Do Docker, microservices and reactive programming always needed?
- Tutorial

Author: Denis Tsyplakov , Solution Architect, DataArt
In DataArt I work in two directions. In the first one I help people repair systems broken in one way or another and for a variety of reasons. In the second, I help design new systems so that they are not broken in the future or, to be more realistic, in order to break them more difficult.
If you are not doing something fundamentally new, for example, the world's first Internet search engine or artificial intelligence to control the launch of nuclear missiles, creating a design for a good system is quite simple. It is enough to take into account all the requirements, look at the design of similar systems and do about the same, without making gross mistakes. It sounds like an oversimplification of the issue, but let's remember that it's 2019 outside, and the “typical recipes” of system design are there for almost everything. A business can throw up complex technical tasks — say, process a million disparate PDF files and extract tables with cost data — but the system architecture is rarely very original. The main thing here is not to be mistaken with the definition of which system we are building, and not to miss the choice of technology.
In the last paragraph, typical errors regularly occur, some of which I will discuss in the article.
What is the difficulty of choosing a technical stack? Adding any technology to a project makes it harder and brings some limitations. Accordingly, a new tool (framework, library) should be added only when this tool brings more benefits than harm. In conversations with team members about adding libraries and frameworks, I often use the following trick: “If you want to add a new dependency to a project, you put a box of beer on the team. If you think that this dependence box of beer is not worth it, do not add. "
Suppose we create an application of some kind, say, in Java and add a TimeMagus library to the project (a fictional example) to manipulate dates. The library is excellent, it provides us with many features that are not available in the standard class library. How can such a decision be harmful? Let's sort out the possible scenarios:
- Not all developers know a non-standard library, the threshold of entry for new developers will be higher. There is a greater chance that the new developer will make a mistake when manipulating the date with the help of an unknown library.
- The size of the distribution kit increases. When the size of an average Spring Boot application can easily grow to 100 MB, this is not a trifle at all. I have seen cases when, for the sake of a single method, a 30 MB library was dragged into the distribution kit. This was justified as follows: "I used this library in the past project, and there is a convenient method there."
- Depending on the library, the start time may significantly increase.
- The developer of the library may abandon its offspring, then the library will start to conflict with the new version of Java, or it will reveal a bug (caused for example by changing the time zones), and no patch will be released.
- The license of the library at some point will come into conflict with the license of your product (do you check licenses for all the products you use?).
- Jar hell - the TimeMagus library needs the latest version of the SuperCollections library, then after a few months you need to connect the library to integrate with a third-party API that does not work with the latest version of SuperCollections, but works only with version 2.x. Do not connect the API, you can not and there is no other library to work with this API.
On the other hand, the standard library provides us with sufficiently convenient means for manipulating dates, and if you do not need, for example, to maintain some kind of exotic calendar or calculate the number of days from today to the “second day of the third new moon in the previous year, the soaring eagle” may be worth refrain from using a third party library. Even if it is absolutely wonderful and on a project scale it will save you as much as 50 lines of code.
The considered example is quite simple, and I think it is easy to make a decision here. But there are a number of technologies that are widespread, widely known, and their benefits are obvious, which makes the choice more difficult - they do provide significant advantages to the developer. But this does not always have to be a reason to drag them into your project. Let's look at some of them.
Docker
Before the advent of this really cool technology, many unpleasant and complex issues arose during the deployment of systems related to version conflicts and incomprehensible dependencies. Docker allows you to pack a system status snapshot, roll it into production and run it there. This allows the conflicts mentioned to be avoided, which of course is great.
Previously, this was done in a monstrous way, and some problems were not solved at all. For example, you have a PHP application that uses the ImageMagick library for working with images, your application also needs specific php.ini settings, and the application itself is hosted using Apache httpd. But there is a problem: some regular routines are implemented by running Python scripts from cron, and the library used by these scripts conflicts with the versions of libraries used in your application. Docker allows you to pack all your application along with settings, libraries, and an HTTP server into one container that serves requests on port 80, and routines into another container. All together will work fine, and the conflict of libraries can be forgotten.
Should I use Docker to package each application? My opinion: no, not worth it. The picture shows a typical composition of a docked out application deployed in AWS. The rectangles here are the layers of insulation that we have.
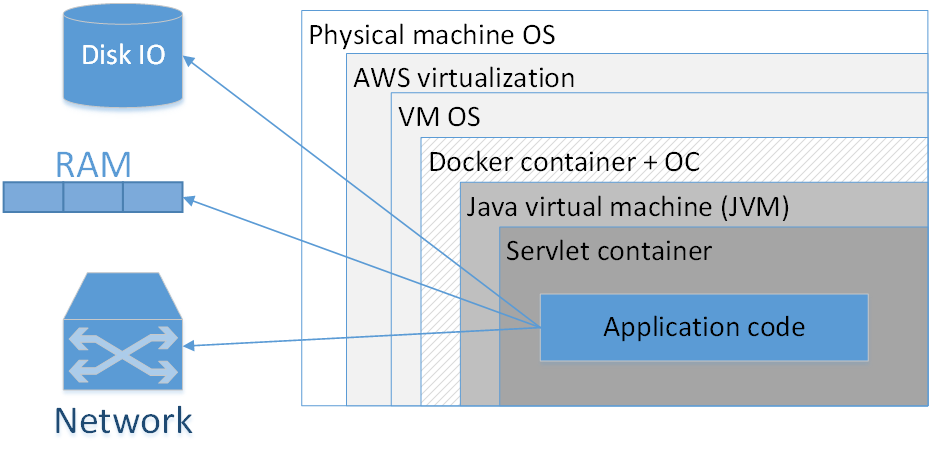
The largest rectangle is the physical machine. Next is the operating system of the physical machine. Then - amazonovsky virtualizer, then - the OS of the virtual machine, then - the docker-container, followed by the OS of the container, JVM, then - the Servlet-container (if it is a web application), and already inside it contains the code of your application. That is, we already see quite a few layers of insulation.
The situation will look even worse if we look at the abbreviation JVM. JVM is, oddly enough, a Java Virtual Machine, that is, in fact, we always have at least one virtual machine in Java. Adding here an additional Docker container, firstly, often does not provide such a noticeable advantage, because the JVM itself isolates us well from the external environment, and secondly, it is not in vain.
I took the figures from IBM research, if I’m not mistaken, two years ago. In short, if we are talking about disk operations, processor utilization, or memory access, Docker almost does not add an overhead (literally a fraction of a percent), but when it comes to network latency, the delays are quite noticeable. They are not gigantic, but depending on which application you have, they may surprise you unpleasantly.
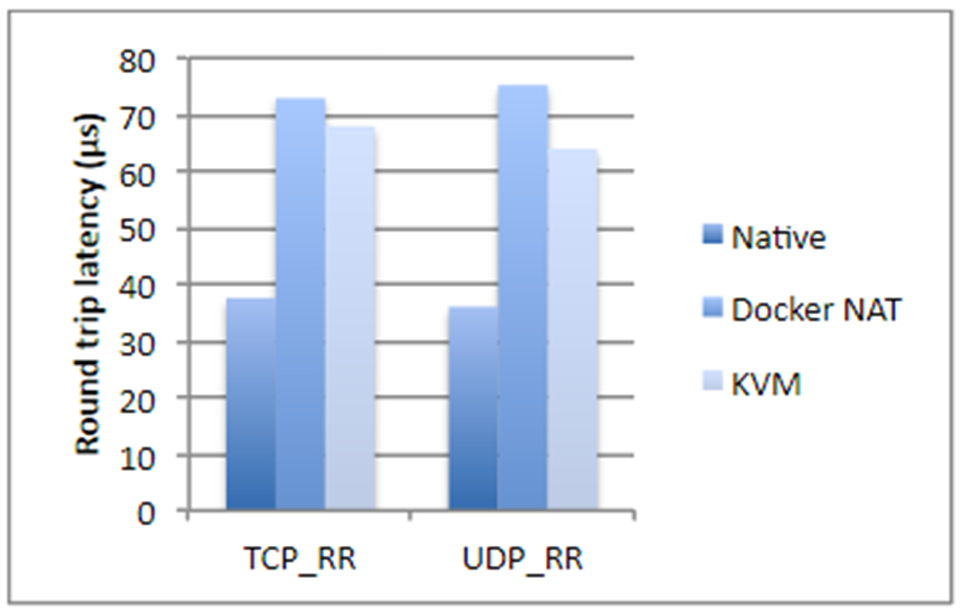
Plus, Docker eats up additional disk space, takes up some of the memory, adds start up time. All three things are uncritical for most systems - usually both disk space and memory are plenty. Startup time, as a rule, is also not a critical problem, as long as the application starts up. But still there are situations where the memory may not be enough, and the total time of launch of the system, consisting of twenty dependent services, is already quite large. In addition, it affects the cost of hosting. And if you are engaged in some high-frequency trading, Docker is absolutely not suitable for you. In general, any application that is sensitive to network latency in the range of up to 250–500 ms is better not to be cured.
Also with the docker, the analysis of problems in network protocols is noticeably more complicated, not only delays grow, but all timings become different.
When is a docker really needed?
When we have different versions of JRE, and at the same time it would be good to carry the JRE with us. There are cases when you need a certain version of Java to run (not “the latest Java 8”, but something more specific). In this case, pack the JRE well with the application and run it as a container. In principle, it is clear that different versions of Java can be put on the target system at the expense of JAVA_HOME, etc. But in this sense, Docker is much more convenient because you know the exact version of JRE, everything is packaged together and with another JRE, even by chance the application will not run .
Docker is also needed if you have dependencies on some binary libraries, for example, for image processing. In this case, a good idea might be to pack all the necessary libraries along with the Java application itself.
The following case refers to the system, which is a complex composite of different services written in different languages. You have a piece on Node.js, there is a Java part, a Go library, and in addition, some Machine Learning in Python. This whole zoo should be carefully and long set up to teach its elements to see each other. Dependencies, paths, IP addresses - all this should be painted and carefully raised in production. Of course, in this case Docker will help you a lot. Moreover, doing this without his help is simply painful.
Docker can provide some convenience when you need to specify many different parameters on the command line to run an application. On the other hand, bash scripts do this perfectly, often from a single line. Decide what to use better.
The last thing that comes to mind is the situation when you use, say, Kubernetes, and you need to do orchestrate the system, i.e., raise some number of different microservices that automatically scale according to certain rules.
In all other cases, Spring Boot is enough to pack everything into a single jar file. And, in principle, the springboot jar is a good metaphor for the Docker container. This, of course, is not the same thing, but in terms of ease of deployment, they are really similar.
Kubernetes
What if we use Kubernetes? To begin with, this technology allows you to deploy a large number of microservices on different machines, manage them, do autoscaling, etc. However, there are quite a few applications that allow you to manage the orchestration, for example, Puppet, CF engine, SaltStack and others. Kubernetes itself is certainly good, but it can add significant overhead, which not every project is ready to live with.
My favorite tool is Ansible in combination with Terraform where it is needed. Ansible is a fairly simple declarative lightweight tool. It does not require the installation of special agents and has an understandable syntax of configuration files. If you are familiar with Docker compose, you will immediately see the overlapping sections. And if you use Ansible, there is no need to dock it - you can deploy systems using more classical tools.
It is clear that all the same these are different technologies, but there are some set of tasks in which they are interchangeable. And a conscientious design approach requires an analysis of which technology is more suitable for the system being developed. And how it will be better to comply with it in a few years.
If the number of different services in your system is small and their configuration is relatively simple, for example, you have only one jar file, and you don’t see any sudden, explosive growth of complexity, you may need to do with the classic deployment mechanisms.
This raises the question “wait, how is one jar file?”. The system should consist of as many atomic microservices as possible! Let's analyze to whom and what the system should with microservices.
Microservices
First of all, microservices allow for greater flexibility and scalability, allow flexible versioning of individual parts of the system. Suppose we have some kind of application that has been in production for many years. The functional grows, but we cannot infinitely develop it extensively. For example.
We have an application on Spring Boot 1 and Java 8. A great, stable combination. But it's 2019, and, whether we like it or not, we need to move towards Spring Boot 2 and Java 12. Even a relatively simple transition of a large system to a new version of Spring Boot can be very laborious, but about jumping over the precipice from Java 8 to Java 12 I do not want to talk. That is, in theory everything is simple: we migrate, we rule the problems that have arisen, we test everything and run it in production. In practice, this may mean several months of work that does not bring new functionality to the business. A little bit to move to Java 12, as you know, also will not work. Here microservice architecture can help us.
We can allocate some compact group of functions of our application to a separate service, migrate this group of functions to a new technical stack and roll it into production in a relatively short time. Repeat the process piece by piece until the old technologies are completely exhausted.
Also, microservices allow for fault isolation, when one dropped component does not destroy the entire system.
Microservices allow us to have a flexible technical stack, i.e., not to write everything monolithically in one language and one version, and if necessary to use a different technical stack for individual components. Of course, it is better when you use a uniform technical stack, but this is not always possible, and in this case, microservices can help out.
Also microservices allow a technical way to solve a number of managerial problems. For example, when your big team consists of separate groups working in different companies (sitting in different time zones and speaking different languages). Microservices help isolate this organizational diversity by component, which will be developed separately. Problems of one part of the team will remain within the same service, and not spread throughout the application.
But microservices is not the only way to solve these problems. Oddly enough, a few decades ago, for half of them, people came up with classes, and a little later, the Inversion of Control components and patterns.
If we look at Spring, we see that in fact it is a microservice architecture inside the Java process. We can declare a component, which, in essence, is a service. We have the ability to lookup through @Autowired, there are tools for managing the life cycle of components and the ability to separately configure components from a dozen different sources. In principle, we get almost all the same that we have with microservices - only within one process, which significantly reduces costs. A regular Java-class is the same API contract that also allows you to isolate implementation details.
Strictly speaking, in the Java world, microservices are most similar to OSGi - there we have an almost exact copy of everything that microservices have, except, apart from the possibility of using different programming languages and executing code on different servers. But even staying within the capabilities of the Java classes, we have a powerful enough tool for solving a large number of problems with isolation.
Even in “managerial” scenarios with team isolation, we can create a separate repository that contains a separate Java module with a clear external contract and test suite. This will significantly reduce the ability of one team to carelessly complicate the life of another team.
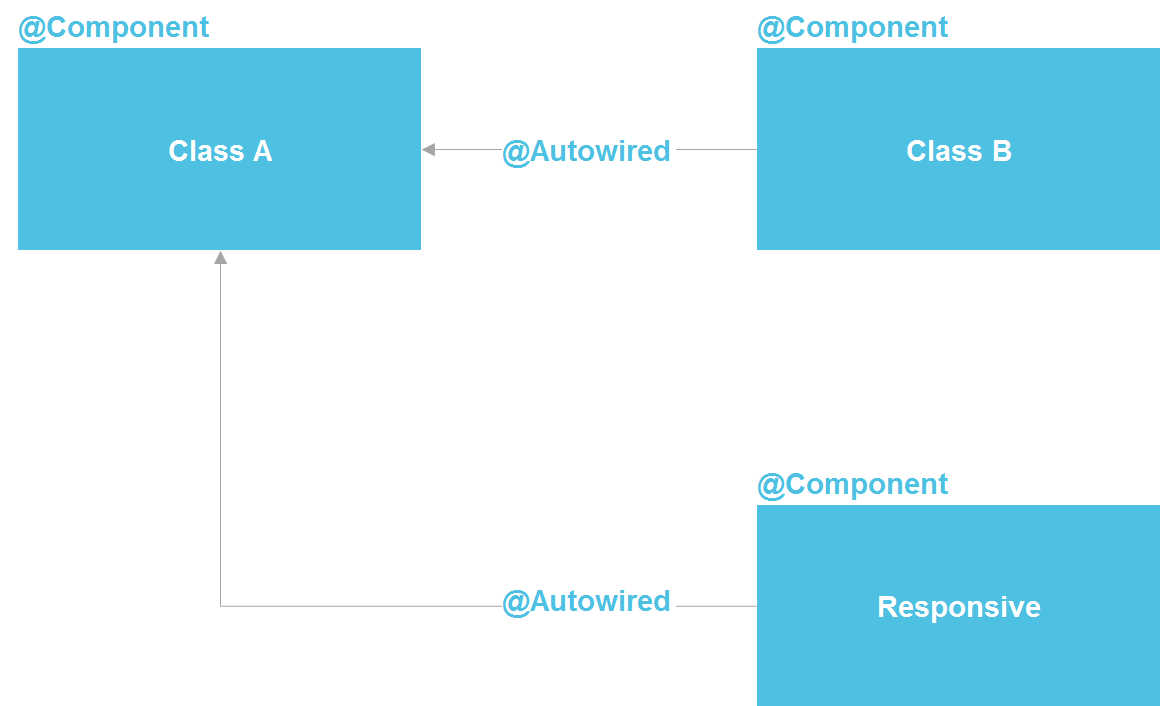
I have repeatedly heard that it is impossible to isolate implementation details without microservices. But I can answer that the entire software industry is just about the implementation isolation. For this, a subroutine was first devised (in the 50s of the last century), then functions, procedures, classes, and later microservices. But the fact that microservices are the last in this series does not make them the highest point of development and does not oblige us to always use their help.
When using microservices, you should also take into account that the calls between them take some time. Often it does not matter, but I have seen the case when the customer needed to fit the system response time in 3 seconds. It was a contractual commitment to connect to a third-party system. The call chain went through several dozens of atomic microservices, and the overhead of making HTTP calls did not allow to be squeezed in 3 seconds. In general, it should be understood that any division of a monolithic code into a number of services inevitably degrades the overall system performance. Just because data cannot be teleported between processes and servers “for free”.
When are microservices still needed?
In what cases does a monolithic application really need to be broken up into several microservices? First, when in functional areas there is an unbalanced use of resources.
For example, we have a group of API calls that perform calculations that require a large amount of CPU time. And there is a group of API calls that are executed very quickly, but require to keep in memory a cumbersome data structure of 64 GB. For the first group, we need a group of machines with a total of 32 processors, for the second one is enough (OK, let there be two machines for fault tolerance) with 64 GB of memory. If we have a monolithic application, then we will need 64 GB of memory on each machine, which increases the cost of each machine. If these functions are divided into two separate services, we can save resources by optimizing the server for a specific function. Server configuration might look like this:

Microservices are needed and if we need to seriously scale up some narrow functional area. For example, a hundred API methods are called at intervals of 10 times per second, and, say, four API methods are called 10 thousand times per second. Scaling the entire system is often not necessary, that is, we can, of course, multiply all 100 methods into multiple servers, but this is usually much more expensive and more complicated than scaling a narrow group of methods. We can select these four calls into a separate service and scale it only to a large number of servers.
It is also clear that we may need microservice if we have a separate functional area written, for example, in Python. Because some library (for example, for Machine Learning) was available only in Python, and we want to allocate it as a separate service. It also makes sense to make microservice, if some part of the system is prone to failures. Well, of course, to write code so that there are no failures in principle, but the reasons may be external. Yes, and no one is immune from their own mistakes. In this case, the bug can be isolated within a separate process.
If none of the above is in your application and is not foreseen in the foreseeable future, most likely, a monolithic application will suit you best. The only thing I recommend is to write it so that non-related functional areas are not dependent on each other in the code. So that if necessary, unrelated functional areas can be separated from each other. However, this is always a good recommendation, following which increases internal consistency and teaches to carefully formulate contracts for the modules.
Reactive Architecture and Reactive Programming
The reactive approach is a relatively new thing. The moment of its appearance can be considered in 2014, when The Reactive Manifesto was published . Two years after the publication of the manifesto, he was on everyone's lips. This is a truly revolutionary approach to system design. Its individual elements were used decades ago, but all the principles of the reactive approach together, as outlined in the manifesto, allowed the industry to take a serious step forward in designing more reliable and more high-performance systems.
Unfortunately, a reactive design approach is often confused with reactive programming. When I asked why I use a reactive library in a project, I heard the answer: “This is a reactive approach, didn’t you read the reactive manifest !?” I read and signed the manifesto, but, the trouble is, reactive programming doesn’t have a reactive approach to system design direct relationship, except that the names of both have the word "reactive". You can easily make a reactive system using a 100% traditional set of tools, and create a completely non-reactive system using the latest developments in functional programming.
A reactive approach to system design is a fairly general principle, applicable to very many systems - it definitely deserves a separate article. Here I would like to talk about the applicability of reactive programming.
What is the essence of reactive programming? First, consider how a regular non-reactive program works.
Thread is executed some code that makes some calculations. Then comes the need to perform some kind of input-output operation, for example, an HTTP request. The code sends a packet over the network, and the thread is blocked waiting for a response. There is a context switch, and another thread starts to execute on the processor. When a response comes over the network, the context switches again, and the first thread continues execution, processing the response.
How will the same code snippet work in a reactive style? The thread performs calculations, sends an HTTP request, and instead of blocking and processing it synchronously, it describes the code (leaves the callback) that should be executed as a reaction (hence the word reactive) to the result. After that, the thread continues to work, doing some other calculations (maybe, just processing the results of other HTTP requests) without switching the context.
The main advantage here is the lack of context switching. Depending on the system architecture, this operation can take several thousand cycles. That is, for a processor with a clock frequency of 3 Ghz, context switching will take at least a microsecond, in fact, due to cache invalidation, etc., rather, several tens of microseconds. Speaking practically, for an average Java application that handles many short HTTP requests, the performance increase can be 5-10%. It’s not that crucial, but, let's say, if you rent 100 servers for $ 50 / month each - you can save $ 500 per month on hosting. Not superb, but enough to drink the team a few times with beer.
So, go ahead for a beer? Let's look at the situation in detail.
The program in the classical imperative style is much easier to read, understand and, as a result, debug and modify. In principle, a well-written reactive program also looks quite clear, the problem is that it’s much harder to write a good, understandable not only to the author of the code here and now, but to another person in a year and a half, the reactive program. But this is a rather weak argument, I have no doubt that for readers of an article to write a simple and clear reactive code is not a problem. Let's look at other aspects of reactive programming.
Not all I / O operations support non-blocking calls. For example, JDBC currently does not support (in this direction, work is underway, see ADA, R2DBC, but so far all this has not reached the release level). Since 90% of all applications now go to databases, the use of a reactive framework automatically turns from a virtue into a disadvantage. For this situation, there is a solution - to handle HTTP calls in one thread pool, and calls to the database in another thread pool. But at the same time, the process becomes much more complicated, and without urgent need I would not do that.
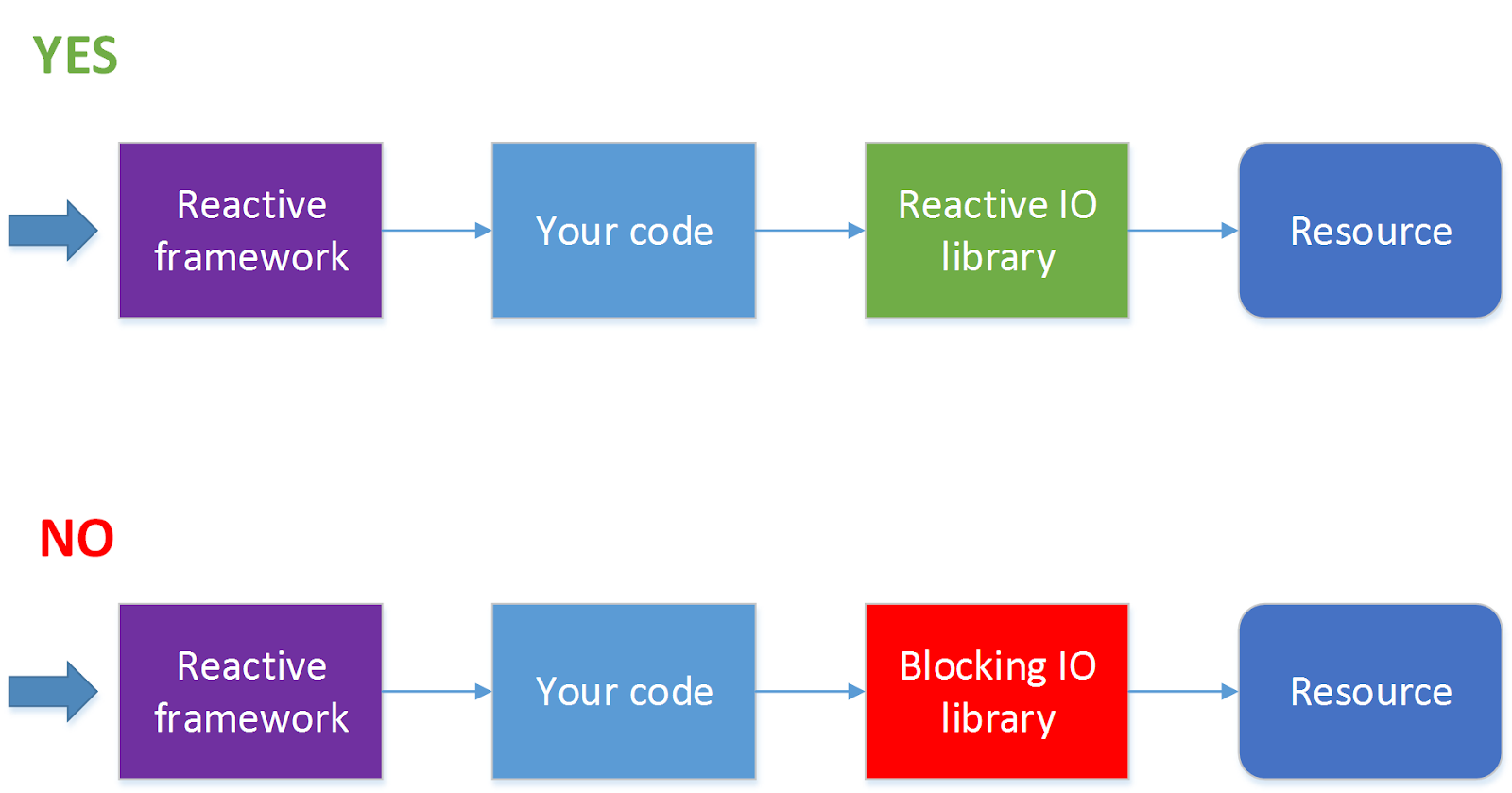
When should I use a reactive framework?
It is worthwhile to use a framework that allows for reactive processing of requests when you have a lot of requests (several hundred a second or more) and at the same time a very small amount of processor cycles is spent on processing each of them. The simplest example is proxying requests or balancing requests between services or some fairly lightweight processing of responses from another service. Where by service we mean something, a request for what can be sent asynchronously, for example, via HTTP.
If, while processing requests, you need to block the thread waiting for an answer, or processing requests takes relatively long time, for example, you need to convert a picture from one format to another, you may not need to write a program in a reactive style.
Also, do not unnecessarily write in a reactive style complex multistep data processing algorithms. For example, the task “to find files with certain properties in a directory and all its subdirectories, convert their contents and send to another service” can be implemented as a set of asynchronous calls, but, depending on the details of the task, such an implementation may look completely opaque and without give significant advantages over the classical sequential algorithm. Say, if this operation should be launched once a day, and there is not much difference, it will be executed 10 or 11 minutes, it may be worth choosing not the best, but simpler implementation.
Conclusion
In conclusion, I would like to say that any technology is always designed to solve specific problems. And if in designing the system in the foreseeable future these tasks are not in front of you, most likely you don’t need this technology here and now, no matter how beautiful it may be.