Matching problems and how to deal with them
Good afternoon! My name is Alexey Bulavin, I represent the center of competence of Sbertech on Big Data. Business representatives, product owners and analysts often ask me questions on the same topic - matching. What it is? Why and how to do it? The question “Why can it fail?” Is especially popular. In this article I will try to answer them.
Let's start with a household example. I have a little son. He recently mastered a mobile phone and now loves to carry it with him, so that, as an adult, he can easily call someone when he wants to and talk on some “very important” topic. He calls only mom, dad and grandmother. Grandmother gets the most: sometimes he calls her 10 times a day to tell him what happened to him 5 minutes ago.
In kindergarten, he has a friend, Denis, and Denis also has a mobile phone. Having met, they as adults are measured by phones, but never call each other. I once asked my son:
“Why don't you call and chat with a friend about this and that, discuss your affairs?”
- Dad, I don’t need this at all, we meet in the garden every day and, if anything, we’ll talk there. Things will wait.
I wondered how so? It turned out that neither he nor Denis simply knew their own phone number and could not exchange them. There is a lack of communication due to lack of keys.
New means of interaction in society give rise to new opportunities, more closely connect people, and indicate to systems that they are connected. Matching is one type of connectedness that indicates a subject’s relationship with himself. For example, when the same machine is sold on different bulletin boards, and we want to link and perceive these ads together as a whole.
Information today is a value that can be monetized. Accordingly, additional information gives additional value, increase profits or reduce costs - through the development of new features, a qualitative change in existing or in general the creation of new products.
As a rule, our product is clearly associated with certain objects for which we want to enrich knowledge. The more additional information we get from new sources, the more relevant the task of combining information from all sources into a single information space becomes more relevant, as if these are attributes of one system.
Getting and linking data seems to be a standard technical task. But due to a number of problems this can be difficult or even impossible:
People, organizations, objects - in each new system, everyone registers anew and receives new personal identifiers.
For some data types, an ID is assigned to individual events or messages in the stream, and not to the object that interests us. For example, the system captures loan applications, and if the same person draws up two separate applications, then it will be two different IDs. And for the person himself, the ID in the system will not be.
Ideally, each unique ID corresponds to a unique object, but in practice this is not the case. For example, a car has changed color or PTS number, a person has changed his surname or gender. According to formal signs for an automatic system, this is a new object. Also, a problem may arise if, for example, the operator instead of searching for an existing record in the database just starts a new one - it’s easier for him.

For example, in social networks, where the owner of the page distorts his first and last name or completely replaces them with fictitious ones. You can find dozens of Ivanov Urgantov or Vladimirov Poznerov, and these are not namesakes.
At different times, different objects or subjects can be expected for the same ID. For example, when phone numbers change owners.
It turns out that it is either impossible to connect the objects of two systems with each other by key, or the percentage and quality of connectedness are below the desired level. You can try to collect the key as a combination of several information fields, a composite key. But here new difficulties arise:
No one promises that ordinary information fields will be “not null”. And then how lucky. The more fields in the composite key, the more likely that some keys will not work.
For example, the address of the organization’s office is filled in at random: d.5 k.2 office 16; house 5 building 2 office 16; 5-2-16. Or phone: +7 (495) 344-3 ..., 8-495-344 ..., 495344 ....
In addition, the information fields in the composite key are characterized by the difficulties that we mentioned earlier. Fields included in the composite key may also not be unique, erroneous, deliberately distorted and not constant.
How to overcome the difficulties listed above and achieve 100% match? It’s worth starting with the question: is it really necessary to achieve such high levels of quality? Maybe 70% is enough to solve a business problem?
We have a composite key consisting of a set of attributes. Each of them with some probability will be filled and with some probability suitable for use as a key element. The probability that the entire composite key will be normal is the product of all the probabilities with all the attributes of the key. All this still needs to be multiplied by the probability that the object is in principle present in two systems. Then we get the probability of a match. And multiplying it by the total number of entities, we obtain a quantitative forecast by comparison.
The fewer attributes in the composite key, the higher the probability of matching, and closer to the probability that the object is in two systems. But the number of comparisons is growing and most often exceeds the forecast. This is due to the fact that with a decrease in the number of attributes in the composite key, the likelihood of erroneous matching increases.
Simply put, with a decrease in the number of attributes in a composite key, both the number of objects matched correctly and the number of matched errors increase. How would quantity fight quality. And depending on the business task, you can choose a matching strategy that biases the result either in the direction of quantity or in the direction of quality.
Is it possible to increase the quality and quantity at the same time? Of course you can. To do this, you need to spend more, and sometimes much more resources for additional data processing.
“Holes” in the data can be filled, getting them from other fields of the source. The location city can be obtained from the phone number code, TIN, region code. Gender can be obtained from the name and surname or by analyzing the author’s text. Enrichment algorithms are many.
Further data should be passed through filters. Filters can be either standard or specific, related to the peculiarities of filling and transforming data of a particular source. For example, a filter that removes non-printable characters, duplicates, doubles of characters, brackets, quotation marks, spaces can be attributed to standard ones.
To specific filtersone can attribute the detection and replacement of characters of another language layout that look the same visually in both languages - for example, the letter O in the English layout in the name Olya. Or the detection and replacement of characters of another language layout that sound the same or almost the same in both languages (Light and Light).
By normalizing may include a translation into another language, transliteration, leading to a pattern fill (name, grade, telephone, address, gender), and the replacement of the short names in full, and the replacement of slang diminutive forms.
Even with the same key composition, different criteria should often be used for different data sources. This is due to how a particular source is populated with data. To choose the right criteria, it is advisable to collect and analyze statistics on filling in the source fields. The quality improvement can be affected by the use of a frequency coefficient by field in the source (for example, for a car brand, last name), a coefficient of “capacity” (for example, for the name of a settlement depending on how big this settlement is in terms of the number of inhabitants).
With the simultaneous combined use of different keys of the match, you can use the coefficients as a condition for using a particular key. In the same way, you can use other criteria, for example, the completeness of a field. It is possible to combine matches on different keys between the same sources without applying conditions - the result is quite acceptable.
There are other matching algorithms that sometimes dramatically differ from those listed above. For example, matching with a weak key in conditions of communication with another object already patched with a strong key, if the capacity of such a connection is, by definition, small.
We give an example. Any car or apartment in its history, on average, has from 1 to 5 owners. If in two systems the object of the apartment or car is patched by a strong key, then the subject - the owner of this apartment, clearly associated with it - can be matched by any weakest parameter, for example, last name and first name.
Objects of any social network or a similar data structure with a large number of stable connections can be matched by weak keys belonging not to the object of the match itself, but to its environment. Matching objects themselves may in addition have their own weak key, but may not. In fact, the statement of the ancient Greek poet Euripides is algorithmized: "Tell me who your friends are, and I will tell you who you are."
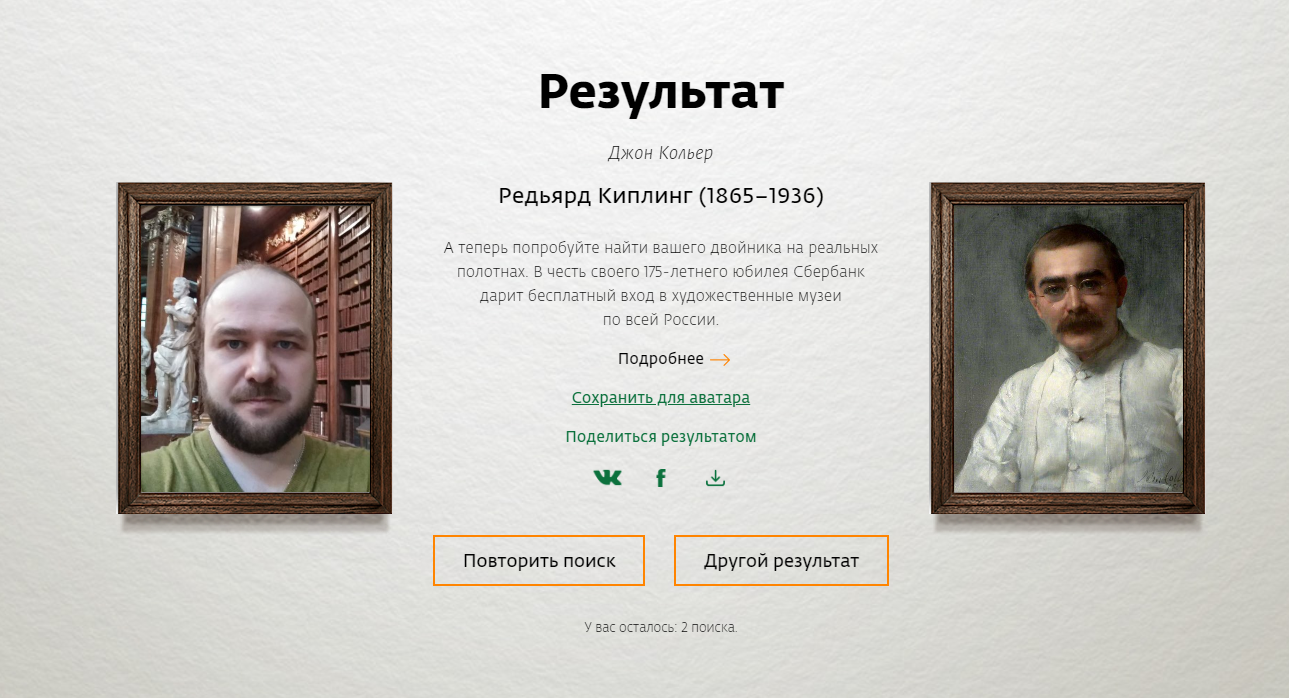
For two sources with one or more photographs of objects that are explicitly associated with their identifiers in the sources, you can apply photo matching. Objects or faces are highlighted in the photo and compared with the same objects or faces in another source. In fact, according to this principle, neural network services such as “Is your portrait in a museum?” From Google work: they match the face with the photo you uploaded with the faces of medieval people in portraits of museums. The criterion for matching is specially selected soft so that a distant, but sufficient similarity is obtained.

If there is a large number of copyright text information in different sources, you can try text mining algorithms to link the authors. This is a kind of analysis of handwriting, but it is not the form of writing that is analyzed, but the content of the text.
To improve the quality of the match, you need to use various algorithms, which in turn require a lot of resources. The more algorithms, the more resources are required. And if there is a lot of data, they are constantly changing, but should they be read quickly and inexpensively?
Most likely, storing, processing and matching data using traditional methods will fail. It’s worth considering the bigdata infrastructure. There are already quite a lot of such solutions, from different vendors and to any wallet.
In Sberbank, for example, corporate data matching is implemented as a data lake component on Hadoop, Spark and HBase. This solution allows you to process heterogeneous, unstructured data of large volume, run calculations on a large cluster, where data is stored without overhead. At the same time, open source software and commodity servers are used, which makes the solution fairly cheap and effective for this class of tasks. Hadoop has written a lot about Big Data. For example, I quite like how DataArt does this .
MatchBox is a system for automatic normalization and matching that we use in data lake of Sberbank. It was recently developed at the Sbertech Big Data Competency Center.
MatchBox is mainly used to build and keep up to date a single semantic data layer and a single client profile. The system makes it possible to automatically combine information from a large number of sources into a single information super entity, to integrate into the process of updating information from sources. This enriches the knowledge about the current and potential customers of the bank: their socio-demographic, psychological, behavioral characteristics and consumer preferences.
MatchBox works with data of any quality, uses libraries with validated normalization and match algorithms, has a custom rules configurator for this, and works in fully automatic mode by event, schedule, or as a service. MatchBox can scale, and the number of regularly processed sources is limited only by cluster resource quotas.
Here's what we managed to achieve through the implementation of MatchBox:
Now we are also exploring and piloting complex combinatorial matches, graph matches, photo matches. And for sources requiring high accuracy - a validation subsystem.
I hope that the article will help to answer questions related to the match, advance in understanding your own problems with working with data and find approaches to solving them.
Let's start with a household example. I have a little son. He recently mastered a mobile phone and now loves to carry it with him, so that, as an adult, he can easily call someone when he wants to and talk on some “very important” topic. He calls only mom, dad and grandmother. Grandmother gets the most: sometimes he calls her 10 times a day to tell him what happened to him 5 minutes ago.
In kindergarten, he has a friend, Denis, and Denis also has a mobile phone. Having met, they as adults are measured by phones, but never call each other. I once asked my son:
“Why don't you call and chat with a friend about this and that, discuss your affairs?”
- Dad, I don’t need this at all, we meet in the garden every day and, if anything, we’ll talk there. Things will wait.
I wondered how so? It turned out that neither he nor Denis simply knew their own phone number and could not exchange them. There is a lack of communication due to lack of keys.
What is matching?
New means of interaction in society give rise to new opportunities, more closely connect people, and indicate to systems that they are connected. Matching is one type of connectedness that indicates a subject’s relationship with himself. For example, when the same machine is sold on different bulletin boards, and we want to link and perceive these ads together as a whole.
Why match?
Information today is a value that can be monetized. Accordingly, additional information gives additional value, increase profits or reduce costs - through the development of new features, a qualitative change in existing or in general the creation of new products.
As a rule, our product is clearly associated with certain objects for which we want to enrich knowledge. The more additional information we get from new sources, the more relevant the task of combining information from all sources into a single information space becomes more relevant, as if these are attributes of one system.
Matching difficulties
Getting and linking data seems to be a standard technical task. But due to a number of problems this can be difficult or even impossible:
- No shared keys
People, organizations, objects - in each new system, everyone registers anew and receives new personal identifiers.
- No keys at all
For some data types, an ID is assigned to individual events or messages in the stream, and not to the object that interests us. For example, the system captures loan applications, and if the same person draws up two separate applications, then it will be two different IDs. And for the person himself, the ID in the system will not be.
- Key entries are not unique
Ideally, each unique ID corresponds to a unique object, but in practice this is not the case. For example, a car has changed color or PTS number, a person has changed his surname or gender. According to formal signs for an automatic system, this is a new object. Also, a problem may arise if, for example, the operator instead of searching for an existing record in the database just starts a new one - it’s easier for him.
- Key entries are erroneous or intentionally corrupted
For example, in social networks, where the owner of the page distorts his first and last name or completely replaces them with fictitious ones. You can find dozens of Ivanov Urgantov or Vladimirov Poznerov, and these are not namesakes.
- Key entries are inconsistent
At different times, different objects or subjects can be expected for the same ID. For example, when phone numbers change owners.
It turns out that it is either impossible to connect the objects of two systems with each other by key, or the percentage and quality of connectedness are below the desired level. You can try to collect the key as a combination of several information fields, a composite key. But here new difficulties arise:
- Compound key fields are insufficiently filled
No one promises that ordinary information fields will be “not null”. And then how lucky. The more fields in the composite key, the more likely that some keys will not work.
- Fields in a composite key have different fill standards
For example, the address of the organization’s office is filled in at random: d.5 k.2 office 16; house 5 building 2 office 16; 5-2-16. Or phone: +7 (495) 344-3 ..., 8-495-344 ..., 495344 ....
In addition, the information fields in the composite key are characterized by the difficulties that we mentioned earlier. Fields included in the composite key may also not be unique, erroneous, deliberately distorted and not constant.
Quantity vs quality
How to overcome the difficulties listed above and achieve 100% match? It’s worth starting with the question: is it really necessary to achieve such high levels of quality? Maybe 70% is enough to solve a business problem?
We have a composite key consisting of a set of attributes. Each of them with some probability will be filled and with some probability suitable for use as a key element. The probability that the entire composite key will be normal is the product of all the probabilities with all the attributes of the key. All this still needs to be multiplied by the probability that the object is in principle present in two systems. Then we get the probability of a match. And multiplying it by the total number of entities, we obtain a quantitative forecast by comparison.
The fewer attributes in the composite key, the higher the probability of matching, and closer to the probability that the object is in two systems. But the number of comparisons is growing and most often exceeds the forecast. This is due to the fact that with a decrease in the number of attributes in the composite key, the likelihood of erroneous matching increases.
Simply put, with a decrease in the number of attributes in a composite key, both the number of objects matched correctly and the number of matched errors increase. How would quantity fight quality. And depending on the business task, you can choose a matching strategy that biases the result either in the direction of quantity or in the direction of quality.
Enrichment, filtration, normalization
Is it possible to increase the quality and quantity at the same time? Of course you can. To do this, you need to spend more, and sometimes much more resources for additional data processing.
“Holes” in the data can be filled, getting them from other fields of the source. The location city can be obtained from the phone number code, TIN, region code. Gender can be obtained from the name and surname or by analyzing the author’s text. Enrichment algorithms are many.
Further data should be passed through filters. Filters can be either standard or specific, related to the peculiarities of filling and transforming data of a particular source. For example, a filter that removes non-printable characters, duplicates, doubles of characters, brackets, quotation marks, spaces can be attributed to standard ones.
To specific filtersone can attribute the detection and replacement of characters of another language layout that look the same visually in both languages - for example, the letter O in the English layout in the name Olya. Or the detection and replacement of characters of another language layout that sound the same or almost the same in both languages (Light and Light).
By normalizing may include a translation into another language, transliteration, leading to a pattern fill (name, grade, telephone, address, gender), and the replacement of the short names in full, and the replacement of slang diminutive forms.
Even with the same key composition, different criteria should often be used for different data sources. This is due to how a particular source is populated with data. To choose the right criteria, it is advisable to collect and analyze statistics on filling in the source fields. The quality improvement can be affected by the use of a frequency coefficient by field in the source (for example, for a car brand, last name), a coefficient of “capacity” (for example, for the name of a settlement depending on how big this settlement is in terms of the number of inhabitants).
With the simultaneous combined use of different keys of the match, you can use the coefficients as a condition for using a particular key. In the same way, you can use other criteria, for example, the completeness of a field. It is possible to combine matches on different keys between the same sources without applying conditions - the result is quite acceptable.
Other matches
There are other matching algorithms that sometimes dramatically differ from those listed above. For example, matching with a weak key in conditions of communication with another object already patched with a strong key, if the capacity of such a connection is, by definition, small.
We give an example. Any car or apartment in its history, on average, has from 1 to 5 owners. If in two systems the object of the apartment or car is patched by a strong key, then the subject - the owner of this apartment, clearly associated with it - can be matched by any weakest parameter, for example, last name and first name.
Objects of any social network or a similar data structure with a large number of stable connections can be matched by weak keys belonging not to the object of the match itself, but to its environment. Matching objects themselves may in addition have their own weak key, but may not. In fact, the statement of the ancient Greek poet Euripides is algorithmized: "Tell me who your friends are, and I will tell you who you are."
For two sources with one or more photographs of objects that are explicitly associated with their identifiers in the sources, you can apply photo matching. Objects or faces are highlighted in the photo and compared with the same objects or faces in another source. In fact, according to this principle, neural network services such as “Is your portrait in a museum?” From Google work: they match the face with the photo you uploaded with the faces of medieval people in portraits of museums. The criterion for matching is specially selected soft so that a distant, but sufficient similarity is obtained.
If there is a large number of copyright text information in different sources, you can try text mining algorithms to link the authors. This is a kind of analysis of handwriting, but it is not the form of writing that is analyzed, but the content of the text.
Big data
To improve the quality of the match, you need to use various algorithms, which in turn require a lot of resources. The more algorithms, the more resources are required. And if there is a lot of data, they are constantly changing, but should they be read quickly and inexpensively?
Most likely, storing, processing and matching data using traditional methods will fail. It’s worth considering the bigdata infrastructure. There are already quite a lot of such solutions, from different vendors and to any wallet.
In Sberbank, for example, corporate data matching is implemented as a data lake component on Hadoop, Spark and HBase. This solution allows you to process heterogeneous, unstructured data of large volume, run calculations on a large cluster, where data is stored without overhead. At the same time, open source software and commodity servers are used, which makes the solution fairly cheap and effective for this class of tasks. Hadoop has written a lot about Big Data. For example, I quite like how DataArt does this .
Our MatchBox
MatchBox is a system for automatic normalization and matching that we use in data lake of Sberbank. It was recently developed at the Sbertech Big Data Competency Center.
MatchBox is mainly used to build and keep up to date a single semantic data layer and a single client profile. The system makes it possible to automatically combine information from a large number of sources into a single information super entity, to integrate into the process of updating information from sources. This enriches the knowledge about the current and potential customers of the bank: their socio-demographic, psychological, behavioral characteristics and consumer preferences.
MatchBox works with data of any quality, uses libraries with validated normalization and match algorithms, has a custom rules configurator for this, and works in fully automatic mode by event, schedule, or as a service. MatchBox can scale, and the number of regularly processed sources is limited only by cluster resource quotas.
Here's what we managed to achieve through the implementation of MatchBox:
- high processing speed of large volumes at low cost of the process
- combining a large number of sources
- full automation of matching on a bigdata cluster - and, as a result, low cost
- Matching regularity - when used in regular cyclic business processes, financial costs are reduced
- high quality of matching due to normalization, enrichment and selection of the optimal configuration - the cost of the final data rises
- matchability due to configuration of rules - the cost of introducing new initiatives is reduced
- unification of the published result (low cost of introducing new initiatives)
- building match chains
Now we are also exploring and piloting complex combinatorial matches, graph matches, photo matches. And for sources requiring high accuracy - a validation subsystem.
I hope that the article will help to answer questions related to the match, advance in understanding your own problems with working with data and find approaches to solving them.