We write a crawler for one or two 1.0
A web crawler (or web spider) is an important part of search engines for crawling web pages in order to enter information about them into databases, mainly for their further indexing. Search engines (Google, Yandex, Bing), as well as SEO products (SEMrush, MOZ, ahrefs) and not only have such a thing. And this thing is quite interesting: both in terms of potential and use cases, and for technical implementation.

With this article, we will begin to iteratively create your crawlerbike , analyzing many features and meeting pitfalls. From a simple recursive function to a scalable and extensible service. Must be interesting!
Iteratively - it means that at the end of each release a ready-to-use version of the “product” is expected with the agreed limitations, features and interface. Node.js and JavaScript were
chosen as the platform and language , because it is simple and asynchronous. Of course, for industrial development, the choice of technological base should be based on business requirements, expectations and resources. As a demonstration and prototype, this platform is completely nothing (IMHO).
The implementation of the crawler is a fairly popular task and can be found even at technical interviews. There are really a lot of ready-made ( Apache Nutch ) and self-written solutions for different conditions and in many languages. Therefore, any comments from personal experience in development or use are welcome and will be interesting.
The task for the first (initial) implementation of ourtyap-blooper crawler will be as follows:
Attention! Ignoring robots.txt rules is a bad idea for obvious reasons. We will make up for this omission in the future. In the meantime, add limits the number of pages crawled parameter limit , to stop and not DoS'it experimental site (for better and do experiments use some your own personal "site-hamster").
For the impatient, here are the sources of this solution.
The first thing we need to be able to do is, in fact, send requests and receive responses via HTTP and HTTPS. In node.js there are two matching clients for this. Of course, you can take a ready-made client request , but for our task it is extremely redundant: we just need to send a GET request and get a response with the body and headers.
The API of both clients we need is identical, we’ll create a map:
We declare a simple function fetch , the only parameter of which will be the absolute URL of the desired web resource string. Using the url module, we will parse the resulting string into a URL object. This object has a field with the protocol (with a colon), by which we will choose the appropriate client:
Next, use the selected client and wrap the result of the fetch function in a promise:
Now we can receive response asynchronously, but for now we are not doing anything with it.
To crawl the site, it is enough to process 3 answer options:
The fetch function will resolve the processed response indicating its type:
Implementation of the strategy of generating the result in the best traditions of if-else :
The fetch function is ready to use: the entire function code .
Now, depending on the variant of the received answer, you need to be able to extract links from the result data of fetch for further crawl. To do this, we define the extract function , which takes a result object as input and returns an array of new links.
If the result type is REDIRECT, then the function will return an array with one single reference from the location field . If NO_DATA, then an empty array. If OK, then we need to connect the parser for the presented text content for search.
For search taskYou can write a regular expression. But this solution does not scale at all, since in the future we will at least pay attention to other attributes ( rel ) of the link, and at the maximum, we will think about img , link , script , audio / video ( source ) and other resources. It is much more promising and more convenient to parse the text of the document and build a tree of its nodes to bypass the usual selectors.
We will use the popular JSDOM library for working with the DOM in node.js:
We get all A elements from the document , and then all the filtered values of the href attribute , if not empty lines.
As a result of the extractor, we have a set of links (URLs) and two problems: 1) the URL can be relative and 2) the URL can lead to an external resource (we only need internal ones now).
The first problem will be helped by the url.resolve function , which resolves the URL of the landing page relative to the URL of the source page.
To solve the second problem, we write a simple utility function inScope that checks the host of the landing page against the host of the base URL of the current crawl:
The function searches for a substring ( baseHost ) with a check for the previous character if the substring was found: since wwwexample.com and example.com are different domains. As a result, we do not leave the given domain, but bypass its subdomains.
We refine the extract function by adding “absolutization” and filtering the resulting links:
Here fetched is the result of the fetch function , src is the URL of the source page, base is the base URL of the crawl. At the output, we get a list of already absolute internal links (URLs) for further processing. The entire function code can be seen here .
Re-encountering any URL, you do not need to send another request for the resource, since the data has already been received (or another connection is still open and waiting for a response). But it’s not always enough to compare the strings of two URLs to understand this. Normalization is the procedure necessary to determine the equivalence of syntactically different URLs.
The normalization process is a whole set of transformations applied to the source URL and its components. Here are just a few of them:
You can always take something ready-made (for example, normalize-url ) or write your own simple function covering the most important and common cases:
Yes, there is no sorting of query parameters, ignoring utm tags, processing _escaped_fragment_ and other things, which we (absolutely) do not need at all.
Next, we will create a local cache of normalized URLs requested by the Crawl framework. Before sending the next request, we normalize the received URL, and if it is not in the cache, add it and only then send a new request.
Key components (primitives) of the solution are ready, it's time to start collecting everything together. To begin with, let's determine the signature of the crawl function : at the input, the start URL and page limit. The function returns a promise whose resolution provides an accumulated result; write it to the output file :
The simplest recursive workflow of the crawl function can be described in steps:
Yes, this algorithm will undergo major changes in the future. Now, a recursive solution is used deliberately on the forehead, so that later it is better to “feel” the difference in implementations. The workpiece for the implementation of the function looks like this:
The achievement of the page limit is checked by a simple request counter. The second counter - the number of active requests at a time - will serve as a test of readiness to give the result (when the value turns to zero). If the fetch function could not get the next page, then set the Status Code for it as null.
You can (optionally) familiarize yourself with the implementation code here , but before that you should consider the format of the returned result.
We will introduce a unique id identifier with a simple increment for the polled pages:
For the result , we will create an array of pages into which we will add objects with data on the page: id {number}, url {string} and code {number | null} (this is now enough). We also create an array of links for links between pages in the form of an object: from ( id of the source page), to ( id of the landing page).
For informational purposes, before resolving the result, we sort the list of pages in ascending order of id (after all, the answers will come in any order), we supplement the result with the number of count pages scanned and a flag on reaching the specified limitfin :
The finished crawler script has the following synopsis:
Complementing the logging of the key points of the process, we will see such a picture at startup:
And here is the result in JSON format:
What can be done with this already? At a minimum, the list of pages you can find all the broken pages of the site. And having information about internal linking, you can detect long chains (and closed loops) of redirects or find the most important pages by reference mass.
We have obtained a variant of the simplest console crawler, which bypasses the pages of one site. The source code is here . There is also an example and unit tests for some functions.
Now this is an unceremonious sender of requests and the next reasonable step would be to teach him good manners. It will be about the User-agent header , robots.txt rules , Crawl-delay directive, and more. From the point of view of implementation, this is first of all queuing up messages and then servicing a larger load. If, of course, this material will be interesting!
With this article, we will begin to iteratively create your crawler
Intro
Iteratively - it means that at the end of each release a ready-to-use version of the “product” is expected with the agreed limitations, features and interface. Node.js and JavaScript were
chosen as the platform and language , because it is simple and asynchronous. Of course, for industrial development, the choice of technological base should be based on business requirements, expectations and resources. As a demonstration and prototype, this platform is completely nothing (IMHO).
This is my crawler. There are many such crawlers, but this one is mine.
My crawler is my best friend.
The implementation of the crawler is a fairly popular task and can be found even at technical interviews. There are really a lot of ready-made ( Apache Nutch ) and self-written solutions for different conditions and in many languages. Therefore, any comments from personal experience in development or use are welcome and will be interesting.
Formulation of the problem
The task for the first (initial) implementation of our
Crawler for one or two 1.0
Write a crawler script that bypasses the internallinks of some small (up to 100 pages) site. As a result, provide a list of URLs of pages with the received codes and a map of their linking. The robots.txt rules and the rel = nofollow link attribute are ignored.
Attention! Ignoring robots.txt rules is a bad idea for obvious reasons. We will make up for this omission in the future. In the meantime, add limits the number of pages crawled parameter limit , to stop and not DoS'it experimental site (for better and do experiments use some your own personal "site-hamster").
Implementation
For the impatient, here are the sources of this solution.
- HTTP (S) client
- Answer options
- Link Extraction
- Link preparation and filtering
- URL normalization
- Main function algorithm
- Return result
1. HTTP (S) client
The first thing we need to be able to do is, in fact, send requests and receive responses via HTTP and HTTPS. In node.js there are two matching clients for this. Of course, you can take a ready-made client request , but for our task it is extremely redundant: we just need to send a GET request and get a response with the body and headers.
The API of both clients we need is identical, we’ll create a map:
const clients = {
'http:': require('http'),
'https:': require('https')
};
We declare a simple function fetch , the only parameter of which will be the absolute URL of the desired web resource string. Using the url module, we will parse the resulting string into a URL object. This object has a field with the protocol (with a colon), by which we will choose the appropriate client:
const url = require('url');
function fetch(dst) {
let dstURL = new URL(dst);
let client = clients[dstURL.protocol];
if (!client) {
throw new Error('Could not select a client for ' + dstURL.protocol);
}
// ...
}
Next, use the selected client and wrap the result of the fetch function in a promise:
function fetch(dst) {
return new Promise((resolve, reject) => {
// ...
let req = client.get(dstURL.href, res => {
// do something with the response
});
req.on('error', err => reject('Failed on the request: ' + err.message));
req.end();
});
}
Now we can receive response asynchronously, but for now we are not doing anything with it.
2. Answer Options
To crawl the site, it is enough to process 3 answer options:
- OK - A 2xx Status Code was received. It is necessary to save the response body as a result for further processing - extracting new links.
- REDIRECT - A 3xx Status Code was received. This is a redirect to another page. In this case, we will need the location response header , from where we will take one single “outgoing” link.
- NO_DATA - All other cases: 4xx / 5xx and 3xx without the Location header . There is nowhere to go further to our crawler.
The fetch function will resolve the processed response indicating its type:
const ft = {
'OK': 1, // code (2xx), content
'REDIRECT': 2, // code (3xx), location
'NO_DATA': 3 // code
};
Implementation of the strategy of generating the result in the best traditions of if-else :
let code = res.statusCode;
let codeGroup = Math.floor(code / 100);
// OK
if (codeGroup === 2) {
let body = [];
res.setEncoding('utf8');
res.on('data', chunk => body.push(chunk));
res.on('end', () => resolve({ code, content: body.join(''), type: ft.OK }));
}
// REDIRECT
else if (codeGroup === 3 && res.headers.location) {
resolve({ code, location: res.headers.location, type: ft.REDIRECT });
}
// NO_DATA (others)
else {
resolve({ code, type: ft.NO_DATA });
}
The fetch function is ready to use: the entire function code .
3. Extraction of links
Now, depending on the variant of the received answer, you need to be able to extract links from the result data of fetch for further crawl. To do this, we define the extract function , which takes a result object as input and returns an array of new links.
If the result type is REDIRECT, then the function will return an array with one single reference from the location field . If NO_DATA, then an empty array. If OK, then we need to connect the parser for the presented text content for search.
For search taskYou can write a regular expression. But this solution does not scale at all, since in the future we will at least pay attention to other attributes ( rel ) of the link, and at the maximum, we will think about img , link , script , audio / video ( source ) and other resources. It is much more promising and more convenient to parse the text of the document and build a tree of its nodes to bypass the usual selectors.
We will use the popular JSDOM library for working with the DOM in node.js:
const { JSDOM } = require('jsdom');
let document = new JSDOM(fetched.content).window.document;
let elements = document.getElementsByTagName('A');
return Array.from(elements)
.map(el => el.getAttribute('href'))
.filter(href => typeof href === 'string')
.map(href => href.trim())
.filter(Boolean);
We get all A elements from the document , and then all the filtered values of the href attribute , if not empty lines.
4. Preparation and filtering of links
As a result of the extractor, we have a set of links (URLs) and two problems: 1) the URL can be relative and 2) the URL can lead to an external resource (we only need internal ones now).
The first problem will be helped by the url.resolve function , which resolves the URL of the landing page relative to the URL of the source page.
To solve the second problem, we write a simple utility function inScope that checks the host of the landing page against the host of the base URL of the current crawl:
function getLowerHost(dst) {
return (new URL(dst)).hostname.toLowerCase();
}
function inScope(dst, base) {
let dstHost = getLowerHost(dst);
let baseHost = getLowerHost(base);
let i = dstHost.indexOf(baseHost);
// the same domain or has subdomains
return i === 0 || dstHost[i - 1] === '.';
}
The function searches for a substring ( baseHost ) with a check for the previous character if the substring was found: since wwwexample.com and example.com are different domains. As a result, we do not leave the given domain, but bypass its subdomains.
We refine the extract function by adding “absolutization” and filtering the resulting links:
function extract(fetched, src, base) {
return extractRaw(fetched)
.map(href => url.resolve(src, href))
.filter(dst => /^https?\:\/\//i.test(dst))
.filter(dst => inScope(dst, base));
}
Here fetched is the result of the fetch function , src is the URL of the source page, base is the base URL of the crawl. At the output, we get a list of already absolute internal links (URLs) for further processing. The entire function code can be seen here .
5. URL Normalization
Re-encountering any URL, you do not need to send another request for the resource, since the data has already been received (or another connection is still open and waiting for a response). But it’s not always enough to compare the strings of two URLs to understand this. Normalization is the procedure necessary to determine the equivalence of syntactically different URLs.
The normalization process is a whole set of transformations applied to the source URL and its components. Here are just a few of them:
- The scheme and host are not case sensitive, so they should be converted to lower.
- All percentages (such as "% 3A") must be uppercase.
- The default port (80 for HTTP) can be removed.
- The fragment ( # ) is never visible to the server and can also be deleted.
You can always take something ready-made (for example, normalize-url ) or write your own simple function covering the most important and common cases:
function normalize(dst) {
let dstUrl = new URL(dst);
// ignore userinfo (auth property)
let origin = dstUrl.protocol + '//' + dstUrl.hostname;
// ignore http(s) standart ports
if (dstUrl.port && (!/^https?\:/i.test(dstUrl.protocol) || ![80, 8080, 443].includes(+dstUrl.port))) {
origin += ':' + dstUrl.port;
}
// ignore fragment (hash property)
let path = dstUrl.pathname + dstUrl.search;
// convert origin to lower case
return origin.toLowerCase()
// and capitalize letters in escape sequences
+ path.replace(/%([0-9a-f]{2})/ig, (_, es) => '%' + es.toUpperCase());
}
Just in case, the format of the URL object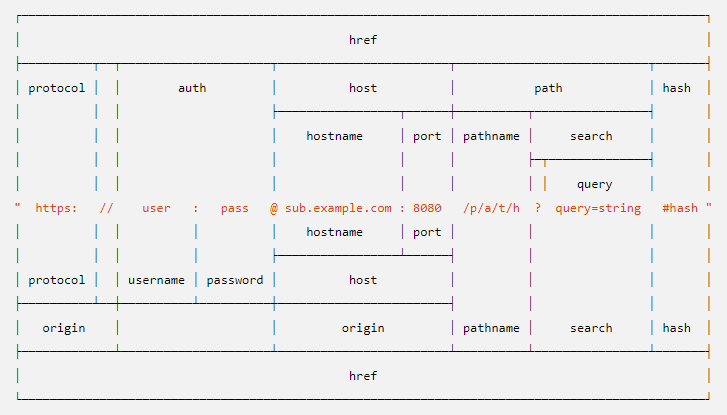
Yes, there is no sorting of query parameters, ignoring utm tags, processing _escaped_fragment_ and other things, which we (absolutely) do not need at all.
Next, we will create a local cache of normalized URLs requested by the Crawl framework. Before sending the next request, we normalize the received URL, and if it is not in the cache, add it and only then send a new request.
6. The algorithm of the main function
Key components (primitives) of the solution are ready, it's time to start collecting everything together. To begin with, let's determine the signature of the crawl function : at the input, the start URL and page limit. The function returns a promise whose resolution provides an accumulated result; write it to the output file :
crawl(start, limit).then(result => {
fs.writeFile(output, JSON.stringify(result), 'utf8', err => {
if (err) throw err;
});
});
The simplest recursive workflow of the crawl function can be described in steps:
1. Initialization of the cache and the result object
2. IF the URL of the landing page (via normalize ) is not in the cache, THEN
- 2.1. IF limit is reached , END (wait for the result)
- 2.2. Add URL to cache
- 2.3. Save the link between the source and the landing page in the result
- 2.4. Send asynchronous request per page ( fetch )
- 2.5. IF the request was successful, THEN
- - 2.5.1. Extract new links from the result ( extract )
- - 2.5.2. For each new link, execute algorithm 2-3
- 2.6. ELSE mark the page as an error
- 2.7. Save page data to result
- 2.8. IF this was the last page, RETURN result
3. OTHERWISE save the link between the source and the target page in the result
Yes, this algorithm will undergo major changes in the future. Now, a recursive solution is used deliberately on the forehead, so that later it is better to “feel” the difference in implementations. The workpiece for the implementation of the function looks like this:
function crawl(start, limit = 100) {
// initialize cache & result
return new Promise((resolve, reject) => {
function curl(src, dst) {
// check dst in the cache & pages limit
// save the link (src -> dst) to the result
fetch(dst).then(fetched => {
extract(fetched, dst, start).forEach(ln => curl(dst, ln));
}).finally(() => {
// save the page's data to the result
// check completion and resolve the result
});
}
curl(null, start);
});
}
The achievement of the page limit is checked by a simple request counter. The second counter - the number of active requests at a time - will serve as a test of readiness to give the result (when the value turns to zero). If the fetch function could not get the next page, then set the Status Code for it as null.
You can (optionally) familiarize yourself with the implementation code here , but before that you should consider the format of the returned result.
7. Returned result
We will introduce a unique id identifier with a simple increment for the polled pages:
let id = 0;
let cache = {};
// ...
let dstNorm = normalize(dst);
if (dstNorm in cache === false) {
cache[dstNorm] = ++id;
// ...
}
For the result , we will create an array of pages into which we will add objects with data on the page: id {number}, url {string} and code {number | null} (this is now enough). We also create an array of links for links between pages in the form of an object: from ( id of the source page), to ( id of the landing page).
For informational purposes, before resolving the result, we sort the list of pages in ascending order of id (after all, the answers will come in any order), we supplement the result with the number of count pages scanned and a flag on reaching the specified limitfin :
resolve({
pages: pages.sort((p1, p2) => p1.id - p2.id),
links: links.sort((l1, l2) => l1.from - l2.from || l1.to - l2.to),
count,
fin: count < limit
});
Usage example
The finished crawler script has the following synopsis:
node crawl-cli.js --start="" [--output=""] [--limit=]
Complementing the logging of the key points of the process, we will see such a picture at startup:
$ node crawl-cli.js --start="https://google.com" --limit=20
[2019-02-26T19:32:10.087Z] Start crawl "https://google.com" with limit 20
[2019-02-26T19:32:10.089Z] Request (#1) "https://google.com/"
[2019-02-26T19:32:10.721Z] Fetched (#1) "https://google.com/" with code 301
[2019-02-26T19:32:10.727Z] Request (#2) "https://www.google.com/"
[2019-02-26T19:32:11.583Z] Fetched (#2) "https://www.google.com/" with code 200
[2019-02-26T19:32:11.720Z] Request (#3) "https://play.google.com/?hl=ru&tab=w8"
[2019-02-26T19:32:11.721Z] Request (#4) "https://mail.google.com/mail/?tab=wm"
[2019-02-26T19:32:11.721Z] Request (#5) "https://drive.google.com/?tab=wo"
...
[2019-02-26T19:32:12.929Z] Fetched (#11) "https://www.google.com/advanced_search?hl=ru&authuser=0" with code 200
[2019-02-26T19:32:13.382Z] Fetched (#19) "https://translate.google.com/" with code 200
[2019-02-26T19:32:13.782Z] Fetched (#14) "https://plus.google.com/108954345031389568444" with code 200
[2019-02-26T19:32:14.087Z] Finish crawl "https://google.com" on count 20
[2019-02-26T19:32:14.087Z] Save the result in "result.json"
And here is the result in JSON format:
{
"pages": [
{ "id": 1, "url": "https://google.com/", "code": 301 },
{ "id": 2, "url": "https://www.google.com/", "code": 200 },
{ "id": 3, "url": "https://play.google.com/?hl=ru&tab=w8", "code": 302 },
{ "id": 4, "url": "https://mail.google.com/mail/?tab=wm", "code": 302 },
{ "id": 5, "url": "https://drive.google.com/?tab=wo", "code": 302 },
// ...
{ "id": 19, "url": "https://translate.google.com/", "code": 200 },
{ "id": 20, "url": "https://calendar.google.com/calendar?tab=wc", "code": 302 }
],
"links": [
{ "from": 1, "to": 2 },
{ "from": 2, "to": 3 },
{ "from": 2, "to": 4 },
{ "from": 2, "to": 5 },
// ...
{ "from": 12, "to": 19 },
{ "from": 19, "to": 8 }
],
"count": 20,
"fin": false
}
What can be done with this already? At a minimum, the list of pages you can find all the broken pages of the site. And having information about internal linking, you can detect long chains (and closed loops) of redirects or find the most important pages by reference mass.
Announcement 2.0
We have obtained a variant of the simplest console crawler, which bypasses the pages of one site. The source code is here . There is also an example and unit tests for some functions.
Now this is an unceremonious sender of requests and the next reasonable step would be to teach him good manners. It will be about the User-agent header , robots.txt rules , Crawl-delay directive, and more. From the point of view of implementation, this is first of all queuing up messages and then servicing a larger load. If, of course, this material will be interesting!