"Under the hood" storage Huawei: proprietary technology, and what others do not
The data storage systems on the market, for the most part, do not differ much from each other, because many vendors order equipment from almost the same ODM manufacturers. We have almost everything of our own, starting from the chassis and ending with controllers, technologies like RAID 2.0+ and software.

Under the cut there are a few details about what is so unusual in each of the nodes of the storage system.
Structurally, all modern storage systems from any manufacturer look the same: controllers are installed in the front part of the steel box chassis, and interface modules are installed in the rear part of the steel box chassis. There are also power supplies and ventilation. It would seem that everything is familiar and standard. But in fact, we have introduced many interesting things into this paradigm.
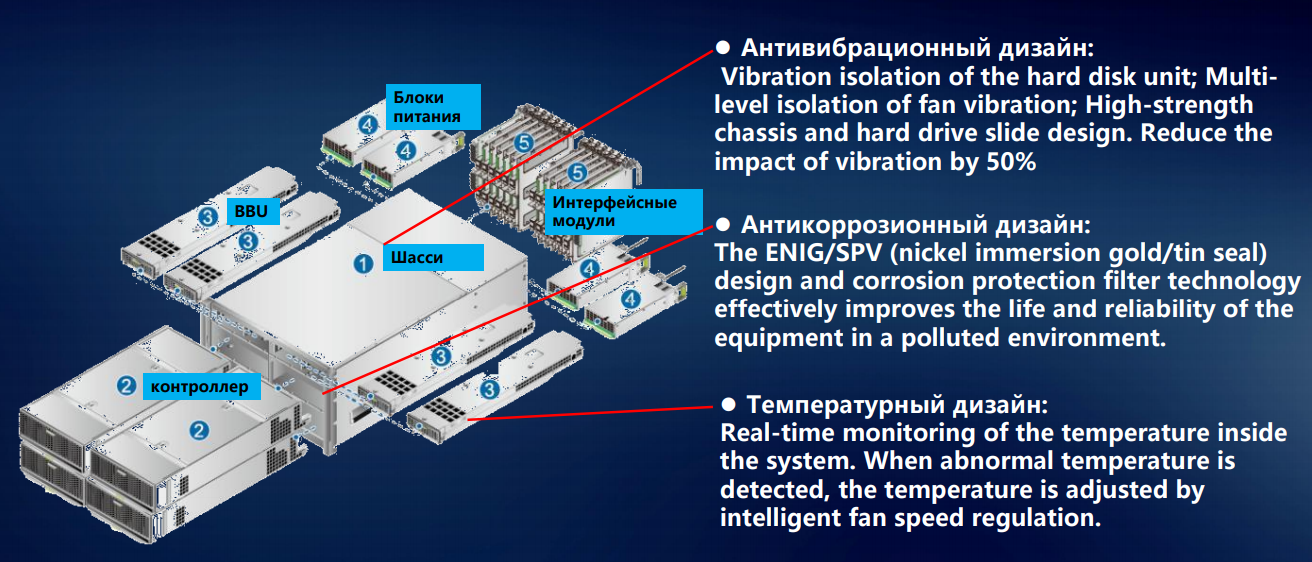
Let's start with the installation of the elements of the storage system in the chassis. Magnetic 3.5-inch disks in the storage system becomes smaller, hybrid systems and all-flash are beginning to dominate. But even a few disk drives with a spindle speed of up to 15 thousand revolutions per minute create a vibration that cannot be ignored. We have a whole set of recommendations for this case - how to distribute magnetic drives with different parameters across disk shelves.
Even if some fraction of a percentage, but it affects the reliability. And on the scale of a large data center, the percentage of one storage drive turns into tangible indicators of failures and failures. To reduce the vibration of individual discs to a lesser degree through a rigid chassis structure, we equip the drive sled with rubber or metal dampers. To neutralize another source of vibration in the storage system - ventilation modules - we put bidirectional fans, and isolate all the rotating elements from the chassis housing.
For spindle drives, minimal shaking is already a problem: the heads start to stray, performance drops significantly. SSD is another matter, they are not afraid of vibrations. But reliable fixing of the components is still important. Take the delivery process: the box can be dropped or casually thrown, put sideways or upside down. Therefore, all of our storage components are fixed strictly in three dimensions. This eliminates the possibility of their displacement during transportation, prevents the connectors from jumping out of the sockets in case of accidental impact.

Once upon a time we started with the development of computing equipment for the telecom industry, where the standards of performance in terms of temperature and humidity are traditionally high. And we transferred them to other areas: the metal parts of the storage system do not oxidize even at high humidity - due to the use of nickel plating and galvanizing.
The thermal design of our storage systems was developed with a focus on the uniform distribution of temperature across the chassis - in order to prevent either overheating or too much cooling of any corner of the disk shelf. Otherwise, it is impossible to avoid physical deformation - even if it is insignificant, but still violates the geometry and can lead to a reduction in the lifetime of the equipment. Thus, some fractions of a percent are won, but this still affects the overall reliability of the system.
We duplicate important storage components: if something fails, there is always a safety net. For example, the power supply modules for the younger models work according to the 1 + 1 scheme, for the more solid ones - 2 + 1 or even 3 + 1.

Controllers that are at least two in the storage system (we do not supply single-controller systems) are also reserved. In the storage system of the 6800th and older series, the reservation is made according to the 3 + 1 scheme, in the younger models - 1 + 1.
Even the management board is reserved, which does not affect the operation of the system directly, but is only needed for configuration changes and monitoring. In addition, any interface storage expansion cards for us are sold only in pairs, so that the client has a reserve.
All components - BP, fans, controllers, management modules, etc. - equipped with microcontrollers capable of responding to certain situations. For example, if the fan starts to slow down by itself, an alarm is sent to the control module. As a result, the customer has a complete picture of the state of the storage system - and, if necessary, can replace some of the components on their own, without waiting for the arrival of our service engineer. And if the customer's security policy allows, we set up the controllers so that they transmit information about the state of iron to our technical support.
We are the only company developing our own processors, chips and controllers for solid-state drives for our storage systems.

So, in some models, we use not the classic Intel x86, but the ARM processor of HiSilicon, our subsidiary, as the main processor of the storage system (Storage Controller Chip). The fact is that the ARM architecture in storage - for calculating the same RAID and deduplication - does better than the standard x86.
Our special pride is chips for SSD controllers. And if our servers can be equipped with third-party semiconductor drives (Intel, Samsung, Toshiba, etc.), then we install only our own developed SSDs in data storage systems.

The microcontroller of the input-output module (smart I / O chip) in storage systems is also a HiSilicon development, as well as a Smart Management Chip for remote storage management. Using our own microchips helps us better understand what happens at each moment in time with each memory cell. This is what allowed us to minimize delays when accessing data in the same Dorado storage systems.

For magnetic disks, constant monitoring is extremely important in terms of reliability. The DHA system (Disk Health Analyzer) is supported in our storage systems: the disk itself continuously records what is happening to it, how well it feels. Due to the accumulation of statistics and the construction of smart predictive models, it is possible to predict the transition of the drive to a critical state in 2-3 months, and not 5-10 days. The disk is still “alive”, the data on it is completely safe - but the customer is ready to replace it at the first signs of a possible failure.
Fail-safe design in the storage system, we have thought through and at the system level. Our Smart Matrix technology is an add-on over PCIe - this bus, on the basis of which intercontroller connections are implemented, is particularly well suited for SSDs.
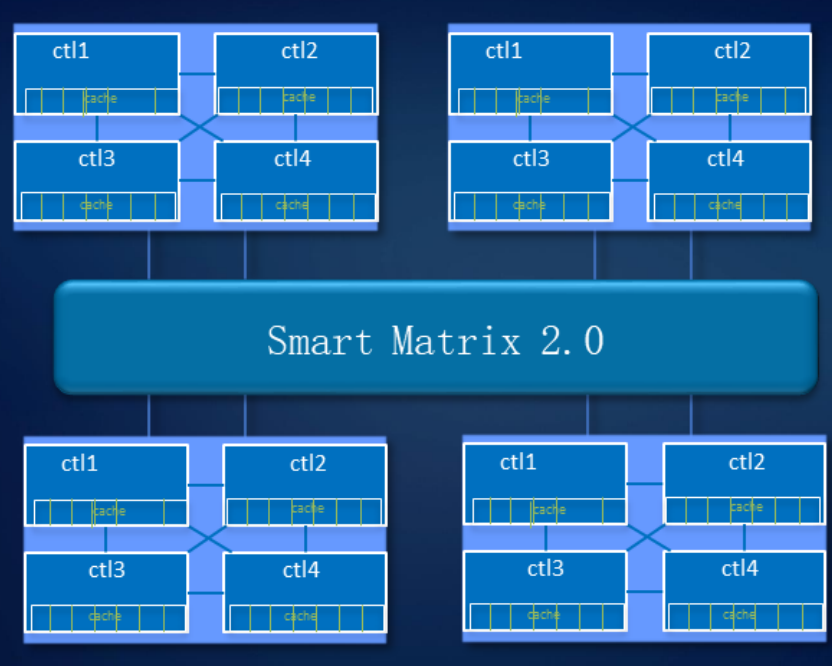
Smart Matrix provides, in particular, 4-controller full mesh in our Ocean Store 6800 v5 storage system. In order for each controller to have access to all disks in the system, we have developed a special SAS backend. The cache, of course, is mirrored between all currently active controllers.

When a controller fails, services from it quickly switch to the mirror controller, and the remaining controllers restore the interconnection to mirror each other. At the same time, the data recorded in the cache memory has a mirror reserve to ensure the reliability of the system.

The system withstands the failure of three controllers. As shown in the figure, if control A fails, the cache data of controller B will select controller C or D for cache mirroring. When controller D fails, controllers B and C mirror the cache.

The RAID 2.0 data distribution system is a standard for our storage systems: disk-level virtualization has long replaced the unsophisticated block copying of content from one medium to another. All disks are grouped into blocks, those are combined into larger conglomerates of a two-tier structure, and logical volumes are built up above its top level, from which RAID arrays are composed.

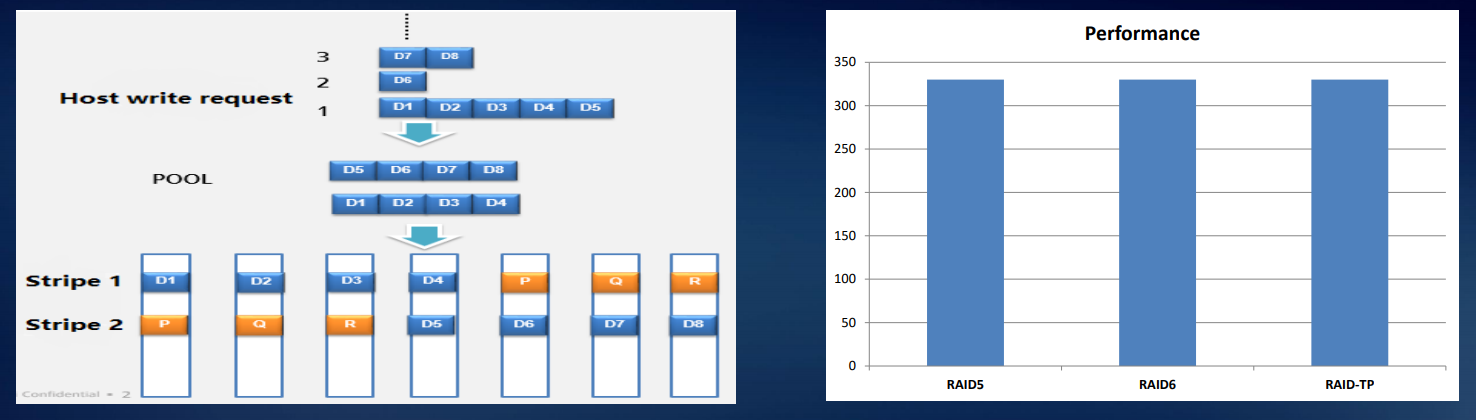
The main advantage of this approach is the shortened rebuild time. In addition, in the event of a disk failure, the rebuilding is performed not on the hot spare disk, but on the free space in all used disks. The figure below shows nine RAID5 hard drives as an example. When hard disk 1 has failed, data CKG0 and CKG1 are damaged. The system selects CK for random reconstruction.

The normal RAID recovery speed is 30 MB / s, so it takes 10 hours to restore 1 TB of data. RAID 2.0+ reduces this time to 30 minutes.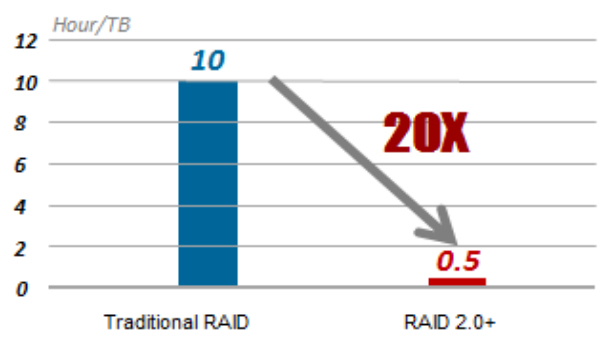
Our developers managed to achieve a uniform load distribution between all spindle drives and SSDs as part of the system. This allows you to unlock the potential of hybrid storage systems much better than the usual use of solid-state drives as a cache.

In Dorado class systems, we implemented the so-called RAID-TP, a triple parity array. Such a system will continue to work with the simultaneous failure of any three disks. This improves reliability compared to RAID 6 by two decimal orders, with RAID 5 by three.
We recommend RAID-TP for especially critical data, especially since, due to RAID 2.0 and high-speed flash drives, this does not have a special effect on performance. Just need more free space to reserve.

As a rule, all-flash systems are used for DBMS with small data blocks and high IOPS. The latter is not very good for SSD: the safety margin of NAND memory cells is quickly exhausted. In our implementation, the system first collects a relatively large block of data in the cache of the drive, and then writes it entirely into cells. This allows you to reduce the load on the disks, as well as in a more sparing mode, to conduct "garbage collection" and freeing up space on the SSD.
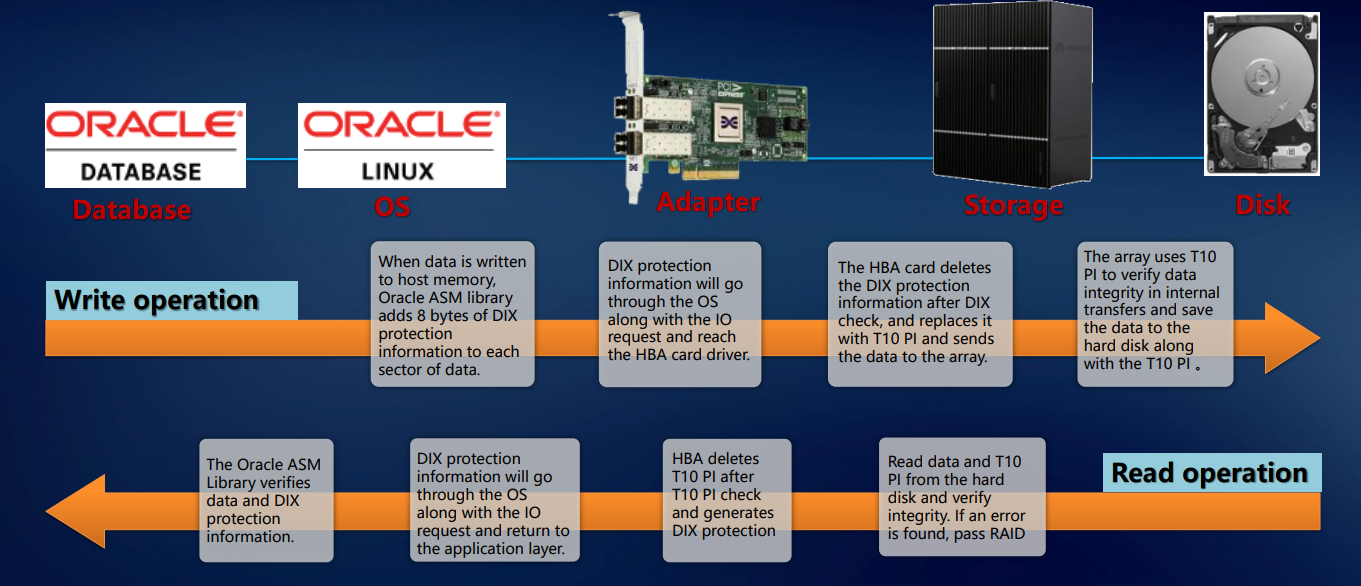
The above allows you to talk about the resiliency of our systems at the level of the entire solution. The check is implemented at the application level (for example, Oracle DBMS), operating system, adapter, storage system - and so on up to the disk. This approach ensures that exactly the block of data that came to the external ports, without any damage and loss will be recorded on the internal disks of the system. This implies an enterprise level.
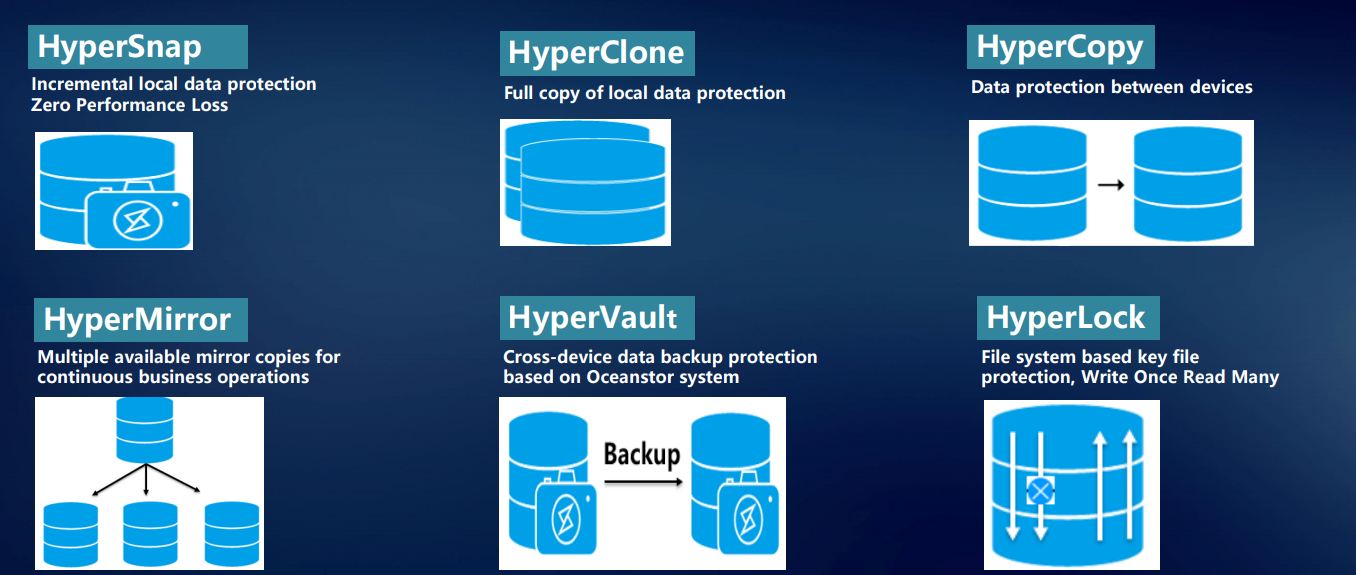
For reliable data storage, protection and recovery, as well as quick access to them, we have developed a number of proprietary technologies.

HyperMetro is probably the most interesting development of the last one and a half years. A ready-made solution based on our storage systems for building a resilient metro cluster is implemented at the controller level; it does not require any additional gateways or servers except an arbitrator. It is implemented simply by a license: two Huawei storage systems plus a license - and it works.

HyperSnap technology provides continuous data protection without loss of performance. The system supports RoW. To prevent data loss on the storage system at any given moment uses a variety of technologies: various snapshots, clones, copies.
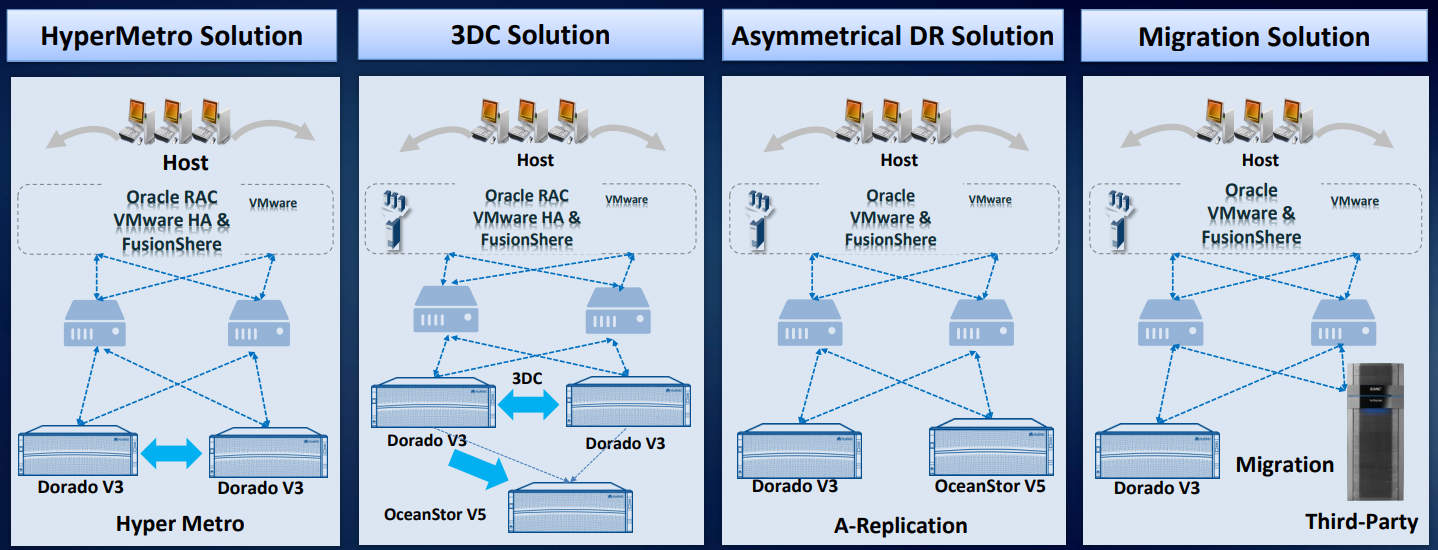
Based on our storage systems, at least four disaster recovery solutions have been developed and tested in practice.
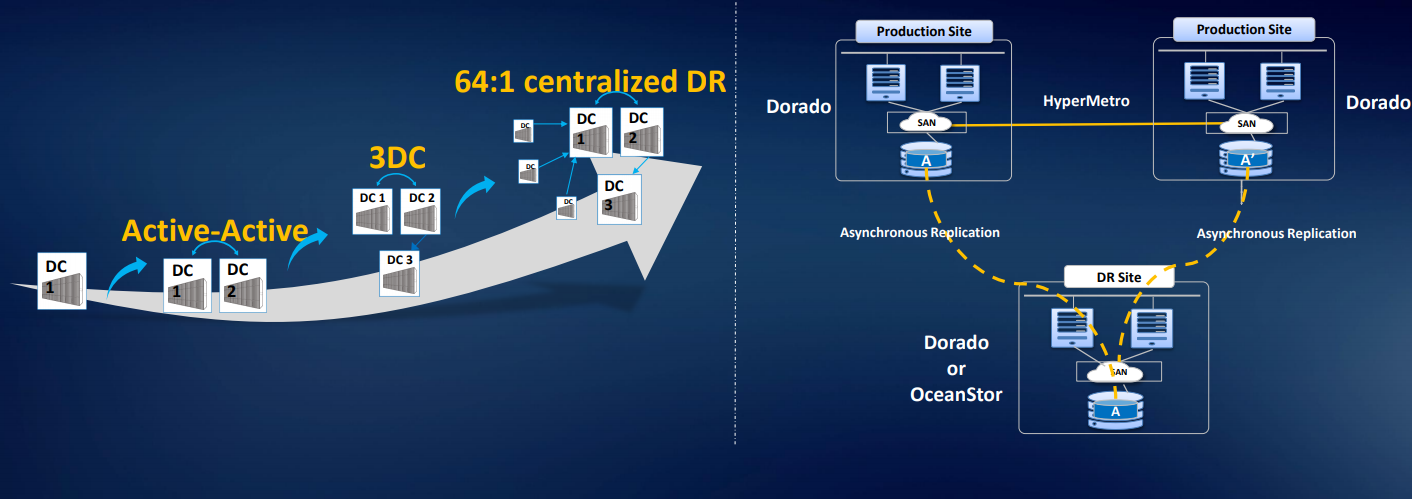
We also have a solution for three 3DC Ring DR Solution data centers: two data centers in a cluster, the third is being replicated. We can organize organized asynchronous replication or migration from third-party arrays. There is a smart virtualization license, so you can use volumes from most standard arrays with access by FC: Hitachi, DELL EMC, HPE, etc. The solution is really worked out, there are analogues on the market, but they are more expensive. There are examples of use in Russia.
As a result, at the level of the entire solution, you can get the reliability of six nines, and at the level of the local storage system, five nines. In general, we tried.
Author: Vladimir Svinarenko, Senior Manager for IT Solutions, Huawei Enterprise in Russia
Under the cut there are a few details about what is so unusual in each of the nodes of the storage system.
What is interesting at the module level
Structurally, all modern storage systems from any manufacturer look the same: controllers are installed in the front part of the steel box chassis, and interface modules are installed in the rear part of the steel box chassis. There are also power supplies and ventilation. It would seem that everything is familiar and standard. But in fact, we have introduced many interesting things into this paradigm.
Let's start with the installation of the elements of the storage system in the chassis. Magnetic 3.5-inch disks in the storage system becomes smaller, hybrid systems and all-flash are beginning to dominate. But even a few disk drives with a spindle speed of up to 15 thousand revolutions per minute create a vibration that cannot be ignored. We have a whole set of recommendations for this case - how to distribute magnetic drives with different parameters across disk shelves.
Even if some fraction of a percentage, but it affects the reliability. And on the scale of a large data center, the percentage of one storage drive turns into tangible indicators of failures and failures. To reduce the vibration of individual discs to a lesser degree through a rigid chassis structure, we equip the drive sled with rubber or metal dampers. To neutralize another source of vibration in the storage system - ventilation modules - we put bidirectional fans, and isolate all the rotating elements from the chassis housing.
For spindle drives, minimal shaking is already a problem: the heads start to stray, performance drops significantly. SSD is another matter, they are not afraid of vibrations. But reliable fixing of the components is still important. Take the delivery process: the box can be dropped or casually thrown, put sideways or upside down. Therefore, all of our storage components are fixed strictly in three dimensions. This eliminates the possibility of their displacement during transportation, prevents the connectors from jumping out of the sockets in case of accidental impact.
Once upon a time we started with the development of computing equipment for the telecom industry, where the standards of performance in terms of temperature and humidity are traditionally high. And we transferred them to other areas: the metal parts of the storage system do not oxidize even at high humidity - due to the use of nickel plating and galvanizing.
The thermal design of our storage systems was developed with a focus on the uniform distribution of temperature across the chassis - in order to prevent either overheating or too much cooling of any corner of the disk shelf. Otherwise, it is impossible to avoid physical deformation - even if it is insignificant, but still violates the geometry and can lead to a reduction in the lifetime of the equipment. Thus, some fractions of a percent are won, but this still affects the overall reliability of the system.
Semiconductor subtleties
We duplicate important storage components: if something fails, there is always a safety net. For example, the power supply modules for the younger models work according to the 1 + 1 scheme, for the more solid ones - 2 + 1 or even 3 + 1.
Controllers that are at least two in the storage system (we do not supply single-controller systems) are also reserved. In the storage system of the 6800th and older series, the reservation is made according to the 3 + 1 scheme, in the younger models - 1 + 1.
Even the management board is reserved, which does not affect the operation of the system directly, but is only needed for configuration changes and monitoring. In addition, any interface storage expansion cards for us are sold only in pairs, so that the client has a reserve.
All components - BP, fans, controllers, management modules, etc. - equipped with microcontrollers capable of responding to certain situations. For example, if the fan starts to slow down by itself, an alarm is sent to the control module. As a result, the customer has a complete picture of the state of the storage system - and, if necessary, can replace some of the components on their own, without waiting for the arrival of our service engineer. And if the customer's security policy allows, we set up the controllers so that they transmit information about the state of iron to our technical support.
Your chips are better and clearer
We are the only company developing our own processors, chips and controllers for solid-state drives for our storage systems.
So, in some models, we use not the classic Intel x86, but the ARM processor of HiSilicon, our subsidiary, as the main processor of the storage system (Storage Controller Chip). The fact is that the ARM architecture in storage - for calculating the same RAID and deduplication - does better than the standard x86.
Our special pride is chips for SSD controllers. And if our servers can be equipped with third-party semiconductor drives (Intel, Samsung, Toshiba, etc.), then we install only our own developed SSDs in data storage systems.
The microcontroller of the input-output module (smart I / O chip) in storage systems is also a HiSilicon development, as well as a Smart Management Chip for remote storage management. Using our own microchips helps us better understand what happens at each moment in time with each memory cell. This is what allowed us to minimize delays when accessing data in the same Dorado storage systems.
For magnetic disks, constant monitoring is extremely important in terms of reliability. The DHA system (Disk Health Analyzer) is supported in our storage systems: the disk itself continuously records what is happening to it, how well it feels. Due to the accumulation of statistics and the construction of smart predictive models, it is possible to predict the transition of the drive to a critical state in 2-3 months, and not 5-10 days. The disk is still “alive”, the data on it is completely safe - but the customer is ready to replace it at the first signs of a possible failure.
RAID 2.0+
Fail-safe design in the storage system, we have thought through and at the system level. Our Smart Matrix technology is an add-on over PCIe - this bus, on the basis of which intercontroller connections are implemented, is particularly well suited for SSDs.
Smart Matrix provides, in particular, 4-controller full mesh in our Ocean Store 6800 v5 storage system. In order for each controller to have access to all disks in the system, we have developed a special SAS backend. The cache, of course, is mirrored between all currently active controllers.
When a controller fails, services from it quickly switch to the mirror controller, and the remaining controllers restore the interconnection to mirror each other. At the same time, the data recorded in the cache memory has a mirror reserve to ensure the reliability of the system.
The system withstands the failure of three controllers. As shown in the figure, if control A fails, the cache data of controller B will select controller C or D for cache mirroring. When controller D fails, controllers B and C mirror the cache.
The RAID 2.0 data distribution system is a standard for our storage systems: disk-level virtualization has long replaced the unsophisticated block copying of content from one medium to another. All disks are grouped into blocks, those are combined into larger conglomerates of a two-tier structure, and logical volumes are built up above its top level, from which RAID arrays are composed.
The main advantage of this approach is the shortened rebuild time. In addition, in the event of a disk failure, the rebuilding is performed not on the hot spare disk, but on the free space in all used disks. The figure below shows nine RAID5 hard drives as an example. When hard disk 1 has failed, data CKG0 and CKG1 are damaged. The system selects CK for random reconstruction.
The normal RAID recovery speed is 30 MB / s, so it takes 10 hours to restore 1 TB of data. RAID 2.0+ reduces this time to 30 minutes.
Our developers managed to achieve a uniform load distribution between all spindle drives and SSDs as part of the system. This allows you to unlock the potential of hybrid storage systems much better than the usual use of solid-state drives as a cache.
In Dorado class systems, we implemented the so-called RAID-TP, a triple parity array. Such a system will continue to work with the simultaneous failure of any three disks. This improves reliability compared to RAID 6 by two decimal orders, with RAID 5 by three.
We recommend RAID-TP for especially critical data, especially since, due to RAID 2.0 and high-speed flash drives, this does not have a special effect on performance. Just need more free space to reserve.
As a rule, all-flash systems are used for DBMS with small data blocks and high IOPS. The latter is not very good for SSD: the safety margin of NAND memory cells is quickly exhausted. In our implementation, the system first collects a relatively large block of data in the cache of the drive, and then writes it entirely into cells. This allows you to reduce the load on the disks, as well as in a more sparing mode, to conduct "garbage collection" and freeing up space on the SSD.
Six nines
The above allows you to talk about the resiliency of our systems at the level of the entire solution. The check is implemented at the application level (for example, Oracle DBMS), operating system, adapter, storage system - and so on up to the disk. This approach ensures that exactly the block of data that came to the external ports, without any damage and loss will be recorded on the internal disks of the system. This implies an enterprise level.
For reliable data storage, protection and recovery, as well as quick access to them, we have developed a number of proprietary technologies.
HyperMetro is probably the most interesting development of the last one and a half years. A ready-made solution based on our storage systems for building a resilient metro cluster is implemented at the controller level; it does not require any additional gateways or servers except an arbitrator. It is implemented simply by a license: two Huawei storage systems plus a license - and it works.
HyperSnap technology provides continuous data protection without loss of performance. The system supports RoW. To prevent data loss on the storage system at any given moment uses a variety of technologies: various snapshots, clones, copies.
Based on our storage systems, at least four disaster recovery solutions have been developed and tested in practice.
We also have a solution for three 3DC Ring DR Solution data centers: two data centers in a cluster, the third is being replicated. We can organize organized asynchronous replication or migration from third-party arrays. There is a smart virtualization license, so you can use volumes from most standard arrays with access by FC: Hitachi, DELL EMC, HPE, etc. The solution is really worked out, there are analogues on the market, but they are more expensive. There are examples of use in Russia.
As a result, at the level of the entire solution, you can get the reliability of six nines, and at the level of the local storage system, five nines. In general, we tried.
Author: Vladimir Svinarenko, Senior Manager for IT Solutions, Huawei Enterprise in Russia