.
From this point of view, the following is perfectly logical:structSquare {int width; }; structRectangle : Square { int height; };
A square has only a width, and a rectangle has a width + height, that is, expanding the square with the height component, we get a rectangle!- As you might have guessed, OOD says that doing this is ( probably ) wrong. I said "probably," because here you can argue about the implied characteristics of the interface ... oh well.
A square always has the same height and width, so from the square’s interface it’s absolutely correct to assume that the area is “width * width”.
Inheriting from a square, the class of rectangles (according to LSP) must obey the rules of the square interface. Any algorithm that works correctly for a square should also work correctly for a rectangle. - Take another algorithm:
std::vector<Square*> shapes; int area = 0; for(auto s : shapes) area += s->width * s->width;
It will work correctly for squares (calculating the sum of their areas), but will not work for rectangles.
Therefore, the rectangle violates the LSP principle.
- As you might have guessed, OOD says that doing this is ( probably ) wrong. I said "probably," because here you can argue about the implied characteristics of the interface ... oh well.
- If you use the interface inheritance approach, neither Square nor Rectangle will inherit from each other. The interfaces for the square and the rectangle are actually different, and one is not a superset of the other.
- Therefore, OOD discourages the use of implementation inheritance. As stated above, if you want to reuse code, OOD says that composition is the right choice!
- So the correct version of the above (bad) code for the hierarchy of inheritance of implementations in C ++ looks like this:
structShape {virtualintarea()const= 0; }; structSquare :publicvirtual Shape { virtualintarea()const{ return width * width; }; int width; }; structRectangle :private Square, publicvirtual Shape { virtualintarea()const{ return width * height; }; int height; };- "Public virtual" in Java means "implements". Used when implementing the interface.
- “Private” allows you to extend the base class without inheriting its interface - in this case, the rectangle is not a square, although it inherits from it.
- "Public virtual" in Java means "implements". Used when implementing the interface.
- I do not recommend writing such code, but if you want to use inheritance of implementations, then you need to do just that!
- So the correct version of the above (bad) code for the hierarchy of inheritance of implementations in C ++ looks like this:
- If you use the implementation inheritance approach, then you completely disregard the LSP and, from a practical point of view, think about the possibility of reusing the code, using inheritance as a tool.
TL; DR - your OOP class told you what inheritance was like. Your missing OOD class should have told you not to use it 99% of the time!
Entity / Component Concepts
Having dealt with the prerequisites, let's move on to where Aras began - to the so-called starting point of a “typical OOP”.
But for starters, one more addition - Aras calls this code “traditional OOP”, and I want to object to this. This code may be typical for OOP in the real world, but, like the examples above, it violates all kinds of basic principles of OO, so it should not be considered as traditional at all.
I will start with the first commit before he started remaking the structure towards ECS: “Make it work on Windows again” 3529f232510c95f53112bbfff87df6bbc6aa1fae
// -------------------------------------------------------------------------------------------------// super simple "component system"classGameObject;classComponent;typedefstd::vector<Component*> ComponentVector;
typedefstd::vector<GameObject*> GameObjectVector;
// Component base class. Knows about the parent game object, and has some virtual methods.classComponent
{public:
Component() : m_GameObject(nullptr) {}
virtual ~Component() {}
virtualvoidStart(){}
virtualvoidUpdate(double time, float deltaTime){}
const GameObject& GetGameObject()const{ return *m_GameObject; }
GameObject& GetGameObject(){ return *m_GameObject; }
voidSetGameObject(GameObject& go){ m_GameObject = &go; }
boolHasGameObject()const{ return m_GameObject != nullptr; }
private:
GameObject* m_GameObject;
};
// Game object class. Has an array of components.classGameObject
{public:
GameObject(conststd::string&& name) : m_Name(name) { }
~GameObject()
{
// game object owns the components; destroy them when deleting the game objectfor (auto c : m_Components) delete c;
}
// get a component of type T, or null if it does not exist on this game objecttemplate<typename T>
T* GetComponent(){
for (auto i : m_Components)
{
T* c = dynamic_cast<T*>(i);
if (c != nullptr)
return c;
}
returnnullptr;
}
// add a new component to this game objectvoidAddComponent(Component* c){
assert(!c->HasGameObject());
c->SetGameObject(*this);
m_Components.emplace_back(c);
}
voidStart(){ for (auto c : m_Components) c->Start(); }
voidUpdate(double time, float deltaTime){ for (auto c : m_Components) c->Update(time, deltaTime); }
private:
std::string m_Name;
ComponentVector m_Components;
};
// The "scene": array of game objects.static GameObjectVector s_Objects;
// Finds all components of given type in the whole scenetemplate<typename T>
static ComponentVector FindAllComponentsOfType(){
ComponentVector res;
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
res.emplace_back(c);
}
return res;
}
// Find one component of given type in the scene (returns first found one)template<typename T>
static T* FindOfType(){
for (auto go : s_Objects)
{
T* c = go->GetComponent<T>();
if (c != nullptr)
return c;
}
returnnullptr;
}Yes, it’s hard to figure out the hundred lines of code right away, so let's start gradually ... We need another aspect of the premise - in the games of the 90s it was popular to use inheritance to solve all the problems of code reuse. You had Entity, extensible Character, extensible Player and Monster, and so on ... This is an inheritance of implementations, as we described earlier ( “code with a choke” ), and it seems that it’s right to start with it, but as a result it leads to a very inflexible code base. Because OOD has the principle of “composition over inheritance” described above. So, in the 2000s, the principle of “composition over inheritance” became popular, and game developers began to write similar code.
What does this code do? Well, nothing good.
In short, thenthis code re-implements an existing feature of the language - composition as a runtime library, and not as a feature of the language. You can imagine it as if the code actually creates a new metalanguage on top of C ++ and a virtual machine (VM) to execute this metalanguage. In the Aras demo game, this code is not required ( we will completely remove it soon! ) And serves only to reduce the game performance by about 10 times.
But what does he actually do? This is the concept of " E ntity / C omponent system" ( sometimes for some reason called " E ntity / C omponent system"("Entity / component system")), but it is completely different from the concept of " E ntity C omponent S ystem systems" ( which for obvious reasons is never called " E ntity C omponent S ystem systems ) It formalizes several principles of the EC:
- the game will be built from not having features of "Entities" ("Entity") ( in this example called GameObjects), which consist of "components" ("Component").
- GameObjects implement the “service locator” pattern - their child components will be queried by type.
- Components know which GameObject they belong to - they can find components that are at the same level with them by querying the parent GameObject.
- A composition can be only one level deep ( components cannot have their own child components, GameObjects cannot have child GameObjects ).
- GameObject can have only one component of each type ( in some frameworks this is a mandatory requirement, in others not ).
- Each component (probably) changes over time in some unspecified way, so the interface contains a "virtual void Update".
- GameObjects belong to a scene that can execute queries on all GameObjects (and therefore all components).
A similar concept was very popular in the 2000s, and despite its limitations, it turned out to be flexible enough to create countless games both then and today.
However, this is not required. Your programming language already has support for composition as a feature of the language - there is no need for a bloated concept to access it ... Why, then, do these concepts exist? Well, to be honest, they allow you to perform dynamic composition at runtime. Instead of hard defining GameObject types in code, you can load them from data files. And this is very convenient, because it allows game / level designers to create their own types of objects ... However, in most game projects there are very few designers and literally a whole army of programmers, so I would argue that this is an important opportunity. Even worse, this is not the only way you can implement a composition at runtime! For example, Unity uses C # as a “scripting language”, and many other games use its alternatives, for example Lua - a convenient tool for designers can generate C # / Lua code for defining new game objects without the need for such a bloated concept! We will re-add this “feature” in the next post, and we will do it this way,
Let's evaluate this code according to OOD:
- GameObject :: GetComponent uses dynamic_cast. Most people will tell you that dynamic_cast is a “code with a choke,” a big hint that you have a bug somewhere. I would say this - this is evidence that you violated the LSP - you have some kind of algorithm that works with the base interface, but it needs to know different implementation details. For this particular reason, the code smells bad.
- GameObject, in principle, is not bad, if you imagine that it implements the “service locator” template ... but if you go further than criticism from the point of view of OOD, this template creates implicit connections between parts of the project, and I think ( without a link to Wikipedia that can support me with knowledge from computer science ) that implicit communication channels are an antipattern , and they should prefer explicit communication channels. The same argument applies to bloated “event concepts” that are sometimes used in games ...
- I want to state that a component is a violation of SRP because its interface ( virtual void Update (time) ) is too wide. The use of “virtual void Update” in game development is ubiquitous, but I would also say that it is antipattern. Good software should allow you to easily think about control flow and data flow. Placing each element of the gameplay code behind the “virtual void Update” call completely and completely obfuscates the control stream and data stream. IMHO, invisible side effects , also called long - range effects , are some of the most common sources of bugs, and “virtual void Update” ensures that almost everything will be an invisible side effect.
- Although the goal of the Component class is to enable composition, it does it through inheritance, which is a violation of CRP .
- The only good side of this example is that the game code is overkill in order to comply with the principles of SRP and ISP - it is broken into many simple components with very little responsibility, which is great for reusing code.
However, he is not so good at maintaining DIP - many components have direct knowledge of each other.
So, all the code shown above can actually be deleted. This whole structure. Delete GameObject (also called Entity in other frameworks), remove Component, delete FindOfType. This is part of a useless VM that violates OOD principles and terribly slows down our game.
Composition without frameworks (i.e. using features of the programming language itself)
If we remove the composition framework and we don’t have the Component base class, how will our GameObjects manage to use the composition and consist of components? As the title says, instead of writing this bloated VM and creating GameObjects in a strange metalanguage on top of it, let's just write them in C ++ because we are game programmers and this is literally our job.
Here is the commit that removed the Entity / Component framework: https://github.com/hodgman/dod-playground/commit/f42290d0217d700dea2ed002f2f3b1dc45e8c27c
Here is the original version of the source code: https://github.com/hodgman/dod-playbb 3529f232510c95f53112bbfff87df6bbc6aa1fae / source / game.cpp
Here is a modified version of the source code:https://github.com/hodgman/dod-playground/blob/f42290d0217d700dea2ed002f2f3b1dc45e8c27c/source/game.cpp
In a nutshell about the changes:
- Removed ": public Component" from each component type.
- Added a constructor to each type of component.
- OOD is primarily about encapsulating the state of a class, but since these classes are so small / simple, there's really nothing to hide: the interface is a description of the data. However, one of the main reasons that encapsulation is the main pillar is that it allows us to guarantee the constant truth of class invariants ... or if the invariant is broken, then you just need to examine the encapsulated implementation code to find the error. In this code example, it is worth adding constructors to implement a simple invariant - all values must be initialized.
- I renamed the too general “Update” methods so that their names reflect what they actually do — UpdatePosition for MoveComponent and ResolveCollisions for AvoidComponent.
- I removed three hard-coded blocks of code that resembled a template / prefab - the code that creates a GameObject containing specific types of Component, and replaced it with three C ++ classes.
- Eliminated antipattern "virtual void Update".
- Instead of components looking for each other through the “service locator” template, the game explicitly ties them together during construction.
The objects
Therefore, instead of this "virtual machine" code:
// create regular objects that movefor (auto i = 0; i < kObjectCount; ++i)
{
GameObject* go = new GameObject("object");
// position it within world bounds
PositionComponent* pos = new PositionComponent();
pos->x = RandomFloat(bounds->xMin, bounds->xMax);
pos->y = RandomFloat(bounds->yMin, bounds->yMax);
go->AddComponent(pos);
// setup a sprite for it (random sprite index from first 5), and initial white color
SpriteComponent* sprite = new SpriteComponent();
sprite->colorR = 1.0f;
sprite->colorG = 1.0f;
sprite->colorB = 1.0f;
sprite->spriteIndex = rand() % 5;
sprite->scale = 1.0f;
go->AddComponent(sprite);
// make it move
MoveComponent* move = new MoveComponent(0.5f, 0.7f);
go->AddComponent(move);
// make it avoid the bubble things
AvoidComponent* avoid = new AvoidComponent();
go->AddComponent(avoid);
s_Objects.emplace_back(go);
}We now have regular C ++ code:
structRegularObject
{
PositionComponent pos;
SpriteComponent sprite;
MoveComponent move;
AvoidComponent avoid;
RegularObject(const WorldBoundsComponent& bounds)
: move(0.5f, 0.7f)
// position it within world bounds
, pos(RandomFloat(bounds.xMin, bounds.xMax),
RandomFloat(bounds.yMin, bounds.yMax))
// setup a sprite for it (random sprite index from first 5), and initial white color
, sprite(1.0f,
1.0f,
1.0f,
rand() % 5,
1.0f)
{
}
};
...
// create regular objects that move
regularObject.reserve(kObjectCount);
for (auto i = 0; i < kObjectCount; ++i)
regularObject.emplace_back(bounds);Algorithms
Another major change has been made to the algorithms. Remember, at the beginning I said that interfaces and algorithms work in symbiosis, and should influence each other's structure? So, the antipattern " virtual void Update " has become the enemy here too. The initial code contains the main loop algorithm, consisting only of this:
// go through all objectsfor (auto go : s_Objects)
{
// Update all their components
go->Update(time, deltaTime);You can object that it is beautiful and simple, but IMHO it is very, very bad. This completely obfuscates both the control flow and the data flow within the game. If we want to be able to understand our software, if we want to support it, if we want to add new things to it, optimize it, execute it efficiently on several processor cores, then we need to understand both the control flow and the data flow. Therefore, "virtual void Update" must be put on fire.
Instead, we created a more explicit main loop, which greatly simplifies the understanding of the control flow (the data flow in it is still obfuscated, but we will fix this in the following commits ).
// Update all positionsfor (auto& go : s_game->regularObject)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
for (auto& go : s_game->avoidThis)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
// Resolve all collisionsfor (auto& go : s_game->regularObject)
{
ResolveCollisions(deltaTime, go, s_game->avoidThis);
}The disadvantage of this style is that for each new type of object added to the game, we have to add several lines to the main loop. I will return to this in a subsequent post from this series.
Performance
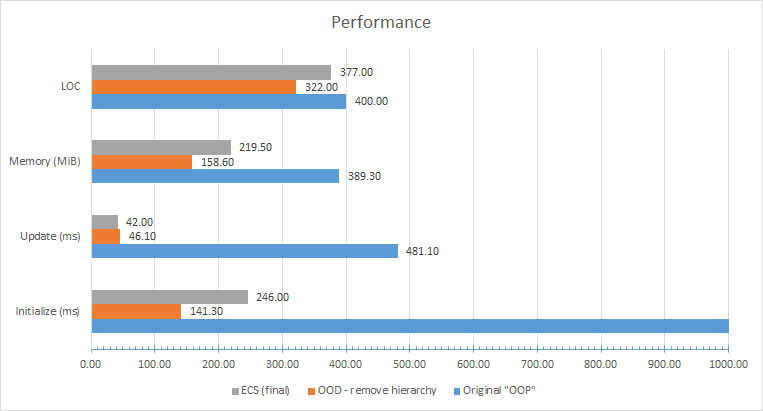
There are many huge OOD violations, some bad decisions are made when choosing a structure, and there are many opportunities for optimization, but I will get to them in the next post of the series. However, already at this stage it is clear that the version with “fixed OOD” almost completely matches or wins the final “ECS” code from the end of the presentation ... And all we did was just take the bad pseudo-OOP code and made it comply with the principles OOP (and also deleted a hundred lines of code)!
Next steps
Here I want to consider a much wider range of issues, including solving the remaining OOD problems, immutable objects ( programming in a functional style ) and the advantages that they can bring in discussions about data flows, message passing, applying DOD logic to our OOD code, applying relevant wisdom in the OOD code, removing these classes of “entities” that we ended up with, and using only clean components, using different styles for connecting components (comparing pointers and the responsibility of carrying) components of containers from the real world, ECS-revision version for better optimization, as well as further optimization, not mentioned in the report Aras ( such as multi-threading / SIMD) The order will not necessarily be this, and perhaps I will not consider all of the above ...
Addition
The links to the article have spread beyond the circles of game developers, so I’ll add: “ ECS ” ( this Wikipedia article is bad, by the way, it combines the concepts of EC and ECS, but this is not the same ...) Is a fake template circulating within game development communities. In fact, it is a version of the relational model in which “entities” are just IDs that designate a shapeless object, “components” are rows in specific tables that reference IDs, and “systems” are procedural code that can modify components . This "template" has always been positioned as a solution to the problem of the excessive use of inheritance, but it is not mentioned that the excessive use of inheritance actually violates the recommendations of the OOP. Hence my indignation. This is not the “only true way” to write software. The post is designed to ensure that people actually learn about existing design principles.