Audio Analysis and Image Processing Algorithms
- Transfer

Today we’ll talk about the highlights of Jack Minardi’s research, which he talked about on his personal blog. We decided to introduce you to the key points of Jack's work. If you just want to take a look at the program code, proceed to the repository on GitHub . For the preparation of materials used IPython Notebook .
The subject of visualization and image processing in order to obtain sound is quite popular. Most recently, we talked about Patrick Fister and his story about an archival find at Indiana University in Bloomington - more than half a million sound recordings, videos and film films, some of which can be considered as the oldest media carriers.
Patrick talked about the following process of reproducing sound from an image: scanning the original with high resolution; “Straightening” a circular image using the transformation from polar coordinates to Cartesian; "Attachment" of individual lines one after another. Next, download to ImageToSound, convert to WAV format and combine paired WAV audio tracks into a stereo file.
In another material, sound and music are considered from the point of view of mathematics and programming: for the writing of music, machine learning and Markov chains were used. This approach allows us to appreciate the multifaceted nature of all that we are used to listening to on the way to work or at home. In this article, we will consider audio analysis from another perspective.
Can I use image processing algorithms outside the usual area? For example, use the method of matching patterns and images to generate sound: determine the audio recording in the database, of which the audio sample is a part, using the mask comparison method.
A simple comparison algorithm with a mask sequentially superimposes it on the image and performs a comparison. The match_template function in skimage.feature does this . It gives a very low chance of matching the template with a portion of the image.
Sensitivity to the shift of the time range can be minimized if we abstract from the timeline and go to the signal level. This is done using the discrete Fourier transform (DFT).More on this .
At its core, the Fourier transform tells us which of the signal frequencies has the highest energies. Since the harmonics of the audio signal usually change over time, the spectrogram contains the properties of the time and frequency domains.
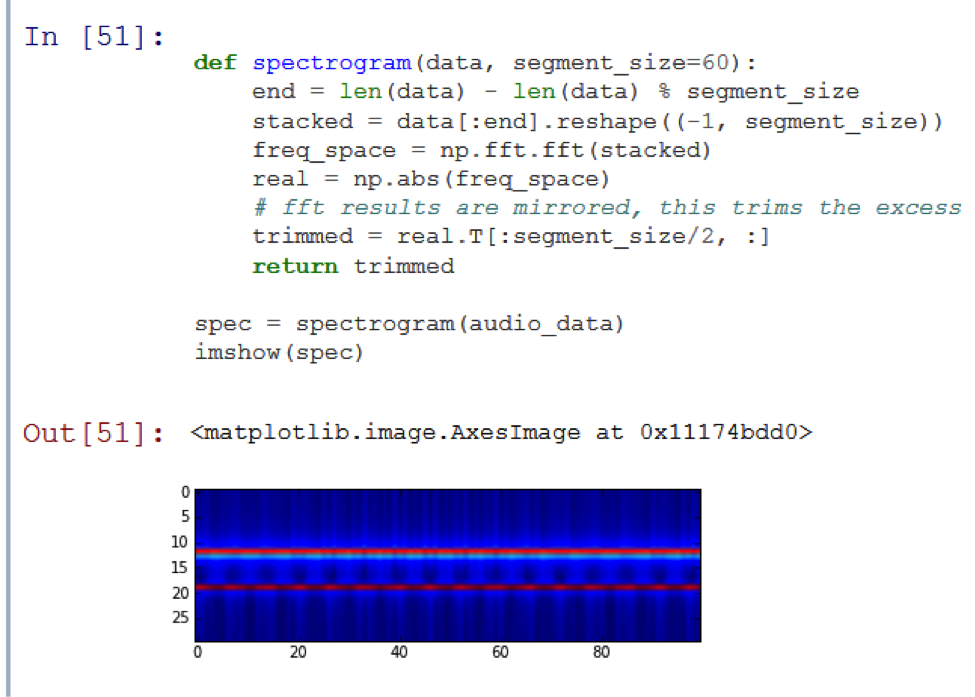
Two horizontal lines are visible in the picture: the audio consists of a combination of two unchanging signals.
How can I help the system determine which episode of a predefined series is being played? Jack's comparison algorithm, in its original version, could do this in 20 seconds, but a man named Harry Nyquist came to his aid. Then, resampling was performed in step 8 so as not to lose too much important information. Runtime decreased by 15 times.
Quantization gave an additional 4 times acceleration, while still maintaining a good signal to noise ratio. Thus, the program correctly recognized the first episode of the season that Jack downloaded. The algorithm was able to identify the first of 11 episodes of the Adventure Time series with sufficient accuracy and in less than 3 seconds.
Jack's application may not be implemented in the best way, but it solves its problem. The classic approach turned out to be the most understandable and simple to implement. Sub-sampling was not tied to the specific type of audio used, but it could ruin everything when a different sound source was connected. In further work, it is worth paying extra attention to this.