TensorFlow on Apache Ignite
- Transfer
We all know how the homeland begins, and deep learning begins with data. Without them, it is impossible to train a model, evaluate it, and indeed use it. Engaged in research, increasing the Hirsch index with articles on new neural network architectures and experimenting, we rely on the simplest local data sources; usually files in various formats. It works, but it would be nice to remember a combat system containing terabytes of constantly changing data. And this means that you need to simplify and speed up data transfer in production, as well as be able to work with big data. This is where Apache Ignite comes in.
Apache igniteIt is a distributed memory-centric database, as well as a platform for caching and processing operations related to transactions, analytics and stream loads. The system is capable of grinding petabytes of data at the speed of RAM. The article will focus on the integration between Apache Ignite and TensorFlow, which allows you to use Apache Ignite as a data source for training the neural network and inference, as well as a repository of trained models and a cluster management system for distributed learning.
Apache Ignite allows you to store and process as much data as you need in a distributed cluster. To take advantage of this Apache Ignite when training neural networks in TensorFlow, use Ignite Dataset .
Note: Apache Ignite is not just one of the links in the ETL pipeline between a database or data warehouse and TensorFlow. Apache Ignite in itself is HTAP (a hybrid system for transactional / analytical data processing). Choosing Apache Ignite and TensorFlow, you get a single system for transactional and analytical processing, and at the same time, the ability to use operational and historical data to train the neural network and inference.
The following benchmarks demonstrate that Apache Ignite is well suited for scenarios where data is stored on a single host. Such a system allows you to achieve a throughput of more than 850 Mb / s, if the data warehouse and the client are located on the same node. If the storage is located on a remote host, then the throughput is about 800 Mb / s.
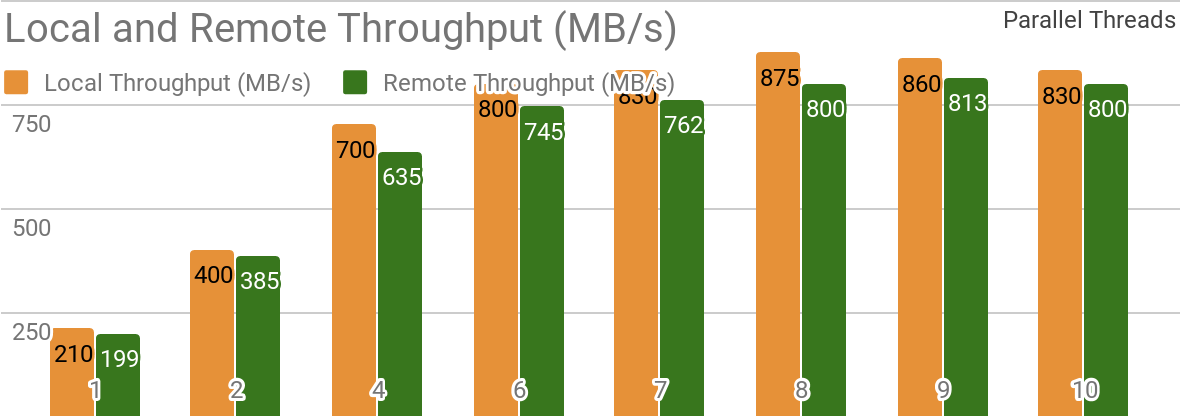
The graph shows the bandwidth for Ignite Dataset for a single local Apache Ignite node. These results were obtained on a 2x Xeon E5-2609 v4 1.7GHz processor with 16GB of RAM and on a network with a bandwidth of 10GB / s (each record has a size of 1MB, page size - 20MB).
Another benchmark demonstrates how Ignite Dataset works with a distributed Apache Ignite cluster. It is this configuration that is selected by default when using Apache Ignite as an HTAP system and allows you to achieve throughput for a single client in excess of 1 GB / s on a cluster with a bandwidth of 10 Gb / s.
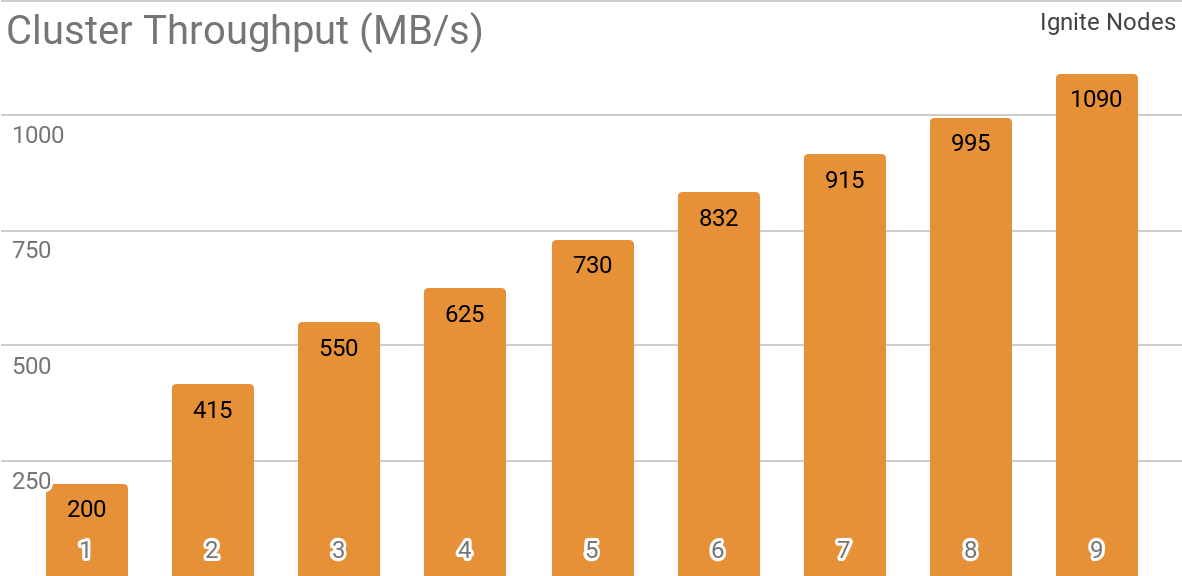
The graph shows the Ignite Dataset throughput for a distributed Apache Ignite cluster with a different number of nodes (from 1 to 9). These results were obtained on a 2x Xeon E5-2609 v4 1.7GHz processor with 16GB of RAM and on a network with a bandwidth of 10 GB / s (each record has a size of 1 MB, page size - 20 MB).
The following scenario was tested: the Apache Ignite cache (with a variable number of partitions in the first set of tests and with 2048 partitions in the second) is filled with 10K lines of 1 MB each, after which the TensorFlow client reads data using Ignite Dataset. The cluster was built from machines with 2x Xeon E5-2609 v4 1.7 GHz, 16 GB of memory and connected via a network operating at a speed of 10 GB / s. On each node, Apache Ignite worked in the standard configuration .
Apache Ignite is easy to use as a classic database with SQL-interface and at the same time as a data source for TensorFlow.
Apache Ignite allows you to store objects of any type that can be built in any hierarchy. You can work with it through Ignite Dataset.
Neural network training and other computations require pre-processing, which can be performed as part of the tf.data pipeline if you use Ignite Dataset.
TensorFlow is a machine learning framework that supports distributed neural network learning, inference and other computing. As you know, neural network training is based on the calculation of gradients of the loss function. In the case of distributed training, we can calculate these gradients on each partition, then aggregate them. It is this method that allows you to calculate the gradients for individual nodes on which data is stored, summarize them and, finally, update the model parameters. And, since we got rid of the transmission of training sample data between nodes, the network does not become the “bottleneck” of the system.
Apache Ignite uses horizontal partitioning (sharding) to store data in a distributed cluster. By creating the Apache Ignite cache (or a table, in terms of SQL), you can specify the number of partitions between which the data will be distributed. For example, if an Apache Ignite cluster consists of 100 machines, and we create a cache with 1000 partitions, then each machine will be responsible for about 10 partitions with data.
Ignite Dataset allows you to use these two aspects for distributed training of neural networks. Ignite Dataset is the compute graph node that is the foundation of the TensorFlow architecture. And, like any node in a graph, it can run on a remote node in the cluster. Such remote node is able to override parameters Ignite Dataset (eg
Apache Ignite also enables distributed learning using the TensorFlow high-level Estimator API library. This functionality is based on the so-called standalone client mode of distributed training in TensorFlow, where Apache Ignite acts as a data source and cluster management system. The next article will be entirely devoted to this topic.
In addition to database capabilities, Apache Ignite also has a distributed IGFS file system . Functionally, it resembles the Hadoop HDFS file system, but only in RAM. Along with its own APIs, the IGFS file system implements the Hadoop FileSystem API and can transparently connect to deployed Hadoop or Spark. The TensorFlow library on Apache Ignite provides integration between IGFS and TensorFlow. Integration is based on TensorFlow ’s own file system plugin and Apache Ignite native IGFS API . There are various scenarios for its use, for example:
Such functionality appeared in the release of TensorFlow 1.13.0.rc0, and will also be part of tensorflow / io in the release of TensorFlow 2.0.
Apache Ignite allows you to secure data channels using SSL and authentication. Ignite Dataset supports SSL connections with and without authentication. See the Apache Ignite SSL / TLS documentation for more details .
Ignite Dataset is fully compatible with Windows. It can be used as part of TensorFlow on a Windows workstation, as well as on Linux / MacOS systems.
The examples below will help you get started with the module.
The easiest way to get started with Ignite Dataset is to start the Docker container with Apache Ignite and downloaded MNIST data , and then work with it using Ignite Dataset. Such a container is available in the Docker Hub: dmitrievanthony / ignite-with-mnist . You need to run the container on your machine:
After that, you can work with it as follows:
TensorFlow IGFS support appeared in the TensorFlow 1.13.0rc0 release and will also be part of the tensorflow / io release in TensorFlow 2.0. To try IGFS with TensorFlow, the easiest way to start the Docker container is with Apache Ignite + IGFS, and then work with it using TensorFlow tf.gfile . Such a container is available in the Docker Hub: dmitrievanthony / ignite-with-igfs . This container can be run on your machine:
Then you can work with it like this:
Currently, when working with Ignite Dataset, it is assumed that all objects in the cache have the same structure (homogeneous objects), and that the cache contains at least one object needed to retrieve the schema. Another limitation concerns structured objects: Ignite Dataset does not support UUIDs, Maps, and Object arrays, which can be part of an object. Removing these restrictions, as well as stabilizing and synchronizing the versions of TensorFlow and Apache Ignite, is one of the tasks of the ongoing development.
Upcoming changes to TensorFlow 2.0 will highlight these features in the tensorflow / io module . After which, work with them can be built more flexibly. The examples will change a bit, and this will be reflected in the gihab and in the documentation.
Apache igniteIt is a distributed memory-centric database, as well as a platform for caching and processing operations related to transactions, analytics and stream loads. The system is capable of grinding petabytes of data at the speed of RAM. The article will focus on the integration between Apache Ignite and TensorFlow, which allows you to use Apache Ignite as a data source for training the neural network and inference, as well as a repository of trained models and a cluster management system for distributed learning.
Distributed RAM Data Source
Apache Ignite allows you to store and process as much data as you need in a distributed cluster. To take advantage of this Apache Ignite when training neural networks in TensorFlow, use Ignite Dataset .
Note: Apache Ignite is not just one of the links in the ETL pipeline between a database or data warehouse and TensorFlow. Apache Ignite in itself is HTAP (a hybrid system for transactional / analytical data processing). Choosing Apache Ignite and TensorFlow, you get a single system for transactional and analytical processing, and at the same time, the ability to use operational and historical data to train the neural network and inference.
The following benchmarks demonstrate that Apache Ignite is well suited for scenarios where data is stored on a single host. Such a system allows you to achieve a throughput of more than 850 Mb / s, if the data warehouse and the client are located on the same node. If the storage is located on a remote host, then the throughput is about 800 Mb / s.
The graph shows the bandwidth for Ignite Dataset for a single local Apache Ignite node. These results were obtained on a 2x Xeon E5-2609 v4 1.7GHz processor with 16GB of RAM and on a network with a bandwidth of 10GB / s (each record has a size of 1MB, page size - 20MB).
Another benchmark demonstrates how Ignite Dataset works with a distributed Apache Ignite cluster. It is this configuration that is selected by default when using Apache Ignite as an HTAP system and allows you to achieve throughput for a single client in excess of 1 GB / s on a cluster with a bandwidth of 10 Gb / s.
The graph shows the Ignite Dataset throughput for a distributed Apache Ignite cluster with a different number of nodes (from 1 to 9). These results were obtained on a 2x Xeon E5-2609 v4 1.7GHz processor with 16GB of RAM and on a network with a bandwidth of 10 GB / s (each record has a size of 1 MB, page size - 20 MB).
The following scenario was tested: the Apache Ignite cache (with a variable number of partitions in the first set of tests and with 2048 partitions in the second) is filled with 10K lines of 1 MB each, after which the TensorFlow client reads data using Ignite Dataset. The cluster was built from machines with 2x Xeon E5-2609 v4 1.7 GHz, 16 GB of memory and connected via a network operating at a speed of 10 GB / s. On each node, Apache Ignite worked in the standard configuration .
Apache Ignite is easy to use as a classic database with SQL-interface and at the same time as a data source for TensorFlow.
$ apache-ignite/bin/ignite.sh
$ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR);
INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY');
INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY');
INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE")
for element in dataset:
print(element){'key': 1, 'val': {'NAME': b'WARM KITTY'}}
{'key': 2, 'val': {'NAME': b'SOFT KITTY'}}
{'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}Structured objects
Apache Ignite allows you to store objects of any type that can be built in any hierarchy. You can work with it through Ignite Dataset.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES")
for element in dataset.take(1):
print(element){
'key': 'kitten.png',
'val': {
'metadata': {
'file_name': b'kitten.png',
'label': b'little ball of fur',
'width': 800,
'height': 600
},
'pixels': [0, 0, 0, 0, ..., 0]
}
}Neural network training and other computations require pre-processing, which can be performed as part of the tf.data pipeline if you use Ignite Dataset.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels'])
for element in dataset:
print(element)[0, 0, 0, 0, ..., 0]Distributed training
TensorFlow is a machine learning framework that supports distributed neural network learning, inference and other computing. As you know, neural network training is based on the calculation of gradients of the loss function. In the case of distributed training, we can calculate these gradients on each partition, then aggregate them. It is this method that allows you to calculate the gradients for individual nodes on which data is stored, summarize them and, finally, update the model parameters. And, since we got rid of the transmission of training sample data between nodes, the network does not become the “bottleneck” of the system.
Apache Ignite uses horizontal partitioning (sharding) to store data in a distributed cluster. By creating the Apache Ignite cache (or a table, in terms of SQL), you can specify the number of partitions between which the data will be distributed. For example, if an Apache Ignite cluster consists of 100 machines, and we create a cache with 1000 partitions, then each machine will be responsible for about 10 partitions with data.
Ignite Dataset allows you to use these two aspects for distributed training of neural networks. Ignite Dataset is the compute graph node that is the foundation of the TensorFlow architecture. And, like any node in a graph, it can run on a remote node in the cluster. Such remote node is able to override parameters Ignite Dataset (eg
host, portorpart) By setting the appropriate environment variables for the workflow (e.g. IGNITE_DATASET_HOST, IGNITE_DATASET_PORTor IGNITE_DATASET_PART). Using such an override, you can assign a specific partition to each cluster node. Then one node is responsible for one partition and at the same time the user receives a single facade of work with the dataset.import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
dataset = IgniteDataset("IMAGES")
# Локально вычисляем градиенты на каждом рабочем узле.
gradients = []
for i in range(5):
with tf.device("/job:WORKER/task:%d" % i):
device_iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
device_next_obj = device_iterator.get_next()
gradient = compute_gradient(device_next_obj)
gradients.append(gradient)
# Агрегируем их на ведущем узле
result_gradient = tf.reduce_sum(gradients)
with tf.Session("grpc://localhost:10000") as sess:
print(sess.run(result_gradient))Apache Ignite also enables distributed learning using the TensorFlow high-level Estimator API library. This functionality is based on the so-called standalone client mode of distributed training in TensorFlow, where Apache Ignite acts as a data source and cluster management system. The next article will be entirely devoted to this topic.
Learning Control Point Storage
In addition to database capabilities, Apache Ignite also has a distributed IGFS file system . Functionally, it resembles the Hadoop HDFS file system, but only in RAM. Along with its own APIs, the IGFS file system implements the Hadoop FileSystem API and can transparently connect to deployed Hadoop or Spark. The TensorFlow library on Apache Ignite provides integration between IGFS and TensorFlow. Integration is based on TensorFlow ’s own file system plugin and Apache Ignite native IGFS API . There are various scenarios for its use, for example:
- Status breakpoints are stored in IGFS for reliability and fault tolerance.
- Learning processes interact with TensorBoard by writing event files to a directory monitored by TensorBoard. IGFS ensures that such communications are operational even when TensorBoard is running in another process or on another machine.
Such functionality appeared in the release of TensorFlow 1.13.0.rc0, and will also be part of tensorflow / io in the release of TensorFlow 2.0.
SSL connection
Apache Ignite allows you to secure data channels using SSL and authentication. Ignite Dataset supports SSL connections with and without authentication. See the Apache Ignite SSL / TLS documentation for more details .
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES",
certfile="client.pem",
cert_password="password",
username="ignite",
password="ignite")Windows support
Ignite Dataset is fully compatible with Windows. It can be used as part of TensorFlow on a Windows workstation, as well as on Linux / MacOS systems.
Try it yourself
The examples below will help you get started with the module.
Ignite dataset
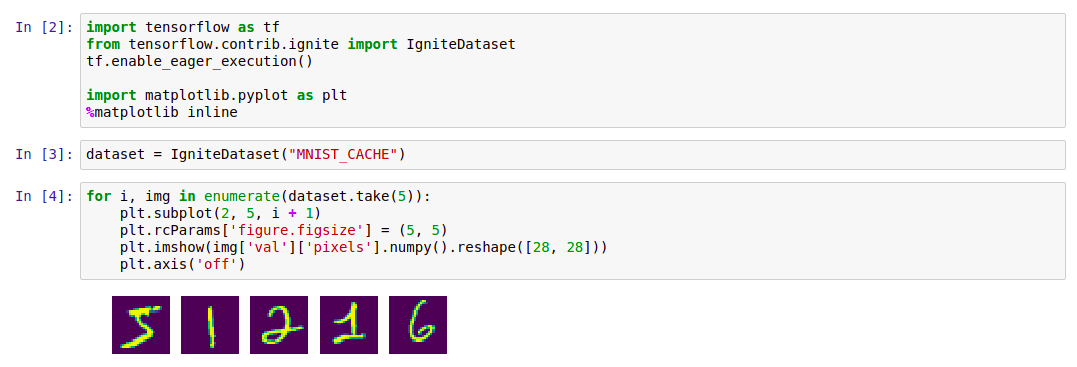
The easiest way to get started with Ignite Dataset is to start the Docker container with Apache Ignite and downloaded MNIST data , and then work with it using Ignite Dataset. Such a container is available in the Docker Hub: dmitrievanthony / ignite-with-mnist . You need to run the container on your machine:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnistAfter that, you can work with it as follows:
The code
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
import matplotlib.pyplot as plt
%matplotlib inline
dataset = IgniteDataset("MNIST_CACHE")
for i, img in enumerate(dataset.take(5)):
plt.subplot(2, 5, i + 1)
plt.rcParams['figure.figsize'] = (5, 5)
plt.imshow(img['val']['pixels'].numpy().reshape([28, 28]))
plt.axis('off')IGFS
TensorFlow IGFS support appeared in the TensorFlow 1.13.0rc0 release and will also be part of the tensorflow / io release in TensorFlow 2.0. To try IGFS with TensorFlow, the easiest way to start the Docker container is with Apache Ignite + IGFS, and then work with it using TensorFlow tf.gfile . Such a container is available in the Docker Hub: dmitrievanthony / ignite-with-igfs . This container can be run on your machine:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfsThen you can work with it like this:
import tensorflow as tf
import tensorflow.contrib.ignite.python.ops.igfs_ops
with tf.gfile.Open("igfs:///hello.txt", mode='w') as w:
w.write("Hello, world!")
with tf.gfile.Open("igfs:///hello.txt", mode='r') as r:
print(r.read())Hello, world!Limitations
Currently, when working with Ignite Dataset, it is assumed that all objects in the cache have the same structure (homogeneous objects), and that the cache contains at least one object needed to retrieve the schema. Another limitation concerns structured objects: Ignite Dataset does not support UUIDs, Maps, and Object arrays, which can be part of an object. Removing these restrictions, as well as stabilizing and synchronizing the versions of TensorFlow and Apache Ignite, is one of the tasks of the ongoing development.
Expected TensorFlow 2.0 Version
Upcoming changes to TensorFlow 2.0 will highlight these features in the tensorflow / io module . After which, work with them can be built more flexibly. The examples will change a bit, and this will be reflected in the gihab and in the documentation.