Gameboy based supercomputer
- Transfer
With a speed of more than 1 billion frames per second, this is arguably the fastest of 8-bit console clusters in the world.
Distributed Tetris (1989)
Take a handful of silicon, apply training with reinforcements, experience with supercomputers, a passion for computer architecture, add sweat and tears, stir for 1000 hours until it boils - and voila.
In short: to move towards enhancing artificial intelligence.

One of the 48 IBM Neural Computer boards used for experimentation
2016 year. Deep learning is everywhere. Image recognition can be considered a solved problem due to convolutional neural networks, and my research interests tend to neural networks with memory and learning with reinforcement.
Specifically, Google Deepmind authorship showed that you can reach a person’s level or even surpass it in various games for the Atari 2600 (a home game console released in 1977) using a simple learning algorithm supported by the Deep Q-Neural Network. And all this happens just when viewing the gameplay. It caught my attention.
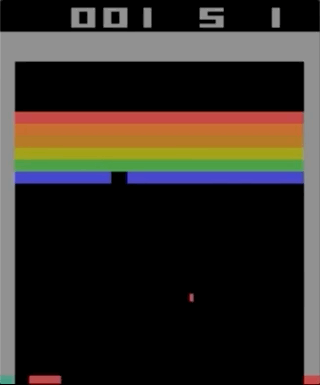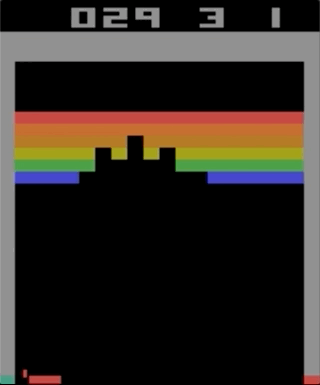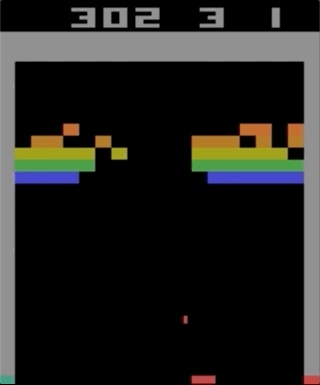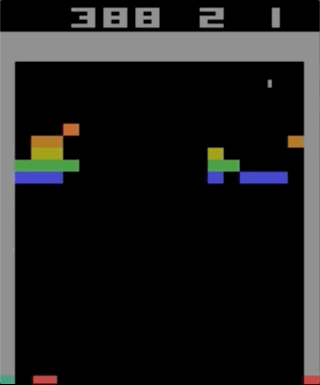
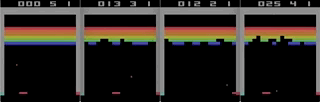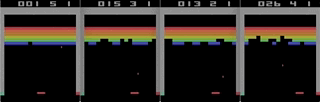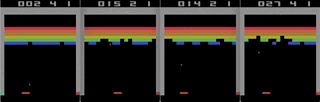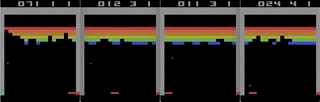
One of the games with the Atari 2600, Breakout. The machine was trained using a simple reinforcement learning algorithm. After millions of iterations, the computer began to play better than humans.
I started experimenting with Atari 2600 games. Breakout, while impressive, cannot be called difficult. Complexity can be determined by the degree of complexity in accordance with your actions (joystick) to your results (points). The problem appears when the effect must wait for quite some time.

Illustration of the problem on the example of more complex games. On the left - Breakout (ATARI 2600) [the author was mistaken, this is the game Pong / approx. trans.] with very fast response and fast feedback. On the right, Mario Land (Nintendo Game Boy) does not provide instant information about the consequences of an action, and long periods of irrelevant observations may appear between two important events.
To make learning more effective, one can imagine attempts to transfer some of the knowledge from simpler games. This task now remains unsolved, and is an active topic for research. A recently published task from OpenAI is trying to measure just that.
The ability to transfer knowledge would not only accelerate training - I believe that some learning problems cannot be solved at all in the absence of basic knowledge. We need data efficiency. Take the game Prince of Persia:

There are no obvious points in it.
To complete the game, it takes 60 minutes.

Is it possible to apply the same approach here that was used when writing work on the Atari 2600? How likely is it that you can get to the end by pressing random keys?
This question prompted me to contribute to the community, which was trying to solve this problem. In fact, we have a chicken and egg task — we need a better algorithm that will allow us to transmit a message, but this requires research, and experiments take a lot of time, because we do not have a more efficient algorithm.

Example of knowledge transfer: Imagine that at first we learned how to play a simple game, such as on the left. Then we save such concepts as “race”, “car”, “track”, “win” and learn colors or three-dimensional models. We argue that common concepts can be “transferred” between games. The similarity of games can be determined by the number of knowledge transferred between them. For example, the game "Tetris" and F1 will not be similar.
Therefore, I decided to use the second best approach, avoiding the initial slowdown, dramatically speeding up the system. My goals were:
- an accelerated environment (imagine that Prince of Persia can be completed 100 times faster) and the simultaneous launch of 100,000 games.
- environment, more suitable for research (we concentrate on tasks, but not on preliminary calculations, we have access to various games).
Initially, I believed that the bottleneck associated with speed may somehow depend on the complexity of the emulator code (for example, the Stella code base is large, besides, it relies on C ++ abstractions - not the best choice for emulators).

I worked together on several platforms, starting with one of the very first games ever created (along with Pong) - the Space Invaders arcade, Atari 2600, NES and Game Boy. And all this was written in C.
I managed to reach the maximum frame rate of 2000-3000 per second. To begin to get the results of experiments, we need millions or billions of frames, so the gap was huge.

FPGA Space Invaders - Low Speed Debugging Mode. The counter on the FPGA shows the number of past clock pulses.
And then I thought - what if we could speed up the right environment with iron. For example, the original Space Invaders went to the 8080 CPU with a frequency of 1 MHz. I managed to emulate an 8080 40 MHz CPU on a 3 GHz Xeon processor. Not bad, but after I placed all this inside the FPGA, the frequency went up to 400 MHz. That meant 24,000 FPS from one stream — the equivalent of a 30 GHz Xeon! Did I mention that you can push 100 8080 processors into the average FPGA? This already gives FPS of 2.4 million.

Space Invaders with hard acceleration, 100 MHz, a quarter of full speed.
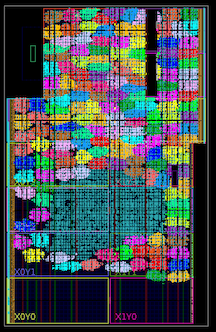
More than a hundred cores inside the Xilinx Kintex 7045 FPGA (indicated by bright colors; the blue spot in the middle is general logic for the demonstration).

Uneven execution path
You may ask, what about the GPU? In short, we need MIMD type concurrency , not SIMD . As a student, I worked for a while on implementing a Monte Carlo GPU tree search (this search was used in AlphaGo).
At that time, I spent countless hours trying to get the GPU and other hardware that work on the SIMD principle (IBM Cell, Xeon Phi, AVX CPU) to execute such code, and nothing came of it. A few years ago, I began to think that it would be nice to be able to independently develop iron specifically designed for solving tasks related to reinforcement training.
MIMD concurrency
On the 8080, I implemented Space Invaders, NES, 2600, and Game Boy. And here are some facts about them and the advantages of each of them.
NES Pacman
Space Invaders were just warming up. We managed to make them work, but it was only one game, so the result was not very useful.
The Atari 2600 is actually a standard in reinforced learning research. The MOS 6507 processor is a simplified version of the famous 6502, its design is more elegant and more efficient than that of the 8080. I chose the 2600 not only because of certain limitations associated with games and their graphics.
I also implemented the NES (Nintendo Entertainment System), it shares the CPU with 2600. There are much better games than the 2600. But both consoles suffer from an overly complex graphics processing pipeline and several cartridge formats that need to be supported.
In the meantime, I re-opened the Nintendo Game Boy. And that was what I was looking for.

1049 classic games and 576 games for Game Boy Color
In total, there are more than 1000 games, a very large variety, high quality, some of them are quite complex (Prince), games can be grouped and assigned complexity for research on knowledge transfer and training (for example, There are variants of Tetris, racing games, Mario). To solve the game Prince of Persia, you may need to transfer knowledge from some other similar game in which the points are clearly indicated (there is no such thing in Prince).
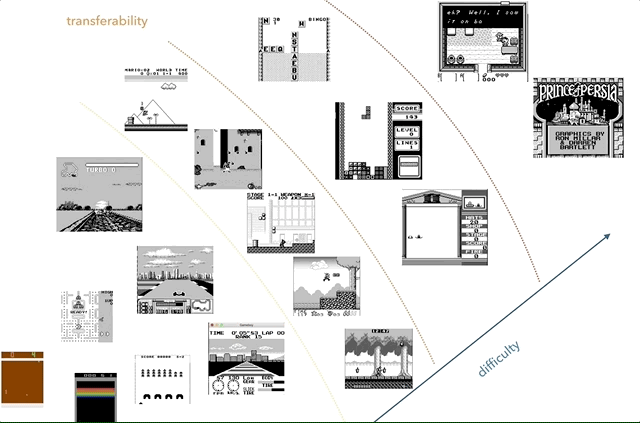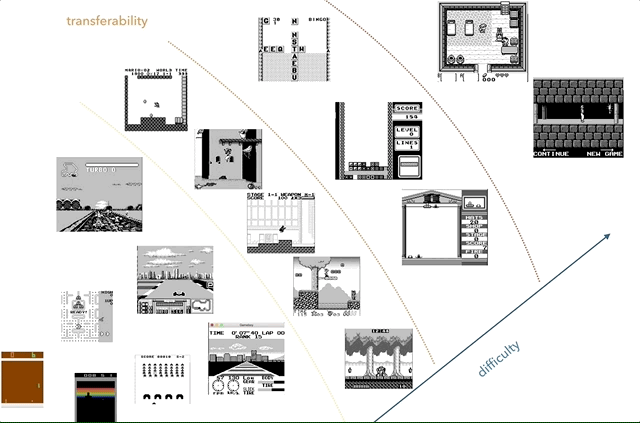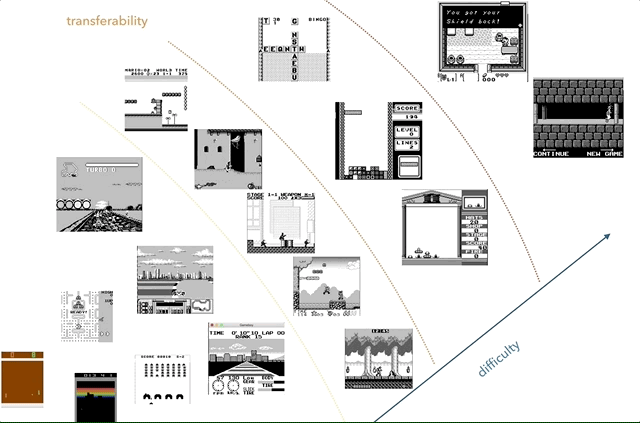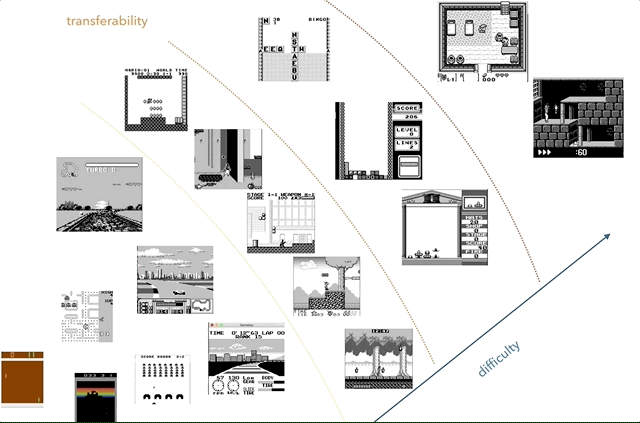
Nintendo Game Boy is my favorite research platform for knowledge transfer. On the chart, I tried to group games by complexity (subjectively) and similarities (concepts like racing, jumping, shooting, various games like Tetris; did anyone play HATRIS?).
The classic Game Boy has a very simple screen (160x144, 2-bit color), thanks to which the preprocessing becomes simple, and you can concentrate on important things. At 2600 even simple games have many colors. In addition, on the Game Boy objects are shown much better, without blinking and without having to take a maximum of two consecutive frames.

No crazy memory markup like NES or 2600. Most games can be made to work with 2-3 mappers.
Compact code - I managed to fit the entire emulator in C with no more than 700 lines of code, and my implementation of Verilog fits in 500 lines.
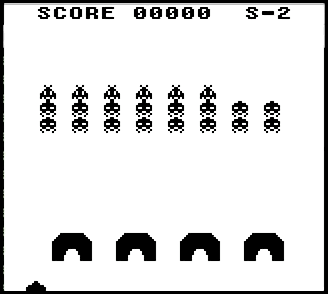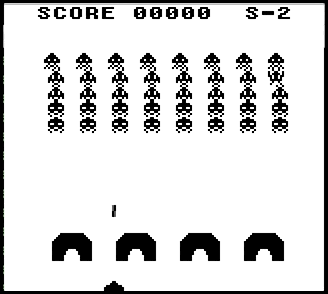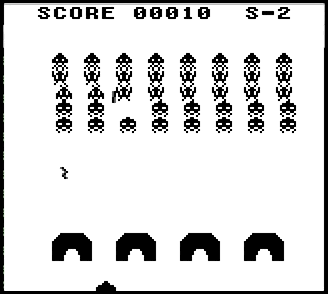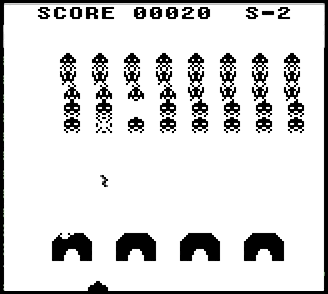
There is the same simple version of Space Invaders, as in the arcade.
And here it is, my 1989 dot-matrix Game Boy and FPGA version working via HDMI on a 4K resolution screen.

But what my old Game Boy can't:
Tetris, accelerated with the help of iron - recording from the screen in real time, the speed is 1/4 of the maximum.
Yes there is. So far, I have been testing the system under simple conditions, with an external network of rules interacting with individual Game Boys. More specifically, I used the A3C algorithm (Advantage Actor Critic), and I plan to describe it in a separate post. My colleague connected it to a convolutional network on an FPGA, and it works.
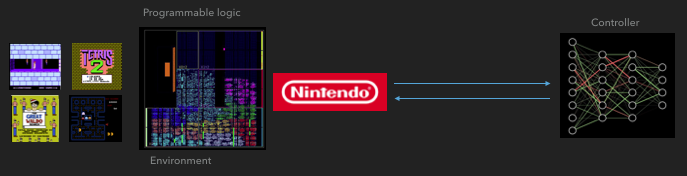
How FGPA communicates with the neural network
A3C Distributed
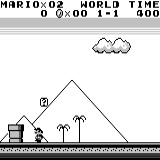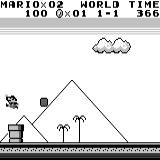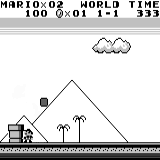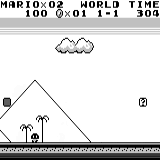
Mario land: the initial state. Accidentally pressing the keys will not take us far. In the upper right corner shows the remaining time. If we are lucky, we will quickly finish the game after touching the gumba. If not, it will take 400 seconds to “lose”.
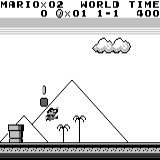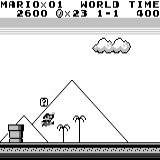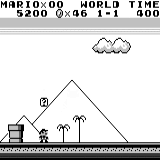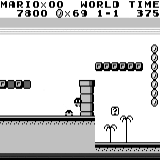
Mario land: after an hour of play, Mario learned to run, jump, and even opened a secret room, climbing into the pipe.
Pac Man: after about an hour of training, the neural network even managed to finish the whole game once (after eating all the dots).
I want to think that the next decade will be a period when supercomputer computing and AI find each other. I would like to have hardware that allows me to tune myself up to a certain level in order to adjust to the desired AI algorithm.
The next decade
code for the Game Boy C .
People often ask me: what was the most difficult? Everything - the whole project was quite painful. To begin with, there is no specification for the Game Boy. All that we learned, we got through reverse engineering, that is, we ran an intermediate task, such as a game, and watched how it is performed. This is very different from standard software debugging, because here we are debugging the hardware that runs the program. I had to come up with different ways to implement this. And I talked about how difficult it is to follow the process when it is running at 100 MHz? Oh, and no printf is there.
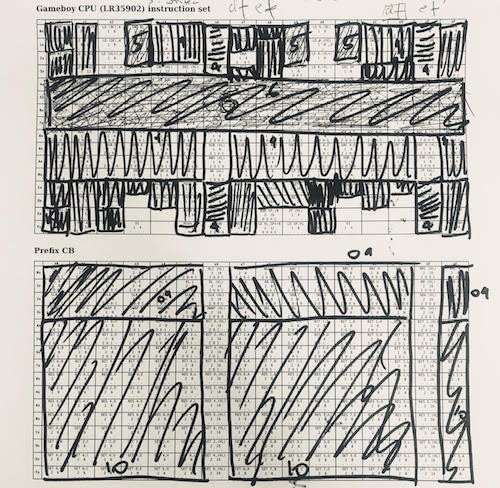
One approach to implementing a CPU is to group instructions by their functions. With 6502 it is much easier. The LR35092 crammed all sorts of "random" nonsense and there are many exceptions. I used this table when working with the Game Boy CPU. I used a greedy strategy - I took the largest piece of instructions, implemented them and crossed them out, then repeated them. 1/4 of the instructions are ALU, 1/4 is the loading of registers, which can be implemented fairly quickly. On the other side of the spectrum, there are all sorts of individual things, such as “download from HL to signed SP”, which had to be processed separately.

Debugging: run the code on the hardware you are debugging, write a log of your implementation and additional information (this shows a comparison of the Verilog code on the left with my C-emulator on the right). Then run diff for logs to find inconsistencies (blue). One of the reasons for using automation is that in many cases I found problems after millions of execution cycles, when a single CPU flag caused a snowball effect. I tried several approaches, and this one turned out to be the most effective.
You need a lot of coffee!

These books are 40 years old. It was amazing to rummage through them and look at the world of computers through the eyes of the users of that time - I felt like a guest from the future.
At first, I wanted to work with games in terms of memory, as described in a post from OpenAI.
Surprisingly, making Q-learning work well on input data representing memory states was unexpectedly difficult.
This project may not have a solution. It would be unexpected to learn that Q-learning will never succeed at work with memory in Atari, but there are chances that this task will be quite difficult.
Given that the Atari games used only 128 bp of memory, it seemed very attractive to process the 128 b instead of full screen frames. I got mixed results, so I started to deal with it.
And although I cannot prove that memory-based learning is impossible, I can show that the assumption that memory represents the full state of the game is not true. The CPU Atari 2600 (6507) uses 128 bp of memory, but it still has access to additional registers that live on a separate circuit (TIA, TV adapter, something like a GPU). These registers are used to store and process information about objects (racket, rocket, ball, collisions). In other words, they will be inaccessible if only memory is considered. Also, NES and Game Boy have additional registers that are used to control the screen and scroll. Only one memory does not reflect the full state of the game.
Only 8080 directly stores data in video memory, which allows you to extract the full state of the game. In other cases, the “GPU” registers are connected between the CPU and the screen buffer, while outside RAM.
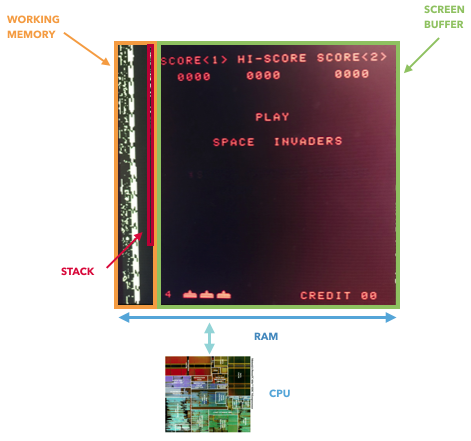
An interesting fact: if you study the history of the GPU, then the 8080 may turn out to be the first “graphics accelerator” - it has an external shift register, which allows the space invaders to be moved using one command, which offloads the CPU.

EOF
Distributed Tetris (1989)
How to build such a computer?
Recipe
Take a handful of silicon, apply training with reinforcements, experience with supercomputers, a passion for computer architecture, add sweat and tears, stir for 1000 hours until it boils - and voila.
Why would anyone need such a computer?
In short: to move towards enhancing artificial intelligence.
One of the 48 IBM Neural Computer boards used for experimentation
But a more detailed version
2016 year. Deep learning is everywhere. Image recognition can be considered a solved problem due to convolutional neural networks, and my research interests tend to neural networks with memory and learning with reinforcement.
Specifically, Google Deepmind authorship showed that you can reach a person’s level or even surpass it in various games for the Atari 2600 (a home game console released in 1977) using a simple learning algorithm supported by the Deep Q-Neural Network. And all this happens just when viewing the gameplay. It caught my attention.
One of the games with the Atari 2600, Breakout. The machine was trained using a simple reinforcement learning algorithm. After millions of iterations, the computer began to play better than humans.
I started experimenting with Atari 2600 games. Breakout, while impressive, cannot be called difficult. Complexity can be determined by the degree of complexity in accordance with your actions (joystick) to your results (points). The problem appears when the effect must wait for quite some time.
Illustration of the problem on the example of more complex games. On the left - Breakout (ATARI 2600) [the author was mistaken, this is the game Pong / approx. trans.] with very fast response and fast feedback. On the right, Mario Land (Nintendo Game Boy) does not provide instant information about the consequences of an action, and long periods of irrelevant observations may appear between two important events.
To make learning more effective, one can imagine attempts to transfer some of the knowledge from simpler games. This task now remains unsolved, and is an active topic for research. A recently published task from OpenAI is trying to measure just that.
The ability to transfer knowledge would not only accelerate training - I believe that some learning problems cannot be solved at all in the absence of basic knowledge. We need data efficiency. Take the game Prince of Persia:
There are no obvious points in it.
To complete the game, it takes 60 minutes.
Is it possible to apply the same approach here that was used when writing work on the Atari 2600? How likely is it that you can get to the end by pressing random keys?
This question prompted me to contribute to the community, which was trying to solve this problem. In fact, we have a chicken and egg task — we need a better algorithm that will allow us to transmit a message, but this requires research, and experiments take a lot of time, because we do not have a more efficient algorithm.
Example of knowledge transfer: Imagine that at first we learned how to play a simple game, such as on the left. Then we save such concepts as “race”, “car”, “track”, “win” and learn colors or three-dimensional models. We argue that common concepts can be “transferred” between games. The similarity of games can be determined by the number of knowledge transferred between them. For example, the game "Tetris" and F1 will not be similar.
Therefore, I decided to use the second best approach, avoiding the initial slowdown, dramatically speeding up the system. My goals were:
- an accelerated environment (imagine that Prince of Persia can be completed 100 times faster) and the simultaneous launch of 100,000 games.
- environment, more suitable for research (we concentrate on tasks, but not on preliminary calculations, we have access to various games).
Initially, I believed that the bottleneck associated with speed may somehow depend on the complexity of the emulator code (for example, the Stella code base is large, besides, it relies on C ++ abstractions - not the best choice for emulators).
Console
I worked together on several platforms, starting with one of the very first games ever created (along with Pong) - the Space Invaders arcade, Atari 2600, NES and Game Boy. And all this was written in C.
I managed to reach the maximum frame rate of 2000-3000 per second. To begin to get the results of experiments, we need millions or billions of frames, so the gap was huge.
FPGA Space Invaders - Low Speed Debugging Mode. The counter on the FPGA shows the number of past clock pulses.
And then I thought - what if we could speed up the right environment with iron. For example, the original Space Invaders went to the 8080 CPU with a frequency of 1 MHz. I managed to emulate an 8080 40 MHz CPU on a 3 GHz Xeon processor. Not bad, but after I placed all this inside the FPGA, the frequency went up to 400 MHz. That meant 24,000 FPS from one stream — the equivalent of a 30 GHz Xeon! Did I mention that you can push 100 8080 processors into the average FPGA? This already gives FPS of 2.4 million.
Space Invaders with hard acceleration, 100 MHz, a quarter of full speed.
More than a hundred cores inside the Xilinx Kintex 7045 FPGA (indicated by bright colors; the blue spot in the middle is general logic for the demonstration).
Uneven execution path
You may ask, what about the GPU? In short, we need MIMD type concurrency , not SIMD . As a student, I worked for a while on implementing a Monte Carlo GPU tree search (this search was used in AlphaGo).
At that time, I spent countless hours trying to get the GPU and other hardware that work on the SIMD principle (IBM Cell, Xeon Phi, AVX CPU) to execute such code, and nothing came of it. A few years ago, I began to think that it would be nice to be able to independently develop iron specifically designed for solving tasks related to reinforcement training.
MIMD concurrency
ATARI 2600, NES or Game Boy?
On the 8080, I implemented Space Invaders, NES, 2600, and Game Boy. And here are some facts about them and the advantages of each of them.
NES Pacman
Space Invaders were just warming up. We managed to make them work, but it was only one game, so the result was not very useful.
The Atari 2600 is actually a standard in reinforced learning research. The MOS 6507 processor is a simplified version of the famous 6502, its design is more elegant and more efficient than that of the 8080. I chose the 2600 not only because of certain limitations associated with games and their graphics.
I also implemented the NES (Nintendo Entertainment System), it shares the CPU with 2600. There are much better games than the 2600. But both consoles suffer from an overly complex graphics processing pipeline and several cartridge formats that need to be supported.
In the meantime, I re-opened the Nintendo Game Boy. And that was what I was looking for.
Why is the Game Boy so cool?
1049 classic games and 576 games for Game Boy Color
In total, there are more than 1000 games, a very large variety, high quality, some of them are quite complex (Prince), games can be grouped and assigned complexity for research on knowledge transfer and training (for example, There are variants of Tetris, racing games, Mario). To solve the game Prince of Persia, you may need to transfer knowledge from some other similar game in which the points are clearly indicated (there is no such thing in Prince).
Nintendo Game Boy is my favorite research platform for knowledge transfer. On the chart, I tried to group games by complexity (subjectively) and similarities (concepts like racing, jumping, shooting, various games like Tetris; did anyone play HATRIS?).
The classic Game Boy has a very simple screen (160x144, 2-bit color), thanks to which the preprocessing becomes simple, and you can concentrate on important things. At 2600 even simple games have many colors. In addition, on the Game Boy objects are shown much better, without blinking and without having to take a maximum of two consecutive frames.
No crazy memory markup like NES or 2600. Most games can be made to work with 2-3 mappers.
Compact code - I managed to fit the entire emulator in C with no more than 700 lines of code, and my implementation of Verilog fits in 500 lines.
There is the same simple version of Space Invaders, as in the arcade.
And here it is, my 1989 dot-matrix Game Boy and FPGA version working via HDMI on a 4K resolution screen.
But what my old Game Boy can't:
Tetris, accelerated with the help of iron - recording from the screen in real time, the speed is 1/4 of the maximum.
Is there any real benefit from this?
Yes there is. So far, I have been testing the system under simple conditions, with an external network of rules interacting with individual Game Boys. More specifically, I used the A3C algorithm (Advantage Actor Critic), and I plan to describe it in a separate post. My colleague connected it to a convolutional network on an FPGA, and it works.
How FGPA communicates with the neural network
A3C Distributed
Mario land: the initial state. Accidentally pressing the keys will not take us far. In the upper right corner shows the remaining time. If we are lucky, we will quickly finish the game after touching the gumba. If not, it will take 400 seconds to “lose”.
Mario land: after an hour of play, Mario learned to run, jump, and even opened a secret room, climbing into the pipe.
Pac Man: after about an hour of training, the neural network even managed to finish the whole game once (after eating all the dots).
Conclusion
I want to think that the next decade will be a period when supercomputer computing and AI find each other. I would like to have hardware that allows me to tune myself up to a certain level in order to adjust to the desired AI algorithm.
The next decade
code for the Game Boy C .
Debugging
People often ask me: what was the most difficult? Everything - the whole project was quite painful. To begin with, there is no specification for the Game Boy. All that we learned, we got through reverse engineering, that is, we ran an intermediate task, such as a game, and watched how it is performed. This is very different from standard software debugging, because here we are debugging the hardware that runs the program. I had to come up with different ways to implement this. And I talked about how difficult it is to follow the process when it is running at 100 MHz? Oh, and no printf is there.
One approach to implementing a CPU is to group instructions by their functions. With 6502 it is much easier. The LR35092 crammed all sorts of "random" nonsense and there are many exceptions. I used this table when working with the Game Boy CPU. I used a greedy strategy - I took the largest piece of instructions, implemented them and crossed them out, then repeated them. 1/4 of the instructions are ALU, 1/4 is the loading of registers, which can be implemented fairly quickly. On the other side of the spectrum, there are all sorts of individual things, such as “download from HL to signed SP”, which had to be processed separately.
Debugging: run the code on the hardware you are debugging, write a log of your implementation and additional information (this shows a comparison of the Verilog code on the left with my C-emulator on the right). Then run diff for logs to find inconsistencies (blue). One of the reasons for using automation is that in many cases I found problems after millions of execution cycles, when a single CPU flag caused a snowball effect. I tried several approaches, and this one turned out to be the most effective.
You need a lot of coffee!
These books are 40 years old. It was amazing to rummage through them and look at the world of computers through the eyes of the users of that time - I felt like a guest from the future.
OpenAI Research Request
At first, I wanted to work with games in terms of memory, as described in a post from OpenAI.
Surprisingly, making Q-learning work well on input data representing memory states was unexpectedly difficult.
This project may not have a solution. It would be unexpected to learn that Q-learning will never succeed at work with memory in Atari, but there are chances that this task will be quite difficult.
Given that the Atari games used only 128 bp of memory, it seemed very attractive to process the 128 b instead of full screen frames. I got mixed results, so I started to deal with it.
And although I cannot prove that memory-based learning is impossible, I can show that the assumption that memory represents the full state of the game is not true. The CPU Atari 2600 (6507) uses 128 bp of memory, but it still has access to additional registers that live on a separate circuit (TIA, TV adapter, something like a GPU). These registers are used to store and process information about objects (racket, rocket, ball, collisions). In other words, they will be inaccessible if only memory is considered. Also, NES and Game Boy have additional registers that are used to control the screen and scroll. Only one memory does not reflect the full state of the game.
Only 8080 directly stores data in video memory, which allows you to extract the full state of the game. In other cases, the “GPU” registers are connected between the CPU and the screen buffer, while outside RAM.
An interesting fact: if you study the history of the GPU, then the 8080 may turn out to be the first “graphics accelerator” - it has an external shift register, which allows the space invaders to be moved using one command, which offloads the CPU.
EOF