How to add an index on a loaded system 24/7 without downtime?
Friends, at the end of January we will start a new course called “MS SQL Server Developer ”. On the eve of its launch, we asked the course teacher, Kristina Kucherova , to prepare an author's article. This article will be useful to you if you have a very popular spreadsheet with 24/7 access and suddenly you realize that you urgently need to add an index and do not break anything in the process.
So what to do? The traditional way of CREATE INDEX WITH (ONLINE = ON) does not suit you, because, for example, it causes a fall in the system and a heart attack of your DBA, all tops keep a close eye on the response time of your system and, if they increase, they come to you and your DBA to talk about the high figures of your compensation for work.
The scripts and techniques described were used on a 400K request per minute system, versions of SQL Server 2012 and 2016 (Enterprise).
There are two very different index creation approaches that are used depending on the size of the table.
A table of 50 thousand records (small), but very popular (several thousand hits per minute). You need a new index and minimal downtime and locks on the table.
In the application, all access to the database is only through procedures.
If an error occurs, the application will try again to access the table.

What is the problem to apply this index is simple, you ask? With the clause WITH ONLINE = ON (yes, we were lucky, and this one was Enterprise).
The fact is that with such active access, it takes some time to get a lock (even the minimum one needed with the option with Online = ON). In the process of waiting, new requests are queued, the queue is being accumulated, the CPU is growing, the DBA is sweating and nervously squinting towards the developers, while your response time smoothly but inevitably begins to increase on the monitoring graphs of the application. Your Vice President of Engeneering is gently wondering whether it will happen because of this increase in response time of some system downtime, that at the end of the year the availability of the application will be evaluated not 5 nines (99,999), but lower? And then the company has contracts, obligations and heavy fines in the case of reduced availability, and, of course, let's not forget about reputational losses.
What have we done to avoid this regrettable situation?
The index system is still needed.
They took the rights from everyone except the current session to this table.
Applied index.
Yes, the solution has a minus: everyone who turned to the table in those seconds will get Access Denied. If your application handles this situation normally and retries the database request, then you should take a closer look at this option. In the case of our project, this method worked perfectly. Again, you can safely remove ONLINE = ON, since we know that during the creation of the index, only this session will have access to the table.
Code to apply the index:
Graph of response time and error rate during testing under load.
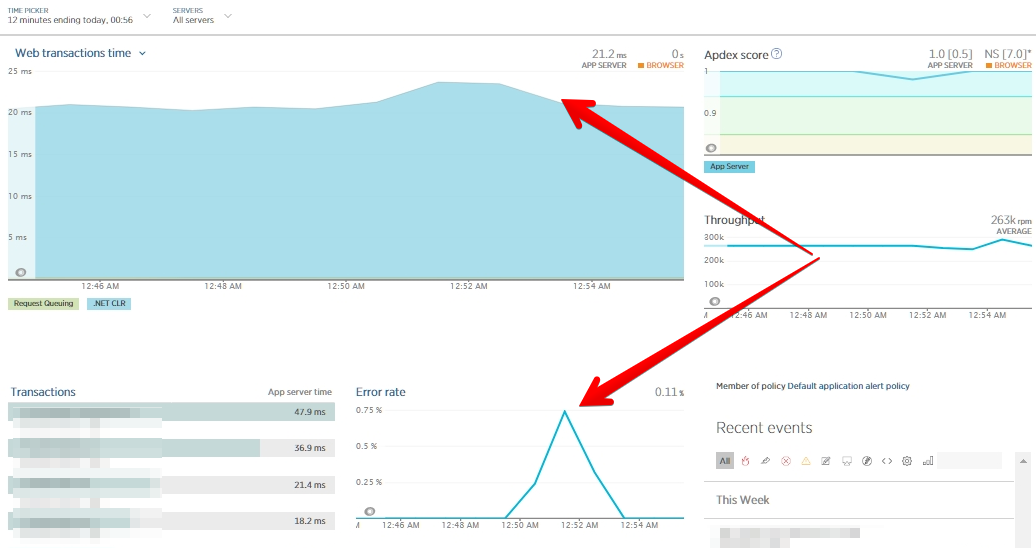
The method can be applied if you have, as in the case described, a small table, and you know that without a load, an index will be created in seconds (or in a reasonable time for you). At the same time, as you can see from the graph above, the response time of the application will not grow, although it can be seen that the error rate per second without access to the table was higher.
If you have a large table and you need to change the indexes on it, then often the most painless way to sell is to create a table with the correct index next to it and gradually transfer the data to a new table.
There are 2 ways to do this:
A bit more detailed option is about rewriting calls to a new table:
In step 2, it was possible, if the load allows, to rename the main table Orders -> OrdersOld, and OrdersView -> Orders and the view itself to OrdersOld UNION ALL OrdersNew, then there is no need to change all the places where there is a selection from the table.
When transferring blocks from one table to another, the data will be fragmented.
If a variable table is actively used for reading, but the data in it rarely changes, you can again use triggers - write a copy of all changes to the third table - transfer data from the table via bcp out and bcp in (or bulk insert) to a new table , create indexes on it after data transfer and then apply the changes from the table with the change log - and switch one table on the other - the current one, renaming it to TableOld, and the new one from TableNew to Table.
The probability of errors in this situation is somewhat higher, so test the application of changes and different switching cases in this case.
The options described are not the only ones. They were used by me on a highly loaded SQL Server database and did not cause problems in the application, which pleased our DBA team. Such bouncing is usually not needed for bases with a more relaxed load, when you can safely apply the changes in the hours of lowest activity. The users of the project, in which the described approaches were used, are located in the USA and Europe and actively use the application on weekdays and weekends, and the tables on which the changes were applied are constantly used in the work. More “quiet” objects were usually modified by automatic scripts generated via the Redgate Toolkit after the developer reviewed the script and one of the DBAs.
All good! Share in the comments, did you use any of these methods, or describe your method! We also invite you to an open lesson and open day of our new course “MS SQL Server Developer”
So what to do? The traditional way of CREATE INDEX WITH (ONLINE = ON) does not suit you, because, for example, it causes a fall in the system and a heart attack of your DBA, all tops keep a close eye on the response time of your system and, if they increase, they come to you and your DBA to talk about the high figures of your compensation for work.
The scripts and techniques described were used on a 400K request per minute system, versions of SQL Server 2012 and 2016 (Enterprise).
There are two very different index creation approaches that are used depending on the size of the table.
Case № 1. Small, but very popular table
A table of 50 thousand records (small), but very popular (several thousand hits per minute). You need a new index and minimal downtime and locks on the table.
In the application, all access to the database is only through procedures.
If an error occurs, the application will try again to access the table.
What is the problem to apply this index is simple, you ask? With the clause WITH ONLINE = ON (yes, we were lucky, and this one was Enterprise).
The fact is that with such active access, it takes some time to get a lock (even the minimum one needed with the option with Online = ON). In the process of waiting, new requests are queued, the queue is being accumulated, the CPU is growing, the DBA is sweating and nervously squinting towards the developers, while your response time smoothly but inevitably begins to increase on the monitoring graphs of the application. Your Vice President of Engeneering is gently wondering whether it will happen because of this increase in response time of some system downtime, that at the end of the year the availability of the application will be evaluated not 5 nines (99,999), but lower? And then the company has contracts, obligations and heavy fines in the case of reduced availability, and, of course, let's not forget about reputational losses.
What have we done to avoid this regrettable situation?
The index system is still needed.
They took the rights from everyone except the current session to this table.
Applied index.
Yes, the solution has a minus: everyone who turned to the table in those seconds will get Access Denied. If your application handles this situation normally and retries the database request, then you should take a closer look at this option. In the case of our project, this method worked perfectly. Again, you can safely remove ONLINE = ON, since we know that during the creation of the index, only this session will have access to the table.
Code to apply the index:
REVOKEEXECUTEON [dbo].[spUserLogin] TO [User1]
REVOKEEXECUTEON [dbo].[spUserLogin] TO [User2]
REVOKEEXECUTEON [dbo].[spUserCreate] TO [User1]
REVOKEEXECUTEON [dbo].[spUserCreate] TO [User2]
CREATE NONCLUSTERED INDEX IX_Users_Email_Status
ON [dbo].[Users] ([Email],[Status]);
GRANTEXECUTEON [dbo].[spUserCreate] TO [User1]
GRANTEXECUTEON [dbo].[spUserCreate] TO [User2]
GRANTEXECUTEON [dbo].[spUserLogin] TO [User1]
GRANTEXECUTEON [dbo].[spUserLogin] TO [User2]
Graph of response time and error rate during testing under load.
The method can be applied if you have, as in the case described, a small table, and you know that without a load, an index will be created in seconds (or in a reasonable time for you). At the same time, as you can see from the graph above, the response time of the application will not grow, although it can be seen that the error rate per second without access to the table was higher.
Case number 2. Large table
If you have a large table and you need to change the indexes on it, then often the most painless way to sell is to create a table with the correct index next to it and gradually transfer the data to a new table.
There are 2 ways to do this:
- If you have a special procedure for changing the table, you simply change the procedure code so that new data is inserted into the new table only, deletion comes from both, update is also applied to both, and the sample is taken from two tables from UNION ALL.
- If you have many different parts of the code where you can change the data in the table, then there are two popular methods: view with triggers or rewrite all parts of the code to insert data into a new table, delete from both, and update both tables. A view with triggers is an option when you create a twist with two tables and rename your table, rename it to TableOld, and twist it to Table. Then you automatically get all the references to the table to the view, there may also be a problem with rename, because you need SchemaLock, but rename goes very quickly.
A bit more detailed option is about rewriting calls to a new table:
- You have an Orders table, create a new OrdersNew table with the same schema, but with the desired index. At the same time, if you use Indentity, then you need to set the first identity value in the new table to be equal to the maximum value in the old table + change step or the gap that you can afford to deviate from the maximum value in Orders.
- Create the OrdersView view, inside of which a selection of Orders UNION ALL OrdersNew
- Modify all procedures / calls to fetch data from a view, insert into OrdersNew, delete and modify both tables.
- Migrating data from an old table to a new one, for example, like this:
DECLARE @rowcount INT, @batchsize INT = 4999; SET IDENTITY_INSERT dbo.OrdersNew ON; SET @rowcount = @batchsize; WHILE @rowcount = @batchsize BEGINBEGIN TRY DELETE TOP (@batchsize) FROM dbo.Orders OUTPUT deleted.Id ,deleted.Column1 ,deleted.Column2 ,deleted.Column3 INTO dbo.OrdersNew (Id ,Column1 ,Column2 ,Column3); SET @rowcount = @@ROWCOUNT; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage; THROW; END CATCH; END; SET IDENTITY_INSERT dbo.OrdersNew OFF; - Return all procedures to the version before the migration - with one table. This can be done through alter or through the removal and creation of procedures (then do not forget about the rights), and you can rename the new table to Orders, removing the empty table and view.
In step 2, it was possible, if the load allows, to rename the main table Orders -> OrdersOld, and OrdersView -> Orders and the view itself to OrdersOld UNION ALL OrdersNew, then there is no need to change all the places where there is a selection from the table.
When transferring blocks from one table to another, the data will be fragmented.
If a variable table is actively used for reading, but the data in it rarely changes, you can again use triggers - write a copy of all changes to the third table - transfer data from the table via bcp out and bcp in (or bulk insert) to a new table , create indexes on it after data transfer and then apply the changes from the table with the change log - and switch one table on the other - the current one, renaming it to TableOld, and the new one from TableNew to Table.
The probability of errors in this situation is somewhat higher, so test the application of changes and different switching cases in this case.
The options described are not the only ones. They were used by me on a highly loaded SQL Server database and did not cause problems in the application, which pleased our DBA team. Such bouncing is usually not needed for bases with a more relaxed load, when you can safely apply the changes in the hours of lowest activity. The users of the project, in which the described approaches were used, are located in the USA and Europe and actively use the application on weekdays and weekends, and the tables on which the changes were applied are constantly used in the work. More “quiet” objects were usually modified by automatic scripts generated via the Redgate Toolkit after the developer reviewed the script and one of the DBAs.
All good! Share in the comments, did you use any of these methods, or describe your method! We also invite you to an open lesson and open day of our new course “MS SQL Server Developer”