Zig programming language

The first commentary on the wonderful article Subjective Vision of an Ideal Programming Language was the reference to the Zig programming language . Naturally, it became interesting what kind of language it is that claims to be a niche C ++, D and Rust. I looked - the language seemed nice and somewhat interesting. Nice C-like syntax, original approach to error handling, built-in coroutines. This article is a brief overview of the official documentation interspersed with your own thoughts and impressions from the launch of code samples.
Getting started
Compiler installation is quite simple; for Windows, just unpack the distribution kit into some kind of folder. We make a text file hello.zig in the same folder, paste the code from the documentation there and save it. Assembly is performed by the command
zig build-exe hello.zigafter which hello.exe appears in the same directory.
In addition to the assembly, the unit-testing mode is available; for this, the code uses test blocks, and the assembly and running of tests is done by the command
zig test hello.zigThe first oddities
The compiler does not support line wrapping (\ r \ n). Of course, the fact that the line breaks in each system (Win, Nix, Mac) are some kind of their own is wildness and a relic of the past. But there's nothing you can do about it, so just choose for example in Notepad ++ the desired format for the compiler.
The second oddity, which I stumbled upon by accident - tabs are not supported in the code! Only spaces. It happens the same :)
However, this is honestly written in the documentation - the truth is at the very end.
Comments
Another oddity - Zig does not support multi-line comments. I remember that in ancient turbo pascal everything was done correctly - nested multiline comments were supported. Apparently, since then, no language developer has mastered such a simple thing :)
But there are documenting comments. Start with ///. Must be in certain places - in front of the corresponding objects (variables, functions, classes ...). If they are somewhere else, a compilation error. Not bad.
Variable declaration
Done in the now fashionable (and ideologically correct) style, when you first write a keyword (const or var), then a name, then an optional type, and then an initial value. Those. automatic type inference is available. Variables must be initialized - if you do not specify an initial value, there will be a compilation error. However, there is a special value undefined, which can be explicitly used to set uninitialized variables.
var i:i32 = undefined;Console output
For experiments, we need console output - all examples use this method. In the area of plug-ins prescribed
const warn = std.debug.warn;and in the code it is written like this:
warn("{}\n{}\n", false, "hi");There are some bugs in the compiler, which he honestly reports when trying to output an integer or floating point number in this way:
error: compiler bug: it must be casted. github.com/ziglang/zig/issues/557
Data types
Primitive types
The type names are taken from Rust (i8, u8, ... i128, u128), there are also special types for binary compatibility with C, 4 types of floating point types (f16, f32, f64, f128). There is a bool type. There is a type of zero length void and a special noreturn, which I will discuss below.
You can also construct integer types of any length in bits from 1 to 65535. The type name begins with the letter i or u, and then the length is written in bits.
// оно компилируется!
var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;However, I did not manage to display this value on the console - during the compilation process, an error occurred in LLVM.
In general, this is an interesting decision, although ambiguous (IMHO: it’s right to support precisely long numeric literals at the compiler level, but it’s not very good naming of types, it’s better to do it honestly through the template type). And why the limit is 65535? Do libraries like GMP seem to impose such restrictions?
String literals
These are arrays of characters (without a terminating zero at the end). For literals with a terminating zero, the prefix 'c' is used.
const normal_bytes = "hello";
const null_terminated_bytes = c"hello";Like most languages, Zig supports standard escape sequences and the insertion of Unicode characters through their codes (\ uNNNN, \ UNNNNNN where N is a hexadecimal number).
Multiline literals are formed using two backslashes at the beginning of each line. No quotes are required. That is, some attempt to make raw lines, but IMHO is unsuccessful - the advantage of raw lines is that you can insert any piece of text into the code from anywhere - and ideally you don’t change anything, but here you’ll have to add \\ at the beginning of each line.
const multiline =
\\#include <stdio.h>
\\
\\int main(int argc, char **argv) {
\\ printf("hello world\n");
\\ return 0;
\\}
;Integer literals
All as in si-like languages. I am very pleased that the octal literals use the prefix 0o, and not just zero as in C. Binary literals with the prefix 0b are also supported. Floating point literals can be hexadecimal (as is done in the GCC extension ).
Operations
Of course, there are standard arithmetic, logical and bitwise C operations. Abbreviated operations are supported (+ =, etc.). Instead of && and || keywords and and or are used. An interesting point - additionally supported operations with guaranteed overflow semantics (wraparound semantics). They look like this:
a +% b
a +%= bIn this case, the usual arithmetic operations do not guarantee overflow and their results in the case of overflow are considered undefined (and for constants compilation errors are issued). IMHO is a bit strange, but apparently made of some deep considerations of compatibility with the semantics of the C language.
Arrays
Array literals look like this:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' };
const arr = []i32{ 1, 2, 3, 4 };Strings are arrays of characters, as in C. Indexing is a classic square brackets. The operations of addition (concatenation) and multiplication of arrays are provided. A very interesting thing, and if everything is clear with concatenation, then multiplication - I waited until someone implements it, and I waited :) In Assembler (!) There is a dup operation that allows you to generate repetitive data. Now in Zig:
const one = []i32{ 1, 2, 3, 4 };
const two = []i32{ 5, 6, 7, 8 };
const c = one ++ two; // { 1,2,3,4,5,6,7,8 }
const pattern = "ab" ** 3; // "ababab"Pointers
The syntax is similar to C.
var x: i32 = 1234; // объект
const x_ptr = &x; // взятие адресаFor dereferencing (taking values on the pointer), an unusual postfix operation is used:
x_ptr.* == 5678;
x_ptr.* += 1;Pointer type is explicitly set by setting an asterisk in front of the type name.
const x_ptr : *i32 = &x;Slices (slices)
A data structure built into the language that allows reference to an array or part of it. Contains a pointer to the first element and the number of elements. It looks like this:
var array = []i32{ 1, 2, 3, 4 };
const slice = array[0..array.len];It seems to be taken from Go, not sure. And also I'm not sure if it was worth building it into the language, despite the fact that the implementation in such an OOP language of such a thing is quite elementary.
Structures
An interesting way to declare a structure is to declare a constant, the type of which is automatically displayed as “type” (type), and that is what is used as the name of the structure. And the structure itself (struct) "nameless."
const Point = struct {
x: f32,
y: f32,
};The name cannot be set in the usual way in C-like languages, but the compiler displays the name of the type according to certain rules - in particular, in the above case it will be the same as the "type" constant.
In general, the language does not guarantee the order of fields and their alignment in memory. If guarantees are needed, then “packed” structures should be used.
const Point2 = packed struct {
x: f32,
y: f32,
};Initialization - in the style of sishnyh designists:
const p = Point {
.x = 0.12,
.y = 0.34,
};Structures may have methods. However, placing a method in a structure is simply using the structure as a namespace; unlike C ++, no implicit this arguments are passed.
Transfers
In general, the same as in C / C ++. There are some convenient built-in means of accessing meta-information, for example, the number of fields and their names, implemented by syntax macros built into the language (which are called builtin functions in the documentation).
For "binary compatibility with C" provides some extern enums.
To specify the type that should be the basis of the listing, the following construction is used:
packed enum(u8)where u8 is the base type.
Enumerations can have methods, like structures (i.e. use the name of the enumeration as a namespace).
Unions
As I understand it, the union in Zig is an algebraic type-sum, i.e. contains a hidden tag field that identifies which of the join fields is “active.” “Activation” of another field is performed by complete reassignment of the whole union. Example from documentation
const assert = @import("std").debug.assert;
const mem = @import("std").mem;
const Payload = union {
Int: i64,
Float: f64,
Bool: bool,
};
test "simple union" {
var payload = Payload {.Int = 1234};
// payload.Float = 12.34; // ОШИБКА! поле не активно
assert(payload.Int == 1234);
// переприсваиваем целиком для изменения активного поля
payload = Payload {.Float = 12.34};
assert(payload.Float == 12.34);
}Associations can also explicitly use enums for a tag
// Unions can be given an enum tag type:
const ComplexTypeTag = enum { Ok, NotOk };
const ComplexType = union(ComplexTypeTag) {
Ok: u8,
NotOk: void,
};Associations, like enumerations and structures, can also provide their own namespace for methods.
Optional Types
Zig has built-in support for optionals. A question mark is added in front of the type name:
const normal_int: i32 = 1234; // normal integer
const optional_int: ?i32 = 5678; // optional integerInterestingly, one thing is implemented in Zig, the possibility of which I suspected, but I was not sure whether it was right or not. Pointers are made compatible with optionals without adding an additional hidden field (“tag”), which stores the sign of the validity of the value; null is used as an invalid value. Thus, the reference types represented in Zig by pointers do not even require additional memory for “optionalness”. In this case, the assignment of the usual pointers to null is prohibited.
Types of errors
Similar to optional types, but instead of a boolean tag ("really-invalid"), an enumeration element is used that corresponds to the error code. The syntax is similar to optionals, an exclamation mark is added instead of a question mark. Thus, these types can be used, for example, to return from functions: either the result object of the successful operation of the function is returned, or an error with the corresponding code. Error Types are an important part of the Zig language error handling system, more details in the Error Handling section.
Void type
Variables of type void and operations with them are possible in Zig.
var x: void = {};
var y: void = {};
x = y;no code is generated for such operations; This type is mainly useful for metaprogramming.
There is also a c_void type for C compatibility.
Control Operators and Functions
These include: blocks, switch, while, for, if, else, break, continue. To group the code using standard braces. Just as in C / C ++, blocks are used to limit the scope of variables. Blocks can be viewed as expressions. There is no goto in the language, but there are labels that can be used with the break and continue operators. By default, these operators work with cycles, but if the block has a label, you can use it.
var y: i32 = 123;
const x = blk: {
y += 1;
break :blk y; // прерывания блока blk и возврат y
};The switch statement differs from the switch in that there is no “fallthrough” in it, i.e. only one condition is executed (case) and the switch is exited. The syntax is more compact: instead of the case, the arrow "=>" is used. Switch can also be considered as an expression.
The while and if statements are generally the same as in all C-like languages. The for statement is more like foreach. All of them can be considered as expressions. Of the new features, while and for, as well as if, can have an else block, which is executed if there has been no iteration of the loop.
And here it is time to talk about one common feature for the switch, while, which is in some way borrowed from the concept of foreach cycles - “capturing” variables. It looks like this:
while (eventuallyNullSequence()) |value| {
sum1 += value;
}
if (opt_arg) |value| {
assert(value == 0);
}
for (items[0..1]) |value| {
sum += value;
}
Here, the while argument is a kind of “source” of data that can be optional, for for an array or slice, and in a variable located between two vertical lines there is a “unwrapped” value — that is, the current element of the array or slice (or a pointer to it), the internal value of an optional type (or a pointer to it).
Operators defer and errdefer
The deferred operator borrowed from Go. It works the same way - the argument of this operator is executed when leaving the scope in which the operator is used. Additionally, an errdefer operator is provided, which works if an error type is returned from the function with an active error code. This is part of the original error handling system in Zig.
Unreachable operator
Element of contract programming. A special keyword that is put where control should not come under any circumstances. If it does come there, then in the Debug and ReleaseSafe modes, a panic is generated, and in ReleaseFast the optimizer throws out these branches completely.
noreturn
Technically, it is a type that is compatible with any other type in expressions. This is possible due to the fact that there will never be a return of this type of object. Since in Zig operators are expressions, we need a special type for expressions that will never be evaluated. This happens when the right-hand side of the expression irrevocably transfers control somewhere outside. These include break, continue, return, unreachable, infinite loops and functions that never return a control. For comparison, a call to a normal function (returning control) is not a noreturn operator, because control, though transferred outside, will be returned to the call point sooner or later.
Thus, such expressions become possible:
fn foo(condition: bool, b: u32) void {
const a = if (condition) b else return;
@panic("do something with a");
}The variable a gets the value returned by the if / else operator. For this, the parts (and if and else) must return an expression of the same type. The if part returns bool, the else part is of type noreturn, which is technically compatible with any type, as a result, the code is compiled without errors.
Functions
The syntax is classical for languages of this type:
fn add(a: i8, b: i8) i8 {
return a + b;
}In general, the functions look pretty standard. So far I have not noticed signs of first-class functions, but my acquaintance with the language is very superficial, I can be wrong. Although perhaps this is not done yet.
Another interesting feature is that in Zig, you can only ignore returned values explicitly with the underscore _
_ = foo();The reflection is provided, allowing to receive various information on function
const assert = @import("std").debug.assert;
test "fn reflection" {
assert(@typeOf(assert).ReturnType == void); // тип возвращаемого значения
assert(@typeOf(assert).is_var_args == false); // переменное число аргументов
}Code execution at compile time
Zig provides the most powerful opportunity - the execution of code written in zig during compilation. In order for the code to be executed at compile time, it is enough to enclose it in a block with the comptime keyword. The same function can be called both at compile time and at run time, which allows you to write universal code. Of course, there are some limitations associated with different contexts of the code. For example, in the documentation in a variety of examples, comptime is used for compile-time checks:
// array literal
const message = []u8{ 'h', 'e', 'l', 'l', 'o' };
// get the size of an array
comptime {
assert(message.len == 5);
}But of course the power of this operator is far from being fully disclosed. Thus, the description of the language provides a classic example of the effective use of syntax macros - the implementation of a function similar to printf, but which parses the format string and performs all the necessary types of arguments at the compilation stage.
Also, the word comptime is used to specify the parameters of the compile-time functions, which is similar to the C ++ template functions.
параметры времени компиляции
fn max(comptime T: type, a: T, b: T) T {
return if (a > b) a else b;
}Error processing
In Zig, an original error-handling system was developed. This can be called “explicit exceptions” (in this language, explicitness is generally one of the idioms). This is also similar to return codes in Go, but everything is different.
The Zig error handling system is based on special enumerations for implementing custom error codes (error) and “types-errors” built on their basis (an algebraic type-sum combining the return type of a function and an error code).
Error enumerations are announced in the same way as ordinary enumerations:
const FileOpenError = error {
AccessDenied,
OutOfMemory,
FileNotFound,
};
const AllocationError = error {
OutOfMemory,
};However, all error codes get values greater than zero; also, if you declare a code with the same name in two enums, it will receive the same value. However, implicit conversions between different error enumerations are prohibited.
The keyword anyerror means an enumeration that includes all error codes.
Like optional types, the language supports the formation of error types using special syntax. The type! U64 is the abbreviated form of anyerror! U64, which in turn means a union (variant), including the type u64 and the type anyerror (as I understand it, code 0 is reserved for the absence of an error and the validity of the data field, the remaining codes are proper error codes).
The catch keyword allows you to catch the error and turn it into a default value:
const number = parseU64(str, 10) catch 13;So, if an error occurs in the parseU64 function that returns the type! U64, then catch will “catch” it and return the default value of 13.
The try keyword allows you to “forward” the error to the upper level (that is, to the level of the calling function). View Code
fn doAThing(str: []u8) !void {
const number = try parseU64(str, 10);
// ...
}equivalent to this:
fn doAThing(str: []u8) !void {
const number = parseU64(str, 10) catch |err| return err;
// ...
}Here the following happens: parseU64 is called, if an error is returned from it - it is intercepted by the catch operator, in which the error code is extracted using the “capture” syntax, placed in the err variable, which is returned via! Void to the calling function.
Also, the errdefer operator described earlier applies to error handling. Code that is an errdefer argument is executed only if the function returns an error.
Some more features. Using the operator || you can merge error sets
const A = error{
NotDir,
PathNotFound,
};
const B = error{
OutOfMemory,
PathNotFound,
};
const C = A || B;Zig also provides the ability to trace errors. This is something like stack trace, but containing detailed information about what error occurred and how it spread through the try chain from the origin to the main function of the program.
Thus, the error handling system in Zig is a very original solution, not like any exceptions in C ++, nor return codes to Go. It can be said that such a solution has a certain price — an additional 4 bytes, which must be returned with each return value; obvious advantages - absolute clarity and transparency. Unlike C ++, here the function cannot throw an unknown exception from somewhere in the depth of the call chain. All that the function returns is that it returns explicitly and only explicitly.
Coroutines
Zig has built-in coroutines. These are functions that are created with the async keyword, through which the functions of the allocator and the allocator are transferred (as I understand it, for an additional stack).
test "create a coroutine and cancel it" {
const p = try async<std.debug.global_allocator> simpleAsyncFn();
comptime assert(@typeOf(p) == promise->void);
cancel p;
assert(x == 2);
}
async<*std.mem.Allocator> fn simpleAsyncFn() void {
x += 1;
}async returns a special object of type promise-> T (where T is the return type of the function). With this object you can control coroutine.
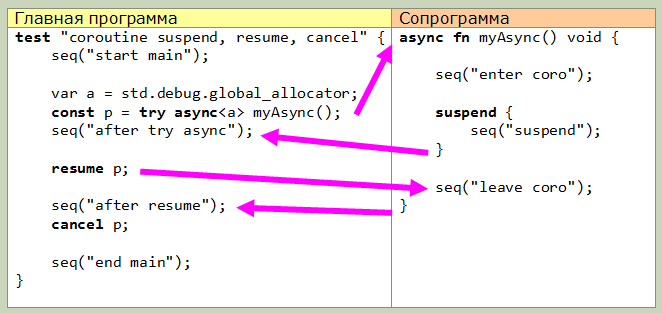
The lowest level includes the keywords suspend, resume, and cancel. Using suspend, the coroutine execution is suspended and passed to the caller. The syntax of the suspend block is possible, everything inside the block is executed until the coroutine is actually suspended.
resume accepts an argument of type promise-> T and resumes the execution of the coroutine from the point at which it was suspended.
Cancel frees coroutine memory.
This picture shows the transfer of control between the main program (in the form of a test) and the coroutine. Everything is quite simple:
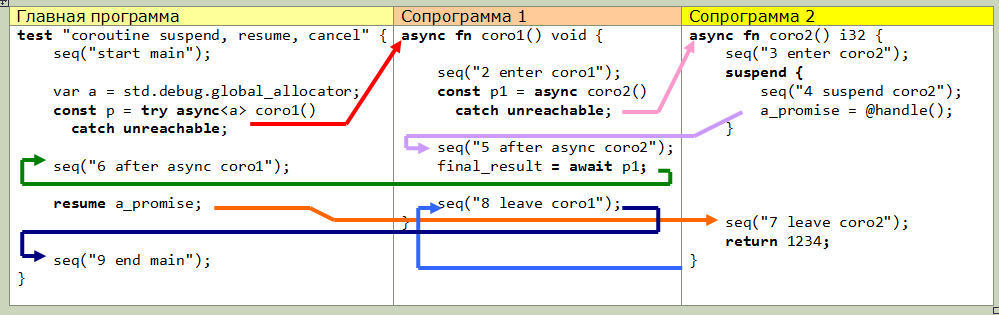
The second (higher level) feature is the use of await. This is the only thing that I honestly did not figure out (alas, the documentation is still very scarce). Here is the actual transfer control chart of a slightly modified example from the documentation, maybe you can explain this to something:
Built-in functions
builtin functions - a fairly large set of functions that are built into the language and do not require the connection of any modules. It may be more correct to call some of them “embedded syntax macros”, because the possibilities of many go far beyond the limits of functions. builtin'y provide access to the means of reflection (sizeOf, tagName, TagType, typeInfo, typeName, typeOf), with them using plug-ins (import). Others are more like classic C / C ++ builtins — they implement low-level type conversions, various operations such as sqrt, popCount, slhExact, and so on. It is very likely that the list of built-in functions will change as the language develops.
In conclusion
It is very pleasant that such projects appear and develop. Although the C language is convenient, concise and familiar to many, it is still outdated and for architectural reasons cannot support many modern programming concepts. C ++ is developing, but objectively over-complicated, it becomes more and more difficult with each new version, and for the same architectural reasons and because of the need for backward compatibility, nothing can be done about it. Rust is interesting, but with a very high threshold of entry, which is not always justified. D is a good attempt, but quite a few minor issues, it seems that the language was originally created rather under the impression of Java, and the subsequent features were introduced somehow not as it should. Obviously, Zig is another such attempt. The language is interesting, and it is interesting to see what comes out of it in the end.









